基于迁移学习与后训练剪枝的水母图像分类方法研究
2024-03-25李杜
李 杜
(兰州职业技术学院 信息工程学院, 甘肃 兰州 730070)
一、引言
近年来,人工智能(AI)技术在各个领域崭露头角,在生态学领域的应用更是受到广泛关注。AI的强大计算能力和智能分析能力帮助人们更深入地认识自然环境,推动环境保护,实现可持续发展的目标。目前已经出现很多成熟的机器视觉或机器学习算法模型,如用于图像识别的LeNet[1]、AlexNet[2]、GoogLeNet[3]、VGG系列[4]等。利用摄像头、卫星以及无人机等设备采集的大量数据,结合深度学习算法,通过人工智能的图像识别技术,能够更快速、准确地进行野生动植物种群的识别和监测。这为生物多样性研究提供了全新的手段,也为濒危物种保护提供了更有力的支持。
水母是海洋等水生环境中常见的浮游生物,是海葵、海蜇、海龟等一些海洋生物的主要食物来源,对于海洋食物链的平衡和海洋生态系统的稳定具有重要的作用。为了更好地掌握水母对海洋生态系统的影响,学术界正在开展相关研究,包括监测水母的数量和分布,探讨其与气候变化、海洋污染等环境问题之间的关系,以制订科学合理的保护和管理策略。
通过强大的图像识别网络模型,结合各种硬件平台精准识别各类水母,并统计不同海洋区域的水母种群变化数据,以便研究人员能够在分析量化数据后,采用更理想的可持续的方法来管理水母种群,使其在海洋生态系统中发挥其天然的生态功能,同时减少可能的负面影响。这对保护海洋环境、维护地球的生态平衡意义重大。
本文使用ResNet18预训练模型,通过对Kaggle的Jellyfish Image Dataset公共数据集进行迁移学习[5],规避了大规模数据训练成本过高的问题,并在此基础上进行训练后剪枝[6]操作,获得了处理速度更快且精度更高的轻量化模型,这将极大地提高不同种类水母的识别精度和效率。
二、相关理论
(一)卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是一类专门用于处理网络数据的深度学习模型,广泛应用于计算机视觉任务,如图像和视频识别、图像分类、物体检测等。CNN的设计灵感主要来自生物学中视觉系统的工作原理,模拟了人类视觉系统对视觉层次的处理方式。CNN包括的核心模块有:卷积层、池化层、激活函数和全连接层。
卷积层(Convolutional Layer)利用卷积操作可以有效提取局部特征,通过在输入数据上滑动卷积核(Filter)来检测不同的特征,如边缘、纹理等。池化层(Pooling Layer)用于减小数据尺寸、降低计算复杂度,同时保留重要的信息;常用的池化操作包括最大池化和平均池化。激活函数(Activation Function)通常为引入非线性,使得神经网络能够学习复杂的模式;常用的激活函数包括ReLU(Rectified Linear Unit)等。全连接层(Fully Connected Layer)在卷积层之后,用于整合卷积层提取的特征;这一层的神经元与前一层的所有神经元相连,通常用于输出最终的分类结果。
