基于请求与应答通信机制和局部注意力机制的多机器人强化学习路径规划方法
2024-03-21邓辅秦官桧锋谭朝恩付兰慧王宏民林天麟张建民
邓辅秦,官桧锋,谭朝恩,付兰慧,王宏民,林天麟,张建民*
(1.五邑大学 智能制造学部,广东 江门 529000;2.香港中文大学(深圳)深圳市人工智能与机器人研究院,广东 深圳 518000;3.深圳市杉川机器人有限公司,广东 深圳 518000)
0 引言
随着时代的进步,电商、物流、户外搜索等行业的大力发展越来越离不开多机器人系统,而多机器人路径规划(Multi-Agent Path Finding,MAPF)是多机器人系统的重要组成部分[1]。MAPF 旨在为全部机器人规划出少阻塞甚至无阻塞的一组路径,一些基于图节点结构的搜索方法如A*、基于碰撞的搜索(Conflict Based Search,CBS)、D*Lite 在简单、拥挤程度低的非动态环境具有较高的求解效率[2-6]。然而,在一些特定的场景(如过道拥挤的动态仓储环境、灾后搜索等障碍物无规则分布的复杂环境),上述方法存在两个主要问题:1)机器人难以对周围的动态环境建模;2)机器人因为缺少信息交互而规划出不协调的动作策略。
随着深度学习在图像领域的快速发展,结合深度学习的深度强化学习方法能够使用卷积神经网络(Convolutional Neural Network,CNN)等图像处理技术对动态环境进行图像化建模,此外,基于神经网络支持多维信息输入的特性,设计进行信息交互的神经网络架构,故而在一系列决策任务中获得显著的成功,如游戏领域和多机器人路径规划领域[7-9]。虽然每个机器人能够利用CNN 对其视野进行特征提取,但是该网络缺乏高效的信息传递功能。
有效的沟通是合作成功的关键,近年来,一些方法如VDN(Value-Decomposition Network)[10]、QMIX[11-12]、QTRAN[13]学习每个机器人的独立Q 函数,并使用混合网络将这些局部状态行动值(Q 值)组合成全局状态行动值,进行一定的信息传递实现对动作策略的优化。上述方法属于集中式的方法,能融合所有机器人的信息参与决策,但也会带来冗余的信息,增加方法计算量。因此,如何为每个机器人提供本身所需的精准信息并降低网络计算量,成为重要研究方向。
为了降低多机器人路径规划的阻塞率,本文基于Actor-Critic 架构提出一种分布式请求与应答通信机制与局部注意力机制的多机器人深度强化学习路径规划方法(Distributed Communication and local Attention based Multi-Agent Path Finding,DCAMAPF)。针对机器人间信息传递效率不高、难以精确获得所需信息的问题,本文设计一种基于请求与应答机制的Actor 网络。如图1 所示,以3 号机器人为例,3 号机器人请求视野范围(灰色)其他机器人的局部观测和动作信息,并主动获取动态障碍物的相对位置信息,其中2、8、9 号机器人及时反馈信息。5 号机器人由于距离较远、传输迟延等导致信息传输超时,而本文的Actor 网络能自动屏蔽传输超时带给CNN 的影响。与此同时,3 号机器人也会主动感知视野内的动态障碍物,获得其动态障碍物的相对位置,作为本机器人局部观测信息的一部分。最终,将应答的信息和本机信息一起输入Actor 网络,进而规划出3 号机器人的动作策略。针对全局注意力机制带来的冗余信息的问题,本文提出基于局部注意力机制的Critic 网络,该网络能将注意力权重动态分配给视野内的其他机器人,降低计算量。

图1 请求与应答机制(以3号机器人为例)Fig.1 Request-response mechanism(taking robot No.3 as example)
