改进YOLOv8s与DeepSORT的矿工帽带检测及人员跟踪
2024-03-12缪小然胡建峰赵作鹏张新建
丁 玲,缪小然,胡建峰,赵作鹏,张新建
1.江苏联合职业技术学院徐州财经分院,江苏 徐州 221116
2.中国矿业大学计算机科学与技术学院,江苏 徐州 221116
3.河南龙宇能源股份有限公司陈四楼煤矿,河南 永城 476600
根据相关技术标准和安全法规,安全帽佩戴时必须按头围的大小调整帽箍并系紧帽带,在监督检查中发现戴安全帽不系帽带的行为时,可以责令立即消除隐患。这是因为不系帽带,安全帽等于没戴。在统计的多起死亡事故中,受害者虽戴了安全帽,但未系好帽带,最终被物体打击或头部撞击地面致死。安全帽是保护矿工免受坠物撞击的有效个人防护用品之一,在井下规范佩戴安全帽也是企业进行安全生产的必然要求[1]。然而,由于佩戴安全帽的不适感和矿工薄弱的安全意识,经常出现脱帽或不规范佩戴的情况,从而导致事故发生。此外,作为高危作业环境的煤矿井下,佩戴安全帽且是否系帽带对其安全至关重要[2]。传统的安全帽佩戴检查主要包括人工巡视和对监控图像的检查[3],需要耗费大量的时间和人力,效果不佳。近年来计算机视觉技术广泛应用于诸多领域[4],基于AⅠ方法的安全帽帽带检测,是解决上述问题的有效方法[5-6]。
安全帽及帽带检测属于目标检测的范畴,目标检测分为两阶段检测和单阶段检测。在两阶段检测系列中,Girshick等人[7-8]和Ren等人[9]提出区域卷积神经网络(RCNN)、快速区域卷积神经网络(Fast R-CNN)和超快区域卷积神经网络(Faster R-CNN)等一系列检测器,在准确率和速度上均有极大提升。与此同时,以YOLO 系列[10]为代表的单阶段检测器虽然在准确率上不如两阶段检测器,但在速度上有了很大提升。Tan 等人[11]在EfficientNet的基础上提升了训练速度,提出了参数量更少的卷积神经网络。由于Transformer在自然语言处理方向取得的成就,越来越多的学者将其应用到计算机视觉领域。Zhu等人[12]在DETR的基础上提出了RT-DETR,做到了端到端的实时检测。
基于卷积神经网络的检测方法极大促进了安全帽佩戴检测的发展,两阶段检测首先被用于检测安全帽的佩戴。Gu 等人[13]使用多尺度训练、增加锚点等策略来改进Faster R-CNN,安全帽的检测精度最终比原来的算法提高了7%,但却需要大约0.2 s 的时间来检测一个图像,这无法满足实时性要求。最近,越来越多的研究人员选择单阶段检测来完成安全帽检测任务。王建波等人[14]在YOLOv4 的基础上提出了一种轻量级特征融合结构,缓解特征融合部分的语义混淆问题,有效地提升了模型提取特征的能力。