基于上下文信息与特征细化的无人机小目标检测算法
2024-03-12彭晏飞陈炎康袁晓龙
彭晏飞,赵 涛,陈炎康,袁晓龙
辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125105
随着科学技术的进步,无人机在军事和民用方面的应用越来越普遍,无人机(unmanned aerial vehicle,UAV)由于具有体积小、成本低、使用方便等优点,在无人机跟踪[1]、农业[2]等领域得到了广泛的应用。由于无人机飞行高度不稳定,图像场广阔,无人机航拍图像中的物体呈现尺度各异,小物体多,密度大,物体之间存在遮挡现象,难以准确捕捉[3]。以上问题给无人机航拍目标检测带来了挑战,因此准确处理无人机目标检测的各种复杂场景,具有重要的理论意义和应用价值。
目前,基于深度学习的目标检测技术主要分为两种[4]:第一种是基于候选区域的两阶段方法,以Fast R-CNN[5]、Faster R-CNN[6]为代表。第二种是单阶段方法,以SSD[7]和YOLO 系列算法YOLOv1[8]、YOLOv2[9]、YOLOv3[10]和YOLOv4[11]为代表。
当前的目标检测算法通常专注于一般场景下的检测,无人机航拍图像中存在大量分布密集的小目标,由于小目标像素信息少,特征纹理模糊,复杂多样的背景环境使检测更加困难,难以达到最佳检测效果。因此直接将普通检测器应用于无人机航拍图像效果较差。对此,宋谱怡等人[12]将压缩-激励模块引入YOLOv5s中,提高特征提取能力,并使用双锥台特征融合提高小目标检测精度,最后使用CⅠoU损失函数提高边界框回归精度,该算法使用双锥台的方式可以提取出较多的有效信息,减少无关信息的干扰,并保持较快的速度。Zhu 等人[13]提出了TPH-YOLOv5,通过在YOLOv5中添加了一个预测头,并在头部应用了Transformer 编码器块以形成Transformer检测头,提高了无人机图像中高密度遮挡物体的检测。贾天豪等人[14]提出了一种引入残差学习与多尺度特征增强的目标检测器,通过在骨干网络中引入基于残差学习的增强特征映射块,使模型更加专注于对象区域,并通过特征映射增大感受野,最后使用双重注意力模块抑制背景噪音,在小目标数据集上检测效果较好。邓姗姗等人[15]提出了一种多层频域特征融合的目标检测算法,通过对输入图像进行高频增强和对比度增强,提高样本质量,并利用多尺度卷积特征融合的方法,解决了小目标在深层特征图中丢失特征信息的问题,提高了小目标的检测精度。
无人机航拍图像中的物体通常因为分辨率低、遮挡现象等原因导致特征不明显,直接从细粒度局部区域获得的信息非常有限,而如果利用图像中的上下文信息捕获小目标与背景或其他目标的潜在联系,就可以帮助网络进行推断,因此图像中的上下文信息在无人机图像检测中非常重要。但大多数算法使用自注意力获取全局上下文信息,由于计算量较大,无法满足无人机的实际部署应用。李晨等人[16]设计了自监督二阶融合模块,生成密集空间像素相关性矩阵,获取连续的全局上下文特征信息,提高对全局信息的利用率,但由于其特征图展开之后的矩阵较大导致计算量较大,不能满足实时检测要求。