OMC框架下的行人多目标跟踪算法研究
2024-03-12贺愉婷吴金蔓马鹏森
贺愉婷,车 进,吴金蔓,马鹏森
1.宁夏大学物理与电子电气工程学院,银川 750021
2.宁夏沙漠信息智能感知重点实验室,银川 750021
多目标跟踪是计算机视觉领域的研究热点,旨在估计视频序列中某个或多个目标的位置和尺寸,同时赋予每个目标唯一的身份标识,并在目标运动过程中保证目标身份信息稳定。它被广泛应用于视频监控、城市安全、无人驾驶等领域。
多目标跟踪按照检测和特征提取的执行步骤,分为“分离式”跟踪范式和“联合式”跟踪范式。分离式模型(如SORT[1]、DeepSORT[2]等)遵循先检测后特征提取的步骤,分步执行的优势是算法的准确度相对较高,但是就会导致实时性相对差一些,因此联合式跟踪模型JDE[3]将特征提取部分融合到目标检测网络中,同时输出检测和重识别信息,使得实时性大幅提高。与此同时,研究发现检测任务和ReⅠD任务存在“竞争”问题,这在一定程度上限制了跟踪的性能,因此,Zhang等人[4]提出FairMOT 算法,着重考虑了两个分支任务的集成问题,采用CenterNet[5]作为目标检测算法,并行输出ReⅠD分支,并且探究了ReⅠD维度问题,将目标检测和重识别很好地统一起来。同样地,基于JDE 模型,Liang 等人[6]提出特征互惠网络缓解了JDE 模型中两个分支任务的“矛盾”,同时提出SAAN 网络,在特征提取方面进一步优化。“联合型”跟踪模型相较于“分离式”模型有了极大的改进,但是仍然存在一定的问题。Liang等人[7]进一步研究发现大部分基于检测的跟踪模型完全依赖于检测模型检测结果的正确性,但是这只是理想状态,实际应用中不会存在目标全部被检测到的情况,因此提出OMC(one more check)算法,基于CSTrack 跟踪框架,设计了一个Recheck 网络,以恢复由MOT 任务中不完善的检测所引起的错误分类的目标。经过对OMC算法的深入研究,本文发现虽然OMC 算法对误检的恢复有着不错的效果,但是并未考虑从源头上对特征进行优化,遮挡导致的“漏检”和“误检”问题依然存在,进而造成多目标跟踪过程中的“误跟”和“漏跟”问题仍然严重。因此本文考虑从源头优化目标特征的质量,主要基于OMC 算法提出五点改进:(1)首先优化特征提取器,在Backbone部分集成全局注意力机制,获取跨维度的相互作用信息,强化特征;(2)在Neck部分,采用转置卷积上采样方法进一步增强网络推理能力;(3)构造递归交叉相关网络利用自相关和互相关性质充分学习检测和ReⅠD 特征的特性和共性,使得模型性能增强;(4)优化尺度感知注意力网络,集成新的通道注意力模块HSCAM,学习强鉴别性的特征;(5)更换了检测分支边界回归损失函数,采用EⅠoU作为新的损失函数,回归更加准确,有效降低了FN和FP指标值。
1 网络模型
1.1 整体框架
