自动驾驶环境感知多任务去耦-融合算法
2024-03-21廖存燚刘玮瑾刘守印
廖存燚,郑 毅,刘玮瑾,于 欢,刘守印*
(1.华中师范大学 物理科学与技术学院,武汉 430079;2.武汉大学 测绘学院,武汉 430079)
0 引言
汽车自动驾驶系统的环境感知模块能自主采集周边环境信息,计算得到车辆周围物体的位置、车辆本身的位姿和车辆附近的地图等信息。在汽车对环境精准感知的基础上,自动驾驶系统能对行进路线进行正确的决策。由于目前摄像设备价格低廉,拍摄的图像富含色彩、纹理等信息,基于车载摄像机的环境感知模块已被广泛应用于自动驾驶中[1]。
近年来,深度学习技术在自动驾驶的环境感知领域中发挥着至关重要的作用,其中,确定车辆周围行人和其他车辆的位置、种类和运行轨迹是研究的重点和难点任务。针对这些问题,目前研究者分别对目标检测任务[2-3]、实例分割任务[4-5]和目标跟踪任务[6-7]开展独立研究。针对每个任务,目前业界提出了许多优秀的模型,且分别取得了较高的性能。自动驾驶系统需要同时接收多个任务的预测结果,以作出正确的行进决策。多个独立的任务处理单元势必对计算资源和实时性提出了巨大的挑战,因此,探究一种多任务学习方法,构建能同时完成目标检测、实例分割和目标跟踪等多任务环境感知算法,是一项重要的研究任务[8]。
目前,构建自动驾驶环境感知多任务模型的主要思路为:首先构建一种可以并行处理多个任务的深度学习模型,模型包含多个并行模块,每个模块对应一个主要任务;其次,研究并行模块间网络参数的共享和融合,同时,探究并行模块间的训练优化方法,使多个任务同时收敛到最优。例如,Teichmann 等[9]提出了MultiNet 模型,通过设计单编码器和多解码器结构,同时完成车辆检测、街道分类和路面分割这3个任务,提升了模型推理速度;但它的输出层未建立共享机制,无法彼此共享权重,导致检测精度下降。针对这个问题,Qian 等[10]提出了DLT-Ne(tDrivable Lane Traffic Network)模型用于可行驶区域、车道线和交通目标的联合检测。该模型提出一种上下文张量结构,融合了3 个任务的特征映射,实现了多个任务间的参数共享,提升了检测精度;但由于上下文张量结构过于复杂,难以满足实时检测的要求。Wu 等[8]提出 了YOLOP(You Only Look Once Perception)模 型,在YOLOv4[3]模型基础上,并行增添了两个解码器结构,节省了计算成本,减少了推理时间;但是它仅将各任务损失函数线性相加,未考虑模型各任务损失函数的权重平衡,可能导致部分子任务收敛不充分。更重要的是,由于行驶汽车周围环境变化复杂,目前这些模型均未考虑行驶汽车周围的行人和车辆的运动轨迹预测,不能为自动驾驶系统的决策导航模块提供充分的决策信息。
针对以上问题,本文提出一种多任务环境感知算法。首先,通过卷积神经网络(Convolutional Neural Network,CNN)提取连续帧图像的空间特征。由于帧间存在相关性,本文利用代价关联矩阵构建时序融合模块,提取得到时空特征。然后,考虑到目标检测、实例分割和目标跟踪这3个任务存在着相关性,本文构建了并行执行的3 个子任务网络,在降低模型的参数量的同时提高了运行速度。