Nie 等人[17]设计了一个上下文信息增强模块,该模块主要由两个卷积分支组成,两个分支分别使用不同大小的卷积核,然后对两个分支的特征图融合从而得到包含上下文信息的增强特征。此模块的优点是通过使用不同大小的卷积核在多个尺度提取特征获得全局上下文信息,避免了因特征图展开做矩阵乘法导致计算量过大问题。徐坚等人[18]在骨干网络中引入可变形卷积,在不同的感受野提取多尺度特征信息,利用上下文信息提高无人机航拍图像中小目标的检测精度。但是其直接使用相加或拼接的方式进行融合,会带入冗余信息与噪声信息,影响特征图的表达能力,对上下文信息的获取产生干扰。
提高小目标检测精度的另一种有效方法是多尺度特征融合。Lin等人[19]提出的经典FPN网络使用自上向下的结构和横向连接,可以使不同层级的特征信息交互,将浅层特征传递到高层特征,达到增强小目标特征的目的。
虽然上述结构提高了网络的多尺度表达能力,但是其在融合不同层级特征图时没有考虑不同特征图之间的密度不同,不同尺度的特征之间具有较大的语义差异,并且不同层级特征图对小目标的贡献不同,直接融合会使模型的多尺度表达能力降低。针对上述问题,为了获得更充分的特征图表示,利用不同层级特征图聚合丰富的上下文信息更好的检测小目标,考虑无人机目标检测的特点,提出了一种基于YOLOv5s 的无人机小目标检测算法。
本文主要工作如下:
(1)提出一种自适应上下文特征增强模块,通过空洞卷积与自适应融合方式获取上下文信息进行特征增强,丰富检测所需信息,提高小目标识别能力。
(2)提出一种特征细化模块,其中包括设计的一种空间通道注意力模块,来抑制特征融合引入的冲突与干扰信息,提高多尺度表达能力。
(3)构造浅层特征融合网络,将深层特征图与浅层特征图融合,保留更多小目标的特征信息,提高小目标检测精度。
(4)提出一种带权重的损失函数,提高边界框回归精度,增强网络对小目标的学习能力。
1 本文方法
在兼顾检测精度与检测速度前提下,对YOLOv5s进行改进。首先,为了保留更多小目标的特征信息,构造了浅层融合网络,去掉检测大目标的P5 层,并将N2送入特征融合网络,使用分辨率更高的特征图检测小目标,减少小目标漏检和错检;其次,使用上下文特征增强模块,通过补充上下文信息,帮助模型进行检测;最后,通过特征细化模块,减小特征融合时引入的冲突信息对小目标的干扰,防止小目标淹没在冲突信息中。本文方法的总体架构如图1所示。
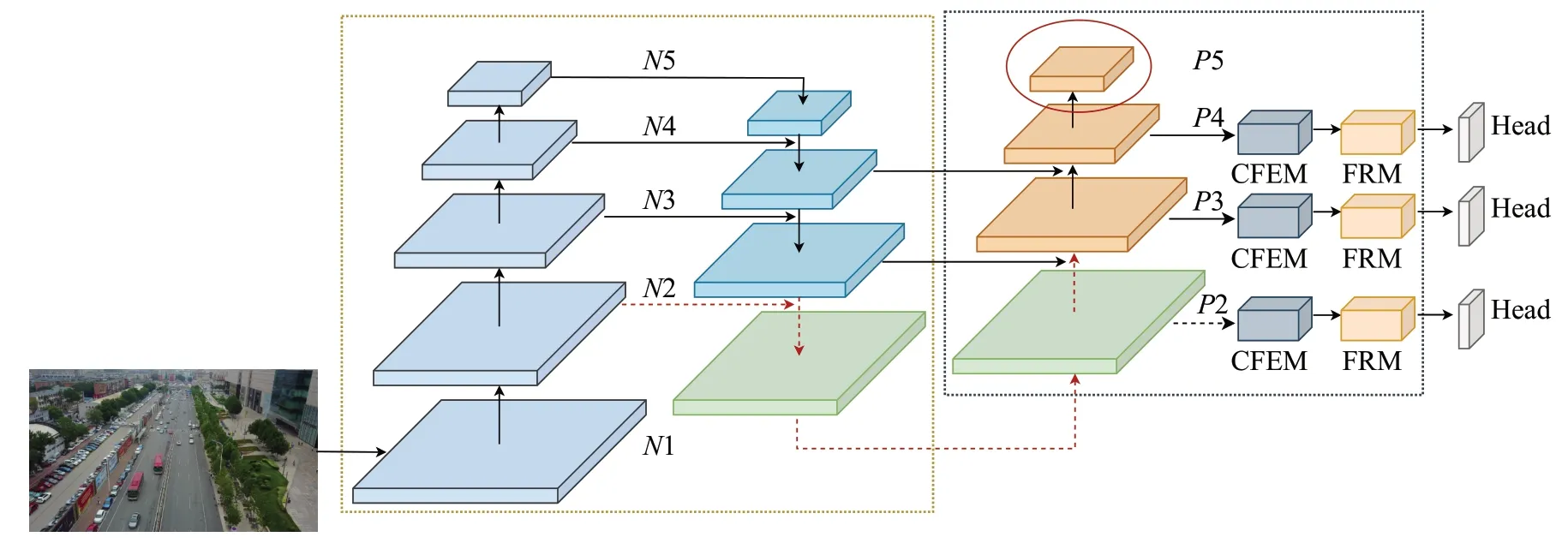
图1 模型总体结构图Fig.1 Structure diagram of proposed model
其中CFEM 为上下文特征增强模块,FRM 为特征细化模块,Head 为检测头,负责进行最后的分类与检测。N1~N5为骨干网络所提取的特征图,P2~P4为送入CFEM 以及FRM 的特征图,最后在Head 中使用本文优化的损失函数进行训练。
1.1 上下文特征增强模块
