CIEFRNet:面向高速公路的抛洒物检测算法
2024-03-12宋焕生张朝阳刘泽东孙士杰
李 旭,宋焕生,史 勤,张朝阳,刘泽东,孙士杰
长安大学信息工程学院,西安 710018
随着我国高速公路的迅速发展,高速公路的车流量日益增长,导致高速公路抛洒物事件频发。这些抛洒物大多都是车辆遮盖物或故障车辆掉落的车辆碎片,抛洒物事件的发生具有随机性和偶然性,它们对高速公路车辆通行造成安全隐患,极易诱发交通事故,如何及时发现和排除这些抛洒物事件对保障行车安全意义重大[1]。目前对抛洒物的识别还主要依靠人工巡视,工作量巨大、效率低下,且不能及时发现道路中的抛洒物。随着图像处理技术在交通监控视频中的广泛应用,如何从视频中识别出抛洒物成为当前研究的热点问题。
近年来,已经涌现出一些针对道路抛洒物检测的算法。Fu等[2]使用混合高斯背景建模检测前景,再使用边缘统计特征降噪,最后通过跟踪算法来区分前景目标中运动的车辆和静止的抛洒物,从而实现对抛洒物的检测。Zeng 等[3]利用双目相机重建路面上疑似抛洒物的三维信息,根据疑似物的大小和高度来判断是否将其划分为抛洒物。这种方法需要对双目相机进行标定和参数校正,算法效率低且工程应用难度较高。汪贵平等[4]结合五帧差分法和背景差分法得到运动目标,然后对其进行跟踪并分析目标的运动轨迹,若目标运动一段时间并保持静止则可认为该目标为抛洒物。李清瑶等[5]提出帧间差分自适应法检测抛洒物,该方法结合连续帧间差分法和背景减除法来识别图像中的抛洒物,但当运动目标处在光照较强的环境中时就会产生虚警。王立志[6]建立长短效双背景模型,并对两个背景进行差分和二值化从而检测出图像中的抛洒物。上述的方法都是基于传统的图像处理方法间接地检测抛洒物。由于抛洒物的尺寸普遍较小,这些方法的识别率较低。
随着深度学习的发展,卷积神经网络的特征提取能力不断提高,出现了很多使用深度学习的抛洒物检测方法。金瑶等[7]基于YOLOv3提出一种使用多尺度特征的抛洒物检测网络,可以检测出城市道路中的小像素抛洒物目标。张文风等[8]对Faster R-CNN加以改进,采用残差网络Resnet101[9]代替传统的VGG-16[10]和ZFNet[11]作为网络的特征提取部分,同时调整原始锚框大小以适应高速公路中不同大小抛洒物的检测。该方法提高了抛洒物检测的平均准确率,但是网络参数量巨大,不便于实际部署应用。章悦等[12]提出一种基于CenterMask 改进的分割算法用于抛洒物的检测,该算法可以分割出抛洒物的具体形态,但模型在一些复杂场景下适应能力较弱,存在较多的抛洒物误检情况。YOLOv5s 目标检测算法兼具速度和精度,因此YOLOv5s 在抛洒物检测领域也得了广泛关注。周勇等[13]采用Ghost网络轻量化YOLOv5s 并融合背景差分法检测道路抛洒物。姜子渊[14]提出了一种基于改进YOLOv5s的高速公路异常检测模型,可以很好地检测出高速公路抛洒物等道路异常物体。Liu等[15]通过引入深度可分离卷积和注意力机制对YOLOv5s进行优化,并将其用于抛洒物的检测,提高了抛洒物的检测效果,但对于小抛洒物仍存在漏检。以上基于深度学习的方法不断提高了抛洒物的检测能力,但由于高速公路抛洒物尺寸较小、可利用的特征较少和图像复杂背景噪声的干扰,仍存着较多的漏检和误检的情况,准确地识别出抛洒物仍具挑战。
针对上述问题,本文以YOLOv5s为主体框架,构建了一种基于上下文信息增强和特征提纯的抛洒物检测网络(contextual information enhancement and feature refinement network,CⅠEFRNet)。本文的主要贡献有:
