基于深度学习的有锚框行人检测方法综述
2024-03-28章博闻
章博闻
重庆交通大学 机电与车辆工程学院,重庆 400074
0 引言
行人检测(Pedestrian Detection)是指利用计算机视觉技术判断图像或者视频序列中是否存在行人并给予精确定位,被广泛应用于智能驾驶、智慧交通、智能机器人等领域。基于锚框的目标检测算法有着检测精度高、提取特征能力强等特点,因此一直是目标检测领域的研究热点。有锚框的行人检测算法按照是否需要生成区域候选框可以分为两阶段(two-stage)和单阶段(one-stage)。本文介绍了传统的行人检测方法,重点阐述了基于有锚框的行人检测算法在面对小尺度行人和遮挡行人等检测问题上的研究进展。
1 传统的行人检测算法
传统的行人检测算法主要是依靠人工设计的特征算子来提取特征,再将提取后的特征传入分类器,得到最终的检测结果,即特征提取+分类器模式。VIOLA P 和JONES M[1]提出了Viola-Jones 检测器用于人脸检测,Viola-Jones 检测器主要由Haar-like 特征、Adaboost 分类器和Cascade 级联分类器组成。DALAL N 等人[2]提出方向梯度直方图(Histogram of Oriented Gradients,HOG),HOG 算法主要利用光强梯度或边缘方向的分布能够对图片中物体外形进行描述的原理,但是难以应对有遮挡或者人体姿态变化较大的情况。FELZENSZWALB P F 等人[3]在HOG 的基础上,采用多组件的策略,提出可变形的组件模组(Deformable Part Model,DPM),DPM 对目标的形变具有很强的鲁棒性。由于传统的行人检测算法大多是采用滑动窗口来一一筛选,所以效率低下,同时,人工设置的特征提取算子会使准确性和鲁棒性都得不到保证,在复杂场景下,准确率会大大降低。深度学习的迅猛发展为目标检测带来了转机,与传统检测方法相比,通过让网络自己学会如何提取特征,取代人工设置的特征提取器,充分学习图片中的特征,使网络检测目标的性能大幅度提高。
2 两阶段行人检测方法
两阶段的目标检测算法主要分为两步,即先从原始图片或者特征图产生可能包含物体的候选框,再对候选框中的特征进行分类回归。基于锚框的两阶段目标检测算法有Faster R-CNN[4]、Cascade R-CNN[5]等。
2.1 R-CNN
GIRSHICK R[6]提出R-CNN 目标检测算法。首先输入原始图像,通过选择搜索(selective search)网络,获得约2 000 个尺寸不一致的候选区域;再将这些区域缩放到同一尺寸(227×227)后,利用卷积神经网络对候选区域提取特征;最后使用分类器对得到的特征向量进行分类,以及使用回归器对候选框的位置进行修正。
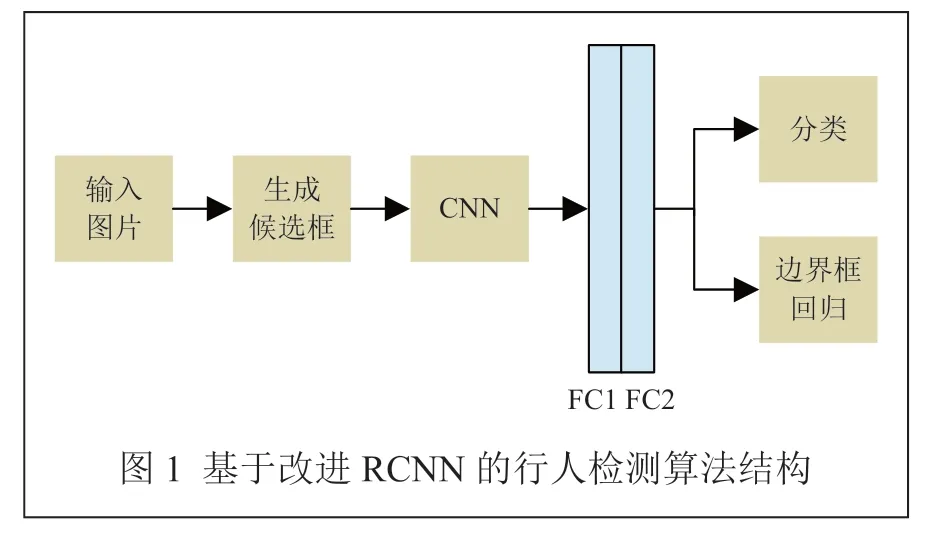
DONG P 等人[7]提出了一种基于ACF(Aggregated Channel Feature)模型的候选区域获取算法,用于替换R-CNN 中的选择搜索网络,算法流程如图1 所示。该候选区域获取算法只在可能包含行人的区域生成区域候选框,将R-CNN 通用目标检测器变为只针对行人进行检测,在提升检测精度的同时,减少了大量无用的候选框,检测速度有所提升。
2.2 Faster R-CNN
