基于概率球面判别分析的说话人识别信道补偿算法
2024-03-21景维鹏肖庆欣
景维鹏,肖庆欣,罗 辉
(东北林业大学 信息与计算机工程学院,哈尔滨 150006)
0 引言
说话人识别(Speaker recognition)技术也被称为声纹识别技术,是指通过分析处理采集到的语音信号识别相关说话人的身份,是语音处理领域最重要的技术之一[1]。经过50 余年的研究,说话人识别技术得到了很大的发展,研究者们相继提出了联合因子分析(Joint Factor Analysis,JFA)[2]、说话人身份矢量(i-vector)[3]和基于深度学习的说话人识别[4]等技术。说话人识别流程的如图1 所示。

图1 说话人识别流程Fig.1 Flowchart of speaker recognition
基于i-vector 的说话人识别系统是目前最有效的技术之一,它采用总变化空间(Total Variability Space,TVS)对说话人信息进行全局差异建模,不严格区分说话人信息和信道信息,减少了对训练语料的限制,且计算简单、性能优秀。
概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)[5]模型具有优秀的特征表示能力,通常用于基于i-vector 的说话人识别系统中的分类任务。PLDA 在跨域特征分类任务上有不错的表现[6],这取决于PLDA 假设本征音和本征信道满足高斯分布,但说话人特征分布存在很多非高斯行为,如果强行以高斯先验假设处理特征必然会损失特征中的说话人信息。目前,主要可以从特征端或判别模型端两个方面解决这一问题。在特征端,文献[7]中提出了特征长度归一化算法,该算法将空间Rd上的说话人特征通过高斯长度归一化到低维空间Sd-1上,通过多次迭代不断地对说话人特征进行高斯化规整,使得说话人特征分布不断趋向于高斯分布,取得了不错的效果。然而,只在特征级进行高斯变换操作,虽然减小了特征间单位尺度差异对模型的影响,但会在径向方向上破坏说话人类内特征结构,违背了PLDA 对类内分布的假设,使模型不能充分利用特征信息,影响模型性能。在判别分析模型端,文献[8]中提出的重尾PLDA(Heavy-Tailed PLDA,HT-PLDA)利用i-vector 模型中数据的长尾效应,统一用有更好拟合性的t-分布代替模型中先验分布和特征分布中的高斯分布,解决了说话人特征分布存非高斯特性的问题。文献[9]中提出一种概率球面判别分析(Probabilistic Spherical Discriminant Analysis,PSDA)模型,使用冯·米塞斯-费希尔(Von Mises-Fisher,VMF)分布代替高斯分布先验假设,保护了说话人特征结构不被破坏,有效提高了模型的性能。但这两种方法仅在判别分析模型更改了分布假设,并没有提出与该假设相对应的特征信道补偿方法,限制了模型的性能。考虑到特征级的信道补偿与判别分析模型的分布假设存在互相促进的关系,仅针对高斯分布进行特征级变换[7],以及仅通过变换判别分析模型的分布假设[8-9],并不能很好地解决判别分析模型中分布的先验假设与说话人特征真实分布不适配的问题。
基于上述分析,针对文献[9]方法不能有效处理不满足VMF 分布假设的说话人特征的问题,本文在该工作的基础上,提出基于概率球面判别分析的说话人识别信道补偿算法(Channel Compensation algorithm for speaker recognition based on PSDA,CC-PSDA),通过引入基于VMF 分布先验假设的概率判别分析模型,并在PSDA 基础上提出与之相应的VMF 特征长度归一化方法进行信道补偿(Channel Compensation,CC),在特征端和判别分析模型端完成互补,提高模型的识别性能。