考虑到不同任务在训练过程中存在负迁移现象,会导致3 个任务相互干扰,降低各自任务的预测精度。针对这个问题,本文提出一种基于注意力机制的去耦-融合模块。首先,使用注意力机制对时空特征去耦,在去耦过程中通过赋予时空特征不同的贡献度权重,实现不同任务对时空特征的差异化选择;其次,通过特征融合模块对已去耦的特征进行信息整合,在融合过程中,建立一种参数共享机制,使模型充分利用了任务间的相关性,提升模型在各任务上的估计精度。
考虑到模型对不同任务的学习能力有差异,为了防止训练收敛快的任务影响其他任务,本文提出对不同任务的损失函数使用动态加权平均[11]的方式训练。通过上一时刻各任务损失函数的比值,动态调节各任务损失函数下降速度,从而使模型训练时在不同任务的收敛过程中达到平衡。
为验证本文模型的有效性,在KITTI 数据集上与近年来部分优秀的模型进行对比实验,本文模型可并行运行目标检测、实例分割和目标跟踪3 个任务,运行速度达到了8.23 FPS,优于串行执行3 个任务的性能。本文模型在目标检测方面,F1 得分优于CenterTrack 模型[12];在目标跟踪方面,多目标跟踪精度(Multiple Object Tracking Accuracy,MOTA)优于TraDeS(Track to Detect and Segment)模型[13];在实例分割方面,AP50和AP75指标优于SOLOv2(Segmenting Objects by LOcations version 2)模型[14]。本文还设计了消融实验,进一步验证了去耦-融合模块的有效性。为了方便后续的研究工作,本文模型代码已经开源到了https://github.com/LiaoCunyi/Decoupling_fusion_TraDes/tree/master。
1 相关工作
1.1 目标检测
目前,目标检测算法可分为单阶段和双阶段两种。双阶段目标检测算法首先产生目标识别的候选区域,再修正候选区域宽高[15-16];单阶段目标检测算法直接回归物体类别的概率和位置坐标。例如,Redmon 等[17]提出了YOLO 系列单阶段模型,通过预定的锚框直接预测物体的边界框和所属类别,但预定的锚框会限制检测算法的性能,并且非极大值抑制(Non-Maximum Suppression,NMS)算法等后处理算法会限制检测算法的效率。针对这个问题,Zhou 等[18]抛弃锚框,采用基于关键点的方法,提出了兼顾推理时间和检测精度的CenterNet 模型。
1.2 实例分割
实例分割需要预测对象的实例和每个像素点的分割掩码。He 等[19]提 出Mask-RCNN(Mask Region-based Convolutional Neural Network)模型,首先进行目标检测,提取检测目标的边界框,再依次对每个边界框内部物体进行掩码预测,得到目标的实例分割结果;但该模型速度较慢,不能满足实时性的要求。针对这个问题,Wang等[20]提出了SOLO模型,将分割问题转化为位置分类问题。SOLOv2在SOLO的基础上增加了学习分类器权重以及掩码的特征表达,极大地缩减了前向推理所需时间。目前,SOLOv2在实例分割任务中有着较好的性能。
1.3 目标跟踪
如图1 所示,主流的目标跟踪框架[12]主要可分为逐步检测跟踪(Tracking By Detection,TBD)和联合检测跟踪(Joint Detection and Tracking,JDT)两类。