宋晓凤等人[15]提出了一种融合特征环境与改进YOLOv5的安全帽佩戴检测方法,能较好的检测到安全帽这一小目标。王玲敏等人[16]在YOLOv5的基础上引入注意力机制,并将原始的FPN结构更换为BiFPN,很好地提高了精度。Zhao 等人[17]在YOLOX的基础上提出了一种新的标签分配策略来有效地定义了正负样本并设计了新的损失函数,将精度提升了2.3%。
现有研究基本上都是面向安全帽检测,缺乏对帽带的规范性佩戴检测研究。同时,由于矿井下低照度、高粉尘、强光扰,现有的检测算法无法适用于煤矿井下特殊的检测环境。智能化安全管控,需要跟踪不佩戴或未规范佩戴安全帽的人员。针对上述问题,本文提出了一种结合了改进YOLOv8s 与DeepSORT 的矿工帽带检测及人员跟踪的综合解决方案。在YOLOv8s 的基础上,通过引入高分辨率的特征图和级联查询机制,能在不增加额外计算负担的情况下,实现对安全帽及其带子这类小物体的精准检测,有效提高了模型对于井下工作人员头部小区域特征的感知能力,极大地增强了算法在复杂背景下的识别准确性。同时,对DeepSORT算法的改进进一步增强了目标追踪的稳定性和准确性。通过在追踪算法中集成更深层次的卷积网络,以替代原有的小型残差网络,能够更有效地提取和利用目标的外观信息。这种深层特征的应用显著提升了算法在面对人员快速移动、遮挡变化等挑战时的追踪连续性和鲁棒性。实验结果表明,改进后的模型不仅提高了对矿工安全帽带是否规范佩戴的检测能力,而且增强了对未规范佩戴人员的追踪效率,显著地提升了整个监控系统的性能,为矿井安全管理提供了一个切实可行的技术支持,进而有助于更有效地预防安全事故的发生。
1 研究方法
针对现有检测方法通常无法更进一步地检测安全帽是否佩戴规范等问题,设计了一个智能识别和跟踪系统。整体框架图如图1所示。首先,使用改进YOLOv8s作为检测器提取特征信息,得到每个目标帧的定位信息、分类信息和置信度。然后将检测结果输入DeepSORT,通过卡尔曼滤波预测模块获得先验预测轨迹,再利用匈牙利算法计算当前帧的检测结果和预测轨迹之间的匹配度。最后,错误的轨迹被删除,修正后的轨迹由卡尔曼滤波更新模块更新,实现对没有规范佩戴安全帽人员的跟踪。
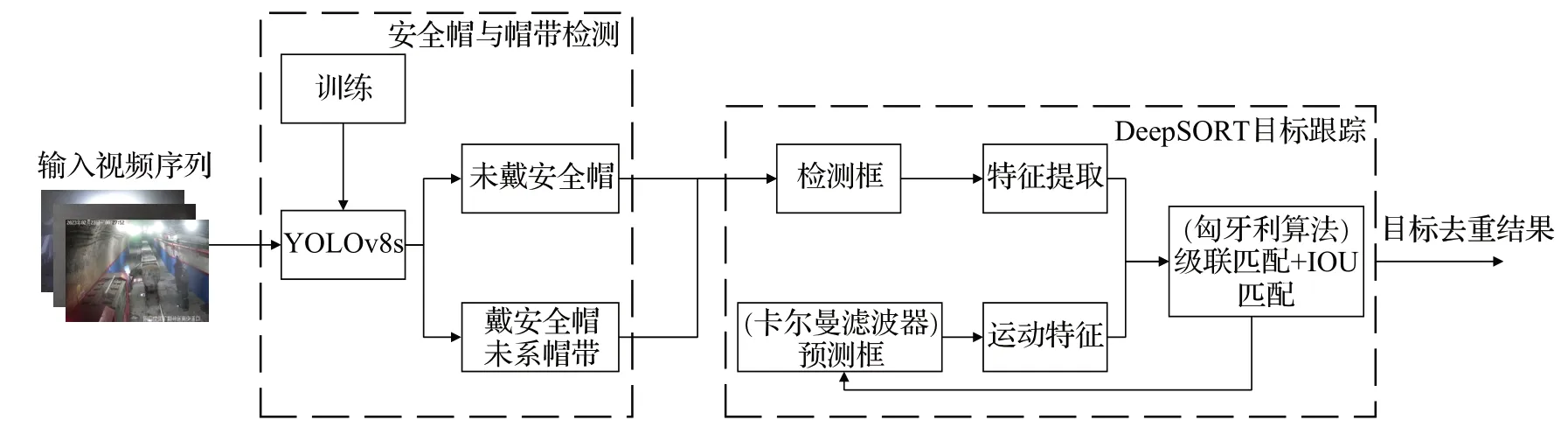
图1 整体流程图Fig.1 Overall frame diagram
1.1 改进的总体流程
步骤1将视频输入改进YOLOv8s 检测器,检测后得到三种类型的检测框:人、安全帽、帽带。不戴安全帽与戴安全帽未系帽带的检测框是两个不同的类别。然后计算检测框的中心坐标、长宽比、高度以及它们各自在图像坐标中的速度。
