改进YOLOX-s的密集垃圾检测方法
2024-03-12谢若冰李茂军李宜伟胡建文
谢若冰,李茂军,李宜伟,胡建文
长沙理工大学电气与信息工程学院,长沙 410114
近年来,我国大、中城市的年生活垃圾产生量达2 亿吨且同比仍呈攀升态势,许多城市面临着“垃圾围城”的问题[1]。目前,国内垃圾处理大多为人工分拣,劳动强度大且效率低。随着新冠肺炎疫情的爆发,工人在处理垃圾时具有感染风险。为实现生活垃圾减量化、资源化、无害化处理,推进基于人工智能的分拣自动化是大势所趋。实现分拣自动化的前提是确定垃圾位置和识别垃圾种类,因此,垃圾检测技术发挥着至关重要的作用。
基于机器学习和图像处理的传统垃圾检测方法主要分为区域选择、特征提取、图像分类三部分[2]。Salimi等人[3]提出的垃圾检测与分类装置,首次使用Haar-Cascade方法检测地面上垃圾,再结合灰度共生矩阵和方向梯度直方图进行纹理和形状分析,进而获得一组特征,输入到支持向量机(support vector machine,SVM)进行分类,准确率可达73.49%。这类检测方法需手动提取特征,在特定条件下采取特定方法可获得较好检测效果,但受到数据集影响较大,鲁棒性差,存在检测精度低和检测速度慢等问题。胡斌等人[4]提出了一种红外光谱结合机器学习的方法,实现了生活垃圾高值化利用的深度分选,针对四类垃圾平均识别率能达到90%以上,但该方法只能处理部分特定种类的垃圾,且对使用环境要求较高,难以广泛应用。
相比于机器学习方法,深度学习技术自动提取的特征具有较强层次的表达能力,更适用于检测任务中。当前基于深度学习的目标检测算法主要有以YOLO系列、SSD 等算法为代表的单阶段目标检测算法和以FastRCNN为代表的两阶段目标检测算法。其中,YOLO系列算法具有结构简洁、计算处理速度快等优点,被广泛应用于不同领域中[5]。Patel 等人[6]对比了在街道垃圾、生活密集垃圾等真实场景下,5 种不同模型EfficientDet、SSD、CenterNet、FasterR-CNN 以及YOLOv5 的检测能力,由实验得出YOLOv5 能检测出最多垃圾,且检测精度最高。Ge等人[7]进一步对YOLO系列算法作出改进,提出YOLOX系列目标检测算法,并与YOLOv5系列进行对比实验,验证了该系列模型性能优于YOLOv5系列模型,具有更高的检测精度。
随着深度学习技术渗透到各行各业,其在垃圾检测方面的研究也取得了较大的进展。马雯等人[8]提出一种基于改进FasterR-CNN的垃圾检测与分类方法,研究表明该方法具有良好的识别率,但模型复杂,检测速度慢。耿丽婷等人[9]提出一种改进SSD 的可回收垃圾检测方法,通过采用轻量化骨干网络RepVGG和自适应调节感受野尺寸的方式来提高模型推理速度和检测精度。但该方法存在垃圾类别少,训练图片目标数量和种类单一,缺乏一定的实用性。Pan[10]提出了一种适用于垃圾分类的目标检测模型YOLOv3++,主要通过优化主干网络和使用迁移学习来减少计算量、参数量,提高模型的精度,实现了对10种可回收垃圾的高效检测。Wang等人[11]通过使用轻量级EfficientNet 主干网络和深度可分离卷积层来改进YOLOv4算法,减少网络模型的参数量。并在特征金字塔模型中,引入了一种轻量级的ECA注意机制,实现对不同通道特征图重要性的权重分析。该算法在6类密集垃圾检测中的平均精确率可达91.09%,但检测速度有所欠缺。Zhan 等人[12]基于YOLOv5 检测垃圾分拣站现场散乱丢弃的袋装密集垃圾,由于现场丢弃垃圾位置相对集中,引入了EⅠoU 损失,加快收敛速度,最终算法平均精确率可达89.7%,检测速度达0.014 frame/s。Lin 等人[13]提出一种Soft YOLOX 算法来检测下水道井盖处较密集的垃圾,通过使用SoftNMS算法对检测框分数进行惩罚,避免漏检现象,检测精度可达91.89%。但该工作所使用数据集为特定场景下的特定垃圾目标,种类较少。