相较于最新的路径规划方法如基于进化方法与强化学习的多机器人路径规划(Multi-Agent Path Planning with Evolutionary Reinforcement learning,MAPPER)[14]、动态环境下基于注意力机制与BicNet 通信模块的多机器人路径规划方法(Attention and BicNet based MAPPER,AB-MAPPER)[15],本文的主要工作为:
1)设计一种基于请求与应答通信机制的Actor 网络,机器人请求视野内其他机器人的状态信息与最新的动作信息,使机器人能获得精确的局部观测-动作信息,规划出协调的动作,提高机器人的避障能力。
2)设计一种基于局部注意力机制的Critic网络,机器人能够将注意力权重动态分配给视野内的其他机器人,相较于全局注意力网络,本文的Critic 网络缩小注意力权重的分配范围,降低注意力权重的计算量,将权重分配给更该注意的周围机器人,提高策略优化的效率,减少显卡缓存的占用量。
3)与传统动态路径规划方法D*Lite、最新的分布式强化学习方法MAPPER 和最新的集中式强化学习方法AB-MAPPER 相比:DCAMAPF 在离散初始化环境,阻塞率均值约减小了6.91、4.97 和3.56 个百分点。在集中区域初始化环境下能更高效地避免发生阻塞,阻塞率均值约减小了15.86、11.71、5.54 个百分点,并降低占用的计算缓存。
1 相关工作
1.1 通信类强化学习方法
沟通有助于学习他人的经验并传递知识,以更好地在团队中工作,是形成智能的一个基本要素。在多机器人强化学习中,机间通信允许多个机器人通过合作完成共同目标。在部分可观察的环境中,多机器人能够通过通信分享它们从观察视野中获得的信息,规划出更优的策略。
近年来的深度强化学习方法普遍基于Actor-Critic 架构,该架构由两部分组成:Actor 网络负责规划动作策略;Critic网络负责以Q 值的形式评估Actor 规划出的动作策略,机器人每执行完一次动作策略,都会进行一次策略的优化,因此能快速提高方法收敛的速度。
Liu等[14]提出了MAPPER,每个机器人用图像化建模的方式对视野内的环境信息进行表征。基于进化方法在迭代一定次数后将挑选一个最大奖励值的机器人所属的网络模型替换一些奖励值低的机器人网络模型,在一定程度上进行了信息传递,该机制使该方法在动态拥挤环境下的路径规划效率比近年较为经典的方法基于强化学习与模仿学习的路径规划方法(Pathfinding via Reinforcement and Imitation Multi-Agent Learning-Lifelong,PRIMAL2)方法[9]更高,因此,MAPPER 成为最新的多机器人强化学习路径规划方法,也是本文的对比方法之一。
通过替换网络模型属于一种规划后信息交互的模式,这虽然能提高方法的收敛速度,但却不能使机器人在规划动作策略前获得更精确的信息,不能为机器人规划出阻塞率更低的动作策略。
1.2 集中式的信息传递强化学习方法
多机器人强化学习中大多数现有的通信工作都集中于广播式通信,即将每个机器人的信息广播到所有其他或预定义的机器人 。Sukhbaatar 等[16]提出了 CommNet(Communication Neural Net),每个机器人需要在一个公共的通道传播一个通信向量,通过这个通道各自接收其他机器人汇总的通信向量。在合作任务中,该网络提高了机器人的协作能力。然而,CommNet 对所有机器人的通信向量做算术平均操作,这意味着它将不同机器人的信息看作等价。由于CommNet 的公共通道将所有机器人的信息传达给每一个机器人,每个机器人被动接收大量冗余信息,因此不适用于解决局部路径冲突的路径规划任务。