基于深度学习的表面缺陷检测技术研究进展
2024-04-10胡翔坤李少波
李 键,李 华,2,胡翔坤,李少波,乔 静
(1.贵州大学 省部共建公共大数据国家重点实验室,贵州 贵阳 550025;2.清华大学 机械工程系,北京 100084;3.新疆科技学院 信息科学与工程学院,新疆 库尔勒 841000)
1 问题的描述
在各类工业产品中,表面是否有缺陷能很大程度上反映其性能,表面缺陷检测是淘汰残次品的重要手段和衡量技术进步的重要依据。在我国制造业规划《中国制造2025》中明确指出,制造业数字化、网络化和智能化是这一轮工业革命的技术核心[1]。加快表面缺陷检测装备技术水平,对提升工业产品性能、质量和寿命等指标有着重要意义。
视觉缺陷检测方法是目前的主流检测方法,其主要优势是安全准确,受材料和形状的影响较小且检测效率高,经过数十年的发展,已有大量的基于机器视觉的缺陷检测设备被开发出来[2],但也存在如设计复杂、设备环境适应能力差、模型参数量大硬件成本高等问题。传统的基于图像处理的缺陷检测方法分为特征提取和识别两个阶段,文献[3-4] 分别采用选择性支配局部二进制模式(Selectively Dominant Local Binary Patterns, SDLBP)框架和广义完全局部二进制模式(Generalized Completed Local Binary Patterns, GCLBP)框架进行特征提取,然后采用近邻分类器分类特征,虽然取得了不错的效果,但其检测环境要求严格,需要手工设计并提取特征且适应性较差,当缺陷处于复杂环境条件下时(如图1)表现出了明显的局限性。近年来,以卷积神经网络(Convolutional Neural Networks, CNN)为主的深度学习方法由于其强大的自动特征提取能力,在计算机视觉领域取得了巨大成功。如关键点检测、目标跟踪、智能驾驶等,相较于传统图像处理方法,深度学习方法在特征提取和环境适应能力上优势明显。

图1 复杂环境下的表面缺陷
调研发现,目前相关的综述文献如下:文献[5-6]仅介绍了传统图像处理的缺陷检测方法,并没有涉及深度学习方法。文献[7-8]主要介绍具体对象(电子元器件、焊接件、纺织材料、半导体、钢铁、纺织材料)的深度学习缺陷检测方法,局限性较大。文献[9] 依据数据标签的不同展开,介绍了不同的基于深度学习的缺陷检测方法,但其对于不同方法的对比总结较少。文献[10]主要介绍缺陷分割算法,并不全面。本文归纳梳理了近年的相关文献,对比分析分类、检测、分割方法的优劣势和内在联系,同时整理了大量常用数据集和近年来提出算法在东北大学表面缺陷数据库(Northeastern University (NEU) surface defect database)数据集上的表现,分析了目前的改进方向。因此,是对上述文献很好的总结与深化。
2 深度学习和表面缺陷检测
2.1 深度学习
LECUN等[11]于2006年首先提出深度学习(Deep Learning),属于机器学习(Machine Learning)的一个新分支。感知机是深度学习中最基本的结构,由许多模拟人脑的“神经元”组成,通过对感知机进行堆叠学习便达到了“深度”这一范畴(见图2),对于深度学习的详细介绍请参考文献[12]。自深度学习算法在ImageNet[13]数据集和ImageNet大规模视觉识别挑战赛( ILSVRC)上实现了突破后,它已经成功地应用于各应用领域。在缺陷检测领域,目前绝大部分深度学习方法都是基于卷积神经网络(CNN)方法,文献[14]详细介绍了卷积神经网络。其核心操作为卷积,卷积也是深度学习在计算机视觉领域内大获成功的基石。目前深度学习模型已经逐步向自注意力机制[15](如大语言模型)和扩散模型[16]发展,但并没有影响CNN在缺陷检测领域的主导地位,对其进行研究综述仍有重要意义。
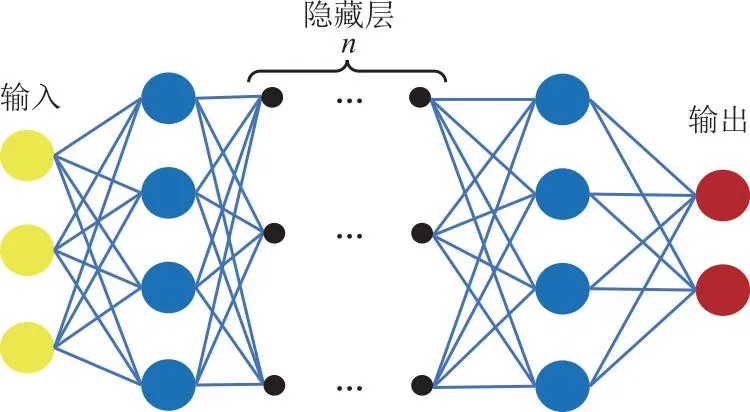
图2 深度学习模型原理
2.2 表面缺陷检测
