多模态特征的越南语语音识别文本标点恢复
2024-03-21王文君余正涛高盛祥
赖 华,孙 童,王文君,余正涛,高盛祥*,董 凌
(1.昆明理工大学 信息工程与自动化学院,昆明 650500;2.云南省人工智能重点实验室(昆明理工大学),昆明 650500)
0 引言
自动语音识别系统将输入的语音转录为一段连续的文本序列,但输出文本不包含标点符号。现有语音识别数据集的转录文本鲜有包含标点符号,因此很难在语音识别模型中直接输出带有标点符号的文本。然而,标点符号是语言中一个重要组成部分,具有表示停顿、语气和词语性质的作用。标点符号有助于分句和分词处理,提高机器翻译(Machine Translate,MT)和命名实体识别(Named Entity Recognition,NER)等任务的准确率[1],对语音翻译、自动问答等语音识别的后续任务有较大影响,因此,通用的语音识别系统都需要级联标点恢复模型恢复语音识别模型输出的文本标点。
对于中、英等富资源语言,语音识别系统已取得较好识别效果,SOTA(State-of-the-art)模型[2-3]的词错率低至2.85%,识别文本质量较高。在此基础上,研究者们利用循环神经网络(Recurrent Neural Network,RNN)[4]和卷积神经网络(Convolutional Neural Network,CNN)[5-6]等方式作为后处理模型用于恢复语音识别文本标点,取得了较好的效果。
目前面向越南语的语音识别系统由于训练数据相对较少,识别效果仍不理想,越南语SOTA 模型(https://github.com/vietai/ASR)的词错率高达10.77%,识别模型输出的文本中常包含对文本语义造成灾难性破坏的错误音节、字词等。有研究者利用条件随机场(Conditional Random Field,CRF)[7]、Transformer[1]等方式作为后处理模型恢复越南语语音识别文本标点,然而这些模型仅使用了文本作为特征输入,单纯利用文本特征对目标标点符号做预测,对上述语义混乱的情况不能很好地处理。在语音识别系统输出带噪声数据的情况下,模型对目标标点的预测能力不强。如表1 所示,越南语语音中的多个单词被错误识别,由于声调相近,名词“(头晕)”被错误识别为动词“(面向)”“tình(爱)”被错误识别为“rtình(错误单词)”,导致语义被破坏,面临着带噪文本的上下文信息难以被模型有效学习的问题,基于文本单一模态的标点恢复模型无法对“”作出正确标点预测。

表1 错误文本对标点恢复模型的影响实例Tab.1 Example for effect of incorrect text on punctuation recovery model
语音中包含较丰富的停顿、语调信息,能帮助降低标点恢复模型在输入文本质量不高情况下的混淆程度,增强模型对目标标点的预测能力。预训练语言模型预先训练大量无标签语料,语言理解能力和鲁棒性较强。因此,本文基于预训练语言模型融合音频特征提出多模态特征越南语语音识别文本标点恢复方法:使用预训练语言模型作为文本编码器,以提取文本特征,并在标点标签特征的引导下将文本特征与相应的转录语音特征融合,利用多模态融合特征预测含噪声的文本序列标点符号。