步骤2卡尔曼滤波将获得的中心坐标、长宽比、高度和它们各自的速度作为对物体的直接观察,并计算出预测的目标位置。若当前帧的检测结果与卡尔曼滤波的预测结果相匹配,卡尔曼滤波器会更新轨迹,进入下一帧的目标跟踪。
步骤3当检测失败时,会出现轨迹没有匹配检测结果的情况;当出现新目标时,会出现检测结果没有匹配轨迹的情况,这两种情况都会导致匹配失败。计算出的ⅠoU对预测框和检测框进行第二次匹配,卡尔曼滤波器在第二次匹配成功后更新轨道。
步骤4为再次匹配失败的检测框建立新的轨道,并将其标记为未确认轨道。当未确认轨道能成功匹配三次时,就修改为确认轨道,并重复步骤2~3。对再次匹配失败的预测框的状态进行判断,以确定该轨道是被保留还是被删除。如果该轨道被标记为未确认的,它将被删除。如果该轨道被标记为确认的,并且在有效期内匹配失败,它将被删除。否则,该轨道将被保留,并重复步骤1~3。
1.2 改进YOLOv8s对安全帽的检测
在卷积神经网络中,高层次特征图通常具有更加抽象的信息,对目标的位置信息更为敏感;低层次特征图具有更高的空间分辨率,对细节信息表述得更为清晰。由于小物体通常在空间中分布稀疏,在高分辨率特征图上的密集计算范式是非常低效的。因此借鉴级联策略的思想,提出一种由高到低的方法来减少计算成本,首先在高层次特征图上预测小物体的粗略位置,然后计算低层次特征图上的具体位置。如图2,首先找到高层次特征图上的粗略位置,再自顶向下定位到高分辨率特征中的小物体。

图2 小物体查询机制Fig.2 Small object search mechanism
如图3所示,在解耦头部分新增一个与分类和回归头平行的查询头,用于预测小物体的粗略位置。查询头使用特征图Pl作为输入,并输入热力图Vl∈ℝH′×W′,表示网格(i,j)中包含一个小物体的概率。在训练过程中,预先设定阈值sl,每一层小于sl的目标被定义为小物体。对于小物体o,通过计算其中心位置(xo,yo)与特征图各个位置之间的距离来编码查询头的目标图,并将距离小于sl的位置设置为1,否则为0。在推理过程中,只查询预测分数大于阈值σ的位置,然后将映射到上四个邻近位置作为关键位置,定义如下:
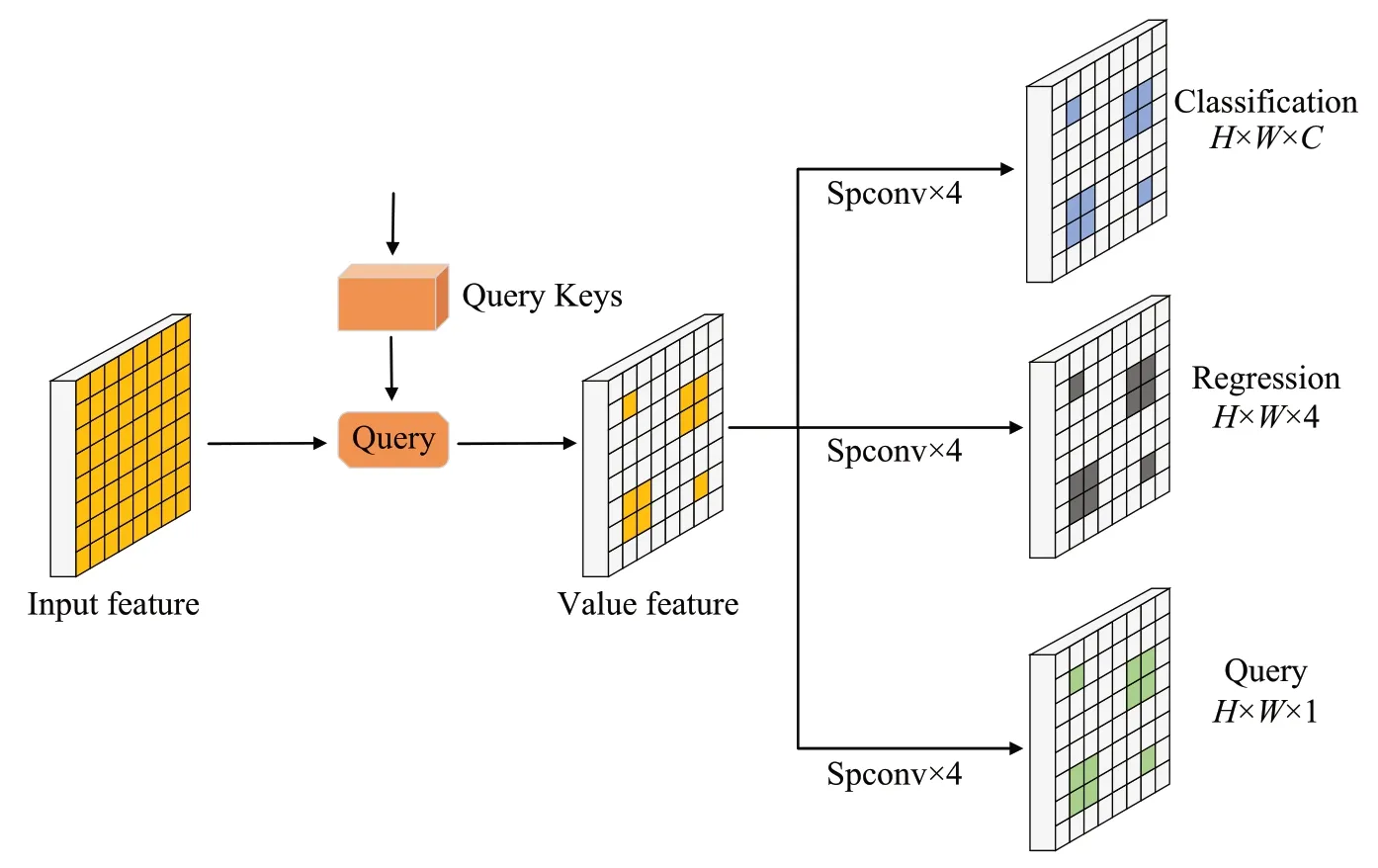
图3 解耦头部分新增查询头Fig.3 New search head in decoupled head
pl-1上的所有集合起来形成关键位置集,然后三个解耦头只处理小物体的位置信息并用于下一级的查询。具体来说,从pl-1中提取特征并构建稀疏张量,然后利用稀疏卷积计算第l-1层的结果。从单一的Pl生成查询{ql} 会导致在查询过程中随着l的减少,相应的关键位置kl的大小呈指数级增长。所以采用级联的策略来查询,能最大限度地提高推理速度。例如,Pl-2的查询只会从{kl-1} 产生。
