基于隐式信任和群体共识的群体推荐方法
2024-03-21李婷婷楚俊峰王燕燕
李婷婷,楚俊峰,2*,王燕燕
(1.福州大学 经济与管理学院,福州 350108;2.福州大学 决策科学研究所,福州 350108;3.福建农林大学 公共管理学院,福州 350002)
0 引言
大数据时代的信息过载问题以及用户如何快速精准地获取满足自身需求信息的困扰日益凸显,推荐系统是缓解信息过载和实现个性化服务的有效途径之一[1-3]。传统推荐系统虽然能对单个用户提供推荐服务,但在具有一定社会属性的领域会受到限制,如视频服务、购物、旅游线路规划等[4]。线上到线下(Online-to-Offline,O2O)商务是一种整合线上和线下市场的新商业模式,它激励在线用户在线下实体商店购买,旨在促进线下销售[5]。为提高O2O 服务推荐质量,Han等[6]提出了一种基于用户上下文信息和信任服务的O2O 服务推荐算法。为缓解O2O 服务匹配的马太效应,Yang 等[7]提出了一种考虑O2O 服务资源有限动态特性的O2O 服务匹配自适应优化算法。虽然O2O 服务推荐得到有效利用,并提高了推荐的准确度,但大多专注于单个用户的服务需求推荐,未考虑群体用户的推荐需求。O2O 服务推荐也可以为群体服务提供良好的应用场景:用户群体在线创建或加入如一群朋友计划旅游、寻找餐厅或影片、一个社区或附近居民团购等以群体为单位的活动,并从中获得推荐服务以在线预定或订购服务,然后到线下商店享受服务[8]。
需要考虑群体内每位成员的偏好需求的推荐系统,被称为群体推荐系统(Group Recommender System,GRS)[9]。GRS和个体推荐系统间的相同点是两者在推荐过程中均使用个性化推荐算法;不同点是两者的推荐对象和推荐步骤不同[3,10]。GRS 的推荐对象可以是群体也可以是个体用户,而个体推荐系统仅为个体用户推荐;相较于个体推荐系统,GRS 需要考虑融合群体成员偏好的步骤。大多数GRS 可分为偏好聚合和分数聚合[11-13]两类:前者通过聚合每位群体成员的个人偏好创建群体配置文件,然后将群体视为一个伪用户,通过个人推荐技术为群体生成推荐结果;后者为每位群体成员生成个人推荐,然后将它们聚合到该群体的推荐列表。在群体推荐场景中,群体内包含多个用户,具有偏好异构性,同时关系复杂,缓解冲突并寻求多方平衡是一项重要挑战。目前,针对不同应用场景开发出不少的群体推荐系统,例如PolyLens[14]、CATS(Collaborative Advisory Travel System)[15]、HappyMovie[16]等。
随着社交网络和在线社区的完善发展,在GRS 中重要的问题之一是群体成员间社交关系对彼此的影响[17]。Fang等[18]通过分析群体内外成员间的社会关系和用户偏好构建群体画像,具有较高精度;Zhu 等[19]提出了一种基于社交网络中的信任关系和注意力机制的群体推荐方法,在聚合权重的计算过程中考虑成员之间的社会信任关系,最终群体偏好能更准确地反映真实的群体情况,有效提高推荐结果的质量;Xu 等[20]将社交网络中成员在群体内外的社会影响力和成员间信任关系引入群体推荐任务,减小群体共识内的差异,提高推荐的准确性。因此,有必要在偏好建模时考虑群体成员间的社交网络关系,不仅可以在一定程度上缓解评分数据稀疏和用户冷启动等问题,还可以丰富最终群体偏好中包含的信息,进一步提高推荐质量。