类似地,Peng 等[17]提出了基于双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)神经网络的 BicNet(Multiagent Bidirectionally-coordinated Nets)通信网络,与CommNet 要进行信息聚合不同,BicNet 是一种集中式的网络,信息只在Actor 和Critic 网络内流通,不会聚合,所有接入BicNet 的机器人都能接收其他机器人的信息。此外,LSTM 的门控机制使它能自主决定是否接收传递的信息以规划动作,提高了通信的效率。Kim 等[18]提出了SchedNet 方法,该方法在Actor网络上搭建了一个调度器模块,该调度器模块学习如何对机器人的局部观测赋予权重进而在有限的通信带宽下挑选最有利的局部观测信息规划动作。
1.3 分布式信息传递强化学习在Actor网络的优化
上述隶属于集中式的网络模型虽然在一定程度上解决了机器人的通信问题,但普遍需要所有机器人的局部观测信息作为输入,导致方法难以在较多的冗余信息中甄别强相关信息,缺乏灵活性。随着机器人数的增加,集中式方法难以从全局共享的信息中区分有助于合作决策的有价值信息[19]。
为了提高通信的灵活性,更精准地获取其他机器人的相关信息,Jiang 等[19]提出了ATOC(ATtentional Communication)方法,该方法的Actor 网络部分通过一个注意力模块对视野内的其他机器人赋予权重,决定该机器人是否允许通信,从而选择相应的协作者。在选择协作者时,通信发起者依据距离依次在没有被选择过的机器人、别的发起者的协作者、别的发起者三个类别的机器人中选择一个作为协作者,获得了较为精准的信息,提高了通信的效率。类似地,有针对性的通信是提高通信效率的关键,Das 等[20]提出了TarMAC(Targeted Multi-Agent Communication)方法,该方法的Actor 网络使用了注意力机制,信息发送方发送通信向量,在接收端的每个机器人会预测一个询问向量,询问向量将与所有通信向量进行点乘操作,其结果用归一化处理之后采用Softmax函数得到每个通信向量的注意力权重,当通信向量与询问向量相似时,注意力权重则比较高,实现有针对性的通信。Ding 等[21]提出了I2C(Individually Inferred Communication)方法,该方法的Actor 部分包含一个输出置信度的优先级网络,该优先级网络决定视野内哪些机器人需要进行通信,随后,通信发起者请求获取被赋予置信度机器人的局部观测信息,通信接收方应答发起者,实现点对点的通信,进一步提高通信效率。受I2C 网络启发,本文的Actor 网络虽基于请求与应答机制,但与上述方法不同,本文的Actor 网络不仅基于请求与应答机制获取局部观测信息,还会获取其他机器人最新的动作信息,并在规划动作策略前参考其他机器人的动作信息,因此能降低机器人的阻塞率,提高路径规划的效率。
1.4 强化学习方法在Critic网络的优化
策略的评估和优化是提高机器人学习能力的关键,在Actor-Critic 架构中,Critic 网络用于策略的评价。Parnika等[22]设计的基于注意力机制的Critic 网络将注意力权重分配到所有机器人的局部观测和动作信息上,并学习如何将较大的权重分配给需要关注的机器人。在AB-MAPPER 中,也使用基于注意力机制的Critic 网络学习如何对机器人的局部观测信息和动作信息赋予权重[15]。然而上述方法使用的是集中式的方法架构,每个机器人基于Critic 网络进行策略评判时,需要其余所有机器人的局部观测和动作信息,在机器人数较少时,注意力权重的分配范围较小,注意力权重不会被稀释;然而,随着机器人数的增加,集中式网络被输入更多信息,注意力权重的分配范围也会逐渐扩大,导致注意力权重被稀释得越来越小,网络难以区分哪些信息更需关注,不利于策略的优化。