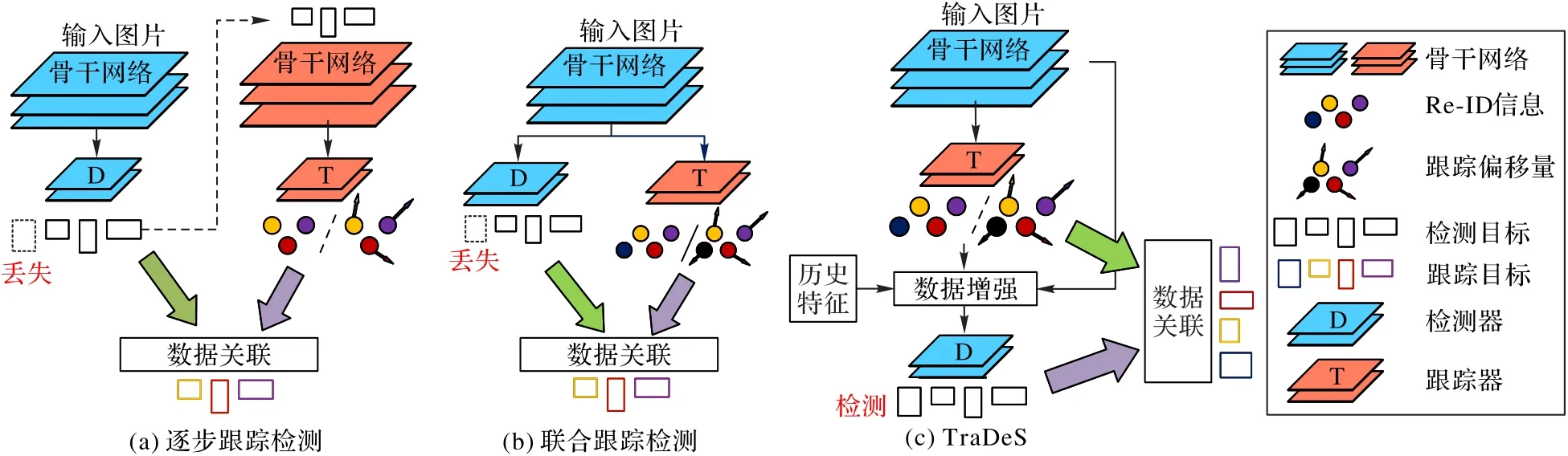
图1 目标跟踪框架Fig.1 Target tracking framework
TBD 方法首先对图像逐帧检测;然后提取检测目标特征,通过提取得到的特征构建帧间相似度矩阵;最后运用匈牙利算法或贪婪算法等匹配方法求解矩阵,得到目标轨迹[21]。这种先检测再跟踪的串行跟踪算法过于冗余,运行速度较慢。针对这个问题,JDT 方法将检测和跟踪并行执行,使用共享骨干网络同时对两个任务提取特征[22],但这种方法的检测和跟踪两个任务通常独立执行,没有利用两者的相关性。针对这个问题,Wu 等[13]提出TraDeS(Track to Detect and Segment)模型,通过跟踪器的结果对公有特征进行数据增强,帮助检测器的工作。
1.4 多任务学习
多任务学习是迁移学习的一种,旨在通过学习多个任务间的共同有效信息提高模型的学习效率和预测精度,增强模型的健壮性和泛化性能。多任务学习具有如下优势:1)得益于多任务学习的共享机制,模型的参数量显著下降,对硬件资源的占用大幅减小;2)由于骨干网络的共享,模型的推理速度提升;3)若各任务之间存在相关性,各任务的检测性能增强。因此,多任务学习被广泛应用于计算机视觉、自然语言处理和语言识别等领域。
如图2 所示,基于编码器结构的多任务学习框架可分为硬共享和软共享机制两种。软共享机制为每个特定任务单独设计子网络,并通过连接实现参数分享,有效解决了低相关性任务之间互相影响的问题。例如:Misra 等[23]提出的十字绣网络(Cross-stitch Network),通过设计十字绣单元完成子任务间的参数分享,但是十字绣单元会逐步削减前一时刻卷积层的信息,无法关联层数较远的区域。闸式网络(Sluice Network)[24]借助残差网络的思想,在共享层之间引入跳接与选择性共享等策略改善此问题。这些模型参数量大,推理速度较慢,并且共享网络的设计比较困难。硬共享机制的模型通常由一个共享的编码器组成,之后再细分为各个特定子任务[22]。此方法网络设计简单且参数量少,对具有高度相关性的任务效果较好,但对于低相关性的任务通常存在负迁移的现象[25]。
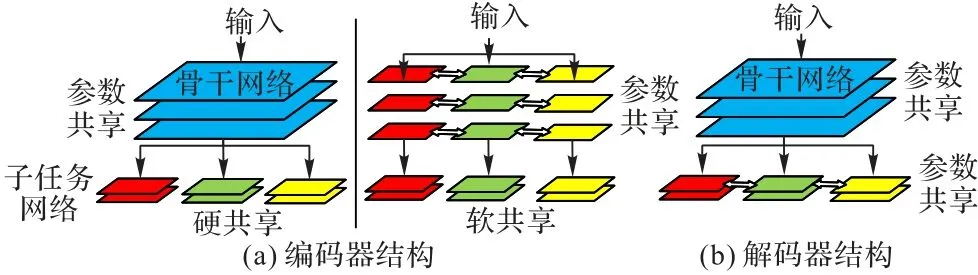
图2 多任务学习框架Fig.2 Multi-task learning framework
针对软硬共享冲突的问题,基于解码器结构的模型在子任务网络间建立参数分享机制,有效解决了低相关性任务互相干扰的问题,提高了模型的性能[26-27]。
2 多任务去耦-融合算法
自动驾驶过程中,车辆需要对周围行人和车辆等目标进行准确地感知,从而为路径规划提供决策基础。由于车辆在行进过程中需要快速决策以应对各种突发情况,所以自动驾驶系统对环境感知算法的推断时间有较为严格的限制。针对这个问题,本文提出了一种基于深度学习的多任务环境感知算法对环境目标并行进行目标检测、实例分割和目标追踪3 个任务。本文提出如图3 所示框架的模型,该模型利用车辆行驶过程中车载摄像头拍摄的连续帧图像,首先通过时序融合模块提取特征的时空信息,然后利用多任务学习技术同时实现所在区域目标检测、识别目标类别与追踪目标运动轨迹。