GRS 旨在使最终推荐结果尽可能满足所有群体成员的需求,因此Castro 等[21]创新性地将来自群体决策(Group Decision Making,GDM)的共识方法集成于群体推荐系统,并称之为共识驱动的GRS。该类共识驱动的群体推荐系统包括推荐阶段和共识阶段两个阶段。同时,Castro 等[22]将相同的方法应用于餐厅推荐。由于成员间可能会考虑其他成员的偏好意见来支持或者怀疑自己的偏好意见,最终调整更新自己的偏好,这一过程可能导致他们的偏好意见发生冲突或者共识[23]。Castro 等[21]在共识阶段进行共识达成过程(Consensus Reaching Process,CRP),在提供推荐结果之前使群体成员的个人推荐更接近彼此,提高群体成员对推荐结果的满意度,改善推荐结果。在推荐阶段使用协同过滤算法为每位群成员提供个人推荐,虽然协同过滤技术取得了一定成功,但仍存在数据稀疏和冷启动等问题[24]。目前将GDM 中的共识方法应用到GRS 的研究较少,这仍是一个相对较新的研究领域[25]。一个具有社会关系的群体不仅有利于解决协同过滤技术存在的问题,还有利于最大化群体成员的满意度[9],因此,为减小成员间的偏好冲突,提供达成共识的推荐结果,研究在社交网络的背景下的共识驱动的GRS 非常有意义。
基于上述分析,本文通过考虑群体成员的社交关系和偏好,采用GDM 中的共识技术,试图在群体成员的个人推荐之间达成高度共识,确定一个在群体中大多数用户满意的群体推荐结果。本文方法包括推荐阶段和共识阶段两个阶段。首先,在推荐阶段利用群体成员相似性、社会影响力作为一组隐式信任值,再利用群体成员偏好距离、信任距离作为另外一组隐式信任值,将两组加权计算群体成员间的最终隐式信任值并应用于群体推荐;然后,根据隐式信任值,估计每位成员的个人偏好并计算每位成员在群体中的重要性,得到初始群体偏好;其次,在共识阶段根据每位成员对初始群体偏好的共识程度识别成员间无法达成共识的因素,即识别不一致成员的不一致因素,构建基于最大和谐度的共识反馈机制;建立共识优化模型,最大限度地保留不一致成员的初始偏好,减少调整成本;最后,根据共识阶段调整更新得到达成共识的群体偏好,尝试提供给成员们在群体共识和个体独立性间保持平衡的推荐结果。
1 基于用户隐式信任的推荐阶段
1.1 问题描述
假设在社交网络中有z个用户构成的用户集合记为U={u1,u2,…,uz};由t个备选 项目构成的项目集合记为I={i1,i2,…,it};一个有m个成员的群体记为G={g1,g2,…,gm},G⊂U,m≪z,并向该群体提供推荐列表。评分阈值D,为用户对某项目进行评分的一组可能值;预测评分阈值为群体推荐系统为用户未评分项目进行预测评分的一组可能值。本文主要符号及含义描述如表1所示。

表1 主要符号及含义描述Tab.1 Main symbols and meaning descriptions
1.2 成员隐式信任的度量
1.2.1 考虑成员相似性和社会影响力
考虑到具有相同品位的两个用户更有可能相互信任,与他人有紧密社会联系的成员,在影响他人的方面更深刻[26]。在社交网络中,拥有高影响力的个体更容易赢得朋友的信任,这并不仅仅取决于他们与朋友的相似性[24]。在基于用户的协同过滤推荐算法中,皮尔逊相关系数的表现优于其他相似性度量方法[27]。本文采用皮尔逊相关系数(Pearson Correlation Co-efficient,PCC)计算群体成员间偏好相似度如下:
进而得到成员gu和成员gv之间的相似度Sgu,gv:
接近中心性[28]用于衡量节点在它的连通分量中到其他各点的最短距离的平均值,即一个点距离其他点越近,则它在网络的中心度越高。若成员处于接近网络中心的有利位置,可以控制和获取群组内重要信息和资源,同时也会得到小组成员的信任。值得注意的是,本文主要讨论由群体成员在群体内外有直接社交朋友关系所构成的网络,在此网络中任意两个用户之间是连通的情况。根据接近中心性[28]计算群体成员的社会影响力如下:
其中:C(gu)表示gu的社会影响力,取值范围为[0,1];m表示gu所在群体G的成员数;c表示该群体成员在群体外有社交关系的用户数表示gu与此网络中剩余用户相连的最短路径长度。
最后将相似度和社会影响力结合计算隐式信任值IT1,如式(3)所示。它对有大差异性的输入值有鲁棒性,只有高相似性和高影响力的成员才会具有高权重。
1.2.2 考虑成员偏好距离和信任距离
PCC 是一种常用的相似性度量,它用于测量用户偏好之间的相关性,但没有考虑用户的偏好距离[29]。本文采用欧氏距离度量群体成员偏好距离,如表示gu和gv之间的偏好距离,计算如下:
鉴于信任具有传播性,并且伴随路径传播具有信任衰减的趋势,为了减少信任衰减,采用Dijkstra 最短路径算法计算gu和gv间的最短间接路径考虑到信任路径的长度会影响用户间的信任度,本文设计一种路径惩罚函数来模拟这种情况:
成员间的最短间接路径越长,受到的惩罚就越大。最后将欧氏距离和路径惩罚函数结合计算隐式信任值IT2如下:
1.3 基于隐式信任的个人预测评分
同时考虑第1.2.1、1.2.2 节隐式信任值计算方法,综合得出群体成员间隐式信任值IT,计算公式如下:
1.4 基于隐式信任的初始群体偏好
用户-项目预测评分矩阵由式(8)计算,下一步就是衡量成员们对群体偏好共识程度。在衡量共识程度前,先计算基于隐式信任度的成员重要性权重和群体偏好。
定义1成员权重。隐式信任值用于为成员分配重要性权重,计算gu基于隐式信任度的重要性权重如下:
定义2初始群体偏好。根据上述的成员权重ωgu以及成员对每个备选项目i的预测评分,基于隐式信任对项目i的初始群体偏好计算如下:
2 基于最大和谐度的共识阶段
在初始群体偏好汇总成最终达成共识的群体偏好之前需要完成共识达成过程,即共识度量、共识识别和反馈机制。
2.1 基于隐式信任的共识度量方法
1)在个人偏好和初始群体偏好间引入距离函数,成员和群体关于项目i的共识水平计算如下:
2)gu的共识程度计算如下:
其中t表示备选项目集合总数。的值越大,gu的偏好和初始群体偏好越接近;当=1 时,表示gu和群体间的初始偏好无偏差,共识程度最高。然而在现实生活中,这种情况几乎不可能。因此设置阈值γ≥γ,则称该成员达到满意群体共识性。
2.2 共识识别过程
为确定对群体共识贡献较小的成员与项目,将执行以下两个步骤:
1)共识度低于共识阈值的偏好冲突成员,即不一致成员(InconsistenT Member,LTM)集合被识别:
2)对于上述不一致成员,他的共识度低于阈值的不一致备选项目(InconsistenT Alternative,LTA)集合被识别:
根据上述两个识别规则,可以识别出全部不一致成员的不一致因素。接下来实施基于最大和谐度的个性化反馈,根据不一致成员的和谐度调整他们的预测评分达到共识阈值。
2.3 共识反馈机制