(1)设计了一种融合了上下文Transformer 的特征提取模块,该模块可充分提取抛洒物的上下文信息,提高小抛洒物的识别率;
(2)改进了空间金字塔池化,减轻小抛洒物目标在下采样过程中的特征损失,保留目标的更多细节信息;
(3)设计了一种融入混合注意力机制的特征提纯模块,抑制图像中的复杂背景噪声,强化目标特征,降低抛洒物的误检率;
(4)引入了基于动态非单调聚焦机制的WⅠoU[16]损失函数,减轻小抛洒物等低质量样本对梯度带来的负面影响,加速网络收敛。
1 算法原理
CⅠEFRNet的网络框架如图1所示,网络主要分为三个部分:主干特征提取网路(Backbone)、颈部(Neck)和头部(Head)。Backbone 用于图像特征提取,主要由基本卷积层Conv、CSP-COT 和ⅠSPP 组成,其中CSP-COT和ⅠSPP分别为本文提出的特征提取模块和金字塔池化改进模块。Neck由基本卷积层Conv、上采样Upsample、特征拼接Concat 和CNAB 组成,可融合不同层级的特征,其中CNAB 为本文提出的特征提纯的模块。Head用于大中小三种尺度的抛洒物的预测。
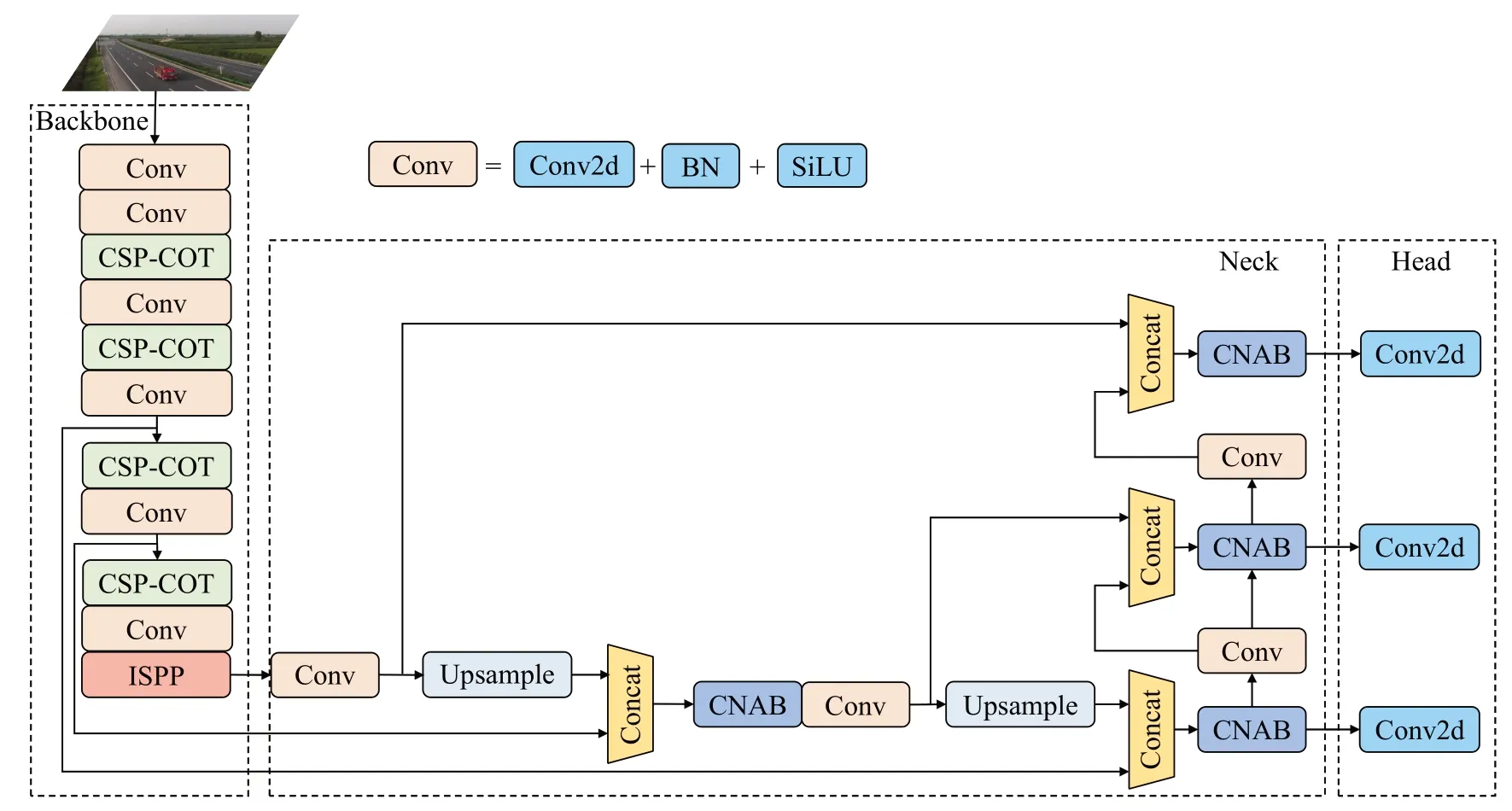
图1 CⅠEFRNet结构图Fig.1 Structure of CⅠEFRNet
1.1 CSP-COT特征提取模块
高速公路场景中的抛洒物尺寸较小,它们通常分布在图像的特定区域(道路上),如果能计算出抛洒物像素点与其周围环境像素点(即道路像素点)的关系,即充分利用抛洒物像素点的上下文信息,则有利于提高抛洒物的识别率。Transformer采用自注意力机制(selfattention)可以学习不同像素点之间的关系,捕获目标与环境之间的关联关系。为此,本文提出了一种融合了上下文Transformer的CSP-COT特征提取模块。
传统的Self-Attention 采用点积模型,如图2(a)所示,其中的Key、Query和Value都是由输入特征通过1×1的卷积映射而来,先将Key和Query相乘得到局部关系矩阵,再经过Softmax 操作进行归一化,最后与Value 相乘得到注意力矩阵。
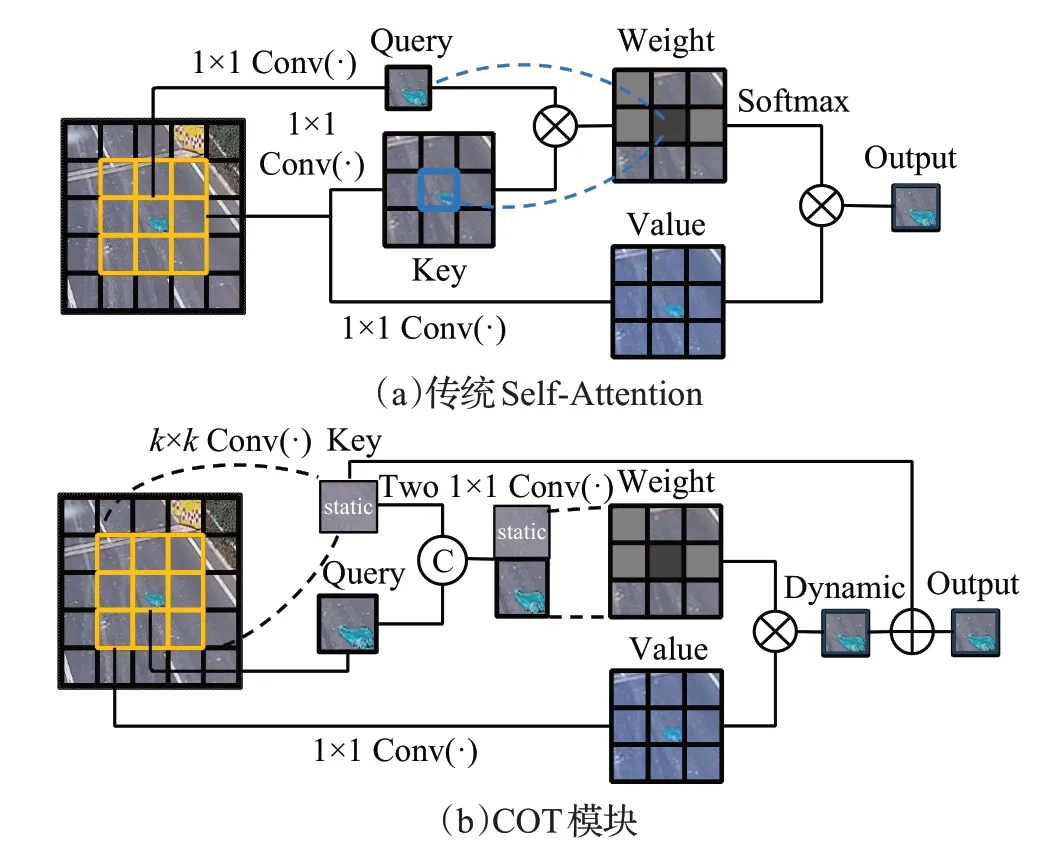
图2 传统Self-Attention和COT模块Fig.2 Conventional self-attention and COT block
由于传统的Self-Attention 中注意力矩阵主要由Key-Query对交互而来,而Key由1×1卷积生成,没有充分利用输入中丰富的相邻键特征,忽略了局部上下文信息。而COT 模块(contextual transformer block)[17]充分利用输入键之间的上下文信息,通过k×k(k的取值为3)的卷积对Key 进行编码,获取局部静态上下信息,并与Query拼接再与Value交互生成全局动态上下文信息,最后和局部静态上下信息融合,如图2(b)所示。因此,本文的CSP-COT 使用COT 模块代替CSP[18]网络Bottleneck中的3×3卷积,如图3所示。
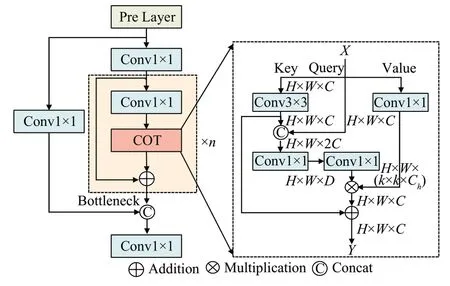
图3 CSP-COT结构图Fig.3 Structure of CSP-COT
在CSP-COT 中,COT 模块将上层的输出特征X∈ℝH×W×C作为输入,其中H、W和C分别为特征图的宽、高和通道数,则模块中的Key、Query和Value分别被定义为K=X、Q=X和V=XWv,Wv为V的嵌入矩阵。COT 模块首先在3×3 大小的网格内对所有相邻的Key使用3×3的卷积,从而获得包含相邻键的局部静态上下文信息K1∈ℝH×W×C。将K1和Q进行拼接,并依次通过两个1×1 卷积,便可得到注意力矩阵A∈ℝH×W×(k×k×Ch),Ch为注意力的头数,计算公式如式(1)所示:
其中,Wθ表示带ReLU激活函数的卷积运算,Wδ表示不带ReLU 激活函数的卷积运算。注意力矩阵的每个空间位置信息都是由查询特征Q和包含上下文信息的关键特征K1交互得到的。将注意力矩阵A与1×1卷积提取到的V相乘得到有效特征图K2,K2包含全局动态上下文特征,其计算公式如式(2)所示:
最后将包含局部静态上下文特征的K1和包含全局动态上下文特征的K2相融合便可得到COT 模块的输出Y∈ℝH×W×C,如式(3)所示:
高速公路小抛洒物目标可利用的特征较少,CSPCOT 提取的上下文信息提供了目标与周围环境之间的交互关系,通过加强目标与周围环境的纹理、颜色和形状等特征信息的联系,将目标特征和周围环境的相关特征相结合,可以增强小抛洒目标的特征表达能力,从而提高对小抛洒物的识别率。
1.2 改进的ISPP模块
SPP(spatial pyramid pooling)[19]通过最大池化层对特征图进行多尺度下采样并融合,如图4(a)所示,但池化层会降低特征图的分辨率,丢失目标的细节信息,且丢失的特征信息无法恢复,增大了小抛洒物的识别难度。为减少特征的损失,本文提出了改进的空间金字塔池化(improved spatial pyramid pooling,ⅠSPP),ⅠSPP中加入了级联的空洞卷积,空洞卷积可以有效地获取多尺度信息,且不会损失特征信息,空洞卷积上的可学习参数还会提高网络的特征提取能力,提高小抛洒物目标的识别能力。
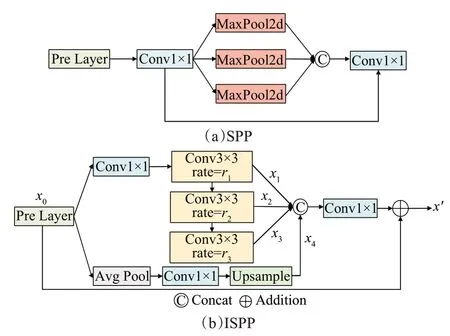
图4 SPPF和ⅠSPP结构图Fig.4 Structure of SPPF and ⅠSPP
ⅠSPP的结构如图4(b)所示,其上侧分支由1个1×1的卷积和3 个扩张率(rate)分别为1、2、3 的空洞卷积构成,为减少计算量,3个空洞卷积采用级联的方式连接,每个空洞卷积都会产生一个分支的输出。ⅠSPP 的中间分支由自适应平均池化、1×1 的卷积和上采样构成,用于补充高级语义特征。ⅠSPP 的下侧分支为一条残差边。将主干网络的提取的特征x0作为输入,将得到四个分支的特征输出{x1,x2,x3,x4} ,将这些特征在通道方向拼接,通过1×1 的卷积后再与原始特征相加,便可得到网络的输出x′,x′可由式(4)计算而得:
式中,Conv1×1为1×1的卷积,为扩张率为ri的3×3卷积(i=1,2,3), f为Batch Normalization和SiLU激活函数操作,P为自适应平均池化,U为上采样操作。
1.3 CNAB特征提纯模块
ConvNeXt[20]借鉴了Swin Transformer[21]的网络结构,构建出一个纯卷积模型,它不需要特征分块合并、移位窗口和相对位置偏执等操作,在多个计算机视觉任务上达到比Swin Transformer 更好的性能。为细化主干网络提取到的特征,本文在ConvNeXt 的基础上设计了特征提纯模块(ConvNeXt attention block,CNAB)。CNAB由两个1×1的卷积和多个改进的ConvNeXt残差块构成,其结构如图5所示。
