考虑设备劣化的加工工时预测方法
2024-04-10裴凤雀张佳煊刘检华庄存波
裴凤雀,张佳煊,刘检华,庄存波
(1.河海大学 机电工程学院,江苏 常州 213022;2.北京理工大学 机械与车辆学院,北京 100081)
1 研究意义与背景
设备劣化是指设备在使用过程中,由于零部件磨损、疲劳造成的变形、老化,使原有性能逐渐降低的现象[1]。设备劣化对生产过程可造成直接和间接影响,具体为:
(1)设备劣化可直接导致加工工时波动[2]。如图1所示,在设备寿命初期,往往因其具有较高的可靠性而具备了在额定工时状态(t1)下的生产能力;随着设备劣化逐步加深(轻度劣化阶段),加工工时产生了不可忽视的延长(t2);在寿命末期(深度劣化阶段),实际加工工时与理论加工工时产生了明显差异(t3)。

图1 设备劣化过程与加工工时对应关系
(2)设备劣化可间接导致生产决策失效。从工艺序列角度分析,设备劣化导致累计加工工时偏差,生产计划执行率被严重影响,间接导致生产决策失效。如图2所示为生产计划和执行过程的示意甘特图,对比发现,随着设备劣化的产生,部分工件加工工时增加,会导致最终完工时间增加,甚至会产生加工顺序变化。这些变化会对生产流程和资源分配产生负面效应,从而影响生产计划的执行,对车间决策造成一定的困扰。
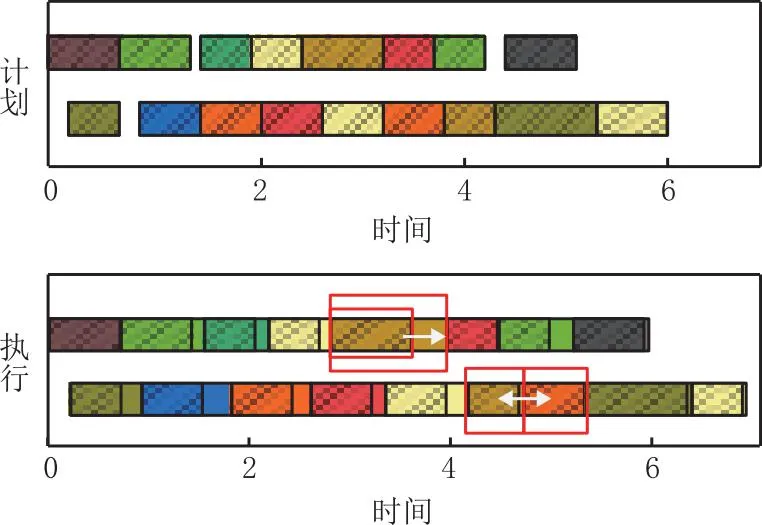
图2 生产计划与执行过程对比
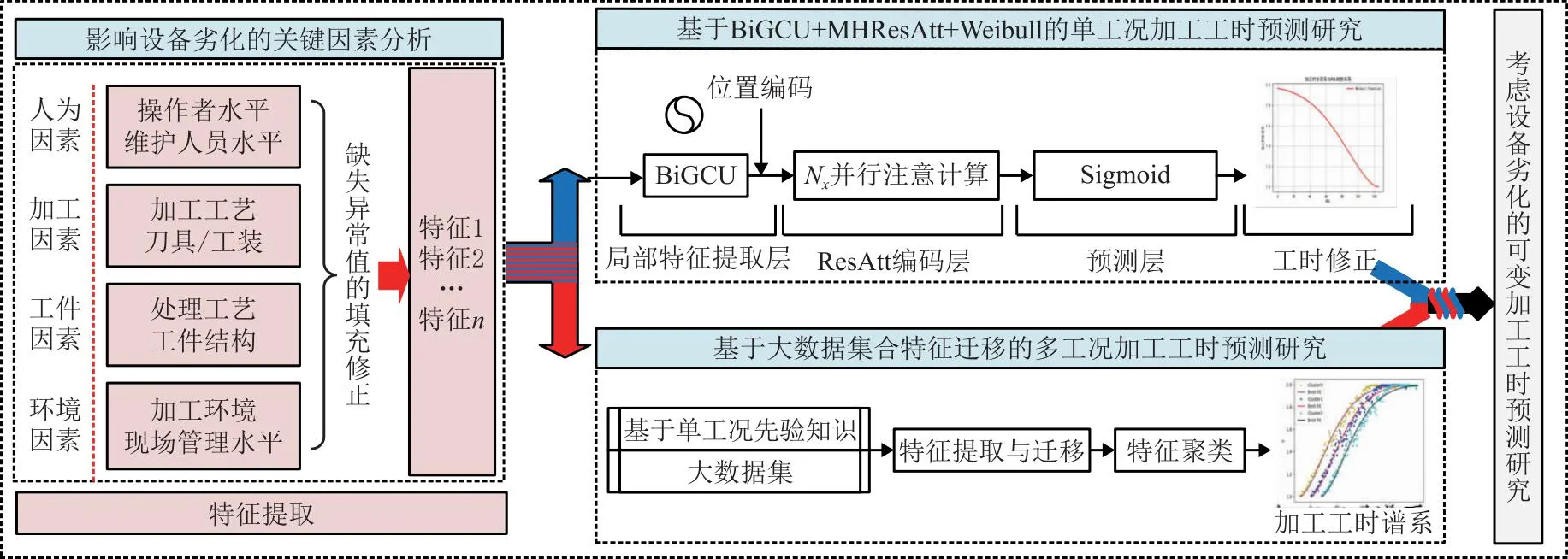
图3 加工工时预测方法技术路线
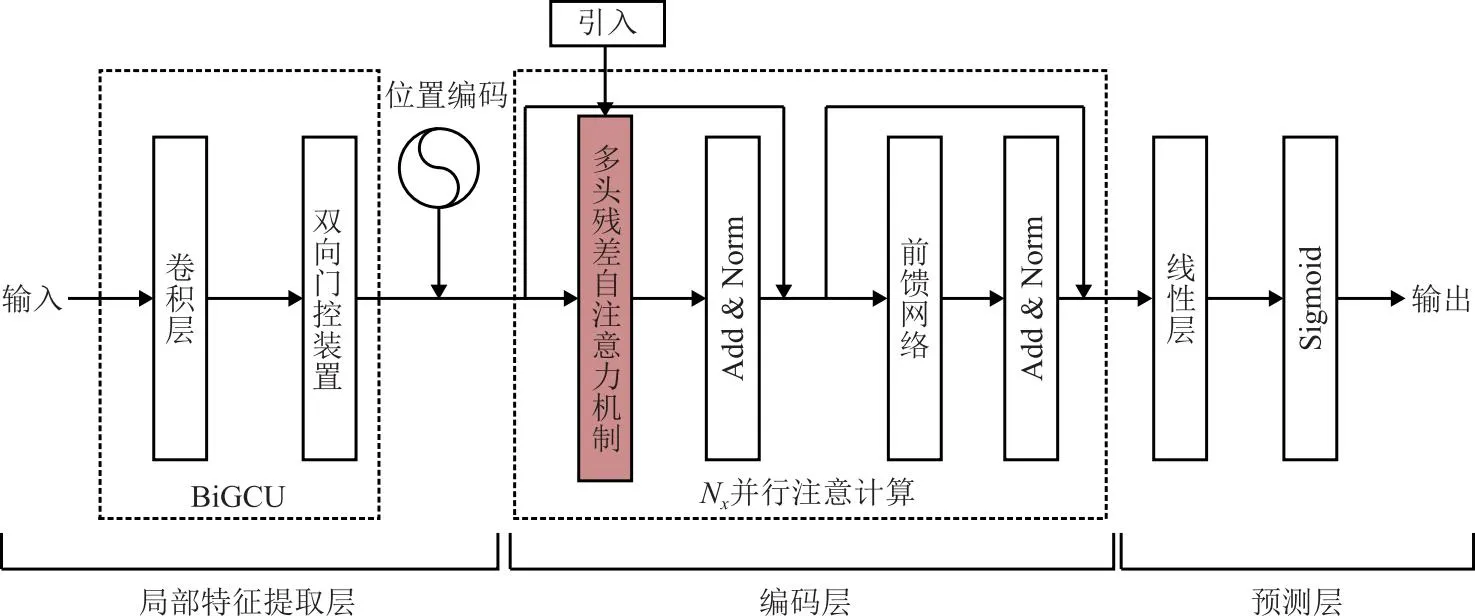
图4 BiGCU-MHResAtt-Weibull预测方法流程图
然而,在真实管控中,设备只有“可用”和“不可用”两种状态,针对设备劣化造成的生产延误,决策者往往采用容忍态度,认定其为可接受的生产偏差。只有当设备深度劣化,将对生产过程产生重大影响时,方引入预测性运维,以恢复设备到可操作状态。这种粗狂的管控方式,将会给车间决策造成明显障碍[3],尤其是在依赖加工工时的生产决策中(如生产调度等),准确的加工工时额定对生产决策及后续决策(如生产计划的执行率)将产生较大影响。因此,近年来针对设备劣化对加工工时的影响研究,逐步成为热点,其主要研究方法可分为:
(1)基于惩罚系数的劣化过程表征
