炳灵寺石窟图像无检测特征匹配方法研究
2024-03-25王鑫,田欢
王 鑫,田 欢
(兰州职业技术学院 a.信息工程学院; b.现代服务学院, 甘肃 兰州 730070)
一、引言
炳灵寺石窟位于中国甘肃省临夏回族自治州永靖县境内,是中国著名的佛教石窟遗址之一,具有重要的文物研究价值。炳灵寺石窟开凿年代久远,由于很多文物部分或完全暴露在野外环境中,经过千年的风雨侵蚀,文物色彩甚至结构均不同程度存在缺失,尤其是凿刻于石壁中的浮雕和标志性的大佛,其色彩几乎已经完全褪去,因而对其进行数字化保护显得尤为重要。
对文物进行三维重建是文物数字化保护重要的组成部分,而文物数字化三维形态复原的质量在很大程度上取决于对于文物多视图间的特征点匹配。尽管已经有许多经典算法,如SIFT等能够取得良好的匹配结果,但对于在空间区域中出现大面积的纯色等弱纹理且视觉模式比较重复的石窟文物图像而言,其匹配效果欠佳[1-2]。随着深度学习技术在计算机视觉领域的广泛应用,许多算法利用深度学习模型来学习图像表示信息,并通过比较特征向量或分析特征信息来实现图像匹配,取得了比传统算法更加明显的效果,尤其针对弱纹理区域的情况。如SuperPoint是一种基于学习的局部特征匹配算法,利用的是神经网络学习图像中的关键点和描述子[3],对特征图中的关键点,在特征图上取一个固定大小的区域,并将其扁平化成一个向量,作为该关键点的描述子。然而,这些算法都强调在匹配之前明确检测关键点和计算描述子,因此在大规模训练数据时往往会受到计算资源的限制,其性能仍有较大的提升余地。DeepMatching是一种基于学习的端到端特征匹配算法[4],它利用神经网络学习图像之间的匹配关系,通过多层卷积叠加的方式来获取全局特征信息,因此将会付出较多的计算成本。结合上述方法所存在的问题,本文针对炳灵寺文物图像匹配任务,搭建了一个无法检测的局部特征匹配网络模型,在融合Transformer特征提取模块的前提下,充分利用其对于全局特征的感知能力,获取每个像素间的相关性得分[5],Linear Transformer能使计算复杂度有较大幅度的下降,且该模型采用由粗略到精细化的方法,输出的像素级匹配效果良好。经具体实验证明,本方法无论在单应性估计评价方面,还是在输出匹配数量方面,较其他方法均有明显的提升;且本方法不仅在炳灵寺石窟文物图像匹配应用中表现良好,对于普通室内外各类场景,也表现出良好的性能,具有很好的泛化能力。
二、图像匹配方法研究
图像匹配是诸如三维重建等三维计算机视觉任务的基础环节。给定要匹配的两幅图像,常见匹配方法包括三个阶段:特征检测、特征描述以及特征匹配。首先把各幅图像中检测类似角点作为兴趣点,然后在此类兴趣点的邻域提取局部描述符,产生具有描述符的兴趣点,最后根据最近邻搜索或其他匹配算法找到图像间的点对点对应关系。大多数情况下,特征检测算法能够满足任务要求。然而特征检测会减少可选的匹配空间,所得到的对应关系也比较稀疏。在特征检测环节还可能由于图像纹理信息匮乏导致图像模式单一等情况,从而很难获取足够的兴趣点,这个问题在石窟文物图像中尤为突出。
(一)SuperPoint深度学习网络模型
局部特征匹配算法SuperPoint利用了深度网络学习特征图中的关键点及描述算子,由一个类似于VGG网络的编码器和两个并行的解码器构成,编码器主要用于对输入图像进行下采样,而两个解码器分别用来提取特征点和特征描述子。每当图像样本被输入后,首先,通过卷积层提取图像的特征图;其次,在特征检测层中,使用非极大值抑制(Non-Maximum Suppression)选择具有最高响应的特征点作为关键点;再次,对每个关键点,在特征图上取一个固定大小的区域,并将其扁平化成一个向量,作为该关键点的描述子;最后,通过损失函数和训练数据来优化网络参数,提取的关键点和描述子能够更好地适应图像匹配任务。
(二)SuperGlue端到端网络模型
SuperGlue是一种图像匹配算法,旨在解决图像间几何关系的估计问题。作为对局部特征匹配算法的一种扩展,特别是对SuperPoint算法的进一步发展,SuperGlue采用了更综合的方法,不仅是匹配局部特征点,还考虑了这些点之间的全局几何关系。其创新之处在于将局部特征匹配与全局几何关系建模结合起来,提供了更全面的图像匹配解决方案。它在各种计算机视觉任务中具有广泛的应用,如三维重建、SLAM[6]等。其综合性能在许多情况下比传统的特征匹配算法更出色,特别是在存在较大视角变化和复杂场景的情况下。
(三)Transformer
Transformer可以作为一种编码器,由相互连接的注意力层构成,输入向量分别为Query(Q)、Key(K)和Value(V),其注意力层的运算机制如图1所示:
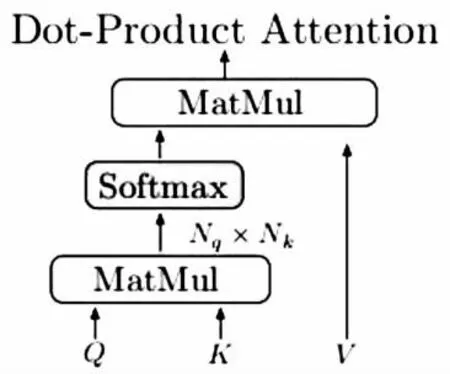
图1 注意力机制
并可以表示为:
Attention(Q,K,V)=softmax(QKT)V
(1)
注意力机制通过度量Query和Key之间的相似程度来获得关联度信息,最后的输出向量则由相似度得分矩阵与Value的加权获得。根据相似度的高低,将从Value向量中根据权重提取特征信息。
三、无检测特征匹配网络模型
笔者在认真研究SuperGlue后深受启发,使用含有Self-Attention和Cross-Attention的Transformer将backbone输出的密集局部特征进行转换[7]。首先以1/8的图像空间维度提取两组变换特征间的密集匹配,选择其中高置信度的匹配,然后利用相关性将所得匹配结果进行亚像素级细化。其次,利用Transformer的全局特征感知并引入位置编码使所得变换后的特征表达具备上下文和位置信息。通过重复的Self-Attention和Cross-Attention,笔者所搭建的网络模型通过Ground-Truth匹配中所显示的密度学习到具有全局一致性的匹配先验。最后,采用线性Transformer进一步将计算复杂度减少至可控水平,且其提供的全局特征提取能力使得在弱纹理区域产生比较密集的匹配效果。该网络模型由一个局部特征提取器串联一个粗粒度匹配模块及细粒度优化模块组成,下面将分别介绍各个组成部分。
(一)局部特征提取器

