基于USB PD 3.0协议的新型双相标记解码电路设计与验证
2024-03-31史轶男赵宏亮尹飞飞
史轶男, 赵宏亮, 尹飞飞
(辽宁大学 物理学院,辽宁 沈阳 110036)
随着智能手机的应用,人们对充电效率的要求不断提高,各种快充协议芯片应运而生[1]。为了统一规范,USB-IF协会定义了基于双相标记编码解码电路的USB Power Delivery 3.0协议[2]。
双相标记编解码是PD协议的核心模块,使单线传输的波形中既包含时钟信息也包含真实数据[3-4],由于信号在传输过程中可能受到干扰产生突变,近年来研究人员提出一些优化方案[5-7]。文献[5]采用计边沿个数的方法确定64 bit前导码,再利用前导码总的计数值求平均获得解码阈值,该方法计算复杂,无法发现错码,没有错误恢复机制;文献[6]采用前34 bit的前导码,即初始2 bit加上4组8 bit的计数值求平均的方法获得解码阈值,该方法易出现解码错误。文献[5-6]只能解码(300±75) kHz频率的数据,解码范围比较小,并且计算复杂,使电路的面积大,功耗高;文献[7]利用有限长单位冲激响应滤波器计算解码阈值,但计算精度较低,解码范围小,准确性较差,且没有错误检测和前导码分辨机制,功能不全面,功耗也比较大。
本文提出的设计能够弥补上述不足,解码模块增加6阶有限长单位冲激响应滤波器,设定全面的前导码预测机制、错误恢复机制。电路采用状态机实现功能,且整个电路复用一个计数器,节省了面积和功耗;并增加了门控,在空闲时关闭解码电路,节约能耗。增大信号的解码频率范围,支持相邻13个数据的传输周期连续变化7.13%。与其他参考文献比较,解码能力更强,电路结构更简单,面积显著减小,功耗大幅降低,能有效降低成本。
1 传统双相标记解码系统的设计