层与层之间的参数共享和局部连接的特性使得CNN对于图像等数据的处理更加高效。CNN的特点在于它拥有局部感知域,还可以进行权重共享。权重共享使得网络学习具有平移不变性,而局部感知域使网络对局部特征有更好的提取能力。CNN成功应用于图像数据的有效处理和特征提取能力,使其成为计算机视觉领域的重要工具。除图像处理外,CNN也被用于处理其他类型的网格数据,如语音识别、自然语言处理等。
(二)AlexNet
AlexNet是一种深度卷积神经网络,由亚历克斯·克里切夫斯基(Alex Krizhevsky)、伊利亚·苏茨克沃(Ilya Sutskever)和杰弗里·辛顿(Geoffrey Hinton)在2012年设计的,它在当时的ImageNet图像分类挑战赛中取得了SOTA,标志着深度学习在计算机视觉领域的崛起。AlexNet包含8个学习层,其中有5个卷积层和3个全连接层。AlexNet 在卷积层后引入了局部响应归一化,这有助于增加模型的泛化能力。此外,为了防止过拟合,AlexNet 引入了随机失活(Dropout)技术,即在训练过程中以一定的概率随机关闭一些神经元,这有助于提高模型的泛化性能。AlexNet 是首个在GPU上进行了大规模并行处理的深度学习模型,这一点也促使了深度学习在工业界的广泛应用,因为GPU相比于传统的CPU能够更有效地处理深度学习任务。
AlexNet的成功奠定了深度学习在计算机视觉领域的地位,启发了后续许多深度神经网络的设计。由于硬件和算法的进步,一些后续的模型如VGG、GoogLeNet和ResNet等在结构上进行了更深入的探索,并在性能上取得了更好的结果。
(三)VGG16
VGG16(Visual Geometry Group 16-layer)问世于2014年,是一款强大的面向机器视觉任务的卷积神经网络架构,其设计简单而有效,成为了深度学习领域的经典模型之一。VGG16包含16个学习层,其中包括13个卷积层和3个全连接层。与之前的模型相比,VGG16的深度相对较大,但结构相对更简单。VGG16采用了统一的卷积核尺寸,即3×3的卷积核,这种设计有助于减少参数数量,并且通过多个较小的卷积层堆叠,网络可以学习更复杂的特征。在卷积层之后,VGG16使用最大池化层来减小特征图的尺寸,有助于保留重要的特征并降低计算复杂性。与AlexNet一样,VGG16采用了线性修正单元(Rectified Linear Unit,ReLU)作为激活函数,增加了网络的非线性。 类似于AlexNet,VGG16在设计时也考虑了多尺度的特征,通过对输入图像进行裁剪和缩放来增加训练数据的多样性。VGG16在网络的顶部包含三个全连接层,最后一个全连接层输出类别概率。不同于AlexNet中的局部响应归一化,VGG16中并没有采用参数共享的方法,这导致了模型的参数量相对较大。
VGG16的设计简单、清晰,易于理解和实现。尽管它在一些计算资源有限的情况下可能较为昂贵,但它成为了许多后续卷积神经网络的基础。继VGG16成功之后,后续的VGG19等模型也相继提出。
三、研究方法
