改进YOLOv5的汽车齿轮配件表面缺陷检测
2024-03-12朱德平姚景丽
朱德平,程 光,2,姚景丽
1.北京联合大学北京市信息服务工程重点实验室,北京 100101
2.北京联合大学前沿智能技术研究院,北京 100101
随着现代工业的发展和技术的进步,汽车行业已成为全球经济的重要组成部分。汽车齿轮作为传动系统中不可或缺的部件,其性能和可靠性对整个车辆的运行和驾驶体验至关重要,确保齿轮配件的质量和完整性成为汽车制造商和用户关注的焦点。齿轮配件的表面缺陷对其功能和寿命产生直接影响,这些缺陷可能导致齿轮的早期故障和性能下降。因此,及早发现和准确评估齿轮配件表面缺陷对于确保汽车的安全性、可靠性和经济性至关重要。传统的齿轮配件表面缺陷检测方法主要依赖于人工目视检查,这种方法存在主观性高、效率低、易出错等问题。近年来,随着计算机视觉和图像处理技术的快速发展,自动化的表面缺陷检测方法逐渐成为研究和应用的热点。
随着工业4.0[1]的到来,制造业正朝着数字化制造[2]的转型迈进,这一转型对于工业产品的质量检测任务提出了更高的精度要求。为了应对这一挑战,基于深度卷积神经网络的深度学习在缺陷检测领域取得了很大的突破。深度卷积神经网络(CNN)等深度学习模型通过从大量标注图像中学习特征表示和分类规则,能够高效地检测和识别不同类型的缺陷。这些方法在自动化程度、检测准确性和处理速度方面都取得了显著的改进,为齿轮配件制造商提供了一种更可靠和高效的缺陷检测解决方案。然而深度学习方法在齿轮配件缺陷检测领域仍存在一些挑战和待解决的问题。例如,样本不平衡、多类别缺陷的检测、小尺寸缺陷的识别等仍然是需要关注的问题。此外,深度学习模型的可解释性和鲁棒性也是需要进一步研究的方向。
本文旨在研究和探索汽车齿轮配件缺陷检测领域的最新进展和挑战,提出一种YOLO-CNF模型,并将其应用于齿轮配件表面的缺陷检测。
1 相关工作
人工视觉检测一直是汽车齿轮配件缺陷检测中最早且最常用的方法之一。然而,该方法存在主观性高、检测速度慢以及由于操作员疲劳而导致的误判等问题。此外,人工视觉检测也受限于操作员的经验和专业知识,因此需要更准确、快速和自动化的方法来替代或辅助。随着计算机视觉技术的不断发展,基于图像处理和特征提取的自动化缺陷检测方法逐渐在实际生产中得到应用。这些方法通过边缘检测、阈值分割和形态学操作等图像处理算法对缺陷图像进行预处理、分割和特征提取,然后利用统计学方法或支持向量机(SVM)[3]、决策树等机器学习算法对提取的特征进行分类,以检测和定位缺陷。