提示学习启发的无监督情感风格迁移研究
2024-03-12蔡国永李安庆
蔡国永,李安庆
1.桂林电子科技大学计算机与信息安全学院,广西 桂林 541004
2.广西可信软件重点实验室,广西 桂林 541004
文本样式迁移(text style transfer,TST)[1]旨在将原始句子改写为新的样式,同时保留其语义内容和流畅性。文本样式迁移应用广泛,如不同人物的对话风格与类属特性[2-3]、文本的书面语体与诗歌体式[4-5]、文本情感极性与友善性[6]等。早期的TST工作主要依赖平行语料库来监督训练序列到序列模型,然而许多现实领域TST缺乏监督训练所需的平行数据。因此无监督式的TST方法得到重视,其框架主要有两类:(1)生成类框架方法,即通过训练基于编码器-解码器的生成模型,直接生成新样式句子[7-14];(2)编辑类框架方法,即将样式理解为句子中特定词语,通过检测、删除、插入、替换等操作来修改源句子以实现句子样式变化[6,15-18]。
生成类框架方法的一种主要做法是将隐藏空间中的内容与样式的潜在表示分离,利用分离后的潜在表示来实现样式迁移[8,10],该类框架方法迁移的准确率较高,但Rao等人[4]的研究表明该类方法在非风格的语义内容保留方面效果通常不好。此外,该类方法还有其他短板,如由于内容和样式的潜在解纠缠表示具有稀疏性,容易生成人类难以理解的句子、无法实现细粒度的控制等。
对比生成类方法,编辑类方法无需从头训练,且支持词级别的细粒度控制。Li 等人[15]提出了“删除-检索-生成”框架,但仍存在三个问题:(1)删除错误;(2)生成错误;(3)流畅度低。随后,Sudhakar等人[18]继续改进该工作,使用注意力权重来识别样式词,通过TF-ⅠDF加权词重叠来完成目标词的检索,最后将样式无关的内容部分和目标词交由解码器来生成新句子,减少了删除错误。
受Sudhakar 等人[19]工作和近来被高度关注的提示学习的启发,在文本的情感迁移任务上,本文针对删除错误和流畅度低等问题做了进一步的研究,并提出了两种新的算法来改进情感样式迁移:(1)提出新的过滤策略改进基于Transformer识别样式词的方法以减少删除错误;(2)借助在无标注语料库上训练的掩码语言模型进行提示学习,利用预训练语言模型自身丰富的知识进行目标样式词推荐以提升流畅度。
1 相关工作
下面主要针对非平行语料情况,文本样式迁移研究的生成类和编辑类方法工作进行介绍。
1.1 生成模型类方法
在该类方法中,一部分工作主张在隐藏空间对内容和样式进行解纠缠,获得内容和样式各自的潜在表示,然后基于内容的潜在表示配合目标样式的表示来完成样式迁移。如文献[7]提出多解码器和样式嵌入两种模型。前者利用编码器和样式分类器来计算内容的潜在表示,然后由指定样式的解码器以实现样式迁移。样式嵌入是将内容表示与目标样式的潜在表示一起送入解码器来生成目标句子。文献[8]利用情感词典获得内容表示,再通过自编码器生成迁移句子。文献[10]假设跨不同文本语料库共享潜在内容分布,提出一种利用潜在表示的交叉对齐来执行样式转换的方法。
有部分研究认为无需显式地分离内容和样式,通过某些技术在隐藏空间中调整句子的潜在表示,最终获得与样式无关的语义内容表示以实现样式迁移。如文献[11]提出了一种双重强化学习框架(DualRL),通过一步映射模型直接迁移文本的样式,而不需要任何内容和样式的分离。文献[12]提出了Style-Trans 模型,它不对源语句的潜在表示进行假设,而在Transformer 中改进注意力机制,实现了更好的内容保持。
还有部分工作不涉及隐藏空间内容与样式解纠缠,而是借助某些技术生成质量不高的伪平行数据集,并用伪平行数据对迁移模型做半监督训练。如文献[13]首先利用风格偏好信息和词嵌入相似性来使用统计机器翻译(SMT)框架生成伪平行数据,然后采用迭代反向翻译方法联合训练两个基于神经机器翻译(NMT)的传输系统。文献[9]提出了一个深度生成模型(DeepLatentSeq),设计了一种概率方法将来自两个域的非平行数据建模为部分观察到的平行语料库。通过在其变分目标与其他无监督风格迁移和机器翻译技术之间建立联系,实现了文本样式迁移。
上述这些方法中无论是否将潜在空间中的内容和样式解纠缠,或从头生成目标句子,均存在稀疏性和收敛性问题[4],因此会生成低质量的句子。
1.2 编辑类方法