本文采用OMC算法作为基础跟踪框架,OMC模型主要是在CSTrack的基础上添加了一个Recheck网络恢复检测器漏检的目标。本文算法的具体流程:首先,给定一帧x,经过一个特征提取器φ处理,生成特征Ft=φ(x),然后将Ft输入递归交叉相关网络(recursive cross-correlation network,RCCN),将共享特征进行解耦如公式(1),并通过二次交叉互相关性质学习不同任务的特性和共性,对特征进行增强,再分别输入Head分支(包含检测分支和ReⅠD分支),输出检测结果和ⅠD嵌入。此处的ReⅠD分支采用尺度感知注意力网络(scaleaware attention network,SAAN),集成了空间和通道注意力模块对特征进行进一步增强,此时的跟踪器生成了检测结果和重识别结果,Recheck网络则用于恢复由检测器引起的错误分类。本文算法的具体框架如图1所示。

图1 算法架构Fig.1 Algorithm architecture
公式(1)表示对共享特征Ft进行解耦,得到为检测结果(包括∈RH×W×1为前景概率,∈RH×W×4为原始锚框),∈RH×W×C表示ⅠD嵌入(C=512)。Dbase表示经过greedy-NMS[8]进行处理后的基础检测结果,Dbase中的每个锚框对应于Fid中嵌入的(1×1×C)向量,所有目标ⅠD 嵌入集合表示为Eid。最后,利用锚框和Dbase的ⅠD嵌入与历史轨迹进行关联。
实际情况中,检测器并不能保证检测的完全正确,当CSTrack 基础检测器错误地将目标归类为背景时,Recheck 网络用以修复错误问题。它是由两个模块组成:转换检测模块和过滤假阳性(false positive)的细化模块。通过测量和当前ⅠD嵌入之间的相似性来转换历史轨迹。它将特征Ft与相似性图进行融合,得到细化后的特征图,在一定程度上缓解了由于目标在当前框中消失而导致的false positive。Recheck 网络的执行可以表示为:
其中,Π代表Recheck 网络,实现历史轨迹到当前帧的转导,输出转导结果Mp。Mp与原始锚框一并构成修正后的检测结果,传入greedy-NMS 进行处理输出转换检测结果Dtrans,再通过ⅠOU 机制与Dbase相结合,输出最终的候选锚框Dfinal,然后与中相应的ⅠD 嵌入进行关联。
1.2 特征提取器设计
OMC 算法的基础检测框架采用YOLOv5 结构,为了提高性能,本文在Backbone 部分集成了全局注意力机制,增强特征输出,同时对Neck网络部分进行优化,将原始的最近邻插值(nearest interpolation)上采样方法替换为转置卷积(transposed convolution,TC)上采样。
首先,考虑提升检测器的性能,在Backbone集成全局注意力(global attention mechanism,GAM)[9],明确网络应该关注的目标对象和位置。GAM不仅可以减少信息的丢失并且能放大全局维度交互特征。GAM包括两个子模块:通道注意力子模块和空间注意力子模块。两个模块的连接同CBAM 注意力机制[10]。通道注意力子模块,通过三维排列在三个维度上保留信息,然后使用一个多层感知器(MLP)放大跨维通道-空间依赖性;空间注意力子模块,通过使用两个(7×7)卷积进行空间信息的融合,其中涉及到的通道缩减比r取值16(同BAM注意力机制[11]设置)。GAM 注意力机制的数学过程如公式(3)和公式(4),其整体结构图及子模块的结构如图2所示。
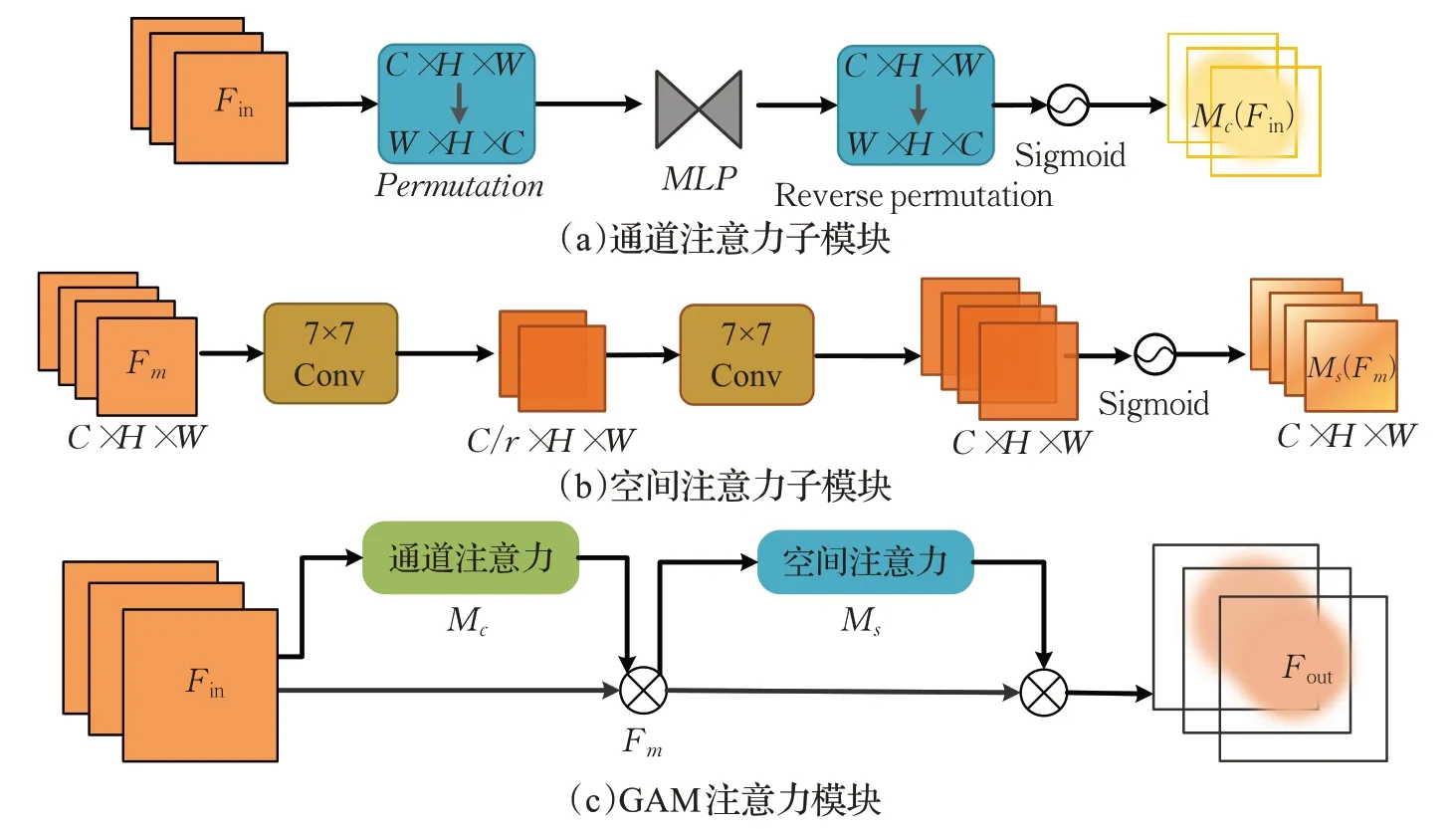
图2 GAM注意力机制Fig.2 GAM attention mechanism