Jian等人[4]提出了基于差分投影的联合缺陷识别方法和改进的模糊C 均值聚类(ⅠFCM)算法。前者消除了环境光线变化对待测图像灰度的影响,后者能够从噪声图像中分割出具有模糊灰色边界的缺陷。然而,该方法非常依赖于模板图像。Zhang 等人[5]将离散傅立叶变换(DFT)和最佳阈值引入缺陷检测中,通过DFT中的谱残差法确定缺陷位置并对其进行突出显示,通过多次迭代确定缺陷区域分割的最佳阈值。Huang等人[6]提出了一个完整的基于机器视觉的手机面板表面缺陷检测框架,该框架由不同的特征提取算子和SVM分类器组成,该方法在精度和速度方面都取得了不错的效果。
传统的基于图像处理和特征提取的方法在处理复杂的产品图像和缺陷场景时存在一定的局限性。近年来,深度学习技术在目标分类[7]、目标识别[8]、目标跟踪[9]以及自动驾驶[10]等领域取得了良好的效果。由于神经网络模型可以自动从数据中学习到最具有区分性的特征,而无需手动设计和提取特征,这使得深度学习在缺陷检测领域具有巨大潜力,并为提高检测准确性和效率提供了新的机遇。因此,许多研究人员开始采用深度学习方法来解决缺陷检测问题。Ding 等人[11]提出了一种基于卷积神经网络(CNN)的印刷电路板缺陷检测方法,与传统检测方法相比,具有较高的检测性能。Chen 等人[12]将深度学习技术引入供电系统中接触网支架装置上紧固件缺陷检测领域,提出了一种基于改进的SSD网络自动检测方法,可以快速而准确地检测出紧固件的缺陷。He等人[13]提出一种基于Faster R-CNN的端到端的钢表面缺陷检测方法,该方法将取局部特征与全局特征相结合来提高检测性能。Bao等人[14]使用改进的YOLO模型检测输电线路中的部件缺陷,该方法用双向特征金字塔网络(BiFPN)[15]取代了原有的PANet 特征融合框架,使网络更加关注对输出特征贡献更大的特征映射。
综上所述,深度学习技术已经被引入缺陷检测领域,并取得了很好的效果。然而,目前应用深度学习技术检测齿轮配件表面缺陷的研究还很少。为此,本文提出一种新的YOLO-CNF 模型,并将其应用于汽车齿轮配件的缺陷检测。
2 本文方法
YOLOv5是一种出色的通用目标检测模型,它具有更小的参数量和更快的训练速度,在自动驾驶、医疗影像分析、机器人导航等领域得到了广泛应用。本文将YOLOv5应用到汽车齿轮配件表面缺陷检测领域,并改进YOLOv5以解决对微小缺陷检测效果不佳的问题。