本文针对水母图像分类识别任务,基于迁移学习的ResNet18算法,并融合了后训练剪枝等技术,有效提升了图像分类识别效率。采用迁移学习的方法解决训练数据不足的问题。运用ResNet18预训练网络模型,利用该网络模型在大规模数据集上已经学习到的知识,充分利用数据样本间的相关性,利用水母图像公共数据集J对ResNet18预训练模型进行再次训练,并根据任务需要回归出相应分类概率值。在取得更新后预训练模型的基础上,进行后训练剪枝操作,通过主动去掉一些分支来降低过拟合的风险,测试时间开销降低,从而获得更加轻便的网络模型,使其能够更容易地部署在移动电话等弱算力机器上,以方便用户使用。
(一)迁移学习
在各个领域使用广泛的机器学习[7]算法通常是根据已有数据集训练出一个已经获得知识的网络模型,再利用该完成训练的网络模型对新的数据样本进行推理预测。而迁移学习是将已经学到的知识,应用到具有一定数据相关性的新任务当中,以较小的学习代价满足当前任务的需要。这类似人类的思维过程,当我们学会如何驾驶汽车以后,再学习驾驶电动汽车就会得心应手。
1.领域
领域(Domain)是算法模型进行学习的对象。领域的构成主要包括两个部分:样本特征空间X及数据样本的概率分布P(X)。可以用D来表示一个Domain,而用P表示一个概率分布。在迁移学习中,会涉及两个基本领域:源领域(Source Domain)和目标领域 (Target Domain)。一般用Ds表示源领域,而用Dt表示目标领域。
2.任务
任务(Task)是迁移学习的目标,主要由两个部分构成:标签空间Y及其所对应的函数f。如果用Y表示标签空间,则与Y相对应的学习函数可以用f(·)表示。与之相关的源领域空间和目标领域空间分别由Ys和Yt表示。
3.迁移学习模型
若给定源领域Ds和源任务Ts,以及目标领域Dt和目标任务Tt的情况下,迁移学习的目标则是当Ds≠Dt或Ts≠Tt的情况下,使用由Ds和Ts所获得的知识,来增强目标学习函数ft(·) 的预测能力。迁移学习的工作流程如图1所示。
从图1中可以看出,迁移学习利用在历史任务中所学习到的知识,具体如样本数据特征、网络模型参数等,来进一步拓展在目标任务中的学习效果,最终得到满足当前任务的网络模型。
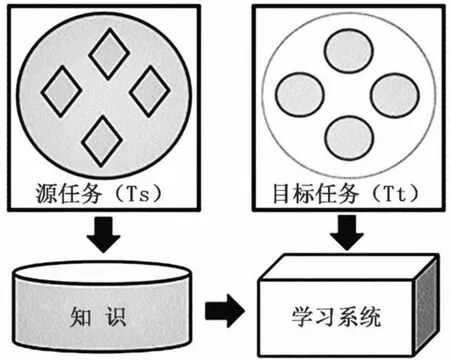
图1 迁移学习的工作示意图
(二)ResNet
对于深度网络模型而言,当网络层数过深时会存在梯度消失[8]或梯度爆炸的问题。当梯度消失的情况出现时,在反向传播的过程中,每当向前传播一层,均需要乘以一个小于1的误差梯度。可以使用对数据进行标准化处理或者对权重进行初始化以及批量归一化[9]等方法来解决梯度消失或梯度爆炸问题。此外,深度网络会出现退化问题(Degradation Problem),而ResNet的提出较好地解决了此问题。
ResNet(残差网络)是一种深度卷积神经网络架构,它主要通过引入残差块(Residual Block)来解决深度神经网络训练中的梯度消失和梯度爆炸问题。ResNet18是ResNet的一个常见变体,是计算机视觉任务中常用的轻量级深度学习模型之一。
1.残差结构
ResNet可以由两种不同的残差结构组成,其中针对网络层数较浅的情况(如18层和34层)可以使用残差块(Residual Block,图2左);而对于层数较深的网络(如50层,101层和152层)则使用瓶颈层(BottleNeck Block,图2右)。
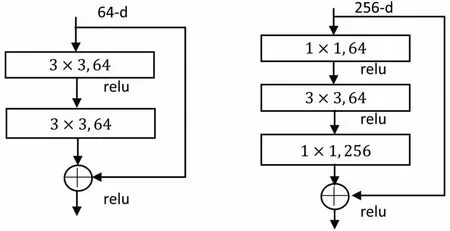
图2 两种残差单元结构