双相标记编解码的规则是首先设定每一个数据的持续时间为一个单位时间长度,简称1个UI。在每个UI的开始,先将电平翻转,在每一个UI的中间处,若电平翻转,则数据代表1;否则代表0[7]。规定前导码始终为1、0交替发送。

表1 性能对比
文献[5]的解码阈值计算方式如下:利用前导码是1、 0交替的规则,所有前导码的数据边沿数量是固定值,可以通过当前收到输入信号的边沿个数确定是否为前导码。对64 bit的前导码过采样,得到的总计数值除以64,乘以3/4,即可得到 3/4 UI的计数值作为解码阈值,然后解码后面真实的数据。
文献[5]通过数边沿的方式确定前导码的范围,如果前导码出现错码、漏码,那么就会把真实的数据当作前导码,从而会发生解码错误。由于没有错误检测机制,解码错误也无法及时发现;再加上计算量较大,整个电路面积很大,功耗很高。
文献[6]的解码阈值计算方式如下:前导码最初始2 bit为一组,判断先发0还是先发1,后面以检测到12个边沿即8 bit数据为一组,每一组与前面的解码阈值求平均值作为新的解码阈值,共求5次。以第1次的解码阈值为例,如果前2 bit的计数值为C2 bit,第1次的8 bit计数值为CFirst-8 bit,那么解码阈值的计算公式为:
(1)
解码只对3/4 UI过采样,有翻转则为1;无翻转则为0,剩余1/4 UI不采样。采用式(1)得到的解码阈值解出第2个8 bit,并将第2个8 bit的计数值和前面的值求平均,更新解码阈值。此后的每8 bit数据的解码和解码阈值的更新以此类推,直到接收到34 bit前导码后,解码阈值固定不变。
文献[6]的解码阈值来自每8 bit一组求得的平均值,解码范围为(300±75) kHz。但如果数据的周期在此范围内不是固定值,而是变化的,那么就可能会出现解码错误。如在18 MHz的采样频率下,若某一时刻求得解码阈值为49(频率367 kHz),此时实际能解码的数据对应的解码阈值范围为49.00±12.25(频率290~458 kHz)。当新的数据频率为225~290 kHz,将会错误地认为解码失败,放弃解码,并将电路复位。