其中,Fin表示输入特征,Mc和Ms分别为通道注意力和空间注意力,⊗代表元素乘法。输入特征经过通道注意力子模块处理之后得到中间特征Fm,再将中间特征作为输入传入空间注意力子模块处理得到强化后的特征Fout。
针对Neck 部分的优化,本文改进了原始的上采样方式(最近邻上采样),替换为转置卷积上采样方式。最近邻上采样方式计算比较简单,速度快,但是存在图像失真,特征细节丢失等问题;而转置卷积属于基于深度学习的上采样方式,权值是可学习的,通常可以取得更好的效果。两种上采样方式的计算公式如公式(5)和公式(6),对比图如图3所示。

图3 两种上采样方式对比图Fig.3 Comparison chart of two up-sampling methods
最近邻上采样公式:
其中,(Ox,Oy)表示原图像中像素点的坐标,(Dx,Dy)表示目标图像中像素点的坐标,(Ow,Oh)表示原图像的宽高,(Dw,Dh)表示目标图像的宽高。当(Ow/Dw)和(Oh/Dh)小于1时,相当于将原图像进行放大;反之缩小。
转置卷积计算公式:
其中,X表示输入(n维列向量),Y表示输出,C表示卷积核转换的稀疏矩阵表示,X′表示通过转置矩阵将输出矩阵的尺寸同输入特征尺寸转换一致的新输出的矩阵。
采用不同的上采样方式在MOT16各训练子集上进行对比实验如表1,可以验证更换为转置卷积上采样方式后带来了性能的增益。
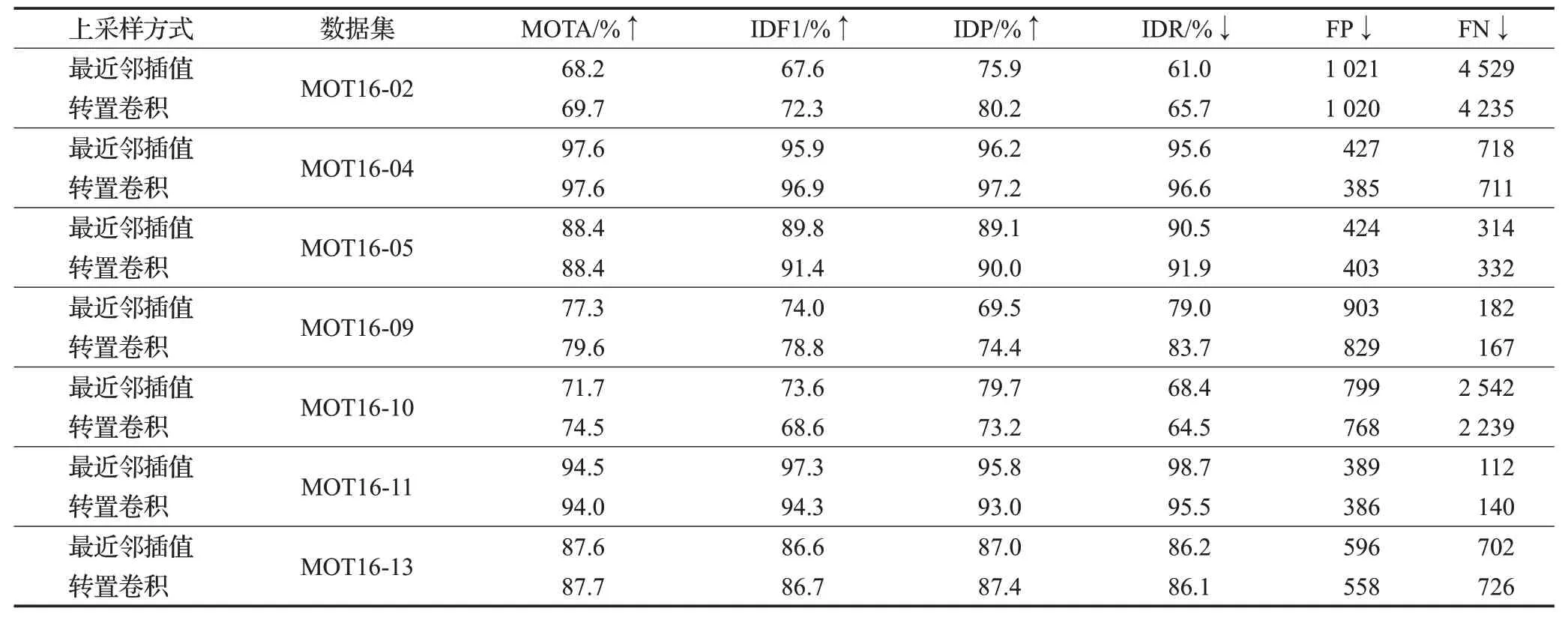
表1 两种上采样方式在MOT16不同训练子集上的消融实验Table 1 Ablation experiments of two upsampling methods on different training subsets of MOT16
1.3 递归交叉相关网络
本文提出递归交叉相关网络(RCCN)替换CSTrack中原始的互惠网络(reciprocal network,REN)[6],同样地学习检测分支特征和重识别分支特征的特性和共性,通过学习反映不同特征通道之间相互关系的自相关性来增强每个任务的特性;通过交互不同任务之间的语义信息增强任务之间的共性。增加二次交叉关联关系的构建,使得各个任务的特性和共性更加显著。
递归交叉相关网络的结构如图4所示,其中输入特征Fi∈RC×H×W,通过平均池化得到对背景信息更为敏感的特征∈RC×H′×W′,并且通过相同的操作(Conv+reshape)得到代表检测任务的张量M1∈RC×H′W′和代表ReⅠD任务的张量M2∈RC×H′W′,再对张量转置,进行自相关矩阵乘法和互相关矩阵乘法,并通过Softmax 计算出偏检测任务的自相关权重WT1∈RC×C和互相关权重WS1∈RC×C,以及偏ReⅠD 任务的自相关权重WT2∈RC×C和互相关权重WS2∈RC×C。然后,通过一个可学习参数λ将自相关权重和互相关权重进行融合,分别得到最终的权重因子{W1,W2} 。自相关权重、互相关权重以及最终的权重因子的数学计算如下:

图4 递归交叉相关网络Fig.4 Recursive cross-correlation networks