由图2可知,Residual Block的参数个数为3×3×64×64 + 3×3×64×64=73,728个,而BottleNeck Block的参数量为1×1×256×64+3×3×64×64+1×1×64×256=69,632个。使用1×1的卷积核对输入特征数据进行维度大小的升降,以控制参数量。
2.浅层ResNet网络模型
由于本文侧重于模型轻量化的研究,如何使用容量更小、更易部署到移动边缘设备以达到对水母图像的快速识别是本文研究的重点,所以选取了网络层数较浅、参数量较少的ResNet18轻便模型作为本文方案的基础算法,它的结构如表1所示。
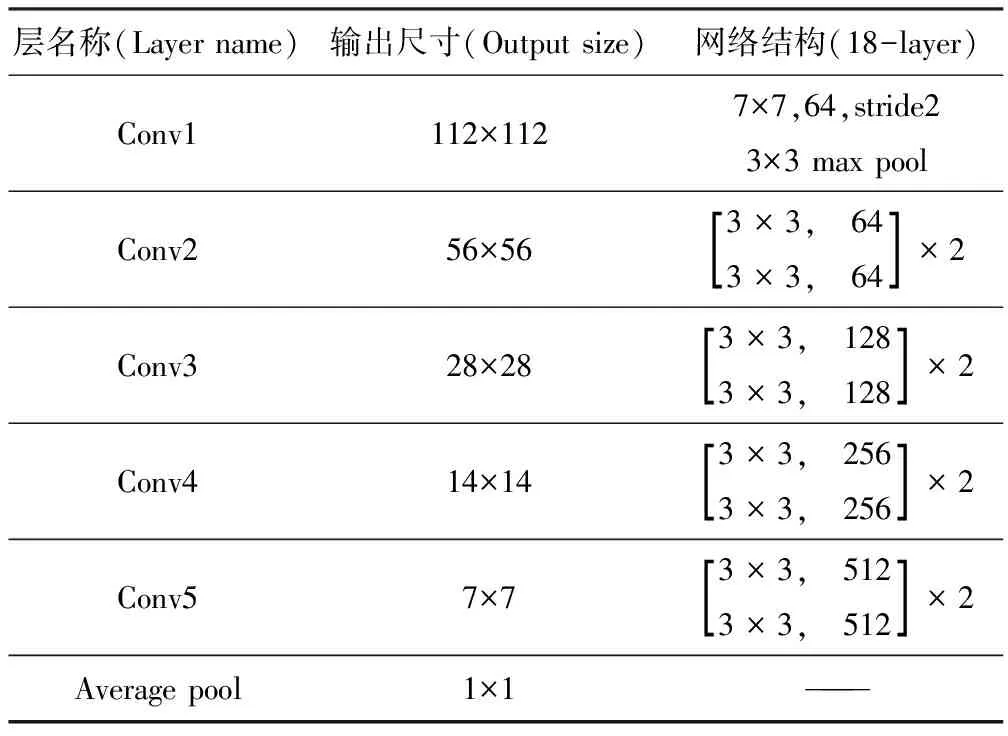
表1 ResNet18网络结构
本文所用网络结构中,FLOPS为1.8×109,Conv2的第一层为实线残差结构(输入图像的高、宽和通道数都发生了变化),其通过最大池化进行下采样后会得到维度大小为[56,56,64]的特征图,恰好是实线残差结构(输入特征矩阵与输出特征矩阵维度未发生改变,故可直接进行Add操作)所要求的输入特征矩阵Shape。而Conv3的第一层为虚线残差结构,输入特征矩阵Shape为[56,56,64],而输出特征矩阵Shape则是[28,28,128]。
3.批量归一化
BN的目标是将一个批次样本(Batch)特征映射(Feature Map)的每个通道维度都满足均值为0、方差为1的标准正态分布,以便加速网络学习的收敛并提高准确率。在对各个通道进行具体处理时,通过计算得到μ和σ2向量,即一个均值和方差对应一批Feature Map的同一个通道。
理论上需要对整个训练集的特征图进行计算,再实施标准化处理,但对于大型数据集而言,显然是不实际的,所以在对网络进行训练的过程中需要持续计算每个Batch的均值和方差,然后使用移动平均记录统计后的均值和方差。在训练完成后,可以近似地将所统计的均值和方差等同于整个训练集的均值和方差。最后,在验证及预测环节,使用统计得到的均值和方差的近似结果进行标准化操作。该过程可以用公式表示如下:
(1)
(2)
(3)
(4)
首先,通过(1)(2)计算出各个Channel(一批数据xi、同一个通道)所对应的均值μ和方差σ2,再由(3)(4)(引入ε可以防止分母为0),最终使用学习到的参数γ和β分别对方差和均值进行调整,得到均值0、方差1的符合标准正态分布的数据yi。
4.后训练剪枝
本文在对水母小规模数据集进行微调(Fine-Tuning)训练所得模型的基础上,为了使得到的模型更加轻量化,使用后训练剪枝的方法减少模型的计算量并使得模型更适合在资源受限的环境中部署。具体步骤如下:
(1) 模型微调:对预训练ResNet18模型进行Fine-Tuning。在微调期间,模型将在水母数据集上进行进一步训练。微调的目的是进一步优化模型,使其适应水母图像识别任务。
(2)训练后剪枝:完成微调后,剪枝操作被引入。剪枝的目的是去除模型中冗余的参数(权重)或神经元,达到模式轻量化。通常,剪枝操作会基于一些准则,例如权重的大小或梯度的大小。