表面缺陷检测是指对各类工件进行表面检测,识别其表面缺陷。与计算机视觉任务中的三大任务(分类任务、检测任务、分割任务)层级相似,表面缺陷检测的目标可以划分为3个层次,即“什么缺陷”、“哪里有缺陷”、“有多少缺陷”:①“什么缺陷”对应视觉任务中的分类任务,即对缺陷进行识别分类并区分缺陷类型;②“哪里有缺陷”是最严谨的缺陷检测,对应视觉任务中的检测任务,即给出缺陷的定位信息并用矩形框框出;③“有多少缺陷”对应视觉任务中的分割任务,即对缺陷进行像素级别的分割,确定其形状和尺寸等。这3类任务结果如图3中检测结果所示。虽然这3个任务的功能需求和目标不同,但其实际上相互包含且能够互相融合。例如对于②的实现的前提就已经包括了①,③实现的过程中就已经实现了②。因此,缺陷检测是一个较为宽泛的概念,只有对结构和目的进行综述时才加以区分。
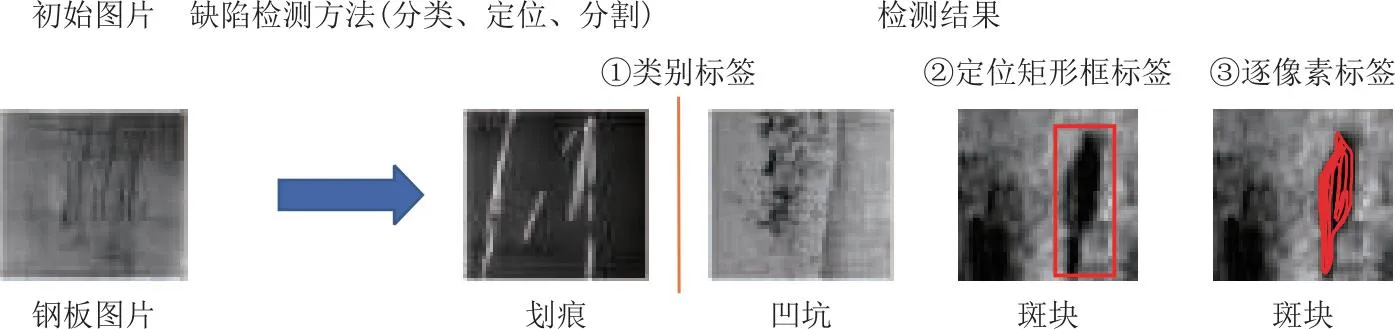
图3 表面缺陷检测定义
3 基于深度学习的表面缺陷检测方法
基于深度学习的表面缺陷检测方法如图4所示。目前基于深度学习的缺陷检测方法大部分为全监督学习模型,其次为无监督学习模型和弱监督与半监督学习模型,三者任务目的相同,主要区别在于对样本数据的标注要求不同。后两者在缺陷检测领域应用并不广泛, 但由于数据获取简单且数据标注成本较低,更加符合真实工业条件,现已成为缺陷检测领域内的研究热点,将在第4章关键问题中加以介绍。全监督学习模型根据其网络结构的不同,将其分为分类网络、目标检测网络、语义分割网络3类。目标检测和语义分割的主干(backbone)网络都以分类网络为基础,因此并不区分其主干结构。
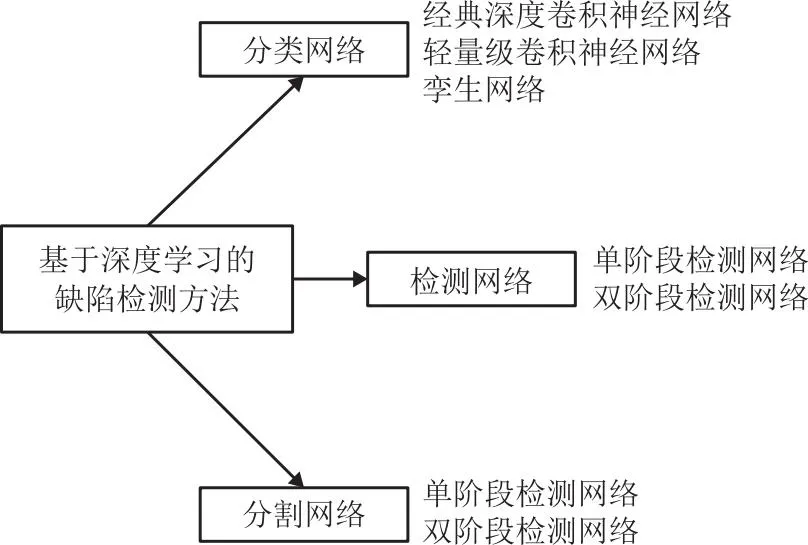
图4 基于深度学习的缺陷检测方法分类
3.1 分类网络
在各类工业产品的生产和使用阶段,由于产品的尺寸、形状、纹理和表面反光能力的巨大差异使得在真实环境下的表面缺陷分类尤为困难。目前分类网络基本采取基于CNN的网络,一般由级联的卷积层+ 激活函数层+池化层组成,再通过全连接层+softmax函数进行分类。一般将其分为经典深度卷积神经网络(classical deep CNNs)、轻量级卷积神经网络(lightweight CNNs)和孪生网络(siamese network)3类。其特征描述和出处如表1所示。
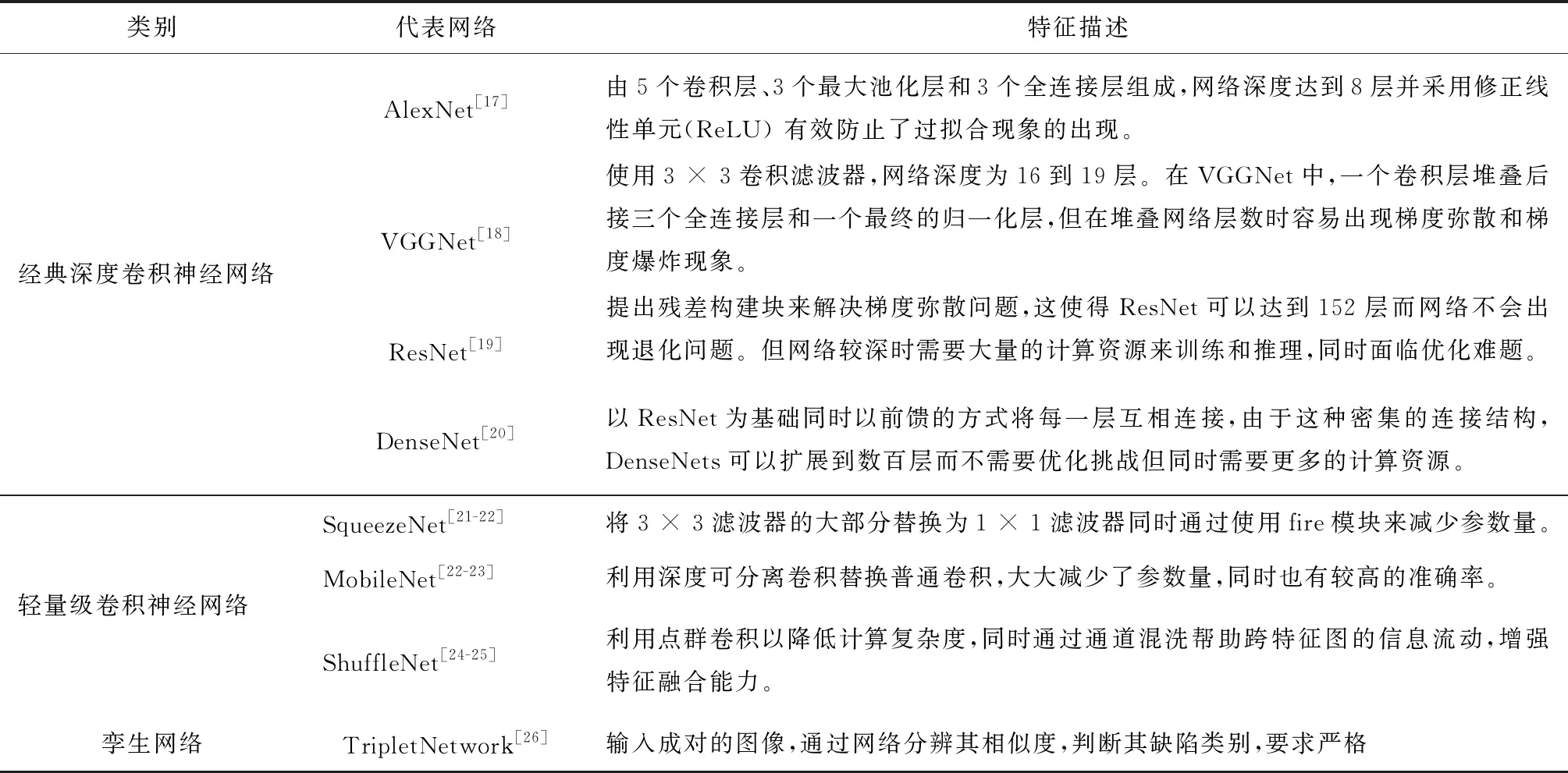
表1 分类网络特征
(1)经典深度卷积神经网络
卷积神经网络(CNN),是一类包含卷积计算且具有深度结构的前馈神经网络,由于其强大的特征提取能力,成为了目前分类网络的基础。2014年,SOUKUP等[27]首先将卷积神经网络应用在缺陷检测上,用纯监督方式训练的经典CNN进行实验,同时也探索了无监督预训练和数据增广对训练效果的影响,证明了经典的CNN明显优于基于模型的方法。由于识别准确率与速度仍不理想,YANG等[28]提出一种结合AlexNet和序列极限学习机分类器的Mura缺陷在线检测方法,它能够在1.5 ms内学习并分类Mura缺陷图像。KIM等[29]通过修改AlexNet并采用ResNet结构,提出一种用于表面贴装技术缺陷检测的CNN网络。通过直方图拉伸和芯片区域提取进行额外的输入图像变换,提高检测精度。为进一步提升识别准确率,LSHIDA等[30]提出一种基于VGG(visual geometry group)的深度CNN网络来识别晶圆图故障模式。数据处理采用具有降噪功能的数据增强技术。在基准数据集上的实验结果证明了该方法的高精度。WESTPHAL[31]等使用来自ImageNet数据集的VGG16和带有预训练权重的Xception CNN模型作为初始化和自适应分类器来分类零件制造过程中记录的好的和有缺陷的图像数据,VGG16模型架构在准确率( Precision,0.958 )、精确率(Accuracy,0.939 )、召回率( Recall,0.980 )、F1 - Score (0.959 )和AUC值( 0.982 )方面取得了最好的结果。对于梯度弥散与爆炸现象,KIM等[32]针对硅通孔工艺,提出一种基于残差网络的CNN缺陷图像分类模型,它们实现了高达97.2 %准确率的分类性能。VANNOCCI等[33]总结了CNN包括DenseNet在带钢图像分类中的应用,并与经典的机器学习方法进行了比较,从而确立了深度学习的有效性和一般有效性。
(2)轻量级卷积神经网络
