中文文本屏幕内容图像通用视频编码标准编码感知失真研究
2024-04-10杨楷芳晁学敏蒙琴琴公衍超
杨楷芳,晁学敏,蒙琴琴,公衍超
(1. 陕西师范大学计算机科学学院,710119,西安; 2. 现代教学技术教育部重点实验室,710062,西安; 3. 陕西省教学信息技术工程实验室,710119,西安; 4. 西安邮电大学通信与信息工程学院,710121,西安)
随着多媒体技术和云技术的快速发展,屏幕内容图像被广泛应用于远程会议、屏幕共享、在线教育等领域[1]。屏幕内容图像是由计算机或其他电子设备生成或渲染的图像,通常包含文字、图形、图表、图标、动画等内容[2]。在当前公开的屏幕内容图像数据库中,文字区域面积占比超过40%[1]。主要包含文字内容的屏幕内容图像又被称为文本类屏幕内容图像(text screen content image, TSCI)。相比于图形、图表、图标、自然场景等内容,文字作为与人类先验知识密切相关的符号,所携带的语义对图像信息的准确感知有重要影响。文献[1, 3]研究表明,人眼对文字内容的质量感知更加敏感。所以,TSCI的感知质量显著影响远程会议、在线教育等视频应用中用户的感知体验,是决定这些视频通信系统有效运行的关键因素之一。
在远程会议、在线教育等通信系统中,TSCI需要经过采集、编码、传输、存储、显示、分析等操作[4]。编码的目的是用更少的编码码率获得更高质量的重建TSCI。编码通常是有损的,这不可避免地在重建TSCI中引入失真,显著影响TSCI的感知质量。当前一些研究已经关注了TSCI的感知质量。文献[3]通过分析主观实验感知质量分数的统计特征发现文字区域的感知质量与图像总体感知质量的相关性更强,且文字的清晰度和完整性是人眼评价文本感知质量的重要依据。然后,采用锐度相似度和亮度相似度作为文字清晰度和完整性的测度,并提出有效的TSCI质量评价方法。文献[5]指出文字区域含有丰富的高对比度边界信息,这些信息与文本内容的准确表达密切相关,而小波变换可以提供多尺度的边界信息。因此,文献[5]将文本图像从像素域变换到小波域,并基于小波系数的幅值、方差、熵等信息提出了有效的TSCI质量评价方法。与文献[5]类似,文献[2, 6-7]也关注到了文字边界信息对TSCI感知质量的重要影响,并分别提出了适用于编码失真的质量评价方法。不同的是,文献[2]提取的是文字边界对比度、边界宽度和边界方向特征,文献[6]提取的是文字边界的梯度和宽度特征,而文献[7]提取的是基于Gabor滤波器的时空Gabor特征张量模型(spatiotemporal Gabor feature tensor-based model,SGFTM)特征。文献[8]考虑屏幕内容图像中的文本形状规则且包含大量细线条和锐利笔画,因此提出利用像素的标准差分布特征衡量文本区域感知质量。面向由JPEG、JPEG2000标准压缩的图像,文献[9-11]分别提出了有效的质量评价方法。文献[9]采用梯度信息表征文字区域的结构特征,并进一步根据原始图像和失真图像的结构特征相似度得到文字区域的质量。文献[10]通过分析文本区域和图像区域标准差分布的差异,提出一种考虑局部标准差分布特征的质量评价方法。文献[11]则基于人眼对文本区域的先验知识,提出了考虑文本区域感知重要性的质量评价方法。但是当前研究还存在以下明显问题:
(1)都是面向的英文TSCI,未考虑中文TSCI。汉字是中华文化传承和信息传播的重要载体,是中文文本的符号系统。汉字作为一类由特定笔画构成的表意文字,也是目前世界上还在使用的人数最多的象形文字,其笔画特征是影响汉字语义信息表达的重要因素[12-13]。英文作为一类表音文字,其源于拉丁字母,单个字母本身没有含义,字母的特定组合形成单词后才能表达语义[14]。因此,中英文文字系统的先天差别决定了中文TSCI和英文TSCI对应的编码失真特性也会存在明显不同,需要针对中文TSCI的编码感知特性进行针对性研究。