残差块中使用7×7的逐深度卷积(depthwise convolution,DC),其卷积核个数与输入特征图的通道数一致,每个卷积核只在对应通道上进行卷积操作,有效减少了参数量。在DC后使用层标准化(layer normalization,LN),LN可对单个样本做标准化,对样本量的大小没有限制,能有效减少模型对显存的消耗。LN 后两个1×1大小的卷积用于调整输入特征图的通道数。为了提高网络的非线性性和泛化性,在两个卷积层之间加入了GELU 激活函数,GELU 激活函数通过统计输入自身的概率分布情况来实现神经元的随机正则化。在第二个卷积层后是DropPath,它可以将结构中的主分支按概率随机失活,此时该结构就等效于仅捷径分支构成的输出了,可以克服网络的过拟合和退化问题。
为了抑制图像中复杂背景噪声的干扰并强化抛洒物的特征信息,本文设计了一种新的注意力机制ECSA(efficient channel and spatial attention),以替换原ConvNeXt残差块中第二个卷积层后的Layer Scale[22],并将ECSA提前至DC之后。受CBAM注意力机制[23]的启发,ECSA将高效的通道注意力模块(efficient channel attention,ECA)[24]和空间注意力模块(spatial attention,SA)[23]融合在一起,其结构如图6所示。

图6 ECSA结构图Fig.6 Structure of ECSA
对于输入特征F∈ℝH×W×C,先在通道维度做全局平均池化得到1×1×C的特征图Fcgap,再经过卷积核为k×k的一维动态自适应卷积,其卷积核的大小可由输入特征图的通道数决定,可有效实现特征信息的跨通道交互,最后经过Sigmoid激活函数,便可得通道注意力模块的输出Mc∈ℝ1×1×C,如式(5)、(6)所示:
其中,σ为Sigmoid 激活函数,Convk×k为k×k的卷积,C为输入特征图的通道数,|t|odd表示最接近t的奇数。同时并行地对F做平均池化和最大池化,得到两个H×W×1 的特征图Fasvg和Fmsax,再将两个特征图在通道方向相加可得到H×W×2 的特征图,接着使用7×7的卷积,得到的特征图大小为H×W×1,最后再经过Sigmoid 激活函数,则可得空间注意力模块的输出Ms∈ℝH×W×1,如式(7)所示:
其中,Conv7×7为7×7 的卷积。则最终ECSA 的输出为F′∈ℝH×W×C,如式(8)所示:
1.4 损失函数优化
损失函数影响着网络的收敛速度和精度,良好的损失函数定义能为模型带来性能的显著提升。本文算法的损失函数由目标边界框损失、置信度损失和分类损失构成,如式(9)所示:
其中,L为总损失,Lbox为边界框回归损失,Lobj为置信度损失,Lcls为分类损失。
由于大部分抛洒物尺寸较小,易产生较大的回归误差,这会引起训练样本不平衡的问题,即回归误差大的低质量样本远多于误差小的高质量样本。原YOLOv5的边界框回归损失为CⅠoU损失函数[25],但CⅠoU没有考虑训练样本不平衡的问题,这些低质量样本主导了梯度,会造成损失函数的剧烈振荡。为降低低质量样本对梯度的影响,并提高小抛洒物等困难样本的学习能力,本文引入了动态非单调聚焦机制的WⅠoU损失函数,其计算公式如式(10)、(11)、(12)和(13)所示:
其中,x、y、w和h分别代表预测框中心点横坐标、纵坐标、预测框的宽和高,xgt、ygt、wgt和hgt分别代表真实框中心点横坐标、纵坐标、真实框的宽和高,Wg和WH为预测框与真实框区域构成的最小封闭盒的宽高,Wi和Hi为预测框与真实框重叠区域的宽和高。-- ----LIoU为LIoU的滑动平均值。β为离群度,其值越大意味着样本的质量越差。聚焦系数r由β计算得到,α和δ的取值为1.8 和3,r的值随损失值的增加呈非单调变化,通过r来动态调节这些低质量样本对梯度的贡献,从而加快网络的收敛的速度并提高模型的定位能力。本文针对抛洒物的检测问题,将置信度损失与分类损失相融合,采用二元交叉熵损失函数,则优化后的损失函数如式(14)所示:
其中,LBCE为置信度和分类损失,LWIoU为边界框损失。
2 实验结果与分析
2.1 实验数据集
由于现阶段还没有公开的高速公路抛洒物数据集,且高速公路抛洒物事件多为偶然事件,因此高速公路抛洒物图片较难收集。为验证本文算法的有效性,本文构建了高速公路抛洒物数据集(highway abandoned objects dataset,HAOD),如图7 所示。本文采集了多个高速公路和隧道的路侧相机在白天不同时段拍摄的路面抛洒物图像,其中包含2 471张像素为1 920×1 080的图像。为提高网络泛化能力,对抛洒物图像做数据增强处理,增强方法包括改变图像宽高比、HSV颜色空间变换、随机裁剪、镜像、随机旋转、高斯噪声等,数据集图片总数扩充至5 000 张。由于单种抛洒物数量较少,所以将所有抛洒物用单类别标签标注,并将数据集按8∶2的比例划分为训练集和测试集。

图7 HAOD数据集部分图像Fig.7 Partial image of HAOD dataset
2.2 实验环境与网络训练
2.2.1 实验环境
本文的具体实验环境配置如表1所示。

表1 实验运行环境Table 1 Experimental operating environment
2.2.2 网络训练
为得到较好的网络训练模型,在HAOD数据集上从头训练300 个epochs,batch size 设置为8,采用SGD 优化器,初始学习率为0.01。为了避免因学习率设置过大造成模型的严重振荡,采用epoch为3的Warmup预热学习优化学习率,预热学习阶段动量为0.8 并采用线性插值的方式更新学习率,预热学习结束后动量为0.973 并采用余弦退火算法更新学习率,权重衰减为0.000 5。
2.3 评价指标
为综合评价抛洒物检测网络的性能,本文采用精确率(precision,P)、召回率(recall,R)、平均精度(average precision,AP)等指标衡量模型的检测精度,采用浮点运算次数(floating point operations,FLOPs)和参数量(parameters)来衡量模型的复杂度,采用每秒处理帧数(frames per second,FPS)衡量模型推理速度,其计算公式如式(15)~(19)所示:
其中,TP 表示真正例,FP 表示假正例,FN 表示假负例。以召回率为横轴、精确率为纵轴就可以绘制出p( )r曲线,对曲线进行积分可得AP。AP0.5表示交并比取值为0.5 时的AP 值,AP0.5:0.95表示交并比的值以步长为0.05从0.5 取到0.95 的AP 的均值。t为每帧图像的平均推理时间。
2.4 实验过程与结果分析
2.4.1 CSP-COT模块实验结果分析
为验证CSP-COT 模块的有效性,分别在网络中加入CSP 模块、CSP-CSA 模块和CSP-COT 模块。CSP 模块保留原结构不做修改,CSP-CSA 模块中加入基于KQV点积模型的传统自注意力模块,CSP-COT中加入COT 模块并对COT 模块中的注意力头数取不同的值,分别对比不同结构对模型检测精度的影响,实验结果如表2所示。

表2 CSP-COT模块验证实验Table 2 CSP-COT module validation experiment单位:%