基于深度学习技术的垃圾检测在精度、速度及鲁棒性方面有显著提升,但目前研究中所使用的大部分垃圾图像数据集是单目标和少目标数据,或者缺乏丰富的垃圾类别,不足以满足现实生活中不同类型和数量的垃圾堆积在一起的实际需求。针对生活中密集遮挡、形状多变、种类繁多的垃圾目标,现有算法存在目标误检、漏检以及定位框不准确的问题,从而影响检测效果。
在实际检测任务中,关注密集目标的全局特征有助于减少类别混淆。由于卷积操作的感受野有限,难以捕捉全局表征,因而通常采取多次池化操作来逐渐提取全局信息,但这将会导致一部分信息被丢失。Dosovitskiy等人[14]将自然语言处理中基于自注意力机制的编码器-解码器模型Transformer[15]应用在视觉识别任务中,将输入图像分割后进行序列化,并通过多头自注意力机制学习图像序列之间的复杂依赖关系,以获得全局表示。Liu等人[16]提出了更适用于目标检测任务的Swin Transformer模型,引入滑动窗口操作和使用跨窗口连接策略,大大减少了计算量并使得窗口间进行信息交互。
因此,为解决多类别密集垃圾检测识别准确率低、检测框定位不够准确和待检测目标容易被误检、漏检问题,本文提出一种融合多头自注意力机制改进YOLOX-s模型的密集垃圾检测方法,以提高待检测垃圾的识别精度和定位精度。本文主要工作概括为:
(1)提出一种基于滑窗操作多头自注意力机制的特征提取网络,该主干网络引入Swin Transformer 模块,模块内部自注意力机制提高了网络获得全局信息的能力,滑动窗口操作可减少自注意力权重的计算量。
(2)在回归初始预测框后,使用可变形卷积,对预测框进行精细化处理,使预测框更贴近待测目标边缘,提高了模型的定位精度。
(3)分析模型在训练的不同阶段,中心距离损失和宽高损失对预测框与真实框间位置和尺寸重要性程度,改进EⅠoU损失函数,引入加权系数,自适应调节中心距离损失和宽高距离在总损失函数的权重。
1 YOLOX-s目标检测算法
YOLOX在YOLOv3[17]算法的基础上,进行数据增强、预测分支解耦、无锚点以及SimOTA(simple optimal transport assignment)标签分配等多个方面的改进,与以往YOLO系列算法相比,在检测精度和速度方面具有优势。YOLOX-s 作为YOLOX 模型的一个衍生版本,结构简单、参数较少且方便部署。综合考虑,本文选择YOLOX-s作为基准模型。如图1所示为YOLOX-s网络结构图。

图1 YOLOX-s模型网络结构图Fig.1 YOLOX-s model network structure diagram
YOLOX-s网络结构分为4个部分:输入端、主干网络、颈部网络和预测输出端。在进行训练之前,YOLOX-s对输入图像同时使用Mosaic 和Mixup 两种数据增强进行预处理。主干网络沿用CSPDarknet 来提取特征,该主干网络通过引入CSPNet(cross stage partial network)结构,将特征图输入两个分支以减少计算开销,消除网络反向优化时的冗余梯度信息,增强卷积网络的学习能力。颈部网络采用路径增强网络结构(path aggregation network,PANet),该结构是在特征金字塔网络(feature pyramid networks,FPN)结构中增加了一条自底向上的路径,能够缩短浅层与深层特征之间的信息路径、提高网络信息传递能力。预测输出端将分类和回归分支解耦,从而产生一系列固定的预测集合,该集合包括预测目标框的4 个坐标信息、1 个目标置信度得分,以及N个种类的预测得分。
