反向残差结构的指纹细节点提取轻量型网络模型
2024-04-10侯雪峰苏毅婧
侯雪峰,苏毅婧,李 俊,徐 敏*
(1. 厦门理工学院电气工程与自动化学院,福建 厦门 361024;2. 中国科学院海西研究院泉州装备制造研究中心,福建 泉州 362000)
随着社会信息化水平的提高,人们需要更加可靠的识别技术对身份进行认证[1]。在生物识别系统中,自动指纹识别系统(automatic fingerprint identification system,AFIS)因其在速度、准确性、鲁棒性和成本之间具有相当好的平衡性而较为出众[2]。其中,通过细节点比对来寻求指纹的相似性是指纹识别中最普遍的方法[3]。在实际场景中,由于不稳定因素(如个人的手指缺陷、按压方式不当、背景环境复杂、提取设备误差等)较多,不可避免地会遇到低质量的指纹,影响提取算法性能和识别率。为了更好地识别指纹,有不少改进的提取算法相继被提出,这些方法可大致分为2类:一类是传统数字滤波算法[4-6];另一类是通过卷积网络直接从图像中提取语义特征[7-9]。
在过去的几十年里,传统方法在一定程度上解决了指纹特征提取的问题,该类算法需要图像的归一化、分割、增强、二值化和指纹脊线的骨架化等步骤[10]。针对质量差的指纹,需要用到复杂的增强滤波办法。如为了获得更加流畅的纹线,文献[4]尝试使用3 种方式对脊线的中断点、毛刺及端点进行处理,以消除它们对特征提取的影响;文献[5]将统计模式识别与结构模式识别相融合进行特征提取;文献[6]通过Gabor 相位提取细节特征,以克服褶皱和噪声的影响,但人工设计的特征很难适应复杂的背景差异。这些算法都需要对输入图像进行预处理后再设定相关模板参数,虽然实验结果可以达到预期,但是过程的复杂度增加了人力消耗。
近年来,卷积神经网络(convolutional neural networks,CNN)在计算机视觉任务中表现出了较好的效果[11]。如文献[7]提出了一种基于分块的细节点提取方法,将指纹图像分割为重叠的小块,训练一个名为Judge-Net的二元分类器来判断输入小块中是否存在细节点,再训练另一个名为Locate-Net的九类分类器来决定其细节点所属的区域,缺点是缺少每个细节点的方向信息;文献[8]将细节点提取的分类问题转化为目标检测问题,通过模拟Fast R-CNN 模块获得每个细节的位置和方向信息,增加了细节点方向信息,但其准确性仍有进一步的提升空间;文献[12]提出了一种端到端的分类网络FingerNet 来提取细节点,该网络首次使用多个CNN 来分别映射传统步骤中的分割、增强、方向场估计和特征提取等完整流程,缺点是该网络耗时较长,且没有抑制虚假细节点的产生。文献[9]提出基于分块输入的双阶段网络FineNet,一阶段网络是由MinutiaeNet 选择候选框,二阶段网络由CoarseNet对备选框进行判断,FineNet 遏制了虚假细节点的产生,也拥有较高的精准度,但其结果耗时高达1.2 s;文献[3]提出了基于生物医学网络U-Net改进的F-Net,有效减少了预测耗时,但未抑制虚假细节点的产生。
