基于FPGA的YOLOv5s网络高效卷积加速器设计*
2024-03-26王林林周文勃
刘 谦,王林林,周文勃
(1.中国科学院国家空间科学中心,北京 100190;2.中国科学院大学 计算机科学与技术学院,北京 100049)
0 引 言
近年来,卷积神经网络目标识别算法在人脸识别、自动驾驶以及物体识别等民用领域获得了巨大的成功。目前国内航天技术也逐渐向智能化转变,在航天设备上应用智能化的目标检测系统受到越来越多的关注。然而星载硬件计算资源十分匮乏,如何将基于卷积神经网络的目标检测算法部署到资源有限的宇航级芯片上是亟需解决的一项技术难题[1]。
现场可编程门阵列(Field Programmable Gate Array,FPGA)作为航天常用主控器件,具有功耗低、可重构以及并行计算能力强等优点,利用其高度的并行计算能力能够以较低的功耗实现高效的卷积计算,在卷积加速方面能够表现出独特的优势[2]。因此,本文提出采用FPGA作为硬件加速单元实现基于卷积神经网络的目标检测加速系统。
目前基于FPGA的卷积加速器研究主要集中在3×3标准卷积加速的优化上,对于目标检测常用的YOLO网络的网络加速优化研究还较少。由于目标检测网络较卷积计算有着更加复杂的结构,因此研究如何实现高效的网络加速更具有意义。在YOLO目标检测网络中卷积一般为两种,分别是1×1卷积和3×3卷积。对于YOLO目标检测网络的加速,文献[3-4]中提出的加速结构分别对1×1卷积和3×3卷积进行了硬件设计,两种卷积计算单元相互独立,计算资源互不共享。由于卷积神经网络目标检测算法每次只对一种卷积进行计算,因此此类结构中总有一部分计算单元会空闲,从而使硬件利用率较低。而文献[5]中提出卷积复用的方法,将1×1卷积权重放置在3×3卷积核权重第5位,剩余8位权重置零。该方法用3×3卷积直接代替1×1卷积,虽然大幅提高了硬件利用率,但是1×1卷积计算时每计算1次会产生8次无效计算和无效数据传输,因此造成了1×1卷积计算效率低下。文献[6]中提出了一种策略,将3×3卷积转换成1×1卷积进行计算,并对YOLOv5s网络实现了加速计算,但是该方法却牺牲了部分并行性,计算性能较差。文献[7]采用了基于Winograd算法的硬件加速结构完成了对3×3、5×5以及11×11尺寸的卷积加速,并取得了较好的加速效果,但该方法并不支持1×1卷积的计算。由于YOLOv5目标检测网络中具有大量的1×1卷积计算,因此该方法并不适合用于加速YOLOv5目标检测网络。
为解决以上文献中所提结构的缺点,本文提出了一种将1×1卷积和3×3卷积计算单元复用共享的结构。在大幅提高硬件利用率的同时,既可以计算1×1卷积也可以计算3×3卷积,同时1×1卷积计算时也不会产生无效计算和无效数据传输,解决了文献[3-7]中加速器结构硬件利用率低、计算效率低以及不支持1×1卷积计算等问题。此外,该硬件加速器还利用了层融合、多维度并行卷积加速、模型量化降低资源消耗等方法以较低的FPGA资源消耗获得了较高的计算能力,实现了卷积神经网络目标检测的高效计算。最后本文以通用目标检测算法YOLOv5s算法为基础,并以天体表面陨石坑的识别为主,验证了所提出的加速器结构的有效性。
1 YOLOv5s目标检测算法
YOLOv5目标检测算法由Ultralytics LLC公司于2020年5月提出,是目前优秀的目标检测算法之一。通过YOLOv5算法能够实现多目标高精度的目标检测,可以解决传统目标检测算法要求检测背景简单以及需要被检测目标特征明显类型单一等问题。YOLOv5目标检测网络结构共有5个主流版本,分别是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。