在普通的卷积网络中,受其卷积核大小、激活操作、池化操作等的影响,导致卷积神经网络参数量过大,缺陷分类识别时间过长。在真实的工业环境中,效率问题不容忽视,因而如何在确保准确率尽可能高的前提下减少参数量成为了研究热点。FU等[34]对卷积神经网络(CNN)模型SqueezeNet进行一些列优化,调高低层特征训练的权重,融合各尺度感受野,达到了快速且准确地对钢铁表面缺陷进行分类的效果。CAO等[35]提出一个基于预训练的SqueezeNet架构的轻量级缺陷分类模型,并提出了冻结权重、大小无关组归一化(Group Normalization, GN)和增加辅助任务3个有效的技术来实现使用极少数收集的缺陷训练样本的高准确度缺陷分类。SqueeseNet模型参数较多,且特征提取能力较差, PAN等[36]提出一种新的MobileNet结构,通过DropBlock技术和GAP(global average pooling)方法,成功地优化了TL-MobileNet模型的整个训练过程, 精度达到了97.69% 。SAMBANDAM等[37]将MobileNet V2、ResNet-18和一般CNN模型进行分类任务对比,在对潜水泵叶轮缺陷分类任务中,MobileNet V2以98.17%的最高测试准确率取得了最好的结果。HUANG等[38]开发了一种紧凑的基于 CNN 的模型,由轻量级(Light Weight, LW)瓶颈和解码器组成,通过轻量级内核的金字塔,LW 瓶颈以更少的计算成本提供丰富的功能,它不仅可以在微小缺陷检测上实现高性能,不可以在低频 CPU(中央处理器)上运行,模型获得了与 MobileNetV2 相似的精度,但只有不到其 1/3 的 FLOP(每秒浮点运算)和 1/8 的参数量。为进一步提升特征提取融合能力,DOSS等[39]提出的一个由 ShuffleNet-v2 的预训练深度迁移学习模型和卷积神经网络(CNN) 架构组成模型,ShuffleNet-v2-CNN按照数据预处理、数据增强、特征提取和分类的工作流程执行缺陷识别和分类过程,所提出的模型在基于晶圆图图像对硅晶圆缺陷进行分类时获得了 96.93%、95.40% 的精确度。
(3)孪生网络
孪生网络通常是输入成对的图像,通过学习出它们的相似度,判断它们是否属于同一类。孪生网络的关键在于损失函数的构造,其核心思想是让相近类别的输入距离尽可能小而不同类别的输入距离尽可能大。MIAO等[40]提出一种新的成本敏感深度学习模型—成本敏感孪生网络(Cost-Sensitive Siamese Network, CSS-Net),基于孪生网络、迁移学习和阈值移动方法区分真实和伪印刷电路板(Printed Circuit Board, PCB) 缺陷作为成本敏感分类问题,使用 NSGA-II 等优化算法来确定最佳成本敏感阈值,真实缺陷预测精度提高达 97.60%,并在实际生产场景中保持相对较高的伪缺陷预测精度,为 61.24%,训练时间平均缩短 33.32%。LUAN等[41]提出一种基于孪生网络的缺陷敏感损失函数,用于检测工业生产表面的缺陷,学习过程最小化设计损失,以驱动无缺陷图像的类内距离更小,并扩大最难缺陷图像与无缺陷图像之间的距离,所提方法在不平衡率为10:1和50:1时的准确率为 100%。LI等[42]提出一种端到端方法(TireNet),孪生网络在新模型中用作下游分类器的一部分,以捕获缺陷特征。
综上,分类网络应用广泛且结构种类众多,表2中给出各类网络的优缺点。可以根据实际任务需求选择合适的网络。

表2 分类网络优缺点对比
3.2 检测网络
定位关键目标是计算机视觉的核心任务之一,同时也是最接近传统缺陷检测的任务,即找出图像中感兴趣的目标(物体),确定它们的类别和位置并用矩形框框出。目前常见的目标检测网络在结构上可以大致分为以Faster R-CNN[43]为代表的双阶段网络和以SSD(single shot multibox detector)[44]和YOLO(you only look once)[45]为代表的一阶段网络两类。其主要差别在于双阶段检测网络引入区域建议网络进行建议生成候选框,一阶段检测网络直接将主干网络提取的特征来预测缺陷的类别和位置。
(1)双阶段检测网络