现有研究中,基于惩罚系数的劣化过程表征是最常见的方法之一,如以阶梯函数或递增指数函数等形式表示惩罚。CHENG等[4]在研究单机调度的批量处理作业问题中,提出实际处理时间需在批处理操作时间的基础上,增加递增指数函数,以表示设备劣化过程。WOO等[5]提出作业的实际加工工时会根据其开始时间和劣化而发生变化,以此提出线性劣化率乘以开始时间的指标作为惩罚系数,修正实际加工工时。轩华等[6]将工件的开始加工时间和加工工时用递增函数的形式进行表示,根据工件在不同机器上的惩罚系数建立对应的数学模型。针对工件的加工工时和交货期模糊的单机成批调度问题,王雷雷等[7]根据工件的模糊加工工时和模糊交货期的关系建立数学模型,并提出了相应的优化算法。但总结发现,现有文献只是简单地增加固定的惩罚时长[8]或线性递增函数[9],并未考虑与当前设备状态的耦合关系,缺少劣化过程的时变特性分析。
(2)基于RUL的劣化过程预测
另一种研究思路是将加工工时预测转换为RUL预测,构建加工工时和RUL的对应曲线,以修正加工工时。基本的RUL预测方法主要分为两类:基于物理模型和基于数据驱动。传统基于物理模型的方法严重依赖基于系统设备失效原理的先验知识,难以应对复杂装备[10]。数据驱动方法,如卷积神经网络(Convolutional Neural Network,CNN)[11-12]、循环神经网络[13](Recurrent Neural Network,RNN)等,凭借更深层的网络结构,更强大的特征提取能力,能更好地应对复杂装备的RUL预测。徐浩等[14]利用双向门控循环单元网络(Bidirectional Gate Recurrent Unit,BiGRU)可高效处理时间序列数据的能力,克服了传统变分自编码器难以提取时序特征的限制,并在经典数据集上进行测试,证明了该预测方法的优越性。刘丽等[15]同时结合CNN和RNN,并引入注意力机制将每层,时域卷积网络(Temporal Convolutional Neural,TCN)残差块的关键退化特征进行提取,提高多工况下预测的精度。但RNN和CNN方法存在局限性,RNN的顺序计算限制了并行性,增加了时间成本;CNN只可感知局部信息,难以捕捉远程依赖和长序列信息。为此,提出基于自我注意力(Self-Attention)的Transformer网络[16]用于序列建模,该方法可有效且并行地获取随时间推移的单层长期依赖关系,且可适应不同的输入序列长度[17]。MO等[18]结合CNN和RNN的优势,提出门控卷积单元(Gate Convolutional Unit,GCU),以强调相邻时间步长的局部信息,克服自注意力的缺陷。