由于在一张图像内的候选框之间存在着大量重叠的区域,提取图像特征时操作冗余。为了解决上述问题,GIRSHICK R[8]提出了Fast R-CNN。Fast R-CNN 是将整张图像进行卷积得到特征图,再把生成的候选框投影到特征图上,与R-CNN 算法中对约2 000 个候选框进行卷积操作相比,减少了大量冗余计算。同时,Fast R-CNN将分类与边界框回归任务融合在一个网络,不再单独训练分类器和边界框回归器。但Fast R-CNN依然采用了选择搜索算法来生成区域候选框,该过程十分耗时。因此,GIRSHICK R 又提出了Faster R-CNN,使用区域建议网络(RPN)生成区域候选框,同时提出了锚框(Anchor)这一重要概念。Anchor 是指在图像上预先设置好尺寸和比例不同的参照框,尽可能地包含物体出现的位置。Faster R-CNN 设置了3 组高宽比(0.5,1,2)以及每种高宽比又分为3 组尺度(8,16,32)的Anchor,共组成了9 种形状大小不一的边框。
ZHANG H 等人[9]提出了一种基于Faster R-CNN的行人检测算法,如图2 所示。该算法通过ZFnet[10]提取图片特征,将K-means 聚类算法与RPN 相结合,生成可能包含行人的候选区域,最后检测网络对候选区域中的行人进行检测与定位。但是,这种方法在面对图像中小尺度行人时检测效果较差。

SHAO X 等人[11]提出了一种改进的基于Faster R-CNN 的行人检测算法。在前者的基础上,提出了一种基于级联的多层特征融合策略,通过高层次特征与低层次特征相结合来增强网络的语义信息。同时,采用OHEM(Online Hard Example Mining,在线困难样本挖掘)方法对高损失样本进行训练,处理正负样本的不平衡。实验结果表明,该方法提高了小尺度行人检测的精度。但是,由于这些方法都是对行人的整体特征进行计算,在有部分身体被遮挡的情况下,其检测效果明显降低。
为了解决对遮挡行人检测的问题,许多研究者发现,可以采用基于人体部位的行人检测方法来解决。XU M 等人[12]提出了一种基于人体关键节点的行人检测算法,该算法通过关键点检测器来获取行人的6 个关键节点(头部、上身、左右手臂和腿)的语义信息,将这些语义信息与原图信息相融合,从而使最终的检测器对遮挡和变形具有鲁棒性。
基于人体关键部位的行人检测网络倾向于关注行人的部位信息,忽略了行人整体的信息,容易对形似人体部位的物体产生误判。因此,研究者提出了基于行人整体与部位加权的检测方法[13]。CHI C 等人[14]提出了一种头部和人体联合检测网JointDet,如图3 所示。使用RPN 生成头部候选框,头部和全身的候选框分别经过头部R-CNN 和全身R-CNN 提取特征;将提取的特征进行匹配后,使用RDM 判别是否属于同一个人。

2.3 Cascade R-CNN
在行人检测中,使用IOU 阈值来定义正负样本。如果IOU 阈值越小,那么就会学习越多的背景框。但是随着IOU 阈值的增加,正样本的数量会大量减少,容易发生过拟合。同时,训练优化感知器过程中的最优IOU 与输入proposal 的IOU 会出现误匹配,从而降低检测精度。CAI Z 等人[5]提出了Cascade R-CNN,该算法采用级联式的结构,由多个感知器组成,这些感知器通过递增的IOU 阈值进行训练,从而解决了高IOU 下容易发生过拟合的情况。
