基于改进生成对抗网络的变压器声纹故障诊断
2024-04-22柴方森李文鹏
王 欢,王 昕,张 峰,齐 笑,柴方森,李文鹏
(1.上海电力大学电气工程学院,上海 200090;2.上海交通大学电工与电子技术中心,上海 200240;3.国网吉林省电力有限公司四平供电公司,吉林四平 136000)
0 引言
电力变压器作为电网的重要组成部分,其安全可靠运行对电力系统供电的稳定性和可靠性至关重要。当变压器发生故障时,可能会产生不同的声音信号,这些声音信号蕴含丰富的状态信息,对变压器故障的有效反映与识别具有重要意义[1-4]。
目前变压器异常状态的声纹数据十分匮乏且不均衡,造成深度学习算法过拟合、泛化能力低、训练不稳定等问题[3],使得现有方法在小样本变压器故障诊断场景下的识别准确率有限[5-9]。为此,有研究采用数据增强技术(Data Augmentation Technology,DAT)[10-11]对小样本数据集进行扩充,并调整训练数据的类间分布,以提高诊断模型的泛化能力和故障识别准确率。生成对抗网络(Generative Adversarial Network,GAN)[12-16]相比传统的数据增强方法,如几何变换法、过采样技术[17-18]和Mixup[19]等,能够生成更高质量、更多样性的合成数据,且能够自适应学习。但传统GAN 存在梯度消失和模式崩塌的问题,为解决该问题,Martin Arjovsky 等提出的Wasserstein 生成对抗网络[20](Wasserstein Generative Adversarial Network,W-GAN),引入了Wasserstein距离[21-22]来替代JS(Jensen-Shannon)散度,以更有效地度量真实数据分布和生成数据分布之间的距离。然而,尽管该方法在理论上表现出色,但在应用到变压器的声纹故障检测上仍存在一些缺陷:(1)需要针对变压器故障的每个类别单独训练1 个生成器,使得每个生成器专门生成某个特定类别的样本,对于多类别的变压器故障诊断而言,操作繁琐且耗时较长;(2)为了满足Lipschitz 连续性约束,W-GAN 规定所有参数矩阵的元素限制在某个范围[-c,c],但参数总是取到极限值,同时参数c也很难确定,选取不好就会引起梯度消失或爆炸,参数矩阵的结构不稳定,以致W-GAN 收敛速度较慢。
本文提出1 种基于梅尔声谱图和改进的Wasserstein 生成对抗网络(Improve Wasserstein Generative Adversarial Network,IW-GAN)的变压器声纹故障识别的方法。其中,在W-GAN 基础上加入条件约束项,使其更好引导多类别样本生成;同时,提出使用更具表达能力的Transformer 网络[23-24]作为生成器,设计满足Lipschitz 连续性约束的谱归一化[25]卷积神经网络(Spectral Normalization-Convolutional Neural Network,SN-CNN)作为判别器。Transformer 生成器的多头注意力机制使模型拥有更好的表达能力;结构简洁的SN-CNN 判别器使得图像生成模型的计算复杂度低,且性能良好。最后采用了多种评价指标评价了在不同的数据增强算法和不同的分类算法下变压器故障诊断的效果,验证了本文模型的有效性。