事实上,只有周围其他机器人的动作才会影响到当前机器人的决策,其他距离较远的机器人的局部观测信息和动作信息不仅对当前机器人的决策没有帮助,反而会带来冗余信息,干扰当前机器人的决策和策略优化。
为了降低冗余信息的干扰,Liu 等[23]在池化层与卷积层之间引入局部注意力网络,有效增强了抑制无用特征的能力。类似地,本文为了降低冗余信息的干扰,基于请求与应答机制通信机制与局部注意力机制,将注意力权重只分配给应答成功的机器人,缩小Critic 网络中注意力权重的分配范围,不仅避免了冗余信息的干扰,还利用具有较强相关性机器人的信息参与策略优化,减少了显卡缓存的占用量,提高了路径规划的效率。
2 本文方法
本文将机器人与环境的交互过程建模为部分可观测马尔可夫决策过程(S,A,P,R,O,M,γ),其中S是状态空间,A是动作空间,P:S×A×S→[0,1]表示状态转移概率,R:S×A→R为奖励函数,O代表局部观测,M代表状态转移概率矩阵,γ是奖励折扣因子[24-25]。类似PRIMAL2和MAPPER 中的环境建模方法,本文将环境的局部观测由3 个有限视野(15×15 网格大小,如图1 浅灰色区域)的观测图像组成,分别对应图2(a)中每个机器人的局部观测(Observation)Oi由3 个矩阵构成。第1 个矩阵存储当前观察到的静态障碍物、周围其他机器人和动态障碍物的相对位置,这些位置由不同的值表示;第2 个矩阵记录了周围其他机器人和动态障碍物的轨迹,对时间序列信息进行了编码;第3 个矩阵记录了当前机器人基于静态环境图通过A*方法规划的局部参考路径。Maxpool为最大池化层,FCN(Fully Convolutional Network)为全连接网络,MLP(Multilayer Perceptron)为多层感知机,Dummy 为反馈动作信息失败的机器人设置的无效动作向量,以保证网络能够正常运算。由于Actor-Critic 框架可以帮助强化学习方法通过当前策略的梯度有效地更新策略,适用于路径规划中的实时决策任务[26],因此本文使用Actor-Critic 架构。
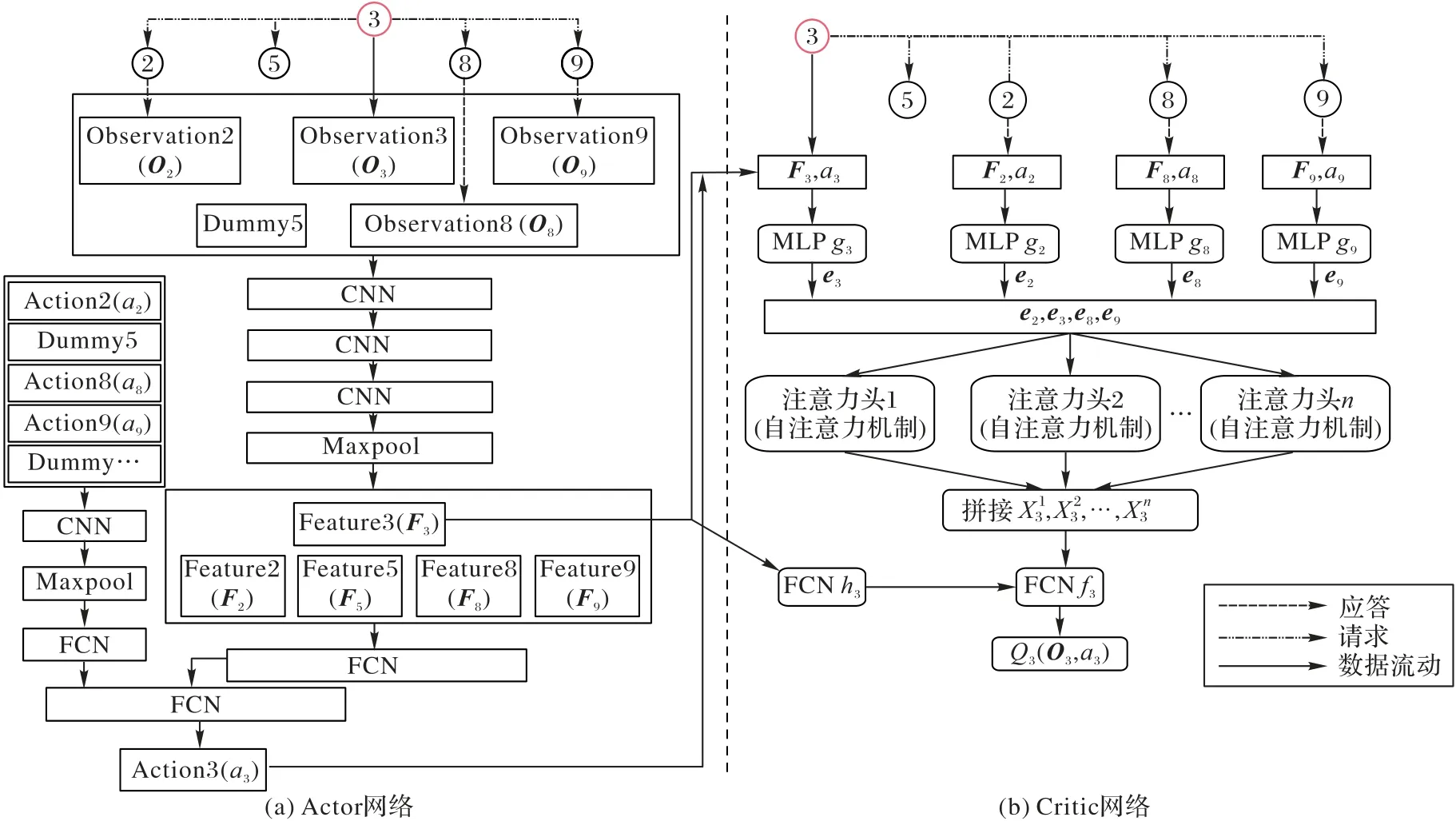
图2 DCAMAPF网络架构Fig.2 Network architecture of DCAMAPF
基于集中式网络架构的方法在获取所有接入该网络的机器人信息后,才能统一为所有机器人进行信息的数值计算,该类方法在通信时延小、机器人数较少的情况下具有能与其他机器人充分传递信息的优势;然而,随着机器人数的增多,信息流通存在计算量大、冗余信息多、无法为每个机器人精准获取所需信息等问题。分布式网络无须基于所有机器人的信息参与决策,每个机器人都有独属自己的方法网络,能灵活地进行决策和优化,因此,将方法网络模型进行分布式设计是一个可行方向。
本文方法主要分为三步:首先,基于请求与应答机制,机器人对视野内的其他机器人发送请求,请求它们的局部观测以及最新动作信息,其他机器人在限定的时间内回应;其次,该机器人的Actor 网络分别用两种不同维度的CNN 对反馈的局部观测信息和动作信息进行特征提取,进而规划动作;最后,对于每一个机器人,基于局部注意力机制的Critic 网络在请求与应答机制下将注意力权重动态分配到视野内成功应答本机器人的其他机器人局部观测-动作信息上。