双阶段检测网络(Fast-RCNN)的两层架构为:①首先通过主干特征提取网络Backbone(一般为VGG、ResNet等),在提取的特征图上利用RPN(region proposal network)网络生成先验框 (anchor box)及其置信度,通过非极大值抑制NMS(non maximum suppression)等筛选先验框并获取到建议框(Proposal)区域;②对建议区域的特征图进行ROIpooling后输入网络,得到最终的缺陷的定位和类别预测。根据其特点,对于双阶段网络的改进往往针对其Backbone结构、NMS值大小、ROIpooling和损失函数的构造方面。SUN等[46]提出一种改进的Faster R-CNN方法,构建了由2412幅1080 × 1440像素图像中的四类缺陷组成轮毂缺陷数据集,基于该数据库对Faster R-CNN进行修改、训练、验证和测试,最终实验结果mAP为72.9%,优于与之比较的R-CNN和YOLOv3网络。由于特征融合效果较差,HE等[47]提出了多级特征融合网络融合各层特征,将融合后特征通过RPN网络生成感兴趣区域,最终得到每个区域的类别和位置信息,在自建的数据集NEU-DET上,该方法在主干网络ResNet34 / 50上使用300个候选集取得了74.8 / 82.3 mAP的成绩。为应对小目标的任务,ZHAO等[48]在传统Faster R- CNN算法中进行了一系列改进措施,针对目标的小特征,对网络进行多尺度融合训练,而对于复杂特征,将部分传统卷积网络替换为可变形卷积网络增强其特征提取能力,银纹、夹杂、斑块、麻面、鳞片、划痕的平均精度分别为0.501、0.791、0.792、0.874、0.649、0.905,检测方法能够有效识别钢材表面的小目标缺陷。SU等[49]在Fast-RCNN的基础上将新颖的通道注意子网与空间注意子网顺序连接起来,在原始太阳能电池缺陷数据集上实现了87.38%的平均精度。ZHU等[50]提出一种基于Faster-RCNN的改进型多目标缺陷识别算法,该算法以VGG16为Backbone,采用ROI Align和交替优化策略,改进后的Faster-RCNN用于输电线路目标识别的召回率为0.8252~0.9869,平均为0.9254。DENG等[51]对锚框筛选算法进行改进,通过k-means++聚类算法对锚框算法进行优化,以ResNet50为主干网络改进后的网络在发动机缸体水路缺陷数据集中的平均精度达到88.74%。
(2)单阶段检测网络
单阶段检测网络以SSD和YOLO系列网络为代表,通过输入整幅图片,直接在输出层输出回归的边界框(bounding box)的信息,并不需要首先生成锚框,因此单阶段检测网络在运行速度方面快于双阶段检测网络。双阶段检测网络主干的特征提取能力直接决定了检测精度,LI等[52]提出一种采用SSD网络结合MobileNet识别表面缺陷类型和位置的表面缺陷检测方法,该方法能够比传统机器学习方法更准确、快速地自动检测表面缺陷。JIANG等[53]提出一种将MobileNetV3与SSD结合的网络模型通过深度可分离卷积、逆残差网络和线性瓶颈结构对目标检测算法进行优化,该网络的完整检测准确率达到了64.81 %和64.12 %,取得较大幅度的提升。DING等[54]使用彩色电荷耦合器件相机来收集赤木和松树两种木材的表面图像,引入DenseNet网络改进SSD算法,对活节、死节和检查3类缺陷的平均精度为96.1%。SONG等[55]在YOLOV3网络基础上使用量纲聚类方法计算缺陷的宽度和高度以及中心点的坐标,最终识别率可达97 %以上,识别时间约为0.15 s。YUAN等[56]提出了以YOLOv3为基础的MOLO网络框架,以MobileNetV2为骨干网络提取图像特征,然后进行多尺度缺陷检测,其平均精度(mAP)达到了87.40%比YOLOv3提高4.03%。YIN等[57]提出一种以YOLOv3为主体的下水道管道的缺陷检测模型,框架侧重于精简信息和数据流,提出输入和输出数据处理模式,平均精度(mAP)为85.37 %。GUO等[58]提出了MSFT-YOLO模型,将基于Transformer设计的TRANS模块添加到骨干和检测头中,使特征与全局信息相结合,在图像背景干扰大、缺陷类别容易混淆、缺陷尺度变化大、小缺陷检测效果差的工业场景中的平均检测精度为75.2,相比于YOLOv5提高了18%。