(2)都是面向早期的编码标准,未考虑最新的通用视频编码标准(versatile video coding, VVC)标准。现有研究[2, 3, 5-11]中已经关注的编码标准包括1992年发布的JPEG标准、2000年发布的JPEG2000标准、2003年发布的H.264/AVC标准、2013年发布的HEVC标准和2017年发布的HEVC-SCC标准。JPEG、JPEG2000、H.264/AVC、HEVC标准在设计时并未考虑屏幕内容图像的典型特性,所以针对屏幕内容图像的编码效率较低[15-16]。为了提升屏幕内容图像的编码效率,第一个面向屏幕内容图像/视频的编码标准,即HEVC-SCC标准,应运而生。近几年随着屏幕内容视频朝高清化、多维度等方向快速发展,HEVC-SCC标准的编码效率已经很难满足实际需求。相应地,ITU-T和ISO/IEC联合制定并发布了最新的通用视频编码(versatile video coding, VVC)标准[17]。相比于之前的标准,VVC采用了大量先进的编码技术,例如改进的调色板模式、帧内块拷贝、块差分脉冲编码调制等。新的技术大幅提高了VVC编码屏幕内容视频的效率,同时也显著改变了屏幕内容图像的编码失真类型和感知表现。但是,当前针对TSCI的VVC编码感知失真研究还是空白。
本文首次聚焦中文TSCI的VVC编码感知失真研究,并首次构建中文文本屏幕内容图像数据库(Chinese text screen content image dataset, CT-SCID)。进一步地,结合图像主观观测实验和VVC混合编码框架原理,探索分析VVC引起的TSCI感知失真类型及其发展路径,理论分析及实验验证影响感知失真程度的因素,并总结当前代表性的图像质量评价方法在评价这些感知失真时的性能表现。
1 中文文本屏幕内容图像数据库
1.1 数据库构建
目前,涉及TSCI编码感知质量评估的数据库包括SIQAD[3]、SCID[2]、QACS[5]、SCVD[7]、CSCVQ[8]、SCD[18]。涉及的编码失真包括由JPEG、JPEG2000、H.264/AVC、HEVC和HEVC-SCC标准产生的失真。这些数据库还存在以下明显问题:①包含的TSCI绝大多数为英文TSCI,中文TSCI只有极少的几幅,且未对中文汉字的失真特性做针对性的分析总结;②未考虑VVC标准,数据库中没有包含VVC编码的失真图像。所以,为了便于后续针对中文TSCI 开展VVC编码感知失真的研究,需要首先建立中文TSCI数据库。
在充分调研已有数据库指标及TSCI典型应用场景的基础上,本文构建了中文文本屏幕内容图像数据库(Chinese text screen content image dataset, CT-SCID),如图1所示。CT-SCID共包括55幅原始图像,涉及远程会议、在线教育、屏幕共享、网页浏览等典型的TSCI应用场景,包含各类办公软件、学术文献、代码编辑、网页、新闻、广告、游戏等丰富内容。数据库还考虑了文本对比度、字体大小、字体类型等因素。文本对比度的范围为 [139,5 115],字体大小的范围为 [327,3 509],范围能够覆盖大部分实际场景。字体大小和文本对比度衡量测度的定义请分别参见第3.1节和第3.2节中相关内容。字体类型考虑了宋体、楷体、微软雅黑、黑体等主流字体。原始图像的空间分辨率为1 920×1 080,这是当前TSCI典型应用场景中硬件终端广泛支持的空间分辨率之一。图像颜色空间为YCbCr 4∶4∶4,比特深度为8。