文献[7]的解码阈值计算方式如下:首先利用有限长单位冲激响应滤波器使解码阈值随每个UI的长度变化而变化。每收到1 UI数据,根据计数值与解码阈值的关系,得到解码值为1或0,并更新解码阈值;然后在解码模块内设置状态机,通过状态机跳转实现解码。文献[7]的解码模块状态转换图如图1所示。
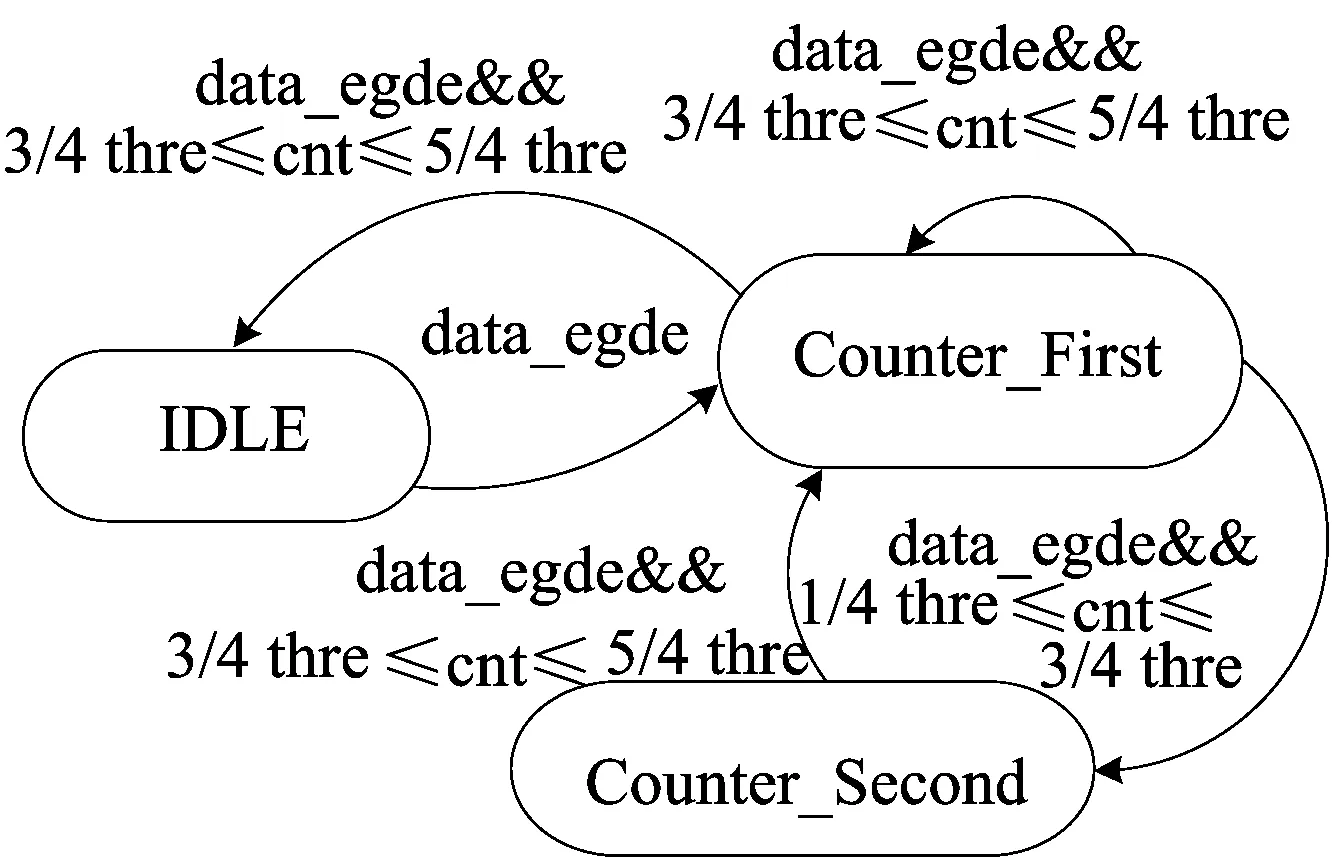
图1 文献[7]的解码模块状态转换
若空闲状态IDLF下检测到边沿,则会跳转到Counter-First状态,此状态下检测到边沿时,如果计数值cnt 的值处于解码阈值的3/4~5/4 thre之间,那么解码值为0;如果cnt的值处于1/4~ 3/4 thre之间,那么跳转到Counter-Second,继续计数。在Counter-Second下有边沿时,如果cnt值处于3/4~5/4 thre之间,那么解码值为1。
文献[7] 解码阈值计算方式缺点如下:① 解码阈值的计算精度较低,只能对周期以6.25%增加的连续10位解码;② 没有错误检测机制,若出现错码、漏码,则把一连串错误的解码结果输出;③ 没有PD协议必需的前导码检测机制,无法分辨真实数据,将增加其他模块的负担,不利于各个模块的协同工作,且前导码错误依然继续解码,产生不必要的功耗。
2 新型双相标记解码系统的设计
新型的解码电路模块结构如图2所示,该结构包含滤波模块、解码模块、预期模块、输出模块。

图2 新型的双相标记解码电路模块结构
解码电路设计流程如图3所示。
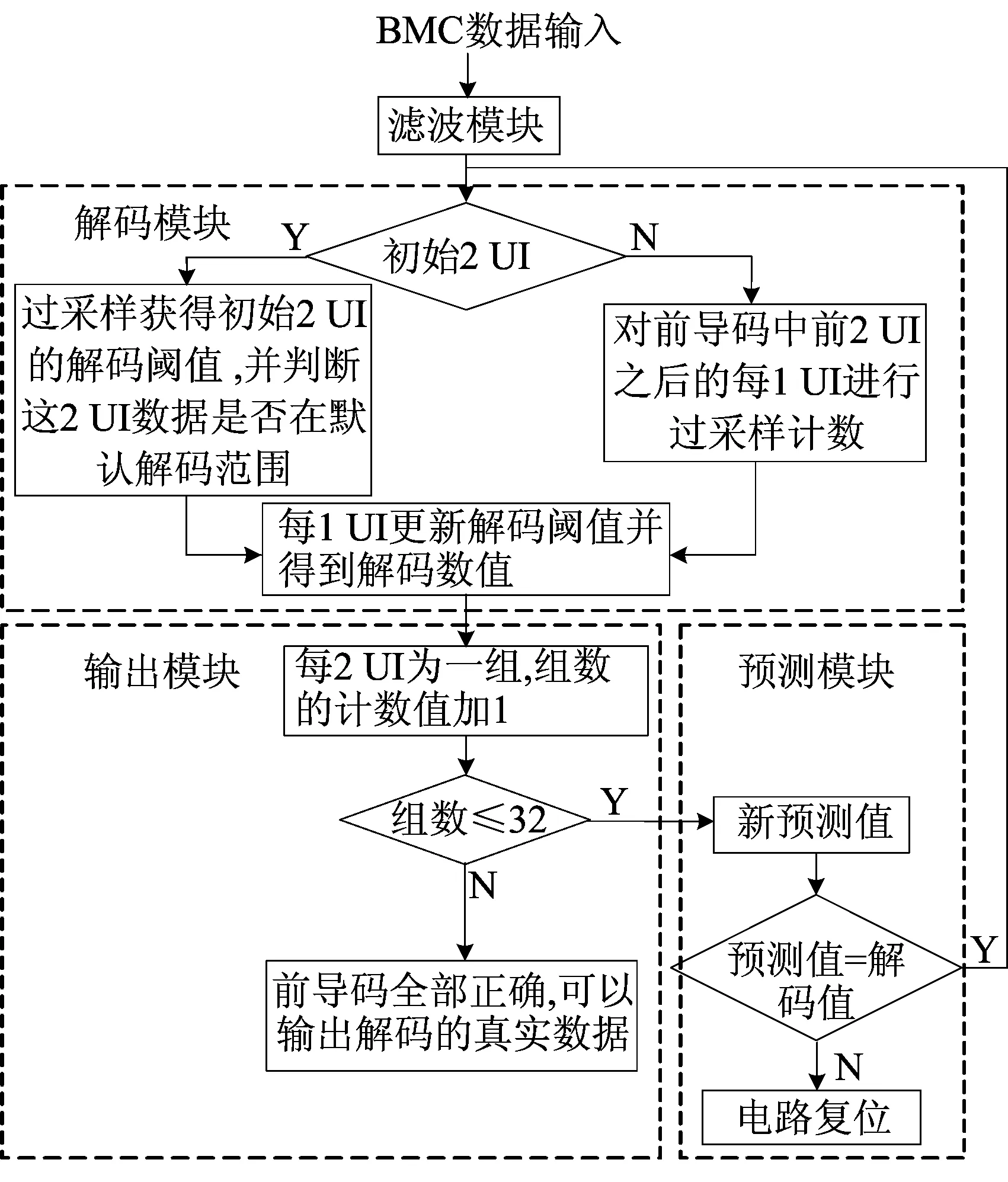
图3 新型的双相标记解码电路设计流程图
1) 输入数据BMC-data经过滤波模块去掉3 MHz频率以上毛刺。
