利用可信反事实的不平衡数据过采样方法
2024-03-12高峰,宋媚,祝义
高 峰,宋 媚,祝 义
江苏师范大学计算机科学与技术学院,江苏 徐州 221000
不平衡数据是指样本中某一类的样本个数远大于其他类的样本个数[1]。在二分类问题中,类别样本数较多者称为多数类(正类),较少者为少数类(负类)。在许多实际应用中都存在着这个问题,如医疗诊断[2]、软件缺陷预测[3]、信用欺诈检测[4]等。在数据不平衡的分类问题中,由于传统分类算法考虑的是整体精度的最大化,会导致分类器的学习偏向多数类,而忽略对少数类的识别,进而削弱对少数类的识别效果,降低了分类器整体性能。然而,少数类往往才是更加关注的对象,例如在信用欺诈检测中,违约样本(负类)才是需要重点识别的,错误识别存在违约可能的样本往往要比误分守信用户带来的损失要大。因此,如何有效处理不平衡数据对于机器学习分类问题具有重要意义。
目前,对不平衡数据集的处理方式主要有两类:算法层面的改进和数据层面的改进。算法层面是通过修改传统分类算法机理或调整其代价权重,以减少其对多数类的决策偏差,但是它们并没有改善原始数据间的类不平衡性,不能提供更多的决策信息,具有一定的使用局限性[5-7],所以在实际应用中,更多采用的是数据层面的改进。数据层面即对原数据集进行重采样以平衡数据分布[8],重采样包括欠采样和过采样两种。欠采样即删除部分多数类样本来平衡数据集,但由于很容易在删除过程中丢失掉数据的重要信息,造成欠拟合,因此,众多学者更倾向于过采样方法的相关研究[9]。最经典的过采样方法是Chawla等[10]提出的SMOTE算法,其使用插值法在相邻的少数类样本之间产生新样本,以平衡原始数据分布。后又有众多学者根据SMOTE算法提出了一系列改进算法,如Borderline-SMOTE[11]、ADASYN[12]、WKMeans-MOTE[13]等。不难发现,SMOTE及其改进算法都是基于插值法生成的“虚拟”样本,并没有充分挖掘原始数据集中的有用信息,使得生成的新样本并不能很好的体现数据特征,对分类性能提升有限。
结合上述研究,本文提出了一种基于反事实解释的过采样方法,使用基于案例推理的反事实方法进行数据扩充,根据现有实例的真实特征值(不是插值)合成反事实实例(少数类样本),从而填充少数类,解决类不平衡问题。经典的反事实解释案例是当一个智能系统拒绝个人贷款申请时给出的解释[14],当用户问为什么被拒时,该系统可能会给出:“如果你每个月的收入能再多300美元,那么贷款申请将会被通过”的解释。在反事实解释生成方面,主要有扰动式和填充式两种。扰动的主要思想是对查询样本(多数类)进行最小限度的特征调整,以改变决策区域,主要方法有ADAM[14]解算器、梯度下降[15]、混合整数编码[16]、K-D 树[17]等。填充式主要是根据现有数据的真实特征值进行样本合成。Smyth 和Keane[18]在2020年提出了一种基于案例推理的反事实生成方法,有效地利用了数据的边界信息。王明等[19]提出了一种基于贪心树的反事实解释生成方法:生成链接树,具有更高的数据真实性,为反事实解释的应用提供了可能。在应用方面,马舒岑等[20]利用反事实样本分析结果生成用户报告,为贷款失败用户改善自身情况提供了确切建议。Temraz 等[21]在气候对作物生长的影响研究中,使用基于案例的反事实方法增强数据集,改善了气候破坏时期的后续预测。夏子芳等[22]将反事实与知识图谱进行结合,有效提升了推荐的可解释性。以上研究都验证了反事实解释的可用性。Temraz和Keane[23]也将反事实解释应用于数据增强,使模型分类性能得到了有效提升,但是其并没有考虑所生成反事实实例的决策区域问题。