综上所述,一般的传统提取算法对指纹处理步骤比较复杂且依赖人工经验,而现有的基于CNN的方法则有输入分块化、多阶段网络不方便训练、参数量大、实时性较差的缺点。为解决这些问题,本文提出一种基于深度学习的轻量化端到端改进多尺度反向残差网络模型(inverted residual network for fingerprint minutiae extraction,IRFingerNet), 在NIST 4、FVC 2002、FVC 2004 数据库上的实验结果表明,该模型的实时性和综合性能均优于以前的同类网络模型。
1 IRFingerNet算法的整体框架
本文的指纹细节提取框架由浅层特征提取和细节点提取2部分组成。
1)浅层特征提取部分。它是一个基于改进FingerNet[12]的卷积神经网络。在本部分中,输入的图像经过不同网络深度的特征提取,得到方向图、分割图、增强图等特征图并进行特征融合,以便为第二部分提供更加充分的特征信息。
2)细节点提取部分。它是一种基于改进的轻量级反向残差结构[13]的网络。本部分对联合特征进行高阶信息提取,输出细节点详细的位置和方向信息。
本文提出的IRFingerNet网络模型构架图见图1。
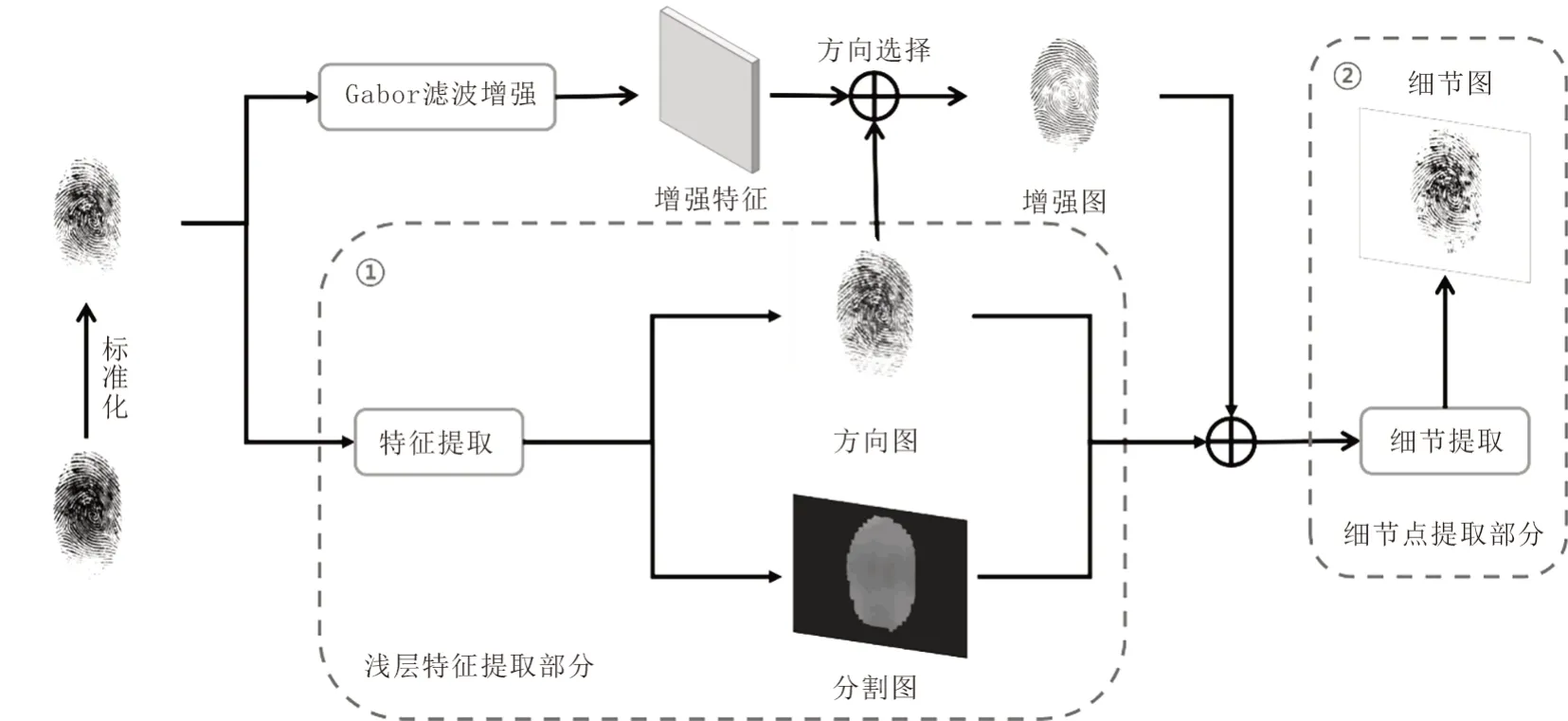
图1 IRFingerNet网络模型构架Fig.1 Framework of the IRFingerNet network model
1.1 浅层特征提取
指纹的特征提取不同于自然图像的处理,指纹图像可能包含大量的噪声,提取的每个细节点为方形区域且要求精度高。因此,本文在IRFingerNet中运用先验知识与CNN相结合的思想,将原始图像、增强图、方向图和分割图整合到CNN 中,以提高细节检测的精度。受Tang等[12]的启发,本文将人工传统算法映射到一个具有固定权值的网络中,详细结构见图2。
1.1.1 标准化
由于指纹图像采集的特殊性,同一个手指采集后其像素分布差异较大,需要使用标准化将像素映射到同一特定区间[14]。其定义为
式(1)中:I(x,y)为输入图像(x,y)处的强度值;m和v分别为图像均值和方差;m0和v0分别为标准化后期望的均值和方差。
1.1.2 分组滤波
将N个具有不同固定权值的卷积核代替Gabor 滤波器。标准化后的指纹图像通过与其进行卷积,可以得到一组滤波后的复杂图像,即增强特征,定义为