后训练剪枝的优势是能够在模型训练完成后通过去除冗余参数来提高模型的效率,降低计算和存储成本。剪枝有导致一定性能损失的可能。但总体而言,后训练剪枝是深度学习模型优化的一种策略,使得模型更适用于实际应用中的资源受限环境。相关核心代码如下:
tensor_to_module_metadata = get_tensor_to_module_metadata(spec.tensor_to_metadata)
tensor_to_inputs_weight_indices = spec.tensor_to_inputs_weight_indices
tensor_to_outputs_weight_indices = spec.tensor_to_outputs_weight_indices
tensor_to_input_activation_indices = spec.tensor_to_input_activation_indices
for tensor_id, module_metadata in tensor_to_module_metadata.items():
module_metadata = tensor_to_module_metadata[tensor_id]
metadata = spec.tensor_to_metadata[tensor_id]
for param in metadata.non_tracers:
if len(param.shape) >0:
module = module_metadata.get('module', None)
pruned = generate_pruned_weight(
weight=param.data,
input_weight_indices=tensor_to_inputs_weight_indices.get(
tensor_id, [None])[0],
output_weight_indices=tensor_to_outputs_weight_indices.get(
tensor_id, [None])[0],
module=module,
)
param.data = pruned
if tensor_id in tensor_to_input_activation_indices:
insert_subselection(
module_metadata,
tensor_to_input_activation_indices[tensor_id],
is_not_ane=is_not_ane,
baseline=baseline,
channel_axis=metadata.channel_axis,
)
四、实验过程
(一)数据集
本文采用Jellyfish Image Dataset公共数据集的图像样本作为训练和测试对象。该数据集包含6种分类的水母图像,它们分别为:Barrel_Jellyfish、Blue_Jellyfish、Compass_Jellyfish、Lions_Mane_Jellyfish、Mauve_Stinger_Jellyfish和Moon_Jellyfish。每种水母图像均有150张训练样本和10张以内的验证和测试样本,且每张图像样本为224×224像素大小的RGB图像,属于小规模数据集。其样本示例如图3所示。