卷积神经网络中每层特征的感受野是固定的,无法捕获不同尺度的特征信息,并且在航拍图像中小目标边缘模糊,特征不明显,纹理信息不足,导致能够提取的特征信息少,模型很难分辨图中物体。但如果为模型提供了上下文信息,比如,周围的环境、道路、车轮,可以有助于模型推断出很有可能是汽车,因此图像中的上下文信息在无人机图像检测中非常重要。为此,本文提出一种上下文特征增强模块(context feature enhanced module,CFEM),该模块通过将输入的特征图使用不同扩张率的空洞卷积进行处理,然后使用自适应特征融合方式对得到不同的感受野特征进行处理生成自适应权值,充分挖掘了不同深度特征层的多维特征,捕获小目标与背景或其他目标的潜在联系,为网络补充上下文信息,帮助网络进行推断,从而实现不同感受野特征的高效融合和增强表示,有效利用了不同尺度下浅层和深层的特征,进而丰富特征信息,提高模型对小目标的检测能力。
如图2为CFEM模块结构图,对输入的特征图分别进行扩张率为1、3、5的空洞卷积操作,使用3×3的卷积的卷积来获得更多的特征细节。经过空洞卷积后可以获得不同的感受野,有利于获得多尺度的特征信息,最后对三个分支的输出进行自适应融合。图2 中虚线部分为自适应特征融合,该融合方式通过建立输入目标尺度和特征融合之间的联系,依据输入目标的大小去学习融合权重,为多尺度特征分配不同的融合权重。具体过程为首先将输入的特征图拼接后通过1×1 卷积进行降维,然后利用3×3 的卷积和Softmax 激活函数将经过降维的特征映射到F1、F2、F3三个分支对应的权重,最后,将输入特征与空间权重通过特征加权融合得到具有丰富上下文信息的输出特征。通过利用上述自适应特征融合的方式,从不同感受野的特征层中聚合了更多的上下文信息,使网络关注更具有判别力的小目标特征信息,并且此融合方式可以在几乎不增加计算量的前提下丰富检测所需信息,从而提高小目标的检测效果。

图2 上下文特征增强模块Fig.2 Context feature enhanced module
此外,融合的方式还可以选择加权融合与拼接融合,如图3 所示。图3(a)为加权融合,即分别在空间和通道维度进行相加;图3(b)为拼接融合,即分别在空间和通道维度直接拼接。本文通过实验选择自适应特征融合方式,消融实验结果见2.4节。
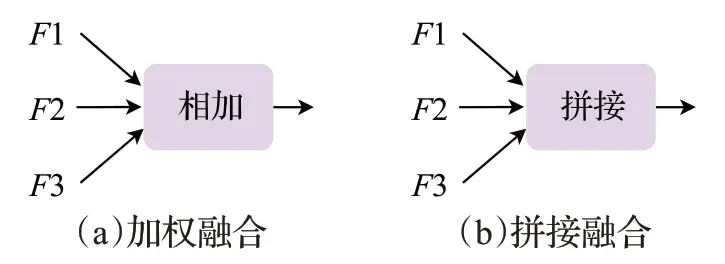
图3 融合方式Fig.3 Fusion method
1.2 特征细化模块
在特征融合过程中,因为不同层的特征密度不同,而且不同尺度的特征之间具有较大的语义差异,直接进行多尺度融合会带入大量的冲突信息与冗余信息,从而使模型的多尺度表达能力降低。为了让模型可以更快的定位到目标本身,不被噪声等冗余信息影响,防止小目标特征被淹没在冲突信息中,本文构造了一个特征细化模块FRM(feature refinement module)抑制冲突信息,其结构如图4所示。

图4 FRM模块结构Fig.4 Structure of FRM module
FRM模块在仅增加少量参数量与计算量的前提下进行设计,其主要包括一个针对关注小目标空间维度特征的空间通道注意力模块(spatial-channel attention,SCA),通过结合空间与通道注意力,提高模型提取有用特征的能力。