基于上述研究,本文结合CNN双向传播网络结构的BiGRU和多头残差自我注意力机制,提出基于BiGCU-MHResAtt-Weibull的加工工时预测方法。此外,考虑实际生产环境中的多样性和复杂性,针对单工况和多工况分别进行研究,以提升模型的泛化能力。
2 设备劣化的影响因素分析
加工工时是制造执行系统中的重要参数,在产能核算、负荷计算、生产调度等方面起着重要的作用。加工工时影响因素主要是从人为因素、加工因素、工件因素和环境因素4个角度考虑,具体如表 1所示。

表1 加工工时影响因素
人为因素方面,操作者的技能水平和匹配程度、维护人员的水平以及人为失误均对工时有影响。加工因素包括加工工艺、刀具选择和工装方式等,可直接影响作业完成的效率和准确度。工件因素方面,处理工艺、工件结构以及工件的质量和精度要求会对加工工时产生影响,如质量、精度要求越高,加工工时越长。此外,环境因素如加工环境的温度、湿度、振动、噪音和化学物质也会影响工时定额;合理的现场管理可以提高生产效率、降低成本,确保工时定额的准确性。其中,设备劣化影响的主要因素是加工因素中的刀具因素,劣化程度越深,越加剧刀具的磨损,需要增加进刀次数以达到工件因素中的加工精度等要求。其他因素则是间接通过加剧设备劣化从而影响加工工时,如环境因素。因此,研究以该因素为设备劣化的影响因素与决策变量,作为算法模型的输入,进行加工工时预测研究。
3 算法模型的建立
考虑工业现场作业能力的复杂性,本文将加工过程分为单工况和多工况。单工况是指单台套设备仅有一种加工能力或以某一种加工能力为主,如流水作业车间设备;多工况是指单台套设备需具备多种不同类型零件加工能力,如柔性作业车间设备。单工况是多工况的特例,仅涉及系统在特定条件下的性能,多工况是单工况的扩展和泛化,关注的是机床在更广泛的操作条件下的性能表现。针对单工况,构建基于BiGCU、MHResAtt和Weibull的预测方法,其中,BiGCU用以实现局部特征提取,创新的将多头残差自注意力机制(Multi-Head Residual Self-Attention,MHResAtt)引入并完成特征编码,实现模型在不同的子空间(多头)并行学习不同的关系,完成RUL预测后利用Weibull分布进行工时修正,实现基于设备劣化的关键特征到单工况加工工时预测研究。针对多工况,结合单工况先验知识,构建不同工况的劣化过程大数据集,通过特征提取和迁移匹配,实现基于加工工时谱系的聚类预测,整体技术路线如图 3所示。