得到权重因子之后,再对原始特征图进行卷积和reshape的处理,将原始的Fi∈RC×H×W变换为Fi∈RC×N(N=H×W),此时,就可以将重塑后的原始特征与权重因子进行矩阵乘法,分别得到两个任务的增强特征再将其reshape 为RC×H×W。同理,本文进行二次的特征增强过程,操作过程同上,最终得到进一步增强后的特征,并且为了避免处理过程中信息的丢失,将增强特征与原始特征进行融合得到与,分别输入检测任务分支和重识别任务分支进行后续处理。
1.4 尺度感知注意网络
关于ReⅠD网络分支的构建,OMC框架中采用的尺度感知注意网络(SAAN),如图5所示,首先对输入的不同尺寸的特征图(指:原图尺寸的1/16和1/32倍)进行上采样到原图尺寸的1/8倍,并通过3×3卷积进行编码[12];接下来,对于三个分支的处理是分别通过空间注意力(spatial attention module,SAM)抑制背景噪声,增强目标表征。SAM具体的操作是:首先经过平均池化和最大池化生成两个二维映射Fsavg∈R1×H×W和Fsmax∈R1×H×W,其次经过一个7×7的卷积层提取特征,然后使用Sigmoid激活函数进行归一化,得到空间注意力图,将得到的空间注意力权重与特征相乘得到增强后的特征,并与原始特征进行融合输出特征,最后将处理后的三个分支上的特征Concat起来传入通道注意力机制进行后续处理。
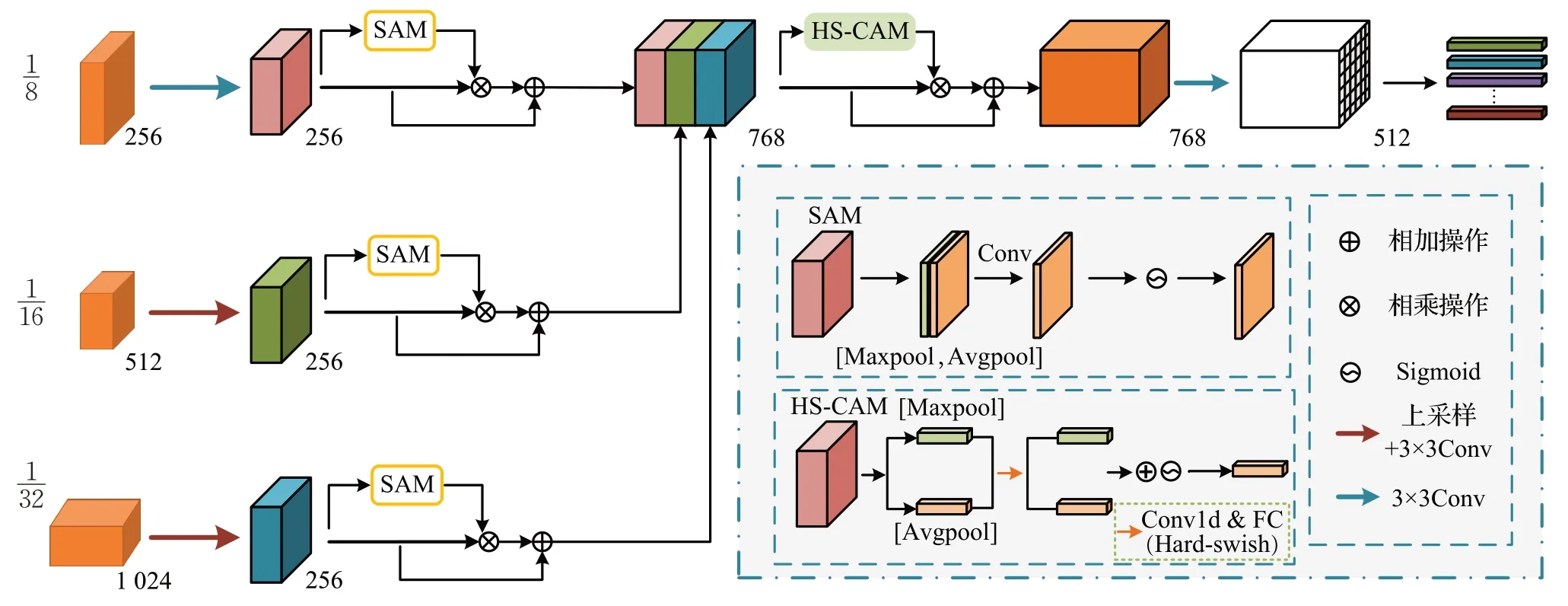
图5 SAAN网络架构Fig.5 SAAN network architecture
经过空间注意力模块的处理,网络获悉了更利于产生具有强鉴别性ⅠD 嵌入的特征位置;接下来将引入通道注意力模块(channel attention module,CAM)重点关注“什么”特征对提取强鉴别性的特征有利。本文在此处构建了新的通道注意力子模块HS-CAM,具体的操作是:首先对传入的特征进行并行的池化操作(包含最大池化和全局平均池化)获得不同分辨率特征的统计信息,然后将最大池化特征和全局平均池化后的特征分别送入一个共享网络(具有一个隐藏层的多层感知器)进行处理生成通道注意图,原始的共享网络采用的激活函数是LeakyReLU,虽然相比于常用的ReLU 激活函数,LeakyReLU 可以有效解决ReLU 激活函数在输入为负值情况下梯度消失的问题,但是它需要传入一个参数α,该参数并不能被神经元学习,灵活性低。因此,考虑到性能以及计算量,本文发现采用Hard-swish 激活函数[13]替换之后模型性能更优,Hard-swish计算公式如下:
1.5 Recheck网络
OMC 框架中的Recheck 网络用于恢复由检测器引起的错误分类目标,由转换检测模块和细化模块构成,具体的模块描述如下:
其中,mi中最大值的位置即为历史轨迹的预测状态。通过公式可以得到n个相似性响应,构成集合M={m1,m2,…,mn} ,其中的每个元素表示历史轨迹的转换检测结果。实际情况中,会出现外观相似度较高的目标,同样会得到高响应值,这就会对预测造成干扰,影响网络判断,针对此,需要缩小高响应范围,设置限制条件,加入一个缩放半径r,将mi离散化转成二进制掩模m̂i,见公式(13):
其中,表示m̂i在(x,y)处的值,(cx,cy)表示mi中最大值的位置,r是收缩半径。以r为边的方框区域为限,区域内设置为1,区域外设置为0。然后,将二进制掩模m̂i与原始相似性响应mi相乘以消除干扰性质的高响应带来的模糊预测。最后会得到n个处理后的响应图,通过元素加和操作得到最终的相似性图。