本文将Actor 网络进行分布式设计,机器人之间的信息传递采用请求与应答机制,如图2(a)所示,具体在Actor 网络的改进如下:1)每个机器人在规划动作前先获取在本机器人视野里其他机器人的编号,并向它发送请求,期望获取它的局部观测信息(三维矩阵)和动作信息(a)i。2)视野内的机器人接收请求,并作出应答,反馈自己的局部观测信息和动作信息。3)在规定时间内,机器人接收应答成功的机器人的局部观测信息和动作信息,结合本身的局部观测信息一并输入到卷积神经网络,最终规划出本机器人的动作策略。基于请求与应答机制的通信机制,既能捕获周围机器人的局部观测信息以及动作信息、又不需要像集中式网络汇集所有信息才能规划策略,因此能提高信息传递的效率、利用更加精准的信息规划出更优的动作策略。
在MAPPER 方法的Critic 网络中,每个机器人只基于自己的局部观测信息和动作信息进行评判,缺少与其他机器人进行信息传递,难以对机器人的策略进行充分的评判。在AB-MAPPER 中,每个机器人使用基于注意力机制的Critic 网络将注意力权重分配到所有机器人的局部观测信息和动作信息中,评判出Q 值,意味着注意力机制的分配范围是全部机器人,换言之,该方法容易增加一些冗余信息,不利于策略的优化。此外,为了对局部观测信息和动作信息进行编码,也需要更多的编码网络,这导致Critic 网络承担更大的计算量以及需要更多的缓存。
注意力机制可以被描述成可查询的键-值记忆模型,如图3 所示,有3 个要素query(q)、key(k)、value(v)[22],这3 个要素实质上都是矩阵,通过式(1)计算出注意力权重矩阵ω:

图3 注意力机制Fig.3 Attention mechanism
其中dk是k的维度。
本文设计了更加灵活的局部注意力网络,如图2(b)所示,本文以3 号机器人为例,3 号机器人只请求在其视野范围内的其他机器人(2、5、8、9)最新的局部观测信息和动作信息;随后,在指定时间间隔内,其他机器人反馈回来的局部观测信息和动作信息会将输入单独的多层感知机(MultiLayer Perceptron,MLP)进行编码,得到状态动作编码(e2,e8,e9)。在本文中,k和v是状态动作编码即本文的e,q是状态编码即本文的F。每个注意力头都是自注意力网络,X3是vj的权重乘积和,j是成功应答3 号机器人的其他机器人编号集合,如式(2)所示:
ω3是3 号机器人分配给2、8、9 号机器人的注意力权重,如式(3)所示:
其中:F3是3 号机器人的状态编码。f是一层全连接网络,h是多层感知机,最终,Critic 网络对3 号机器人的评判值如式(4)所示:
与MAPPER 相同,本文使用Actor-Critic 架构下最新的优势Actor-Critic 方法A2C(Advantage Actor-Critic),相较于原始的Actor-Critic 方法新增了一项优势函数Advantage,在本文中,具体如式(5)所示,该函数作为衡量所规划出动作策略的优劣,如果函数值大于零,则策略优:
R3是3 号机器人执行a3后环境反馈的奖惩值,γ是奖励折扣因子。3 号机器人的Actor 网络损失函数如式(6)所示:
Critic 网络的损失函数如式(7)所示:
3 实验仿真与结果分析
3.1 实验设置
为验证本文方法DCAMAPF 求解多机器人路径规划问题的性能,本文将传统的基于图节点搜索方法D*Lite、深度强化学习方法MAPPER 和集中式强化学习方法AB-MAPPER作为对比方法。实验环境如图4 所示,图4(a)、(b)为20×20维度,35 个机器人(蓝色红字)30 个动态障碍物(人形),分别模拟机器人在灾后搜索时集中初始化并向四周散开的场景和机器人灾后搜索场景散开后遇到无规则障碍物分布的场景;(c)、(d)为24×30 维度,35 个机器人15 个动态障碍物,分别模拟机器人在仓储环境集中初始化的并向四周散开的场景和机器人散开后遇到规则障碍物分布的仓储场景。形状较大的灰色方块为静态障碍物,黑色方块为目标点,此外,本文在图4(a)做了消融实验,对比方法主要为最新的深度强化学习方法 MAPPER、MAPPER+local Attention、ABMAPPER。所有实验在操作系统为Linux、编程语言为Python、深度学习依赖库为PyTorch 的环境下进行。