综合上述研究,本文针对不平衡数据分类问题,在数据层面提出了一种基于反事实的数据过采样方法,并对生成的决策边界的非正确反事实合成样本进行了筛除。为了验证本方法的有效性,在KEEL与UCⅠ数据库中选取多组数据与其他算法进行了多维度对比实验,实验结果表明,本文所提方法能明显提升基本分类器在不平衡数据集上的AUC 值、F1 值和G-mean 值,具有良好的泛化性。
1 基于反事实的过采样处理步骤
基于扰动的反事实解释生成方法是对查询样本的“盲”扰动,有时会合成边界外的、无效的样本[14,24-25],这在类不平衡问题中可能存在严重副作用,因为它表示用噪声数据填充少数类。因此,本文参考了Keane等[18]提出的基于案例的方法生成反事实实例。这种由实例引导的方法,首先捕获数据集中现有实例之间的反事实关系构建“反事实对”,然后查询样本(多数类)依据KNN算法查找最近已配对实例邻居并根据已配对邻居“反事实对”之间的特征差异来改变其决策区域。这对于不平衡数据集意味着决策边界的类别改变。
1.1 基于反事实生成“少数”样本
位于决策边界两侧相反类中的样本,依据一定约束条件(限定特征差异)会形成一对反事实对cf,其捕获了数据集中现有两实例之间的反事实关系。如图1 所示,圆圈与正方形所在决策区域分别为多数类与少数类,x与p为一对原生反事实对,dp为其差异特征;x′为未配对查询实例,依据HEOM 距离寻找其最近已配对实例x,将匹配特征mx′与dp组合合成新的实例p′添加到数据集中,以改进未来的预测。一些形式化定义如下:
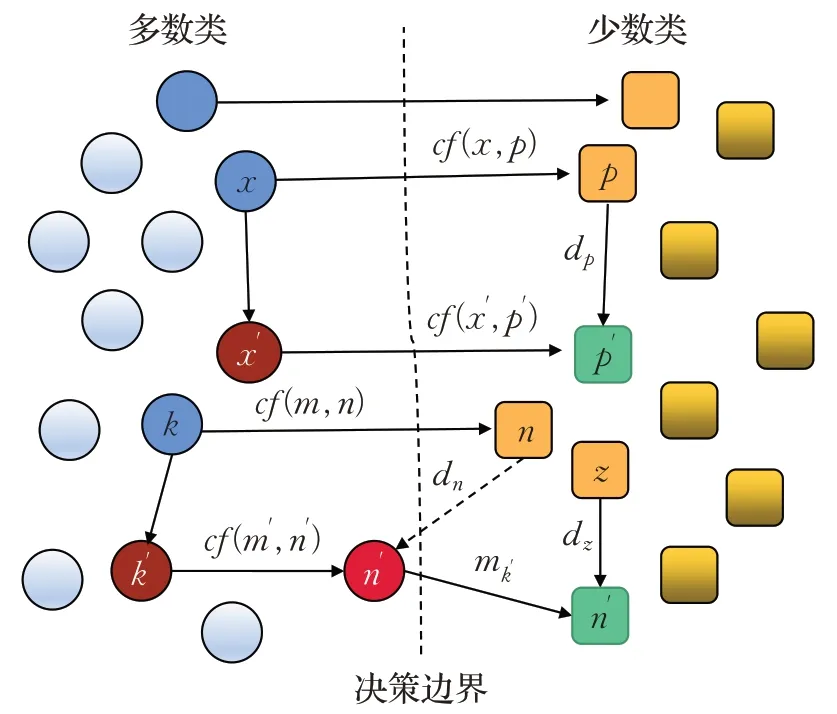
图1 反事实数据生成方法Fig.1 Counterfactual data generation methods
(1)X是一个多数类集合,P是一个少数类集合。
(2)反事实对集合CF,一个原生反事实对cf(x,p),x∈X,p∈P。
(3)未配对实例x′的最近邻已配对实例为x,有F(x)≠F(x′),匹配特征mx′,差异特征dp。
具体步骤如下:
输入:训练集T,匹配容忍度match_tol,类别特征索引数组Cat。
输出:添加了合成样本后的新数据集。
步骤1计算数据集T的CF集:将T划分为多数类X和少数类P,对多数空间中的实例(称为配对实例)和在少数空间中的反事实相关实例(称为反事实实例)进行配对,形成本地反事实对cf(x,p)。每一原生反事实对都有一组匹配特征和一组差异特征,其中的差异决定了样本所属类在决策边界上的变化。其中,mx′是来自x′所对应的匹配特征列的具体数据,dp是来自p所对应的差异特征列的具体数据。