反馈机制是达成共识的关键步骤之一,使用反馈机制能有效为不一致成员自动调整预测评分以提高共识度。
2.3.1 传统共识反馈机制
传统的反馈机制,如式(13)所示,需要在每次迭代时为所有不一致成员提供一个固定的反馈参数σ∈[0,1]修改个人意见,直到所有成员的共识度都超过共识阈值[30-31]。
其中:gh(h=1,2,…,p)表示不一致成员;gk(k=1,2,…,q)表示一致成员分别表示gh对不一致项目i更新预测评分和原始预测评分表示除gh的其余群体成员对不一致项目i的初始意见均值;σ用于控制不一致成员的初始观点的变化程度。
2.3.2 最大和谐度的个性化反馈
传统共识反馈机制中,每位不一致成员的反馈参数σ都一样,意味着持有不同调整态度的不一致成员将受到相同调整成本的影响;同时对于存在社交关系的群体中采用均值代表群体的初始偏好是不合适的[32]。而Cao 等[33]提出了一种基于最大和谐度的个性化反馈机制,将和谐度分为个体和谐度和群体和谐度。通过构建基于和谐度的优化模型,为实现全局最优,追求最大群体和谐度。该机制仅通过一轮偏好修改使每个不一致成员在达成群体共识时,最大限度保持其初始意见。为解决传统共识反馈机制问题,采用基于隐式信任诱导的最大和谐度的共识反馈机制。本文将传统反馈机制改进为个性化反馈,如式(14):
其中:σgh为反馈参数,即gh的个人意见和群体共识间可接受的折中表示gh的不一致项目i调整后的预测评分;分别由式(8)、(10)所得。
定义3个体和谐度。个体和谐度用于确定不一致成员在达成共识过程中保持初始预测评分的程度,并且可以用于衡量调整预测评分前后的个体独立性[31,33-34]。设gh∈LTM,则成员的个体和谐度为:
定义4群体和谐度[33]。群体和谐度用于确定所有不一致成员在达成共识过程中保持初始预测评分的平均程度。
其中:群体和谐度越大,对不一致成员的偏好调整就会越小;当VGHD=1 时,不一致成员的偏好不需要更新。
建立以下优化模型,为了实现全局最优,群体和谐度为目标函数,共识阈值、反馈参数为条件约束。在达成群体共识的情况下,生成最优调整方案,达到最大群体和谐度。
通过求解模型(17),可以确定最优边界反馈参数σmin,然后根据式(14)调整不一致成员个人预测评分。
经过基于最大和谐度的共识驱动调整更新成员-项目预测评分后,根据式(10)更新得到达成共识的群体偏好,群体对备选项目的偏好从高到低排序,为该群体提供推荐列表。
3 群体推荐流程
根据第1 章的推荐阶段和第2 章的共识阶段,得到完整的基于隐式信任和共识驱动的群体推荐方法(Group Recommendation method based on implicit Trust and group Consensus,GR-TC)过程,它的简要流程步骤如下:
步骤1 根据初始成员-项目评分矩阵和成员间社交朋友关系网络,采用式(1)、(2)分别计算成员间的偏好相似度和社会影响力,再根据式(3)计算基于相似性和社会影响力的隐式信任值。
步骤2 采用式(4)、(5)分别计算成员间的偏好距离和路径惩罚函数,再根据式(6)计算基于偏好距离和信任路径的隐式信任值。
步骤3 根据上两步计算的两部分隐式信任值,采用式(7)计算成员间的隐式信任矩阵。
步骤4 通过成员间的隐式信任矩阵,采用式(8)求出基于隐式信任值的个人预测评分。
步骤5 采用式(9)求得基于隐式信任的成员重要性权重,最后根据式(10)求出基于隐式信任的初始群体偏好。