YOLOX-s 基于无锚机制,直接预测目标框中心的偏移量和高宽值()x,y,w,h。使用SimOTA标签分配策略将网络生成的预测框和真实框进行关联,首先根据中心先验的方法确定正样本候选区域,再计算每个候选正样本的代价来动态匹配每个真实框的正样本数。代价的公式如下所示:
其中,λ是平衡系数;和是真实框与预测框之间的分类损失和回归损失。
2 改进的YOLOX-s密集垃圾检测算法
改进算法继承了YOLOX-s 的优点,在垃圾检测任务中使用Mosaic 和MixUp 两种数据增强策略,丰富检测背景信息并增加重叠的垃圾数量,提高了模型的泛化能力。同时,YOLOX-s 算法以无锚方式直接生成高质量候选框,并通过SimOTA标签匹配方法对不同目标匹配合适的正样本。
在此基础上,为进一步提高YOLOX-s 算法在密集垃圾检测中的性能,本文对YOLOX-s 的主干网络进行了改进,引入基于滑窗操作的多头自注意力机制,使得模型能够学习到更多全局特征信息;在预测框回归阶段使用可变形卷积,对预测框进行精细化处理;改进EⅠoU损失函数,设置权重系数,自适应调节中心距离损失和宽高距离在总损失函数的权重。
改进YOLOX-s 的网络结构如图2 所示,下文对其进行详细介绍。

图2 改进YOLOX-s模型网络结构图Fig.2 Ⅰmproved YOLOX-s model network structure diagram
2.1 基于滑窗操作多头自注意力机制的主干网络
针对数据集中密集垃圾类别易混淆的问题,本文将Swin Transformer模块集成到YOLOX-s主干网络末端,以获取全局语义信息。CSP结构和Swin Transformer模块的结构如图3所示。

图3 改进主干网络末端CSP2结构图Fig.3 Ⅰmproved CSP2 structure diagram at end of backbone network
假设输入特征图为F∈ℝN×M×M,在Swin Transformer模块中先后进行基于窗口的局部自注意力机制(window multi-headed self-attention,W-MSA)和基于滑窗操作的全局自注意力机制(shift-window multi-headed selfattention,SW-MSA)操作,模块中的子层之间使用残差连接。其中,局部窗口尺寸设置为。
基于窗口的多头自注意力机制的计算过程为:
其中,Q、K、V分别为查询、键和值向量;dk为输入特征图的通道数;B为各像素相对位置偏差。通过引入B,使得各像素间保持空间位置关系,能够避免输入序列的位置信息丢失。自注意力的计算复杂度与输入特征图尺寸成线性关系[18],而W-MSA 在划分出的小窗口内计算自注意力,大大降低计算复杂度,但只在窗口内部获取信息,窗口之间无信息交流,所以无法获取全局特征,故在经过W-MSA操作后还需进行SW-MSA操作。
如图4所示,SW-MSA会将所有窗口整体在横轴和纵轴方向向右向下滑动个像素,使得原先的窗口被切分,重新组合为新的窗口,生成的新窗口采用跨窗口连接策略再次计算其自注意力权重,因此特征单元能在不同窗口内进行信息交互。SW-MSA 能使不同窗口进行信息交互,使得网络捕获更多上下文信息。该主干网络结合了卷积层和Swin Transformer的优势,兼顾局部信息和全局信息,能够学习更多可区分的特征。

图4 划分、滑动窗口操作Fig.4 Division,sliding window operation
当Swin Transformer 模块应用于网络较高分辨率特征图时,为保证计算量不过大,特征图会被划分成多个窗口,这也意味着特征图中的一个目标有更大的可能被分割,划分到不同的窗口,从而丢失上下文信息。所以相比于将Swin Transformer 模块应用于网络较高分辨率特征图上,Swin Transformer 模块应用于网络最低分辨率特征图时丢失的位置特征较少,且计算量更少。同时主干网络末端特征图是颈部特征融合网络的高层特征图输入,颈部网络能够将Swin Transformer模块编码的低分辨率特征图的全局语义信息进行传递,与主干网络高分辨率特征图的空间信息进行充分融合,降低了Swin Transformer模块带来的位置特征丢失的影响。故本文仅将主干网络末端CSP2 结构中的1×1 卷积和3×3卷积替换为Swin Transformer模块。
