基于词向量和卷积神经网络的税务问答系统∗
2024-04-17杜航牟莉
杜 航 牟 莉
(西安工程大学计算机科学学院 西安 710600)
1 引言
随着我国社会的不断发展,税法的地位与日俱增,税务机关作为国家职能部门之一,普及税收法律法规及相关政策更是任重道远。因此,如何帮助纳税人快速便捷地了解税务知识,对税务机关来说尤为重要[1]。早在2010年,国家税务总局就开通了全国统一的12366 纳税服务热线,由税务工作人员电话解答纳税咨询问题,并逐步开始建立税收业务知识库[2]。随后国家税务总局加快了发展税务信息化的脚步,于2017 年上线了12366 纳税服务平台,税收业务知识库收录的税收政策及答复口径从最初的几百条已逐步扩展到了几万条。以往,纳税人主要通过现场咨询或电话咨询解决与纳税相关的问题,后来也出现了网络留言等更加简单便捷的咨询方式。但随着目前纳税人咨询数量的快速增长及税务咨询问题的复杂度逐渐加深,过去传统的口头咨询出现了解答不正确,人力成本偏高等问题,而正确度较高的网络咨询却又无法保障回应的及时性[3~5]。因此,仅依赖于传统的税务咨询方法,很难完全解决纳税人的咨询需求,导致税务机关面临的咨询压力较大。
目前网络税务咨询方式大多为在线留言,纳税人提出的问题不能够立即得到回答。当然也有一些平台提供了半智能的在线问答服务,但从工作人员的角度出发,此类系统服务反而造成了新的问题[6~7]。这是由于此类平台是在纳税人提出询问后,由工作人员手动选择相应的问题再进行回答,往往会导致答案比较模糊,反馈的质量也不高。此外,这些系统进行数据更新和采集时操作较为复杂,使得维护成本也相对较高。
因此,税务问答系统的目标就是对纳税人提出的税务问题做出有针对性的简洁易懂的回答。通过税务问答系统受理大部分的咨询业务,使税务服务和税收业务得以改变、创新和提升。
2 关键技术
2.1 技术思路
现有问答系统的基本思路是通过数据模块化分类以及问题关键词提取,来实现对问题的准确检索[8~9]。因此,问答系统的性能高低与其基本算法、性能以及对数据的处理程度有着密切的关系。数据处理效果取决于对数据本身预处理和关键字提取的设计[10~11]。由于中文自身带有特定的情感,以及语气、语义、语境的复杂性,因此对于数据关键词的处理是整个问答系统性能的关键点之一。其中许多限定领域的问答算法使用了单词向量(Word2Vec)和卷积神经网络(Convolutional Neural Networks,CNN)相结合的方式进行构建,该方法可以对多个数据集的处理,并且具有一定的可靠性和有效性。基于以上设想,本文将Word2Vec 和CNN模型添加到现有的税务咨询问答系统的初始框架中,继而对税务咨询问答系统中的各类型指标进行改进。
2.2 Jieba分词
由于使用Word2Vec构建词向量是基于词语进行的,因此需要对输入的语料数据在清洗后进行词汇分割,目前进行中文词汇分割的算法有很多,例如Jieba 分词、正向最大匹配法、逆向最大匹配法等。通过各类分词方法的尝试,本文最终选择采取Jieba 分词的方法对词汇进行分割,分词的主要原理是将一个句子进行划分,使其变成一个个组成句子的词语[12]。先对各个词语进行编号并形成路径,然后对所有路径进行可能性计算,最后找出最大可能性的路径作为分词结果,如式(1)所示:
W为句子的划分,所产生的分词为w1,w2,…,wn。最大可能性计算方法如式(2)所示:
2.3 Word2Vec词向量
Word2Vec是Google在2013年发布的基于神经网络的词向量生成工具。它从包含高质量的分布式词向量的大量文档中进行学习,涵盖了大量的词语含义和词汇信息[13]。Word2Vec 的核心结构是简化的神经网络语言模型,主要分为两个模型:ContinuousBag-of-Words(CBoW)和 ContinuousSkipgram(Skip-gram)[14]。在此选择CBoW 模型,如图1所示。

图1 CBoW模型示意图
优化CBoW模型目标如式(3)所示:
其中,wt是当前词,p(w|Context(w))是核心概率条件函数,Word2Vec输入可以作为可优化参数,更好地为相似性任务的疑问句提供服务。
2.4 卷积神经网络
上一节提到以词向量作为输入层,并对句子中的含义进行建模,接下来要进行语义识别和特征提取[8],这就需要通过卷积神经网络来具体实现,最后才可以引入最大池化层(Max-Pooling)。合并各种结果后将卷积窗口下提取的特征引入Softmax,以实现问题类别的多分类算法。CNN(卷积神经网络)分为三层结构:拥有局部特征提取功能的是卷积层;拥有降低数据维度功能的是池化层(即降维操作);拥有结果输出功能并类似于传统神经网络的部分的是全连接层[15]。
1)卷积层特征提取
如图2 所示,对长度为n 个单词的句子进行划分段落,再将长度为k 的单词向量连接起来以形成n*k 的特征矩阵,然后使用不同长度的卷积窗口对其执行卷积运算,从而获得各种n-gram功能。
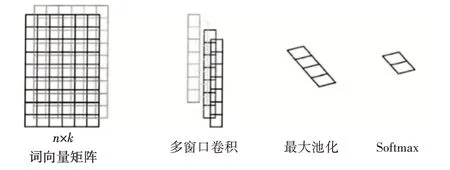
图2 卷积层特征提取示意图
2)池化层合并
在池化层,可以将多个卷积层的结果进行合并。通过Max_Pooling 的处理,能够将多个卷积层得到的特征进行合并进行降维操作以形成最终的特征。Max_Pooling有两个优点。
首先,本操作可以保证位置与旋转不变形。使用Max_Pooling 时不必考虑强特征的位置,即无论强特征出现在哪个位置,Max_Pooling 都能将其提取出来。
其次,Max_Pooling 能减少模型参数数量,有利于减少模型过拟合问题。经过操作后往往把数组转换为单一数值,这样能减少后续全连接层的神经元个数。
3)输出层多分类
Softmax 多重分类器作为模型的最后一层,计算过程如式(4)所示:
交叉嫡作为问答模型的目标函数,如式(5)所示:
卷积神经网络问答模型的第个神经元的输出如式(6)所示:
在同一时刻使用Softmax 和交叉熵,进行误差的反向传播,得到的结果如式(7)所示:
3 参数调优
3.1 正则化方法
卷积神经网络模型复杂度(即卷积神经网络隐含层的层数和神经元的个数)取决于问题的复杂度:若模型复杂度过低,当遇到复杂函数时很难找到其规律,拟合的效果会变差,也就达不到理想的拟合精度;若模型复杂度过高,计算量就会随之增加,计算所需要的时间也会延长,整个模型的训练速度就会变慢,甚至会出现过拟合现象。在实际应用中,模型复杂度一般都是依靠使用者的经验或者实验进行调节的,这种调节方式主要依靠的是使用者的主观判断,往往并不能获取正确的样本,导致模型训练存在误差。训练误差和训练模型复杂度之间的相关性如图3所示。

图3 训练误差和模型复杂度相关性示意图
可见,当模型复杂度达到一定程度时,随着模型复杂度的增加,虽然训练误差仍在继续降低,但实际的测试误差却不断上升。即在训练集进行测试的时候,性能表现很好,但当在测试集进行测试时,性能表现较差,这种现象被称为过拟合。导致过拟合现象的主要原因就是训练模型的复杂度较高,最直观的办法就是降低训练模型复杂度,但这也会导致拟合精度下降。
正则化为解决上述问题提供了思路,通过正则化可以制约训练模型最终的复杂度,降低过拟合现象出现的概率,从而提升了神经网络面对新事物的能力,使得神经网络能够更好地适应各种模型。正则化是通过引入矩阵范数来计算损失函数,由此来对模型的复杂程度做出惩罚。正则化一般是模型复杂的单调递增函数,如式(8)所示:

L1 范数正则化是指所有特征系数的绝对值求和,见式(9):
L2 范数正则化是指所有特征系数的平方和再求平方根,见式(10):
L1范数和L2范数都是通过求和来限制参数的大小,但所起到的效果却大不相同:L1 范数每次更新时会加上一个常数,往往会导致特征系数为0,这样该特征便不能影响训练结果,使得特征稀疏化,所以比较合适用来进行特征选择;而L2 范数会对特性系数进行比例缩放,只会使特征系数越来越小但不会为0,可以有效防止模型过拟合。