式(2)~式(3)中:C(x,y,i)表示第i次滤波图像中像素(x,y)处的强度值;I是标准化后的图像;gωi,θi是手工制作的指纹脊频率ω固定脊方向θ逐渐变化的卷积核;F(x,y,i)则是图像卷积后的增强特征包含通道上的全部参数。
1.1.3 方向选择
将生成一个掩模,以从增强特征中选择适当的增强块用于生成增强图,其定义为
式(4)中:M(x,y,i)表示在掩模中(x,y)处的第i个卷积处理后的像素值。当增强特征方向θ(x,y)与固定参数卷积核方向θi相对应时,掩膜设置为1。
1.1.4 方向图与分割图
标准化后图像送入神经网络,经过9 个3×3 卷积层、3 个池化层和6 个残差结构的运算后,得到256 个80×60 的特征模板,再经过不同空洞率的空洞卷积层后[15],完成多尺度信息提取,得到3 个80×60×90 的三维方向信息,对其进行数据叠加后输出1 个80×60×90 的三维方向图。分割图同理。方向图的输出直接预测每个输入像素的离散角的概率,即在(x,y)处的预测角度可以表示为N维向量,其定义为
式(5)中:第i个元素Pori(i)表示该位置的脊方向值为的概率,可以通过选择一个最大响应θmax(x,y)来得到最终的方向输出。
1.1.5 增强图
将方向图上采样8倍与增强特征进行方向信息筛选,得到1个640×480的二维增强图,其定义为
式(6)中:E(x,y)为增强图在坐标(x,y)的像素值。
1.1.6 反向残差结构
在网络中增加更多的层可能会导致梯度爆炸或消失的问题。本文提出的CNN 由一系列残差结构改造后串联而成,将部分标准卷积更改为深度卷积[16],在不降低精度的情况下减少参数的数量,额外添加一个映射层,以确保添加操作的两个部分的长度相同,调整残差结构中的维数顺序,以减少参数的数量;最后再添加一层线性结构,以便更好地提取低维空间的特征。每个卷积层之后是一个批归一化层[17]。改进的残差结构与标准差结构的对比如图3所示。

图3 改进的残差结构与标准差结构的对比Fig.3 Improved residual structure versus standard deviation structure
1.2 细节点提取
节1.1 部分使用先验知识获得的特征图只是该网络的一个副产品,但对于指纹细节点提取是非常重要的。本文将特征图与第二部分结合,获得细节点特征,然后将细节点特征与细节点得分图连接起来,添加通道注意机制,得到细节点的详细位置信息,具体见图4。最后,对这些信息进行整合,得到理想的细节点提取图。由于细节点可能聚集在某一区域周围,本文使用阈值12像素和点方向20°的非最大抑制[18]来剔除冗余的细节点。

图4 细节点提取部分网络详细结构Fig.4 Detailed architecture model of extracted part of minutiae