4 基于BiGCU-MHResAtt-Wellbull的单工况工时预测方法
构建基于BiGCU-MHResAtt-Wellbull的预测方法流程,如图 4所示,方法流程分为局部特征提取层、编码层和预测层三大部分。
4.1 基于BIGCU的局部特征提取
局部特征提取以输入的时序数据为对象,首先设定时间窗,提取局部特征;其次,利用CNN卷积网络提取每个时间步向上/向下提供的相邻时间步之间的历史特征、预测特征信息,并通过门控机制,实现其与局部特征融合,最终输出带有相邻时间关系的局部特征。
(1)门控机制 门控机制在GRU[25]中用以解决传统RNN的梯度消失和梯度爆炸问题。其计算流程如图5所示,计算公式如式(1)~式(4)所示。
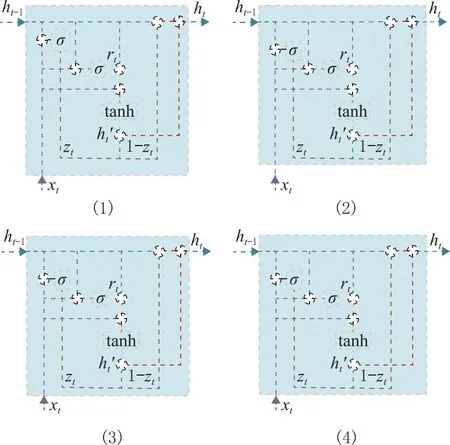
图5 门控机制运行原理

图6 双向门控结构
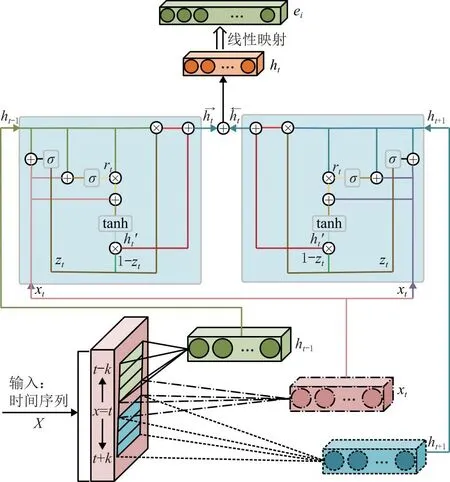
图7 BiGCU模型
zt=σ(Uz·ht-1+Wz·xt),
(1)
rt=σ(Ur·ht-1+Wr·xt),
(2)
(3)
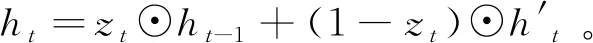
(4)
其中:Wz、Uz、Wr、Ur、W、U∈Rm×m为可训练的参数;σ(·)表示sigmoid函数,通过该函数可将数据压缩到0~1范围;⊙为Hadamard(按元素)乘积;tanh(·)为非线性激活函数。
由于单向循环神经网络无法获取时间序列数据中后向序列的相关信息,本文采用双向门控机制 (BiGRU),在保持门控机制单向高效的时序信息处理能力的前提下,构建两个方向相反的门控GRU结构,在初始和末尾用padding[0]进行填充,如图 6所示。为此,需要新增式(5)以计算最终输出。
(5)
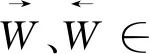
(2)BiGCU机制 由于GRU时间复杂度为O(N),而CNN时间复杂度为O(logk(N))[16],由卷积网络代替GRU中的隐藏循环层,可以加快模型运行速度。整个局部特征提取具体计算方式如图 7所示,将xt前/后k项经过卷积操作得到一维的向量,对于给定的x在每个时间步长t提取窗口k内的局部信息ht,如式(6)所示。卷积后包含了前向/后向历史信息,再将其视作ht-1/ht+1加入到门控机制中,输出局部特征ht,然后将ht线性映射到位置编码器需要的维度ei,作为位置编码的输入。