2.2 预测目标边界框精细化操作
Dai 等人[19]提出的可变形卷积,引入可学习的偏移量使卷积核产生不规则的感受野,解决了目标识别和检测中的几何变化问题。文献[20]的研究表明,可变形卷积应用于密集物体探测器中,可优化预测框的形状,在不损失过多效率的情况下提升预测框定位精度。本文实现预测框精细化网络结构如图5所示,在预测框回归分支中增加了一个可变形卷积层和标准卷积层。
YOLOX-s 输出的预测框由4 维向量(x,y,w,h)进行编码所得,即分别对应预测框的中心点坐标及宽高长度,且预测框中心点到左上、右下4 条边框的距离为为优化预测框,手动设置9 个固定采样点(在图6中用紫色点表示),将其作为可变形卷积的偏移量输入,充分学习周围区域的信息,再经过一个卷积层学习4 个距离缩放因子(Δl,Δt,Δr,Δb)对预测框进行缩放,使得缩放后的预测框中心点到左上右下4条边框的距离为,中心点保持不变,使得预测框更接近真实框。经过边界框精细化操作后,将原先输出的预测框中心点及的宽高(x,y,w,h),细化为预测框中心点及中心点到边框左上右下的距离(x,y,l,t,r,b)。边界框精细化操作原理图如图6所示,绿色的初始预测框经过精细化操作后得到了更精确的橙色预测框。
2.3 加权EIoU损失函数
在YOLOX-s 中,位置回归损失函数使用预测框和真实框之间的交并比(ⅠoU)作为损失计算,只考虑预测框和真实框的重叠面积,无法优化与真实框不相交的预测框,并忽视了预测框的位置信息。针对垃圾目标具有形态各异、集中堆叠等特点,引入Zhang等人[21]提出的EⅠoU损失函数,综合考虑了三个几何因素,即预测框与真实框的重叠度、中心点距离和长宽差值。其计算公式定义为:
EⅠoU 损失只是重叠损失、中心距离损失和宽高损失3个部分的简单叠加。在训练的不同阶段,中心距离损失和宽高损失对预测框与真实框间位置和尺寸重要性程度不同,故本文此基础上,提出加权EⅠoU 损失函数,其计算公式如下:
式中,λ为加权系数,λ∈[0,1] 。当λ取值为0 时,加权EⅠoU损失退化为DⅠoU损失[22]。然而手动调整损失权重方式需多次试验确认最佳λ,实用性不高。
预测框与真实框间的ⅠoU 值随着训练迭代逐渐变化,因此,将λ设置为ⅠoU 值,在训练初期,预测框与真实框的ⅠoU 值较小,中心距离损失占主导地位,促使预测框向真实框靠近;当训练到一定程度后,预测框与真实框的ⅠoU 值都为较大的值,高宽损失占主导地位,促使预测框更贴近真实框。由式(4)得:
综上所述,本文使用加权ⅠoU-EⅠoU损失对YOLOX-s算法中的ⅠoU损失进行替换,改进后的总损失函数为:
其中,bbox为未经精细化的预测框;bboxgt为真实框;bboxrefine为精细化后的预测框;在YOLOX-s 算法中,ⅠoU损失函数权重系数取值为5。本文所提算法中,γ1、γ2分别为未精细化和精细化预测框权重系数,通过实验验证,本文取值为γ1=2,γ2=3 最佳。
3 密集垃圾检测实验过程与分析
3.1 实验数据集
实验使用海华研究所开源的多垃圾目标检测数据集,共2 998 张RGB 图片,分辨率为1 920×1 080,包含204个类别的垃圾。该数据集按照8∶2的比例分为训练集和测试集,所有标签采用COCO2017格式。不同于大部分垃圾数据集,在该数据集中,一张图片包括多个类别的垃圾实例,实例密集堆放在一起且部分实例间存在遮挡,更符合现实生活中的垃圾检测状况。