本文的所提出的方法是通过改进YOLOv5s的网络结构实现的,命名为YOLO-CNF,如图1 所示。它由骨干网络、中间层和预测层共三个部分组成。骨干网络主要用于提取输入图像的特征,在骨干网络的P2 层引入CBAM(convolutional block attention network)模块[16],可以增强模型对微小缺陷的特征提取能力。
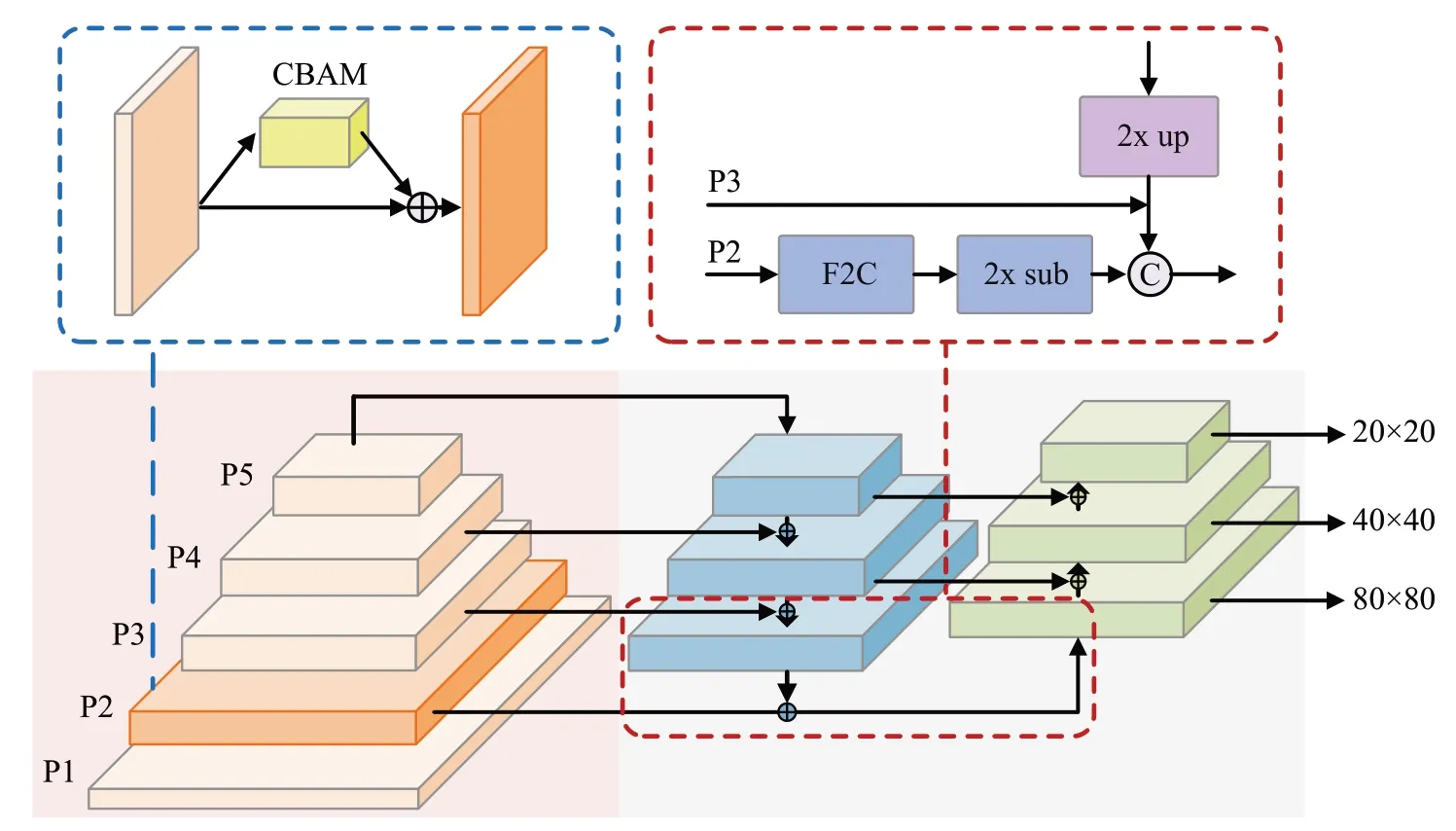
图1 YOLO-CNF模型结构Fig.1 Model structure of YOLO-CNF
中间层主要用于融合多尺度的特征,为了进一步提高缺陷位置的感知能力,本方法在原有PAN结构[17]的基础上额外融合了P2层的特征信息。最后的输出层使用三个不同尺度的特征图对缺陷目标进行分类和回归定位。针对ⅠoU 对微小缺陷定位偏差的敏感性,利用NWD 对回归损失进行优化,从而改善模型对微小缺陷定位的准确性。
2.1 CBAM模块
CBAM 注意力模块的通道注意力机制允许模型自动学习并聚焦在输入特征图的重要通道上。对于汽车齿轮表面缺陷检测来说,不同类型的缺陷可能在不同通道中有不同的视觉特征表现,例如颜色、纹理等。CBAM能够自适应地增强与缺陷相关的通道,从而提高了模型对缺陷特征的感知能力,使算法更加敏感和准确。
此外,CBAM模块中的空间注意力机制有助于模型捕捉输入特征图中不同位置的相关性。在齿轮表面缺陷检测中,缺陷可能出现在不同位置和尺度上。通过引入空间注意力,模型可以更聚焦于可能存在缺陷的区域,降低误检的风险,提高检测的可靠性。
因此,为了增强模型对微小缺陷的关注和识别能力,在骨干网络中加入了CBAM 模块(convolutional block attention network)。该模块由两个关键部分组成,即通道注意力模块和空间注意力模块,如图2所示。
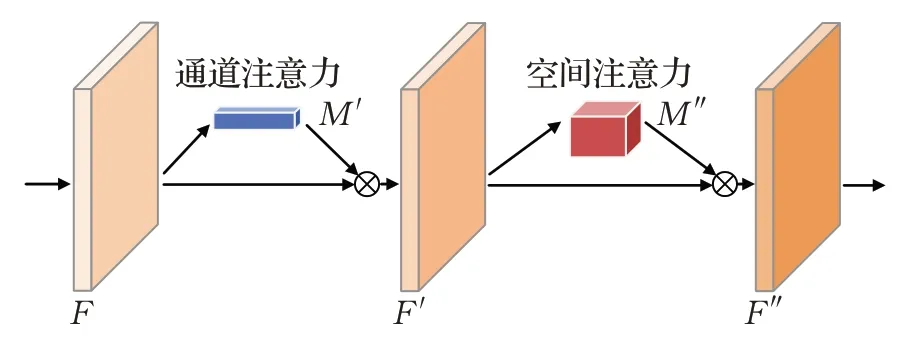
图2 CBAM模块Fig.2 Convolutional block attention network
通道注意力模块的结构如图3所示。首先,输入特征F经过全局平均池化和最大池化操作,以获取每个特征通道的全局信息。然后,通过两个全连接层对这两组池化后的信息进行加权求和,再使用Sigmoid 激活函数对这个结果进行激活处理。最终得到了通道注意力特征图M′,其中包含了对输入特征F不同通道的关注程度的信息。其计算方式见式(1):
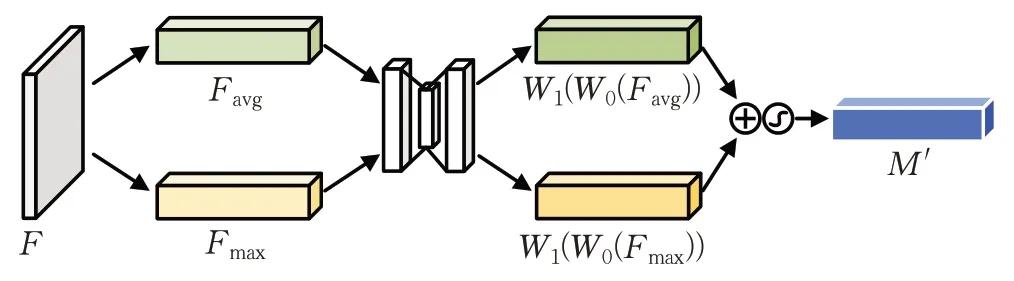
图3 通道注意力模块Fig.3 Channel attention module