图像作为由像素构成的二维矩阵,其空域细节信息的多少也是衡量图像特性的一个重要因素[19]。ITU-R BT.1788标准定义了空域感知信息(spatial perceptual information, SI)[19]衡量图像的空域细节信息。为了适应TSCI纹理边缘较尖锐,甚至包含单像素边界的特点,本文计算SI时采用的是Canny算子,且计算的是二值图像的标准差。SI越大表明图像包含的空域细节信息越多,图像越复杂。图2给出了CT-SCID数据库中55幅原始图像的SI。可以看出,图中的数据点可以涵盖SI较大的范围,表明原始图像对应的空域细节信息分布较广泛,能够覆盖大部分实际场景。

图2 CT-SCID中原始图像的SIFig.2 SI of the original images in CT-SCID
采用VVC官方推荐的测试模型VTM16.2[20]编码原始图像获得对应的失真图像。VVC仍然沿用传统的基于预测变换量化熵编码的混合编码框架[17, 21], 但是在每个编码模块中都采用了更加先进的技术以提高视频编码的效率。例如,在预测模块中,VVC采用了更灵活的编码单元块划分和更丰富的帧内帧间预测方向。在熵编码模块中,VVC采用了更灵活更高效的上下文模型。但是,预测、变换、熵编码中的技术在原理上都是无损的,而量化才是引起视频编码失真的根本原因[4,21]。一方面,VVC采用多对一的量化映射机制,在减少变换系数取值空间的同时会显著降低视频细节信息的表达能力,导致视频清晰度降低,视频内容变模糊,引入编码失真。另一方面,考虑人类视觉系统对于视频细节信息感知不敏感,VVC进一步采用了量化矩阵技术,对高频系数使用更大的量化步长(quantization step, QS),这易导致高频信息的丢失,从而使得视频内容进一步变模糊,引入编码失真。综上可知,相比于其他编码策略或技术,量化中的QS是影响编码失真的最重要因素[21]。当前代表性的屏幕内容图像数据库[3, 5, 8, 18]也都是考虑调整QS来获得不同编码失真程度的图像。本文也是沿用这一思路。
在实际应用中,VTM是通过选择量化参数(quantization parameter, QP)来控制QS的取值。VVC规定的QP取值范围为-6(η-8)~63,其中η表示比特深度。韦伯-费希纳定理[22]表明,人眼不可能感知两幅图像间较小的质量差别,只有当质量差别超过一定阈值时人眼才能感知得到。当图像采用较小QP编码时,重建图像与原始图像之间的差别较小,人眼很难感知得到。所以,较小QP编码产生的重建图像感知质量都处于与原始图像感知质量一样的最好等级。当图像采用较大QP编码时,重建图像已经非常模糊,很难提取有用信息,这时不同QP对应的重建图像对应的感知质量等级是一样的,都处于最差等级。
基于以上人眼感知的先验知识可知,数据库中没有必要包含较小或较大QP对应的失真图像,因为它们的感知失真等级是确定的,且增加失真图像也会显著提高后续图像主观观测实验的成本。所以,本文考虑的QP范围为 32~60,采用VTM16.2编码原始图像获得每一个QP对应的失真图像。其他主要编码参数使用配置文件encoder_intra_vtm.cfg中的默认配置,档次为main_10_444_still picture。最终得到的CT-SCID共包含1 595幅失真图像。
1.2 失真图像主观观测实验