本文综合速度、精度等方面的因素采用了YOLOv5s,并对YOLOv5s算法结构进行了微调:
一是将原算法模型的激活层由SiLU替换为Leaky ReLU。由于SiLU激活函数中包括指数、乘法、除法和加法计算,其计算复杂度高,而Leaky ReLU激活函数中仅包含一个乘法计算计算复杂度低,因此采用Leaky ReLU激活函数能够在一定程度上降低计算量。
二是保留了YOLOv5s-5.0中的FOCUS结构和YOLOv5s-6.0中的SPPF结构,SPPF结构中只采用了一种尺寸5×5的Maxpool,相较于SPP结构中3种不同尺寸(5×5、9×9、13×13)的Maxpool在FPGA上仅需要设计一种尺寸Maxpool,能够简化FPGA对Maxpool的设计。
以上算法修改均能够有效减少FPGA资源使用,且对算法本身影响不大。调整后的YOLOv5s网络结构如图1所示。
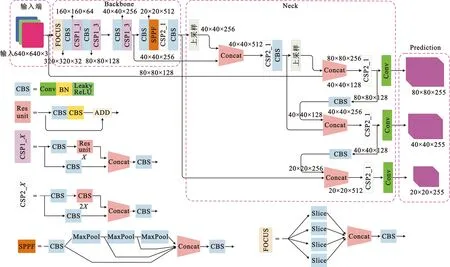
图1 调整后YOLOv5s网络结构Fig.1 Network architecture of adjusted YOLO V5s
2 网络模型层融合与量化
2.1 网络模型层融合
YOLOv5s算法中CBS计算过程包括卷积、BN(Batch Normalization)和Leaky ReLU三部分。在模型训练过程中BN层能够解决梯度消失和梯度爆炸的问题,并可以加快网络的收敛提高训练效率,同时也可以提高网络稳定性。而在前向推理过程中BN层却降低了模型的性能,所以在推理过程中可以通过层融合的方式将BN层融合到卷积层中,从而达到降低计算量、提高模型性能的效果[8]。卷积层BN层融合过程如下:
在BN层中μ表示输入的均值如式(1)所示,式中x表示输入特征图中的元素,m表示输入特征图中元素的个数。δ2为输入的方差,如式(2)所示。
(1)
(2)
BN计算公式如式(3)所示,式中γ为尺度因子,β为偏移因子。尺度因子优化了特征数据分布的宽窄,偏移因子则优化了数据的偏移量,在模型训练过程中这两个参数自动学习,训练结束后数值固定。ε为一个大于0且极小的数值,用于防止方差δ2为0的异常情况出现。式(4)为卷积计算公式,其中W表示卷积核,X表示输入特征图,B表示偏置,Y表示输出特征图。将式(4)代入到BN计算中得到卷积和BN计算的总公式(5),式中Y′表示卷积和BN计算后的输出特征图。
(3)
Y=WX+B
(4)
(5)
将式(5)展开可得出新的卷积核W′如式(6)所示,新的偏置B′如式(7)所示。
(6)
(7)
层融合的方法通过提前计算获得新的卷积核W′和偏置B′,从而将BN层融合到卷积层中,有效降低了模型推理阶段FPGA上的计算量,减少FPGA片上DSP48E、LUT等资源的消耗。同时由于计算步骤减少,所以也能够在一定程度上减小推理延时,提高系统整体性能。
2.2 网络模型量化
在深度学习领域量化是一种常用的能够有效降低存储空间和计算成本的方法[9],可以有效压缩模型大小。在FPGA上采用量化方法用低位宽的定点乘法器、加法器代替高位宽的浮点乘法器、加法器可以大幅降低FPGA逻辑资源的使用,提高资源紧缺情况下FPGA上的计算能力。本文对模型进行了量化,将32位单精度浮点转换为16位定点数,在FPGA中设计16位定点乘法器、加法器来完成卷积层的计算。
3 FPGA硬件加速器设计
3.1 加速器体系架构