空间注意力模块的结构如图4所示。首先,特征图F′ 经过最大池化和平均池化操作,以捕捉其空间信息。接下来通过一个7×7 的卷积操作,将F′降维为一个通道,以便进行后续计算。然后,使用Sigmoid函数生成空间注意力特征图M″,计算方式见式(2)。其中,F′是原始输入特征图F与通道注意力特征图M′ 的乘积。类似地,也可以计算得到F″,其计算方式与F′相同。通过空间注意力模块,可以获得对输入特征图F的空间关注程度的信息,并得到相应的特征图表示。
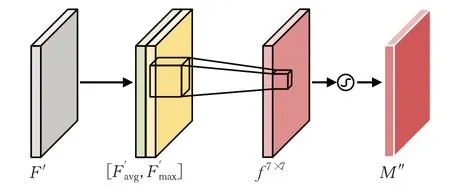
图4 空间注意力模块Fig.4 Spatial attention module
微小缺陷目标往往具有较低的信噪比和较弱的表现形式,这使得它们难以被常规的特征提取方法准确捕捉到。CBAM 模块通过对特征图进行通道注意力和空间注意力的加权处理,来提升模型对重要特征的关注和提取能力。将CBAM 模块引入到骨干网络的P2 层中,使得模型能够更好地捕捉微小缺陷的特征,进而提高了对微小缺陷的识别能力,同时也有助于提升模型的检测和分类准确性。
2.2 浅层特征融合
通过多次连续的下采样处理,YOLOv5的SPP结构生成了大、中、小三个不同尺寸的特征图,这些特征图被输入到特征融合网络中用于目标识别。这种结构的设计使得YOLOv5 能够更好地捕捉目标在不同尺度上的特征,但对于微小缺陷样本而言,它们的尺寸较小,因此在连续下采样的过程中会丢失掉它们的关键位置特征信息,导致微小缺陷的检测效果不够理想。基于特征金字塔网络[18]的思想,经过深度卷积后的特征图携带了丰富的语义信息,但多次卷积可能会导致目标位置信息的丢失,所以不利于小目标的检测,而浅层卷积产生的特征图能够提供更准确的目标位置信息,但在语义信息方面不够丰富。
为了解决齿轮配件缺陷检测任务中小目标特征信息不足的问题,本文设计了F2C 模块,如图5 所示。该模块能够增强浅层特征图中小目标的特征信息。在YOLOv5的检测头中,将经过F2C模块增强后的特征信息与原有特征信息进行融合,从而获得更准确的小目标位置信息,如图6 所示。通过这种方式,能够在保持语义信息的同时增强目标位置信息,从而改善小目标的检测效果。这种策略能够提升模型的准确性,在齿轮配件表面缺陷检测任务中具有重要的意义。
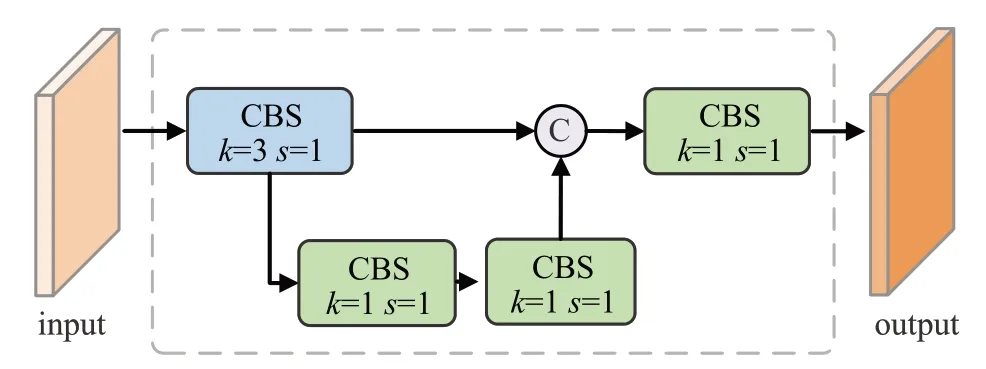
图5 F2C模块Fig.5 F2C module