本节设计失真图像主观观测实验以获得失真图像的感知质量等级。主观观测实验涉及的关键因素和流程均严格按照ITU-R BT.500-13标准[23]中的规定执行。具体地,实验共包括30名测试者,其中男性17名、女性13名,年龄在20~40岁之间。所有测试者都没有图像质量评价领域的研究经验,且经过检测均具有正常的视力。采用side-by-side方式,将原始图像和对应的失真图像同时显示给测试者,测试者依据平均意见分数(mean opinion score,MOS)五级量表给对应的失真图像质量评级。MOS五级量表是ITU-R BT.500-13标准推荐的且被广泛使用的图像感知质量评级测度,其将图像的感知质量划分为5个等级,并用1~5分表示,分数越高表示图像的感知质量越好。在实验开始前,会首先向测试者说明实验流程和注意事项。在实验过程中,当测试者持续观测时间达到20 min时,强制让测试者休息5 min,以避免视觉疲劳。
通过以上过程可获得每一位测试者给每一幅失真图像打的感知质量分数。但是,受个体差异性等因素的影响,这些数据中可能会存在一些异常值。本文应用3σ准则[24]筛选并剔除异常值。n幅失真图像感知质量分数的均值μn和标准差σn为
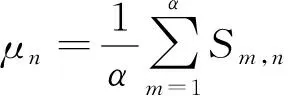
(1)
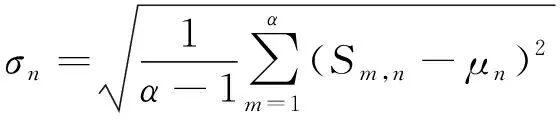
(2)
式中:Sm,n表示第m位测试者对第n幅失真图像打的感知质量分数;α表示测试者数量。当某位测试者对应的感知质量分数处于(μn-3σn,μn+3σn)之外时,则认为其为异常点并将剔除。然后,计算剩余测试者对应的感知质量分数均值,此均值即为第n幅失真图像对应的MOS。
图3为CT-SCID中所有失真图像对应的MOS。可以看出,CT-SCID数据库中失真图像的感知质量等级范围足够广,可用于后续中文TSCI的感知失真研究。

图3 CT-SCID中失真图像的MOS分布Fig.3 MOS distribution of distorted images in CT-SCID
2 中文TSCI VVC编码感知失真类型
汉字作为由特定类型笔画构成的象形文字,其笔画信息对汉字语义的感知具有决定性作用。笔画信息属于图像的高频信息。包含VVC在内的传统基于混合编码框架的编码技术考虑人眼对自然图像高频信息不敏感,通常会使用压缩高频信息的方式实现数据压缩。但是,汉字笔画信息的变化却会对TSCI感知质量产生重要影响。本文研究发现,中文TSCI在经过VVC编码时,随着QP的增加,其对应重建图像中汉字的笔画会发生多种类型变化,对应产生多种类型的感知失真。本节将说明这些感知失真类型及其发展路径。
2.1 感知失真类型分析
2.1.1 笔画模糊
模糊是图像编码导致的一种常见失真。自然图像和屏幕内容图像经过有损编码后都会出现模糊,但是具体的失真感知形式会有不同。图4以“WebPage02”图像中的区域为例,展示汉字对应的笔画模糊失真。图4(a)、(b)分别为原始图像和QP为49时编码得到的失真图像,并将其中的“双”字放大展示。可以看出,原始图像中的“双”字笔画边界比较清晰,易识别其表示的语义,而失真图像中的“双”字笔画边界已经不分明,笔画相对模糊,出现了模糊失真。笔画模糊会增加汉字语义识别的难度。

(a)原始图像
2.1.2 笔画丢失
除了笔画模糊外,TSCI中的汉字还会出现笔画丢失失真。图5以“PDF01”图像中的区域为例,展示了汉字对应的笔画丢失失真。图5(a)、(b)分别为原始图像和QP为46时编码得到的失真图像,并将其中的“借”字放大展示。易看出,原始图像中的“借”字笔画清晰且笔画结构完整,而失真图像中的“借”字虽然笔画较清晰,但第9、10笔顺对应的两个“横”缺失了。笔画丢失显著影响原汉字语义的准确感知,影响中文TSCI的感知质量。

(a)原始图像
2.1.3 笔画增加
