高判别精度的区块链交易合法性检测方法
2024-03-12蔡元海宋甫元陈彦宇付章杰
蔡元海,宋甫元,黎 凯,陈彦宇,付章杰
1.南京信息工程大学数字取证教育部工程研究中心,南京 210044
2.西安电子科技大学综合业务网理论及关键技术国家重点实验室,西安 710071
随着区块链技术的快速发展,以比特币为代表的加密数字货币受到了广泛的关注。在拥有庞大活跃用户数量与超万亿美元总市值的繁荣景象之下,大量不法活动也涌现出来,如恐怖主义资助、洗钱、诈骗等。不法分子很容易利用加密货币的用户匿名性、交易去中心化等不稳定的特性,进行金融犯罪活动。然而在区块链新环境下的监管制度还处于初步阶段,传统的中心化监管方式不再起效,而链上非法活动数量却在与日俱增。因此,如何有效利用区块链上交易数据公开透明的有利条件,进行链上交易的合法性检测对于加密数字货币的监管具有重大意义。
目前,根据分类方式的不同,交易合法性检测方法大致可以分为如下四类:基于可视化分析的方法[1-3]、基于聚类[4-6]的方法、基于传统机器学习的方法[7-8]以及基于神经网络的深度学习方法[8-11]。
(1)基于可视化分析的方法。McGinn等人[1]构建了一个自上而下的比特币交易活动可视化系统,能够辅助分析人员直观地发现特定的交易模式。Bistarelli等人[2]设计了一种可视化分析工具BlockchainVis,支持对无用信息的过滤,并可视化分析比特币中的特定特征。然而该类方法只能辅助人工分析,并不能满足在交易密度极大的比特币等公链上的实时性分析需求。
(2)基于聚类的方法。Conti等人[4]从比特币支付角度研究勒索软件这类特定类型的非法活动,并结合多输入交易信息与找零地址信息,提出了两种基于启发式规则的聚类方法。Pham等人[5]使用传统无监督聚类方法,如K均值聚类、无监督支持向量机等对在无标签的情况下,检测链上的异常交易行为。该类方法对于样本标签的需求不高,但普遍导致了检测结果的高假阳性率与低检出率,不具备可靠性。
(3)基于传统机器学习的方法。Harlev 等人[7]使用经典机器学习算法如随机森林、梯度提升决策树来进行比特币网络的去匿名化与分类任务。Weber等人[8]在Elliptic数据集上验证了逻辑回归、随机森林与多层感知机三类经典算法的性能,并从实验结果发现随机森林在交易分类任务上有着良好的表现。
(4)基于神经网络的深度学习方法。朱会娟等人[9]设计了一种挖掘特征隐含关系的多特征融合交易检测模型BATDet,有效融合了高层抽象特征与原始特征,具备良好的检测精度。然而该算法整体设计仅关注交易本征信息,未能将交易连接的拓扑结构融入判断,因此损失了大量有效信息。此外,图神经网络作为分析交易图数据的一种最具潜力的方案,也吸引学者进行了相关研究。如Chai等人[10]提出了一种多频图神经网络AMNet,它能够高效的捕获低频与高频信号并进行自适应的组合,因此取得了较好的异常检测性能。然而由于图网络的聚合机制带来的过平滑问题限制了网络的深度,使得网络提取到的信息较为浅层,所以这类算法的检测精度仍存在不足。
本文针对上述检测方法存在的检测精度不足以及未充分利用交易本身与拓扑结构两方面信息的问题,提出基于可信生成特征的深度森林TForest,引入基于Transformer 的图神经网络并结合深度残差网络在双阶段集成策略下进行高效融合,得出多角度分析结果,主要贡献如下:
(1)设计基于基尼指数的特征重排序方法,在此基础上构建基于可变滑动窗口的可信特征生成阶段,解决了深度森林多粒度扫描中存在的特征采样不均衡与子样本混淆的问题。在大幅减少生成特征维度的同时有效提升了深度森林的检测性能。
(2)引入基于Transformer 的图神经网络,以更高效的多头自注意力机制,将链上交易前后链接的拓扑结构信息融入判断。并且添加缓解特征过平滑问题的跳跃连接,避免了图中同一连通分量内的节点隐层表征过于相似进而导致难以区分的弊端。
(3)提出一种双阶段集成策略,以可信深度森林为主导,逐层优化,有效融合不同基类模型得出的交易本征信息与拓扑连接信息两方面判断的结果,提升了整体多角度分析模型T2Rnet的综合性能,取得了可靠的交易合法性检测结果。
1 相关工作
1.1 深度森林
深层神经网络近年来在各项任务下都表现出优秀的性能。然而深度网络还存在着一些缺陷,例如需使用大量标签数据进行训练、模型内部组合结构需精心设计等。为了避免上述问题,Zhou等人[12]探索了基于不可微模块构建深度模型的可能性,提出了深度森林(multi-grained cascade forest,gcForest),整体包含多粒度扫描与级联森林两部分,其中多粒度扫描对原始输入进行转换生成,级联森林在转换特征之上进行判断,结构如图1所示。

图1 深度森林结构图Fig.1 Deep forest architecture diagram
级联结构让模型具备了逐层处理与模型内特征转换的特性,从而可以通过森林进行表示学习。级联森林内每层包含多组随机森林与极端随机树,对输入进行判别并生成类向量作为增强特征,再结合原始输入一起输入到下一层当中,当下一层性能不再提升时便停止级联森林的生长。多粒度扫描结构以多样性的方式在原始输入特征的基础上构造出转换特征向量,提升了整体模型的表示学习能力。具体而言,对输入采用滑动窗口依次提取出大量与窗口大小相同的子样本,将所有子样本标签设置为输入样本标签,再送入随机森林与极端随机数这两种生成模型中进行训练并构造出转换类向量。所有子样本生成出的转换类向量最终拼接起来形成整体转换向量,作为后续级联森林的输入。
然而由于多粒度扫描过程中使用固定的滑动窗口与滑动步长,使得生成的特征维度相比原始输入大幅提升。此外,由于滑动的局限性,原始输入的两端特征只能被少量子样本覆盖,而中部特征则至多可以被采样到与滑动窗口大小相同的次数,这种不均衡的特征采样操作将导致模型忽略位于样本两端的部分重要特征从而影响模型精度。同时提取出的维度一致的子样本之间也存在着非一致性,而在多粒度扫描中并未采取增加区分度的操作即给所有子样本打上了与源样本相同的标签,给生成特征带来了混淆干扰,在本身具有一定不可区分度的任务下将会导致整体检测性能的降低。为解决上述问题,本文设计基于特征重排序与可变滑动窗口的可信特征生成方法,以均衡可区分的方式提取子样本并进一步构造出维度大幅降低的可信特征,以此得到更好的检测精度。
1.2 图卷积网络