图6 改进前后检测效果对比Fig.6 Comparison of detection effects
2.3 损失函数改进
在齿轮配件表面的缺陷检测中,有一部分的缺陷的尺寸非常小,仅包含少数像素。而在YOLOv5 中,基于交并比(ⅠoU)的相似度度量对微小目标的位置偏差非常敏感,这会极大地降低针对小目标缺陷的检测能力。为了解决这个问题,引入了一种新的评估标准——归一化Wasserstein 距离(normalized Wasserstein distance,NWD)[19]。该方法使用二维高斯分布来对目标的边界框进行建模,并通过它们之间对应高斯分布的相似度来计算预测目标和真实目标之间的相似度,对于检测到的目标,无论它们是否重叠,都可以通过分布相似度来衡量。归一化瓦瑟斯坦距离的计算方式如式(3)所示:
其中,C是一个与数据集密切相关的常数,(Na,Nb)是一个距离测度,计算方式如式(4)所示。Na和Nb是由真实框A=(cxa,cya,wa,ha)和预测框B=(cxb,cyb,wb,hb)建模的高斯分布。
由于NWD 对目标的尺度不敏感,因此更适合衡量小目标之间的相似度。在回归损失函数中添加NWD损失可以弥补ⅠoU 损失在小目标检测中的不足,同时将ⅠoU 与NWD 损失之间的比例调整为8∶2,如式(5)所示。对损失函数进行以上的改进有助于提高模型对微小缺陷的检测能力。
3 实验
在本章中,对所提出的模型进行了全面的消融分析,包括注意力模块、多尺度融合金字塔结构和损失函数设计,验证了改进模型的有效性。接着,比较了该模型与其他主流模型之间的性能差异。
本实验使用了一台NVⅠDⅠA Quadro P5000 16 GB GPU 进行模型训练,软件环境为Ubuntu 20.04,Python 3.8.13,PyTorch 1.9.0 和Cuda11.1。超参数batch_size 设置为32,学习率设置为0.01,随机梯度下降(SGD)的动量设置为0.937。所有实验均在相同的训练轮数(200 epoch)下进行训练。
3.1 数据集
使用的齿轮配件数据集来自公开的国内某汽车制造企业在生产加工中的真实齿轮配件数据,所有数据由人工在生产流水线中拍摄而得。数据集中的图片均为真实缺陷齿轮的平面展开图,并由专业人员标注。图6展示了3 种缺陷标注后的例图和正常图像的例图,包括:齿面黑皮(hp_cm)、齿底黑皮(hp_cd)、磕碰(kp)。