目标检测领域仍在高速发展,相信今后会有更好的检测网络出现。双阶段检测网络首先需要提取特征并对其进行RPN、NMS与pooling操作,其所需时间较长但精度较高,而单阶段检测网络直接输入图片并直接输出边界框信息,并不需要多阶段处理,其所需时间较短但精度较低。综上,现阶段的缺陷检测领域内,两种算法各有利弊,若追求高检测精度任务中选择双阶段检测网络较多,在强调检测速度的检测任务中一般选用单阶段检测网络。
3.3 分割网络
分割网络是近年来将缺陷检测任务转换为计算机视觉中语义分割甚至是实例分割的一个成功尝试,它不仅可以对缺陷区域进行精细的分割,还可以准确地识别出缺陷的类别以及不规则的几何形状(如轮廓和面积等)。依据结构的不同,分割网络大致可分为两类:以全卷积神经网络(Fully Convolutional Networks, FCN)[59]为代表的单阶段分割网络和以Mask R-CNN[60]为代表的双阶段分割网络。双阶段分割网络需要首先生成兴趣框,然后利用网络对兴趣框进行像素级分割。而单阶段分割网络则是对整个图像进行全卷积操作,直接对图片进行分割。
(1)单阶段分割网络(FCN)
单阶段分割网络一般指基于FCN的一系列网络,根据结构的不同可以分为FCN、U-Net[61]和SegNe[62]三种。①FCN方法:QIU等[63]通过三通道特征融合特征,使用轻量级全卷积网络(FCN)对缺陷区域进行像素级预测,网络每秒可处理25张缺陷图像(尺寸为512 × 512),像素精度达99 %以上。WANG等[64]提出一种基于alternate-selection策略来消除拼接图像的残余和几何失真,利用改进的FCN-8s-Conv4-Conv5网络对拼接图像进行像素分割,平均准度达到0.867。TABERNIK等[65]将FCN应用在少量的缺陷表面上,大约25~30个缺陷训练样本,使用改进平均交叉熵损失函数,实现了7个百分点的精度增长。②U-Net:U-Net构建了一整套完整的编码器-解码器网络,在解码器上使用反卷积进行上采样。MIAO等[66]提出一个改进的U-Net模型,包括一个组合的挤压和激发(Squeeze and Excitation, SE)和ResNet块,模型在剥落和裂缝数据集上的交并比 (Intersection over Union,IoU)分别为89.1%和70.0%。PAN等[67]在U-Net的全连接层与卷积层间添加了一个特征重用和注意力机制,用来解决高水平和低水平特征之间的语义差异,它能以每秒32幅图像的高速处理CCTV图像,取得了76.37%的最高平均交叉率(mIOU)。PRATT等[68]以VGG16为编码器训练了一个U-Net网络模型,通过优化参数减少误差,在太阳能板数集上取得了94%的缺陷检测精确度。③SegNet:SegNet主要是在解码器中使用反池化操作对特征图进行下采样,对高频细节保留较好。DONG等[69]将基本的SegNet网络与焦点损失函数结合进行训练,模型在各种噪声的条件下,其小尺寸损伤的图像的mAP和MIoU达到81.53%和69.86%。CHEN等[70]构建了包含路面复杂裂纹纹理的裂纹数据集,参照SegNet网络并使用VGG16为主干网络训练,其平均精度(mAP)达到了83%。
(2)双阶段分割网络
双阶段分割网络受益于目标检测的丰硕成果,Mask-RCNN以Fast-RCNN为基础,增加了一个与bbox检测并行的预测分割mask分支,同时改进ROIpooling等操作,Mask-RCNN在语义分割中取得了良好的效果。WEI等[71]以ResNet101为主干网络构建了Mask-RCNN网络用于路面的缺陷分割,结果显示边界框和掩码的平均精度 (Average Precision, AP) 分别为 90.0%、90.8%。XU等[72]将增强特征金字塔网络和边缘检测分支加入Mask-RCNN网络中,在隧道表面缺陷的分割上mAP为88.76%。ZHANG等[73]提出了一种基于Mask RCNN的车辆损伤检测分割算法,对残差网络(ResNet)和FPN进行优化,对车辆缺陷检测的准确度达到了96.68%。郭龙源等[74]提出了一种改进型Mask RCNN缺陷检测算法,引入预处理模块和C1模块,对磁瓦表面缺陷检测准确率达98.38%。