分类头和回归头的训练与原始YOLOv8s相同。使用FocalLoss 来训练查询头:令在Pl上的小物体为,首先计算Pl上特征位置(x,y)与所有小物体中心点的最小距离Dl:
因此,查询图V*l:
对于每一层Pl,损失函数定义如下:
其中,Ul、Rl、Vl分别为分类、回归和查询的输出,、为对应的真实值,LFL为focal loss,Lγ为边界框回归损失。
原始YOLOv8s 通过3 个不同尺度的检测层可以针对性的预测大、中、小目标,但由于安全帽帽带更加微小,YOLOv8s并不能满足检测需求。因此,有必要增加一个高分辨率检测层来负责帽带的检测。如图4所示,在CM-YOLOv8s模型中,640×640大小的输入图像分别经过4 倍、8 倍、16 倍和32 倍的下采样。在前向推断的过程中,4个检测层分别输出预测信息,包括预测框的中心点坐标(x,y)、宽度w、高度h和置信度参数c,通过与标签信息进行比对,计算预测值与真实值之间的损失,进而指导反向传播中参数的调整,从而在反复训练的过程中优化模型性能,整个损失公式如下:
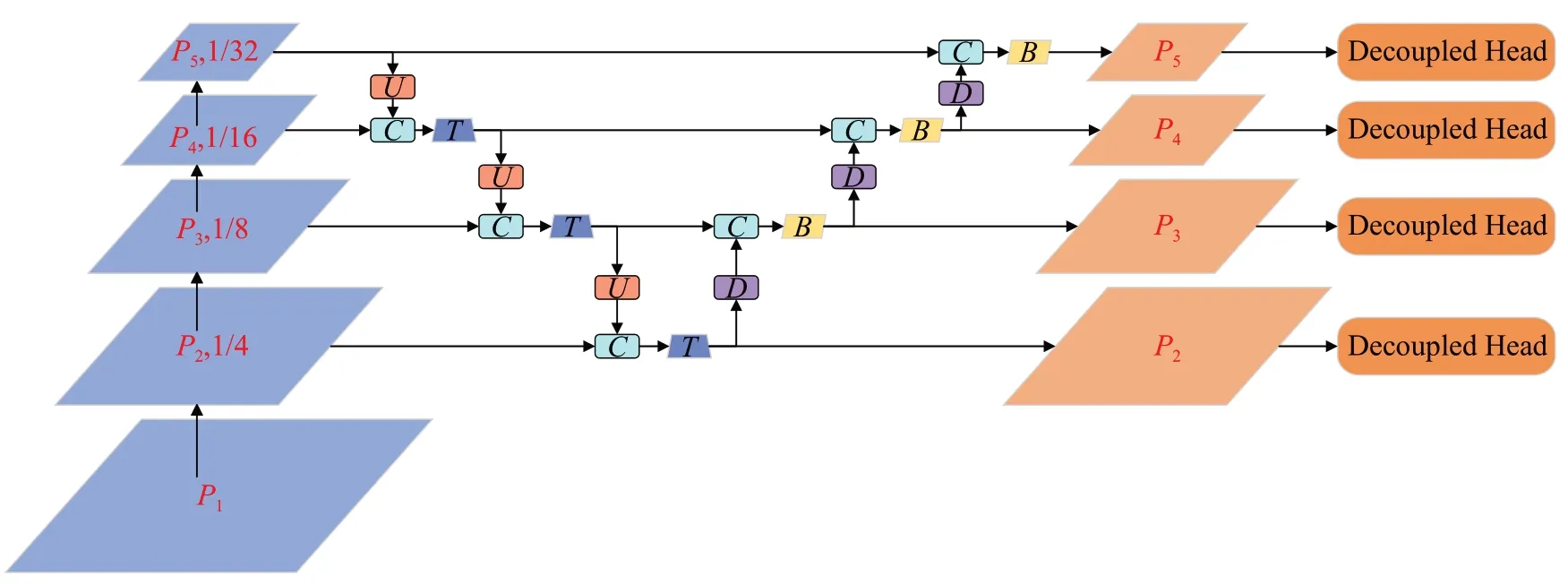
图4 改进CM-YOLOv8框架图Fig.4 Ⅰmproved CM-YOLOv8 framework
由于加入P2这样的高分辨率特征,训练样本会发生明显的变化,所以使用βl重新平衡每一层的损失。P2上训练样本的总数甚至比P3到P7的训练样本总数都要大,如果不降低高分辨率特征层的权重,训练就会被小目标所主导。所以需要重新平衡不同层的损失,使模型同时从所有层学习。
1.3 改进DeepSORT对人员进行追踪
用于提取外观特征的方法通常基于一个简单的网络结构,该结构由两层卷积网络和六个残差单元组成的深度堆叠残差网络构成。尽管在通用数据集上,这种网络模型能够取得优异的效果,但在光照不均、烟尘较多的井下环境下,其在追踪井下作业人员的能力就显得有限。鉴于此,本文引入了一种新的特征提取架构,即一次性聚合架构(OSA),以取代DeepSORT原有的深度堆叠残差块。这种新架构旨在在增强特征提取效率的同时,减少了对重复特征处理和存储的需求,从而提高了系统性能。相应的一次性聚合架构的示意图如图5所示。
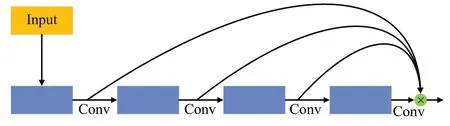
图5 OSA结构Fig5 OSA structure
在更新外观状态的过程中,采取了基于指数加权移动平均的策略来刷新第t帧中第i个目标轨迹的外观特征。
其中,代表表示第t帧中第i个目标轨迹的外观特征嵌入,α代表动量因子。