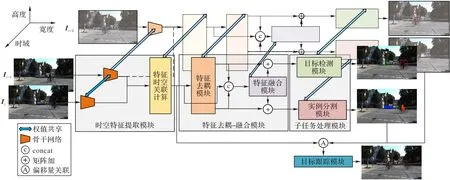
图3 多任务去耦-融合算法整体流程Fig.3 Overall flow of multi-task decoupling-fusing algorithm
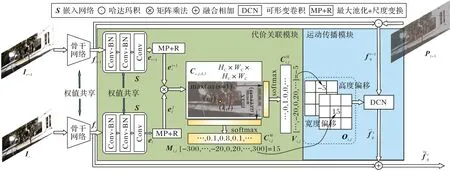
图4 时空特征提取模块Fig.4 Spatio-temporal feature extraction module
2.1 算法整体框架
本文提出的多任务环境感知算法的重点在于同时针对3 个任务,分别提取有效的时空特征。然而在多任务学习提取特征的过程中,这些子任务之间通常会产生认知混淆,从而相互干扰,这种现象被称为负迁移现象。负迁移现象可能会使检测精度比学习单一任务时大幅下降,甚至导致任务中的子任务无法收敛。本文提出一种多任务特征去耦-融合模块,通过引入注意力机制分离时空特征,实现不同子任务对时空特征的差异化选择;并设计特征融合模块整合去耦特征,充分利用任务间的相关性缓解任务间的负迁移现象。
如图3 所示,多任务环境感知算法整体流程分为时空特征提取模块、特征去耦-融合模块和子任务处理模块。首先,由车载摄像头获取的包含环境信息的连续帧图像作为模型的输入。其次,通过时空特征提取模块对连续帧图像,分别进行空域和时域的特征提取。然后,将提取的时空特征分配给不同的子任务,如:目标检测与实例分割子任务。值得注意的是,由于不同的子任务之间具有负迁移问题,本文设计了一种特征去耦-融合模块,通过注意力机制学习不同子任务,针对时空特征分配的权重,从而充分利用不同子任务之间的相关性,阻止多任务学习过程中不同子任务的相互干扰。最后,将目标检测结果通过偏移量关联,为检测目标分配ID 信息,并使用动态加权平均的方法对模型进行整体调优。
2.2 时空特征提取模块
然后提取时间特征,为得到连续帧图像中同一行人和车辆的相似度,使用矩阵乘法计算图像间的代价关联矩阵代表t时刻的像素点坐标(i,j)与t-n时刻的像素点坐标(k,l)之间的相似性。
最后进行时空特征融合,通过代价关联模块得到代价关联矩阵Ci,j,k,l后,运动传播模块利用它将前n帧图像的空间特征传播到当前帧,并对当前帧空间特征进行补偿增强。首先使用1 ×WC和1 ×HC大小的内核分别对Ci,j,k,l的宽高维度进行最大池化操作,并通过softmax 函数归一化,得到对应的二维代价关联矩阵它们分别表示目标物体在t时刻出现在指定像素坐标下的水平和垂直位置的最大概率。再分别计算t时刻像素点坐标(i,j)到t-n时刻像素点坐标(k,l)的水平和垂直方向上的偏移量Mi,j,l和Vi,j,k,计算公式为:
2.3 特征去耦-融合模块
针对各任务互相影响的问题,本文提出了特征去耦-融合模块,如图5 所示。首先,本文设计了特征去耦模块,分离时空特征,赋予它不同的贡献度权重。该模块通过减轻任务间低相关性共享信息的影响,实现不同任务对时空特征的差异化选择。然后,针对模型输出层共享信息不足的问题,构建了特征融合模块。整合含有不同任务语义信息的特征,充分利用任务间的相关性,缓解不同任务间的负迁移现象。

图5 特征去耦-融合模块Fig.5 Feature decoupling-fusing module