2) 解码模块需要对信号过采样,利用采样的计数值获得解码阈值。必须首先确定最初始的2 UI数据是在默认的(300±75) kHz解码频率范围之内,否则不会接收后面的数据。解码模块在解码过程中,每收到1 UI数据,若计数值在1/4~3/4解码阈值之间,则解码为1;若计数值在3/4~5/4解码阈值之间,则解码为0。每一个UI解出新的解码数值,同时将新的1 UI计数值加入解码阈值的计算中,更新一次新的解码阈值。
3) 因为在前导码阶段,数据的发送顺序是固定的,所以预期模块能够根据当前数据预期到下一个数据是什么。利用解码阈值在输出模块对数据解码。以每2 UI为一组进行计数,前32组数代表64个1、0交替的前导码。在前导码阶段需要比较每个解码值是否与预期值相等,如果相等,那么继续解码;否则电路复位,等到新的数据来临,整个解码过程再重新开始。
经过上述步骤后,如果确定前导码接收完毕且没有错误,那么开始对真实数据解码,只有真实数据解码结果会从输出模块输出。
新型设计利用状态机来进行解码和预测模块的工作以及错误状况的检验。增加3个状态寄存器控制计数器的复用,减少更多计数器的寄存器数量。解码模块状态转换如图4所示。每2 bit数据作为一组,状态机分5个状态,其中:IDLE为空闲状态; First-1 bit-front、First-1 bit-behind状态判断前1个数,Second-1 bit-front、Second-1 bit-behind判断后1个数,然后每2个数循环1次。
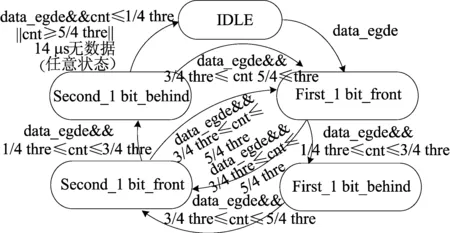
图4 解码模块状态转换