与笔画丢失对应,TSCI中的汉字也会出现笔画增加失真。图6以“PPT01”图像中的区域为例,展示了汉字对应的笔画增加失真。图6(a)、(b)分别为原始图像和QP为48时编码得到的失真图像,并将其中的“情”字放大展示。易看出原始图像中的“情”字笔画清晰且笔画结构完整,而失真图像中的“情”字虽然笔画清晰,但其第9笔顺 “横折钩”变为了“横折横”,导致“情”字的下半部分“月”变成了“目”。笔画增加也影响原汉字语义的准确感知,影响中文TSCI的感知质量。

(a)原始图像
2.1.4 字符转换
前面提到的失真类型,即笔画模糊、笔画丢失、笔画增加,通常会影响汉字语义的识别难度,其导致的最严重情况是人眼难以识别汉字。但是,本节涉及的第4种失真,即字符转换,则会导致汉字语义的错误识别,对中文TSCI的感知质量产生严重影响。
当原始TSCI中的汉字经过编码后,汉字的笔画发生了变化,使得变化后的字符转换为了与原始汉字不同的其他汉字,本文将此种特殊失真类型定义为字符转换。图7以“PDF13”图像中的区域为例,展示了字符转换失真。图7(a)、(b)分别为原始图像和QP为45时编码得到的失真图像,并将相应的汉字放大展示。原始图像中的“间”字笔画清晰且笔画结构完整,但其在失真图像中则转换为了“问”字,且“问”字的笔画也相对清晰。可以认为,字符转换是汉字笔画在增加或减少过程中出现的一种特殊情况,即增加或减少笔画后的符号与汉字字库中除原始汉字之外的某一个汉字的笔画结构趋近相同。区别于前3种失真类型,字符转换传递给人眼虚假语义信息,欺骗人眼对于汉字语义的感知,严重影响中文TSCI的感知质量。

(a)原始图像
2.2 感知失真类型变化
原始中文TSCI在使用VTM编码时,随着QP增大,失真图像中汉字的笔画出现各种变化,从而产生前述的各种失真类型。为了便于分析这些失真类型的发展路径,将原始图像中的汉字定义为原始汉字字符(original Chinese character,OCC),将其对应在失真图像中的汉字定义为失真汉字字符(distorted Chinese character,DCC)。表1直观地展示了中文TSCI VVC编码感知失真类型随QP增大的发展路径。图8给出了两个汉字形象的代表性示例。下面结合表1、图8进行说明。

表1 感知失真类型随QP增大的发展路径Table 1 Perceptual distortion type development path with increasing QP

图8 “WebPage03”图像中的“前”和“这”感知失真类型发展路径Fig.8 Perceptual distortion types development path on “前” and “这” in “WebPage03” image
第1阶段:笔画感知无变化。当QP较小时,图像高频信息损失较少。通过韦伯-费希纳定理可知,人眼很难感知到笔画信息的微小变化,主观上可认为DCC和OCC是一样的。
第2阶段:笔画模糊,笔画丢失,笔画增加,字符转换。当编码QP继续增大到一定程度时,其引起的笔画变化已经达到人眼感知的阈值。此时,DCC对应产生笔画模糊、笔画丢失、笔画增加、字符转换等失真。在本阶段存在两个重要感知现象:①定义第1个感知现象为空域耦合失真效应,即任一QP对应的某一个DCC有可能呈现出一种失真类型,也有可能同时呈现出多种失真类型;②定义第2个感知现象为时域耦合失真效应,即随着QP增大,任一DCC可能会出现笔画模糊、笔画丢失、笔画增加、字符转换中的任意几个失真类型,而不是所有的失真类型都会出现。以上两个感知现象见图8。
第3阶段:字符模糊。当编码QP继续增加时,图像高频信息损失严重,DCC的笔画信息严重模糊。