(6)
(3)位置编码 位置编码旨在为模型引入图像中的位置信息。其在处理序列数据的深度学习模型中起到关键作用。位置编码通过将位置信息嵌入到输入数据中,帮助模型更好地理解数据中的顺序和距离关系,其计算过程如式(7)所示。其中,d是ei的维度。位置编码的可视化如图8所示,展现了其编码的变化和周期性特征。通过位置编码,将pt与任意l值的pt+l线性关联起来,使得模型能较好地具备通过相对位置推断相对关系的学习能力。
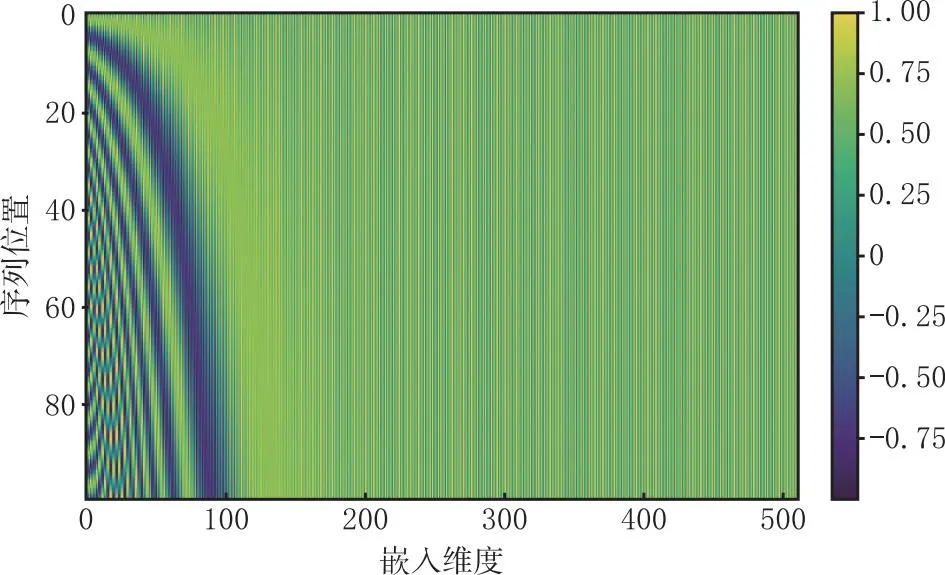
图8 位置编码

(7)
4.2 基于多头残差自注意力机制的并行编码
(1)多头残差自注意力机制[26]用于处理序列数据的特征交互,该机制允许模型在不同的子空间(多头)上并行学习不同的关系,融合特征以获取更丰富的信息。在传统自注意力机制的基础上,本研究考虑梯度爆炸以及计算复杂度等方面的约束, 创新地引入多头残差自注意力机制,该机制主要包括以下3个部分:
①自注意力机制:自注意力机制允许模型为输入序列中的每个元素分配权重,以获取元素之间的关系。在自注意力中,每个元素都可以与序列中的所有其他元素相互交互。
②多头机制:为了增强模型的表示能力,多头机制引入了多个自注意力头,每个头可以学习不同的关系。每个头拥有独立的权重矩阵,用于计算注意力分布,从而降低计算复杂度。最后,每个头的输出被组合以获得最终输出。
③残差连接:多头自注意力机制通常与残差连接结合使用。这意味着输入数据与多头自注意力机制的输出相加,以便更好地传递信息和减轻训练中的梯度消失问题。
多头残差自注意力机制如图9所示,经过QKV矩阵变换后(式(8)),将计算得到的bheadi(式(9))进行拼接(式(10)),然后通过线性转换得到Output。
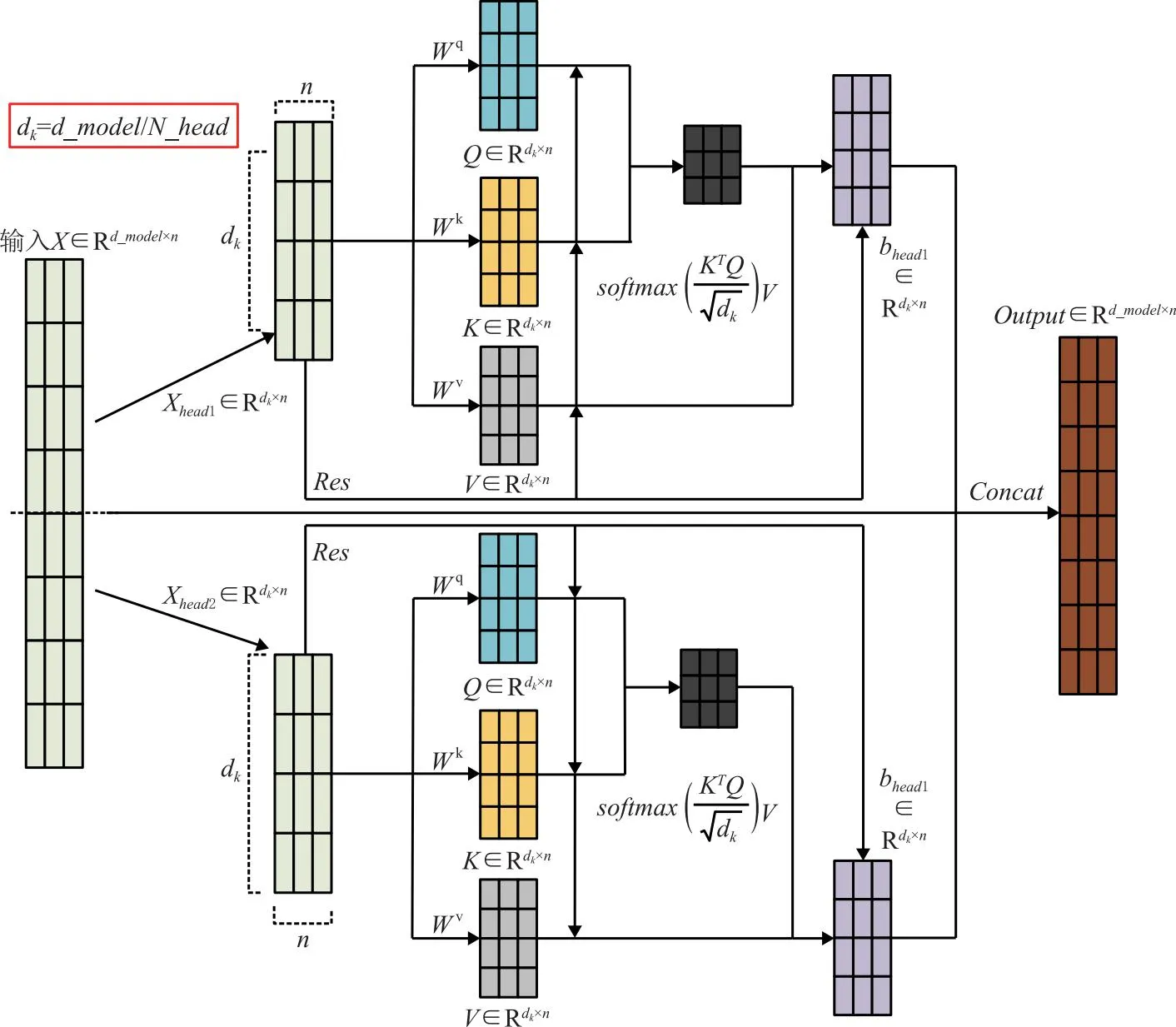
图9 多头残差自注意力机制(N_head=2)
(8)
(9)
Output=Concat(bhead1,bhead2,...,bheadn)。
(10)
其中dk=d_model/N_head,Output∈Rd_model×n,x、Q、K、V、bheadi∈Rdk×n。
(2)前馈网络,首先将数据通过线性变换进行传递,并通过ReLU函数实现激活,同时引入非线性,最后将结果通过另一个线性变换进行传递,具体计算过程如式(11):
FFN(x)=W2·ReLU(W1x+b1)+b2。
(11)