根据图1中YOLOv5s网络结构框图可以看出其内部由基础模块构成,包括卷积Conv模块、ADD模块、Maxpool模块、Silce模块、上采样模块和Concat模块。其中卷积分为两类,分别为1×1卷积和3×3标准卷积,在YOLOv5s算法中一共了包含43层1×1卷积和19层3×3标准卷积,该部分是YOLOv5s算法中计算最复杂的部分,需要在FPGA设计并行计算单元以达到计算加速效果。本文对YOLOv5s算法中计算量较大的模块在FPGA上进行了硬件加速设计,包括Conv1×1卷积、Conv3×3卷积、ADD、Maxpool和上采样模块。
加速器整体架构如图2所示,该架构中包括CPU和FPGA两个部分。其中CPU部分为双核ARM Cortex-A9 MPCore,该部分外挂DDR3内存,用于缓存特征图和权重数据以及运算过程中产生的中间数据,外挂NAND FLASH用于存储输入的图像文件和权重文件以及存储计算后的输出文件。UART接口用于监控加速器各个阶段的计算耗时,输出所识别到的陨石坑在图像中的坐标信息。CPU部分主要进行图像和权重等文件的读取、将图像和权重文件转存到DDR3、配置FPGA端加速器以及处理YOLOv5s中简单的计算如Silce和Concat。
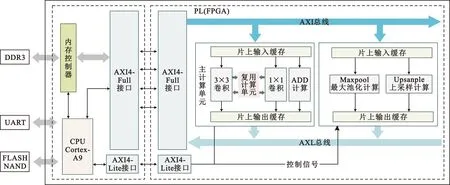
图2 系统整体架构Fig.2 Overall system architecture
FPGA端设计有主计算单元和辅计算单元两个部分。其中主计算单元包括3×3卷积缓存模块、1×1卷积缓存模块、通用并行计算模块和ADD计算模块。在主计算单元中由于涉及的数据量较大且数据传输延时较长,所以在主计算单元中采用双缓存乒乓机制用于掩盖数据传输所消耗的时间。辅计算单元包括Maxpool计算模块和上采样计算模块。
CPU和FPGA之间通过AXI(Advanced eXtensible Interface)总线交互数据,采用了1个AXI-GP接口和4个AXI-HP接口。其中AXI-GP接口用于FPGA和CPU之间的控制信号传输,实现加速器的偏移地址配置以及其他参数配置。而AXI-HP接口负责计算过程中DDR3内存与FPGA的高速数据交换,AXI-HP接口和DDR之间具有专有控制器可以直接实现FPGA与内存的高速数据交换,由于不需要经过CPU从而大大提高了数据传输效率,适合大数据吞吐量的应用场景。
3.2 存储设计
3.2.1 循环分块策略
由于FPGA的片上存储BRAM(Block Random Access Memory)资源十分有限,而卷积计算过程中的权重、偏置以及特征图会占用大量的存储资源,所以无法直接将整个特征图存储到FPGA的片上存储中。因此本文采用对特征图进行循环分块的设计策略,将片外DDR3中存储的完整特征图分为数个小块,分批次存储到FPGA片上存储BRAM中进行后续的卷积计算,解决了FPGA片上存储资源不足的问题。循环分块过程如图3所示,分块后的小特征图存储在双缓存结构中。
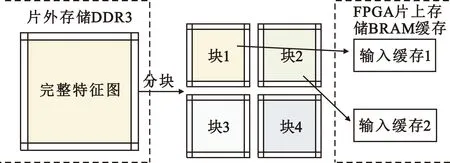
图3 循环分块过程Fig.3 Cyclic chunking process
3.2.2 双缓存与缓存分割
为进一步提高整个系统的吞吐量,掩盖AXI总线和内存之间的传输延时,本文设计了一种双缓存机制,使加速器可以在AXI总线传输特征图的过程中同时进行卷积计算。双缓存结构如图4所示,当计算单元读取缓存1中的数据进行卷积计算的过程中,缓存2可以同时用于接收AXI总线中的数据,而缓存2用于计算时,缓存1则可以用于接收数据,以此往复。该结构可以使计算单元一直处于工作状态,从而在一定程度上提高整个系统的工作效率。