2 实验结果与分析
2.1 实验准备
2.1.1 数据集
目前大多安全帽数据集场景为工地,煤矿井下工况的公开数据集不多。为了解决这一问题,利用Opencv从井下监控视频中截取图像,得到10 885幅不同角度的图像,并使用标注工具labelⅠmg 对每个图像进行标注。将得到的数据集按照特定比例分为训练集和测试集如表1所示。在最后的10 885幅图像数据集中,训练集中的样样本数为9 371,测试集中的样本数为1 514。
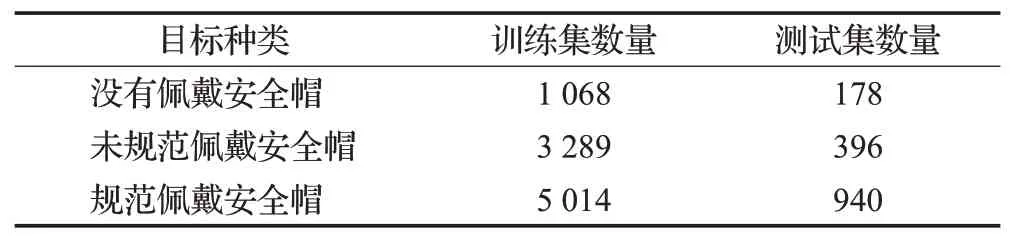
表1 训练集、测试集比例Table 1 Proportion of training set and test set
2.1.2 实验环境
本文的实验在Windows11上执行,安装了Pytorch1.10.2、Python3.9 和Cuda11.3,训练和测试是在CPU:Ⅰntel®CoreTMi5-10600KF,4.10 GHz;GPU:NVⅠDⅠA RTX3090,24 GB 显存上执行的。所有程序都用Python3.9 实现,CUDA 和CuDNN 被用于GPU 计算,OpenCV 被用于图像显示和处理。
2.1.3 评估指标
(1)目标检测评价指标:
本研究通过计算模型的精度召回率、mAP、F1-score、和FPS 来评估系统性能,以分析模型性能。这些计算公式如下。
式(7)和(8)中,真阳性(TP)样品的ⅠOU大于某个阈值,负样本是ⅠOU 小于特定阈值的假阳性(FP)样本,FN是假阴性示例,这意味着模型对负类的预测不准确。式(9)中,mAP 是所有类别中AP 的平均值,它表示模型在类检测中的整体性能。式(10)中,F1 分数通过计算分类器的调和平均值来组合分类器的精度和召回率。
(2)跟踪算法评价指标:
在多目标跟踪系统中,编码变换次数(ⅠDS)衡量的是跟踪过程中目标的标识编号发生更改和遗失的频率。该指标的数值较低意味着跟踪的连续性和准确性较高。另一个关键指标是多目标跟踪准确率(MOTA),它反映了系统在整个跟踪周期内对目标数量的识别准确性以及误差的累积情况,该指标通过公式(11)进行定义:
其中,Mm代表漏检率,Mf代表误检率,IDS 代表编码转换次数,GTt代表目标数量。
多目标跟踪精度(MOTP)是用来评估多目标跟踪系统定位精度的指标。它计算的是系统跟踪到的目标位置与实际目标位置之间的平均误差,通常以像素为单位。这个度量标准关注的是目标位置预测的准确性,而不是识别目标的准确性。MOTP的值越高,说明跟踪到的目标位置越接近于真实值,因此系统的定位能力越精确。
2.2 目标检测结果分析