图神经网络对于处理如社交网络、交易网络、引用关系网络等图类型数据有着强大的能力。Welling等人[13]从空间角度定义节点的权重矩阵,利用卷积核的参数化方法设计出图卷积模型(graph convolutional network,GCN),解决了谱空间图卷积方法的时空复杂度较高的问题。
然而每个节点无偏聚合周边节点特征的方式导致了在同一连通分量中的节点表征类似,进而产生了过平滑的问题。本文针对此问题,利用多头自注意力机制[14-15]有选择的聚合节点周边的有效信息,同时添加跳跃连接来关注原始信息,减少过平滑问题带来的精度降低。
1.3 残差网络
神经网络利用卷积操作在不断加深的网络层中逐步提取到更抽象的高层特征,因此为了更好的模型表征能力,往往会选择层数更深的网络;然而随着深度增加,由多层反向传播带来的梯度消失会导致网络难以训练进而影响模型精度。为了解决该问题,He等人[16]提出了残差结构,在每个残差模块的输入与输出之间增加一条残差路径,解决了深度网络性能退化的问题。本文将深度残差网络作为基判别器之一,利用其深度结构充分挖掘交易本身信息。
2 融合可信深度森林的双阶段集成交易合法性检测方法
2.1 交易合法性检测整体框架
本文提出了基于可信深度森林与双阶段集成策略的多角度交易合法性检测模型,整体结构如图2 所示,由基类模型判别模块、双阶段集成模块两部分组成。交易数据输入至三种基类判别模型中得到对应的类概率分布输出,再将类概率分布输入至双阶段集成模块中进行融合得出最终预测结果。在基类模型判别模块中,用于交易本征信息分析的两种基模型分别为基于构造可信生成特征的可信深度森林与深度残差网络,用于拓扑结构分析的基模型为基于Transformer 的图神经网络;在双阶段集成模块中,设计一种双阶段策略,结合不同基模型对于正负样本的识别能力,融合多角度分析结果,保证最终预测结果的准确性。
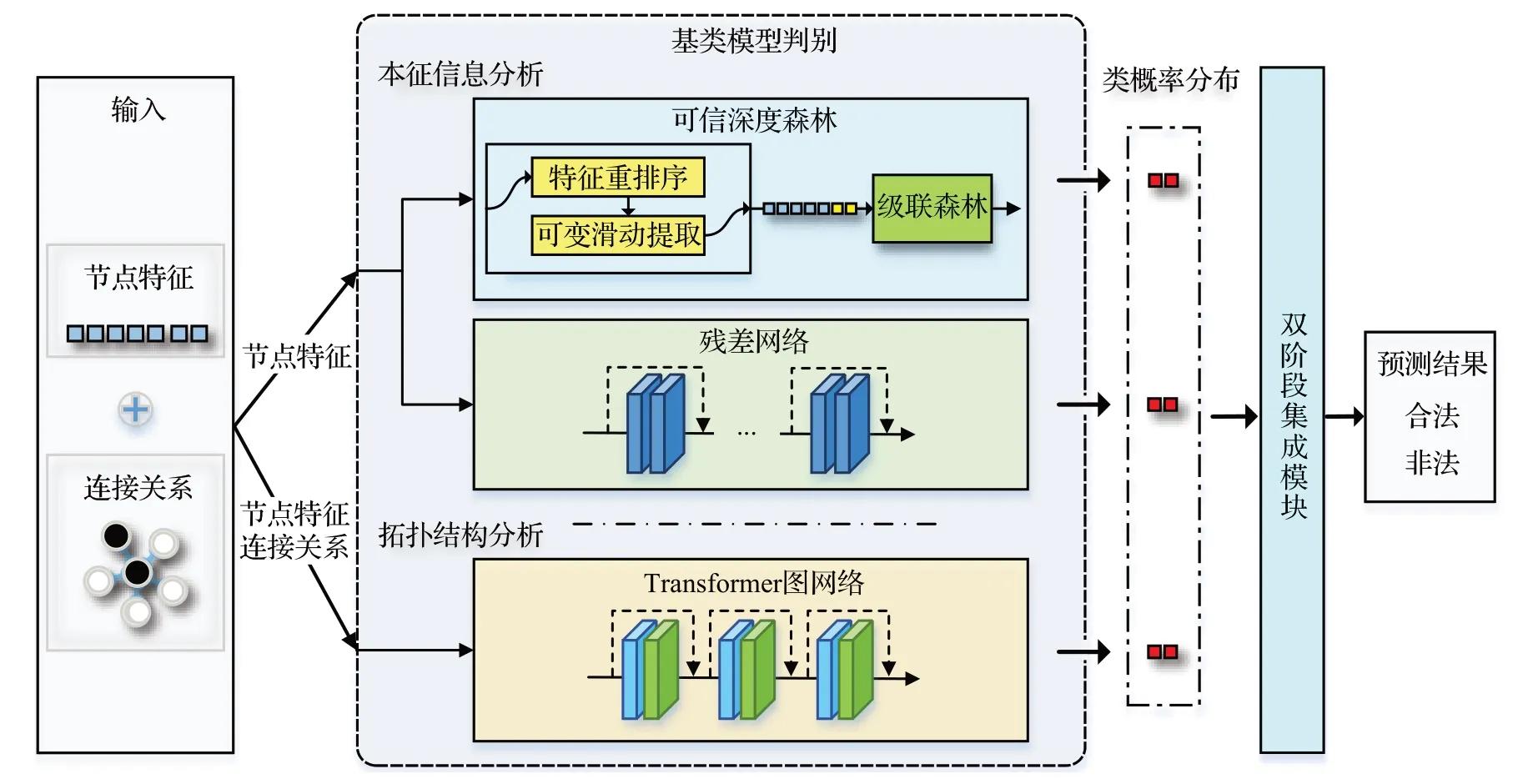
图2 整体结构图Fig.2 Overall framework
2.2 基于特征重排序与可变滑动窗口的可信深度森林
本文针对深度森林中多粒度扫描模块存在的特征采样不均衡、子样本混淆以及生成特征维度过度增长的问题,设计基于特征重排序与可变滑动窗口的可信生成特征构造方法,结构如图3所示。
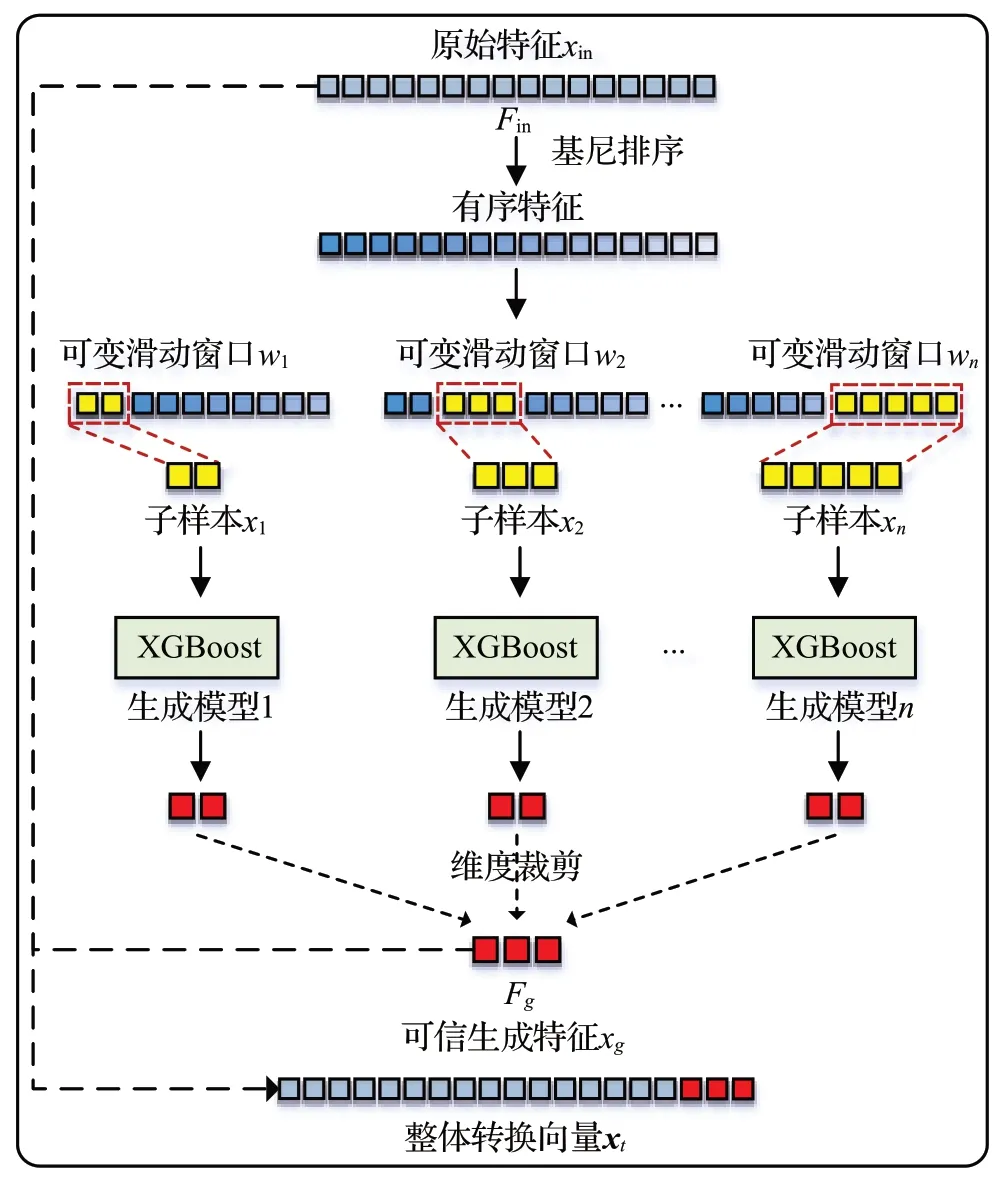
图3 可信特征生成模块Fig.3 Trustworthy feature generation module
特征重排序作为提取可区分子样本与构造可信生成特征的前序步骤,将区分度较高的特征放置于整体样本数据的首部,相对不易区分的特征则被移至样本尾部。其中每个特征的区分度采用基尼指数Gini_index来确定,计算公式如下:
其中,D指整体数据集,pk指k类别的出现概率,a代表样本中的某一特征,Dv指根据特征a划分后的子数据集,a的基尼指数越小代表Dv内部确定性越高,即特征a对样本的区分度越高。
得到依据区分度高低重新排序的特征样本后,本文设计基于可变滑动窗口与可变滑动步长的子样本提取过程。为了保证每个子样本具有一定的可信度,本文根据区分度相对较低的特征结合使用的原则,让窗口每进行一次滑动过后都依据膨胀系数进行尺寸扩张,滑动窗口尺寸的计算公式为:
其中,wi指滑动窗口的大小,W指窗口初始大小,E指膨胀系数,Fin指原始特征维度;Fi指滑动至第i步时已提取到的特征总维数,计算公式如式(4);当剩余特征数量不足以完成下一步滑动操作时将上一窗口尺寸扩大至可容纳所有剩余特征的大小。可变的滑动窗口配合特征的内部有序性,合理地提取出大小不一但均具可区分性的子样本,有效解决了子样本混淆影响模型训练与生成不可信杂质特征的问题。
为了避免产生原始多粒度扫描中的采样不均衡的缺陷,本文将滑动步长与窗口尺寸进行动态绑定,进而提取出互相之间无交叉的子样本,公平地遍历样本中的所有特征,滑动步长计算公式为:
其中,si指第i步时对应的滑动步长,wi指第i步对应的滑动窗口大小。随着窗口扩张而逐步增大的滑动步长设计大幅减少了生成特征的维度,原始多粒度扫描的生成特征维度Fm与可信生成特征维度Fg分别为:
其中,c为总类别数。两种生成特征的维度都依赖于子样本的总数,亦即窗口的总滑动次数,本文与窗口大小动态绑定的滑动步长大幅减少了所需的滑动次数继而减小了生成特征的维度。
对于生成模型,本文采用XGBoost[17]取代多粒度扫描中的随机森林与极端森林作为生成器,增加了生成过程的多样性。前序步骤提取出的具有区分度的子样本输入到生成模型之后即可得到对应的可信生成特征。为了避免出现过拟合的现象,本文将用于训练生成模型的数据单独划分出来。此外,为了减少冗余度并进一步减少生成维度,本文设计维度裁剪方法,具体而言,取生成模型得出的所有互补二维向量中的第一维构成可信生成特征。最后为保留原始特征中的细节,避免丢失整体有效信息,将可信生成特征与原始输入向量进行拼接得到整体转换向量。将其输入到级联森林中即可得到最后的预测向量。总体称为可信深度森林(trustworthy deep forest,TForest),整体转换流程如下:
其中,xin指输入样本,xi指提取到的子样本,xg指整体可信生成特征,y指输出的类概率分布,xgb(·) 指XGBoost生成模型转换,concat(·) 指拼接操作,caforest(·)指级联森林判别。
2.3 基于Transformer的图神经网络
为将交易前后连接的拓扑结构信息融入判断,本文引入基于Transformer 的图神经网络(transformer graph neural network,TGNN)[15]。TGNN 基于多头自注意力机制,具备高效的从周边节点聚合信息的能力,能够关注到节点连接关系内重要的交易,同时在数据标注不全时也可以充分利用到交易图中的无标签样本。此外,为了缓解特征过平滑的问题,本文在每层卷积激活操作前后添加跳跃连接,整体结构如图4所示。
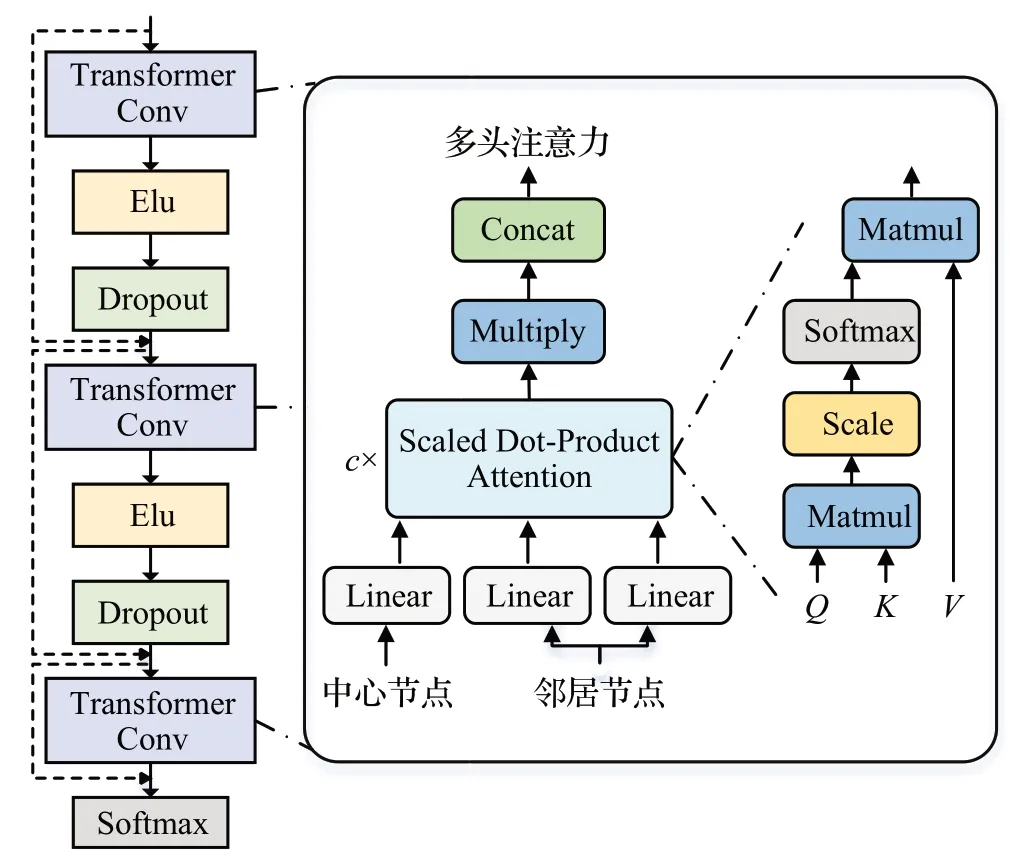
图4 基于Transformer的图神经网络Fig.4 Graph neural network based on Transformer
其中,||指对不同注意力头的拼接操作。为了避免特征过平滑的问题,本文在每层图卷积前后添加跳跃连接,计算公式为:
其中,ELU(·) 指elu 激活操作,Ws与bs指跳跃连接对应的权重矩阵与偏置。
2.4 基于残差结构的深层网络