注意力机制模拟了人类感知周围环境的内部过程,试图通过关注图像的特定区域降低模型的运算复杂度并提高性能。在深度学习领域,注意力机制通常被当作一种资源分配的手段,根据特征的重要性程度分配不同的权重,突出重要特征忽视次要特征。自注意力(Self-Attention,SA)是注意力机制的一种,通过输入图像像素点的相关性确定输入的权重分配,然而忽视了特征各通道域之间的关联;对偶注意力(Dual-Attention,DA)[29]在自注意力的基础上,添加了一个通道注意力的分支,试图从空间域注意力和通道域注意力两个模块得到更好的权重表示,然而这种方式引入了过多的参数和计算量;有效通道注意力(Efficient Channel Attention,ECA)[30]只使用了一个感受野可学习的一维卷积核,大幅减少了计算量,并通过不降维的跨通道交互策略进一步提高了精度。本文选取有效通道注意力构建注意力机制,并通过实验验证了该方案的有效性。特征去耦模块的流程如图6所示。
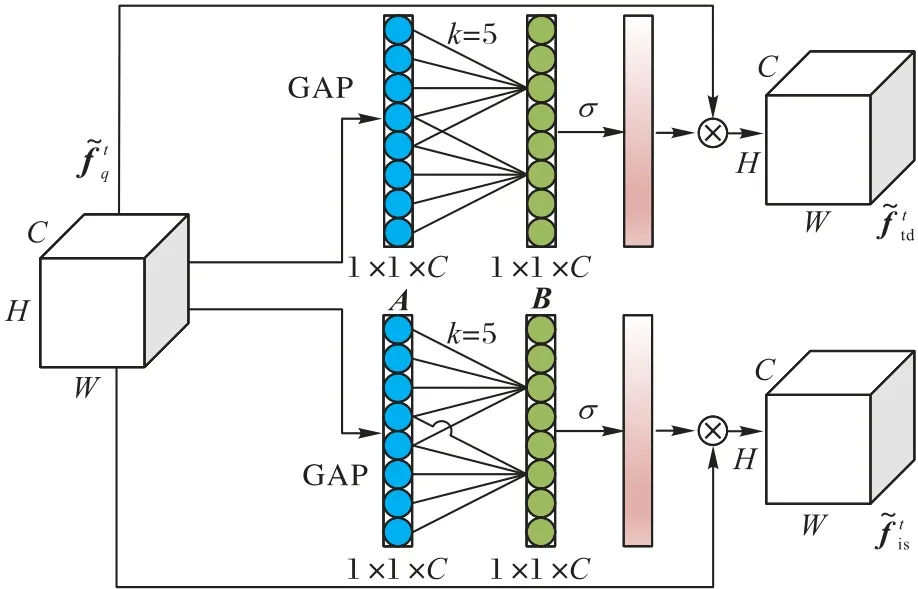
图6 特征去耦模块流程Fig.6 Flow of feature decoupling module
其中:W1和W2为超参数表示时空特征经过全局平均池化操作后的结果。特征映射A经过大小为k的一维卷积核提取通道特征后得到Β∈R1×1×C,其中k的大小可自适应学习得到,它表示注意力关注的通道数。B通过σ=softmax 函数映射后得到通道间的注意力权重,并与时空特征相乘融合,得到目标检测和实例分割两个任务分别加权后的时空特征
2.4 子任务处理模块
检测目标的中心点(i,j)和跟踪偏移量Oi,j进行两步数据关联。首先,以t-1 时刻检测目标的中心点(i,j)+Oi,j为中心,r为半径作圆,其中r为目标检测框的宽度和高度的平均值。在圆中搜索最近的未匹配检测目标,并使用匈牙利算法进行数据关联。其次,如果第一轮匹配未在t-1 时刻找到合适的匹配对象,则计算与历史轨迹的余弦相似度。如果在历史轨迹中找到相似度大于设定阈值的目标时,此时认为目标在跟踪过程中存在遮挡问题,重新为它分配相同轨迹。如果两轮关联均未成功,为目标分配一个新的轨迹。
2.5 损失函数优化及训练方法
由于多个任务的训练过程中任务训练速度难以平衡,可能会导致过拟合或者任务训练不充分等问题,并且多个任务之间的权重很难人工设定。此外,目标检测、实例分割和目标跟踪3 个任务同时存在损失不兼容的问题,也会导致负迁移现象。产生这个现象的原因在于,目标检测任务的重点在于最小化类内误差的同时最大化类间误差;然而,实例分割任务由于需要区分所有目标,它的损失函数要求扩大类内误差;目标跟踪任务同样重点关注类内误差。
针对以上问题,本文使用动态加权平均的方式对网络进行整体调优。首先,它是一种自适应的权重调节方法,有效解决了手工设计训练权重困难的问题;其次,它会通过上一时刻各任务损失函数的比值动态地调节各任务损失函数下降速度,降低下降速度快的损失函数权重,提高下降速度慢的损失函数权重,使模型的训练达到动态的平衡;最后,它有效地折中平衡了3 个任务损失不兼容的问题。
多任务环境感知模型通过最小化损失函数Ltotal的方式达到优化模型的目的,Ltotal的计算方式如下所示:
其中:目标检测、实例分割和目标跟踪3 个任务的损失函数如下:
目标检测任务的损失函数由3 个部分组成:Lk表示热力图损失函数,通过降低热力图与标签之间的差异,可达到预测目标中心点的目的。针对热力图中存在着正负样本不均衡的问题,本文采用焦点损失(Focal Loss)作为损失函数。Lsize和Loff分别表示目标框宽高与目标中心点偏移量的损失函数,这两个损失函数采用常用的L1 损失函数,在高度、宽度和中心点三方面同时降低预测目标框和真实目标框的误差。对于实例分割任务,Lmask表示预测目标掩码与真实目标掩码之间损失函数,由于掩码的预测实质上是基于像素点的分类任务,因此采用骰子函数(Dice Loss)作为损失函数。对于目标追踪任务,LCVA表示代价关联矩阵Ci,j,k,l的损失函数,为了降低连续图像中同一对象的相似度差异,采用代价容量函数作为损失函数。3 个任务的损失函数对应的权重ωi(t)的计算公式如下所示:
其中:ri(t-1)表示任务i在t-1 时刻对应的训练速度,N表示任务数。ri(t-1)除以超参数T后通过指数函数进行映射,当T=1 时,ωi(t)等同于softmax 函数的结果。最后计算各任务损失函数所占的比值,值越小表示任务训练速度越快。ri(t-1)的计算公式如下所示:
其中:Ln(t-1)表示任务i在t-1 时刻的迭代周期对应的损失函数。
3 实验与结果分析
3.1 数据集与实验平台
KITTI 数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创建,是目前自动驾驶领域最重要的数据集之一。它提供了大量真实场景下的数据,用来度量和测试算法的表现。该数据集中包含8 088 张连续帧图片作为训练集,4 009 张连续帧图片作为测试集。数据集标定了行人和车辆的位置、编号以及分割信息。
实验的硬件条件为Intel Core i7-7700K 的CPU 和NVIDIA GeForce GTX 2080Ti 12G 的显卡,开发语言为Python,深度学习框架为PyTorch。
3.2 评价指标
在目标跟踪任务中,本文选用多目标跟踪精度(MOTA)和F1 得分作为评价指标,其中MOTA 用于衡量检测目标轨迹保持方面的性能,即:
其中:FNt表示t时刻负例预测为负例的比例;FPt表示t时刻负例预测为正例的比例;GTt表示t时刻预测的总目标数;IDSWt表示跟踪目标ID 切换的总数。
F1 得分为精确率(precision)和召回率(recall)的调和平均,用于衡量目标检测的性能,即:
在实例分割任务中,本文使用AP50和AP75作为评价指标,分别用于评价困难和简单场景下的实例分割性能,即:
其中:G1表示实例预测值集合,G2表示实例标签值集合。模型的运行速度采用FPS 作为评价指标。
3.3 对比方法与定量分析
为验证本文提出模型的有效性,与近年来部分优秀的目标跟踪和实例分割模型对比。比较的模型包括:
1)TraDeS[13],该模型通过代价矩阵融合多帧信息,充分利用了时空信息。
2)CenterTrack[12],该模型基于关键点直接预测目标的中心点和前后帧之间的偏移量。
3)DEFT(Detection Embeddings for Tracking)[31],该模型在CenterTrack 的基础上,引入LSTM 网络过滤不合理的匹配结果,提供了一个更有效的跟踪记忆。