1 变压器声纹诊断流程
小样本下基于改进生成对抗网络的变压器声纹故障诊断技术,其诊断流程分为数据预处理及特征提取、故障数据增强、诊断模型训练和诊断效果评价4 个部分。具体流程如图1 所示。

图1 变压器声纹诊断模型整体流程Fig.1 Overall process of transformer voiceprint diagnosis model
1)在采集到待识别的变压器声纹样本后,将音频进行预处理,并提取梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)[26-27],沿时间堆叠得到声谱图;对原始数据集进行划分,增量样本与测试样本的比例为8∶2。
2)对IW-GAN 的判别器D 进行预训练,以提升其辨别能力,促进生成器G的优化;然后将生成器和判别器按5∶1次数交替训练,直到达到平衡点。
3)用新生成的变压器故障样本对原始训练样本扩充后,输入到不同分类器,如支持向量机(Support Vector Machine,SVM)、长短期记忆网络(Long Short-Term Memory,LSTM)和卷积神经网络(Convolutional Neural Network,CNN)中进行识别。
4)采用IS(Inception Score)、FID(Fréchet Inception Distance)、KID(Kernel Inception Distance)评价指标对生成效果进行评价,基于准确率、损失率对不同识别模型分类效果比对分析。
2 MFCC特征提取
MFCC 的计算流程为:
1)预处理,包含预加重、分帧、加窗等。
2)对每一帧的时域信号进行快速傅里叶变换,得到线性频谱X(k),如式(1)所示:
式中:x(n)为时域信号;n为时域上的采样点;k为频域上的离散频率点;N为第一帧信号的长度。
3)将X(k)通过梅尔三角滤波器组,变换线性频率到梅尔频率,如式(2)所示:
式中:s(m)为第m个梅尔滤波器的输出;Hm(k)为第m个滤波器参数。
4)随后再将得到的梅尔频率取对数后进行离散余弦变换(Discrete Cosine Transform,DCT),得到最终的特征参数MFCC。
式中:b为频率通道索引;M为梅尔滤波器组的三角滤波器个数;L为MFCC 的阶数;c(r)为第r维倒谱系数值;P为s(m)的长度。
3 IW-GAN数据增强
3.1 W-GAN的原理
针对变压器故障声纹数据匮乏,导致后续故障分类采用的深度学习算法过拟合、泛化能力低、识别准确率有限等问题,常采用数据增强算法扩充故障数据。但是传统数据增强算法GAN 网络会出现梯度消失和模式崩溃问题,主要原因在于其使用了KL(Kullback-Leibler)散度和JS 散度来度量2 个分布之间的差异。为了解决这些问题,Wasserstein 生成对抗网络引入了Wasserstein 距离W(Pdata,Pg)来取代JS 散度,Wasserstein 距离的表达式如式(4)所示:
函数f由神经网络表示,并通过权重剪枝限制f中所有参数不超过确信范围以确保K的存在。但是,剪枝使得判别器权重矩阵的结构被破坏,以致WGAN 收敛速度较慢。
W-GAN 的生成器和判别器的损失函数LG和LD如下:
式中:E(·)为期望;fw(x)为判别器对真实数据样本的评估输出;fw(G(z))为判器对生成器生成样本G(z)的评估输出。
3.2 损失函数的改进
由于电力变压器故障的复杂性,故障诊断是一个多分类问题。针对传统的W-GAN 模型需要对每个故障类别单独训练生成器的问题,提出了将故障样本的类别标签y作为模型的额外条件变量。这样做使得模型能够生成多类故障数据,并且显著提高了生成样本的效率。结合类别信息的模型结构如图2 所示。
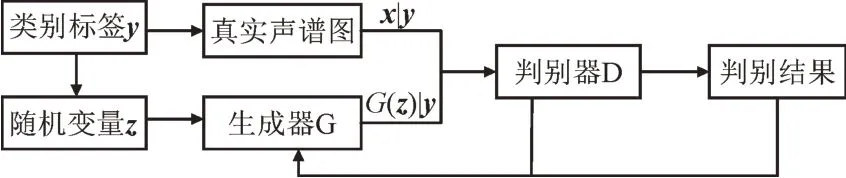
图2 改进的W-GAN模型结构Fig.2 Improved W-GAN model structure
从图2 可以看出,在生成器中,输入为随机变量z与类别标签y的组合;判别器的输入是真实故障样本x和生成G(z)分别与类别标签y结合后共同输入以进行判别,即判别器不仅能判断生成的梅尔声谱图是否真实,还能判断生成声谱图的类别和输入真实故障声谱图的实际类别是否相符。这样使得模型能够生成指定类别的变压器声纹声谱图。
因此IW-GAN 模型的损失函数如式(6)所示:
3.3 基于Tansformer网络的生成器
近年来,聊天生成型预训练变换模型(Chat Generative Pre-trained Transformer,ChatGPT)因其强大的创造性和逻辑思维能力而成为广受关注的模型。该模型采用了Transformer 作为底层架构,这种模型通过引入自注意力机制,使网络能够并行处理输入序列中的位置信息,更好地理解了输入序列之间的相互依赖关系,从而显著提高了训练和推理速度。因此。在GAN 中,将Transformer 作为生成器的结构能够赋予模型更强的表达能力和泛化能力。相对于CNN,Transformer 能够建立图像的全局依赖关系,从而获取更多的图像全局信息。为了适应图像任务,本文模型对传统结构进行了调整,去掉了解码器,仅保留编码器。
编码器主要由多头注意力机制和多层感知机组成。单个的注意力机制,其每个输入包含3 个不同的向量,分别为Query向量(Q),Key向量(K),Value向量(V)。他们的结果分别由输入特征图X和3 个权重Wq,Wk,Wv做矩阵乘法得到。
接着通过softmax 函数计算每个输入向量的注意力分数Attention,如式(8)所示:
式中:dk为Q或K的维度,Q和K的维度相等。
多头注意力机制MltiHead如式(9)所示:
式中:Concat为连接操作;headh为第h个注意力头的输出;Wo为权重矩阵。
3.4 基于SN-CNN的判别器