从表中可以看出,CSP-CSA 使得召回率、AP0.5和AP0.5:0.95分别提高了0.2、0.1 和0.1 个百分点,由于CSPCSA 中Key 和Query 采用点积方式且没有充分挖掘上下文信息,所以提升效果不明显。当加入CSP-COT 且注意力头数为8 时模型的提升效果最明显,准确率、召回率、AP0.5和AP0.5:0.95分别提高了0.6、0.4、0.4和0.5个百分点,表明CSP-COT 可以有效捕获道路中抛洒物的上下文信息,增强小抛洒物的特征表示,改善小抛洒物的检测精度。
2.4.2 ISPP实验结果分析
ⅠSPP 中空洞卷积的扩张率是影响多尺度特征提取的主要因素。为保留图像更多的细粒度特征,并避免连续使用多个空洞卷积引起的网格效应,本文根据HDC原则[26]设计了三组不同扩张率的空洞卷积,对比不同组合的扩张率对模型精度的影响,实验结果如表3所示。
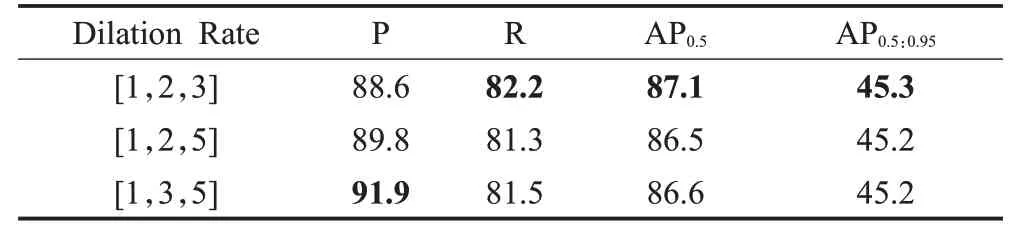
表3 不同扩张率组合实验Table 3 Experiments with different combinations of dilation rates单位:%
从表中可以看出,当扩张率逐渐增大,模型的召回率、AP0.5和AP0.5:0.95都有所下降且其值趋于平稳,当扩张率的取值为[1,2,3]时,AP0.5和AP0.5:0.95的值分别为87.1%和45.3%,优于其他组合,所以本文三个空洞卷积的扩张率的取值为[1,2,3]。
2.4.3 CNAB实验结果分析
为验证本文所提出的CNAB模块结构的有效性,本文构建了五种CNAB的变体,并对比不同结构对网络检测精度的影响。CNAB 中分别保留Layer Scale 且不使用注意力机制、去掉Layer Scale 并使用ECA 注意力机制、SA注意力机制、CBAM注意力机制和ECSA注意力机制,实验结果如表4所示。

表4 CNAB结构改进实验Table 4 CNAB structure improvement experiments单位:%
从表中可以看出,当CNAB中加入各种注意力机制后模型的检测精度都有所提高。CNAB中使用ECA后,精确率、召回率、AP0.5和AP0.5:0.95的值增加了1.7、0.3、0.3 和0.3 个百分点,说明ECA 可以提高模型的检测精度。而加入SA后AP0.5仅提高了0.1个百分点,其他指标都有所下降,这表明仅考虑空间信息对模型检测精度的提升不明显。CNAB中加入CBAM后,精确率、AP0.5分别提高了0.8 个百分点和0.4 个百分点。当CNAB 中加入ECSA,精确率、AP0.5和AP0.5:0.95分别增加了1.9、0.8 和0.9 个百分点。CBAM 和ECSA 都同时关注了通道信息和空间信息,但ECSA 的精度提升效果最明显,充分证明了本文设计的模块的有效性。为了更加直观地展现CNAB中加入ECSA的特征提纯作用,本文使用Grad-CAM[27]对特征可视化,如图8 所示。从图中可以看出,CNAB中加入ECSA后可以更好地抑制图像中的背景噪声,强化目标的特征,让目标与背景的边界更清晰,使模型可以更好地适应各种的复杂环境。

图8 CNAB融入ECSA前后特征可视化Fig.8 Visualization of features beforeafter incorporation of ECSA in CNAB
2.4.4 WIoU改进实验结果分析
为验证WⅠoU 是否能动态地调整小抛洒物等低质量样本对梯度的影响,加速模型收敛,提高网络的性能,本文分别将GⅠoU、DⅠoU、CⅠoU、SⅠoU和WⅠoU作为模型边界框损失函数,并对比了不同损失函数对模型精度的影响,实验结果如表5所示。
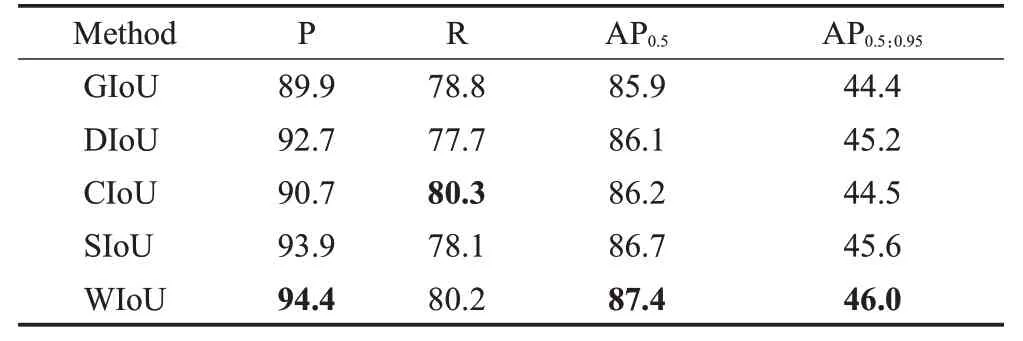
表5 WⅠoU有效性验证实验Table 5 WⅠoU validation experiments 单位:%