4.3 设备残余使用寿命预测
最后使用一层全连接层将Output输出为量化结果,用以表征设备的残余使用寿命,如式(12):
ypre=σ(woO+bo)。
(12)
其中,wo∈dmodel×1是可训练的参数;bo是一个标量。
4.4 基于RUL预测的加工工时修正
由于不同工艺的加工工时存在不同的标准加工工时,需要提前进行加工工时无量纲化,提升不同工艺加工工时的可比较性,因此提出了加工工时倍率的概念:修正后的加工工时=标准加工工时×加工工时倍率。
阶段加工工时的分界点参考的是单倍标准加工工时和双倍标准加工工时,因此,本文将加工工时曲线的起点(RUL为Max时),设置成标准理论加工工时,加工工时曲线的终点(RUL为0时),设置成双倍标准理论加工工时,中间数据采用概率密度函数拟合,最终形成基于RUL预测的加工工时修正曲线。
5 基于大数据集和特征迁移的多工况加工工时预测
在实际工程应用中,复杂装备所处的环境条件可能发生实时变化,且其本身的操作条件也可能发生变化,即处于多工况运行状态。受到环境条件、操作条件等不确定性因素的影响,运行过程中可能会出现多种失效模式,其失效机理和失效时间也会呈现出一定随机性,为了更好地服务工业生产,抑制生产计划和实际执行之间的偏差,变工况及多种失效模式下的加工工时预测需深入研究。
本文针对多工况提出了基于大数据集和特征迁移模型。单工况采用数据+模型双驱动的方式进行构建,当单工况数据积攒到一定体量,可形成多工况数据集。同理也可在多种工况中匹配到不同设备在单一工况下的数据。首先,依托单工况的先验知识,收集多工况下某台或者同类型设备的所有运行状态(包括设备本身属性如振动信号、电流信号、进出口温度等)、操作状态(包括工艺类型、参数设定等)和对应的加工工时,形成寿命劣化大数据集。类似于单工况,不同工艺的加工工时存在不同的标准加工工时,需提前进行加工工时无量纲化,即多工况下的加工工时倍率。其次,将运行状态构建为特征集,并按操作状态进行聚类,然后按照不同类回归出一条与特征集和加工工时相关联的曲线,并最终形成加工工时谱系,如图 10所示(本文以3个工况为例)。如果有新的工件(如图10中的黑点),首先进行预设的操作状态聚类分析,以确定其类别,其次,通过特征集进行迁移匹配,找到在大数据集中具有相似或接近特征的历史数据点(如图10中的四个红点),最终,通过均值计算或拟合计算以确定新工件的加工工时。

图10 多工况下的加工工时谱系
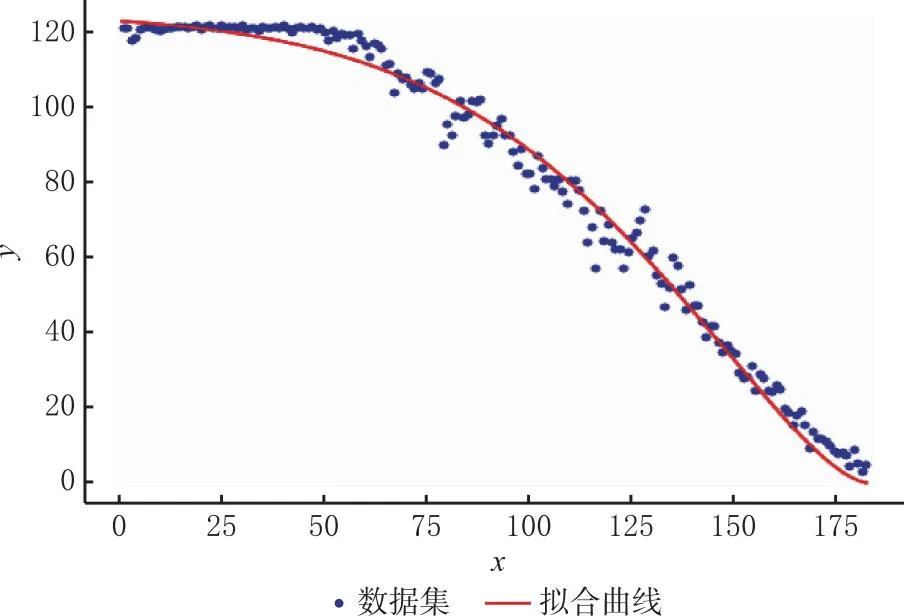