保证GAN 判别器的训练稳定性,本质上是需要判别器的函数满足Lipschitz 条件,若判别器仍采用Transformer,其模型函数不满足Lipschitz 条件,因此,提出基于谱一化卷积神经网络设计判别器。W-GAN首次提出了采用权重裁剪方法来使GAN 的判别器满足Lipschitz 条件。但是,剪枝使得判别器权重矩阵的结构被破坏,以致W-GAN 收敛速度较慢。本文设计SN-CNN 判别器,通过在CNN 中引入谱归一化层,将每一层网络的权重矩阵限制在一个范围内,即通过使参数矩阵中的每个元素除以其谱范数,使得Lipschitz 常数为1。在算法实现中,使用幂迭代法来计算权重矩阵的奇异值,以减少计算资源的使用。
式中:wa,wa-1分别为第a层和第a-1 层的权重矩阵;Ha,Ha-1分别为第a层和第a-1 层的海森矩阵;‖·‖2为谱范数。
σ(ω)为矩阵ω的最大奇异值。对于对角矩阵H,有σ(H)=max(h1,h2,...,ha),其中h1,h2,...,ha为H的奇异值。因此,式(10)可以写成:
为了让f(x)满足Lipschitz 连续性约束,需要对其梯度进行归一化处理,如式(12)所示。
式中:i为神经网络层次。
由式(12)可知,SN-CNN 判别器每层网络的权重矩阵的最大奇异值恒等于1,且没有破坏权重矩阵的结构。因此,SN-CNN 判别器不仅能够满足Lipschitz 条件,还能保持参数矩阵的稳定性,加速训练,简化超参数调整。
4 算例分析
4.1 实验方法与频谱分析
通过实验评估本文所提变压器声纹故障诊断模型的性能,使用信号采集系统采集了220 kV 变压器正常运行、短路故障和过电压异常3 种状态的声信号。
将采集后的声音分割为1 s 的长度并保存为音频文件,共675 条声纹切片样本数据。在特征提取MFCC 的预处理阶段,首先需要对采集的变压器音频分帧,取帧长为30 ms,取帧重叠率为40%;然后对每帧信号加窗,窗函数选择汉明窗;本文提取13 维的MFCC 特征向量,对正常运行、短路故障和过电压运行3 种状态下的MFCC 沿时间维度堆叠起来得到二维矩阵并进行可视化分析,结果如图3 所示。图例中数值的大小对应特征强度和能量的高低。

图3 不同状态下的可视化声谱图Fig.3 Visual spectrograms under different states
实验采用电容式麦克风对某220 kV 变电站主变不同状态的声信号进行采集,麦克风频率响应范围为20~20 000 Hz,设置变压器声信号的采样频率为8 000 Hz。变压器的正前方、正后方和右侧分别布置一只麦克风,均距离变压器表面0.5 m,距离地面1.2 m。
由图3 可以看出,正常运行、短路故障、过电压运行3 种状态的梅尔声谱图颜色分布和明暗存在明显差异,故可以作为声纹提取的有效特征。
经过预处理和特征提取后,需要对样本集进行划分。实验共采集变压器声纹数据675 条,为了进行后续的增量学习研究,首先从变压器3 种运行状态中分别提取80%的样本作为增量样本,剩下20%作为测试集。利用IW-GAN 生成的新梅尔声谱图对原始数据集进行扩充,使得每一类变压器运行状态的总样本数达到500,以起到提高数据集样本多样性的目的。具体的样本分布如表1 所示。

表1 样本数据具体分布Table 1 Specific distribution of sample data