从数据集中共选取了1 082 张图像进行测试,绘制了不同对比模型在不同类别下的P-R曲线,曲线与X轴(precision)和Y轴(recall)所围成的面积记为平均精度,面积越大代表模型性能越好,具体指标结果如图6 所示,并对性能指标值进行了比较,见表2。结合表2 和图6分析得知,Faster R-CNN对井下安全帽佩戴情况有一定的检测能力,相对于单阶段检测算法而言,虽然实时性远不能达到工业需求,但在多数场景下各类预测框的定位和大小正确且类别判断基本无误。这证明了输入端图像分辨大小确实能影响模型的检测性能,特征图分辨率越大,检测小物体的性能越强。YOLO系列算法相较于Faster R-CNN,各项指标均有一定程度的提升,其中检测速度最为显著,但漏检与误检的情况严重,无法满足对帽带这一小目标在检测中对准确率的要求。
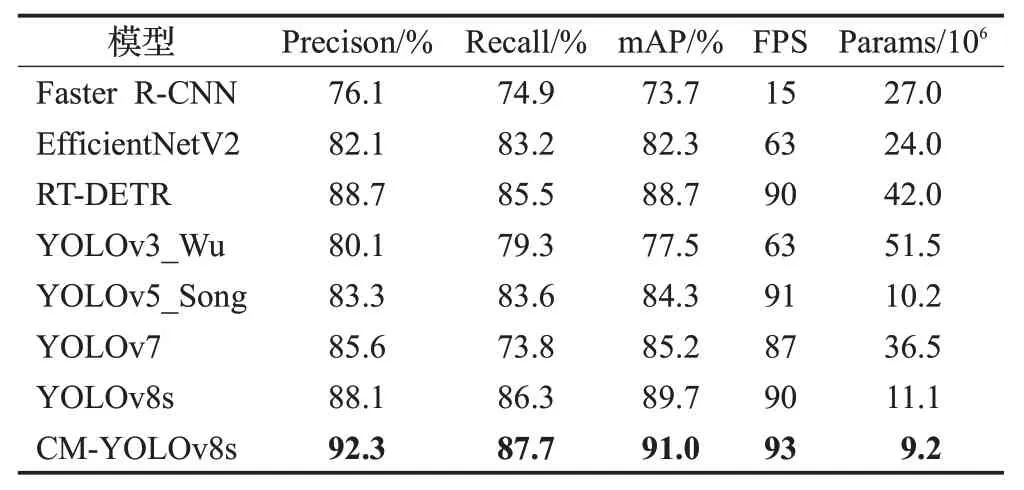
表2 不同模型对比结果Table 2 Comparison results of different models

图6 不同模型P-R的曲线Fig.6 Curves of Precision-Recall for different models
而本文提出的CM-YOLOv8s对安全帽有更好的检测能力并能检测出帽带佩戴情况,相比于Faster R-CNN、YOLOv3_Wu[18]、YOLOv5_Song[19]、YOLOv7和YOLOv8s,mAP分别提升了17.3个百分点、13.5个百分点、6.7个百分点、5.8 个百分点和1.3 个百分点,且该算法预测框的大小和位置分布更加准确,对于其他算法均存在的漏检和误检问题也能较好改善。由于引入了更高分辨的特征图会消耗一定的计算时间,相较于YOLOv5s,模型检测速度虽有所减慢,但仍是Faster R-CNN 的6 倍,YOLOv3的1.6倍,EfficientNetV2的1.4 倍,可以满足实时性的需求。此外,模型参数量仅为Faster R-CNN的1/3,YOLOv3 的1/6,RT-DETR 的1/5,YOLOv5 的1/4,易嵌入巡检机器人等小型设备。
对不同算法的检测效果进行可视化分析,见图7。前两列为光线较好的场景,后面两列分别为井下高粉尘、强光扰的情况。从图7 可以看出:图像质量较好时,由于目标较小、目标与护栏之间边缘细节特征的不准确,导致其他算法均存在漏检与误检,只有CM-YOLOv8s算法能够准确地检测所有目标,且拥有更低的漏检率。而当环境存在视觉干扰,如高浓度的粉尘、浓密的水雾或其他颗粒物时,其余算法的检测效果急剧下降。只有CM-YOLOv8s 算法能凭借先进的特征学习技术,准确地检测出矿工与安全帽。综合各项实验指标来看,CMYOLOv8算法可以较好地平衡检测速度与精度,略微降低检测速度,但显著地提升了检测精度,并能够满足目标检测的实时性需求,更加适用于井下安全帽规范佩戴的检测任务。