图2 局部特征提取器结构
(二)LoFTR局部特征转换模块
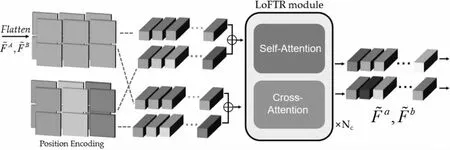
图3 局部特征转换模块结构
从图3可以看出,粗粒度特征经过flatten操作处理后,结合位置编码信息交由Nc个重复的LoFTR模块处理,所有相同结构的模块中均包含自注意力层和交叉注意力层。
1.Linear Transformer
相比普通注意力计算复杂度较高的情况,当Q、K均具有N个输入特征,而每个特征的长度都为D,则两矩阵相乘的复杂度为O(N2)。笔者采用计算复杂度相对简单的Linear Transformer作为相似度量的函数,其可以表示为:
sim(Q,K)=φ(Q)·φ(K)T
(2)
如此一来,便将计算复杂度降低为O(N),其中,
φ(·)=elu(·)+1
(3)
其结构如图4所示。

图4 Linear Attention计算机制
2.Position Encoding
笔者采用与DETR一致的Transformer位置编码,针对LoFTR的输入特征图进行位置编码[9],所不同的是,仅在输入LoFTR模块前一次性将编码信息添加到Backbone,而位置编码是以正弦表达形式为各个输入Token提供了唯一的位置信息,如此,LoFTR便会输出与特征位置相关的特征信息。
3.Self-Attention与Cross-Attention层
笔者采用与Transformer中相同的自注意力和交叉注意力层。
(三)粗粒度匹配
将LoFTR模块的输出结果导入可微匹配层[10],此处既可以使用SuperGlue的最优传输层OT,又能够采用Dual-Softmax操作计算LoFTR输出的特征相关性得分矩阵S[11],该过程可以表示为:
(4)
如果使用OT进行匹配操作,S则可作为局部分配成本矩阵,得到置信矩阵Pc。如果针对S的两个维度使用Softmax,则匹配概率矩阵Pc可以表示为:
Pc(i,j)=softmax(S(i,·))j·softmax(S(·,j))i
(5)
接下来便可以对匹配空间进行筛选了。根据置信度矩阵Pc,选择置信度高于阈值θc的匹配,进一步进行最近邻(MNN)[12]操作便会得到粗粒度级匹配。该粗粒度级匹配可以表示为:
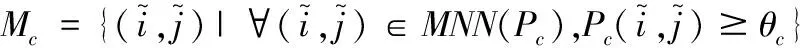
(6)
(四)从粗粒度到细粒度
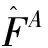
(五)损失函数
笔者采用的损失由粗粒度损失和细粒度损失构成,可以表示为:
L=Lc+Lf
(7)
1.粗粒度损失