该数据集包含1 398张带有缺陷的图像和602张无缺陷的正常图像,由于真实场景中缺陷数据量偏少,所以对原数据集使用翻转、色彩抖动、尺度变换、添加噪声等方式进行随机扩充,扩充后的数据集共有3 530 张,表1 展示了最终的数据集所包含的缺陷实例数量。所有的图像按6∶2∶2 的比例进行划分,其中训练集2 118张,验证集和测试集各706张。

表1 缺陷类型与数量Table 1 Classifications and quantity of defects
3.2 评估指标
本文使用准确率(precision,P)、召回率(recall,R)和平均精度均值(mean average precision,mAP)作为评价指标。准确率指的是所有被判定为正例的样本中,真正为正例的样本所占的比例;召回率指的是所有真正为正例的样本中,被正确判定为正例的样本所占的比例;mAP是对所有类别的平均精度(AP)进行平均得到的指标。它们的计算公式分别为:
其中,XTP表示模型正确检测到的目标数量,XFP表示网络模型错误检测到的目标数量,XFN表示模型未检测到的目标数量,c表示类别数。AP 表示单个目标类别的平均精度,其计算公式为:
3.3 实验结果分析
图7 展示了本文所设计的网络和原始YOLOv5s 网络在相同配置下进行200轮训练的mAP曲线。在图中,红色曲线代表本文模型训练时的mAP 曲线,蓝色曲线代表原始YOLOv5s 网络训练时的mAP 曲线。横坐标表示训练的迭代,纵坐标表示mAP值。从图7的结果可以观察到:与YOLOv5s的原始网络结构相比,本文设计的网络模型能够更快速地收敛。在相同的训练轮数下,本文设计的网络模型能够达到更高的精度。
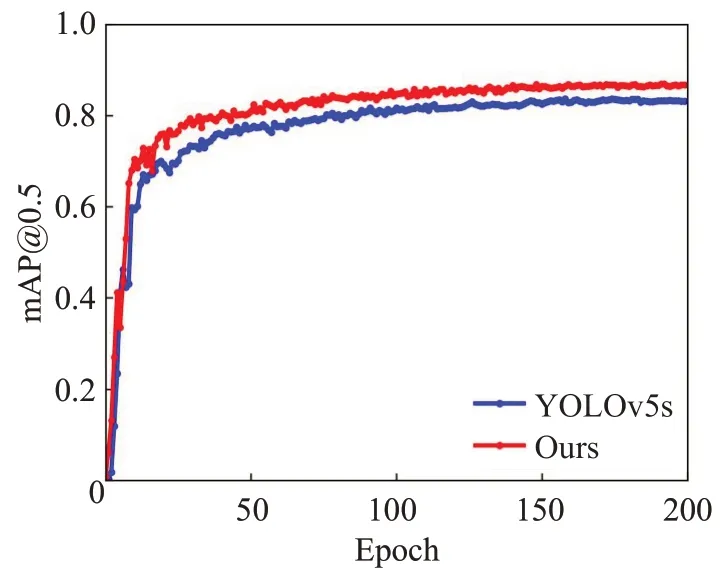
图7 mAP@0.5曲线Fig.7 mAP@0.5 curve of model
模型的PR 曲线(precision-recall curve)如图8 所示,其表示精确率(precision)和召回率(recall)之间的关系。图中蓝色的曲线表示原YOLOv5 网络模型的多类别平均精度,红色曲线表示本文改进后的网络模型的多类别平均精度。从图中可以看出,红色曲线几乎将蓝色曲线完全包裹住,说明本文改进后的模型性能要优于原YOLOv5s模型。
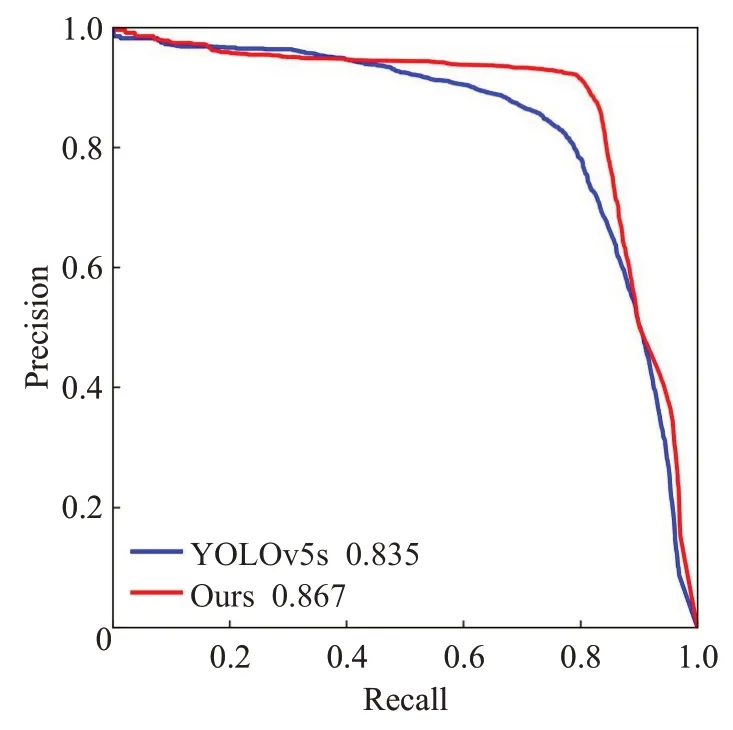
图8 模型P-R曲线图Fig.8 P-R curve of model