相较于分类和检测方法,分割方法在信息获取上优势明显。分割网络一直在不断地发展,例如近年来提出的DeepLabv3[75]、PSPNet[76]等。与目标检测网络相似,从精度和速度两个方面来看,双阶段算法相比单阶段算法在相同基础网络下表现更优,且所需训练迭代次数较少。单阶段算法速度更快,精度处于平均水平,但需要更多的训练迭代次数。因此需要根据具体需求选择合适的算法。
综上,基于深度学习的缺陷算法分为分类、检测、分割三类,为展现不同种类网络的优缺点,各网络详细对比见表3。

表3 三类网络特征对比
4 关键问题
4.1 小样本问题
缺陷检测是工业领域内的一项具体应用,在真实工业条件下,能提供的缺陷样本数量很少。与ImageNet或者COCO数据集这种上亿样本数据的数据集相比,缺陷数据集提供的样本数量太少,在某些工业条件下甚至只有数十张缺陷图片,因此小样本问题成为了缺陷检测面临的最大问题之一。目前提出的解决小样本问题的方法主要有3种。
(1)结构优化 通过对网络结构的改进优化,可以增强网络的特征提取能力,同时减少了样本需求。BHUGRA等[77]研究了使用具有多个金字塔层级的深度神经网络融合不同尺度的图像特征的图像。LYU[78]提出一种新颖的结合注意力机制的少样本学习方法,由一个提取图像特征的CNN和一个计算一对图像之间相似性分数的关系网络(Relation Network,RN)组成,通过相似性分数可以预测图像类别。为了提取更加有效且具有判别性的特征,该方法引入了挤压激励网络(Squeeze-and-Excite Networks,SENet)作为注意力模块来增强有效特征并削弱无效特征。
(2)数据增广 数据增广一般包括数据扩增、数据合成与生成。一类扩展方法是对原有缺陷数据进行翻转、裁剪、采样等操作实现,例如WEI等[79]利用压缩采样定理对数据进行压缩和扩展,在疵点样本数量较少时,该方法也能有效提高织物疵点样本的分类准确率。另一类增广方法就是数据合成,即将不同的缺陷与正常背景分开进行叠加融合。文献[80] 利用算法模拟4种典型的采集屏缺陷,将其与正常背景图片叠加融合,创建人工缺陷数据库,然后将人工数据集应用于深度学习识别算法,训练初始模型。由于生成对抗网络(Generative Adversarial Network,GAN)的强大图像生成能力,出现了大量基于GAN的表面缺陷检测研究,如LIU等[81]、HE等[82]和NIU等[83]提出的基于GAN网络的方法。
(3)预训练或迁移学习 由于深度学习网络参数量巨大,在小样本上训练很容易导致过拟合现象。在大数据集上训练的预训练模型存在着许多相似的特征数据和权重信息,能有效地缓解过拟合现象。GOPALAK RISHNAN等[84]首先将ImageNet预训练模型应用到表面缺陷中,随后如FERGUSON等[85]、GONG等[86]、冯毅雄等[87]、ABU等[88]和LIU等[89]也将预训练模型权重迁移至所提出的缺陷检测模型中。
4.2 不平衡样本标签问题
不平衡样本问题包含正常样本学习和部分样本学习问题,如图5所示。区别于全监督学习模型对所有样本数据的详细标注,不平衡样本标签的主要特征是其训练样本无标签或者其标签并不完整(弱标签),由于数据获取简单且数据标注成本较低,在这种条件下对产品表面进行缺陷检测识别是否存在缺陷更加符合真实工业条件,现已经成为了缺陷检测领域内研究热点[90]。
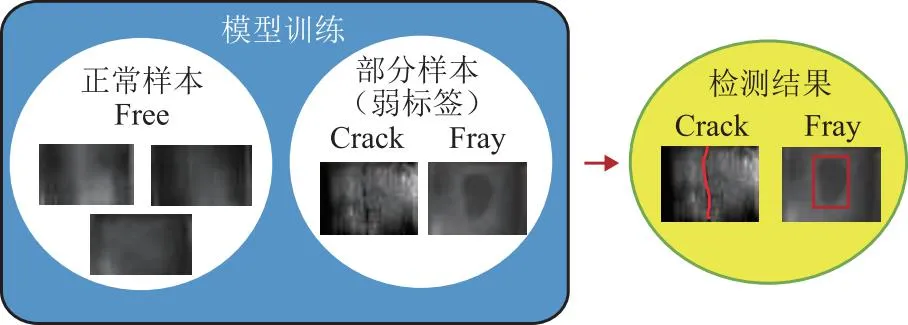
图5 不平衡样本学习问题定义
4.2.1 正常样本学习问题
在深度学习的背景下,无监督是指在训练阶段只包含了正常样本的图像,即没有任何的缺陷标注。在真实工业场景中,正常样本的获取难度远低于缺陷样本,无监督学习方式可以有效避免采集缺陷或异常样本的困难,目前无监督学习方法仅应用在简单的纹理缺陷检测中,对于复杂的纹理缺陷或者结构缺陷效果不佳。解决无监督学习问题的方法主要为图像重建,它是基于只训练模型重建正常图像的思想,当输入一幅异常图像时,模型仍将异常区域重建为正常,输入图像和重建图像之间的差异代表了定位结果,该方法主要使用自编码器(AutoEncoder,AE)、GAN和归一化流(Normalizing Flow,NF)。