根据Sun 等[8]的研究,逗号(COMMA)、句号(PERIOD)在日常用语中的占比远大于其他标点符号,并且在将其他标点符号转换为逗号或句号后同样能有效消歧,不会产生新的歧义;而问号(QUESTION MARK)代表疑问句,具有明显不同的语义倾向。本文结合越南语的语言特点及越南语标点恢复的实际应用场景,旨在进一步优化越南语识别文本,消除歧义、提高可读性,因此本文仅研究逗号、句号和问号的标点恢复,模型对输入序列中每个空格处预测一个标点符号标签,其中没有标点符号的位置预设为“空格(SPACE)”。
本文的主要工作如下:
1)使用预训练语言模型对输入文本特征建模,提高标点恢复模型的语言理解能力。
2)利用原始转录音频的特征分布挖掘音频中影响标点符号的隐式信息,融合多模态联合特征预测标点符号,提升含噪声数据的标点预测精确率。
3)以目标标点标签特征为指导,充分利用标签特征分布知识,引导模型更有效地融合文本-音频模态,从而对目标标点符号作出正确预测。
1 相关工作
语音识别文本标点恢复工作被研究者广泛探索。早期的标点恢复工作被定义为“不可见词事件检测”,通过使用n-gram 模型[9]、隐马尔可夫模型[10]等方法对单一标点符号做出预测;随着深度神经网络(Deep Neural Network,DNN)的发展,标点恢复任务被定义为序列生成式任务,模型根据输入序列生成一段带有标点符号的文本或一段完整的标点符号序列[11-12]。近些年,多数研究工作将标点恢复定义为序列标注任务,利用DNN[13-14]预测输入序列的每个词标签,输出一个与输入序列等长的标签序列。研究者使用CRF[15-18]结合DNN 编码器预测输入序列的目标标点符号,Tilk 等[4]提出将循环神经网络与注意力机制相结合的标点恢复方法,实现了对序列边界的准确检测和对逗号、句号及问号三种标点符号的准确预测。Żelasko 等[5]针对对话场景下的文本标点恢复进行优化,实验验证了CNN 相较于双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络有更高的预测准确率、召回率和F1 值。Tündik 等[6]在词级别CNN上构造标点恢复系统。Shi 等[19]引入英语词性标注的辅助模块,引导模型获取更丰富的语法知识,在英语标点恢复上实现较好效果。
然而,针对低资源语种,特别是越南语语音识别文本标点恢复的研究工作相对较少。Pham 等[7]使用CRF 对专家设计的一系列文本特征直接分类标注,实现模型对文本标点符号的预测。Pham 等[20]在小说、新闻数据集上探索了Bi-LSTM 网络在标点恢复任务上的有效性,实验结果表明CRF 在文本标点恢复上具有局限性。Nguyen 等[1]使用Transformer 解码器结合CRF 分类层,通过“大写恢复、标点恢复”多任务联合训练的方式,在越南语文本标点恢复上各项指标达到SOTA(State-Of-The-Art)值;但多任务联合训练存在一定的空间不匹配、错误传递问题,模型预测准确率存在提升空间。Tran 等[21]探索了基于Transformer 结构的预训练模型在越南语标点恢复上的有效性。综上所述,目前标点恢复工作更多关注如何有效提取文本语义特征,忽略了文本对应的音频中隐式包含的标点符号信息。当输入文本包含一定噪声的情况下,模型单纯依赖于文本表征对目标位置的标点符号作预测通常偏差较大。