本文在测试集上使用NVⅠDⅠA Quadro P5000 对YOLOv5和改进后的网络模型进行推理测试,并将结果记录在表2中。与YOLOv5模型相比,改进后的模型在精确率方面提升了5.6个百分点,召回率提升了4.9个百分点,mAP@0.5提升了3.2个百分点。三个指标均显示出改进后的模型优于YOLOv5s 模型,这意味着改进后的模型在齿轮配件缺陷检测任务中能够更准确地定位和识别缺陷。

表2 实验结果对比Table 2 Comparison of experiments 单位:%
图9 展示了YOLOv5s 和本文改进后的网络模型在测试集上的检测效果对比。由图可知,YOLOv5s 模型能够检测出大多数缺陷目标,但在尺寸较小的缺陷目标上存在漏检的情况。相比之下,本文改进后的网络模型具有更高的准确性和鲁棒性,它能够更精确地检测出缺陷目标区域,减少了漏检的情况,尤其是尺寸较小的缺陷目标,使得模型能够更可靠地识别出真正的缺陷目标。检测效果表明本文改进后的网络模型能够提高缺陷检测系统的性能,并在实际应用中取得更好的效果。

图9 缺陷示意图Fig.9 Defect diagram
3.4 消融实验
为验证本文提出的YOLO-CNF中的各个改进方法的有效性,设计了5 组实验,每组实验在不同条件下进行。实验设置如下:
(1)使用原始的YOLOv5模型,作为消融实验的基线;
(2)E1 在骨干网络的P2 层中引入CBAM 模块,以增强特征表示能力;
(3)E2使用F2C模块对浅层特征进行融合,以提取更全面的目标特征信息;
(4)E3 在回归损失中增加NWD 损失,以进一步优化目标位置的精度和准确性;
(5)将本文模型与以上实验结果进行对比,以评估综合效果。
实验结果如表3所示,实验结果展示了各项改进方法对模型性能的影响。
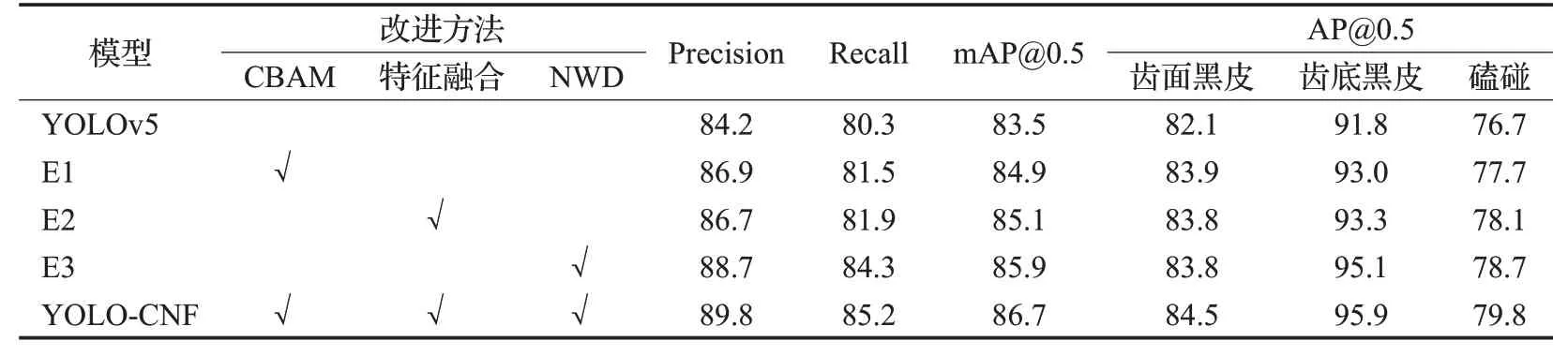
表3 消融实验对比Table 3 Comparison of ablation experiments单位:%
首先,添加CBAM模块使得mAP提升了1.4个百分点。这表明CBAM注意力模块通过自适应地增强通道和空间信息的关注度,提高了YOLOv5模型的特征提取能力和对象检测性能。接着,添加F2C特征融合模块使mAP提升了1.6个百分点。这证明了本研究提出的F2C模块对浅层卷积产生的特征进行了有效增强,进一步提升了模型对缺陷检测的性能。此外,添加NWD 损失函数使得mAP提升了2.4个百分点。这表明NWD损失函数有效分配了边界框中不同像素的权重,在训练过程中能够更好地引导模型学习目标的表示和定位。最后,将这三种改进方法综合应用的本文模型使得mAP提升了3.2 个百分点,最终证明了各个方法在提高模型性能方面的互补作用。