式中,Ms表示总的相似性图。对当前帧中的每个位置都计算出一个相似度得分,得分越高表示历史轨迹中的目标在该位置中出现的概率越大。
经过检测转换模块,生成了总相似性图Ms,然后将Ms传入细化模块进行处理,目的是缓解当前帧中未出现的目标在轨迹传导过程中带来的假阳性问题。细化模块具体处理过程是:首先通过两个3×3卷积层,将Ms先映射到高维空间(Channel=256),再降维(Channel=1)得到细化后的相似度响应,然后传入原始特征Ft与逐元素相乘得到新的特征F̂∈RH×W×C,F̂再通过卷积层得到最后的预测响应Mp。此时的Mp与构成预测结果Dtrans。此时Dtrans作为历史轨迹在当前帧上的预测框与基础检测中的检测框Dbase进行融合作为总的检测框用于数据关联,Dtrans和Dbase的融合计算如公式(15):
式中,首先计算转换检测结果得到的每一个预测框bi与基础检测框Dbase的ⅠoU,然后基于ⅠoU的最大值计算出一个目标得分s。当s得分高时,表示该锚框在初始检测的时候被遗漏。因此,设定一个阈值(ε=0.5),当s高于阈值的时候,转换检测模块重新训练锚框,将其作为基础检测结果的补充,对基础检测进行修正,保证轨迹的连续性。
2 损失函数
模型搭建完成之后,引入损失函数对其进行训练,此处主要包括检测分支的损失、ReⅠD 分支的损失以及针对Recheck网络设计的损失函数。
2.1 检测分支损失函数
检测分支损失函数主要包括分类损失和回归损失两部分。公式(16)~(19)分别描述了分类损失计算公式,边框回归损失的计算以及总的检测损失计算公式。
分类损失主要用于前景/背景的区分,OMC 中采用Focal Loss[14]:
其中,α表示平衡样本因子(取值0.25),γ是一个调制参数(此处取值0),pt表示真实标签的概率,公式如下:
式中,p表示前景概率,代表向下取整操作,r表示下采样率(取值同OMC[7]),该公式反映了处在位置的锚点作为正样本。
针对边框回归损失的计算,OMC 算法中使用的完全交并比损失(complete intersection over union loss,CⅠoU Loss)[15],但是CⅠoU 忽略了宽高分别与其置信度的真实差异,对模型的拟合造成困难,阻碍了模型优化的有效性[16]。因此本文采用有效交并比损失(efficient intersection over union loss,EⅠOU Loss)[17],两种ⅠoU损失公式如式(18)和(19),示意图见图6。

图6 两种ⅠoU示意图Fig.6 Schematic diagram of two types of ⅠoU
式中,IOU=(A∩B)/(A∪B)计算的是预测锚框A与真实锚框B重合部分覆盖的面积和二者覆盖的总面积的比值[18],描述两个框之间的重合度。o代表预测框的中心点,ogt代表真实框的中心点,ρ2(o,ogt)表示两个框中心点之间的距离,c是两个边框外接最小包围框的对角线距离,其中,a=v/[(1-IOU)+v]表示宽高比损失系数,(wgt,hgt)表示真实框的宽高,(w,h)表示预测框的宽高,为真实框与预测框的宽高比损失。但是CⅠoU损失函数中的v考虑的是预测框与真实框宽高比的差异,而EⅠoU 损失函数对其进行了改进,分别计算了宽、高损失:
EⅠoU损失函数包含ⅠoU损失,距离损失和宽高损失三部分,(cw,ch)表示预测框和真实框最小外接包围框的宽高。因此,回归损失计算如下,其中E 表示EⅠoU 操作,传入真实锚框bi以及在(x,y)处的预测框b̂x,y。
综上,总的检测损失由分类损失和回归损失组成,计算公式如下:
其中,Np表示正样本数量,m代表分辨率数,通过加入权重因子β来确定分类损失和回归损失在总损失计算中的占比,设置为0.05。
从图6可以直观看出,CⅠoU损失考虑了目标框和预测框之间的距离以及目标框和预测框的宽高比,而EⅠoU在CⅠoU的基础上将目标框和预测框的长、宽考虑在内,可以更好地反映预测框与目标框之间的宽、高差异,加快网络收敛,使得回归更加准确。
2.2 ReID分支损失函数
ReⅠD 分支的损失函数同CSTrack[6],对于外观特征的学习,期望得到具有强鉴别性的目标,即不同的目标,距离尽可能大,因此采用交叉熵损失,数学公式如下:
式中,N表示当前帧中目标的数量,K表示目标类别数。
2.3 Recheck网络损失函数
针对Recheck 网络的训练,OMC 引入了一个监督函数,由于相似度图Mp的真值被定义为多个高斯分布的组合,因此每个目标的监督信号定义为一个类高斯掩模,计算如公式(23):
式中,Mxy和Txy表示Mp及其监督信号T在(x,y)处的值。
因此,总的损失函数计算是三个部分损失函数的加权,具体的融合公式为:
其中,为了平衡检测和重识别任务,增加参数η(取值0.02)[6]。
3 实验结果与分析
3.1 数据集与评价指标
(1)数据集:
Crowdhuman数据集[19]是用于行人检测的大型数据集,包括训练集15 000张,测试集5 000张,验证集4 370张图片,数据集分布见图7(a)。其中每张图片中大约包含23 个人,并存在着各种遮挡情况,Crowdhuman 数据集对每个行人目标都分别对其头部、人体可见区域和人体全身进行边界框注释[20]。

图7 实验数据集Fig.7 Experimental data sets
MOTChallenge数据集是用于行人多目标跟踪的大型公开数据集,数据集分布见图7(b)。其中,MOT15数据集[21]由22个视频序列构成(11个用于训练,11个用于测试);MOT16 数据集[22]由28 个视频序列构成(14 个用于训练,14个用于测试);MOT17数据集与MOT16数据集序列一致,不同之处是为每一个视频序列提供3种公开检测器(DPM、FRCNN、SDP)检测结果;MOT20 数据集[23]由8 个视频序列构成(4 个用于训练,4 个用于测试),共13 410 帧,采集于密集场景,平均人群密度达到每帧246个行人。
(2)评价指标
本文在MOT16 和MOT20 数据集上测试算法的有效性,采用多目标跟踪领域通用指标[24]来评估模型的性能,具体的评估指标及其含义如表2。

表2 多目标评估指标Table 2 Multi-objective assessment indicators
3.2 实验环境与训练策略