针对上述问题,本文提出融合多模态特征的越南语语音识别文本标点恢复方法。使用预训练语言模型提取文本语义特征,融合转录语音的特征分布,在标签分布知识指导下融合文本-音频特征,使用多模态联合特征对标点符号作预测,增强模型对含噪声数据的语义理解能力和标点预测能力。
2 本文方法
本文融合文本语义特征和对应转录语音的特征,借助分类标签特征分布预测恢复越南语语音识别文本序列的标点符号。本文模型结构如图1 所示。
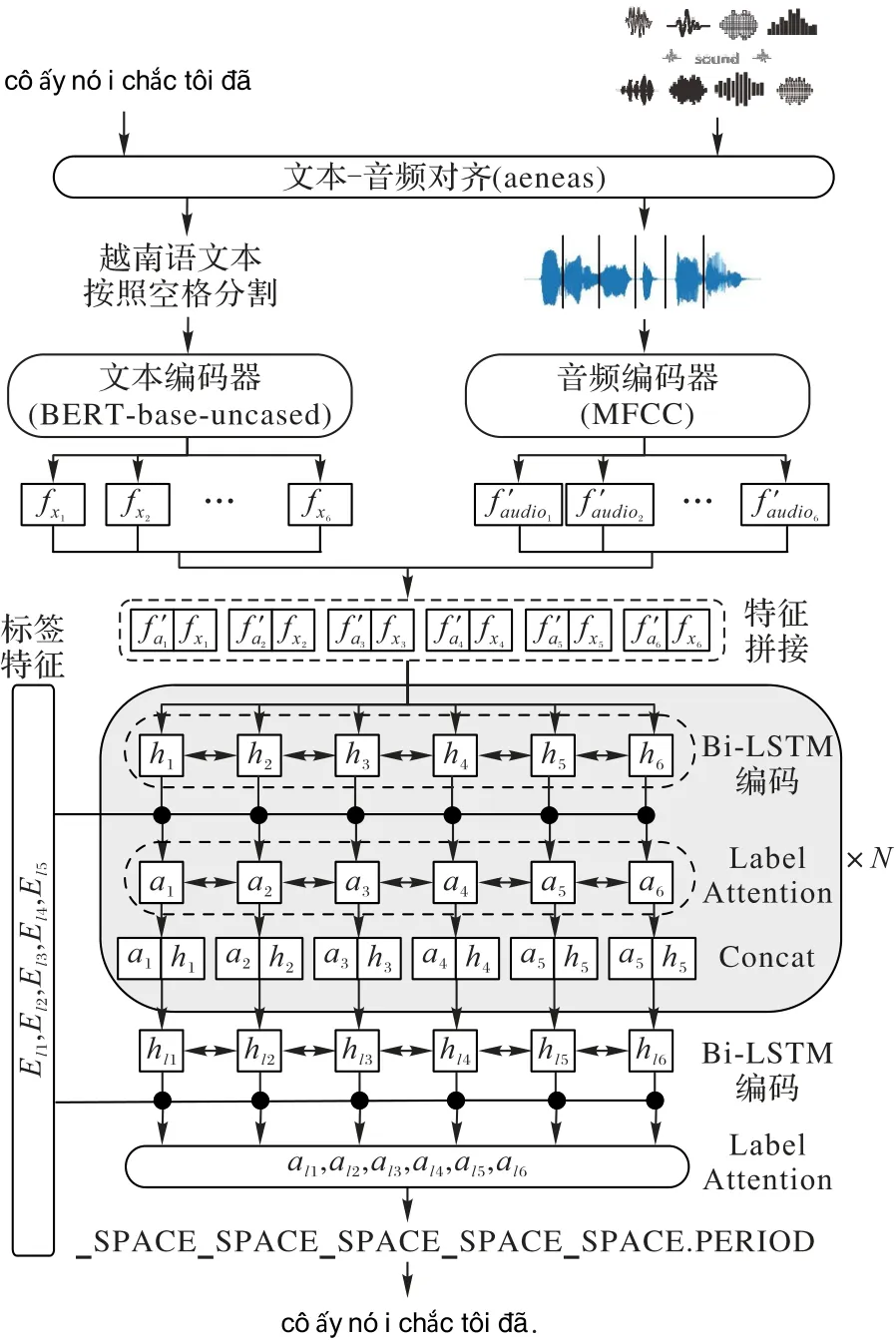
图1 本文模型结构Fig.1 Architecture of proposed model
模型包含文本-音频特征建模、多模态联合特征构造和基于特征分布知识指导的标点符号预测解码器这3 个模块。模型输入为以空格作为分隔符的越南语语音转录文本序列和转录文本对应的原始音频,文本中不包含任何标点符号,输出为对应每个音节后应该添加的标点标签序列,以空格作为分隔符。模型输入和输出序列表示如下:
1)输入序列{X|x1,x2,…,xm},其中:xi表示第i个文本,m为文本长度。
2)音频序列{A|audio1,audio2,…,audion},其中:audioi为xi对应的音频帧片段,长度取决于xi的持续时间,n为音频帧数(n>m)。
3)输出序列{L|al1,al2,…,alm},其中:ali表示第xi个文本后应该添加的标点标签,m为预测标签序列长度。
2.1 文本-音频特征分布建模
音频与文本属于不同模态。音频帧数远大于文本长度,且与文本不同,音频帧连续性更强,边界特征不明显。根据序列标注任务输入输出序列等长的特点,本文以文本长度作为模型的输入长度,将音频帧序列与文本序列粗粒度对齐,得到每个单词对应的音频帧序列片段。将连续音频离散化处理,得到对应文本序列的特征长度。经过对齐处理,文本序列{X|x1,x2,…,xi}可以得到{A|audio1,audio2,…,audioi}个 音频帧序列。例如:文本序列在音频对齐后的结果如表2 所示。
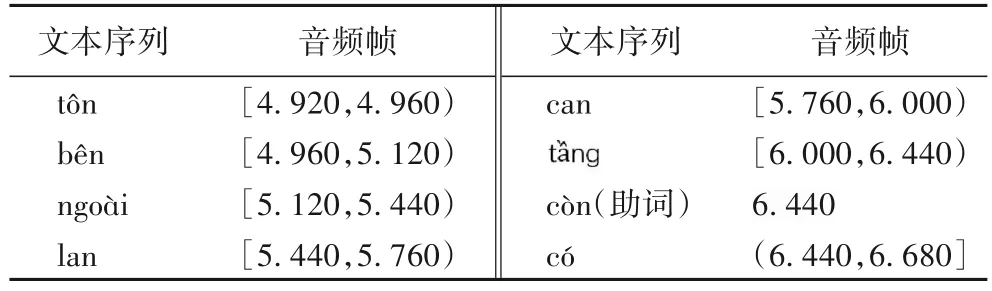
表2 对文本序列进行音频对齐后的结果示例Tab.2 Result examples after audio alignment of text sequence
人工设计的音频特征如梅尔倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)能将语音中包含的能量、音高和停顿等对标点符号有较大影响的信息转换为数学化描述,是目前较为通用的音频特征提取手段。本文采用MFCC 提取文本对应的音频片段特征。对于音频A,对A中的i个音频片段分别提取特征,得到特征分布{fa|fa1,fa2,…,fai}。由于音频对齐片段时长不同,此时序列fa中每个特征矩阵的长度不同。日常口语中,说话人单个音节的语气声调通常一致,传达的情感含义基本不变,fa中的每个特征矩阵对应输入序列中的一个音节,对fa的每个特征片段在长度上取方差值,近似代表该音节的语气倾向等音频信息,得到长度为文本序列长度、嵌入空间维度为80的音频特征矩阵