步骤6 根据式(11)、(12)计算得到每位成员的共识程度。
步骤7 按照两步识别规则,识别出不一致成员的全部不一致项目。
步骤8 激活反馈机制,根据式(17)应用最大和谐度共识优化模型为方程中的不一致成员生成最优反馈参数,根据式(14)为步骤7 中识别的不一致成员的偏好进行调整更新。
步骤9 根据式(10)更新得到达成共识的群体偏好,对备选项目进行从高到低排序,生成最佳推荐列表。
步骤10 结束。
基于隐式信任和群体共识的群体推荐流程如图1所示。

图1 基于隐式信任和群体共识的群体推荐流程Fig.1 Group recommendation process based on implicit trust and group consensus
4 实验与算例分析
4.1 实验设置
4.1.1 数据集
本文使用FilmTrust 数据集[35]进行实验,该数据集有1 508 个用户、2 071 部电影和35 497 条评分记录,评分范围为[0.5,4]。实验之前对数据集进行数据预处理,将用户划分到群体人数分别为5、7、9、11 的群体中,每个群体80%的评分记录作为训练集及剩余20%的评分记录作为测试集检测方法的准确度。
4.1.2 评价指标
为评估本文方法在预测成员评分方面的表现能力以及衡量生成Top-n推荐列表的准确率,采用F-measure[36]和归一化折损累计增益(normalized Discounted Cumulative Gain,nDCG)[36]。
F-measure 广泛应用于个性化推荐系统,是对精确率和召回率之间权衡的结果。它是用于检测向用户推荐合适项目方面的表现能力的指标,公式如下:
其中:TP、FN、FP分别为混淆矩阵中被预测为正类的正样本、被预测为负类的正样本和被预测为正类的负样本数。本文实验中混淆矩阵所用到的阈值设置为3。F-measure 的取值范围为[0,1],值越大,群体评分预测越准确。
nDCG 已被广泛应用于衡量推荐列表的性能,它不仅考虑预测评分的准确性,还考虑预测群体评分和实际评分间的排名表现,公式如下:
其中:{i1,i2,…,ik}是项目推荐列表是用户u对项目i1的评分是用户u根据推荐列表的评分进行降序重排列得到的最佳可能增益。本文计算每个群体成员的nDCG 均值以衡量推荐列表的性能,nDCG 的取值范围为[0,1],值越大,推荐的准确度就越高。
4.1.3 对比方法
为验证本文所提出的基于隐式信任和共识驱动的群体推荐方法(GR-TC)的有效性,从预测群体成员评分方面的表现能力和Top-n推荐列表性能这两方面与以下不同偏好融合策略的基线方法进行比较。
通过均值(Average,Avg)策略[14]生成组配置文件,使用基于用户的协同过滤(Collaborative Filtering,CF)算法生成群体推荐。
通过最大满意度(Most Pleasure,MP)策略[37]生成组配置文件,使用基于用户的CF 算法生成群体推荐。
通过平均无痛苦(Average without Misery,AwM)策略[38]生成组配置文件,使用基于用户的CF 算法生成群体推荐。本文实验中,无痛苦阈值设置为2,它用于过滤导致成员痛苦的低于预定义阈值的评分。
4.2 实验结果与分析