步骤2对于查询实例x′,从多数类中找到其最近邻已配对实例x,即原生反事实对cf(x,p):对于x′,使用HEOM距离找到其最近邻x,这是一个涉及原生反事实对cf(x,p)的配对实例。设F为数据某特征,a、b为该特征的两个具体值,式(1)为HEOM[26]距离计算方式,这种距离度量方式保证了每个特征对总距离的贡献都在0到1之间。
步骤3转移匹配特征mx′以及差异特征dp:将实例x′所对应的匹配特征列的数据mx′以及原生反事实对cf(x,p)中p所对应的差异特征列数据dp转移到新实例p′上,进而生成少数类样本。
需要注意的是,匹配容忍度是CF中的一个参数,它用于提高数据集中良好的原生反事实对的可用性。如果没有容忍,即要求数量特征在数值上须相等,此时发现的反事实对会很少,新样本生成效益也可能会大大减少。在寻找一个原生反事实对的匹配和差异特征时,cf通过计算每个特征的最大值减去最小值作为基础容忍度base。如果两实例某特征差值在base×(match_tol)范围内则允许匹配,类别特征相同才视为匹配成功。此外,如何定义“好的”反事实配对是该算法的一个关键点。在传统意义上将一个“好的”反事实对定义为不超过两个特征差异的配对。在后续实践中,也有学者选用1~3 个[21,27]特征差异的反事实解释。在本文中,实验发现,具有2 个差异的原生反事实相对于1、3、4 和5 个能获得更好的性能。由于匹配容忍度与特征差异个数的限制,并不是每一个多数类样本都有对应的反事实样本,因此,最后生成的反事实合成样本个数是不确定的,输出的新的数据集并不是“绝对的”平衡,但新生成的样本能更好地反映数据集的边界信息差异,更有利于分类器的分类。
1.2 筛除无效样本
个别新生成的实例并不是一个有效的反事实解释,即可能落在相同决策区域内。例如,图1中新的反事实实例n′与k′具有相同的类,因为匹配特征值(来自k′)和差异特征(来自n)的组合不足以改变k′的类,如果将此类样本作为少数类样本进行数据填充,则会产生众多噪声,进而影响模型的预测。因此,本文对生成的反事实合成样本进行了筛除,即将训练好的分类器作为基础模型,去判别新样本所属决策区域。如果判断n′属于少数类区域即可认为p′为好的反事实解释,否则进行以下操作来改变n′的决策区域:
n′所拥有的来自k′的匹配特征不变,自适应迭代与n同类的有序最近邻,直到有一个类别变化。每个最近邻的差异特征值导致一个新的候选反事实实例q′,当q′的类别发生变化时,适应成功终止;如果没有近邻样本能产生类变化,那么适应失败。
SVM 以结构风险最小化为原则,克服了分类器高维、非线性和局部极小点等一系列问题,具有更好的鲁棒性,作为基础分类器的改进方案可以实现良好的分类性能[28-29]。目前,已有众多学者在不平衡数据问题中基于SVM 模型做出了进一步研究,例如:改良SVM 算法分类超平面[30]、与SMOTE算法进行结合采样[31]等,这些研究都有效解决了数据不平衡问题。因此,本文也选取SVM作为基本分类器来判别反事实样本点决策区域。
综上,本文方法完整流程如下:

2 实验设计
2.1 评价指标
在类不平衡问题的研究中,经常会出现模型整体预测准确率较高,而少数类预测准确率为0 的状况,而少数类样本往往更是需要重点关注与处理的。因此,准确率已不能很好地评估模型效果。针对不平衡数据集,有众多学者已经提出了更合理的评价指标,如F1、G-mean,两者均基于混淆矩阵进行计算(见表1)。