图4 实验环境Fig.4 Experimental environments
为了公平比较,将在指定步数内成功抵达目标点的机器人数占机器人总数的比例定义为成功率,将路径规划途中为避免发送碰撞而选择自主阻塞的机器人占机器人总数的比例定义为阻塞率。本文设置训练迭代次数8 000,在方法收敛后,每个环境进行100 次路径规划任务测试,以获得成功率和阻塞率均值。此外,本文统计了每个机器人占用GPU的缓存。
3.2 实验参数
本文使用与MAPPER 相同的奖励机制,总的奖励值为R=rs+rc+rο+τrf+rg,其中rs、rc、rο分别是执行动作、发生阻塞、发生震荡的奖惩值,类似MAPPER,本文也用全局规划方法A*在忽略动态障碍物的情况下生成局部参考路径S,rf用于惩罚机器人当前位置pa偏离参考路径S中的路径点p,τ是偏离奖惩因子设置为0.3,rg是抵达目标点的奖惩值。奖励折扣因子γ被设置为0.99,对比方法以及本文方法的奖励机制如表1 所示。DCAMAPF 方法Actor 网络的学习率设置为0.000 3,Critic 网络学习率设置为0.000 03,进化方法迭代次数为100,Critic 网络的软更新参数设置为0.001。

表1 奖励机制Tab.1 Reward mechanism
3.3 实验分析
实验结果如表2 所示,在图4 的4 种环境中,DCAMAPF的阻塞率均值比AB-MAPPER、MAPPER 与D*Lite 低,成功率均值比其他三种方法高。这是因为D*Lite 不能对周围动态障碍物建模;MAPPER 虽然能对动态环境进行建模,但无法进行有效的信息传递;而AB-MAPPER 两者都考虑,但所需处理的信息量过大,无法精准、高效地传递信息,此外,上述方法均没有利用其他机器人的动作信息规划动作策略,而DCAMAPF 不仅能对动态环境进行图像化建模,也能基于请求与应答机制、局部注意力机制高效传递信息。

表2 四种方法在图4不同环境阻塞率均值和成功率均值比较 单位:%Tab.2 Comparison of mean blocking rate and mean success rate among four methods in different environments in Fig.4 unit:%
D*Lite 在扩展的节点时如果新的障碍物占据路径扩展节点,则更新启发式值,然后执行新的动作策略避开新障碍物。然而,在执行动作之前更新的启发式值不能有效引导机器人避开实时移动的障碍物,这是因为占据其扩展节点的障碍物是动态移动的,D*Lite 更新的节点信息只能确保规划出的动作不会碰撞原占据拓展节点的障碍物,也无法利用动态障碍物、其他机器人的信息规划动作,这是D*Lite 碰撞率高的原因。
MAPPER 的阻塞率低于D*Lite,这是因为MAPPER 的局部观测信息中的第二维、第三维矩阵包含周围动态障碍物的轨迹信息和当前机器人的局部参考路径信息,利用到了其他机器人的局部观测信息规划动作策略,一定程度上协助了机器人避开障碍物。
AB-MAPPER 阻塞率均值皆比MAPPER 小,这是因为AB-MAPPER 在执行动作之前,所有机器人的局部观测信息会在Bi-LSTM 神经网络内部流通,传递信息。在执行完动作后,结合全局注意力机制的Critic 网络分配注意力权重给所有机器人的局部观测信息和动作信息,评判动作策略。虽然AB-MAPPER 解决了通信的问题,但是集中式架构需要处理更多的信息,所有机器人的局部观测信息需要在网络内部流通,信息量大,AB-MAPPER 的Bi-LSTM 也难以精确地甄别哪些机器人的信息是当前机器人所需要的。此外,集中式网络在同一时刻为所有机器人规划动作,这导致每个机器人占用的方法网络资源、显卡内存大。