1.2.1 细节点特征
受文献[19]的启发,本文使用步长为2的卷积和Relu激活函数代替传统的最大池化层,使网络的特征提取性能略有提高。将联合特征发送给CNN,获取这部分的核心信息,即细节点特征。
1.2.2 细节点得分图
文中细节点特征经过4层标准卷积,得到细节点得分图。得分图为原输入图像尺寸的1/8,它代表了每个8×8基本单位有一个细节点的概率。每个像素点的值范围为[0,1],当概率大于设置的阈值δ=0.5时,被认为它是一个候选细节点。
1.2.3X/Y坐标得分图
本文将细节点特征与细节得分图进行通道拼接后送入3层标准卷积并添加注意力机制,并对每个细节进行了8个分散的位置预测,其定义为
式(7)~式(8)中:xtrue、ytrue为原始输入图像的坐标;x、y表示坐标得分图的坐标值;arg max(Xscore)、arg max(Yscore)表示坐标得分图通道最大值索引;(x,y)表示细节得分图中大于阈值δ的坐标。
1.2.4 通道注意机制
本文使用一种注意力机制来制作网络模型来校准特征[20],可促使通道上的有效特征显著化,减少无效特征的权重,将其放到网络中,以更好地利用联合特征的优势。通道注意力主要包含压缩和激励2部分:压缩操作就是一个全局平均池化,经过压缩操作后特征图被压缩为1×1×C向量;激励部分由2 个全连接层组成,其中SERatio 是一个缩放参数,设置这个参数的目的是为了减少通道个数从而降低计算量。第一个全连接层有C×SERatio 个神经元,输入为1×1×C,输出1×1×C×SERadio。第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
本文设计的通道注意力网络结构见图5。
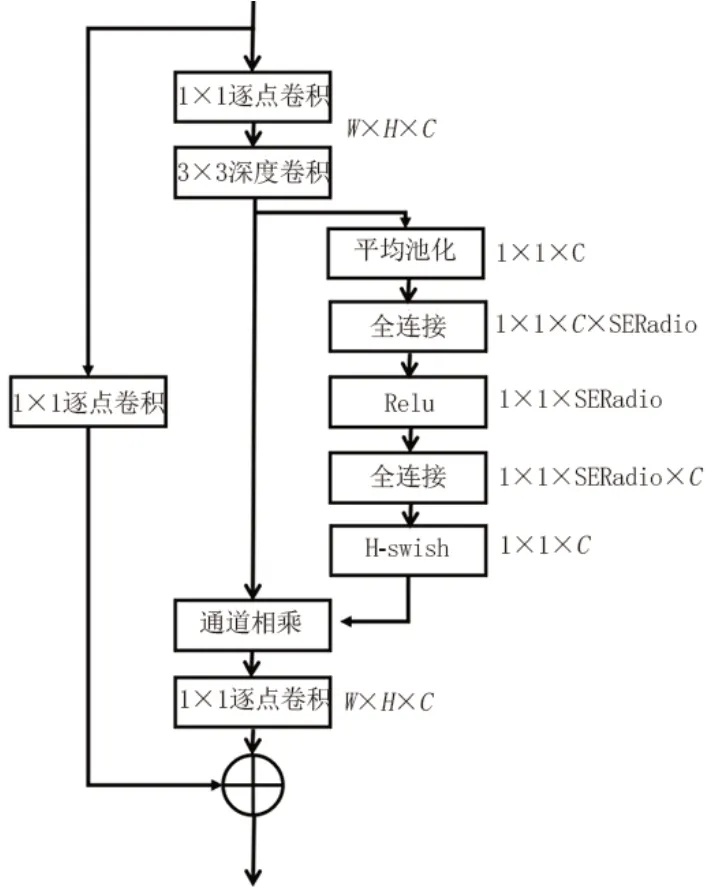
图5 通道注意力网络结构详图Fig.5 Structural details of the channel attention
1.2.5 方向得分图
方向信息是指纹细节点表述的另一个重要信息,一个细节点特征可由其位置坐标和方向来表示[21]。方向得分图的输出是一个大小为的张量,处理方法类似于坐标得分图。文中取通道最大索引作为当前方向块的方向,方向范围在[0,180]。
1.2.6 损失函数
指纹细节点提取属于对图像像素的分类,基于此,本文采用加权交叉熵作为该网络的损失函数,具体公式为
式(9)中:ROI 为感兴趣区域,在实际过程中定义为有值存在的前景区域;ε+和ε-分别为平衡正样本和负样本的权重,对于分割问题将其一般设置为0.5∶0.5,对于细节点则一般设置为10∶0.5;gi和si分别为标签图和预测地图中(x,y)处的概率值。
本文在加权交叉熵基础上使用了平滑损失函数[22],确保图像在分割过程中的梯度不会过大。平滑损失函数可表示为