在训练过程中,由于训练集数量较少,为避免模型存在过拟合问题,采用数据增强策略对训练集图像进行预处理,以提高模型泛化能力。数据增强方式和部分样本数据增强后可视化如表1和图7所示。

表1 数据增强方式Table 1 Data augmention method

图7 对部分样本进行数据增强Fig.7 Data enhancement on subset of samples
3.2 实验环境及训练参数设置
实验服务器Linux 操作系统为Ubun18.04 版本,配置如下:CPU为AMD EPYC 7302,内存为64 GB,GPU为NVⅠDⅠA GeForce RTX 3090,显存为24 GB;深度学习开发环境为Pytorch1.11.0,CUDA11.3,CuDNN8.2.0。
模型使用随机梯度下(SGD)进行训练,输入图像尺寸均归一化为608×608。实验设置训练300个epoch,批量大小为16,共进行45 000 次迭代。初始学习率设为0.01,使用Cosine学习机制,权重衰减为0.000 5。
3.3 实验评价指标
在目标检测算法测试中,通常使用平均精度均值(mean average precision,MAP)、精确率(precision,P)、召回率(recall,R)和每秒传输帧数(frames per second,FPS)作为检测算法的评价指标,计算公式为:
式中,NTP为正确检测数;NFP为误检数;NFN为漏检数;APi为第i类的P-R曲线积分;t为检测每张图像花费的平均时间。本文主要以mAP50:95、mAP50和FPS为测试评估指标,mAP50:95表示IoU=0.5:0.95,步长为0.05时的平均精度,mAP50表示IoU=0.5 时的平均精度,FPS表示每秒检测图像数量。
3.4 实验过程与结果分析
3.4.1 消融实验
为了验证本文改进模块对密集垃圾检测的有效性,本小节以YOLOX-s 为基线模型,在204 类垃圾目标数据集上进行消融实验。在YOLOX-s 基线的基础上,依次加入Swin Transformer模块、精细化边框操作以及加权ⅠoU-EⅠoU损失函数,实验结果如表2所示,Parameter表示模型参数量。从表2中可以看出,引入Swin Transformer模块后mAP50:95和mAP50分别提升0.2个百分点和0.5个百分点;精细化边框操作单独加入时,mAP50:95和mAP50分别提高0.6 个百分点和1.1 个百分点;单独使用加权ⅠoU-EⅠoU 损失对原损失函数进行替换时,mAP50提升1.2个百分点。而当Swin Transformer模块、精细化边框操作和加权ⅠoU-EⅠoU 损失3 种改进策略损失共同加入时,检测效果会有大幅提升,3种改进策略相辅相成。

表2 消融实验结果Table 2 Ablation experimental results
由表2 可以得到,在密集垃圾检测中,本文改进YOLOX-s 算法的mAP50:95和mAP50分别达到80.5%和92.5%,与基线模型相比分别提高了1.7 个百分点和2.5个百分点。在检测速度上,本文所提算法与基线模型相比降低了19 frame/s,其重要原因是Swin Transformer模块和精细化操作的引入增加了一定的计算量和网络参数量,但本文所提算法每秒检测图像数量为112 frame,仍然大大满足在实际垃圾分拣过程中的实时性要求。
图8 为利用grad-CAM 算法可视化主干网络引入Swin Transformer 模块前后输出的热力图,红色表示网络关注度最高的区域,黄色、蓝色区域的关注度逐渐变弱。图8(b)、图8(c)可以看出,改进主干网络网络关注的区域更加全面,其类激活映射区域在各类待测目标上都比较集中,而更少关注到背景区域,验证了该网络具有更强的特征提取能力和对于背景中无效特征的分辨能力。