使用自编码器时,往往对模型的损失函数进行改进,文献[91]使用卷积自编码器重建图像,并首次将结构相似性(Structural SIMilarity, SSIM )度量应用于图像重建,对比L2损失,它在纳米纤维材料数据集和两种编织品的新型数据集上取得了显著的提升。文献[92]提出一种新的多尺度梯度幅值相似度(Multi Scale Gradient Amplitude Similarity, MSGAS)损失,更加关注重构中的结构差异。MSGMS损失通过计算原始图像和重建图像的梯度图像来构建,精度提高了6.5 %。NAKANISHI等[93]设计了一种新的损失函数,称为加权频域(Weighted Frequency Domain, WFD)损失,将重建损失计算从图像域转换到频域,它提供了更清晰的重建图像,提高了异常定位精度。唐善成等[94]在重构误差基础上增加了潜在损失Lμ和Lσ 2,F1值至少提升了7.4%,准确率达98.58%。改进损失函数一般对于特定缺陷分布有一定效果,当缺陷改变时,其效果往往不明显。GAN模型对潜在的特征空间学习能力强,在GAN的生成器生成缺陷图片的伪正常图片后,可以自然的利用GAN的判别器进行分类,以区别缺陷和正常样本。SCHLEGL等[95]最早将GAN应用于异常定位,生成网络G接收来自潜在空间的随机采样样本作为输入,其输出必须尽可能接近训练集中的真实样本,生成网络G的输出与输入图像的差异决定了异常区域。文献[96-97]几项后续工作针对工业表面缺陷采用了该模型。还有如文献[98-101]对GAN网络的生成器和判别器进行改进以提高无监督缺陷检测精度。NF模型是学习数据分布和定义良好的密度之间转换的神经网络[102]。与基于AE或GAN的方法直接处理图像不同,基于NF的方法在特征上进行处理,通过测量测试图像的特征与估计的无缺陷图像分布之间的距离来获得异常区域。2021年RUDOLPH等[102]首次提出基于NF方法的DifferNet。随后,3种基于NF的方法通过3种不同的方式进行了改进,并在多个数据集上取得了惊人的效果,如GUDOVSKIY等[103]设计了基于条件正规化流的CFLOW-AD模型、RUDOLPH等[104]设计的CS-Flow模型与YU等[105]所提出的2D flow模型。3类方法的详细对比如表4所示。

表4 基于不同方法的无监督学习模型的优缺点
4.2.2 部分样本学习问题
相较于全监督学习和无监督学习,弱监督与半监督学习的特点是样本图像标签并不完整(弱标签)。一是有多处缺陷但标注不完全,二是只有较为低级的分类标签,并没有更高一层的矩形框和像素级标签。正因如此,弱监督与无监督学习方法能极大地减小数据标注的难度,提升模型开发效率,本质上看,弱监督与半监督学习就与小样本和无监督学习一致。目前解决弱监督与半监督学习的方法也大多借鉴于小样本问题和无监督学习。NIU等[106]提出一种基于GAN的弱监督缺陷检测方法,在DAGM2007公开数据集上取得了较好的效果。CHEN等[107]在CNN基础上整合了鲁棒分类器和空间注意力模块,同时提出一种新的空间注意类激活图(SA-CAM),通过生成更精确的热图来提高分割的适应性,提高了0.66%~25.50%的分类准确性和5.49%~7.07%的分割准确率。ZHANG等[108]采用了知识蒸馏策略,学习大模型的特征,通过教师-学生模型,提高了模型构建速度和检测性能。此外还有文献[109-110]也提出了各自的解决方法。但不难看出,目前弱监督与半监督学习方法在分类任务上精度尚可,但在检测和分割任务上还有很大的提升空间。
4.3 与传统图像处理技术对比
传统图像处理方法参考文献[111] ,从方法、处理过程、所需条件和适应性3个方面进行对比,以便更好地说明深度学习方法的优越性,对比结果见表5。

表5 传统图像处理方法与深度学习方法对比
5 公开数据集及其挑战
区别于计算机视觉任务中的大型数据集ImageNet[13]、PASCALVOC2007/2012[117]、COCO[118]等,缺陷检测由于其检测任务的场景和对象不同,并没有一个统一的数据集,对某一个场景和对象的研究往往基于某一个特定的数据集。本章整理了涵盖钢材、太阳能板、纺织物、晶体、木材、磁瓦等常用的缺陷检测数据集和相关链接(如表6);此外,如“百度飞浆”(https://aistudio.baidu.com)、“阿里云天池”(https://tianchi.aliyun.com)、“Kaggle”(https://www.kaggle.com)等也有大量的竞赛所用开源数据集。