为进一步对交易本征信息进行分析,同时也为双阶段集成提供必要的一类基模型,本文进一步利用深度模型的优势,弥补TGNN层数较少导致的深层抽象信息提取能力方面的不足,构建了一个18 层结构的深层残差网路,结构如图5所示。
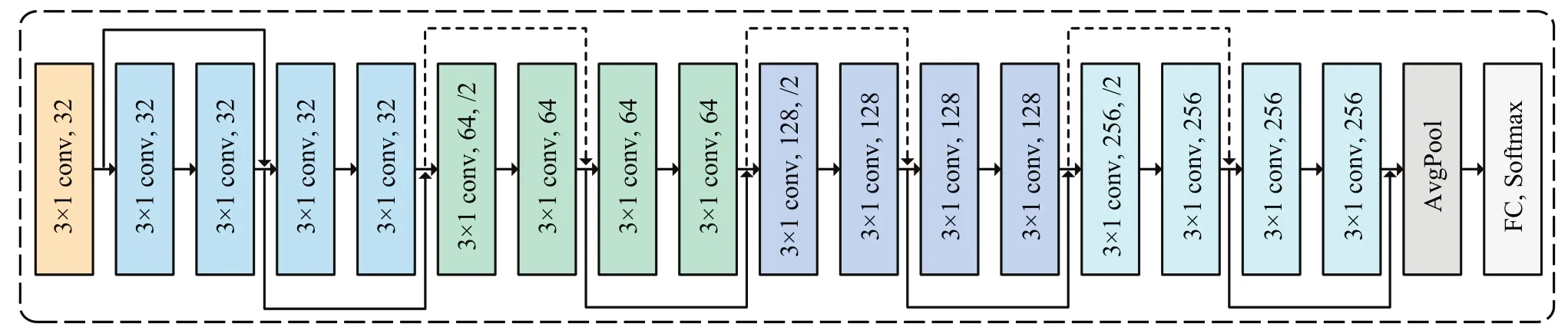
图5 深度残差网络Fig.5 Deep residual network
每个基本残差单元的计算公式为:
其中,ReLU(·) 指relu 激活操作,fin指输入维度,fout指输出维度。
2.5 双阶段集成策略
为融合基类判别模块中得出的交易本征信息判断与交易前后连接的拓扑结构判断,并进一步提升交易合法性的检测精度,本文设计了一种双阶段的集成策略,充分考虑了各模型对于正负样本的不同区分性能,以可信深度森林TForest为主导,采用优势互补原则,层层优化,得出综合性能最佳的整体集成模型T2Rnet。双阶段集成效果示意如图6所示。
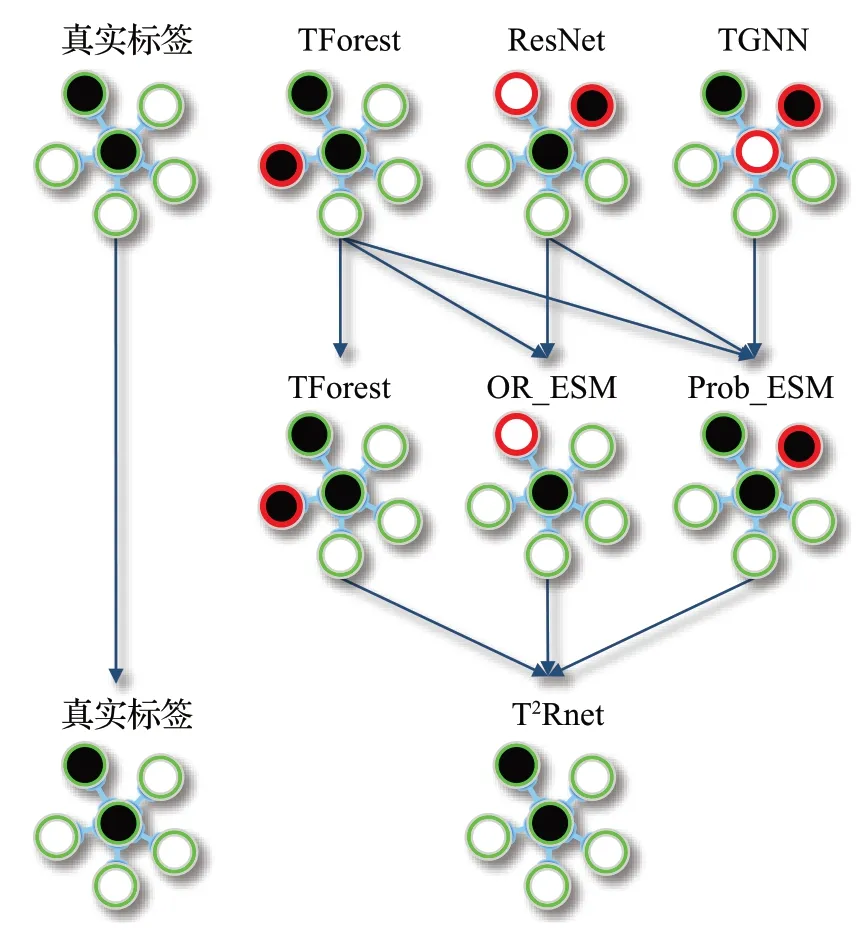
图6 双阶段集成效果示意图Fig.6 Effect diagram of two-stage ensemble
其中第一层的三类基类判别器分别为从交易本征信息角度进行分析的TForest、ResNet 与从交易连接拓扑结构角度进行分析的TGNN,输出表示为:
其中,x表示输入样本,yi,j表示第i层第j个基判别器得出的预测二维结果向量。
第二层首先延用基类判别器中性能最强的Tforest。其次利用对负样本具有良好识别能力的TForest 与ResNet 进行“OR”集成,即当两者中有一方认为某交易为合法则输出合法的预测标签,该集成将大幅减少假阳率。最后采用带调和系数的软投票方法,得出Prob_ESM 判别器,以合理的调和系数β的设置从而更多地关注对正样本的识别。第二层各判别器的计算公式为:
其中,k指交易类别,0代表合法交易,1代表非法交易,指对应判别器对第k个类别的预测概率,指取二维向量中较大者对应的标签,指连乘函数,指累加函数,β指调和系数,本文设置为0.75。此阶段结束得到各判别器的预测标签。
第三层采用相对多数投票法对第二层的子判别器预测结果进行再一次的融合,进而得到最终的双阶段集成模型T2Rnet,计算公式为:
其中,δ(·) 代表指示函数,当预测标签y2,i与类别标签k相等时函数值为1,否则为0。该阶段取第二层输出预测结果的多数类别为预测标签,进一步融合优化了整体模型性能。
3 实验与结果分析
3.1 数据集
本文在Elliptic 数据集上对所提方法进行实验。该数据集由真实比特币交易网络中提取出的交易子图构成,是当下最大的真实区块链交易合法性分类数据集。
数据集中每个样本对应一笔交易,包含166 维特征,其中前94 维为交易本地信息,包括时间步、交易费用等;其余72维为交易前后一跳路径的聚合信息,包括交易费用的最大值、标准差等。整体数据集按照时间顺序共划分为49 个交易时间步,各时间步间的交易无交集;总计包含203 769笔交易以及234 355条代表交易流向的连接边,其中42 019笔为合法交易,4 545笔为非法交易,其余交易未标记。本文采用该数据集上常用的留出法对所设计的模型进行评估,以交易先后时间步7∶3的比例划分数据集,即1~34 个时间步内的交易数据用于训练整体模型,35~49个时间步内的交易数据用于测试评估模型的性能。