首先,在特征处理方面,本文对说话人特征进行仿射变换,使它更符合VMF 分布,由于VMF 分布能更好地描述特征空间内样本的角度分布,因此对音频的信道环境有不错的拟合效果。其次,采用基于VMF 分布的概率球面模型避免高斯特性对信道补偿的影响,模型将说话人特征定义到服从VMF 分布的特定维度超球面上,以保证基于VMF 长度归一化的信道补偿方法能保留说话人特征的类内分布,并能最大化特征区分度。本文算法可以增强特征的VMF 特性,使得判别模型发挥更好的效果;同时,本文根据模型特点提出CC-PSDA 的求解算法。大量相关实验证明,相较于传统的PLDA 模型,所提算法在性能上有不错的提升。
1 基线系统
1.1 i-vector技术与长度归一化
i-vector 是一种衍生于高斯混合模型(Gaussian Mixture Model,GMM)均值超矢量的具有统计特性的语音特征,一般被认为是说话人的身份标识。i-vector 采用总变化空间代替JAF 的说话人空间和信道空间。对于一段语音,通过Baum-Welch 统计量最终将说话人、信道相关的GMM 均值超矢量降维投影到固定长度的i-vector。为了去除信道信息对i-vector 的影响,通常还要进行信道补偿操作[10]。
给定语音段s,在T矩阵参数集条件下,i-vector 可以表示为:
其中:N(s)(s)表示语音段s的0阶、1 阶Baum-Welch 统计量,Σ表示T矩阵训练过程中产生的方差[11],I表示单位矩阵。尽管语音段长短可能不同,i-vector 可以将这些语音段用低维度且固定长度的ws来表示[12]。
为了解决i-vector 特征分布存在非高斯特性这一问题,使用长度归一化(Length Normalization,LN)方法规整特征分布。LN 方法主要分为两个步骤:首先,通过白化变换将i-vector 转换成球面对称分布簇;然后,对每个特征向量除以其对应的单位长度,使全部i-vector 向量长度都相等,从而使特征都映射在半径为1 的单位超球面上。这样可以将i-vector 分布近似的规整转化成更适合的高斯分布。
1.2 two-convariance PLDA
two-convariance PLDA[13]形式与标准PLDA 类似,广泛应用于说话人识别。假设某类说话人类别的某一样本为m,其生成过程框架可以表示为:
其中:x代表类间因子,用于表示每个说话人类别的虚拟类中心(x∼N(0,Φb));y代表类内因子,用于表示类别内部的样本分布分别代表类间和类内方差。类似于标准PLDA,two-convariance PLDA 的参数集也可以通过EM 算法估计得出。打分阶段通过训练模型规整转换计算,具体过程如下:
其中:same代表相同说话人,different代表不同说话人,表示待识别说话人因子表示注册因子。分子联合概率P{up,ug}可通过式(4)得到:
2 概率球面判别分析模型信道补偿
为了充分利用特征端和判别模型端的互补的关系,解决特征分布与判别模型先验假设不匹配的问题,本文提出基于概率球面判别分析的说话人识别信道补偿算法(CC-PSDA),该算法通过对说话人特征进行VMF 分布变换,以完成特征级信道补偿(CC),提高PSDA 模型[9]的性能。CC-PSDA 可用EM(Expectation Maximum)算法来求解参数集,并通过似然比的形式来打分。
2.1 Von Mises-Fisher分布
VMF 分布是一种圆上连续概率分布模型,是缠绕正态分布的一种近似,比高斯分布拥有更好的数学可控性。假设将空间Rd中长度归一化后的说话人特征投影到单位超球空间上有:
如果x∈Sd-1,则x分布在球面上;如果‖x‖<1,则x分布在球面内部。在CC-PSDA 模型中,用VMF 分布代替高斯分布。VMF 分布是一种圆上连续概率分布模型,x的概率密度函数为:
其中:μ表示均值向量方向(μ∈Sd-1);κ表示集中度,即分散度的倒数(κ≥0),Cv(κ)的表达式[14]如下:
其中:Iv(κ)是第一类修正贝塞尔函数,单调递增;Cv(κ)是严格单调递减的函数在VMF 分布中,κ类似于正态分布中的σ2,κ越小分布越均匀,直到κ=0 时满足均匀的超球面分布;相反,κ越大分布越集中于μ。根据文献[9],可以得到式(8):
2.2 特征分布变换
考虑到提取到的i-vector 特征的分布不符合VMF 先验假设,因此需要将它的分布转换为VMF 分布,从而在分类模型中发挥更好的性能。本文通过最大似然估计得到相应的概率密度函数。
文献[15]中给出了一种sinh-arcsinh 分布:
通过改变相应的参数便可执行相关变换,例如相应的偏斜变换或重尾对称等,该分布可以将提取到的特征的分布变换成预期的分布,它的概率密度函数为:
其中:A代表特征变换映射矩阵,x代表待变换向量,b代表偏置向量。仿射函数的本质反映了一种空间映射关系。函数式(14)的雅可比矩阵可表示为:
首先分别求出sinh-arcsinh 中每个参数的导数的对角矩阵:
然后可得到雅可比行列式的对数行列式:
将式(17)作为目标函数通过L-BFGS 算法不断迭代,计算出对数似然的最大化,当对数似然指标改善低于所设定的阈值时,可以完成参数估计。
根据文献[16]中的结论可以得知,sinh-arcsinh 分布中δ、ε分别用来控制分布的重尾以及变量的偏度,因此可以通过实验改变这两个参数实现对预期分布的映射变换。
2.3 概率球面判别分析模型
对于每个说话人设置一个身份隐变量z(z∈Sd-1),身份变量具有VMF 先验v(z|μ,b),μ表示说话人特征向量均值方向(μ∈Sd-1),b表示说话人类间集中度(b≥0)[17],代表特征项在不同说话人类别中的均匀程度,特征项越集中分布在某个类别中而不是均匀分布在各个类中时,带有的类别信息越多,表征类别的能力越强。类似PLDA,μ和b可以通过数据学习得到。Sd-1中的观测数据特征都应服从说话人独立的VMF 分布,来自不同说话人的特征是条件独立的,给定z,如果是某个说话人的特征,则有:
其中ω表示说话人类间集中度(ω>0)。式(18)表明:观测数据VMF 分布的乘积是z的似然函数,其中z也满足VMF 分布。综上:CC-PSDA 模型的参数集为{μ,b,ω}。
CC-PSDA 的打分公式与高斯PLDA 类似,也是似然比的形式。给定一个训练完成的CC-PSDA 模型(参数集为{μ,b,ω}),假设E={e1,e2,…,em}表示某一说话人的注册集、T={t1,t2,…,tn}表示某一说话人的测试集,打分似然比公式可以表示为:
其中:H1代表语音段来自同一说话人,H2代表语音段来自不同说话人。式(20)还可以只用VMF 归一化常数来表示:
模型所需要的统计信息为0 阶统计量和1 阶统计量,用EM 算法更新参数[20],对于给定的训练数据,每个说话人均值特征为,说话人身份分布信息有效地包含在了内,数据总数为,说话人数为S,E 步骤[21]:
CC-PSDA 完整算法的伪代码如算法1 所示,流程如图2所示。

图2 CC-PSDA流程Fig.2 Flowchart of CC-PSDA
算法1 基于概率球面判别分析的说话人信道补偿算法(CC-PSDA)。
输入 i-vector 特征集X={xi},识别任务迭代次数I1,CC-PSDA 分类模型迭代次数I2;
输出 CC-PSDA 模型的参数集{μ,b,ω},相关说话人语音特征的似然比p。
3 实验与结果分析
本文进行了广泛的实验解答以下问题:
问题1 在识别准确率方面,本文方法与目前流行的评分方法尤其是高斯PLDA 方法相比如何?
问题2 仅对后端分类模型的分布先验假设进行改进与对特征级和后端分类模型同时进行先验假设改进效果相比如何?
问题3 在相同的VMF 概率球面判别分析模型条件下,本文方法中的VMF 特征分布变换是否有利于模型的求解?