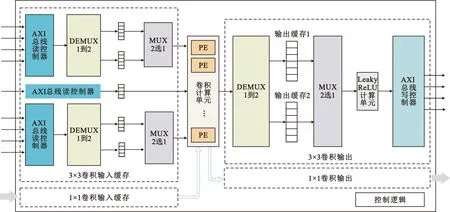
图4 双缓存结构示意Fig.4 Dual cache architecture schematic
此外,由于FPGA中的BRAM仅能配置为双端口进行读写,读写速率受端口数量的限制。为解决此类问题,本文采用数组分割的方式,将分割后的数组存储在不同的BRAM中,用数个小容量缓存代替一个大容量缓存,从而可以实现多个端口同时读写数据提高数据吞吐量,为后续并行计算结构提供充足的数据量。
3.3 卷积计算结构设计
本文中1×1卷积和3×3卷积采用了复用的计算单元,需要计算单元尽可能兼容两种卷积计算,因此本文设计了输入-输出通道并行的加速结构,该结构中计算单元的硬件结构与卷积核尺寸无关。其计算单元中包含64个数据处理单元(Processing Element,PE),PE由8个输入并行数据选择器、4个乘法器、1个加法树以及1个累加结构构成。每个PE单元具有8个输入通道其中1×1卷积和3×3卷积各4个通道,通过数据选择器选择其中4个通道至后续的运算结构,因此实现了1×1卷积和3×3卷积的计算资源共享。PE计算单元结构如图5所示。
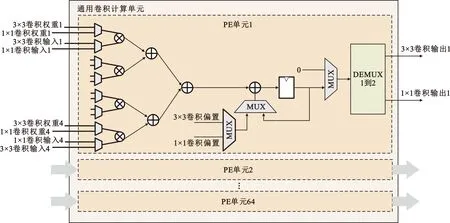
图5 PE结构示意Fig.5 PE architecture schematic
在YOLOv5s算法中的通道数最大达到了1 024,受限于FPGA资源无法将1 024个通道全部在FPGA上实现并行,所以实际输入的特征图通道数远大于PE单元的设计输入通道,因此,输入的特征图只能分批进入PE单元中进行计算。此外,对于3×3卷积每一个通道的每一个输出数据也都会进行9次卷积核内计算,且输出通道的计算结果是分批输入特征图卷积累加的结果,因此在PE单元中增加了累加结构用于将不同批次进入PE单元的输出数据以及3×3卷积核内计算数据进行累加,实现完整的多通道卷积计算。为提高PE结构的运行频率和吞吐量,本文在PE单元的硬件结构中插入了中间寄存器进行了6级流水设计,使加速器可以在高时钟频率下稳定工作。
3.4 Leaky ReLU激活函数计算单元设计
在YOLOv5s中最后一层卷积不需要激活函数,所以由累加器输出的特征图还需要通过数据选择器,选择特征图是否经过激活函数。激活函数根据调整后的算法结构采用Leaky ReLU,该激活函数较SiLU激活函数具有电路结构简单的优点,适合在计算资源紧张的嵌入式环境应用,其计算公式如式(8),本文中a采用0.01。
(8)
由于Leaky ReLU激活函数计算简单,计算延时低仅需要1个时钟周期,故本文中一共设计了4个并行Leaky ReLU计算单元对应在4个AXI输出接口之前,其结构电路如图6所示。
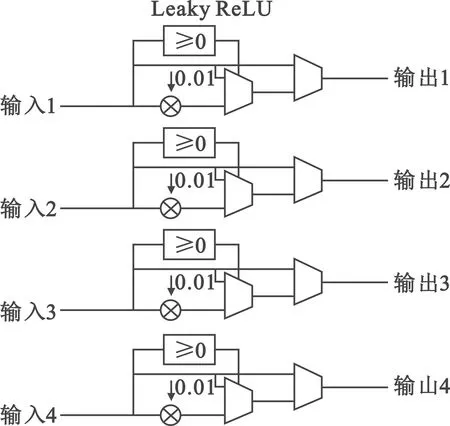
图6 Leaky ReLU结构示意Fig.6 Leaky ReLU architecture schematic
3.5 ADD模块设计
ADD本质是将两个输入层相加,该部分要求输入层的通道数、特征图尺寸完全相等。由于ADD单元的计算结构与卷积计算单元有着较大的差异,难以实现与卷积计算共享硬件资源的计算结构,因此本文对ADD结构进行了单独的硬件加速设计。ADD硬件加速模块的结构如图7所示。
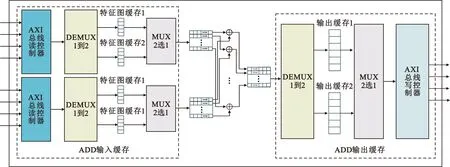