图7 不同模型检测安全帽佩戴效果Fig.7 Different models to test effectiveness of helmet wear
进行消融实验研究以分析并验证每个改进模块如何影响检测精度和速度。如表3所示,当加入高分辨率特征图P2(策略1)时,精度虽然得到了一定的提升,但是FPS却降至23,这恰恰证明了引入高分辨率特征图虽然能实现对小物体更好的检测,但所带来巨大的计算成本是不可避免的。在解耦头新增一个并行的查询头(策略2)能显著提高精度,验证了额外目标监督的有效性。最后,通过级联查询策略(策略3),检测速度从23 FPS提升到93 FPS,显著提高了检测速度。

表3 消融实验Table 3 Ablation experiment
2.3 井下人员跟踪结果与精度分析
为了验证本文算法在井下人员多目标跟踪方面的表现,使用原算法的参数设置在自建数据集上进行验证,对检测及跟踪进行组合消融实验以验证有效性,结果如表4所示。
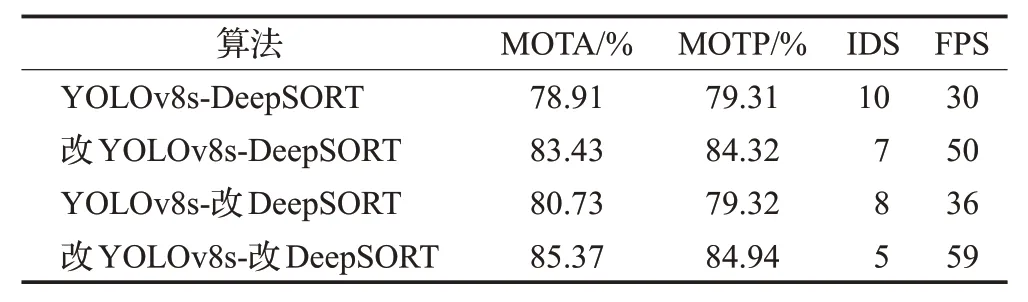
表4 多目标跟踪结果对比Table 4 Comparison of multi-target tracking results
表4展示了井下人员多目标跟踪结果的比较。从表中可以看出,采用改进算法的YOLOv8s-DeepSORT 系统在多目标跟踪准确率(MOTA)和多目标跟踪精度(MOTP)上都有所提升。原始的YOLOv8s-DeepSORT算法MOTA为78.91%,而改进后最高可达85.37%,显示出明显的性能提高。同样,MOTP从79.31%提升至84.94%。编码变换次数(ⅠDS)也有显著下降,从10次减少到5次,减少了一半,这表明跟踪的稳定性得到了增强。每秒处理帧数(FPS)的增加表明,改进后的算法在保持较高跟踪准确率的同时,还提高了处理速度。总的来说,改进措施显著提高了井下多目标跟踪的效率和准确性。
此外,为了进一步验证上节所提目标检测算法的有效性,使用不同的目标检测算法结果作为DeepSORT的输入,实验结果如表5所示。
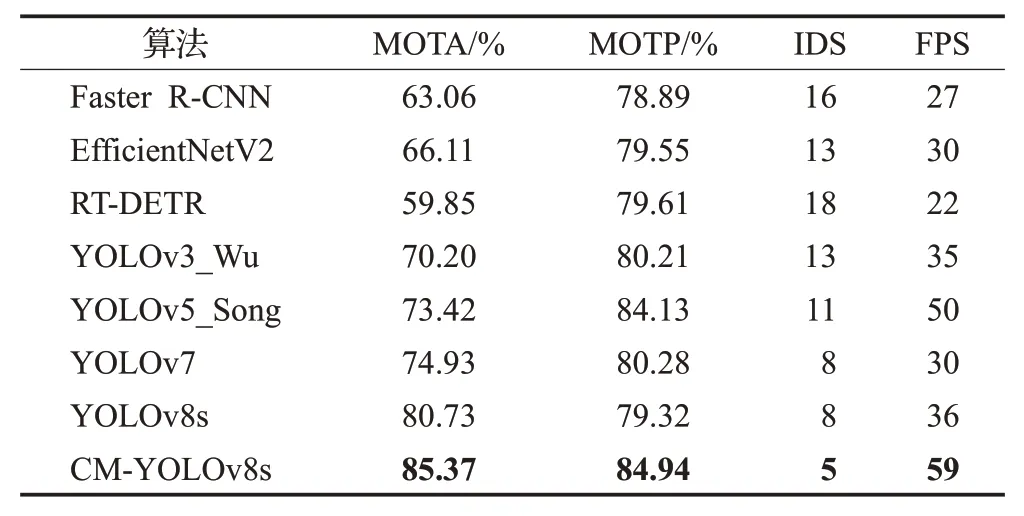
表5 不同检测方法对多目标跟踪效果的影响Table 5 Ⅰmpact of different detection methods on multi-target tracking performance