此外,为了降低可信生成特征带来的过拟合风险,本文在训练可信森林的过程中以随机降采样的方式将训练集的10%,即1 500 对正负样本提取出来作为生成专用数据集,不再用于级联森林的训练。
3.2 实验设置
在可信深度森林中,本文将初始窗口大小设置为2,膨胀系数设置为2,生成模型内部子树数量设置为10。
在深度学习模型训练中,ResNet的初始学习率设置为1×10-4,权重衰减设置为5×10-4,训练轮数设置为100,批次大小设置为256,采用交叉熵损失函数进行训练,使用Adam 随机梯度下降算法进行参数的迭代优化;TGNN的初始学习率设置为5×10-4,权重衰减设置为5×10-4,训练轮数设置为1 000,逐时间步整图训练,采用加权交叉熵损失函数进行训练,正负样本权重比例6∶4,同样使用Adam 随机梯度下降算法进行参数的迭代优化。
在双阶段集成模块中,以提升模型对正样本的识别能力为目的,将超参数β设置为0.75。
本文实验平台为:Win10 系统、i7-10875H 处理器、NVⅠDⅠA Quadro T2000显卡。
3.3 交易合法性检测性能测试与对比分析
3.3.1 模型有效性
为了验证本文设计方法的有效性,将本文方法与基准图卷积网络GCN[13]、基于多特征融合的高性能深度网络BATDet[9]与当下合法性检测领域最先进的图网络AMNet[10]的方法进行对比。采用精确度、召回率、F1-score以及准确率作为衡量指标。在Elliptic数据集上的实验结果如表1 所示。实验表明,本文设计方案在四项指标上均优于其他方法,相比于GCN在综合衡量指标F1-score 上提升了31.6%,整体准确率超过了98%,说明本文方法T2Rnet 对于合法样本与非法样本都有着良好的识别能力,具备高可靠性,能够有效用于区块链上的交易合法性检测任务。

表1 交易合法性检测结果对比Table 1 Comparison of transaction legitimacy discrimination results
3.3.2 可信深度森林相关对比
为了验证本文设计的可信深度森林的有效性,将TForest与经典机器学习模型:支持向量机(SVM)、逻辑回归(LR)、K-最近邻(KNN)、多层感知机(MLP)、Adaboost、GBDT、XGBoost以及深度森林方法进行对比,结果如表2所示。实验结果表明,本文设计的可信深度森林优于其他经典机器学习方法,并且相比于原始深度森林在精确度即对负样本的识别方面获得显著提升。此外,在本实验中以提升原始深度森林的检测准确率为目的,采用大小分别为20、50、100的三个滑动窗口进行多粒度扫描,最终得到的转换向量维度为1 324;而本文设计的可信生成模块在采用初始窗口大小为2、膨胀系数为2的设置之下得到的整体转换向量维度仅172维。实验结果表明,TForest 在大幅减少训练成本的同时有效地提升了整体合法性检测性能。
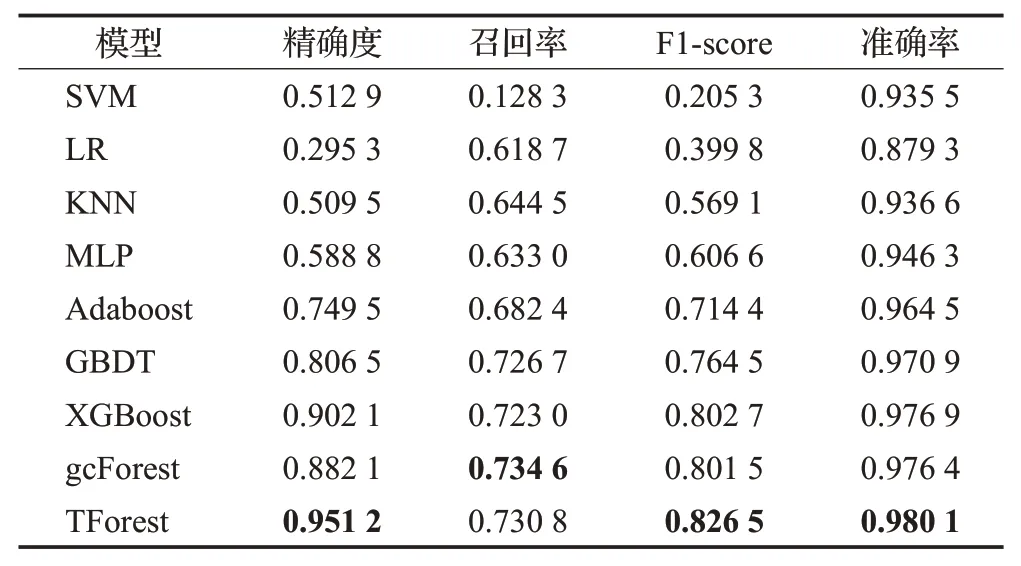
表2 TForest与机器学习模型对比Table 2 Comparison of TForest and machine learning models