具体的状态跳转如下:IDLE时检验到边沿,进入First-1 bit-front;First-1 bit-front、Second-1 bit-front判断收到新的1 UI及中间有无翻转,有翻转则分别跳到First-1 bit-behind、Second-1 bit-behind,解码为1;无翻转则分别跳到Second-1 bit-front、First-1 bit-front,解码为0。如果在任意时刻出现了解码错误或线上空闲超时,那么状态机将会重新回到空闲状态。
新型设计的双相标记解码模块电路如图5所示,图5中BMC-data-filtered为滤除毛刺后的输入信号。
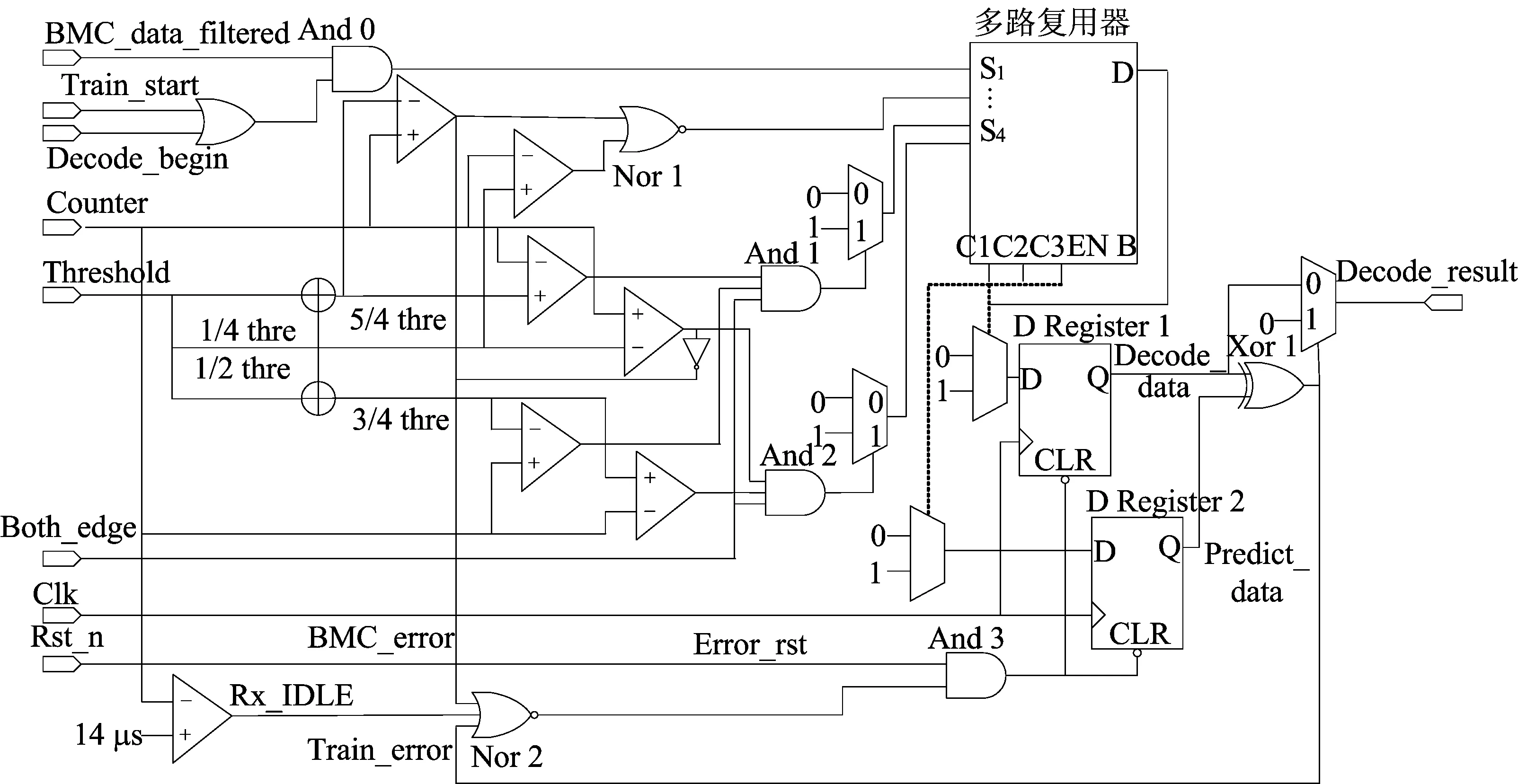
图5 解码模块电路图
在前导码阶段,训练时钟标志Train-start为高,在真实数据解码阶段,Decode-begin为高。将每1 UI的计数值Counter进行移位相加等操作得到1/4、3/4、5/4 thre。多路复用器用于判断状态跳转和解码结果。若IDLE时检验到边沿,则进入First-1 bit-front。First-1 bit-front状态下,当新1 UI的Counter小于1/4或大于5/4 thre,Nor 1输出为1,解码错误,状态寄存器将回到IDLE状态,解码结果寄存器D Register 1保持为0;处于1/4~3/4 thre之间,D Register 1为1;处于3/4~5/4 thre之间,D Register 1为0。
解码过程中有如下3种错误检测机制。
1) 前导码丢码、错码。D Register 2为预测值Predict-data的寄存器,根据状态跳转,每当收到1个前导码,产生1个预测值。当前导码的解码值Decode-data与Predict-data不相等,则Xor 1输出1,Train-error为1;若相等,则Xor 1输出0,Train-error为0。
2) 输入信号频率超出解码范围。如某1 UI计数值大于5/4 thre或小于1/4 thre,信号BMC-error拉高。