第4阶段:字符消失。当QP取值很大时,图像高频信息几乎全部损失,DCC对应的区域已经没有任何笔画信息。字符模糊和字符消失可以认为是笔画模糊的极端情况。
下面以图8为例直观地说明感知失真的变化路径。对于“WebPage03”图像中的“前”和“这”两个字,当QP较小(为40)时,DCC对应着第一个阶段,即笔画无变化阶段。随着QP增大,“前”和“这”对应的DCC先后进入第二个阶段。QP为46时,“这”对应的DCC同时出现了笔画模糊和字符转换两种失真,此即空域耦合失真效应。“前”对应的DCC先后出现了笔画丢失、笔画增加和笔画模糊,未出现字符转换失真,此即时域耦合失真效应。当QP继续增大到很大时,“前”和“这”对应的DCC先后进入字符模糊和字符消失阶段。
3 中文文本屏幕内容图像VVC编码感知失真影响因素
前一节已经说明了中文TSCI VVC编码失真类型及其随着QP增大的变化趋势。从信号处理的角度看,中文TSCI编码过程可以抽象为信源—技术—信宿的信号处理一般模型。中文TSCI是原始信源,其以像素域形式表达图像中的信息。编码器是信息处理技术,通过预测、变换、量化和熵编码等子技术达到数据压缩的目的。编码后的码流是信宿端接收和存储的数据,以压缩域形式表示图像中的信息。结合以上分析易得出以下结论:①在实际应用中,中文TSCI的编码感知失真通常在信宿端出现;②信宿端出现的编码感知失真肯定会同时受信源和编码技术的显著影响。VVC编码技术对TSCI感知失真的影响主要体现为QP的影响,这部分在第1.1节和第2节已经分析。本节将从信源的角度分析影响中文TSCI VVC编码感知失真程度的重要因素。这些因素具体包括字体大小和文本对比度。
3.1 字体大小
字体大小是汉字的一个重要属性。定义中文TSCI的字体大小P为
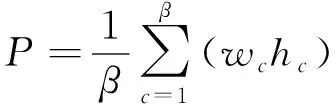
(3)
式中:wc、hc分别表示图像中第c个字符的宽度和高度;β表示图像中字符的数量。在计算P之前采用投影分割法对图像中汉字进行分割[25],从而得到每个字符。
图9(a)~(c)分别给出了P=578,401,245时对应的3幅原始中文TSCI。对3幅图像使用VTM16.2编码,QP设置为49。得到的重建失真图像分别如图9(d)~(f)所示。原始图像及失真图像对应的SI数据也给出,以客观反映图像的纹理复杂度。由图9易知,字体大小显著影响中文TSCI 编码重建图像的感知质量,且字体越小图像的感知质量等级越低。VVC标准采用基于预测、变换、量化和熵编码的混合编码框架。原始图像首先经过帧内预测技术去除图像中的空域冗余。帧内预测后的残差值是后续变换量化的输入。变换在去除一部分空域冗余的同时也使得能量更加集中。变换后的变换系数经过量化模块完成多对一的映射,显著减小了信息的取值区间。量化后的量化系数再经过熵编码,进一步去除熵冗余,最终达到数据压缩的目的。

(a)原始图像, P=578, SI为0.363
理论上,帧内预测技术是无损的,且单独使用该技术无法实现数据压缩,但是其对于提升后续变换、量化和熵编码等模块的效率至关重要。通常,图像纹理越复杂,临近像素间的相关性就越弱,帧内预测技术找到的最优预测值与当前编码像素之间的差别就越大,即预测残差就越大。如图9(a)~(c)所示,图像中的字体越小,即单位面积上的笔画越密,图像的纹理就越复杂,其对应的SI也就越大。所以,字体越小的图像对应的预测残差值也就更大。图10给出了图9(a)~(c) 3幅原始图像在使用VTM16.2、QP为49编码时得到的帧内预测残差值分布。可以看出,字体越小的图像,预测残差值接近0的像素越少,即其对应的预测残差值相对偏大。进一步地,VVC采用的离散余弦变换、离散正弦变换等变换技术,理论上是无损的,且满足能量守恒定律。所以,基于量化多对一的映射原理,在同等QP下,更大的预测残差易导致更大的量化失真。VVC采用的基于上下文的自适应二进制算术编码(context-based adaptive binary arithmetic coding,CABAC)等熵编码技术同样是无损的,所以更大的量化失真最终会导致重建图像中的失真更大,图像质量更差。