从表中可以看出,WⅠoU对模型的精度提升最明显,相较于原模型中使用的CⅠoU 损失函数,WⅠoU 将AP0.5和AP0.5:0.95分别提高了1.2 个百分点和0.5 个百分点。模型训练过程中各损失函数的损失值曲线如图9所示。
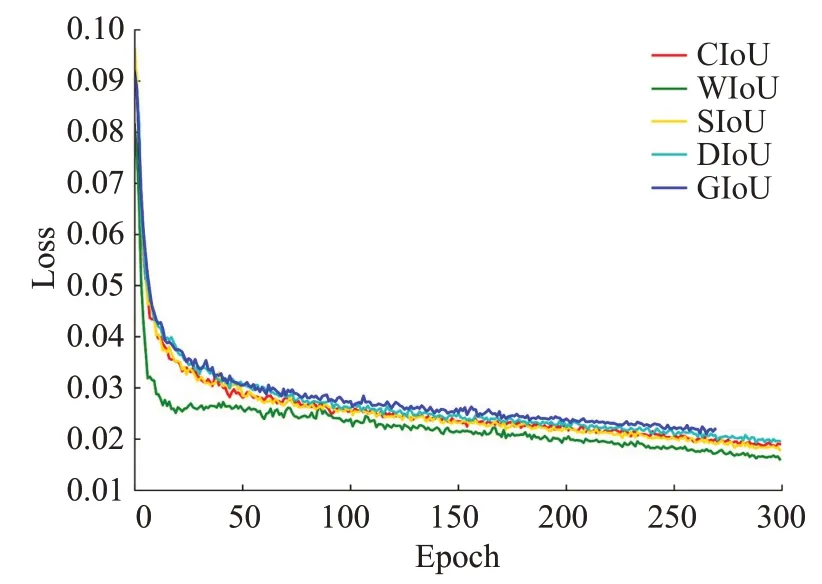
图9 损失值曲线对比图Fig.9 Loss curve comparison char
从图中可看出GⅠoU 在第270 个epoch 时便停止了收敛,且其损失值最高。DⅠoU、CⅠoU、SⅠoU 和WⅠoU 在训练过程中,损失值都在逐渐下降,而WⅠoU 的损失值下降的最快,在第11 个epoch 时WⅠoU 的损失值便与其他损失函数的损失值拉开了较大的差距,且其值一直保持最低。实验结果充分证明WⅠoU 的性能优于其他的损失函数,更好地加速网络收敛,提高小抛洒物的学习能力。
2.4.5 各改进方法提升效果可视化
为更加直观地展示本文不同改进方法对抛洒物检测效果的提升,对基线模型YOLOv5s 和各改进方法的检测结果做可视化,如图10所示。从图中可看出,基线模型将场景1中车辆尾部的备胎误识别为抛洒物,且未能识别出路面上的抛洒物,场景2中墙壁上的灯牌被误识别为抛洒物,场景3中的小抛洒物也未能被全部识别出来;利用CSP-COT模块充分捕获目标的上下文信息,可以很好地改善基线模型漏检的情况,场景1 和场景3中小抛洒物的识别率均有所提高,同时还消除了场景1和场景2 中的误检;使用ⅠSPP 后,场景2 中虽还存在灯牌的误检,但三个场景中的抛洒物全部被识别出来了;CNAB 强化目标特征,减少图像中冗余信息干扰,很好地消除了基线模型在场景1 和场景2 中的误检,并将场景1 中的抛洒物识别出来了;利用WⅠoU 进行损失函数的优化,模型在场景1 和场景3 的漏检情况均有所改善。因此,本文提出的不同改进方法对模型的检测效果均有提升。

图10 各改进方法提升效果可视化Fig.10 Visualization of effect of each improvement method
2.4.6 消融实验
本小节以YOLOv5s 为基线模型,在HAOD 数据集上进行消融实验。在基线模型的基础上,依次加入CSP-COT 模块、ⅠSPP 模块、CNAB 模块和WⅠoU 损失函数,实验结果如表6所示。在特征提取网络中使用CSPCOT模块后,AP0.5和AP0.5:0.95分别提高了0.4个百分点和0.5 个百分点。网络中加入ⅠSPP 代替原空间金字塔池化,参数量和运算量有所增加,模型的检测速度有所下降,但AP0.5和AP0.5:0.95分别再次提高0.8个百分点和0.4个百分点,说明ⅠSPP可有效地减少细节信息的损失,提取更加完整的抛洒物的特征。在特征融合部分加入CNAB模块重构颈部后,由于该模块中使用了逐深度卷积,可有效减少计算量,并且该模块采用类似MobileNetv2的逆残差结构,可以在保证模型精度的同时进一步减少模型的参数量和计算量。因此,使用CNAB后网络模型的参数量和计算量均有所下降,模型的检测速度提高至62 FPS。此外,CNAB 使AP0.5和AP0.5:0.95也分别增加了0.3个百分点和0.6个百分点,说明该模块可以有效克服图像背景噪声的干扰,使网络融合更多有用的信息。使用WⅠoU 损失函数AP0.5和AP0.5:0.95又提高0.4 个百分点和0.5 个百分点,说明该损失函数可以减轻低质量样本带来负面影响,并提高边界框的回归能力。实验结果表明,本文加入的各模块均能提高模型的性能,当加入所有模块后模型的性能最优。