图11 Weibull函数拟合
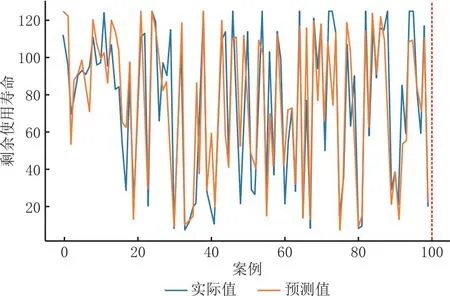
图12 FD001RUL预测
6 实例验证分析
由于加工工时与RUL存在映射关系,因此将加工工时预测转换成RUL预测,采用经典的RUL预测数据集-C-MPASS[27]展开测试验证研究。
6.1 数据预处理
采用C-MAPSS中的FD001数据集,每台发动机包含3个工作状况监测参数(飞行高度、马赫数与推力杆角度)和21个性能监测参数(如风扇进口温度、低压涡轮出口温度等),测试集提供了相应的RUL标签。
(1)退化数据筛选:为了降低计算复杂性,本文使用单调性矩阵和相关矩阵[28]进行退化数据筛选,如公式(13)~式(15)。单调性矩阵表示特征在时间维度上的变化趋势,带有单调性的特征维度包含更丰富的退化信息。相关矩阵反映了特征维度与操作时间之间的关系,具体如下计算[18]:
(13)
(14)
Crii=α·Corri+(1-α)·Monoi-γ。
(15)
其中:α∈ [0, 1]为一个权衡因子,γ为传感器选择的阈值。
(2)数据归一化,考虑到不同传感器测量会导致不同的数值范围,本文应用了最小-最大归一化方法以提高模型的收敛速度和预测准确性。
6.2 模型性能评价标准
为了评价多工况模型预测RUL 的性能和可靠度,评估标准采用均方根误差(RMSE)和评分函数(Score)。二者的定义分别如式(16)和式(17)所示
(16)
(17)
6.3 RUL目标函数及其优化
在C-MAPSS训练集中,真实的RUL标签不可用,需要采用一种模拟RUL目标函数[29]的方法指导模型训练[30]:通过模拟RUL标签,提供监督训练信号,辅助模型RUL估计,从而增强模型的预测能力。经过多次训练后发现,对RUL退化标签进行分布概率优化有助于提高模型精度,结果如表 2所示。
由表2可知,采用Weibull分布函数进行RUL标签优化的MSE最优,如式(18),并寻找最优的参数λ和k。

表2 多次曲线拟合结果

表3 超参数设定
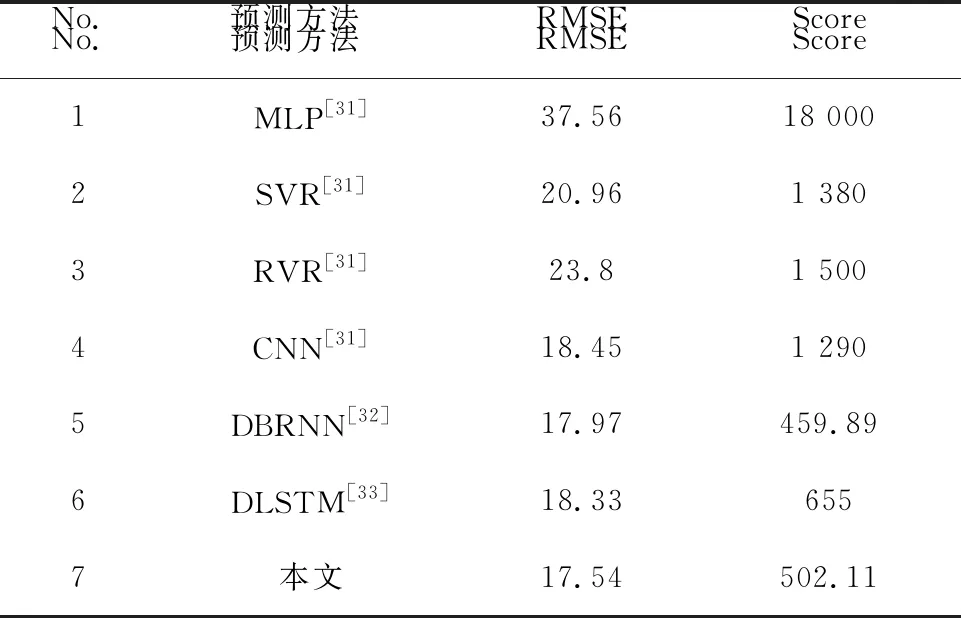
表4 不同预测方法结果对比
(18)
随机选取FD001的某设备,将训练收敛的RUL预测值作为输入,并将RUL归一化,采用Weibull函数拟合得到曲线如图 11。优化后的参数分别为0.014 016,1.495 235。经对比,RMSE降低约3.28%,Score降低约18.18%,从而提高了模型精度。