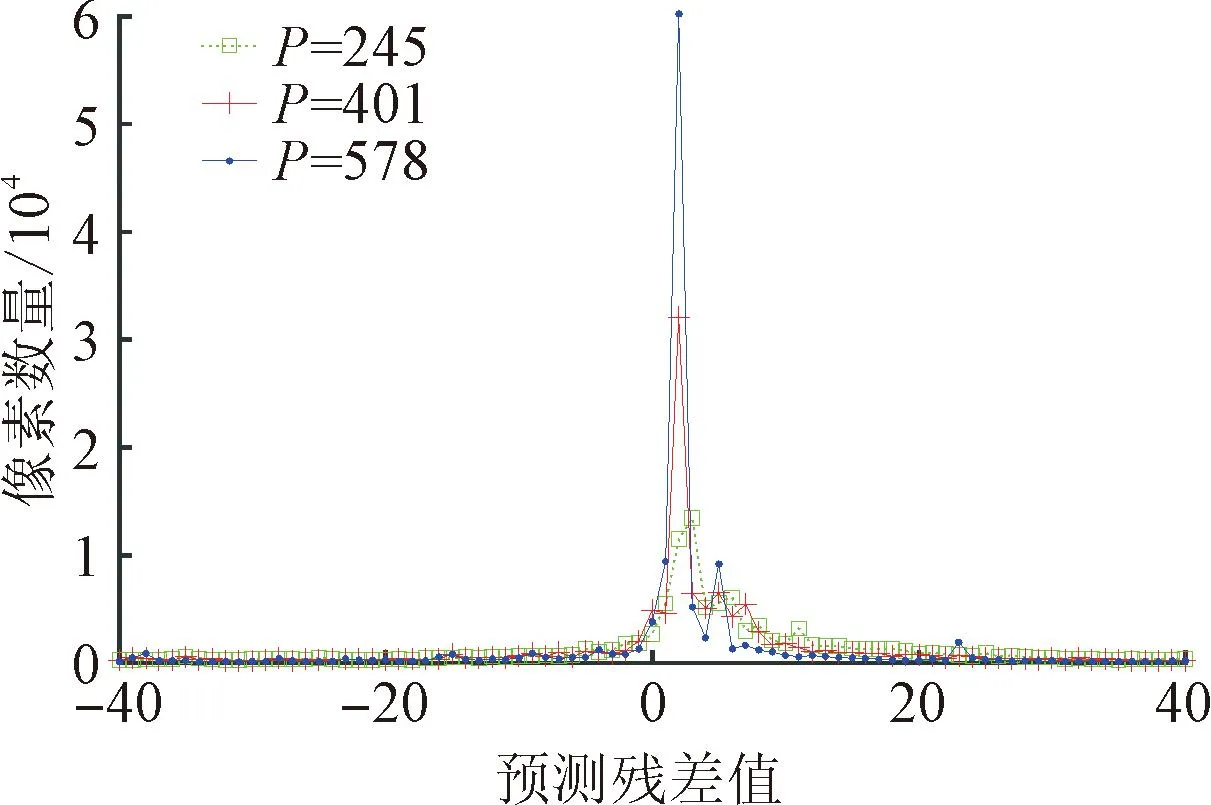
图10 不同字体大小中文TSCI对应的帧内预测残差分布Fig.10 Distribution of intra prediction residuals for Chinese TSCI with different font sizes
当前,屏幕内容图像的质量评价是一个研究热点,一些高水平方法被相继提出。本文复现了一些代表性方法,包括ESIM[2]、GFM[26]、GSIM[27]、GSS[28]、MDOGS[29]、MSEA[30]。图11为12幅测试图像,是由VTM16.2在QP为49时编码获得地,P取值范围为886~204。图12为不同的质量评价方法对12幅测试图像的测试结果。除了上述6种针对屏幕内容图像设计的质量评价方法,也给出了图像质量评价领域应用最广泛的两个传统质量评价测度PSNR、SSIM[31]的评价结果和MOS值。特别地,GSS对应的分数越高说明图像质量越差,而其他方法对应的分数越高说明图像质量越好。

(a)P=886
对比图11和12,可以从宏观整体和微观细节两个角度得到以下结论:①在同样QP下,随着字体变小,失真图像的质量在宏观整体上呈下降趋势,图12复现的所有评价方法都能描述这一整体变化趋势;②对于字体接近的一些图像,其图像差别较少且不影响文本语义的感知,基于韦伯-费希纳定理和文本感知的特点,大部分测试者认为这些图像的感知质量是一样的。但是,当前大部分质量评价方法很难准确描述这一微观差别。例如,图11(a)、(b)两幅图像感知质量明显是一样的,但图12中大部分测度认为这两幅图像的质量是不一样的,PNSN、GSS和 MSEA得出的分数差别甚至还较大。综上,本文认为有必要针对中文TSCI的失真特性研究针对性的更加有效的质量评价方法,且需要考虑字体大小的影响。
3.2 文本对比度
文本对比度是影响中文TSCI编码失真程度的另一个重要属性。应用中文TSCI的文本对比度D为
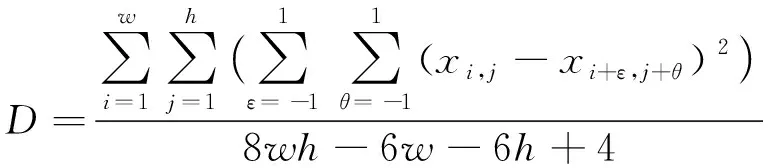
(4)
式中:xi,j表示图像第i行第j列的像素值;w、h分别表示图像的宽度和高度。
图13(a)~(c)分别展示了D=3 542,1 704,757时对应的3幅原始中文TSCI。对这3幅图像分别使用VTM16.2编码,QP为46,得到如图13(d)~(f)所示的重建失真图像。结合图像的SI数据可以看出,在对比度变化影响下,SI仍然可以有效衡量中文TSCI的纹理复杂度,例如图13(a)~(c)包含的文字相同,其对应的SI取值也一样。由图13易看出,文本对比度显著影响中文TSCI 编码重建图像的感知质量,且对比度越小图像的感知质量等级越低。

(a)原始图像, D=3 542, SI为0.379