越南语BERT(Bidirectional Encoder Representations from Transformers)中的自注意力机制能有效处理全局信息,词语间距离缩小为1,更容易获取远距离文本内部的依赖关系,寻找定位序列中的核心词汇,相较于RNN 表现出更强的编码能力。对于模型输入的文本序列{X|x1,x2,…,xi},首先将大写字母经过处理全部替换为小写,然后使用越南语BERT分词器(Tokenizer)将文本转为词表id,对于词表中未登录词使用代替。对输入序列提取文本特征后得到一个特征矩阵{ft|fx1,fx2,…,fxi}。
2.2 多模态特征构造
文本特征ft由越南语BERT 提取得到,音频在经过对齐、压缩等操作后得到声学特征分布,同时与相应的转录文本在长度上对齐。文本特征ft与音频特征fa' 只在词嵌入维度上不同,其余维度保持相同,在词嵌入维度上拼接得到混合特征{fcon|fc1,fc2,…,fci}:
其中⊕代表特征矩阵在词嵌入维度上的拼接。
2.3 基于标签特征分布指导的标点符号预测解码器
本文基于Bi-LSTM 结合Label Attention 构建改进的基于特征分布知识指导的标点符号预测网络,相较于传统模型的“序列编码层+标签推理层”结构,本文使用多个“Bi-LSTM+Label Attention”块结构堆叠的方式同时作为序列特征编码器和目标标签预测器。本文基于上述改进的Label Attention 机制显式地利用标签嵌入捕获潜在的输入特征分布与目标特征分布之间的依赖关系,通过赋予每个输入特征分布更细致化的标签特征分布和层级化的注意力机制,能充分利用预训练语言模型编码得到的上下文语义特征,以及MFCC 编码原始音频得到的隐式音频特征信息,从而对音节对应的目标标点符号作出更准确的预测。
2.3.1 标签词嵌入
越南语的标点符号使用规则与英语相同,根据Sun 等[8]的研究工作,逗号和句号在日常使用中占比更大,同时问号代表整句的疑问语气,对句义的作用较重要,因此,本文模型对逗号、句号、问号和空格(代表无标点符号)作出预测。对于目标标签{L|l1,l2,l3,l4},本文使用词嵌入层(Embedding Layer)提取目标标点符号序列特征,得到标签特征{Eli|El1,El2,…,El4},标签词嵌入层在训练阶段随机初始化并随模型训练一起更新参数。
其中el代表标签词嵌入层。
2.3.2 标签注意力
每个“Bi-LSTM+Label Attention”块结构包含1 个Bi-LSTM子层和1 个Label Attention 子层。其中,最上层的Bi-LSTM 为标准结构,以2.2 节中描述的多模态分类特征作为输入;其他块结构中的Bi-LSTM 子层使用上层Label Attention 的注意力得分与2.2 节中描述的多模态分类特征的残差连接作为输入:
Label Attention 使用多头交叉注意力(Multi-head Cross Attention)机制,在多模态分类特征子空间与标签特征分布子空间内进行信息编码。其中,多模态分类特征分布经过Bi-LSTM 子层后的隐状态hl作为注意力机制中的Q矩阵,标签特征分布作为K,V矩阵,计算得到注意力得分ALAN:
其中dh=dmodel/heads。