BRAZIL G 等人[15]在Cascade R-CNN 的基础上提出了AR-Ped 框架,该框架由自回归RPN(AR-RPN)和R-CNN 检测器两个部分构成,其中,AR-RPN 由多个阶段以及encoder-decoder 模块组成,每个阶段预测分类分数,并通过encoder-decoder 模块将上一阶段的特征传递到下一阶段,从而增强候选框中的语义信息。
3 单阶段行人检测方法
单阶段目标检测算法不需要生成区域候选框,而是直接对图片提取特征后进行分类回归。其检测速度与两阶段的目标检测算法相比更快,但是精度会有所降低。基于锚框的单阶段目标检测算法有SSD[16]、YOLOv3[17]、YOLOv4[18]、YOLOv5 等。
3.1 基于SSD 的行人检测算法
LIU W 等人[16]提出了SSD 算法,图片通过 VGG-16[19]网络提取特征,再经过多次下采样获得6 个不同尺度的特征图,每个特征图都会预测多个bounding box,最后对这些不同尺度的特征进行检测以及非极大值抑制。
为了提升SSD 对行人检测的准确率,LI X 等人[20]提出了一种基于改进SSD 稀疏连接的多尺度融合行人检测方法,采用inception[21]网络代替SSD 中的 VGG-16 进行特征提取,利用FPN[22](特征金字塔网络)将不同层次的特征图像进行合并,并将合并后的特征图像进行分类和回归。与SSD 原算法相比,改进后的方法在面对一般行人检测时,其精度和速度上都有明显提高,但是文章指出,该算法对拥挤人群中有遮挡行人的检测效果没有明显提高。
为了解决遮挡行人检测准确度不高的问题,袁姮等人[23]提出一种基于改进SSD 的行人检测算法,使用BN 层(Batch Normalization)[24]来增加VGG 网络分支结构,充分利用浅层网络的语义信息,提升小尺度行人的检测精度,引入融合SE(Squeeze-Excitation)注意力机制的GhostModule 模型[25],通过SE 注意力机制提升遮挡行人的检测精度。
3.2 YOLO 系列行人检测算法
REDMON J 等人[26]提出了YOLOv1,在保证较高的检测精度下,以其简洁的网络结构和高效的计算速度给目标检测领域带来了巨大的冲击,其结构如图4 所示。但是,由于YOLOv1 的每个网格只含有两个边界框,且每个网格只能预测一个目标,导致其定位误差高以及小目标的检测效果差。所以REDMON J 等人[27]又提出了YOLOv2,该算法借鉴了Faster R-CNN的思想,使用Anchor 来预测边界框,同时使用BN 层来防止过拟合。

3.2.1 YOLOv3
YOLOv3 算法采用DarkNet53 作为骨干网络间特征提取,得到3 个不同尺度的特征图,通过K-means算法在每个特征图上预设3 个不同尺寸的边界框,最后分别对这3 个特征图进行预测输出。
GONG X 等人[28]提出了一种基于YOLOv3 的行人检测算法,引入CSPNet[29],将梯度变化全局整合到特征图中,提高了推理的速度和准确性,加入ECA(Efficient Channel Attention)注意力机制[30],增强网络提取重要特征的能力,在保持性能稳定的同时,显著降低了模型的复杂度。
YU Y 等人[31]为解决行人检测中多尺度目标、遮挡等问题,增加CBAM(Convolutional Block Attention Module)注意力机制[32],使网络更加关注行人相关特征,提高检测速度和精度,以及引入SPP 模块,实现局部特征与全局特征的融合,提高面对遮挡行人时的检测准确率。