通道注意力重点对输入分析每个通道的特征,更关注特征的语义信息。通道注意力对输入的特征图O使用平均池化和最大池化操作分别在空间维度上整合全局空间信息,收集更丰富的特征信息。同时使用平均池化与最大池化操作可以提高模型的表达能力,并减少特征图的大小和计算量。将经过池化后的两个一维向量送入全连接层运算,通过大小为1×1的卷积来实现特征向量间的权值共享。最后,将向量相加后经过sigmoid激活函数生成通道注意力权重Yc:
空间注意力会更关注物体的位置信息,聚焦于特征图中有效信息多的区域,与通道注意力形成互补。空间注意力使用平均池化与最大池化在通道维度上对输入特征图O进行压缩操作,得到两个二维特征图,将其沿着通道维度拼接得到通道数为2的特征图。然后,使用1×1 卷积对拼接后特征图调整通道数,为了保证最后得到的特征在空间维度上与输入的一致。最后,经过sigmoid激活函数生成空间注意力权重Ys:
将空间注意力与通道注意力组合得到SCA 模块,如图4 虚线框所示。SCA 模块首先通过通道注意力得到通道权重Yc,然后将Yc与初始特征图O相乘得到Zc,如公式(3)所示:
将Zc通过空间注意力,得到融合了通道和空间的注意力权重Ys,其包含了一部分通道注意力的先验知识,因此Ys与Yc相比,能更好地关注特征图中的有效特征。在无人机航拍图像中,小目标众多,由于Zc比O具有更丰富的语义信息,为了避免模型对某一类别目标过于敏感及感受野变小,可能会出现误检现象,将Ys与干净的初始特征图O相乘得到Zs,避免语义信息可能会带来的影响,如公式(4)所示:
最后将Zc与Zs加和,此操作为了有效结合通道与空间两个维度的特征。加和后经过sigmoid激活函数得到基于通道和空间注意力的权重,如公式(5)所示:
本文提出的FRM可以让模型更关注包含小目标特征的区域,过滤噪声信息,减小冲突信息对检测的干扰,提高小目标的检测精度。
如图5 展示了使用FRM 模块前后的可视化效果图。图中,最左侧为原始输入图像,中间为未使用FRM,最右侧为使用FRM 后,可以看出使用后,模型会更关注细节,能够注意到包含目标特征的区域并过滤掉冲突、噪声信息,证明了FRM模块的有效性。

图5 可视化分析Fig.5 Visual analysis
1.3 浅层融合网络
原始的YOLOv5算法由于多次下采样操作,导致小目标在不断下采样的过程中丢失了特征信息,并且较深的特征图使小目标的特征难以学习,导致小目标检测不理想。基于上述问题,构造一种浅层融合网络(shallow fusion network,SFN)。
浅层网络主要提取物体的边缘及纹理特征,保留了更多的特征细节;深层网络主要关注物体的语义信息,缺少对小目标的细节特征以及位置信息的感知,导致小目标特征信息丢失,检测效果差。由于本文主要关注小目标检测,因此去除检测大目标的尺寸为20×20 的P5检测层,并添加一个较浅的尺寸为160×160 的P2 检测层。通过加入卷积和上采样操作,扩展特征图。然后,将得到的特征图与骨干网络提取的特征图进行融合,得到更大的特征图用于检测小目标,构成SFN 网络,使模型对图像中的小目标更加敏感。新增的小目标检测层保留了更多小目标丰富的特征信息,提高了小目标的分辨率,有助于模型学习小目标的特征。同时,去除的大目标检测层,减少了模型参数量的同时还加快了模型的收敛速度。