图7 ADD结构示意Fig.7 ADD architecture schematic
该部分同样采用双缓存结构用于提高吞吐量。为降低寻址难度,该部分采用一维形式分块,将n×n特征图所有的数据按照Tp个特征点分批为n×n/Tp次,同时按照Tn个通道将输入通道N按N/Tn次分批处理,将Tn个通道的Tp个特征点数据一次性由DDR3传输到FPGA端并缓存到片上BRAM中,充分利用AXI-HP总线的突发传输模式有效降低传输延时,其中Tn为32,Tp为400。其加法计算部分采用三级流水,分别为读数据阶段、加法计算阶段和写数据阶段,用于提高系统工作频率。
3.6 Maxpool模块设计
Maxpool在算法中主要起到减小特征图尺寸,控制过拟合的作用[10]。对于最大池化模块Maxpool的处理,首先按照Maxpool的窗口尺寸将特征图分为5×5的小块,然后将5×5分块的特征图存储到输入缓存中,之后通过比较器树比较5×5特征图中25个特征点的大小,取最大值并将该值作为输出特征图中的一个特征点存入到输出缓存中。其处理过程和计算单元结构图如图8所示。

图8 5×5 Maxpool结构示意Fig.8 5×5 Maxpool architecture schematic
3.7 上采样模块设计
YOLOv5s中所使用的上采样模块作用是将输入特征图扩大4倍,即1个输入特征点对应4个输出特征点。该部分在FPGA上实现的结构较为简单,仅仅涉及缓存的读写,具体操作是将输入缓存中的1个特征点取出并转存到输出缓存中对应的4个特征点上。
4 实验与分析
4.1 实验环境和平台
本实验在YOLOv5s模型训练阶段采用了自制数据集,使用了124张来自月球和火星的陨石坑图片,图片尺寸为640×640,用于验证小样本数据集下目标检测算法的有效性。采用的训练平台硬件环境为Intel i7-1100 CPU,RTX3080 GPU,16 GB内存。
在加速效果测试中,为比较不同平台间的差异采用了两种平台,分别为实验平台1,Xilinx公司ZC706开发板,该开发板采用的主芯片型号为XC7Z045,XC7Z045芯片集成双核ARM Cortex-A9 CPU和Kintex-7 FPGA,FPGA中具备900个DSP48E单元、218 600个LUT逻辑资源以及545个BRAM36K存储资源;实验平台2,微相公司ZYNQ开发板,该开发板主芯片为XC7Z020,XC7Z020芯片集成双核ARM Cortex-A9 CPU和Artix-7 FPGA,FPGA中具备220个DSP48E单元、53 200个LUT逻辑资源以及140个BRAM36K存储资源。
4.2 实验结果与分析
XC7Z045芯片中FPGA片上资源使用情况如表1所示,其中DSP48E1一共使用了65%,主要用于组成卷积计算结构中的乘法器和加法器以及ADD模块中的加法器;BRAM36K使用了58.07%,主要用于FPGA片上对特征图、权重等的缓存,以及构成双缓冲结构等;而LUT、LUTRAM以及FF等资源主要用于加速器逻辑控制、加速器内部流水线构成等。
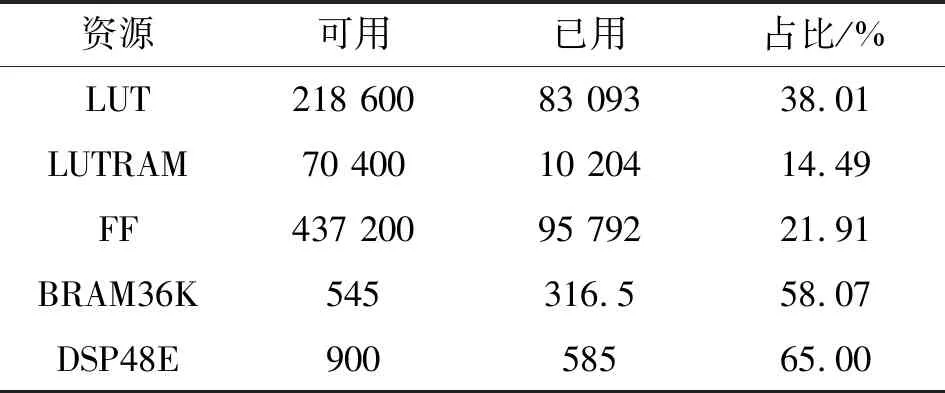
表1 XC7Z045芯片资源占用率Tab.1 XC7Z045 chip resource usage
XC7Z020芯片中FPGA片上资源使用情况如表2所示,各部分资源的作用与XC7Z045相似。
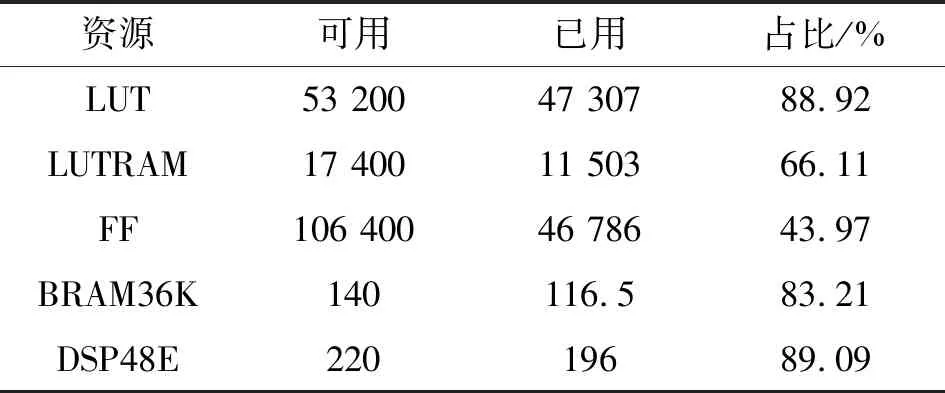