4.2 IW-GAN网络结构及参数设置
根据所需生成数据和输入数据的规模,判别器的结构与参数设如表2 所示,本实验采用的生成器具体结构如图4 所示。
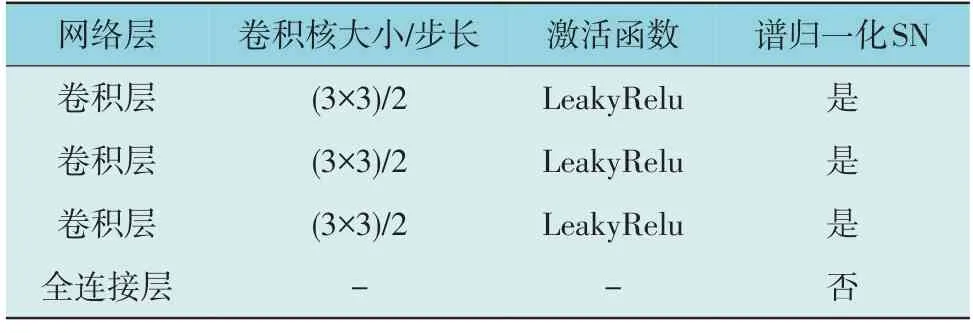
表2 SN-CNN判别器网络结构Table 2 SN-CNN discriminator network structure
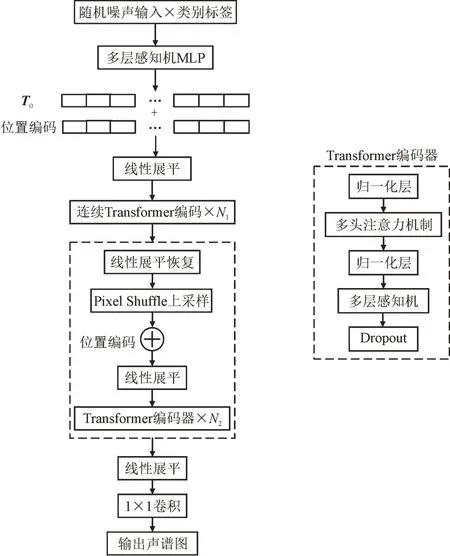
图4 Transformer生成器网络结构Fig.4 Transformer generator network structure
如图4 所示,生成器的输入是随机噪声向量z与类别标签y相乘组成,输入向量经多层感知机映射形成一段长序列T0,并与位置编码向量相加,经过线性展平后输入到N1个Transformer 编码器中。输出的张量经线性展平恢复后,进行Pixel Shuffle上采样,并重复之前步骤。最后线性展平后,进行1×1 卷积,输出声谱图。其中,Transformer 编码器由归一化层、多头注意力机制层、多层感知机层和Dropout 层组成。取N1=3,N2=2。
如表2 所示,本文使用CNN 作为判别器网络,由3 个卷积层和1 个全连接层组成。其中,卷积核大小选为3×3,步长为2,激活函数选择LeakyRelu,每个卷积层后面都跟1 个谱归一化层。生成器和判别器的训练过程中,均采用了Adam 优化器,矩估计参数β1和β2分别设置为0.5 和0.99。设置生成器的学习率为0.000 2,批次大小为1 280 判别器的学习率为0.000 15,批次大小为64。
4.3 模型评价和结果分析
4.3.1 生成图像质量评价和分析
为了对比不同数据增强算法对样本数据的生成效果,这里选用SMOTE(Synthetic Minority Oversampling Technique,SMOTE),GAN,W-GAN 和IW-GAN 网络进行对比。目前比较通用的对GAN 网络生成样本质量的评价指标有IS,FID,KID 3 种。
IS 首先使用Inception 模型来评估每张生成图像的真实性,然后计算生成图像类别分布的KL 散度,以此作为多样性的度量。IS 数值越高表示生成图像质量越好。FID 使用了Inception 模型中抽取的特征向量,并计算了它们之间的Fréchet 距离。FID 的值越低表示生成图像与真实图像的分布越接近。KID 使用了核函数来衡量特征空间中的样本之间的距离,KID 值越低表示生成图像质量越高。
生成样本质量评估结果如表3 所示,从表3 可以看出,IW-GAN 模型的IS 值高达8.92,在4 种方法当中最高,而该方法的FID 值和KID 值最低,分别为14.62,0.71。这说明本文提出的IW-GAN 模型在维持样本相似性同时,有效增强了样本的多样性。
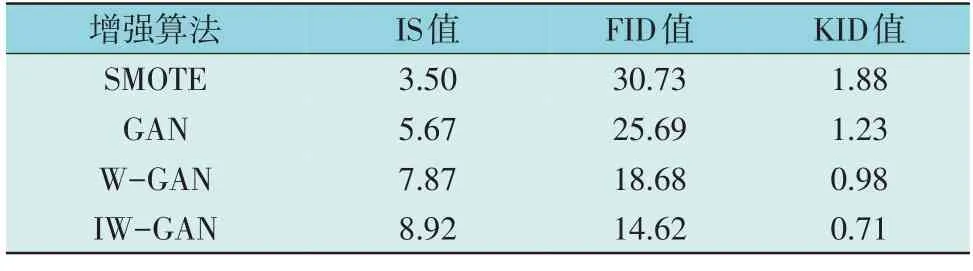
表3 生成样本质量评估Table 3 Quality assessment of generative sample