1.4 Alpha-EIoU损失函数
YOLOv5 采用的损失函数为CⅠoU[20],其计算公式如下:
其中,b和bgt代表预测框与真实框的中心点,ρ代表预测框与真实框中心点之间的欧氏距离,c代表包含预测框和真实框的最小矩阵的对角距离,wgt和hgt为真实框的宽度和高度,w和h为预测框的宽度和高度。从公式可以看出,CⅠoU使用的是宽和高的相对比值,当预测框的宽和高满足一定线性条件后,其添加的惩罚项便失效,惩罚项v对w和h求导如公式(8)、(9)所示:
虽然EⅠoU 解决了CⅠoU 的问题,但对于航拍图像,目标不仅小并密集,会出现重叠框的问题,影响收敛速度。因此,本文在EⅠoU 中计算预测框与真实框中心点之间的欧氏距离上引入一个α幂指数,在长度和宽度上引入一个β幂指数,提出Alpha-EⅠoU。计算如公式(12)所示:
cw和ch分别表示预测框和真实框形成的闭合区域的宽度和长度。Alpha-EⅠoU解决了预测框回归过程中宽和高不能同时增加或减少,并且考虑了难易样本不平衡的问题。从而改善了具有高ⅠoU目标的损失,使回归预测更为精准,在模型训练时加快收敛速度,进一步提高小目标的检测精度,为小目标数据集提供了更强的鲁棒性。
2 实验与分析
2.1 实验环境与数据集
本文实验使用Windows 系统,实验环境为PyTorch 1.11,Cuda 11.3。所有训练与测试都在NVⅠDⅠA RTX 3070Ti GPU 进行,优化器为AdamW,所有模型使用相同超参数。本文评价指标使用mAP50、mAP50:95、FPS。其中mAP50表示设置ⅠoU阈值为0.5时全部目标类别的平均检测精度,mAP50 可以反映模型对不同类别目标的综合分类能力;mAP50:95表示设置以步长为0.05,计算ⅠoU 阈值从0.5 至0.95 的全部10 个ⅠoU 阈值下的平均检测精度;FPS用于衡量模型的检测速度。
本文使用VisDrone2021[22]数据集,由天津大学机器学习与数据挖掘实验室的AⅠSKYYE 团队收集,其中包括6 471 张训练图像,548 张验证图像和1 610 张测试图像,共10 个类别,分别为行人、人、自行车、汽车、面包车、卡车、三轮车、遮阳篷三轮车、公共汽车、摩托车。该数据集检测难点在于:图像中物体较多并有重叠;因为拍摄角度原因导致标注框小,小目标物体居多;与通用检测数据集差别较大,使用预训练权重效果一般。
2.2 模块消融实验
为了验证所设计的上下文特征增强模块(CFEM)、特征细化模块(FRM)和损失函数(Alpha-ⅠOU)的有效性,设计消融实验进行验证,在VisDrone2021 数据集上使用相同参数进行实验,实验结果见表1。
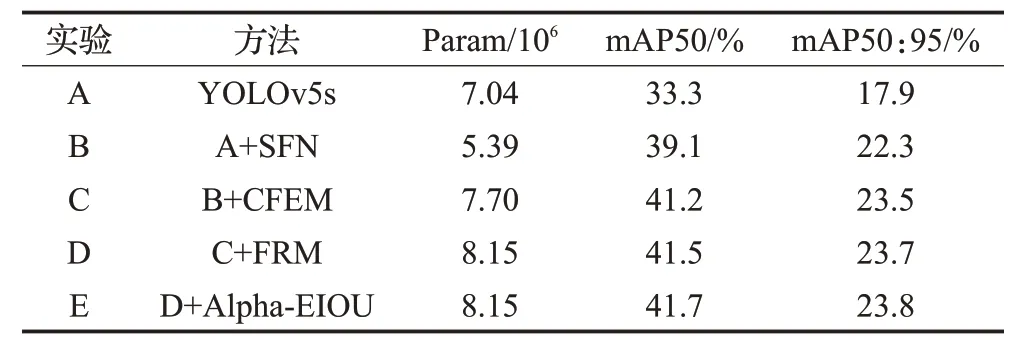