最终前层隐状态Hl-1与注意力得分ALAN组成的残差连接作为LAN(Label Attention Network)的输出:
在最下层块结构中,Label Attention 子层作为目标标签预测器,它的注意力得分输出长度与输入文本序列长度一致,搜索空间维度与标签特征分布空间一致,使用贪心算法解码得到输入序列对应的标点符号序列{L|al1,al2,…,alm}。
3 实验与结果分析
3.1 实验设置
3.1.1 数据集设置
本文使用互联网获取的音频-文本平行越南语数据集,总计10 000 平行句对,数据集文本中包含了真实场景下的标点符号。按9∶1 拆分为训练集和测试集。语音识别文本标点恢复主要目的是对转录文本进行分句,实现有效消歧,以提高文本可读性和后续任务的准确度。根据Sun等[8]的研究,在数据预处理阶段,将数据集中的引号、冒号、分号映射为逗号,叹号映射为句号,保留问号不变,删除其他类别的标点符号,并还原缩写单词为原单词。数据集的具体设置如表3所示。

表3 越南语数据集设置Tab.3 Vietnamese datasets setting
3.1.2 参数设置
本文使用Hugging Face 中基于Pytorch的预训练语言模型BERT-base-vietnamese-uncased 作为越南语的编码器。训练过程中,使用Adam 作为模型参数优化器,学习率设置为5 × 10-5。所有的模型均使用一张Tesla T4 完成训练,训练批次大小(batch size)均设置为最大化利用显存。测试阶段,为保证与以往文本标点恢复工作的可比性,本文使用精确率(Precision,P)、召回率(Recall,R)和F1值(F1)作为评价指标。采用Tilk等[4]使用的评价算法,并在所有模型中保持一致。
3.2 融合音频特征的越南语标点恢复实验
为验证所提方法在越南语标点恢复任务上的有效性,本文在越南语数据集上做实验,分别对比使用传统RNN、使用预训练语言模型进行语义建模以及融合原始音频特征的标点恢复结果,各模型介绍如下:
1)Punctuator2[4]。使用RNN提取文本特征,对特征计算注意力得分,使用线性层推测与输入序列等长的标点符号序列。
2)Transformer CRF[1]。使用Transformer 解码器结合CRF分类层直接预测越南语文本序列的标点符号。
3)VietPunc[21]。使用基于预训练语言模型建模文本,Bi-LSTM+CRF 作为解码器预测目标标点符号。
4)Transformer Linear。本文工作,使用带有自注意力机制的Transformer 作为编码器,将编码后的隐状态经由线性层直接预测标点符号序列。
5)BERT Linear。本文工作,使用预训练语言模型BERT提取文本特征,经由线性层直接预测标点符号序列。
6)BERT MFCC LAN。本文工作,在BERT MFCC 的基础上,引入标签特征分布知识,将线性分类层替换为Bi-LSTM+Label Attention 块结构堆叠,在分类目标特征分布指导下利用多模态融合特征对目标标点符号作出预测。