首先为验证GR-TC 在预测群体成员评分方面的表现能力,通过式(18)对第1 章基于用户隐式信任的推荐阶段产生的预测评分(Group Recommendation method based on implicit Trust,GR-T)进行度量,并与同样采用Avg、MP 策略下的基线模型进行对比。GR-T 进行到第1 章基于用户隐式信任的推荐阶段,未进行到第2 章基于最大和谐度的共识阶段,GR-T包含在GR-TC 中。由于基于用户隐式信任的推荐阶段已经完成对群体成员未评分项目的预测,而基于最大和谐度的共识阶段没有涉及预测未知项目评分,因此使用GR-T 表示GR-TC 在预测群体成员评分方面的表现能力。从图2 中可以看出,在相同Avg、MP 融合策略和不同群体规模大小情况下,对于F-measure 的结果,GR-T 在预测群体成员评分方面的表现能力均优于基线方法,说明考虑成员间的社会关系可以提高推荐效果。当群体规模逐渐增大时,无论GR-T 还是基线方法的预测成员评分的表现能力都会降低,因为F-measure 的值会持续减小。但相较于基线模型,GR-T 的预测评分性能会更稳定。
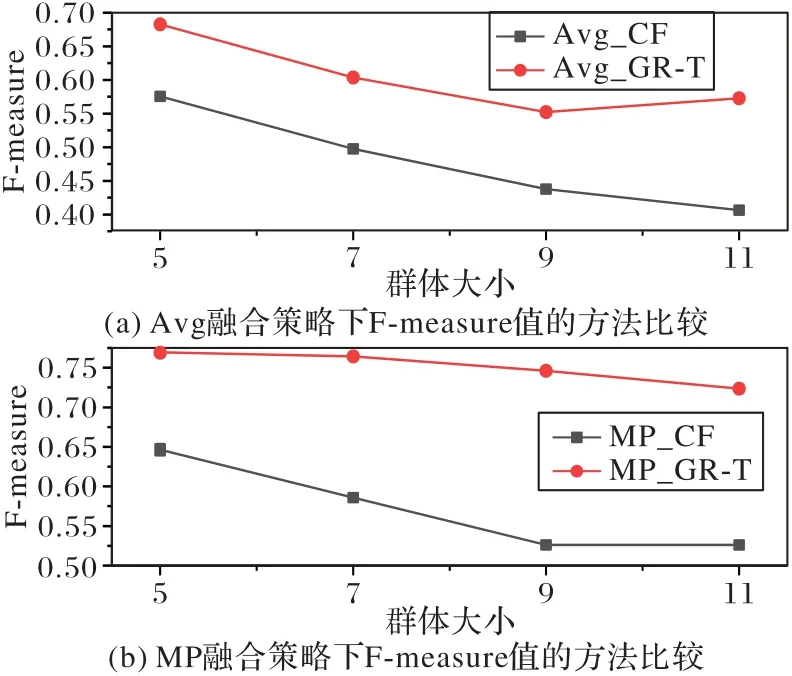
图2 不同群体大小下F-measure值的方法比较Fig.2 Comparison of methods for F-measure values with different group sizes
考虑群体共识在偏好融合过程的作用,主要在于缓解群体偏好冲突,为群体推荐较为满意的项目列表。通过式(20)衡量考虑群体共识后的群体推荐列表性能,并与采用Avg、MP 和AwM 融合策略的基线模型进行对比。在图3 中可以看出:当群体大小为7、9、11 时,Top-5、Top-10、Top-15 的nDCG值,即nDCG@5、nDCG@10 和nDCG@15 值均优于不同融合策略下的基线模型;当群体大小为5 时,本文方法Top-10、Top-15 的nDCG 值接近基线模型;当群体规模逐渐增大时,无论本文方法还是基线方法,nDCG 值在大多情况下会持续增加。
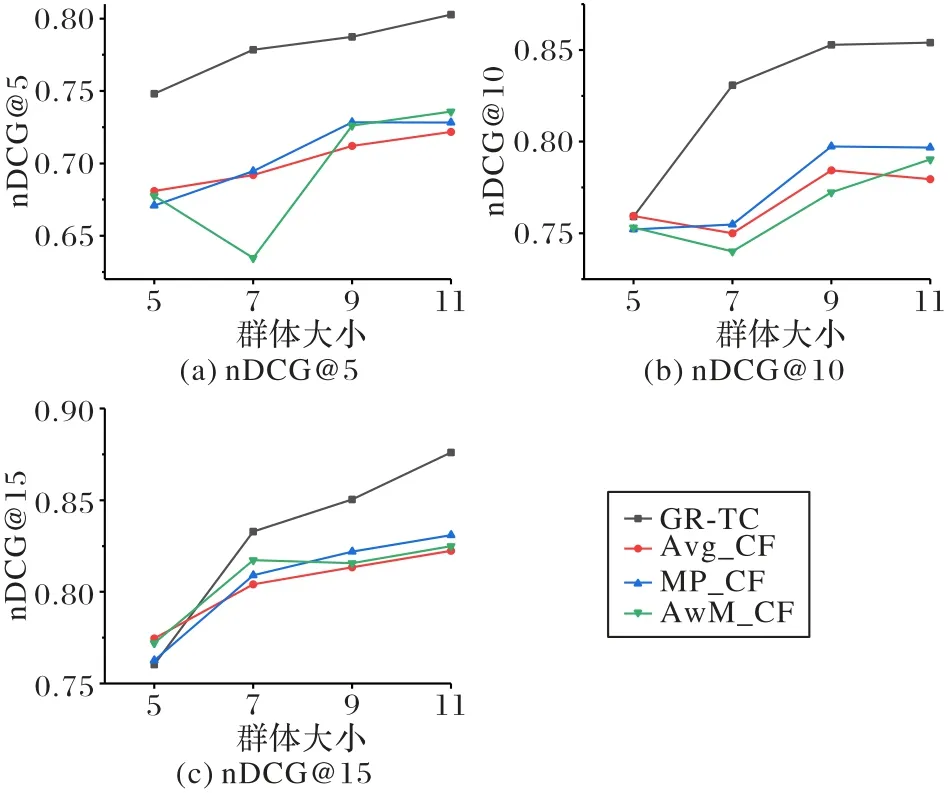
图3 不同群体大小下nDCG值的方法比较Fig.3 Comparison of methods for nDCG values with different group sizes
4.3 算例
随着社交网络的发展,在线一起观看电影受到越来越多网民的青睐。用户们在影音应用平台中与该平台其他用户设置为社交朋友,同时可以创建或加入观影室,通过推荐电影列表选择影片观看。本文以在线一起观看影片的群体为例。定义一个样本群体,其中包括对10 部影片进行评分的5位用户及这5 位用户在影音平台中存在直接社交朋友关系,为这5 位用户提供一个推荐列表,则样本群体Gs={m1,m2,m3,m4,m5},电影项目集合Is={i1,i2,…,i10},该群体成员对电影项目的部分评分见表2;用户集合={m1,m2,m3,m4,m5;o1,o2,o3},其 中{m1,m2,m3,m4,m5}为 样本群体Gs,{o1,o2,o3}为样本群体Gs在群体外有直接社交朋友关系的3 位用户,其中用户集合中所包含的社交朋友关系见图4。

图4 成员间的社交朋友关系Fig.4 Social friendship among members
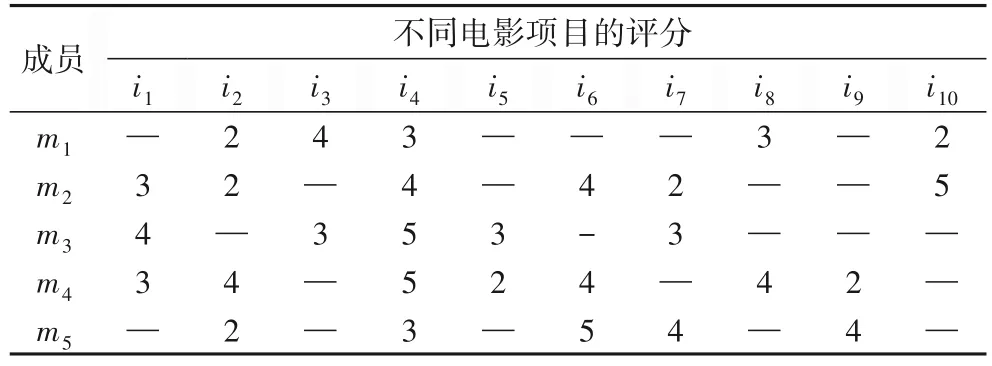