图3 Jellyfish Image Dataset图像样本示例
该图像数据集的样本水母外观变化十分多样,且由于这些图像是在水下拍摄所得,所以图像中一般都会不同程度地包含噪声信息,使得图像识别算法面临不小的挑战,因此该水母图像识别任务具有相当难度。
(二)比较实验
本文使用一个具有两层卷积层和一层池化层的CNN并选取成熟网络模型AlexNet、Vgg16及ResNet18的预训练模型,使用Jellyfish Image Dataset进行训练或者Fine-Tuning。通过量化指标和训练曲线变化趋势,选定相应的网络模型,作为本文对水母图像分类进行迁移学习的基本方法。不同方法的30轮Fine-Tuning曲线变化情况如图4至图7所示。
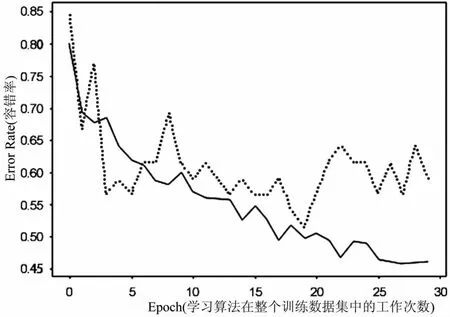
图4 在简单CNN上的训练曲线变化图

图5 在AlexNet上的Fine-Tuning曲线变化图
由图4至图7可以看出,在用本文所搭建的简单CNN对水母数据集进行训练的过程中,训练曲线(图中实线)与验证曲线(图中虚线)相对于采用其他方法更加拟合,但由于其最终训练精度和验证精度较低,其准确率仅为41%,无法完全满足任务需要,故无法采用。
而AlexNet、Vgg16及ResNet18所达到的准确率分别为59%、77%和79%,其中对ResNet18的30轮训练量化细节如表2所示。
在此三种网络模型中,ResNet18的训练曲线相对于其他两者也更加拟合,故本文采用Fine-Tuning后的ResNet18网络模型作为本文的基础方法。
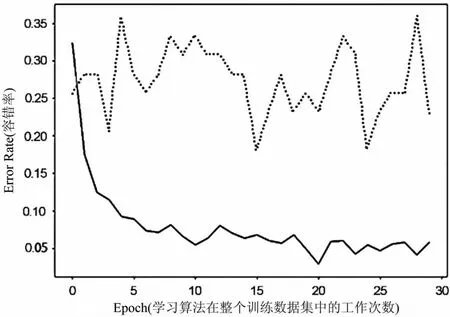
图6 在Vgg16上的Fine-Tuning曲线变化图
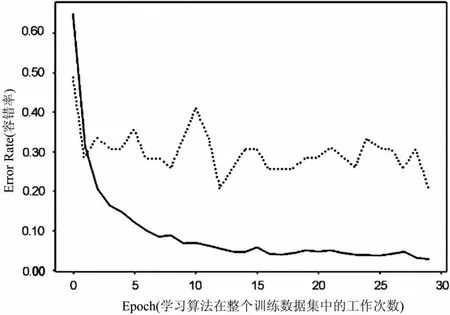
图7 在ResNet18上的Fine-Tuning曲线变化图
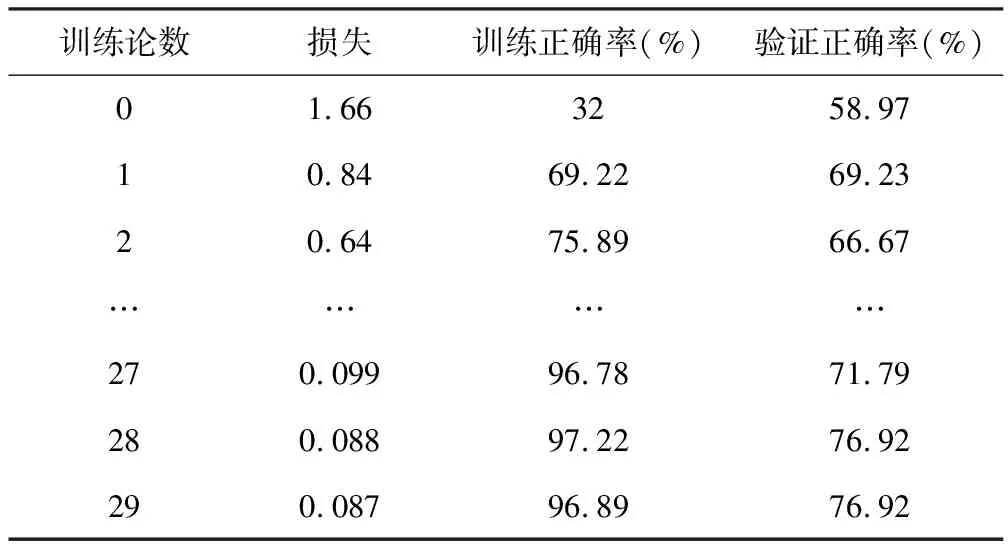
表2 对ResNet18的30轮训练情况量化表
(三)对ResNet18预训练模型的后训练剪枝
为了获得更加轻便的ResNet18,本文在Fine-Tuning后的ResNet18网络模型基础之上,进行结构化剪枝操作,最终所得的模型参数量由初始的11,179,590个降至4,340,314个。本文通过从训练、验证及测试数据集中选取10次图像样本,且每次放回并随机选取16张图像样本,计算预测结果的平均测试精度,最终得到82%的准确率,证明该模型可以有效满足水母图像识别任务的需要。几种方法的相关指标量化结果如表3所示。
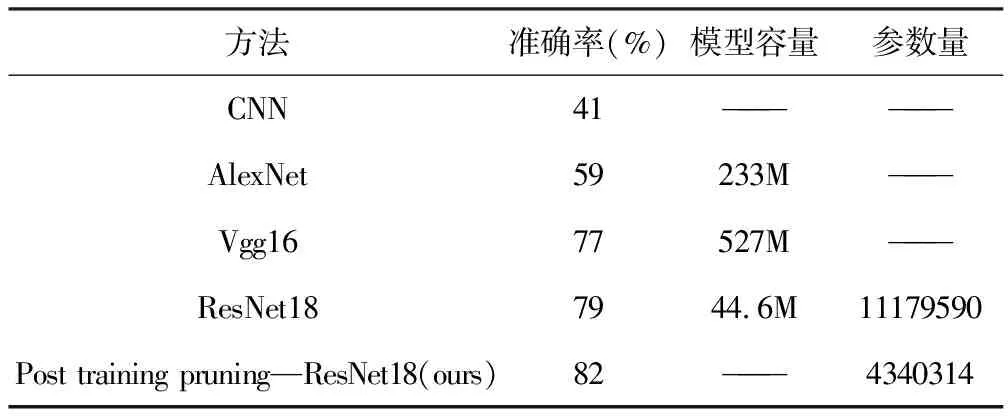
表3 不同方法相关指标量化对比表
五、结论
本文针对水母图像识别任务,将ResNet18预训练模型固有的知识体系通过小规模公共数据集Jellyfish Image Dataset进行迁移学习,在Fine-Tuning成本很小的情况下,使得ResNet18网络模型更适合水母图像识别任务,并在达到较高识别精度的前提下,实现了模型轻量化的目标,在水生物智能监测与水生态保护领域具有一定的实用价值和学术参考意义。