表4 展示了各模型在越南语文本标点恢复上的实验结果。从表4 可以看出,传统基于RNN 并单纯依赖于文本特征的标点恢复模型对逗号、问号出现无法拟合现象,在句号的预测上性能也不佳,显示传统方法在有限的越南语文本数据上模型难以收敛。基于预训练语言模型并使用Bi-LSTM 结合CRF 作为解码器的VietPunc 模型,由于受到训练资源不足、训练数据分布不平衡等因素的影响,模型整体性能不佳,对问号等不常见标点符号的预测效果较差。在Transformer的两组实验中,使用基于自注意力机制的Transformer 作为编码器的模型在特定指标上得到2~3 个百分点的提升,但受制于较为简单的解码器结构,特别是以全连接线性层(Linear)作为解码层的实验中,模型无法拟合问号,出现无法预测的nan 现象,并且对逗号、句号的召回率较低。在使用BERT 作为编码器的实验中,单纯依赖文本特征作出预测的模型相较于Transformer 模型表现出5~10 个百分点的性能提升,表明预训练语言模型对理解句义起到了一定的作用。BERT Linear 组实验中,由于疑问句的语法结构与陈述句差异较大,在文本上具有较明显的特点,模型能通过文本特征学习更多关于问号的特征分布,所以实验中使用文本特征对问号的预测取得更高的召回率。在融合音频特征的实验中,本文方法对逗号、句号预测的精确率、召回率和F1 值均得到至少10 个百分点的提升,对问号的预测精确率也达到最优。分析是由于在语音层面上,逗号、句号通常表现为明显的、不同时长的语音静默,在融合转录音频特征后,模型能够有效对音频中隐式包含的标点符号信息加以利用,从而更有效地区分逗号、句号等标点符号,对目标位置的标点符号作出正确的预测。对问号的预测召回率出现降低现象,本文观察结果后发现,模型将更多问号位置预测为句号,原因在于音频中问号与句号的静默时间相近,而训练数据中问号的占比相对较低,模型更容易输出静默时间相近但更常见的句号。但本文方法在语音特征的融合下有效学习到了噪声文本中问号的上下文信息,对问号的精确率仍高于BERT Linear 方法,证明了本文方法的有效性,融合语音与文本特征能有效指导模型对带噪声文本作出正确标点预测。

表4 越南语融合音频特征的标点恢复结果 单位:%Tab.4 Vietnamese punctuation restoration results fused with audio features unit:%
3.3 消融实验
为了进一步明确语音特征、预训练语言模型和标签特征分布知识对文本标点恢复的影响,本文设计了消融实验。所有超参数的调节均在测试集上完成,所有模型使用多次采样后的最高值作对比。
3.3.1 预训练语言模型对文本标点恢复的有效性
为验证越南语BERT 在文本语义建模上的有效性,本文在不考虑音频特征的前提下,将模型文本特征提取器更换为标准的Transformer 结构,使用线性层作为模型预测层。实验结果如表4 所示。实验结果显示,在使用预训练语言模型对文本特征提取后,模型F1 值提升至60%,召回率提升至58%,表明预训练语言模型具有较强的语义理解能力,在低资源条件下能对输入文本序列进行更有效的语义建模,提升对标点符号位置检测的召回率和精确率。
3.3.2 融合语音特征对文本标点恢复的有效性
为验证文本对应转录音频中隐含信息对语音识别文本标点恢复的作用,修改上述“BERT MFCC LAN”模型,去除模型中音频特征编码器、多模态特征融合部分,最终标签注意力层仅使用文本特征预测标点符号。实验结果如表5所示。