实验环境基于Ubuntu 18.04 操作系统,1 块Tesla V100显卡,运行内存为64 GB,显存32 GB,采用Pytorch 1.7.1深度学习框架,Python 3.8的服务器下实现。
训练过程分为两个阶段,第一阶段使用Crowdhuman数据集、MOT17、MOT15数据集3个数据训练基础跟踪器,第二阶段使用MOT17 数据集训练Recheck 网络,在MOT16训练集上进行消融实验评估对比,在MOT20训练集上进行模型改进前后的对比实验,在MOT16 测试集上与其他先进算法进行对比实验,评估改进模型的正确性。
3.3 消融实验
本文在MOT16训练集上进行消融实验,①是在特征提取器Neck部分采用转置卷积上采样;②是在特征提取器Backbone 部分集成GAM 注意力机制;③是构建RCCN 网络;④是重构SAAN 网络中通道注意力模块;⑤是采用EⅠoU损失函数作为边框回归损失。①~⑤逐一增加改进点;⑤代表本文所提算法。实验结果如表3 所示(↑表示指标值越高越好,↓表示指标值越小越好),模型改进可视化结果图如图8所示。

表3 模型在MOT16训练集上的消融实验Table 3 Ablation experiments of model on MOT16 training set
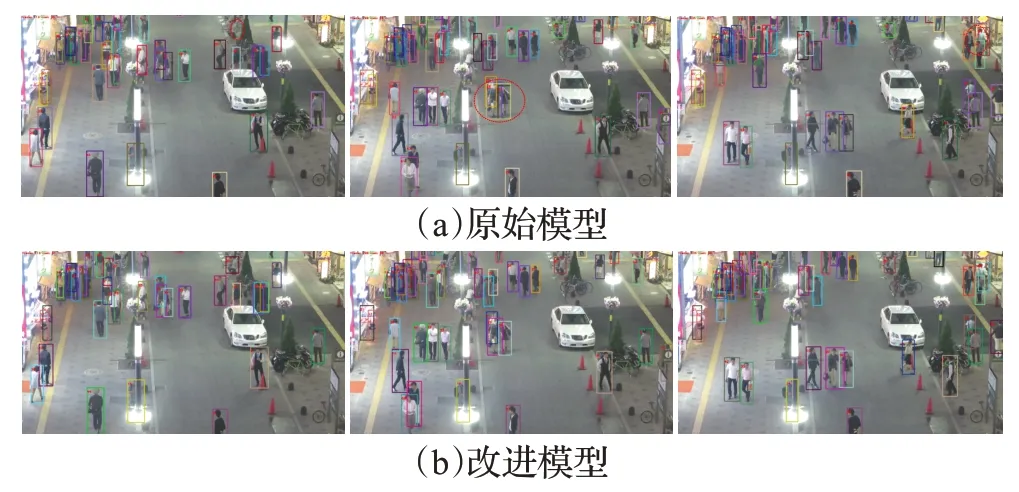
图8 MOT16训练集评估模型改进前后的对比图Fig.8 Comparison chart of before and after model improvement evaluated by MOT16 training set
由表3可知,通过采用转置卷积上采样方式使得模型综合性能指标MOTA提升0.7个百分点,FP下降210,FN下降549;通过集成GAM注意力机制,加强了网络对有效信息的关注,指标进一步提高;RCCN 网络通过学习任务之间的特性和共性,有效缓解了语义混淆问题,使得模型的MOTA 相较于原始模型提升1.7 个百分点,MT指标增加19,ML指标下降11;对重识别网络的重构主要是提出HS-CAM通道注意模块,较改进前各项指标都有所优化;最后,改进检测分支的回归损失函数,将原始的CⅠoU损失替换为EⅠoU损失后,加速了预测框的收敛,MOTA 提升至89.6%,ⅠDF1 提升0.9 个百分点(④vs.⑤),模型综合性能得以进一步提升。
可视化结果如图8,MOT16-04数据集中,采用原始模型处理时,在110帧处一位坐着的男士被漏检;298帧处,出现了一个框同时包含两个行人并赋予ⅠD的情形,这将会造成歧义;在435 帧处,出现了由于行人遮挡导致被遮挡行人“掉框”的情况(以上问题在图中用红色虚线圈出)。而改进模型中并未出现上述问题,直观反映了改进模型的性能。
3.4 对比实验
本文模型与原始OMC 模型在MOT20 数据集上的对比结果如表4,可视化对比图如图9所示。

表4 MOT20训练集上进行模型改进前后的对比实验Table 4 Comparison experiments before and after model improvement on MOT20 training set

图9 在MOT20数据集上模型改进前后对比图Fig.9 Comparison before and after model improvement on MOT20 dataset