3.1 数据集、预处理及评价指标
本文使用VoxCeleb2-dev 数据集进行训练,该数据集包含1 092 009 段语音和5 994 个说话人。为了评估模型的有效性,使用VoxCeleb1-O、VoxCeleb1-E 和VoxCeleb1-H 三个测试集进行验证实验。VoxCeleb1-O 测试集是在VoxCeleb1 数据集中采集的,包含40 个说话人共37 720 个语音测试对,VoxCeleb1-E 是VoxCeleb1-O 的扩展,包含1 251 个说话人共581 480 组测试对,VoxCeleb1-H 包含552 536 个测试对,每对测试中都选取了国籍和性别相同的说话人,相对更难一些[23]。
在i-vector 说话人识别模型中,通常使用梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)作为声学特征进行实验[12,23],实验中提取13 维的MFCC 基本特征作为输入信息,之后对它进行一阶差分、二阶差分计算,最后得到60 维声学特征,提取特征前进行语音静音检测,去除音频中不包含信息的静音部分[24]。本文分别提取了100 维、200 维、400维的i-vector 特征,在不同系统进行实验。实验的识别准确性采用等错误率(Equal Error Rate,EER)和最小检测代价函数(Minimum Detection Cost Function,MinDCF)作为标准。
3.2 识别效果总体比较(问题1、问题2)
表1~3展示了5个模型分别在VoxCeleb1-O、VoxCeleb1-E、VoxCeleb1-H 这3 个测试数据集上的识别性能验证结果,CCPSDA 为本文模型、PLDA 为高斯PLDA 长度归一化方法模型、HT-PLDA 为说话人因子和特征空间采用t 分布假设的重尾分布PLDA、cos[25]为余弦相似度打分后端、PSDA 为未采用VMF 特征分布变换信道补偿的概率球面判别分析模型,从表中可知:

表1 VoxCeleb1-O测试集下各模型识别性能对比Tab.1 Comparison of recognition performance among various models on VoxCeleb1-O test set
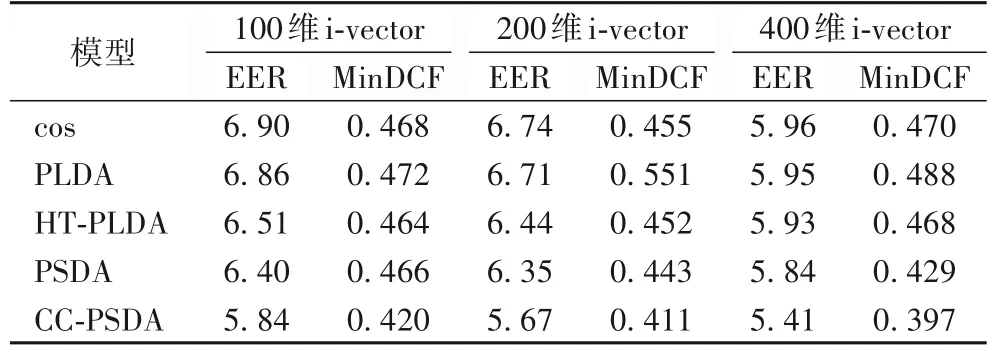
表2 Voxceleb1-E测试集下各模型识别性能对比Tab.2 Comparison of recognition performance among various models on VoxCeleb1-E test set
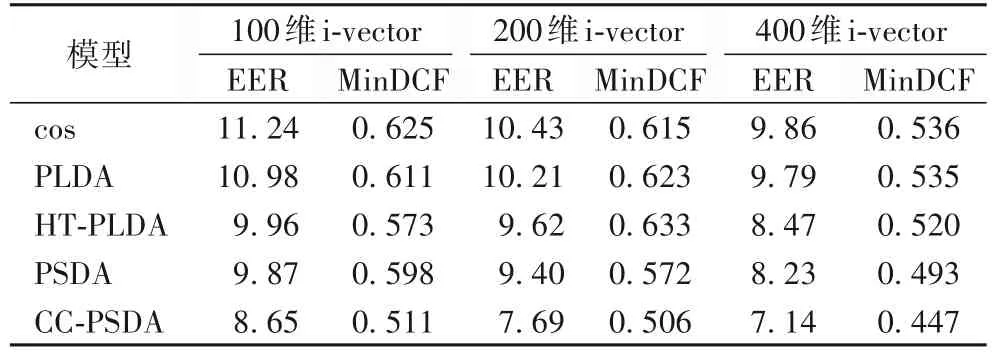
表3 Voxceleb1-H测试集下各模型识别性能对比Tab.3 Comparison of recognition performance among various models on VoxCeleb1-H test set
1)在VoxCeleb1-O、VoxCeleb1-E、VoxCeleb1-H 这3 个测试集下,本文CC-PSDA 模型效果最好,验证了本文模型的有效性;其次是PSDA 模型;高斯PLDA 模型表现最差。PSDA模型相较于传统基线模型性能也有所提升,这是因为基于VMF 分布假设的球面模型不像高斯PLDA 模型一样,在长度归一化时压缩说话人特征的径向维度,以获得更多的说话人特征径向维度的信息。本文模型相较于目前较为流行的cos模型有较大提升,主要原因在于CC-PSDA 模型训练时,可通过监督学习的方式很好地利用训练数据的说话人标签信息,从而得到更具有区分性的参数。