3.5 与其他模型对比
为了客观评价本文模型在齿轮配件表面缺陷检测方面的性能,本文与现有的具有较高综合性能的目标识别模型进行了对比实验,包括SSD[20]、Faster RCNN[21]、Vision Transformer[22]以及YOLO系列[23-25]其他模型。所有实验均在相同的设置下进行200 次迭代训练。实验结果见表4。与早期的SSD 和Faster RCNN 检测模型相比,本文模型在各个性能指标上都远超它们。与YOLO系列的X、v7、v8s 模型相比,mAP 分别提升了2.4、0.8、5.1 个百分点。此外,本文模型的参数大小为7.32 MB,仅略有增加,远远小于其他检测模型。改进后的模型的检测速度为43 帧/s,基本满足检测要求。通过一系列的实验对比,得出结论进一步验证了本文模型在齿轮配件缺陷检测问题上的优越性和可行性。

表4 不同模型实验对比Table 4 Experimental comparison of different models
除此之外,本文选取北京大学智能机器人开放实验室公开的PCB缺陷数据集对模型的性能做进一步验证,该数据集一共包含6类缺陷,是典型的小目标缺陷数据集。实验结果如表5所示。与基线YOLOv5相比,本文提出的YOLO-CNF算法的召回率和mAP值均优于基线模型。其中召回率提升了1.9个百分点,mAP提升了1.5个百分点。上述对比实验进一步验证了本文方法的有效性和可靠性。

表5 在PCB数据集上的实验对比Table 5 Experimental comparison on PCB dataset单位:%
4 结束语
针对汽车齿轮配件表面缺陷检测存在缺陷尺寸较小、缺陷对比不明显、易造成漏检误检、检测效率低且精度差等问题,本文提出了一种YOLO-CNF 缺陷检测模型。在原YOLOv5 的骨干网络加入CBAM 注意力机制,使模型更加关注小尺寸缺陷的特征表达;使用F2C模块将P2 层的特征与特征金字塔进行融合,增强模型对于缺陷的定位能力;引入归一化Wasserstein距离来优化现有的回归损失函数,减少尺度差异对检测结果的影响,提升模型对微小缺陷的检测能力。实验结果表明,该模型可以达到86.7%的mAP值以及每秒43帧的检测速度,相较于其他模型具有明显的精度和速度优势,可以满足复杂工业环境中的检测需求。未来的研究方向是继续提升本文模型的检测精度,减少模型参数量提高检测速率,使该模型能够满足在工业设备上进行实际部署和应用的需求。