3) 当14 μs内无电平翻转即无数据输入,拉高空闲超时标志Rx-IDLE信号。Train-error、BMC-error、Rx-IDLE任一为1,则Nor 2输出为0,Error-rst为0,And 3输出0,电路复位。最终输出结果Decode-result为0;否则,Error-rst为1,And 3输出1,电路正常工作,输出结果Decode-result即为解码值Decode-data。
在新型的解码系统中,解码阈值为1 UI的计数值,新型双相标记编解码规则如图6所示。如果计数器的值在1/4~3/4解码阈值之间检测到边沿,那么解出的码为1;如果在3/4~5/4解码阈值之间检测到边沿,那么解出的码为0。其余情况表示解码错误。
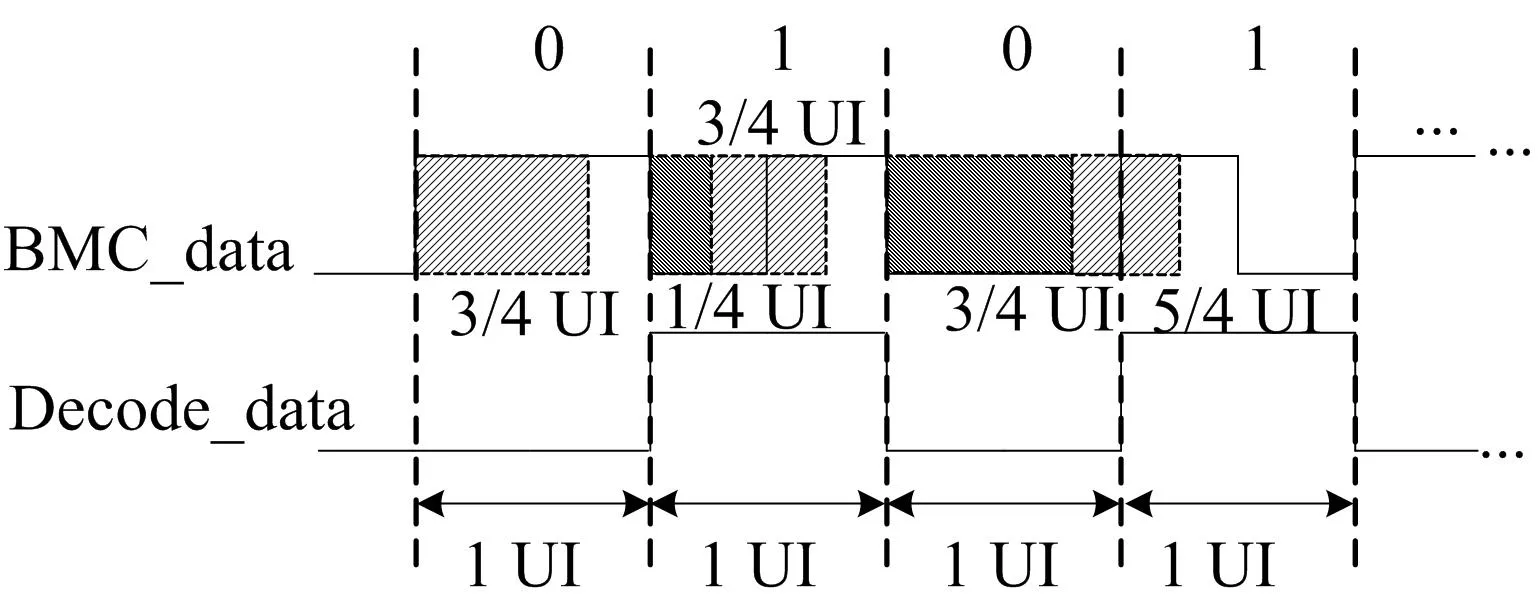
图6 新型双相标记编解码规则
本文的设计为解码模块增加了六阶有限长单位冲激响应滤波器,利用滑动平均计算获得解码阈值。有限长单位冲激响应滤波器的计算公式为:
(2)
其中:N为滤波器的级数;a(k)为系数;x(n-k)为每一级计算时该项的取值[8]。
有限长单位冲激响应滤波器结构如图7所示。图7中:x(n)为输入,对应电路中每一个UI的计数值;z-1为对数据做一阶滤波;y(n)为滤波后的最终输出,对应解码阈值。本设计中的六阶有限长单位冲激响应滤波器对应的抽头系数a(k)分别为1/2、1/4、1/8、1/16、1/16。
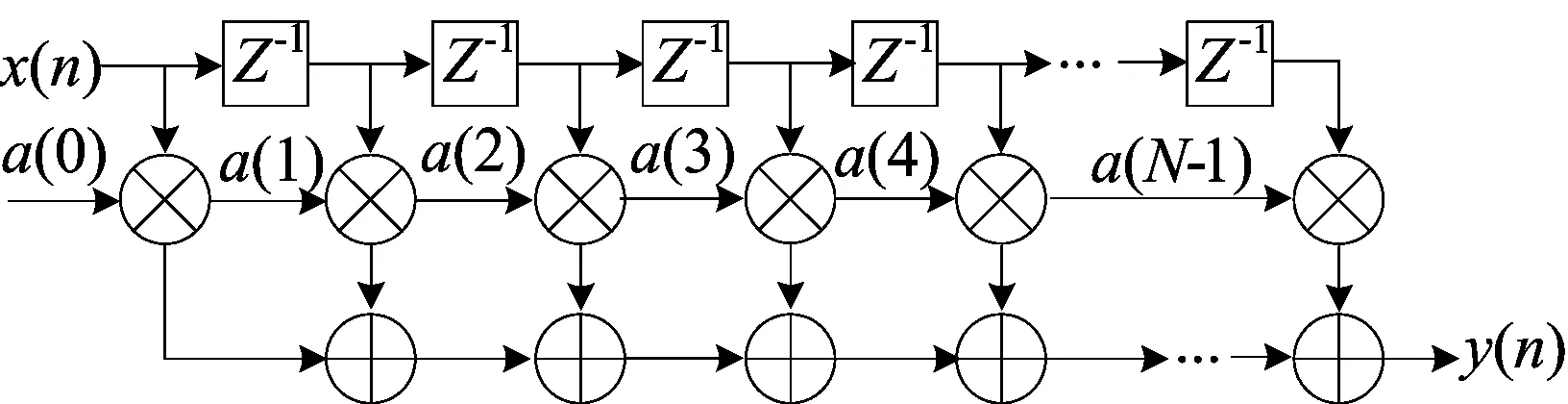
图7 有限长单位冲激响应滤波器结构
新型设计的解码阈值计算公式为:
(3)
其中,CCnt-1 UI为一个UI的计数值,连续5次的计数值与抽头系数的乘积和等于实时解码阈值。