式(10)~式(11)中:Mss是分割得分图;Klap是一个拉普拉斯边缘检测核;I是总图像的区域;Lssmi是平滑损失;Lseg是分割损失函数。
在方向预测过程中运用先验知识方向相干性,并将其转换为相干性损失,其公式为
式(12)~式(14)中:J3为大小3×3的全1矩阵;dˉ为平均脊方向向量;Coh为相干性参数;Lodpi为相干性损失;Lori为方向损失函数。
由于网络有6个特征图的输出,本文使用分步式训练方式,用一个列表来表示不同损失函数的权重,即网络的总损失是3个加权损失的叠加,具体计算公式为
式(15)中:α、β、γ为不同损失函数的权值,在分步式训练过程中会逐步进行赋值,初始值分别为1、0、0;Lsum是网络的总损失。
2 算法参数设置
2.1 数据集
本文在3 个公开的指纹数据集FVC 2002、FVC 2004 和NIST 4 上进行实验。FVC 系列数据集被广泛应用于指纹识别领域,包含的指纹样本较多且质量范围较广,可以更好地对指纹细节点提取算法进行客观评估。FVC 系列的每个数据库由100 个手指组成,每根手指有8 张图像,总共有800 个指纹图像用于训练、验证和测试。为了提高网络的泛化性并增加样本的数量,本文还使用NIST 4 数据集,由2 500个手指组成,共有5 000张图像。
本文对指纹图像细节点进行人工标记,并将其从手动标记的文本文件转换成四维张量,为网络中的每个输出特征图构造真实的标签。由于缺乏大量的真实标签,文中使用商业指纹提取器VerFinger[23]来获取剩余标签作为真实标签的参考。为了更加具有说服力,测试集标签由人工按照顺序进行标定,且对FVC 2004数据集不做任何训练,详细分配结果见表1。

表1 实验数据集详细分配表Table 1 Details of the experimental datasets assignment
2.2 训练
本文的训练过程在显存为16 GB的Linux服务器上运行,实验环境为Pytorch 1.4。分步式训练有4个步骤:1)通过训练分割和方向场来学习指纹的脊线特征,采用SGD 优化器,将学习率设置为0.5,Epoch 设置为200,batch size 设置为4;2)将联合特征发送到细节提取部分,锁定浅层特征提取部分的网络参数,解锁细节得分图的损失函数权重,让网络学习细节点可能出现的区域;3)保留训练后的参数,并在细节提取部分解锁剩余的权重,让网络学习细节点的详细位置(坐标与方向);4)解锁所有的损失权值,并将学习速率设置为0.01,对网络进行微小的调整,Epoch 设置为50。本文将得到的多个特征图集成一个实验结果图,具体见图6。细节点提取图中方框和箭头分别表示提取到细节点的坐标位置与方向,提取的正确细节点用绿色箭头表示,未提取到的细节点用红色箭头表示,提取的虚假细节点用蓝色箭头表示,数字序号为提取到细节点编号。