DCAMAPF 方法是分布式架构,每个机器人都有自己的方法网络,Actor 网络能基于请求与应答通信机制获取视野内其他机器人的局部观测和动作信息,规划出协调的动作策略。在进行策略优化时,Critic 网络基于局部注意力机制,只将注意力权重分配给应答成功的机器人,将注意力应用于具有较强相关性的机器人,降低了信息冗余,利用了更精准的信息,更有利于策略的优化。机器人集中区域初始化会使环境变得拥挤,信息传递的重要性逐渐凸显。如表2 所示,相较于D*Lite、MAPPER、AB-MAPPER 方法,DCAMAPF 在离散区域初始化环境(图4(b)和图4(d)),阻塞率均值约减小6.91、4.97、3.56 个百分点;在集中区域初始化环境(图4(a)和图4(c)),阻塞率均值约缩小了15.86、11.71、5.54 个百分点。可见,本文方法在集中区域初始化环境的阻塞率均值比在离散区域初始化的大,能更高效地避免发生阻塞。
为了凸显本文方法的优势,本文在图4(a)环境进行消融实验,如图5 所示,DCAMAPF 在视野范围内基于请求与应答机制获取必要的局部观测信息和动作信息,能精确且有效地传递信息,基于较强相关性的信息规划出协调的动作策略,有效避免阻塞。
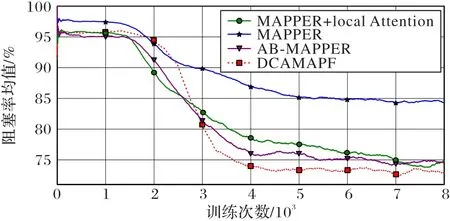
图5 消融实验方法训练曲线Fig.5 Training curves of ablation experiment methods
如图5 中MAPPER+local Attention 曲线所示,局部注意力机制将注意力权重分配给视野内成功应答机器人的局部观测信息和动作信息,避免了其他冗余信息的干扰,能更有效优化策略。此外,本文还统计了每个机器人基于以上深度强化学习方法所占用的显卡缓存,如表3 所示,基于DCAMAPF的每个机器人占用的缓存也比集中式方法AB-MAPPER 低,因此DCAMAPF 适用于求解不同动态环境下的多机器人路径规划任务。

表3 三种深度强化学习方法每个机器人所需显卡缓存 单位:MBTab.3 Graphic card cache required by each robot for three deep reinforcement learning methods unit:MB
4 结语
针对已有路径规划方法面对动态环境中的MAPF 问题阻塞率高的问题,本文采用Actor-Critic 强化学习框架进行解决。同时,为了更加灵活地获取精准的信息、规划出协调的动作策略,本文提出DCAMAPF。首先机器人请求获取视野内其他机器人的局部观测信息和动作信息,接着将应答成功的机器人信息以及本身的局部观测信息和动作信息输入多通道CNN 的Actor 网络,从而规划出协调的动作策略。同样地,在Critic 网络,将注意力权重动态地分配给应答成功的机器人的局部观测信息和动作信息。分布式的DCAMAPF 方法不仅使用了更少、更精准的信息规划更协调的动作,而且占用的显卡内存比集中式方法更少,相较于D* Lite、Mapper、AB-MAPPER 方法,DCAMAPF 在离散初始化环境,阻塞率均值约缩小了6.91、4.97、3.56 个百分点。在集中初始化环境下能更高效地避免发生阻塞,阻塞率均值约减小了15.86、11.71、5.54 个百分点。因此,所提方法确保了路径规划的效率,适用于求解不同动态环境下的多机器人路径规划任务。目前存在每个机器人都需要频繁地获取其他机器人的信息的问题,后续工作可以考虑设计出可以接受任意输入维数的信息处理网络以及信息共享机制,以进一步提高系统的运行效率。