6.4 RUL预测分析
超参数设置如表 3所示,并进行了300次循环迭代。
针对FD001数据集的预测结果如图 12所示,训练集损失Train_loss如图13a所示,RMSE指标如图13b所示,Score指标如图13c所示。本研究将FD001训练集中最优训练损失train_loss的机器unit63及其RUL预测作为数据源,机器整个周期的RUL预测随运行循环次数变化如图13d所示。结果显示,本文模型的最优RMSE为17.54,Score为502.11,单次epoch循环用时20.5940s,表明预测方法能够较好地预测设备劣化程度。与其他方法相比,如表 4所示,本文提出的模型在RMSE和Score两项指标上,均具有一定优势。
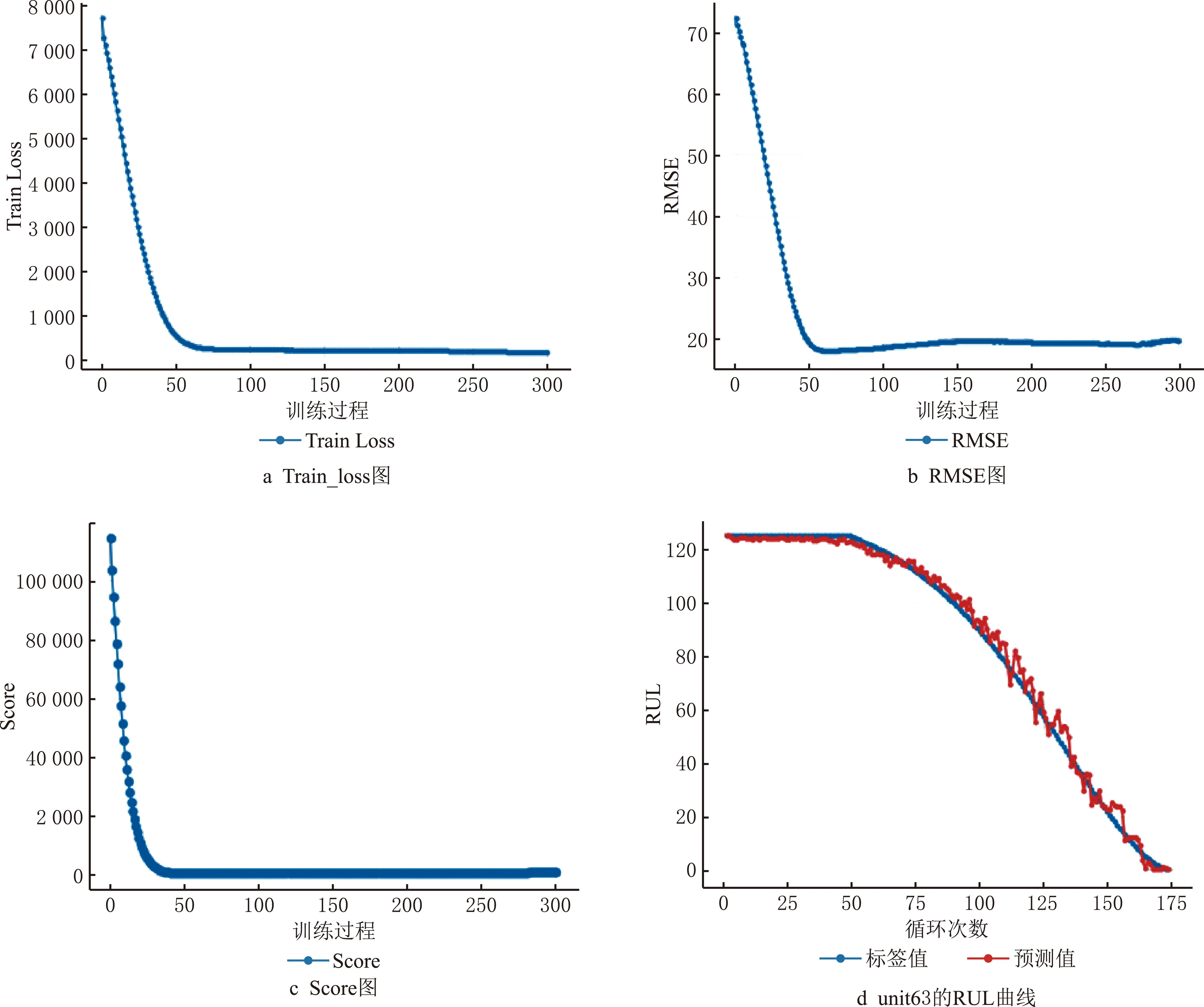
图13 结果图

图14 RUL拟合
6.5 RUL与机加工工时关联分析
RUL分布符合Weibull分布,本研究对FD001训练集中train_loss最优的机器unit63及其RUL预测数据进行了拟合。拟合结果如图 14所示,参数设定为λ= 0.016 3,k= 1.705 8。
阶段加工工时的分界点参考了单倍标准理论加工工时和双倍标准理论加工工时。因此,本研究将加工工时曲线的起点设置为标准理论加工工时,而当RUL为0时,加工工时为双倍标准理论加工工时。概率分布采用Weibull分布。再将加工工时进行无量纲化处理后(即加工工时倍率=加工工时/标准加工工时),得到加工工时倍率与RUL的曲线,如图15所示。

图15 加工工时倍率与RUL映射关系
7 结束语
本文提出了考虑设备劣化的加工工时预测方法。该方法基于设备劣化的影响因素,针对单工况,对比了多类预测回归模型和概率分布模型,在现有方法的基础上引入多头残差注意力机制,完成了基于BiGCU-MHResAtt-Weibull模型的机加工工时预测方法构建;针对多工况,结合单工况模型,设计了大数据集和特征迁移模型,并通过聚类和曲线拟合生成加工工时预测谱系。最后,采用C-MAPSS数据集完成了模型训练和预测,最优RMSE为17.54,Score为502.11,表明预测方法能够较好地预测设备劣化程度,验证了所提方法的有效性。
在未来的工作中,拟将本研究提出的加工工时预测方法,融入动态调度模型,实现考虑设备劣化的加工工时修正,以期解决针对劣化问题导致的生产计划不可靠问题,从而提升生产计划的执行率。