表1 混肴矩阵Table 1 Confusion matrix
据表1,可计算如下指标:
查准率precision 表示当模型预测为正时的可信度,召回率recall 表示模型将样本中正类样本预测正确的概率。
根据式(4)可以看出,F1 综合了precision 和recall两者,更加关注少数类样本的分类效果,在类不平衡问题中可以很好的评估模型。
G-mean 是recall 和specificity 的几何均值,兼顾了多少类与少数类,可用于评估模型整体分类性能。
2.2 实验数据集
本文从KEEL和UCⅠ两大数据库共选取了9组数据集进行实验,且兼顾了数据类型、数据大小、数据属性、数据不平衡率(正类样本总数/负类样本总数),详见表2。

表2 数据集的基本信息Table 2 Basic information of datasets
2.3 实验方法与算法参数
为了更全面、准确的评价算法,选用4 种采样方法(SMOTE、Borderline1-SMOTE、Borderline2-SMOTE、ADASYN,简称SM、B1、B2、ADA)分别在5 个分类器(RF、SVM、Logistic、DT、AdaBoost)上与本文方法进行了对比实验。每次实验中,都用5 折交叉验证的5 次平均结果作为相应指标最终得分。本文算法的参数如表3所示,匹配容忍度match_tol设置为0.1,其决定了数值型特征匹配的好坏,值越小对于匹配要求越严格。特征差异个数diff_nums设置为2,即要求两实例只有在特征差异个数不大于2时才视为匹配成功。基分类器SVM的C设置为1。
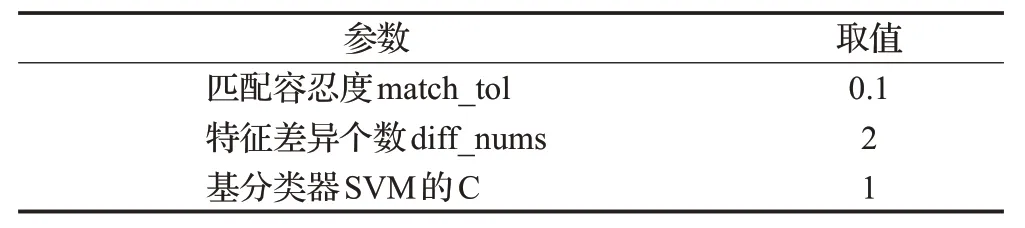
表3 算法参数Table 3 Algorithm parameters
2.4 实验结果
2.4.1 实验结果对比与分析
为了保证结果的稳定性,以下实验都是基于10 次随机种子数不同的5折交叉验证的平均结果,即50次结果的平均。
表4为本文所提方法与4种传统过采样方法在9种不平衡数据集、5 种不同分类器上的F1 与G-mean 的实验结果,黑色粗体表示同一数据集、不同采样方法结果的最大值。在45 组不同组合的实验中,本文在35 组中都同时达到了最高F1与G-mean最大,相较其他方法效果有了明显提升。其中,在5 种不同的类器上,相较其他方法,9 组数据集的平均F1 值分别至少提升了18%、8.5%、11.1%、7.9%、9.7%,平均G-mean 至少提升了4.3%、4.5%、4.4%、2.1%、3.6%。这说明:基于反事实的过采样方法生成的新样本更加可信,对于边界分类可以提供更多有用的信息,可以有效提升分类器对少数类样本的识别能力与整体数据的分类效果,具有良好的泛化性。

表4 5种方法的F1与G-mean值对比Table 4 Comparison of F1 and G-mean values between 5 methods