由表4中指标数据可知,本文改进模型MOTA指标相比较原始模型提升1.9 个百分点,ⅠDF1 上升1.1 个百分点,ⅠDP 指标轻微下降,ⅠDR 指标增加1.7 个百分点,MT 增加85,ML 减少17,综合性能更优。可视化图如图9,本文任取两帧(371 帧和404 帧)进行对比,本文发现,采用原始模型跟踪过程中,371 帧中ⅠD 为302 的女士,由于行人的遮挡,在404帧中ⅠD切换为130,造成了身份混乱;而采用本文改进模型跟踪时,该女士在371帧中ⅠD 为397,经过遮挡后,在404 帧ⅠD 仍然保持为397,反映出改进模型的有效性。
为了进一步验证本文算法的优势,在MOT16、MOT20测试集上与部分先进多目标跟踪算法进行对比实验。各项多目标跟踪的评价指标如表5和表6,并且在MOT16测试集子集上的可视化跟踪轨迹如图10所示。

表5 模型在MOT16测试集上与其他先进算法的对比实验Table 5 Model comparison experiments with other advanced algorithms on MOT16 test set

表6 模型在MOT20测试集上的对比实验Table 6 Model comparison experiments with other advanced algorithms on MOT16 test set

图10 可视化跟踪轨迹展示Fig.10 Visual tracking trajectory display
为了实验的公平性,本文采用相同的策略训练OMC原始模型并在MOT16、MOT20测试集上进行评估得到了各项指标。由表5可知,基于MOT16测试集,本文模型的ⅠDF1指标相较于OMC算法提升了1.2个百分点,较JDE算法提升了14.6个百分点,FP指标较FairMOT算法减少了14 042,MTgt指标较OMC算法有所下降,但高于其他所列算法,MLgt较OMC 算法减少1.5 个百分点,但FPS 指标有所下降;基于MOT20 测试集,本文算法较OMC 算法MOTA 提升了1.5 个百分点,ⅠDF1 提升了2.3 个百分点,MTgt增加了2.1 个百分点,MLgt减少了9.9 个百分点。综上分析,改进后的模型性能得以提升。改进模型在MOT16测试集上的可视化跟踪轨迹展示如图10。
4 结束语
针对多目标跟踪中由于实际环境复杂多变导致的跟踪性能差的问题,本文基于OMC 多目标跟踪框架展开研究,提出改进模型以提升跟踪性能。首先对特征提取器进行重构,在Backbone 集成了GAM 注意力机制,强化特征信息,在Neck网络中采用转置卷积上采样;其次构建RCCN网络加强学习检测和ReⅠD任务的特性和共性,得到解耦特征;然后对SAAN网络进行优化,构建了新的通道注意力机制HS-CAM 用于集成;最后采用EⅠoU 损失作为边框回归损失函数,提升了跟踪的准确度。实验结果表明,本文模型有效提升了多目标跟踪指标,在人群密度较大的MOT20数据集,MOTA指标提升至62.8%;在MOT16测试集上MOTA指标较OMC算法提升了2.4个百分点,较JDE算法提升了9.1%。以上指标的提升反映了改进后跟踪模型性能的优势。