表6 消融实验结果Table 6 Results of ablation experiments
2.4.7 对比实验
为验证本文方法的优势,将本文方法与一些主流算法在HAOD数据集上进行对比实验,实验结果如表7所示。可以看出本文的模型相较于其他算法模型,不仅模型复杂度低,而且检测精度更好。相较于基线模型YOLOv5s,本文算法的AP0.5和AP0.5:0.95分别提高了1.9 个百分点和2.0个百分点,模型的检测速度也提高至62 FPS。同时,本文算法的AP0.5和AP0.5:0.95也比其他YOLO 系列算法YOLOXs、YOLOv7 及YOLO 的改进算法YOLOv5s_anomal、YOLOv5-MN3 高,因为这类算法虽具有较优的网络结构,但不能较好地解决目标尺度小和路面环境复杂的问题。Faster R-CNN 因其固定的锚框参数,不能很好地适应高速公路抛洒物尺度的变化,检测精度不高。SSD-Lite 的模型复杂度低,检测速度快,但算法的检测精度远不及本文算法。Deformable DETR可以很好地检测小目标,但受高速公路图像复杂背景噪声干扰,易出现误检。FocalNet的检测精度最接近本文算法,但由于模型较复杂,模型的检测速度太低,不能满足实时检测的应用需求。因此,综合衡量不同的检测算法,本文算法的性能最优。

表7 对比实验结果Table 7 Results of comparison experiments
为了更加直观地展现本文算法的优势,选取了表7中性能较好的Faster R-CNN、YOLOv5s、YOLOv5s_anomal、YOLOv7、Deformable DETR、FocalNet和本文算法做检测结果可视化,如图11所示。为了突出检测区域,本文对其做局部放大处理。从图中可以看出,Faster R-CNN将场景3 中的圆形反光桶错误地识别为了抛洒物;YOLOv5s未能将场景4中远处的抛洒物识别出来;YOLOv5s_anomal没有将场景2中的抛洒物全部识别出来;YOLOv7 识别的抛洒物置信度很高,但场景1 中的同一抛洒物出现了两个检测框;Deformable DETR受隧道中复杂环境干扰,将场景1 和场景2 中的灯牌错误地识别为了抛洒物;FocalNet 将场景2 中的一处指示牌错误地识别为了抛洒物。以上这些算法都存在着漏检和误检的情况,而本文算法则可以将四个场景的抛洒物都正确地识别出来,因此本文所提算法可有效降低抛洒物的漏检、误检情况。

图11 各算法检测结果可视化Fig.11 Visualization of detection results for each algorithm
3 结束语
目前关于高速公路抛洒物的数据集和研究方法都比较缺乏,一些现有方法仍存在漏检和虚警的问题。为此,本文提出了CⅠEFRNet高速公路抛洒物检测算法,首先在骨干网络使用CSP-COT 模块,充分挖掘目标的上下文信息,提高小抛洒物的识别率;其次使用ⅠSPP实现多尺度特征的提取与融合,有效地减少了特征的损失;在网络颈部分采用CNAB 模块,抑制图像背景的噪声,增强多尺度特征的表达能力;最后利用基于动态非单调聚焦机制的WⅠoU 加速网络收敛。针对高速公路抛洒物数据集的空白,利用高速公路路侧相机收集了各公路和隧道的抛洒物图像,构建了高速公路抛洒物数据集,对检测模型进行训练和测试。
实验结果表明,本文提出的模型具有更低的算法复杂度、更高的检测精度,其性能优于目前的主流检测方法,满足实际场景的应用需求。在未来的工作中,将进一步完善抛洒物数据集,构建规模更大的抛洒物数据集以满足实际应用场景的训练需求,并继续优化网络的结构,提高模型的泛化性和鲁棒性。