如果以每种算法在不同分类器上能取得最高AUC的数据集总数量来评估整体模型,即每种过采样算法分别在5 个分类器与9 组数据集上进行交叉组合实验(共45组实验)取得最高AUC的实验组数,本文所提出方法得分也是最高的(见表5):在未经采样处理的情况下,共有3 组实验取得最高AUC,占比6.7%;经SMOTE 采样后得分最高的有5组,占比11.1%;经B1-SMOTE采样后得分最高的有1组,占比2.2%;经SMOTE采样后得分最高的有1组,占比2.2%;经ADASYN采样后无得分最高实验组,经本文方法采样后得分最高的共有35组,占比77.8%。

表5 各算法能取得最高AUC的数据集数量Table 5 Number of datasets that each algorithm can achieve highest AUC
为了更直观地观察算法整体效果,本文统计了各算法在不同数据集上各分类器的平均G-mean与F1值,具体见图2、图3。图2 为每个算法在各分类器上的平均G-mean图,可以看出,本文算法在不同数据集上都有很好的预测效果,表现稳定。图3是每个算法在各分类器上的平均F1值图,在9种数据集上,本文算法在其中5项上都获得了最高F1 值,且提升效果明显;B2 与ADASYN分别在Pi 和Ad 上取得了最优F1,但不难发现,本文算法与其差距都甚小,依旧表现良好;在Segment和V0这两种数据集上,未经采样处理的原始数据取得了最优平均F1值,其他过采样算法F1值出现了明显下降,但本文算法减少较小,这也证明了该算法生成的样本点更加可信,对模型预测的噪声更少。
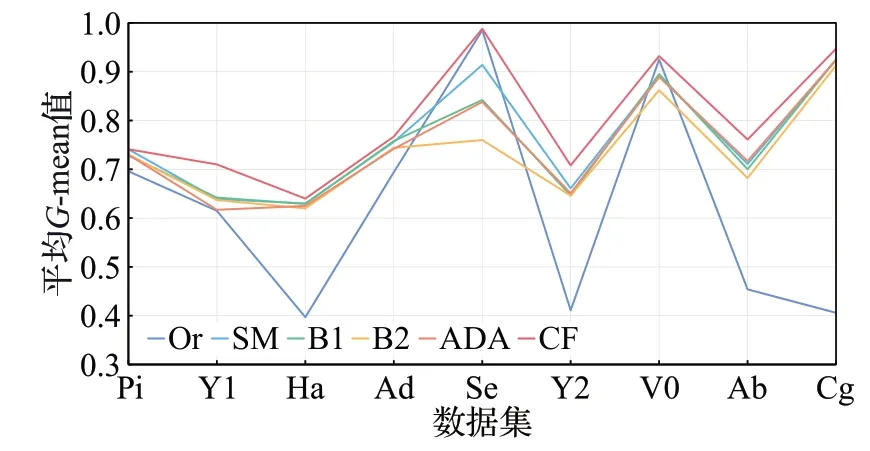
图2 各算法平均G-mean值图Fig.2 Average G-mean value plot of each algorithm
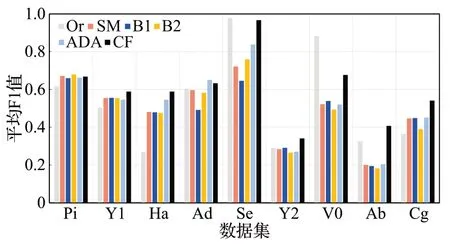
图3 各算法平均F1值图Fig.3 Average F1 value plot of each algorithm
2.4.2 与其他文献中的算法对比
表6 为本文算法与其他文献中所提算法在相同数据集上的分类效果对比,其中,分类器都采用了SVM,且取其他算法的最优评价指标值。可以看出,本文算法在不同数据、不同评价指标下都具有一定的优势,这也验证了本算法的有效性。

表6 基于SVM分类器与其他文献算法对比Table 6 Comparison with other literature algorithms based on SVM classifier
3 结束语
为解决数据不平衡问题,本文提出了一种利用反事实的过采样方法,相比其他传统过采样方法,充分利用了现有实例的特征属性,生成基于真实数据的新样本,更能挖掘原始数据集的有用信息,为了保证反事实合成样本的有效性,对合成样本又进行了边界可信清除。通过结合不同分类器,分别在9组数据集上与经典过采样方法进行了比较,实验结果表明,本方法在AUC、G-mean和F1上都有明显的提升,且具有良好的鲁棒性。
同时,与近年其他文献中所述算法进行了同维度对比,同样表现出了一定的优势,这也进一步验证了本方法的有效性。本文所提方法是针对二分类问题的,如何利用反事实方法在多分类数据不平衡问题中进行有效的过采样,是进一步研究的方向。