新型的双相标记解码系统中,因为用状态机来控制一个计数器的复用,所以计数器的最大计数值更小,解码电路需要的寄存器数量也减少了很多,面积因而可以大幅减小。另外,因为采用更准确的解码阈值计算方式,所以使用频率更低的过采样时钟。同时还增加错误检测机制,当电路出现错误时不再解码。以上这些设计也使功耗大幅减小。
3 新型解码系统的仿真验证
新型双相标记解码系统能够成功对周期连续增大7.13%的13个输入数据进行解码,仿真结果如图8所示。输入信号BMC-data频率由300 kHz逐渐减小,每1 UI的计数值Counter由30逐渐增大到68,解码阈值thres-1 UI随之由27最终到60不断更新,到标识4处成功解码了13个数据。
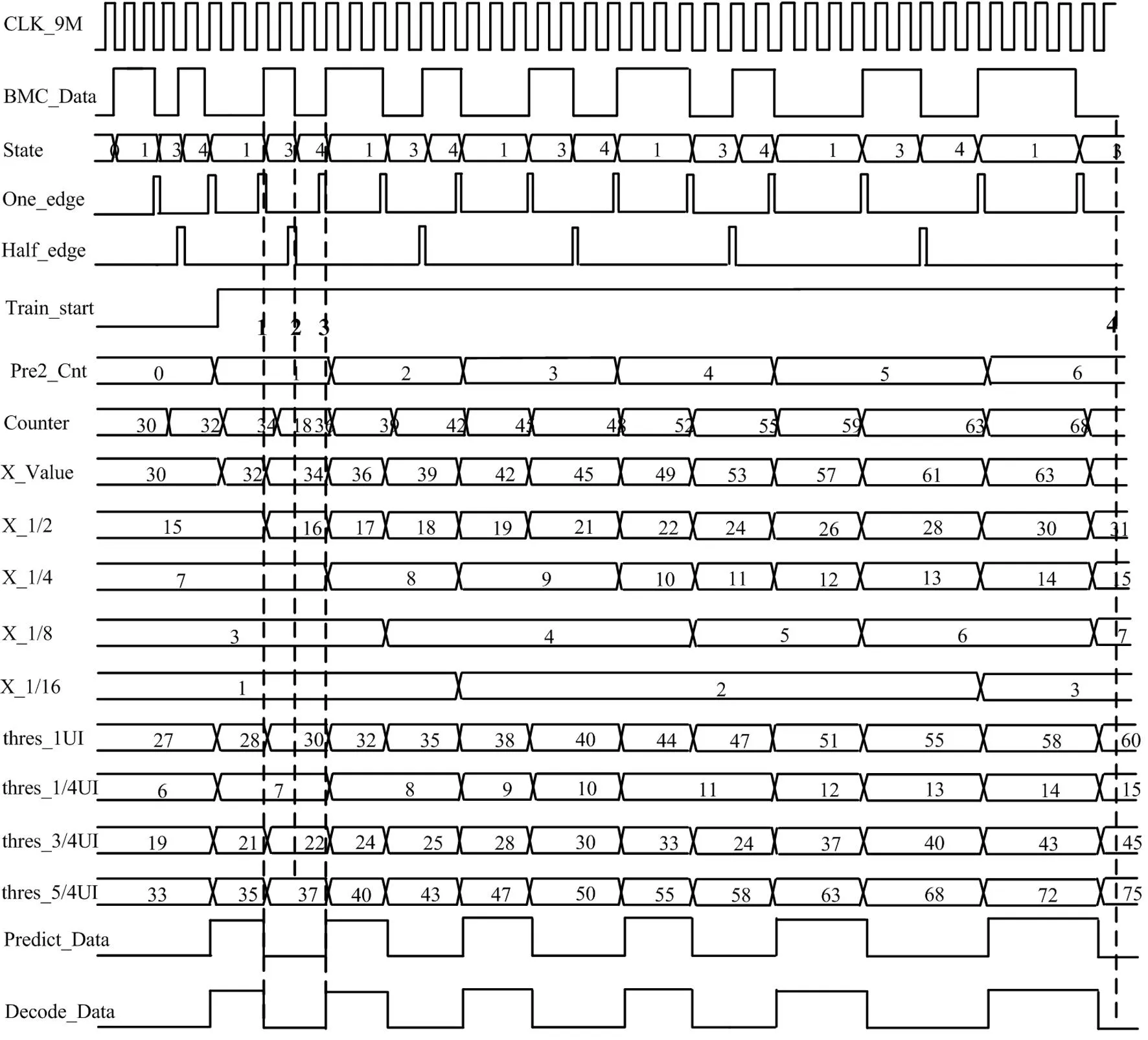
图8 新型双相标记解码系统的仿真结果
具体解码过程如下:用9 MHz的时钟信号CLK-9M对输入信号BMC-data过采样[9]。State为解码过程中的状态机,在实际的电路设计代码编写中,分别使用数字0代表IDLE空闲状态,1代表First-1 bit-front状态,2代表First-1 bit-behind状态,3代表Second-1 bit-front状态,4代表Second-1 bit-behind状态(与图4对应)。图8标识线1处,每当输入信号传输完1 UI电平翻转,则One-edge产生一个脉冲信号,将1 UI的计数值存储到X-Value中。将信号X-Value的连续5个值的1/2、1/4、1/8、1/16、1/16移位相加,得到新的thres-1 UI为30,再进行移位或相加得到thres-1/4 UI为7,thres-3/4 UI为22,thres-5/4 UI为37。Counter此时为34,处于thres-3/4 UI与thres-5/4 UI之间,则解码结果Decode-Data为0。然后计数器清零,状态机从1跳转到3。