图6 IRFingerNet在不同数据集中的特征图展示Fig.6 Feature maps of IRFingerNet in different datasets
3 实验结果及分析
为了验证该方法的有效性,本文通过相关的消融实验验证其可行性,并与其他算法进行比较,以测试其泛化能力。
3.1 评价指标
采用F1分数[3]作为评价指标,其定义为
式(16)中:P是在被所有预测为正的样本中实际为正样本的概率;R是在实际为正的样本中被预测为正样本的概率。P和R有时是相互矛盾的,F1分数可以同时考虑虚假和缺失的细节点,作为它们之间的平衡点。为了避免过拟合,本文在验证中保存了F1得分最高的检查点,并将其用于测试。
文中设置元组(lp,op)和(lgt,ogt),并设置阈值D、O来确定预测的细节点是否正确,其公式为
式(17)中:(lp,op)和(lgt,ogt)分别为预测点和真实细节点之间的坐标和方向的差值;D和O分别为像素距离和方向角度的阈值。
3.2 消融实验
本文从3方面提高了网络模型的效率,即改进网络的主干、特征融合和注意力机制。为了验证其有效性,通过消融实验证明其可行性,所有实验均在阈值D=12 px、O=20°下进行。在NIST 4 数据集中不同方法对网络的影响结果见表2。
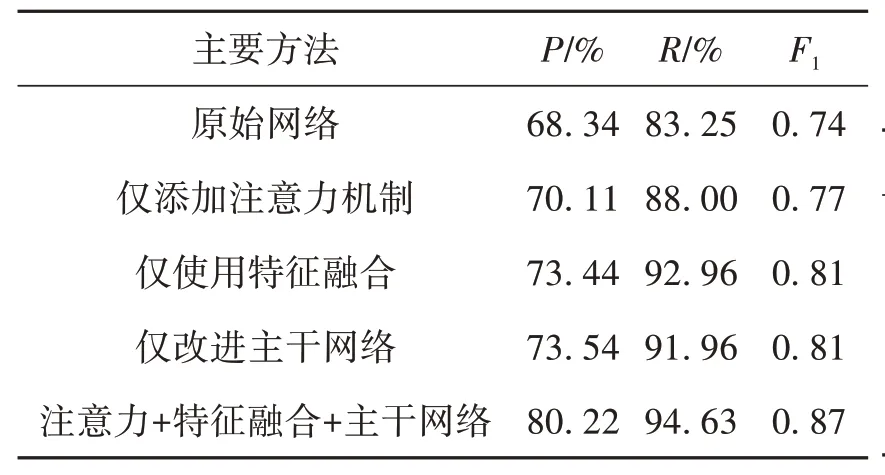
表2 在NIST 4数据集中不同方法对网络的影响Table 2 Effects of different methods on networks under the NIST 4 datasets
由表2 可见,当3 种方法单独对神经网络作用时,综合效果增加了近5%;3 种方法同时作用时,效果比原始网络提高了近12%。由于特征融合的本质属于不同特征图在通道上的拼接,而通道注意机制可以更加关注通道之间的关系,扩大有效参数的权重,改进的网络主干可以使信息提取更加完整。
网络的主干改进则需要根据不同指纹特征的具体要求进行测试,具体的浅层特征提取部分和不同主干网络对准确率的影响结果如表3所示。网络层的适当加深对方向场和分割图的准确性有积极的影响。但随着网络层数的不断加深,在相同训练条件下网络收敛较难,实验效果较差。

表3 在NIST 4数据集中浅层特征提取部分和不同主干网络对准确率的影响Table 3 Effects of shallow feature extraction part and different backbone network on accuracy under the NIST 4 datasets 单位:%