表2 初始成员-电影评分Tab.2 Initial member-movie rating
步骤1 根据表2 和图4 信息,采用式(1)、(2)分别计算成员间的相似度和社会影响力,再根据式(3)计算基于相似性和社会影响力的隐式信任值IT1。
步骤2 采用式(4)、(5)分别计算成员间的偏好距离和路径惩罚函数,再根据式(6)计算基于偏好距离和信任路径的隐式信任值IT2。
步骤3 根据IT1、IT2,采用式(7)计算成员间的隐式信任矩阵IT,此处取α=0.1。
步骤4 根据IT,采用式(8)求出基于隐式信任值的个人预测评分。
步骤5 采用式(9)求得基于隐式信任的成员重要性权重ω。根据式(10)求出初始群体偏好。
步骤6 根据式(11)、(12)计算每位成员的共识程度。
步骤7 按照识别规则,识别出不一致成员的全部不一致项目,其中该算例的阈值γ设置为0.75。
步骤8 激活反馈机制,根据式(17)应用最大和谐度共识优化模型为方程中的不一致成员生成最优反馈参数,根据式(14)更新上一步中识别的不一致成员的偏好。
通过求解上述模型得到最佳反馈参数σ1=0.32,σ4=0.04,max(VGHD)=0.908,更新得到新的个人预测评分矩阵,其中除了成员m1、m4的部分预测评分进行调整之外,其他成员的预测评分完全保持不变。经过一次迭代后,每位成员的共识程度如下:CD1=0.75,CD2=0.86,CD3=0.81,CD4=0.75,CD5=0.79。
步骤9 根据式(10)更新该群体偏好,对备选项目进行从高到低排序,生成最佳推荐列表。
备选项目排序:
推荐列表:
步骤10 结束。
4.4 算例分析讨论
为说明GR-TC 方法的可行性和合理性,下面将对上述算例的平衡参数α进行灵敏度分析、对是否有共识反馈机制进行对比分析和对本文的共识反馈机制与传统共识反馈机制进行对比分析。
4.4.1 灵敏度分析
为了解平衡参数α对群体推荐排序和群体和谐度产生的影响,对α值进行灵敏度分析,不同α值对推荐排序、群体和谐度、产生不一致成员个数的具体细节如表3 和图5 所示。
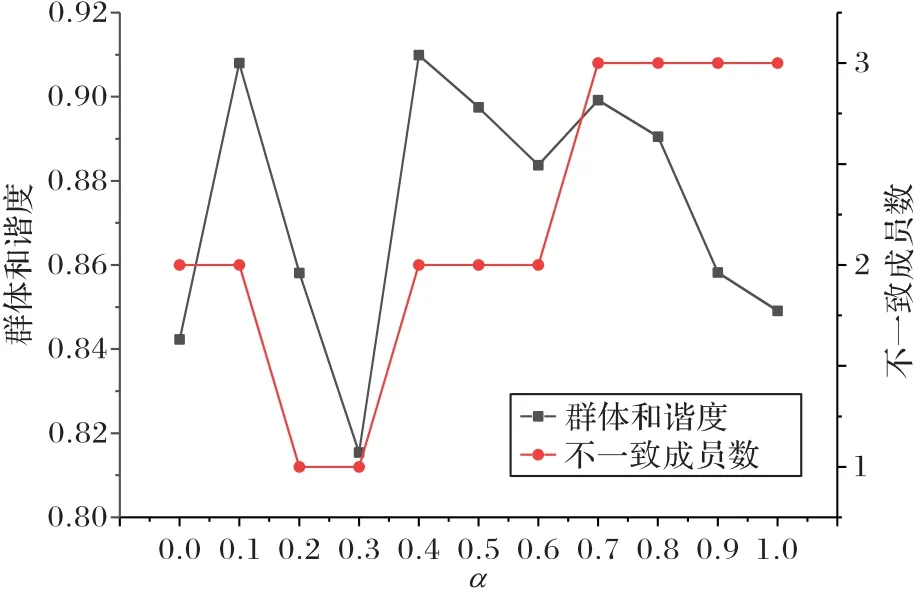
图5 平衡参数α对群体和谐度和不一致成员个数的影响Fig.5 Effect of equilibrium parameter α on group harmony and number of inconsistent members
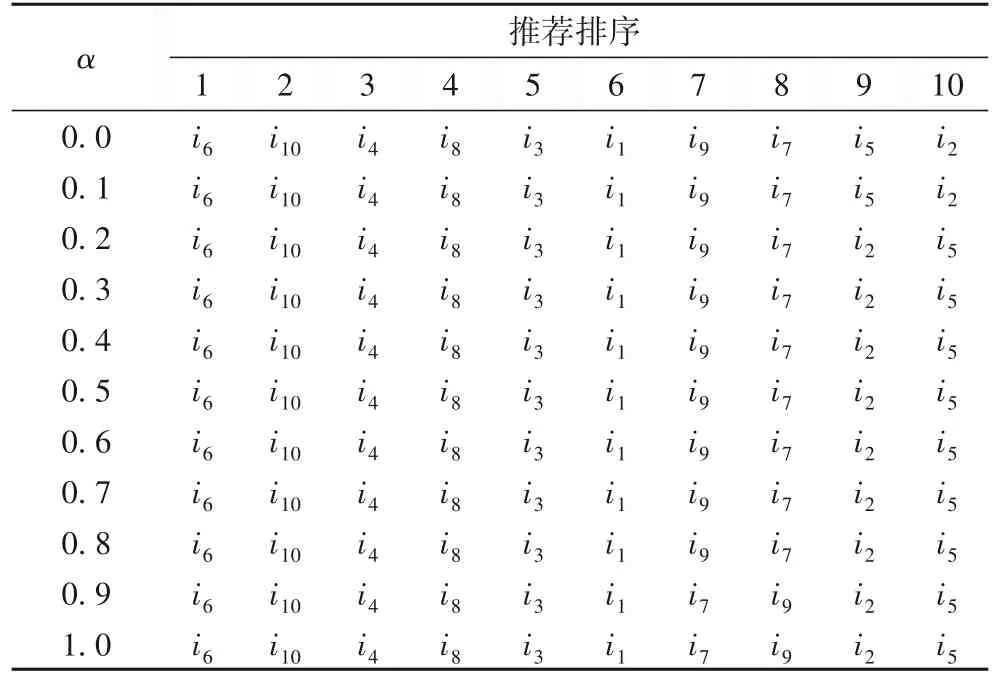
表3 α值对推荐排序的影响Tab.3 Effect of α value on recommendation ranking
由表3 可知,当α=0、0.1 时,该群体对项目的推荐排序结果一致;当α=0.9、1.0 时,该群体对项目的推荐排序结果一致;当α=0.2~0.8 时,该群体对项目的推荐排序结果一致。当α=0~0.8 时,仅i2、i5的排序不一致;当α=0.2~1.0 时,仅i7、i9的排序不一致。不同的α值对排序的前六位推荐项目的影响是一致的,对后四位的推荐项目i2、i5、i7、i9的排序产生不一致。
由图5 可知,当α=0.3 时,有1 个不一致成员,群体和谐度最小;当α=0.4,产生2 个不一致成员,群体和谐度最大。因此群体和谐度与不一致成员数无关,与反馈参数有关。不同的α值对推荐排序结果和群体和谐度的产生一定影响,因此选择合适的α值,有助于协调群体冲突,提高不一致成员的和谐度。