为了更直观地显示本文对于深度森林中多粒度扫描的改进效果,使用t-SNE(t-distributed stochastic neighbor embedding)[18]进行二维映射,可视化了原始输入特征、多粒度扫描生成特征与本文构造的可信生成特征,如图7所示。
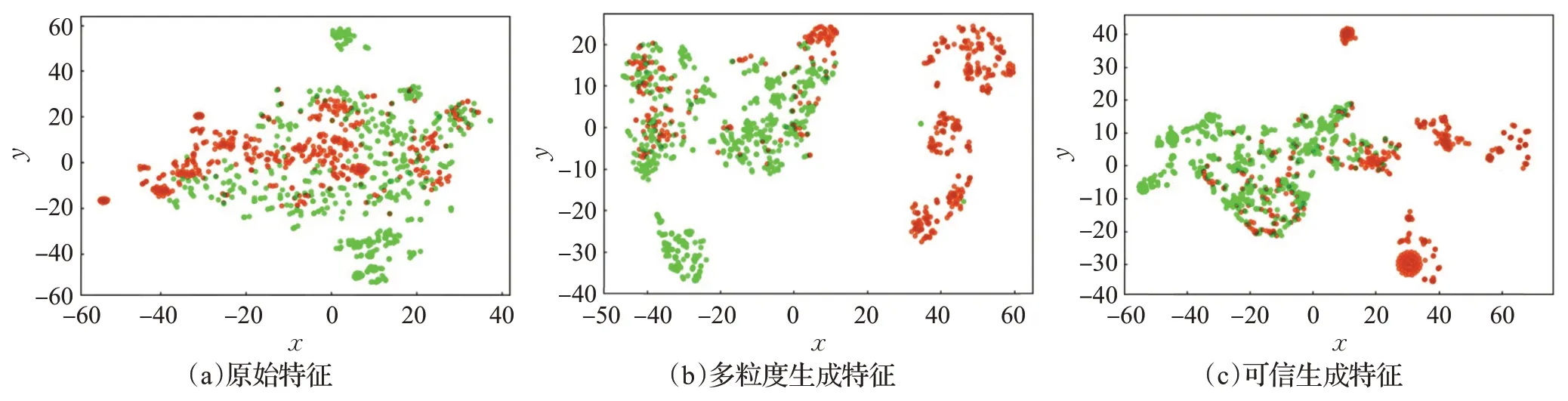
图7 生成特征对比图Fig.7 Comparison of generated feature
图中绿色圆点表示合法交易,红色圆点表示非法交易。图7(a)、(b)、(c)依次为原始特征、多粒度扫描特征与可信特征。由图7可得,原始输入中合法交易与非法交易的混杂情况较为明显,难以有效区分;多粒度扫描生成特征相比于原始特征有了一定的类间间距,但仍有少部分合法样本参杂在非法样本群落之中;而本文设计的可信生成特征不仅具有一定的类间间距,而且有更小的类内间距,分簇明显,不存在合法样本混杂在非法群落当中的情况,有更加良好的区分度,证明了本文提出的可信特征构造方法的有效性。
3.3.3 图网络方法对比
图网络方法的对比如表3。实验表明,本文设计的基于多头自注意力机制的TGNN 全面优于图注意力网络GAT[19],在综合指标F1-score上最佳。此外,跳跃连接的添加也提升了召回率,这对于双阶段集成而言具有更好的效果。
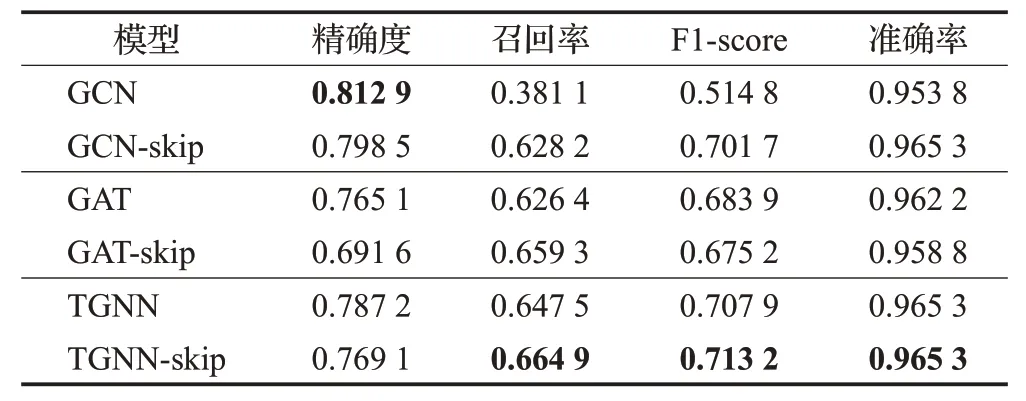
表3 图网络方法对比Table 3 Comparison of graph network methods
3.3.4 双阶段集成的内部对比
为了验证本文设计的双阶段集成策略的有效性,将集成内部各阶段的子模型进行对比,结果如表4。实验结果表明,对负样本进行专门识别的OR集成模型具备最高的精确度;而调和系数β设置为0.75下的软投票集成模型Prob_ESM具备最好的召回率。此外,结果显示,将双阶段集成策略中第二层的软投票子模型替换成硬投票之后,得到的最终集成模型Vote_ESM 的综合性能低于T2Rnet。
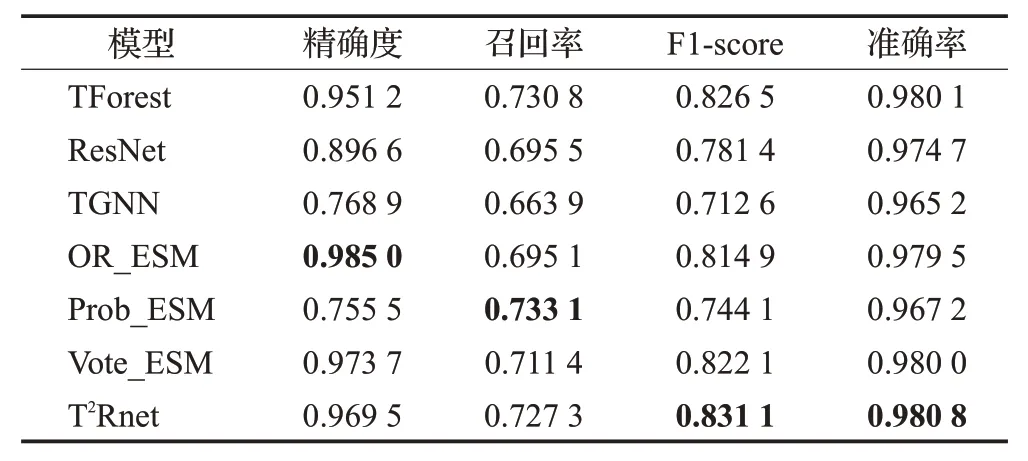
表4 双阶段集成内部对比Table 4 Ⅰnternal comparison of two-stage ensemble
3.4 消融实验与分析
为验证本文方法的有效性,并对本文方法中的可信深度森林内部的特征重排序、可变滑动窗口、维度裁剪、数据集不交叉等部分,以及双阶段集成模块的调和比例超参β的效果有进一步了解,本文进行五类消融实验。
3.4.1 特征重排序的效果
如表5 所示,在LGBoost[20]与XGBoost 两种不同生成模型的设置之下,采用特征重排序的检测结果始终优于不采用特征重排的结果。该实验表明,将特征按区分度重新排序后结合使用的操作有效减少了提取子样本的混淆性,增强了生成特征的质量,提升了合法性检测的精度。
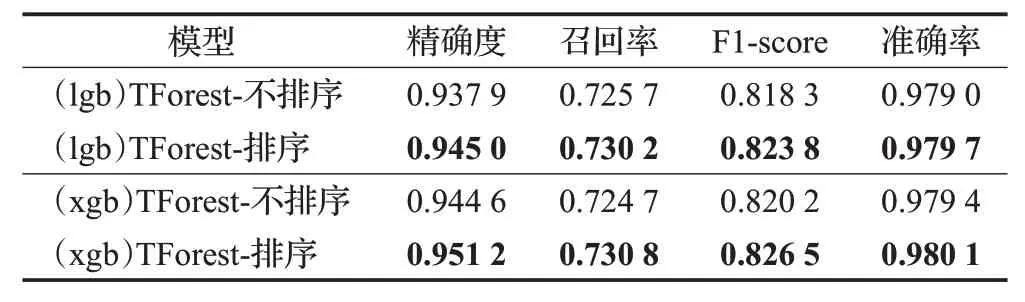
表5 特征重排序的消融实验Table 5 Ablation experiments for feature reordering
3.4.2 可变滑动窗口的影响