本文主要是对L2 范数正则化进行应用,L2 范数正则化可以起到简化模型的作用,能够将关键权值的影响控制在较小的范围内,从而在一定的程度上降低过拟合的风险。
3.2 ReLU激活函数
ReLU(Rectified Linear Unit),即修正线性单元。ReLU的原理是筛选出模型中的不必要特征并将其删除,用于降低计算量、解决梯度消失问题和缓解过拟合问题。为提高本文模型的计算效率,降低计算成本,通过ReLU 算法对模型进行进一步优化,提高模型的精准度。ReLU 激活函数的表现形式如图4所示。
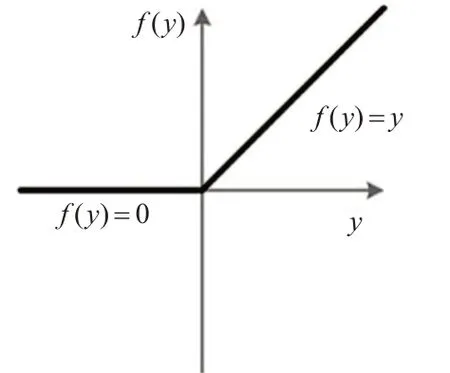
图4 ReLU激活函数示意图
ReLU激活函数的计算方法如式(11)所示:
可以看出ReLU 函数是一个分段线性函数,负数值为0,正数值为其本身。而这种单边抑制会使得神经网络中的神经元具有稀疏激活性,可以有效解决当神经网络模型增加N 层之后出现的过拟合问题。从函数图中可以看出,ReLU函数具有“转折点”,而ReLU的非线性恰恰就是通过这个“转折点”所表现的,由于ReLU的非负区间的梯度是常数,所以ReLU 不会出现梯度消失的问题,从而使整个模型的收敛处在一个稳定的状态。
4 系统设计与实现
4.1 系统框架
在系统设计开始考虑到系统的稳定性,因此系统整体架构采用的微服务开发,由于SpringBoot 具有很强的可扩展性以及能够实现自动装配,因此对于每个服务个体使用SpringBoot框架进行开发。而对于微服务间的注册以及调用熔断等需求,使用阿里巴巴旗下的SpringCloudAlibaba 进行开发,安全框架选用SpringSecurity,从而使服务间的调用更加稳定。数据缓存工具选用Redis 数据结构服务器,将事先页面需要的数据存在Redis 数据库中,等页面有需要就从Redis 查看有没有所需的数据,如果没有就查询MySQL 数据库,同时将查询出来的数据存入Redis 数据库中一份,这样一旦有下一次访问,就可以直接从Redis数据库中取出。由于Redis数据库是基于内存的,且内部机制是IO 多路复用机制,效率极高,响应速度也自然极高,这样可以在一定程度上改善用户的体验感。
4.2 系统核心模块展示
4.2.1 数据导入模块
EasyExcel 是JAVA 用于操作Excel 表格的工具库,可以对各个类型的Excel文件进行读写操作,通过继承AnalysisEventListener 监听器,去读取Excel文件每一行数据,并转换成SQL 语言,转存至MySQL数据库中。系统管理员仅需提前在Excel表格中进行问答数据集的编辑工作,之后将该Excel文件保存再本地,然后上传至系统即可实现批量数据导入的功能,提高了系统管理员的工作效率。Excel文件导入的界面如图5所示。
图5 Excel文件导入界面示意图
4.2.2 问答搜索模块
问答搜索模块的流程是:用户首先输入搜索内容,前端读取内容后,传至服务器,之后对读取到的内容进行分词,构建词向量然后借助神经网络进行语义匹配,最后将匹配的结果传输到前端,展示在用户面前。问答搜索模块的前端界面如图6所示。

图6 问答搜索界面示意图
5 结语
无论是纳税人还是税务工作者,在面对涉税问题时都需要掌握诸多繁杂的税收法律法规以及相关的政策。因此,研究和开发税务咨询智能问答系统具有重要的应用价值。本文通过对研究目前现有的智能问答关键技术,成功构建了基于词向量和卷积神经网络的税务问答系统。从算法实现的角度看,通过使用Jieba 分词和Word2Vec 词向量完成了语料预处理工作,并在卷积神经网络(CNN)的训练过程中加入了正则化和ReLU 算法等优化方法,提升了模型训练的效果。从系统实现的角度看,采用了目前流行的微服务框架,对系统各个模块分别设计,并最终完成了系统的整合。本系统成本较为低廉且便于维护,对税务机关来说减轻了工作压力,降低了咨询成本。对纳税人来说能够方便快捷地获取税务知识,提升了纳税人对税务咨询服务的满意度。