表2 XC7Z020芯片资源占用率Tab.2 XC7Z020 chip resource usage
实验表明,该目标检测系统能够正确读取FLASH中的图像和权重文件并进行YOLOv5s算法的计算,能够准确识别出图像中的天体陨石坑位置。部分天体陨石坑的识别结果如图9所示,矩形框所框出的位置为陨石坑所在位置。表3对原始YOLOv5s网络和本文中的YOLOv5s网络的检测效果做了对比,可见本文中的YOLOv5s网络保持了与原始网络效果相近,虽然指标有一定的损失,但是本文网络更加适合在FPGA上实现,与文献[6]相比在相同硬件平台下,采用本文中的加速器结构和YOLOv5s网络结构获得了数倍的计算性能提升,其利远大于弊。

表3 与原始网络的识别效果对比Tab.3 Recognition results compared with the original network
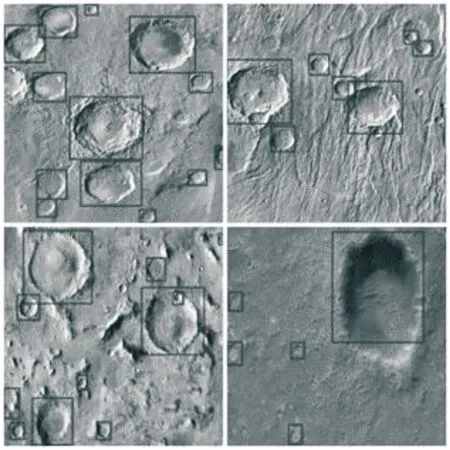
图9 陨石坑识别结果Fig.9 Crater identification results
通过实验将本文中所提出的FPGA加速结构与RTX2060、树莓派两种平台在功耗、速度以及芯片架构、能效等方面做了比较,结果见表4。在FPGA平台下的能效(单位:J/picture)是CPU平台的11~41倍,是GPU平台的2.3倍。通过分析可以得出,FPGA平台上实现的YOLOv5s算法在能效方面较CPU和GPU平台具有显著优势,能够实现低功耗情景下的高性能计算。

表4 不同平台间计算速度对比Tab.4 Comparison of computing speed between platforms
在加速器方面,将本文中提出的加速结构与其他文献中加速结构在计算性能、能效以及DSP利用率等方面进行了比较,结算如表5所示。表中GOPS表示加速器每秒乘法和加法的总计算次数,GOPS·W-1表示能效比,GOPS·DSP-1表示DSP效率。通过对比可以看出,本文所提出的加速器结构在计算能力、能效比、DSP效率等方面均有着较好的表现,平台2(XC7Z020平台)与文献[6]在相同算法、相同硬件平台情况下其计算性能提高了4.46倍,能效比提高了3.69倍,DSP利用效率提高了4.49倍。此外,平台1(XC7Z045平台)与平台2(XC7Z020平台)相比,平台1实现了更强的计算能力,原因是平台1硬件资源较多可以实现更高的并行度,但在能效比和DSP效率上两者基本保持一致,受不同平台的影响较小,因此本文中的加速结构可以在不同硬件平台上进行移植,同样可以实现较高的能效和DSP利用率。通过以上对比可知,本文所提出的YOLOv5s网络FPGA加速结构具有资源使用量少、效率高等特点,在相同器件上能够提供更强的计算能力。

表5 加速性能对比Tab.5 Accelerated performance comparison
5 结束语
本文研究了基于YOLOv5s目标检测网络的加速设计,并提出了一种适用于YOLOv5s网络结构的FPGA硬件加速结构,实现了对YOLOv5s算法各个阶段的加速工作,完成了对天体陨石坑的目标识别检测。此外,还提出了一种1×1卷积和3×3卷积硬件计算资源共享的结构,实验表明该结构较其他结构在能效、资源利用效率等方面具有一定的优势,在资源受限的领域具有重要的意义,为日后的航天器智能化提供了新思路。
本文中的加速结构已经在不同的FPGA平台上获得了较理想的加速效果,因此下一步研究工作可以聚焦在采用宇航级FPGA芯片的验证工作上,实现可以实际应用于航天领域的目标检测系统。