如表6所示,该实验测试的生成模型为:LGBoost与XGBoost,初始窗口大小分别为2、3、4、5,膨胀系数分别为2、3,共计八组不同设置下的检测结果。可以看到不同滑动设置间的性能差异并不明显,表明本文设计的可信深度森林对滑动窗口初始大小与膨胀系数的参数设置具有一定鲁棒性。
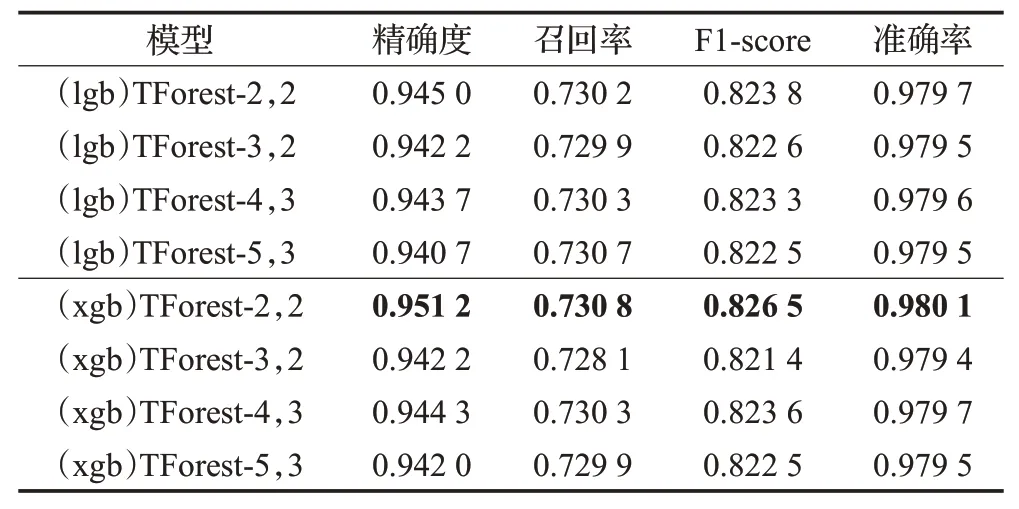
表6 不同滑动设置的效果Table 6 Effect of different slide settings
3.4.3 维度裁剪的效果
如表7 所示,在随机森林(RF)、极端随机树(EX)、LGBoost与XGBoost四种不同生成模型的设置之下,采用维度裁剪的检测精度均有了一定程度的提升。该实验表明,维度裁剪对于降低生成特征的冗余度与避免后续级联森林的过拟合起到有效的作用。
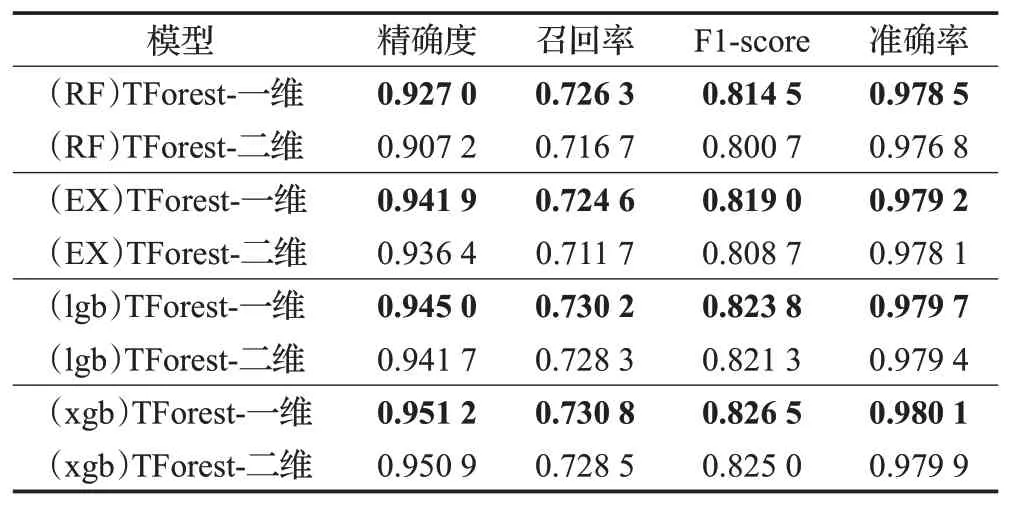
表7 维度裁剪的消融实验Table 7 Ablation experiments for dimension crop
3.4.4 数据集不交叉的影响
如表8 所示,该实验分别从训练集中抽取出1 500、2 000、2 500、3 000个样本作为生成模型专用数据集,由结果可知将用于训练生成模型的数据与用于训练级联森林的数据区分开来可以有效提升可信深度森林的整体性能。这是因为训练生成模块的样本再投入生成模块进行特征生成时会得到与数据标签高度一致的生成特征,继而使得级联森林过度依赖该部分特征,导致产生过拟合的现象。因此只需单独划分出少量数据用以生成模块的训练即可解决该问题。
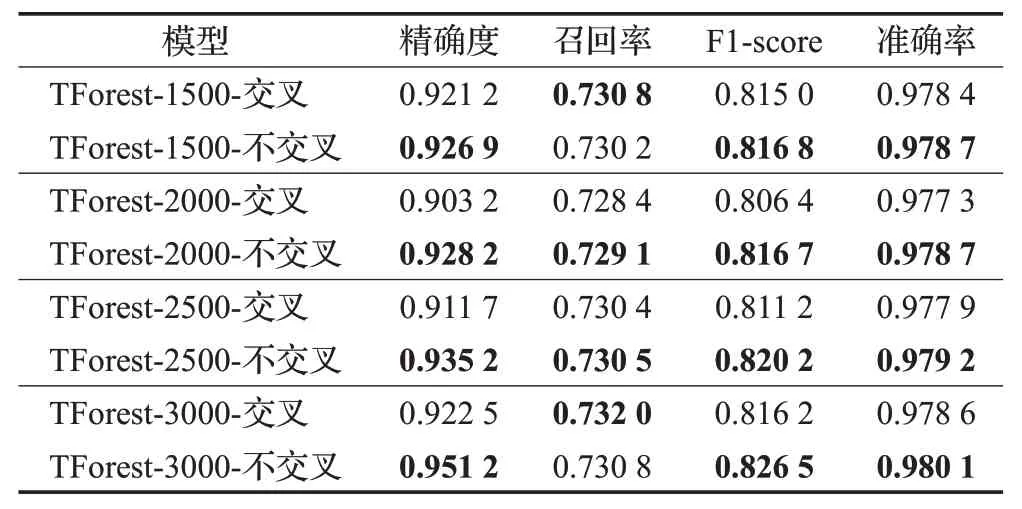
表8 数据集不交叉的影响Table 8 Effect of no-crossover dataset division
3.4.5 双阶段集成超参数β 的影响
如表9所示,双阶段第二层最后一个子模型使用带调和系数β的软投票方法的最终集成结果始终优于使用相对多数硬投票的结果,并且当设置β为0.75时性能最佳。因为该设置更多关注对正样本的识别,当与关注负样本的OR_ESM以及能力均衡的TForest一起结合使用时,将得出更优秀的集成结果。
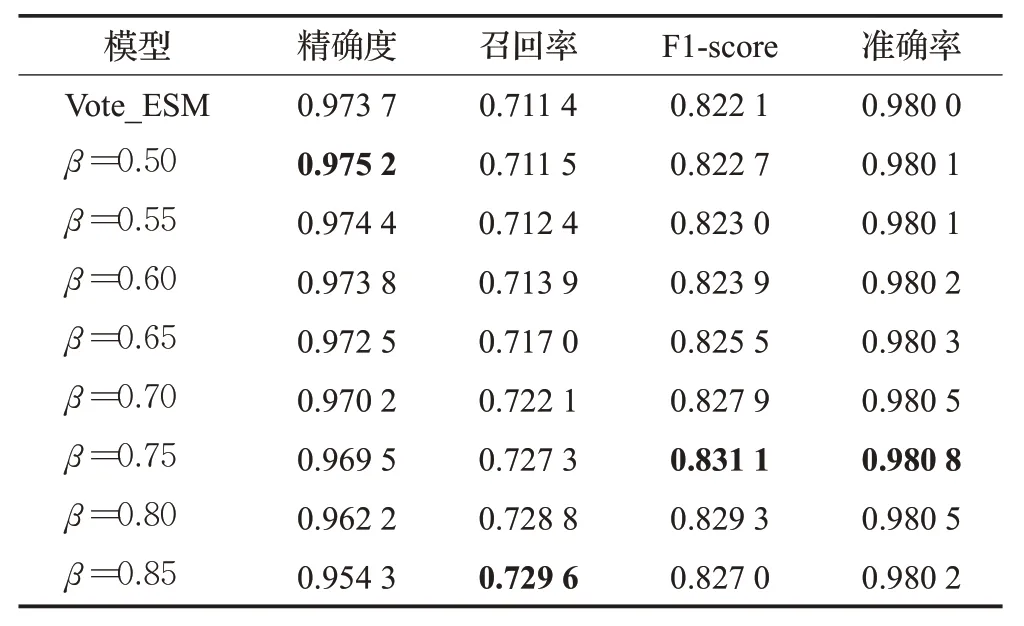
表9 不同β 对检测精度的影响Table 9 Effect of different β on detection accuracy
4 结束语
本文提出了一个融合可信深度森林与双阶段集成策略的多角度高性能的区块链交易合法性检测方法。结合特征重排序与可变滑动窗口实现可信特征的构造,解决了多粒度扫描中存在的采样不均衡、样本易混淆与维度爆发式增长的问题,获得了更高的交易检测精度;同时引入具备交易连接关系分析能力的TGNN 与深度挖掘交易本征信息的ResNet,并基于上述三类子模型对于正负样本的识别能力差异,设计逐层优化的双阶段集成策略,取得更优的综合检测性能。实验结果表明,本文方法在精确度、召回率、F1-score以及准确率等各项指标上均都优于当下先进方法,具备可靠的链上交易合法性检测能力。后续研究将重点考虑提高动荡交易环境下的模型鲁棒性,并进一步加强模型对于非法交易的检测能力。