4)SOLOv2[14],该模型引入了动态机制,学习卷积核权重,优化了特征提取的效率,并提出基于矩阵的非极大值抑制算法,减少了前向推理的时间。
5)OPITrack(Object Point Set Inductive Tracker)[32],该模型提出了一种用于稀疏训练和密集测试的泛化训练策略和样本增强损失函数,前者有利于模型学习更多的鉴别特征,后者有利于模型学习假阳性和真阳性之间的差异。
6)SearchTrack[33],该模型融合了物体外部特征和运动轨迹线索来解决关联问题。
上述模型在KITTI 实例分割数据集上的实验结果如表1所示。从表1 可知,本文模型效果最优。对比单任务方法,本文模型在目标跟踪和实例分割任务上的性能均有所提升,并且模型的推理速度优于串行处理3 个任务之和;对比多任务方法,本文模型在牺牲了推理速度的情况下,提高了模型的检测精度。以上实验充分验证了本文模型的有效性。
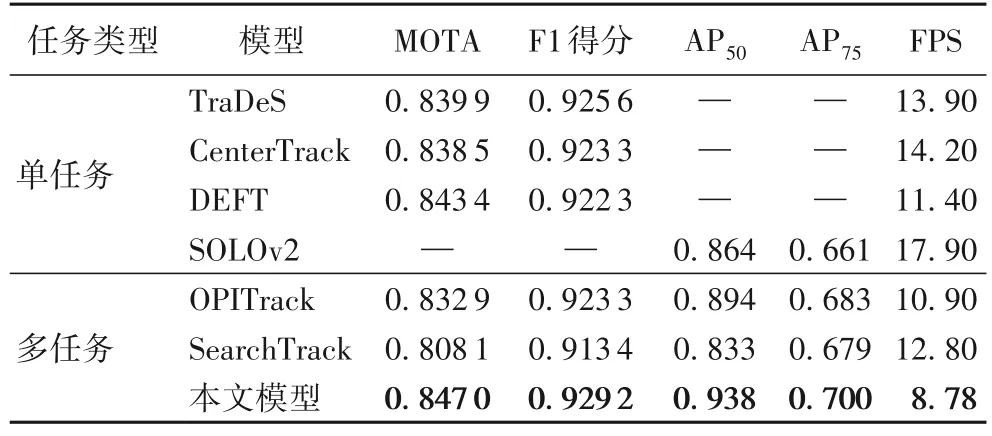
表1 本文方法与现有方法在KITTI数据集上的对比实验结果Tab.1 Comparative experimental results between proposed method and existing methods on KITTI dataset
3.4 消融实验
为验证本文模型各模块的有效性进行了消融实验。首先,将TraDeS 模型作为本文的基准模型(Baseline),并为它添加实例分割任务,分别使用ResNet18 和DLA34 作为特征提取的骨干网络,所有测试模型均训练40 个周期,并选择性能最佳的模型进行比较分析。消融实验添加的模块如下:Seg为实例分割任务模块;Self 为自注意力模块;DA 为对偶注意力模块;ECA 为有效通道注意力模块;FFM 为特征融合模块。
分析表2、3 中前两行的数据可以看出,当使用ResNet18作为骨干网络时,为网络添加实例分割任务模块时,模型的MOTA 指标下降了1.1 个百分点,同时F1 得分下降了0.6 个百分点。使用DLA34 作为骨干网络时,MOTA 指标下降了1.1 个百分点,F1 得分下降了0.5 个百分点。两种骨干网络下的模型性能均低于基准模型,验证了同时训练目标检测、实例分割和目标跟踪3 个任务时会产生负迁移的现象。
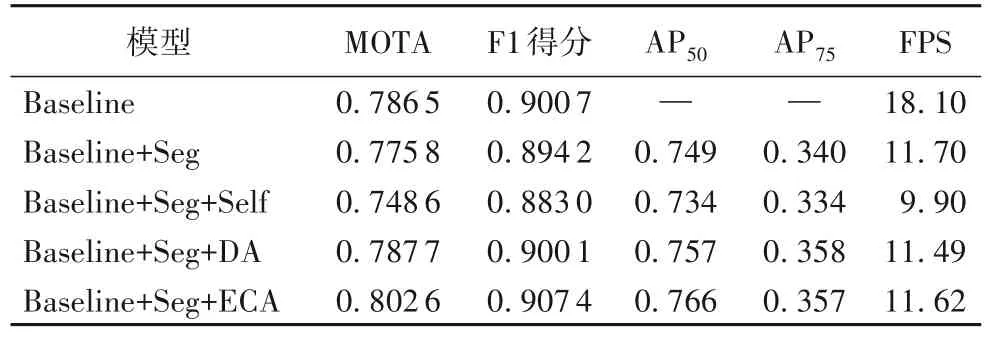
表2 骨干网络为ResNet18的特征去耦模块增减对比实验结果Tab.2 Comparative experimental results before and after adding feature decoupling module with ResNet18 as backbone network
为验证本文所提特征去耦模块和特征融合模块的有效性,对模型依次添加这两种模块。首先,为整个网络添加特征去耦模块,结果如表2 所示。分析表2 中的数据可以看出,当骨干网络为ResNet18 时,为模型分别添加自注意力、DA 和ECA 后,除了自注意力外,另外两种均对网络的性能有所提升。当为网络添加DA 后,MOTA 指标上升了1.2 个百分点,F1 得分上升了0.6 个百分点,同时AP50上升了0.8 个百分点,AP75上升了1.8 个百分点。添加ECA 后,MOTA 指标上升了2.7 个百分点,F1 得分上升了1.3 个百分点,同时AP50上升了1.7 个百分点,AP75也上升了1.7 个百分点,因此,本文构建模型时整体选用ECA 进行研究。并且当网络添加特征去耦模块后,模型的运行速度仅有细微的下降,但是预测精度甚至超过了基准模型,同时还能够并行处理3 个任务。