4.4.2 对比分析
采用未考虑群体共识关系的基于隐式信任的群体推荐方法处理算例4.3 节中的问题,可以从基于隐式信任的个人预测评分矩阵计算出群体偏好,获得一个推荐列表。表4 表示考虑共识与不考虑共识间的群体推荐列表差异。

表4 考虑共识与不考虑共识间群体推荐排序比较Tab.4 Comparison of group recommendation rankings with and without consensus
不考虑群体共识与考虑群体共识的推荐排序结果是不一样的。对于备选项目i1、i2、i5、i6、i7、i9,它们在这两种方案的计算下,排序没有发生变化。考虑了群体共识的方案中,备选项目i4、i10的排名互换,i2、i5的排名互换,i3、i8的排名互换。因为考虑最大和谐度的群体共识后,对不一致成员m1、m4的不一致项目更新预测偏好以缓解成员间的冲突。在群体共识和个人意见间得到可接受的折中,σ1=0.32,σ4=0.04,以实现m1、m4各自最大和谐度的基础上,最小化程度调整他们的初始意见让步群体意见,所以备选项目排序会发生变化。
本文采用基于最大和谐度的共识达成过程,除了不一致成员达成共识之外,为让他们保持独立性以及达到最大和谐度,在更新他们不一致项目的预测评分时,让他们的偏好以较低的变更成本达到共识阈值。本文选择传统共识反馈机制进行对比分析,见表5。

表5 不同共识反馈机制的比较Tab.5 Comparison of different consensus feedback mechanisms
传统反馈机制和基于最大和谐度反馈机制主要区别在于后者由最大和谐度共识驱动,体现在使用的反馈参数较低这一点上。传统的反馈机制为所有不一致成员们生成相同且固定的反馈参数,只追求共识但忽略了不一致成员的个体和谐度,导致他们的预测评分调整成本较高,个人预测偏好变化较大。最大和谐度反馈机制更少去调整不一致成员的预测偏好,使整个群体对某不一致项目达成共识,最大限度保留每个不一致成员的初始预测偏好,并且仍然能够实现共识达成过程。该机制能个性化地为每位不一致成员生成反馈参数,这种个性化对其他不一致成员影响最小,使不一致成员在个体和谐度与群体共识之间取得平衡。
5 结语
针对群体推荐问题,通过挖掘社交朋友关系网络中存在的隐式信任关系,旨在解决由于该群体成员间的偏好冲突导致的意见不一致问题,本文提出一种基于隐式信任和共识驱动的群体推荐方法帮助群体达成共识。通过考虑群体共识问题,量化个人与群体间的偏好冲突,制定规则找出冲突原因,模拟群体协商过程,弥补传统群体推荐方法没有考虑用户间交互对推荐结果的影响。同时,本文提出的基于最大和谐度共识反馈机制相较于传统共识反馈机制,能更快地促进共识的达成,以更少调整成本提高群体和谐度,提供了令群体满意的推荐结果。该方法创新地将隐式信任和最大和谐度共识融入推荐过程,为解决群体推荐问题提供了新思路。目前,将群体决策的共识反馈机制引入群体推荐过程的研究较少,在未来的研究中,可以在考虑群体成员的个性化需求的同时,对成员的个人推荐项目排序实施共识达成过程,使得群体成员们达成最大共识;O2O 服务推荐是群体推荐服务中一个良好的应用场景,可以考虑将上下文信息数据、群体用户数据和社交数据整合到群体推荐算法中并与现实生活服务平台相结合,开发群体化O2O 服务推荐应用。