帽带检测方法的性能一定程度上决定了跟踪任务的效果。如表5所示,各种检测方法在多目标跟踪准确率(MOTA)、多目标跟踪精度(MOTP)、ⅠD 切换次数(ⅠDS)和每秒帧数(FPS)上的表现均有所不同。其中,CM-YOLOv8s在MOTA和MOTP上都展现了最高的精度,分别达到85.37%和84.94%,这意味着它在检测和定位安全帽的准确性上都表现得非常出色。此外,CMYOLOv8s 的ⅠD 切换次数仅为5,是所有比较方法中最低的,说明其在跟踪过程中的连续性和稳定性都非常好。FPS 值为59,表明CM-YOLOv8s 在实时性上的表现也非常优秀。综上所述,CM-YOLOv8s 在安全帽帽带检测和对异常人员跟踪任务上均展现出了明显的优越性。
2.4 井下现场应用
为了更加直观地展示本文跟踪算法的效果,本文将算法应用到陈四楼煤矿实际场景中,并在自建井下安全帽数据集上对矿工的安全帽佩戴进行检测。
如图8 所示,主控界面采用BS 架构,由JAVA 语言编写。监测人员通过主控界面实时及历史数据对工作面作业人数是否正确佩戴安全帽进行判断。
图8 主控界面检测图Fig.8 Main control interface detection diagram
图9 展示了井下实际应用中的多目标跟踪结果。从第一栏图片可以观察到,在井下光照良好的环境中,检测出作业人员佩戴安全帽的情况,对于未规范佩戴安全帽人员,在其持续行走一段距离后,仍能准确匹配序号。从第二栏图片可以观察到,当图像质量不佳,本文所提出的算法仍可以较好地检测出作业人员佩戴安全帽的情况,能够进行稳定的检测跟踪并且其编号没有发生改变,也能够证明本文改进的算法在复杂环境中具有良好的鲁棒性。

图9 多目标跟踪效果Fig.9 Multi-target tracking effect
3 结语
本文提出了一种改进YOLOv8s 和DeepSORT 的井下人员安全帽帽带检测及人员跟踪算法。在YOLOv8s模型的基础上,引入更高分辨率的特征图并新增了一种级联查询机制,在不提高计算成本的前提下能完成对小目标更精准的检测。跟踪阶段使用更深层卷积强化了DeepSORT 的外观信息提取能力。利用自建安全帽检测及跟踪数据集对本文算法进行验证。结果表明,本文安全帽规范佩戴检测算法的准确率达到了96%,检测速率达到每帧0.019 s。多目标跟踪算法准确率提高到了85.37%,目标编号改变次数降低了50%,并且拥有良好的实时性。本文构建的改进YOLOv8s 和DeepSORT 的安全帽佩戴检测与跟踪算法能够实现在井下复杂环境中对未规范佩戴安全帽作业人员的实时检测及跟踪,其参数量也缩减到原来的23%,不仅可以部署于煤矿监控系统,未来也可以部署在井下巡检机器人等小型嵌入式设备上,可以为井下人员的安全生产提供良好的保障。