选择NEU数据集来作为示例,以展现基于深度学习的缺陷检测算法的应用效果。NEU数据集包括NEU-CLS(分类任务)和NEU-DET(检测任务)两个部分,具有热轧钢带的6种典型表面缺陷,包括裂纹、夹杂物、斑块、凹陷面、轧制鳞片和划痕,总共1800张灰度图片,每种类型的缺陷包含300个样本,标注格式为xml格式。表7罗列出了近年来提出的缺陷检测方法在NEU数据集上的应用效果。不难看出,目前在分类任务上的准确率已经基本满足了实际工业条件需求,如文献[137]取得最好精度99.34%的成绩,但在检测速率上还有提升空间。而对于检测任务的性能上还有一定的提升空间。
6 结束语
在缺陷检测的研究和应用中,尽管深度学习方法已经在该领域取得了很大的进展,有些方法在某些数据集上的检测准确率甚至达到了95%以上,但在实际应用中仍存在不少的问题与挑战。
(1)实时性问题(轻量化问题) 在工业生产中,实时性是生产效率的体现。使用高分辨率的图像往往可以使检测精度提升,但将高分辨率图片输入深度学习模型中时会增大网络参数量,延长计算时间,因此如何平衡实时性与精度,值得注意。本文第三章提到的轻量级卷积神经网络是解决这一问题的理想方法之一,如文献[37,53-54]等,此外还有如直接对模型进行压缩的权重裁剪、分解量化与知识蒸馏等方法,但其在缺陷检测领域的实际应用较少,还有很大的发展空间。
(2)工业化集成 表面缺陷检测通常是工业生产线上的一个环节,需要与其他自动化技术进行集成,以实现更高效的生产和质量控制。因此,需要开发更加智能化和自适应的缺陷检测系统,以适应不同的生产环境和需求。在文献[64] 中WANG等通过一套试验台对图像裂纹自动检测系统进行了验证,通过系统的实现,将实时图像采集与传输、快速图像拼接、基于深度学习的图像分割、目标特征描述与定位有效地结合在一起,这是典型的集成应用。在国家大力发展智能制造的背景下,缺陷检测技术的工业化集成具有广泛的发展前景。
(3)异域数据联邦学习 缺陷性检测数据集样本个数往往很少且由于企业或研究机构的隐私问题,数据集之间并没有有效的结合利用,如划痕等广泛存在于木材、金属、太阳能板、玻璃等一系列材料表面,但并没有一个不限材料且具有大量样本的划痕缺陷集,这对于缺陷检测的发展产生一定的限制,如何让模型学习到不同数据集样本特征以达到对整个划痕缺陷的识别是一个值得研究的方向。在第四章小样本解决方法中迁移学习可以缓解这一类问题,但这往往需要其他模型的隐私权重文件。在联邦学习中, 不同领域的数据集可以在本地进行训练, 然后将模型参数上传到中央服务器进行聚合, 从而得到一个全局模型。这种方法可以避免数据泄露和隐私问题, 同时也可以利用不同领域的数据来提高模型的泛化能力和准确性,更好地满足实际工业生产的需求。
(4)Transformer技术的迁移应用(包括多模态统一模型) 2017年提出的Transformer[144]是用于计算机自然语言处理领域的基于纯注意力的自监督模型。在2021年DOSOVITSKIY等[145]首次将Transformer技术成功的应用在计算机视觉领域,近两年来已经在计算机视觉领域取得重大进展。到目前为止, Transformer的性能已经超过了标准CNN在大多数任务上的性能,但它却很少引起工业领域的关注。文献[146-148]将Transformer应用在缺陷检测任务上并取得了不错的效果。但相较于传统CNN模型,其模型参数量过大,训练时间过长。此外,如何建立统一模型,不但让缺陷在图像上直观地显示,而且加上相应的文字解释,调研发现,缺陷检测领域内目前统一模型并无参考。总的来说,Transformer技术在缺陷检测领域有广泛的研究前景。
随着人工智能技术特别是计算硬件(特别是GPU)的高速迭代发展,目前缺陷检测的研究重点已经从传统的图像处理方法转移到深度学习方法,其主要优势在于可以自动学习特征且通用性较好,避免了手工设计特征的繁琐过程。本文系统性地总结了缺陷检测的发展前景、基于深度学习的缺陷检测方法、关键问题和常用的缺陷检测数据集,并对缺陷检测未来的发展进行了合理的展望。通过上述总结与分析,希望能为缺陷检测方面的研究提供有价值的参考。