4.3.2 故障识别评价和分析
在适用性分析中,本文分类算法采用了SVM,LSTM 及CNN。不同分类模型在经过本文模型进行数据扩充后,测试集上对不同故障类型辨识的混淆矩阵如图5 所示。
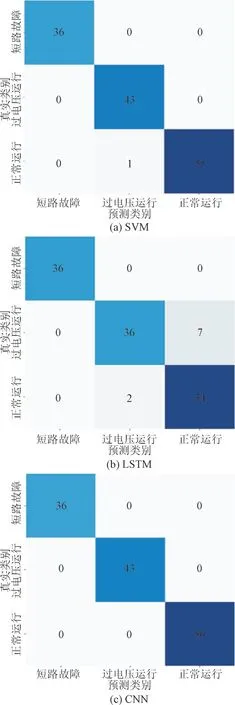
图5 不同分类模型的混淆矩阵Fig.5 Confusion matrices of different classification models
采用不同数据生成模型,如SMOTE,GAN 和W-GAN 扩充数据后,采用CNN 分类时,模型在测试集上的准确率、损失率随训练轮数的变化情况如图6 所示。不同模型的准确率对比如表4 所示。
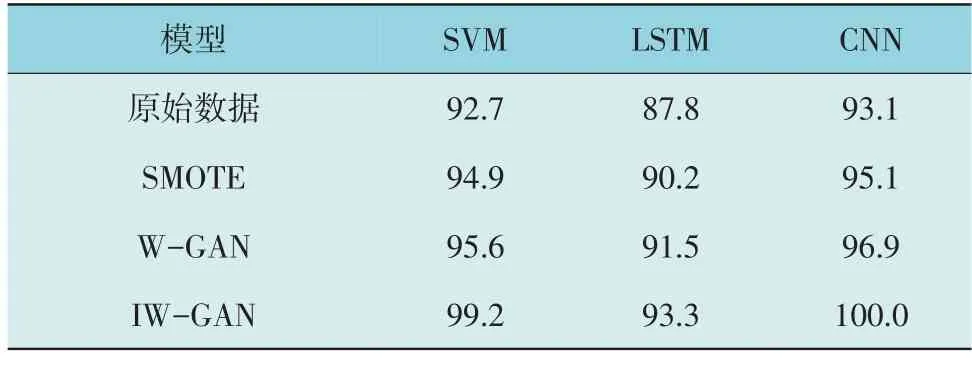
表4 不同模型组合的准确率对比Table 4 Accuracy comparison of different model combinations %
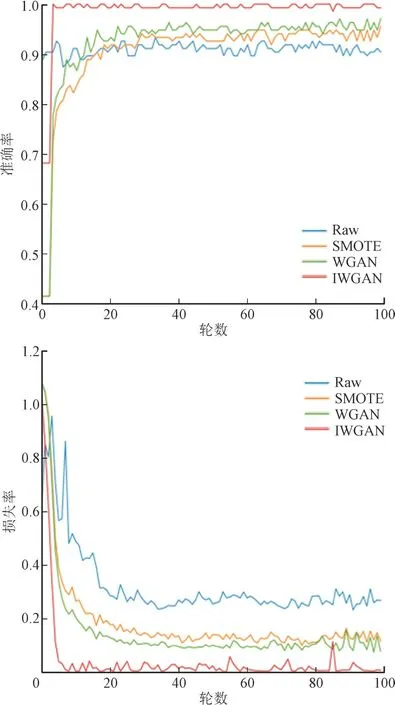
图6 不同生成模型的准确率和损失率对比Fig.6 Comparison of accuracy and loss rate of different generative models
由图5,图6 可以看出,相对于其他数据增强模型结合其他分类算法,采用IW-GAN 数据增强后使用CNN 进行分类的模型表现出明显的识别率提升和损失率降低。
由表4 可知,相较原始数据,采用不同的数据增强算法扩充样本后,对不同分类器的变压器声纹故障诊断模型的识别率均有不同程度的提升。采用SMOTE 算法时,分类器SVM,LSTM 和CNN 识别准确率相较于原始数据分别提升了2.2%,2.4%,2.0%;采用原始W-GAN 算法时,分类器SVM,LSTM 和CNN 识别准确率相较于原始数据分别提升了2.9%,3.7%,3.8%;采用本文改进设计的IWGAN,分类器SVM,LSTM 和CNN 识别准确率相较于原始数据分别提升了5.5%,5.5%,6.9%。
本文提出的采用更具表达能力的Transformer网络作为IW-GAN 的生成器,谱归一化卷积神经网络(SN-CNN)作为IW-GAN 的判别器,能够有效对小样本数据进行扩充,进而提升变压器声纹故障诊断模型的故障识别能力。
5 结论
本文针对电力变压器声纹故障诊断中因变压器故障声纹数据匮乏而导致的模型识别故障识别准确率不高、泛化能力低的问题,提出的基于IWGAN 的变压器声纹诊断模型,通过实验和评价系统验证了本文方法的有效性,得到结论如下:
1)IW-GAN 能够实现对原始数据分布特征的有效学习,相较于传统数据增强算法能够更稳定生成多样性和高质量的样本。
2)应用本文提出的IW-GAN 数据增强后,相较于原始数据,不同分类器的识别准确率都得到了提升,且相比于SMOTE 与原始W-GAN,本文方法的提升效果更加显著。
3)该变压器声纹诊断模型可在数据匮乏和不均衡的情况下对变压器在线状态进行有效诊断,采用IW-GAN 相较原始数据故障识别率提升6.9%。