同时,由于CC-PSDA 模型相较于cos 模型有更多的模型参数可以学习,因此CC-PSDA模型具有更强的特征表征能力,从而具有更好的分类性能。HT-PLDA 模型通过使用t 分布代替高斯分布假设,一定程度上减小了特征分布中非高斯特性带来的影响,相较于高斯PLDA 模型,性能略有提升。CC-PSDA 模型相较于PSDA 模型识别准确率有了较明显的提升,可以证明本文模型进行VMF 特征分布变换操作后,i-vector 分布假设更加拟合球面分类模型的先验假设,可以更准确地计算说话人隐变量的后验概率,有利于提高模型对特征的分类能力。
2)五种模型等错误率在不同特征维度条件下的标准差分别为:CC-PSDA 为0.178、PLDA 为0.260、HT-PLDA 为0.411、cos 为0.382、PSDA 为0.210,本文CC-PSDA 模型对特征维度变化最不敏感。随着i-vector 维度的提升,各个模型的识别准确率也相应提升。使用较大维度的特征模型时,经过特征变换的特征能包含更多的说话人及相关信道信息,识别性能会相应提高。
3)五种模型在VoxCeleb1-O、VoxCeleb1-E、VoxCeleb1-H三个测试集下等错误率的标准差分别为:CC-PSDA 为0.06、PLDA 为1.81、HT-PLDA 为2.45、cos 为2.06、PSDA 为0.20,CC-PSDA 的EER 标准偏差最小,在不同数据集下具有更好的稳定性。
为了验证本文模型在深度学习方法中的效果,使用VoxCeleb2-dev 作为训练集、Voxceleb1-H 作为测试集,使用时延神经网络(Time Delay Neural Network,TDNN)提取256 维的x-vector[26]说话人特征在不同模型上实验[4],结果如表4 所示。当使用深度学习说话人特征时,cos 模型效果优于高斯PLDA 模型,并且由于cos 模型自然遵循球面几何特性,效果与PSDA 模型接近。尽管如此,本文的CC-PSDA 模型取得了最好的效果,说明了本文模型在深度学习框架下有效。