李翔等人[33]提出了一种面向遮挡行人检测的改进YOLOv3 算法,通过提高每层金字塔特征的分辨率,使重叠度高的目标框中心点尽量落在不同的区域,同时,为了使相邻区域的特征区别更明显,将浅层和深层的语义信息进行融合,增加高重叠区域的特征差异,从而尽可能区分重叠行人的特征。
3.2.2 YOLOv4
BOCHKOVSKIY A 等人[18]提出了YOLOv4,使用CSPDarkNet53 作为主干网络,利用SPP 和PANNet来增大感受野以及提取更丰富的图像特征。
原始的YOLOv4 模型在面对小尺度行人时容易出现漏检和误检的情况。为了解决这个问题,王程等人[34]提出了一种小目标行人检测算法 YOLOv4-DBF。在骨干网络中融入SCSE 注意力机制[35](Concurrent Spatial and Channel Squeeze &Excitation),从空间维度和通道维度两个方面进行特征提取融合,提高了小目标行人的检测精度,并采用可分离卷积提升检测速度。
FAN P 等人[36]提出一种基于YOLOv4-tiny 的行人检测方法,使用K-means 重新生成更符合行人尺寸的锚框,替换原本的锚框尺寸。同时,为了提取更多浅层语义信息和小尺度信息,将拼接层从第24 层移动到第17 层,将第34 层的上采样倍数从2 改为4,从而提升遮挡行人以及小尺度行人的检测精度。改进后的结构与YOLOv4-tiny 对比如图5 所示。

3.2.3 YOLOv5
YOLOv5 采用CSP-Darknet53 作为主干网络对图片进行特征提取,通过颈部网络将浅层特征融入特征图中,最后在预测端对特征图进行预测。
由于YOLOv5 算法结构较为复杂,为了满足行人检测实时性的要求,王亮等人[37]提出了一种改进的YOLOv5 行人检测算法。该算法引入轻量级卷积模块Ghost 卷积以及轻量注意力机制ECA,同时使用加权双向金字塔结构BiFPN 替换PAN+FPN 结构。结果表明,改进后的模型大小约为YOLOv5 模型的1/2,检测速度(FPS)提高了约1.67 倍。
针对现有行人检测模型在密集场所行人检测中存在漏检和误检的现象,王宏等人[38]在YOLOv5 的主干网络中加入了一种坐标注意力机制,其目的是为了使网络能更精确地对目标行人进行识别定位,同时,增加了一层尺度为160×160 的检测层用来检测小尺度行人。ZHANG R 等人[39]使用BoT3 模块代替YOLOv5骨干网络中的csp2_1 模块,增强网络的全局特征提取能力,在骨干网络的输出端添加HAM(hybridatattention Module)[40],该注意力机制模块结构简单且兼顾了通道和空间两个维度,使网络提取行人相关特征能力得到增强,提高了在面对拥挤人群时的检测精度与速度。
4 结束语
本文介绍了传统的行人检测算法以及基于锚框两阶段和单阶段的行人检测算法的发展现状,重点阐述基于锚框的行人检测算法在面对遮挡行人和小尺度行人检测任务上的优化方法。随着Faster R-CNN、YOLO 系列等通用目标检测算法的快速发展,在一般行人的检测任务上,无论是精度还是速度都已经取得了优秀的成绩。但是在面临拥挤人群或者小尺度行人时,通用目标检测算法容易发生误检和漏检,因此,许多研究者都尝试在此基础上进行改进,例如通过添加注意力机制、增加不同尺度的检测层,以及将不同层的语言信息进行融合等方式,增强网络对行人特征的提取能力。