表1 消融实验Table 1 Ablation experiment
从表1可以看出,实验B使用SFN网络后mAP50提高5.8 个百分点,参数量减少1.65×106;在实验B 基础上添加CFEM模块后,mAP50提高2.1个百分点,参数量增加2.31×106,与基准模型参数量持平,证明该模块可以在增加少量计算量前提下补充上下文信息,并提高了小目标检测的精度;在实验C 基础上添加FRM 模块后,mAP50 提高0.3 个百分点,证明FRM 可以有效过滤噪声,减少冲突信息对小目标的干扰,增加小目标特征的识别性;在实验D 基础上使用改进的Alpha-EⅠOU 损失函数后,mAP50 提高0.2 个百分点,并且不会带来额外参数量,证明所改进的损失函数对小目标有效。最终改进的模型较基准模型mAP50 提高8.4 个百分点,mAP50:95 提高5.9 个百分点,参数量仅增加1.11×106,证明了本文所设计的各个模块的有效性。
2.3 检测层消融实验
为了验证所构造的SFN 网络的有效性进行实验验证,如表2 所示。由表可看出使用了P2+P3+P4 检测层的SFN 网络mAP50 为39.1%,参数量减少了1.65×106,证明使用SFN网络后可以使模型更关注小目标,新增的检测层保留了更多小目标丰富的特征信息,提高了小目标的分辨率,有利于网络进行特征提取,减少小目标的漏检和误检。同时SFN网络不仅检测精度最优,并减少了模型参数量,去除的检测层减少了网络的冗余,加快了模型的收敛速度。

表2 检测层消融实验Table 2 Prediction layer ablation experimental
2.4 融合方式消融实验
以使用浅层融合网络后的结构为基准模型,对CFEM 模块中的三种特征融合方式进行消融实验验证有效性,实验结果如表3所示。从表中可以看出使用自适应特征融合效果最佳,mAP50 提高2.1 个百分点,mAP50:95 提高2.2 个百分点,拼接融合介于加权融合与自适应特征融合之间。

表3 融合方式消融实验Table 3 Fusion mode ablation experiment 单位:%
2.5 损失函数对比实验
为验证改进的损失函数的有效性,与目前主流的CⅠoU、DⅠoU和SⅠoU损失函数进行实验对比,以YOLOv5s为基准模型进行实验,实验结果如表4所示。表中可以看出,本文提出的Alpha-EⅠOU 与其他损失函数相比具有更好的精度表现,更适合小目标检测任务。

表4 损失函数对比实验Table 4 Loss function comparison experiment单位:%
2.6 对比实验
本文对比了改进后的的算法与其他主流算法在VisDrone数据集的效果。其中包括双阶段算法、YOLO系列算法与专注于小目标的检测算法,实验结果如表5所示。

表5 对比实验Table 5 Comparison experiment