本文将不同网络结构对指纹图像的影响进行可视化,以更清楚地了解不同网络层数对方向场的影响,结果见图7。图7 中,红色为未检测到的方向场信息区,蓝色为预测的虚假错误信息区,绿色为正确的方向场信息。由图7(a)可以看出,图像经过原始网络后,遗漏了部分边缘信息。图7(b)表示图像经过加深3层的网络后,可以看出,边缘信息遗失得到了改善。图7(c)显示,图像经过过度加深12 层网络,虽然解决了信息遗失的问题,但难以收敛,造成了大面积虚假信息并增加了训练和测试时长。
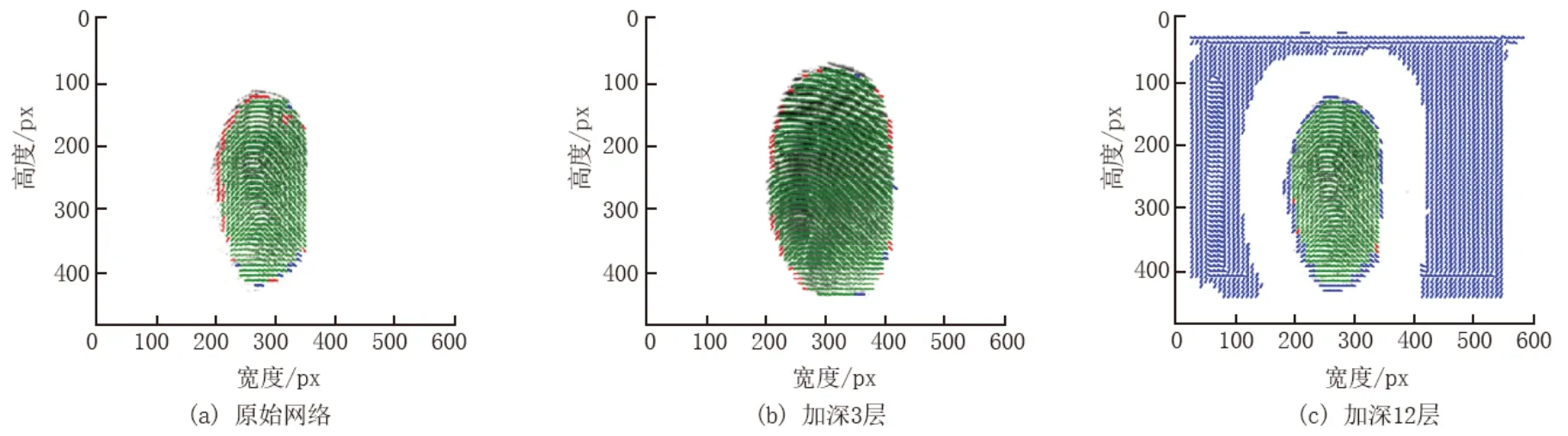
图7 在同等训练条件下不同深度网络对特征图影响Fig.7 Influence of different depth networks on feature maps under the same training conditions
细节点特征提取部分和不同主干网络对准确率的影响见表4。由表4可见,对于细节点提取部分,不同的主干网络对细节点信息提取也有不同影响,深层结构的网络对训练数据集要求会更加严格,训练时间更长,网络收敛难度增大,在测试中对应的耗时也会增加。
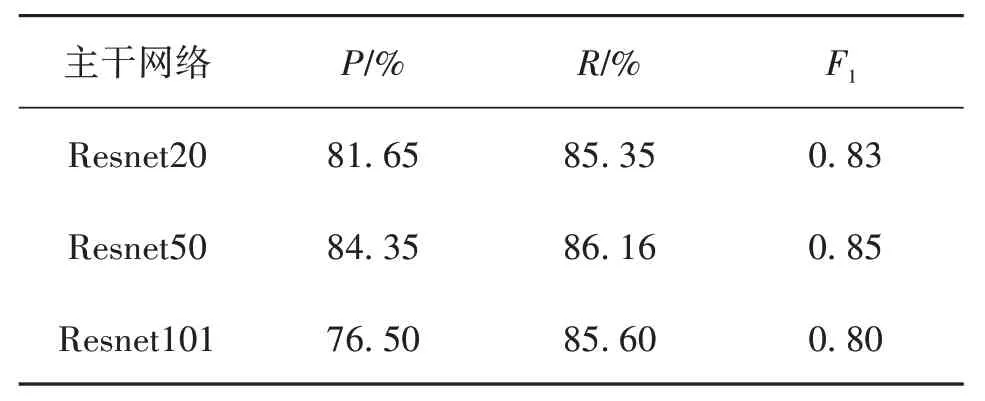
表4 在NIST 4数据集中细节点特征提取部分和不同主干网络对准确率的影响Table 4 Effects of minutiae extraction part and different backbone network on accuracy under the NIST 4 datasets
图8给出了改进的IRFingerNet和原始网络之间的效果比较。由图8可见,利用原始网络进行细节提取仍然存在遗漏和错误提取,而改进的IRFingerNet则显著减少了信息遗漏,提高了检测的准确性。
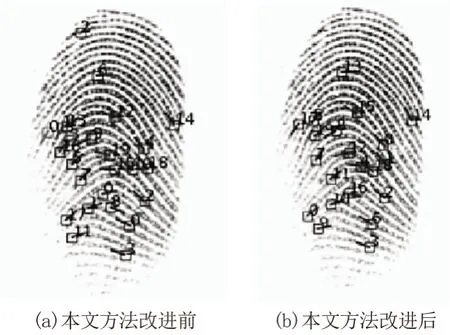
图8 改进前后实验效果对比Fig.8 Comparison of experimental results
3.3 与其他算法的比较
提取器的另一个性能是鲁棒性,即从具有不同像素分布规则的数据集中提取细节,以确定网络的稳定性。这种性能对于存在不稳定因素的实际环境中的细节点提取尤为重要。本文测试了不同提取算法在不同数据集中的提取性能,结果见表5~表6。
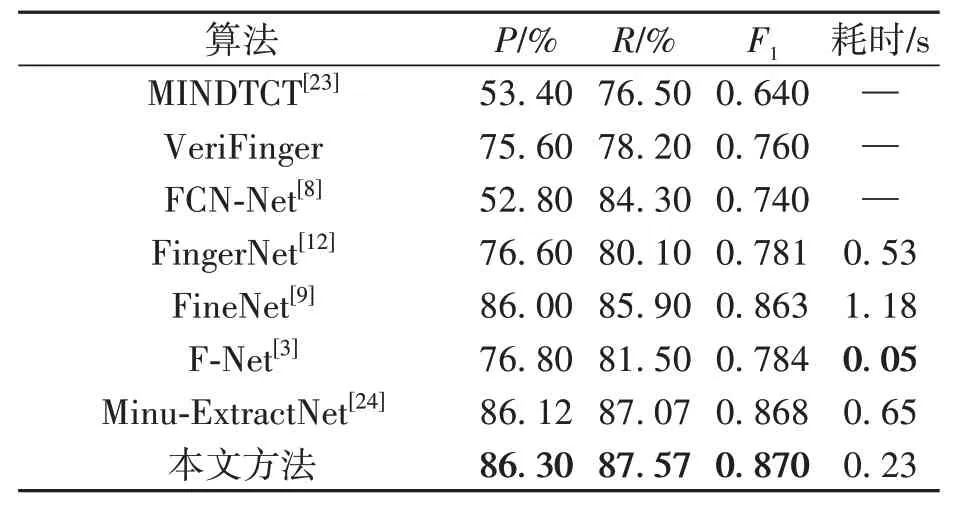
表5 IRFingerNet算法与现有算法在FVC 2002上的对比Table 5 Methods for minutiae extraction on FVC 2002 compared

表6 IRFingerNet算法与现有算法在FVC 2004上的对比Table 6 Methods for minutiae extraction on FVC 2004 compared