(8)
2.细粒度损失
本文使用2范数作为细粒度损失:对于每个点计算由其生成的热图方差,以测量其确定性,使得细粒度化后的匹配结果的确定性较高,其加权损失函数可以表示为:
(9)
四、实验与评价
通过现场拍摄,笔者构建了一个自定义炳灵寺石窟文物图像数据集,该数据集图片内容包括石窟内的佛教建筑构件、佛教故事雕像、壁画及凿刻在石壁上的佛像和大佛雕像等文物图像等,这些图像内容在空间维度中均存在大面积的弱纹理区域和结构缺损的情况。该数据集共包含23个场景内容,且每个场景的视图数量介于4至20个之间,其部分样本如图5与图6。

图5 佛龛图像示例

图6 佛塔浮雕图像示例
笔者在对该图像数据集样本进行相关实验后,为了进一步验证笔者采用方法的先进性,又在HPatches公共数据集上进行实验以证实该方法的良好表现,最后使用相应的三维重建方法,在该方法的基础上对炳灵寺石窟文物进行三维形态恢复。实验机器所搭载的系统为Windows11,其具体硬件配置为CPU:12th Gen Intel(R) Core(TM) i7-12700F。内存16g,显卡为12g的显存Nvidia RTX3060型号。软件实验平台情况:并行计算环境为Cuda11.6,Python为3.7版本,Pytorch版本为1.9.1+cu111,Torchvision版本为0.10.1+cu111,OpenCV-Python 版本为3.4 .2 .17。
(一)在炳灵寺石窟文物图像上的特征点匹配实验
为了快速获得单应性评估结果,以初步验证该方法的性能,笔者先在炳灵寺石窟图像数据采集上开展实验。由于受到现场地形影响,手工拍摄采集的石窟图像无法保证其拍摄角度的规律性旋转,所以同一物体多视图图像的视角变化幅度较大。在这个实验环节,对于每一个场景,用一张随机选定的参考图像与其他剩余图像进行匹配运算,使用OpenCV中集成的RANSAC算法来量化单应性估计。相比于其他方法,该方法所产生的特征点匹配数量具有明显数量优势(图7、图8)。

图7 其他有检测匹配算法匹配结果示例

图8 本文无特征点检测匹配算法匹配结果示例
(二)在HPatches数据集上的实验
为了进一步证明方法的普适性,笔者在含有各类室内外普通场景图像的HPatches公共数据集上进行了更加具体的量化单应性估计结果。在使用RANSAC算法进行估计的基础之上,利用HPatches训练样本中的真值对匹配点进行拐点误差计算,将计算结果作为正确匹配的标准。详细的实验结果如表1。
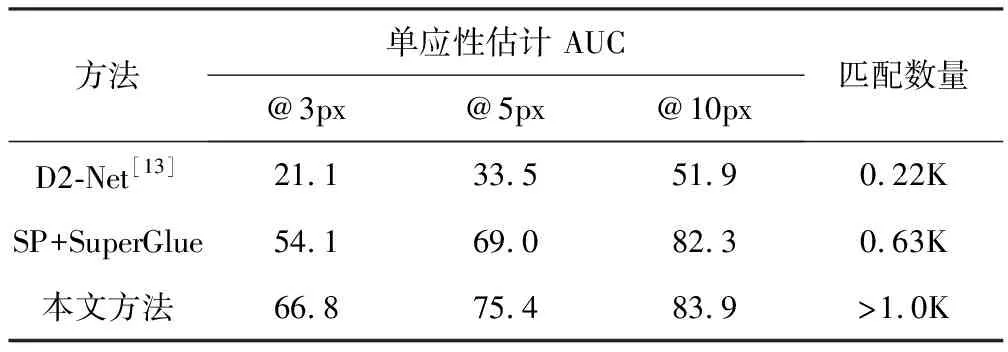
表1 在HPatches公共数据集上的实验结果
在表1中,AUC表示拐点误差曲线所构成的定积分面积,将误差阈值分别设置为3、5和10个像素。根据表1,可以看出,误差阈值在所设定的所有情况下,由于无特征点检测所提供的更多匹配选择和Transformer范式所输出的富含全局上下文的特征信息,以及Coarse-To-Fine模块进一步将匹配结果进行亚像素级细化以提高估计精度等措施,该方法比其他方法表现出明显的优势,匹配数量有很大幅度的提升。
五、结论
炳灵寺石窟作为重要历史遗迹,具有极高的研究价值。为了永久保存其客观空间形态并把它作为修复的原始参考,数字化保护和逆向三维形态复原显得尤为重要。在此过程中,图像匹配在三维形态复原中扮演着关键角色,匹配质量的好坏直接决定了三维重建的精度。笔者基于学习架构,引入了Transformer特征范式进行图像匹配,剔除繁琐的特征检测环节,提高了匹配效率和质量。实验结果证明,相比其他方法,该方法在处理弱纹理和图像模式重复等情况下具有显著优势,并在评价指标上表现出色。基于该方法恢复的石窟文物的三维立体形态不仅具有更高的保真度,还呈现出更出色的视觉效果,这对于炳灵寺石窟文物的保护和研究具有重要意义。