在此基础上,为整个网络添加特征融合模块后,实验结果如表3 所示。当骨干网络为DLA34 时,为网络添加ECA 注意力后,MOTA 指标上升了1.7 个百分点,F1 得分上升了0.9个百分点,同时AP50上升了3.1 个百分点,AP75上升了7.2 个百分点。添加特征融合模块后,MOTA 指标提高了0.1 个百分点,AP75指标上升了1.1 个百分点。说明特征融合模块对于困难条件下的实例分割任务表现良好。由此可见,消融实验验证了本文提出的特征去耦-融合模块的有效性。
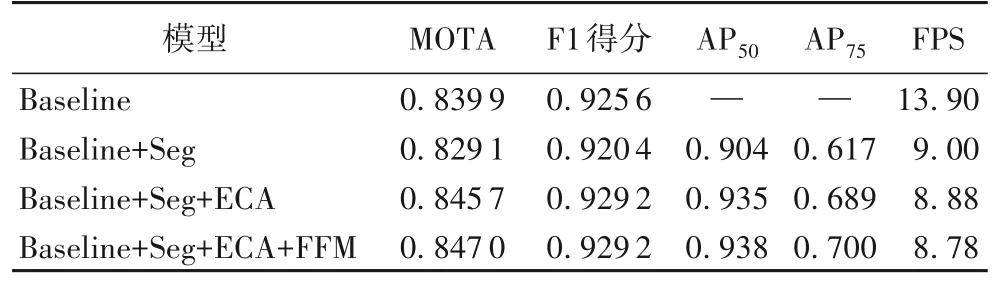
表3 骨干网络为DLA34的特征融合模块增减对比实验结果Tab.3 Comparative experimental results before and after adding feature fusion module with DLA34 as backbone network
为了验证动态加权平均算法的有效性,本文对比4种动态权重训练方法,分别是等权相加、不确定权重(Uncertainty Weighting,UW)[34]、投射冲突梯度(Projecting Conflicting Gradients,PCGrad)[35]和动态加权平均,实验结果如表4所示。

表4 多任务训练方法对比实验结果Tab.4 Comparison experimental results of multi-task training methods
分析表4 中数据可得,除了不确定权重外,投射冲突梯度和动态加权平均都对模型的性能有所提升。其中投射冲突梯度对目标检测和目标跟踪任务效果最好,但是在实例分割任务上的精度远低于动态加权平均。因此,本文选择了动态加权平均对模型进行整体调优。本文模型与基准模型在KITTI 数据集上的对比视觉效果如图7 所示。

图7 本文模型与基准模型在KITTI数据集上对比视觉效果Fig.7 Comparative visual effects of proposed model with baseline model on KITTI dataset
4 结语
本文提出的一种基于注意力机制的多任务去耦-融合模型,能并行运行目标检测、实例分割和目标跟踪这3 个任务,有效减少了推理时间,提高了预测精度。本文使用注意力机制将融合特征去耦,实现任务对特征的差异化选择;使用特征融合模块提取任务间的有效信息,增强彼此的语义表达,使得网络能学习到含有丰富时空信息的特征,充分利用了任务间的相关性,缓解了3 个任务间的负迁移现象。除此之外,本文运用动态加权平均的方式对网络进行训练,平衡多任务间的学习速度。实验结果表明,在KITTI 数据集的对比评估下,本文模型在保证推理速度的前提下,目标检测、实例分割和目标跟踪这3 个任务的预测精度均有提升。