对表5进行分析,本文方法与以精度为优势的双阶段算法相比,例如经典的Faster-RCNN,本文方法mAP50 高出8.5 个百分点。与以速度为优势的YOLO系列算法相比,本文方法在满足实时性的前提下,mAP50比YOLOv8s 高出3 个百分点。与专注于小目标的检测算法相比,对于精度次优的小目标算法TPH-YOLOv5,由于其使用了自注意力机制,计算量较大,速度较慢,本文方法在精度与速度上与其他小目标算法相比更有优势。与基准模型YOLOv5s相比,mAP50提高了8.4个百分点,精度和召回率分别提高了7.0个百分点和5.2个百分点。从实验结果来看,本文方法mAP50 提升较为明显,证明本文方法具有较强的定位能力。综上,本文方法比其他先进算法有一定优势,可以有效提高小目标检测精度。
2.7 检测结果分析
为了验证所提出的算法在无人机场景中的检测效果,在VisDrone2021测试集中选取模糊、遮挡、密集场景下具有挑战性的图像进行检测,对本文方法进行可视化评估。检测结果如图6所示。

图6 检测效果图Fig.6 Detection effect pictures
图6(a)为模糊场景的检测效果图,在实际拍摄场景中由于无人机或摄像头云台转动过快会导致拍摄图像出现模糊失真的情况。图中可以看出模型依旧可以检测出模糊场景下的汽车、人等目标,并且在夜晚昏暗场景中仍然可以识别出模糊的汽车与行人目标。图6(b)为遮挡场景的检测效果图,实际场景中常存在树木、物体重叠等遮挡现象。图中可以看出改进后的算法可以很好检测出被树遮挡的汽车与摩托,且远处骑车的人与自行车也可以区分开来,说明模型能够检测出受遮挡和重叠度高的小目标。图6(c)为密集场景的检测效果图,图中的目标极小,小目标数量丰富,比如对于广场与操场上密集且重叠的人,改进后的算法依然可以较准确地检测出,说明本文方法对密集场景中的小目标检测效果突出。
将基准模型与改进后的算法进行比较,检测效果如图7 所示,图7(a)为基准模型检测结果,图7(b)为本文方法检测结果。图中可以看出,改进后的算法较YOLOv5 检测能力提升明显,YOLOv5 有漏检、错检现象,比如将锥筒识别为人,远处的车辆、人有漏检现象。

图7 检测结果对比Fig.7 Comparsion of object detection results
综上,本文方法通过上下文信息捕捉到更充分的小目标特征信息,并通过特征细化模块从大量特征信息中提取有利于目标分类定位的信息,相比YOLOv5s减少了漏检、错检的情况,在模糊与遮挡的场景下具有较好的鲁棒性,能够应对在无人机中的实际应用。
3 结语
本文提出了一种基于上下文信息与特征细化的无人机小目标检测算法,以解决小目标密集、特征不明显导致检测精度低的问题。首先,为了网络补充上下文信息,设计了一种上下文特征增强模块;其次,通过融合空间与通道的特征细化模块来过滤噪声,避免冲突信息的干扰;最后,优化损失函数来进一步提高小目标检测精度。改进后的网络模型在VisDrone2021 数据集上进行实验,结果表明,本文方法优于其他先进模型,在一定程度上提高了YOLOv5算法对小目标的检测效果,能够有效完成无人机场景下的密集小目标检测任务。未来将研究方向集中在模型优化,使用剪枝、蒸馏等手段进一步压缩模型,使其更好地进行部署应用。