由表5~表6 可见,IRFingerNet 的评价指标在不同分布规则的数据集中均保持了最优效果。IRFingerNet 的精确率、召回率和F1分数的性能结果均远好于MINDTCT、VeriFinger、FCNN-Net、FingerNet和F-Net,略好于FineNet和Minu-ExtractNet。其中,为了遏制虚假细节点,FineNet使用双阶段网络再次判断该点是否为细节点,一阶段网络用于确定候选框,二阶段网络用于筛选候选框。尽管其效果较好,但参数量大且不是一个端到端的网络,耗时预测在非GPU 环境下运行困难,不利于实际应用。F-Net 通过U 型轻量型网络来预测细节点信息,没有设置专门的去除伪细节点功能,极大地缩短了预测时间,预测了更多可能的点来提高回调率,从而提升F1得分,但存在虚假点导致精确率下降。然而,虚假信息过多在大型数据库中参与匹配是致命的缺点,会导致匹配环节的正确度下降。Minu-ExtractNet 是FineNet 的改进版本减少了网络参数,开发了动态阈值化算法,减少了部分耗时并增加了召回率,从而提升F1得分。本文提出的方法相对于前者更加简单有效,通过特征融合与注意力机制相结合的方式极大减少了虚假点产生。此外,本文网络还具有参数量小的特点,且耗时仅为0.26 s,更易于实际应用。
4 结论
针对细节点信息提取错误和提取不充分的问题,本文提出了一种基于反向残差结构的轻量型网络模型。该网络模型使用深度学习框架将传统算法的步骤映射到卷积神经网络中,简化预处理环节,减少人力资源消耗;结合指纹的先验知识,把指纹的脊线、细节点等多种特征进行多尺度提取,融合为联合特征,增强语义信息,提高对细节点的感知能力和可靠性;将通道注意力机制引入联合特征中,可对联合特征进行校正,增大有效特征权重,并减少无效特征权重;结合深度学习领域,使用改进后的反向残差网络框架和深度卷积防止网络退化,改进激活函数并建立容易优化的轻量级网络,在增加网络深度时减少信息丢失。在NIST 4、FVC 2002、FVC 2004 3种不同数据集的测试结果显示,该网络模型具有86.30%的精确率、87.57%的召回率,整体的F1得分高达0.87,其提取效果相较于传统提取方法得到了11%的提升。该网络模型与同类算法相比,在保证有较高精度的同时具有更少的参数量,且端到端的设计减轻了网络模型训练难度,减少网络模型维护成本,降低运行耗时,达到了每个指纹图像0.23 s 的检测速度,相较于已发表的细节点提取算法,其综合能力更好、更易于实际应用。未来,将对IRFingerNet 算法在内存和处理时间上进行优化,使其能够满足在一个实时需求的嵌入式平台中实现,并将其扩展到指纹匹配中,完成端到端的指纹提取、匹配框架。