表4 x-vector说话人特征各模型识别性能对比Tab.4 Comparison of recognition performance of various models using x-vector speaker features
本文还在3 个测试集下,模拟了i-vector 均值特征经过CC-PSDA 中特征变换前后的分布状态。图3 展示了3 个测试集200 维i-vector 均值特征变换前后的分布情况。
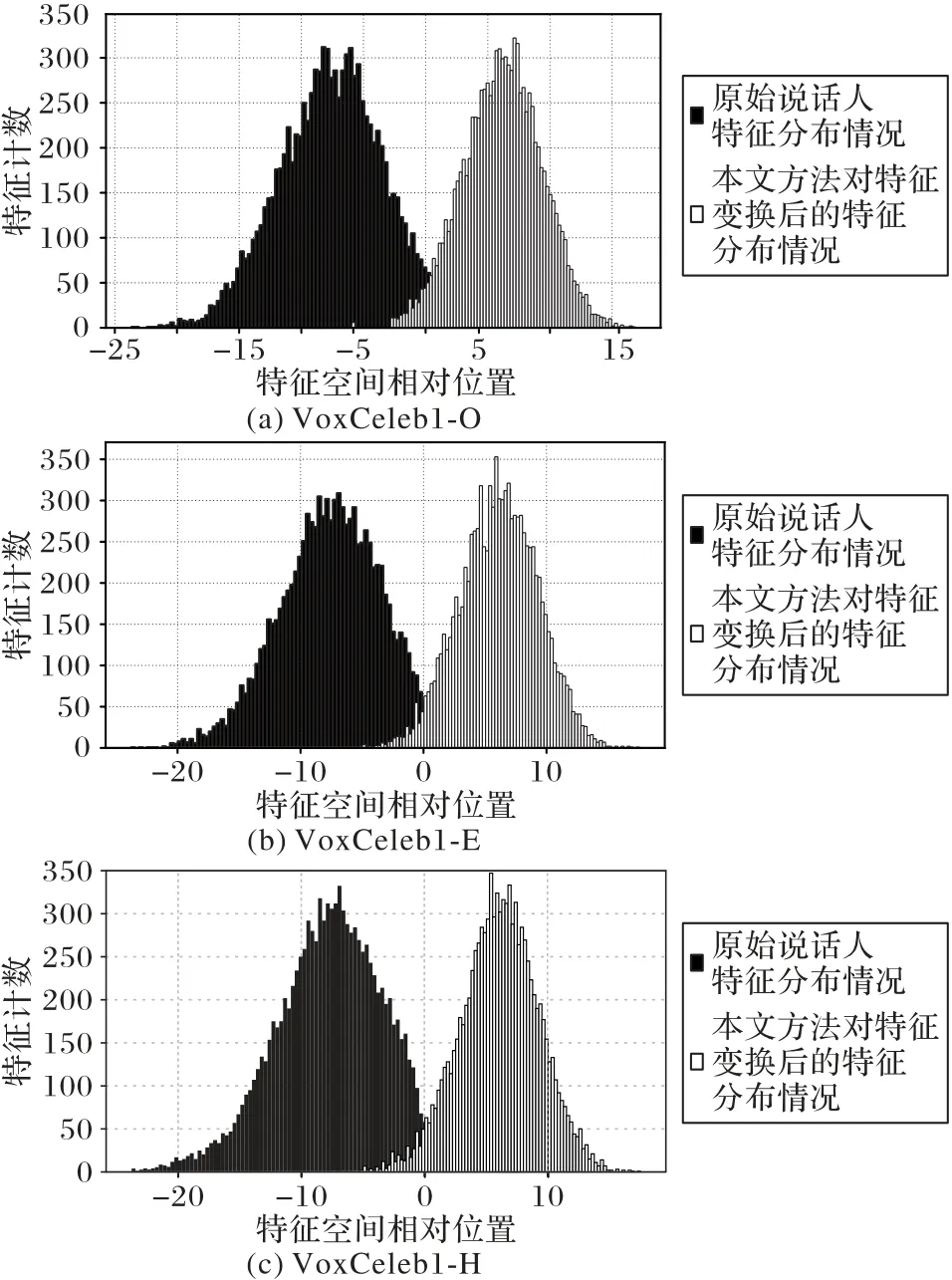
图3 不同测试集下i-vector特征变换前后分布情况Fig.3 Distribution of i-vector before and after feature transformation in different test sets
从图3 中可知,三组实验中变换后的说话人特征均大致服从VMF 单峰分布,且分布更集中,便于模型进行概率计算。
3.3 特征分布变换对模型求解的影响(问题3)
为了探究VMF特征分布变换操作对概率球面判别分析模型求解的影响,本文还在3 个数据集下,取200 维i-vector 说话人特征和相同初始类内、类间参数的条件下设计了两组实验。
1)首先对记录了本文2.3 节中的模型类间集中度b的更新情况,如表5 所示:实验均取b=100 作为实验初值,实验进行10 轮迭代。类间集中度代表不同类别说话人特征的聚集情况,即特征项在各个类别中分布的均匀程度,越小表明模型对说话人特征的分类效果越好。从表5 中可知,在3 个测试集下,使用经过分布变换后的特征训练模型可以得到更小的类间集中度,表明本文提出的VMF 特征分布变换操作有利于模型的收敛。