中文TSCI可以划分为前景汉字和背景两部分。并且,相比于自然图像等其他内容,汉字在内容特性上具有以下显著特点:汉字笔画的亮度或颜色相对单一,甚至经常出现一种亮度或颜色的情况。所以,汉字笔画区域上的像素相关性较强。使用帧内预测编码汉字笔画上的像素时,如果参考像素也来源于笔画上的其他像素,则理论上其预测效率会较高,对应的预测残差值较小。但是,如图13(a)~(c)所示,当图像文本对比度变小时,文字笔画像素取值与背景像素取值越接近。背景像素对笔画像素最优帧内预测参考值选择的干扰增大,笔画像素对应预测残差值变大的概率也会增大。图14给出了图13(a)~(c)3幅原始图像在使用VTM16.2、QP为46编码时得到的帧内预测残差值分布。可以看出,文本对比度越小的图像,预测残差值接近0的像素越少,即其对应的预测残差值相对偏大。如第3.1节分析,在同等QP下,更大的预测残差易导致更大的量化失真。更大的量化失真会导致重建图像中失真更大,图像质量更差。
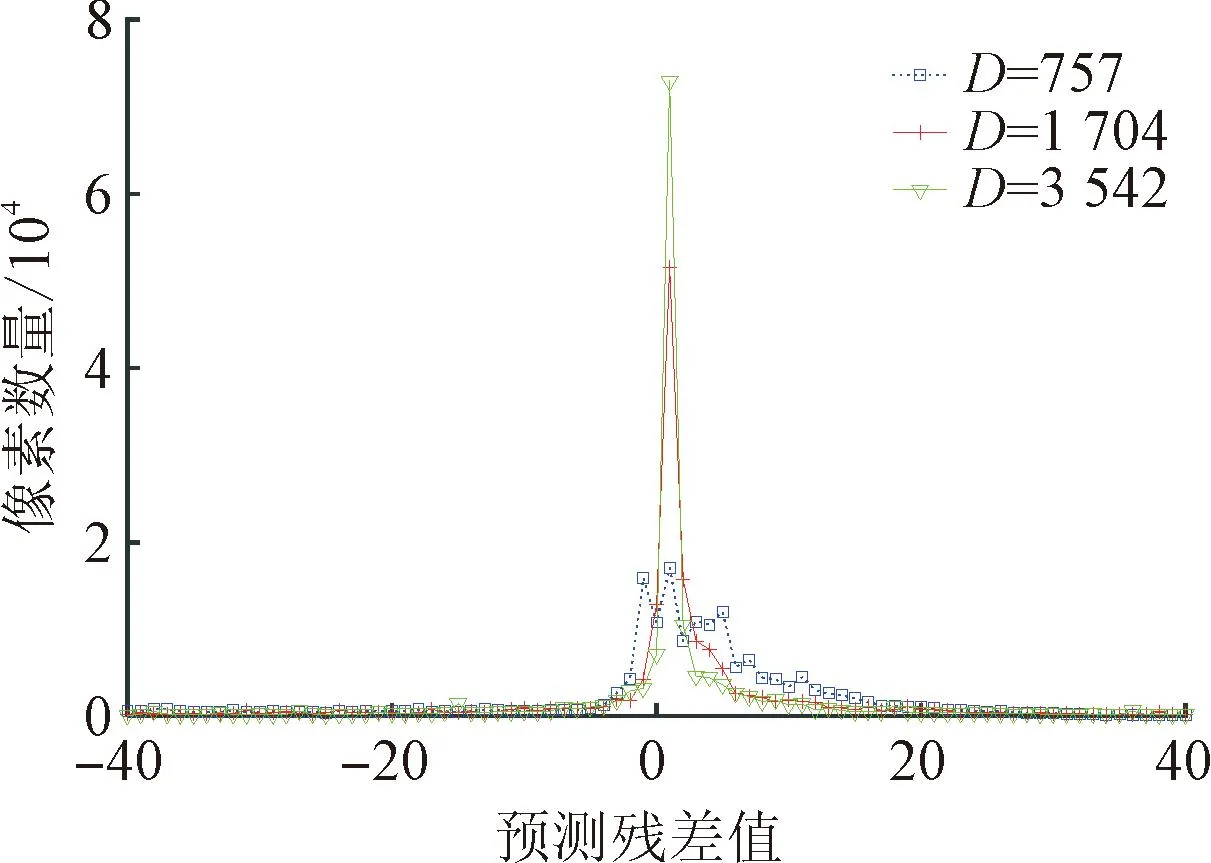
图14 不同文本对比度中文TSCI对应的帧内预测残差分布Fig.14 Distribution of intra prediction residuals for Chinese TSCI with different text contrasts
图15为12幅测试图像,由VTM16.2在QP为46时编码获得,D取值范围为4 937~757,对应现实中常见的文本对比度。图16为不同的质量评价方法对应的测试图像的质量评价结果。

(a)D=4 937

(a)MOS
对比图15和16可以得到以下结论:①在同样QP下,随着文本对比度变小,失真图像的质量在宏观整体上呈下降趋势,而图16显示,除PSNR外的所有方法都能描述这一整体变化趋势。图15(a)的感知质量显著好于图15(l)的感知质量,但是图15(a)的PSNR值反而比图15(l)的PSNR值低,这显然是错误的评价结果。②对于文本对比度引起的失真,人眼通常更关注文本的清晰度是否影响文本语义的准确感知,而忽略背景对比度的变化[3]。当前的大部分质量评价方法很难准确描述对比度变化对中文TSCI感知质量的影响。例如,图15(a)、(b)所示的两幅图像的差别很小,大部分测试者认为其感知质量是一样的,但是图16的所有质量评价方法得出的这两幅图像对应的质量分数显示两幅图像的质量均有差别,与人眼感知结果不符,甚至一些方法对应的质量分数差别较大,例如GSIM、MSEA。综上所述可知,有必要针对中文TSCI的失真特性研究针对性的更加有效的质量评价方法,且需要考虑文本对比度的影响。
4 结 论
本文聚焦中文TSCT图像的感知失真,基于构建的中文文本屏幕内容图像数据库,分析了中文TSCI的感知失真类型和发展路径。在此基础上,结合VVC混合编码架构原理对影响感知失真程度的因素进行了分析,对比了中文TSCI在经过VVC编码后,当前代表性的屏幕内容图像质量评价方法的失真性能表现,得到如下结论:
(1)作为由特殊笔画构成的象形文字,中文TSCI VVC编码感知失真可以从笔画变化的角度将失真类型进行有效分类,并分为笔画模糊、笔画丢失、笔画增加和字符变换4种类型;
(2)字符变换作为汉字编码时出现的一类特殊的失真类型,会传递错误的语义信息,欺骗人眼感知;
(3)随着QP由小到大变化,中文TSCI VVC编码感知失真类型的变化路径分为4个阶段,并在第二个阶段呈现空域和时域耦合失真效应;
(4)字体大小和文本对比度是影响中文TSCI VVC编码失真程度的关键因素,且字体越小或文本对比度越低,则对应失真图像的感知质量等级越低;
(5)当前提出的大部分质量评价方法,能够宏观整体地描述中文TSCI VVC编码失真图像的质量,但在微观细节上还存在提升空间,需要针对中文TSCI VVC编码失真图像研究更加有效的质量评价方法,且需要考虑字体大小与文本对比度的影响。
后续有价值的研究方向包括:适用于中文TSCI VVC编码失真图像的质量评价方法,优化中文TSCI 感知率失真性能的VVC高效编码方法等。