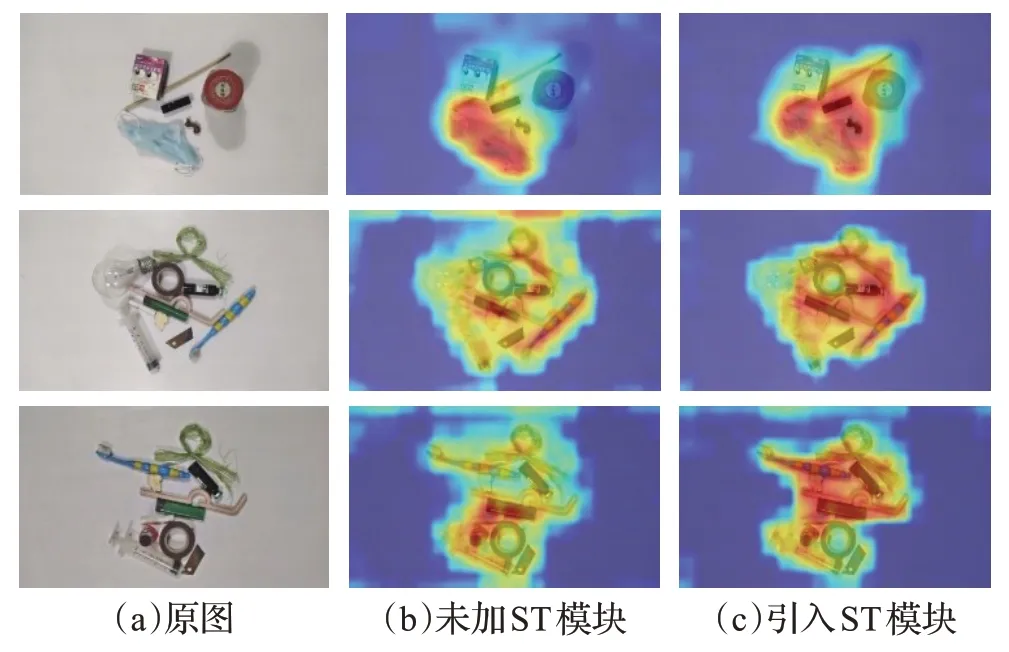
图8 主干网络改进前后热力图Fig.8 Heat map before and after trunk network improvement
图9 中展示的是预测目标边界框精细化前和精细化后经过非极大值抑制筛选的输出结果,白色表示真实框,绿色表示精细化前的检测框,红色表示精细化后的检测框。从图中可以看出,对于边缘清晰和高宽相差不大的待测物体,精细化前后的预测框相差不大。而边缘较为模糊的待测物体,如口罩,精细化前的预测框无法很好的将其包围,预测框大小普遍小于待测物体的实际大小;高宽相差较大的待测物体,如:针管、竹制品等,精细化前的目标预测框无法精确地包围其较长的一边。经过精细化将边框拉长,使得目标预测框更好地包围待测物体。故目标边界框精细化能提高难以回归的待测物体的定位精度。值得注意地是,图9中间的竹制品被针管严重遮挡,精细化之后的检测框虽然也不能很好地将其包围,但是也有一定的改善作用。

图9 预测目标边界框精细化前后的输出结果Fig.9 Predict output before and after refinement of target bounding box
3.4.2 加权EIoU性能分析
本文进行了一系列的对比实验,以展示加权ⅠoUEⅠoU损失的性能优势。图10为YOLOX-s算法、单独加入加权ⅠoU-EⅠoU 损失改进的YOLOX-s 算法和本文所提算法在训练过程中的损失曲线对比,分别由蓝色、橙色、绿色曲线所表示。从图中可以看出,YOLOX-s算法最终训练损失为1.84,单独使用加权ⅠoU-EⅠoU 损失改进的YOLOX-s 算法和本文算法的损失分别为1.43 和1.42,且损失曲线比YOLOX-s 算法更快达到最低点。表明引入加权EⅠoU 损失改进网络有助于降低损失,加快网络收敛速度。同时由曲线图可以看出,本文所提算法的收敛性比单独加入加权ⅠoU-EⅠoU 的YOLOX-s 算法更胜一筹。

图10 加权ⅠoU-EⅠoU训练损失曲线对比Fig.10 Comparison of weighted ⅠoU-EⅠoU training loss curve
表3 为在本文所提算法中使用ⅠoU、GⅠoU、CⅠoU、EⅠoU 损失和取不同权重系数时加权EⅠoU 损失时的检测结果对比。其中mAP75表示IoU=0.75时的平均精度,mAPsmall、mAPmedium、mAPlarge分别表示IoU=0.5:0.95,步长为0.05 时,大中小三种不同尺寸目标的平均精度。由表3可以看出,以ⅠoU损失为基准时,GⅠoU损失、权重系数取0 的加权EⅠoU(DⅠoU)损失、权重系数取0.25、0.75的加权EⅠoU 损失的整体精度都有所下降;CⅠoU 的mAP50:95和mAP50分别提升了0.4 个百分点和0.8 个百分点,但mAP75下降了0.3 个百分点;EⅠoU、权重系数取0.5、1 的加权EⅠoU 损失和加权ⅠoU-EⅠoU 损失的整体精度都有所提升,其中加权ⅠoU-EⅠoU 损失的提升效果最佳,mAP50:95提升了1个百分点,mAP50提升了1.3个百分点,mAP75提升了0.9 个百分点。值得注意的是,在对比的所有损失函数中,权重系数取1 的加权EⅠoU 对于小目标的检测精度最好,权重系数取0.5的加权EⅠoU对于中等目标的检测精度最好,加权ⅠoU-EⅠoU 对于大目标的检测精度最好。实验结果表明,使用加权EⅠoU 损失时,可通过使用不同的权重系数,来着重提升对大、中、小三种尺度物体其中一种的检测效果。

表3 不同损失函数性能对比实验结果Table 3 Performance of different loss functions compares experimental results单位:%
3.4.3 与不同算法对比实验