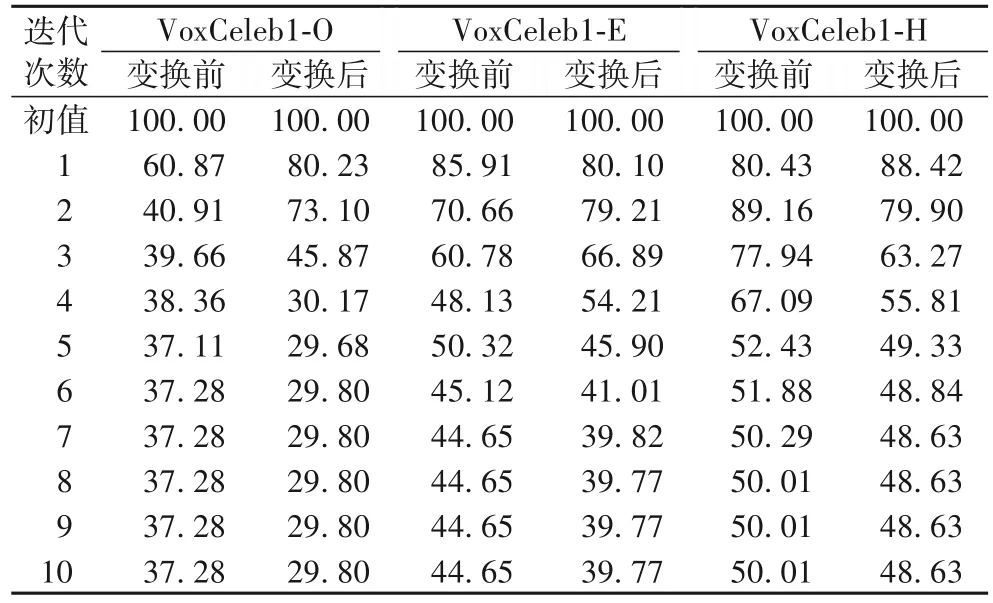
表5 CC-PSDA在各测试集下EM算法类间集中度b更新情况Tab.5 Update of between-class concentration parameter b in EM algorithm for CC-PSDA on different test sets
2)最后在相同模型参数初值条件下,模拟本文使用的训练算法EM 算法的训练情况,主要观测它的收敛速度。
图4 展示了用变换前后的i-vector 特征使用EM 算法对模型训练的情况。对比图4 可以得出结论,本文模型可以通过训练EM 算法,并使用经过分布变换后的特征使模型收敛更快。
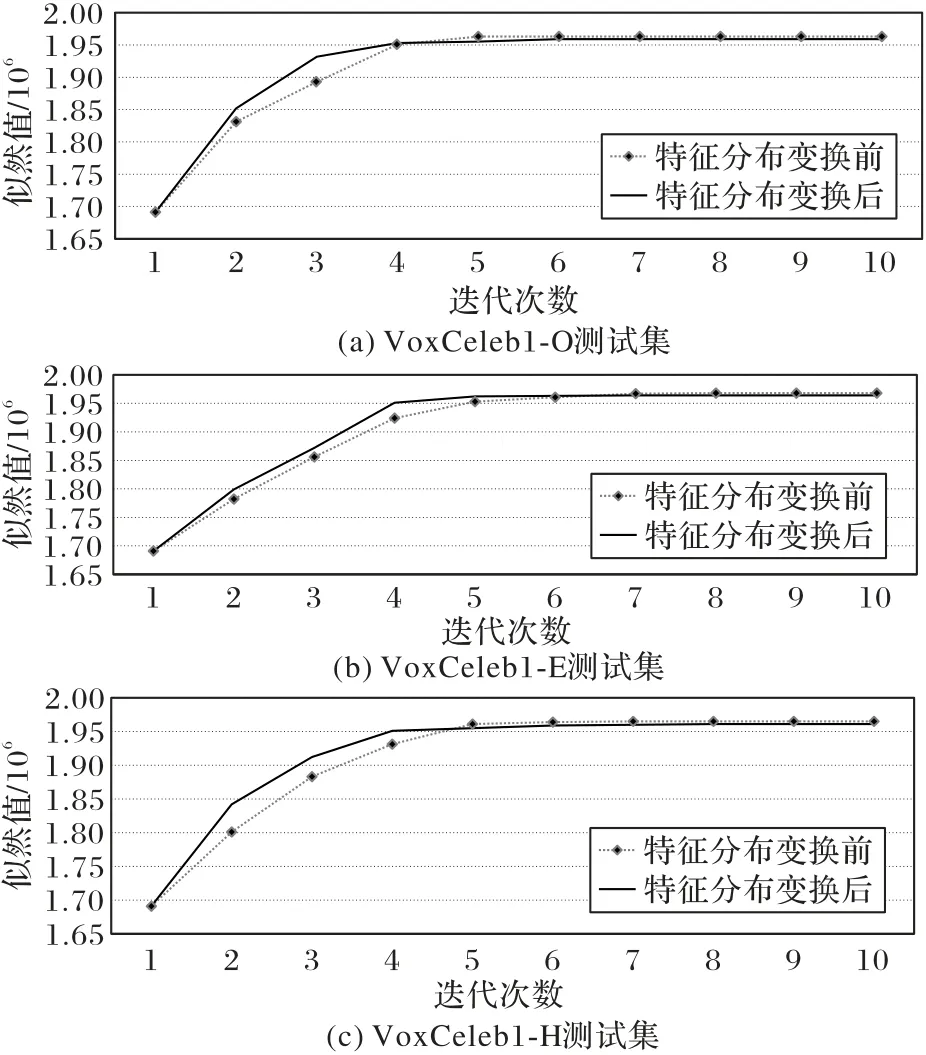
图4 不同测试集下CC-PSDA特征变换前后EM算法训练情况Fig.4 EM algorithm training before and after CC-PSDA feature transformation in different test sets
4 结语
在说话人识别任务中,由于上游任务提取的说话人特征分布总会存在许多后端分类模型分布先验假设以外的特性,因此,协调好说话人特征归一化分布假设与后端分类模型的先验假设是提高系统识别效率的关键。本文介绍了一种基于VMF 分布的概率球面判别分析的说话人信道补偿算法,理论和大量实验分析都表明所提算法能有效克服目前高斯PLDA 存在的弊端。本文算法能对说话人特征非线性变换,使它更适合分类模型的VMF 分布,这与后端概率球面判别分析模型先验假设相呼应,变换后的特征结构不受球面模型的影响,从而被更好地利用。同时,后端分类模型能将变换后的特征定义到服从VMF 分布的特定维度超球面上,最大化说话人特征类间距离,获得更好的识别性能。