表5 音频特征消融实验结果 单位:%Tab.5 Ablation experiment results of audio features unit:%
实验结果显示,融合音频特征后,模型在预测精确率、召回率以及F1 值上得到了近18 个百分点的性能提升。音频中隐式包含的标点符号停顿信息被模型有效学习,一定程度上提升模型的标点预测能力。
3.3.3 标签特征分布知识对文本标点恢复的有效性
为明确标签特征分布知识对多模态特征融合的指导作用,以及在语音识别文本标点恢复上的有效性,修改“BERT MFCC LAN”模型,替换LAN 结构为全连接线性分类层,基于多模态融合特征直接对目标标点符号作出预测。实验结果如表6 所示。

表6 标签特征分布消融实验结果 单位:%Tab.6 Ablation experiment results of label feature distribution unit:%
表6 实验结果显示,引入标签注意力作为模型解码模块后,模型性能达到最优,实现至少15 个百分点的性能提升。外部标签特征分布知识能有效指导文本-音频多模态特征的融合,从不同方向缩短输入文本序列嵌入空间与目标标点符号嵌入空间之间的距离。基于外部标签特征分布知识指导的标点预测网络能够有效捕捉到多模态特征分布中的标点符号信息,提升模型的标点预测能力。
3.4 标点符号预测样例分析
为展示引入外部标签知识指导对标点恢复模型性能提升的有效性,本文对模型推理过程中的标签注意力矩阵进行可视化,图2、3 展示了实验结果与模型最终层的解码注意力矩阵。
实验结果显示,使用LAN 作为解码器的模型在对逗号、句号的预测精确率和召回率上均达到最优值。对于图3 的输入文本中“trên thaothu hú(t在迷人的体育场上)”是越南语典型的“形容词后置”现象,注意力机制使模型能有效关注“hút”后的逗号;同样的情况出现在“này”后,模型出现一定的混淆现象,在结合音频信号中明显的静默停顿信息后,模型对句号给出更高的权重值,作了正确的预测。整体上看,模型解码层的注意力机制学习到句子结构对于标点符号的影响,对句号、问号这类代表句子终止的标点符号给予了更少的关注权重,从而有效避免了对逗号、句号的混淆预测。

图3 标签注意力得分可视化矩阵Fig.3 Visualisation matrix of label attention score
4 结语
本文针对依赖文本表征的标点恢复模型不适应含噪声输入、标点预测能力不强的问题,提出了融合预训练文本特征和音频特征的越南语语音识别文本标点恢复方法。实验结果表明,本文方法在越南语数据集上相较于基线模型有至少10 个百分点的性能提升。基于越南语BERT 预训练模型的文本编码器有助于标点恢复模型更好地对文本进行表征,对含噪声的输入具有更强的鲁棒性;通过融合音频与文本特征分布能够使模型有效获取语音中影响着标点符号预测的隐含信息,避免噪声对输入文本语义的灾难性破坏,提升了预测精确率;引入目标标签词嵌入并利用交叉注意力机制在目标标签特征分布空间内捕获输入序列与输出序列之间的远距离依赖关系,进一步提升模型的语义理解能力和标点预测能力。未来将更深入探索音频与文本特征的有效融合方法,提升低资源语言语音识别文本标点恢复的性能。