为了检验提出的改进算法对多类别垃圾密集检测精度和效率的有效性和先进性,本文进一步将其与目前较为流行目标检测算法进行对比,包括两阶段目标检测算法Faster-RCNN,单阶段目标检测算法SSD、RetinaNet、EffcientDet-d0、YOLOv3、YOLOv4、YOLOv5-s、YOLOX-s,以及同类SOTA 算法ECA_ERFB_s-YOLOv3[23]。训练时均使用相同实验设备、数据集和参数,对比实验结果如表4 所示。由表4 可以得出,在204 类垃圾密集检测中,本文算法的mAP50:95和mAP50值均最大,具有更高的检测精度,与上述算法相比,mAP50:95和mAP50分别提高了1.7~19.7个百分点和3.1~11.4个百分点。改进后的特征提取网络融合多头自注意力机制,使得网络关注全局信息特征,能够减少待检测目标被遮挡误检情况,并使用可变形卷积优化预测框的位置,提高尺度相差较大和由堆叠遮挡导致边界模糊的待检测目标的定位精度,协同加权ⅠoU-EⅠoU 损失进一步加快网络收敛速度,最终使得本文所提算法对密集遮挡目标的检测能力有所提高。本文算法的检测速度达112 frame/s,远快于Faster R-CNN、SSD、RetinaNet、EffcientDet-d0、YOLOv3-v4 和ECA_ERFB_s-YOLOv3,略低于YOLOv5-s和YOLOX-s算法,大大满足实时监测需求(FPS≥30 frame/s)。

表4 不同算法对比实验结果Table 4 Comparison of experimental results of different algorithms
为了更加直观地呈现本文算法的检测性能优势,选取上述算法中检测性能较好的YOLOv5-s、YOLOX-s和本文算法的部分检测图像结果进行对比说明,如图11所示。图11(a)、(b)、(c)分别为YOLOv5-s算法、YOLOX-s算法和本文算法的检测结果图。其中,置信度阈值取0.25,ⅠoU 阈值取0.45。从上述对比图中可以看出,YOLOv5-s和YOLOX-s算法在图中有多处误检(红色箭头指向),如将笔、狗尿布、废弃针管识别为其相似物体;对于如最左检测图所示垃圾更为密集的场景,使用YOLOv5-s 和YOLOX-s 算法检测将会出现重复检测框(黄色箭头指向),而本文算法没有这类问题;此外,最右YOLOv5-s和YOLOX-s算法的检测图中,一次性塑料餐具被灯泡部分遮挡,导致其均识别率低且只有部分在其预测框中。综上所述,本文算法的误检现象更少,对于大部分类别的垃圾检测精度更高。同时,对于边缘模糊和部分被遮挡的垃圾,本文算法能够更精确地定位其位置和边框。

图11 不同算法检测结果对比图Fig.11 Comparison of detection results of different algorithms
4 结束语
针对密集堆叠垃圾形状、颜色多变导致识别精度、定位精度较低以及存在误检现象等问题,本文提出了一种融合多头自注意力机制的改进YOLOX-s模型的密集垃圾检测方法。在这项工作中,基于滑框操作自注意力机制改进的主干网络可以获得更多的全局信息、学习更多可区分的特征,更适用于垃圾密集堆叠的场景;通过可变形卷积对目标预测框进行精细化操作,解决部分垃圾边缘模糊且长宽尺度相差大导致定位框不准确的问题;引入加权ⅠoU-EⅠoU损失函数,进一步加快模型收敛速度。在多垃圾目标检测数据集上进行实验来对本文算法进行评价,结果表明,本文提出的改进算法检测精度mAP50:95可达80.5%,mAP50可达92.5%,并且相比于主流的单阶段和两阶段目标检测算法,其在精确度和检测速度上都具一定的优势。
在后续的研究中,考虑从轻量化模型入手,优化本文算法的检测速度,使其能够部署在工业机器人,应用于垃圾分拣生产线、街道垃圾实时检测等场景。