图8标识线2处,每当传输1 UI的中间有电平翻转,则Half-edge产生一个脉冲,Counter为18,处于thres-1/4 UI与thres-3/4 UI之间,计数器继续计数,状态机由3跳转到4。图8标识线3处,传输1 UI有电平翻转,One-edge产生一个脉冲,Counter为36,处于thres-3/4 UI与thres-5/4 UI之间,解码结果Decode-Data为1。然后计数器清零,状态机由4跳转到1。前导码的初始2个UI接收后拉高Train-start信号,每成功接收2个UI,Pre2-Cnt计数值加1,直到接收全部32组。在此期间Decode-Data必须始终与预测值Predict-Data相等,即所有前导码全部正确,才会继续解码后的真实数据,并将解码结果输出到解码模块之外。
在Synopsys公司的DC平台用华虹0.18 μm工艺对电路面积和功耗评估,相同工艺性能结果比较见表1所列。
由表1可知:本文设计比文献[5]面积减小57.44%,功耗降低93.19%;也比文献[6]面积减小56.51%,功耗降低93.06%;比文献[7]面积大1.81%,功耗降低36.28%,且解码的范围更大,准确性更高。
4 结 论
本文通过对双相标记解码电路增加状态机以及计数器的复用,减少寄存器的使用,从而降低面积和功耗;通过增加六阶有限长单位冲激响应滤波器实时计算解码阈值,可解码的频率范围更大,提高解码准确性;通过设置错误检测机制提高电路的安全性。并增加了门控,在电路闲置时,关闭解码电路,进一步节约能耗。采用Synopsys公司的数字前端仿真工具VCS进行电路的仿真验证,成功对单个周期突变 25%的数据、相邻周期增加或减少7.13%的连续13个数据解码。电路仿真后得到更好的面积和功耗表现。在USBPD 3.0协议芯片中使用可以提高对信号的解码能力,降低芯片的成本。