编辑类方法的典型是文献[15]使用的“删除-检索-生成”框架。通过删除样式词后得到内容部分,接着检索目标样式词,最后将内容部分和目标样式词交由LSTM生成目标句子。文献[16]提出了一种两步方法:遮挡并填充。在遮挡时通过将样式词的位置遮挡来将样式与内容分开;在填充时将掩码语言模型(masked language model,MLM)改进为属性条件MLM,通过预测以上下文和目标情绪为条件的单词或短语来填充遮挡位置。有一些研究侧重对样式词识别方法的改进。如文献[6]使用标记器在源文本中标记样式短语,然后根据标记的源文本生成目标文本。文献[17]为源域和目标域训练MLM,两个模型将可能性方面最不一致的文本跨度识别为源样式词。文献[18]提出新模型GST(generativestyle-Transformer)。首先对语料训练Transformer模型,通过选出最合适的层和注意力头来计算每个词的注意力分数,将前k个词当作样式词。然后,删去样式词后得到内容部分,联合目标情感标签交由GPT来生成目标句子。
上述这些编辑类方法仍存在一些不足,如(1)检索样式词的准确度有待提高;(2)简单的删除样式词,也可能丢失内容;(3)生成目标句子或对遮挡填空只依赖样式分类器,难以保证句子的流畅性。
为弥补这些不足,本文提出了新的过滤策略来提升对样式词的识别精度。与本文工作最接近的是文献[16]和文献[18],但与文献[16]在语料上训练模型不同,本文方法无需重新训练填空模型,而是基于通用的预训练模型。此外,在对遮挡填空时,与文献[16]单纯依赖目标样式标签和样式分类器不同,本文设计了不同的提示模板来挖掘大模型的知识以提升样式无关内容的保留。对比文献[18]利用Transformer 来计算句子中每个词的重要性分数以识别样式词,但该方法未能考虑部分与样式无关的名词的重要性分数同样很大,只依赖此分数可能导致样式无关的名词被错认为样式词并遮挡,从而产生样式无关的语义内容丢失和迁移失败等错误。本文改进了基于Transformer的注意力来筛选源样式词的方法,同时创新地用提示方法来完成对目标样式词的检索,无需训练序列生成模型,也避免了相关弊端。
2 基于提示学习的文本情感迁移
设在给定数据集D={(x1,s1),(x2,s2),…,(xn,sn)}中xi对应第i个句子,si∈S是xi的样式标记。其中样式由可以准确识别给定句子样式的分类器确定,在情感类迁移任务中样式集S={‘Positive’,‘Negative’} 。定义xs表示样式为s的句子,句子xs随样式s变化而变化。样式s的对立样式为sˉ,则迁移后的目标句子为xsˉ。元标记ms表示遮挡(mask)前句子的样式为s,xms表示句子xs遮挡样式词后的内容部分,随样式s变化而变化。符号p表示与提示(prompt)相关,xp表示句子x对应的提示句子,整体是一个符号。本文提出的针对情感迁移的提示方法如图1所示,它分为三个步骤:(1)样式词识别与遮挡,即识别源句子xs中的样式词并遮挡得到内容部分xms;(2)提示构造,利用语言生成模型获得与源句子语义相近的生成句以构造提示句子xp;(3)目标语句构造,即借助提示信息xp指导掩码语言模型获得与xs样式对立的目标句子xsˉ。以下2.1~2.3 节对以上步骤分别作详细说明。
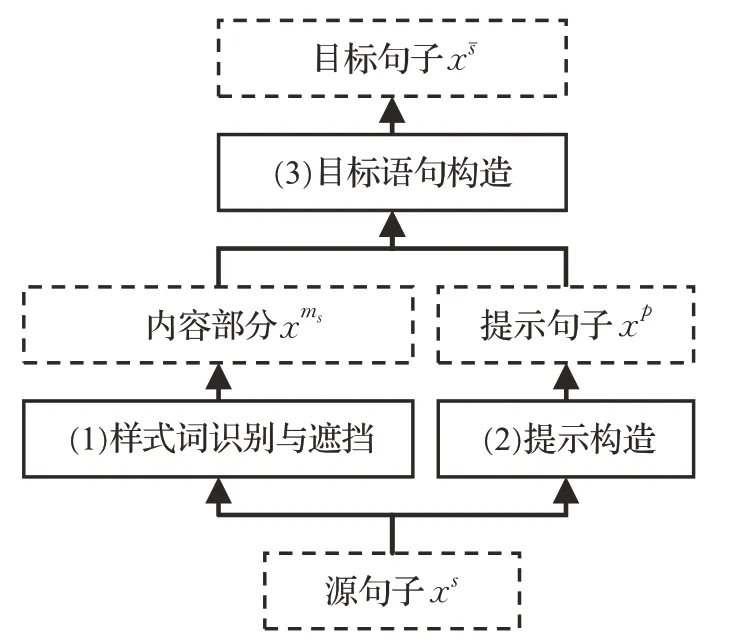
图1 基于提示学习的情感迁移整体框架图Fig.1 Overall framework diagram of emotional transfer based on prompt learning
2.1 样式词识别与遮挡
该步骤分为两个阶段:(1)识别样式词。设源句子xs由词集W={w1,w2,…,wm}构成,通过计算每个词的注意力分数再降序排列得到Wsorted,即PBert(Wsorted|W)。然后取Wsorted的前k个作为句子xs对应的样式词集合as。(2)遮挡。将as中的样式词遮挡得到内容部分xms,如式(1)所示:
第一步识别样式词的这种方法[18]还存在较多误判,本文主要从两个角度改进该方法:(1)过滤情感无关的名词并保留在源句子中;(2)识别情感相关的形容词作为对注意力方法的补充。
具体来说,利用语言处理库coreNLP[20]实现对样式相关的形容词Js和样式无关的名词Nc的识别,即接着先将样式无关的名词过滤,避免注意力分数较高的内容词被遮挡。再从中选取前k个词(topK) ,最后把可能遗漏的形容词补充到topK()方法所得的词集中,其过程如式(2)所示:
算法1 详细描述了改进后的源情感词识别算法。算法中输入Wsorted是情感词的候选列表,它是利用Transformer的注意力结构计算句子W中每个词的重要性分数,然后对所有词按此分数降序排列。词表C和S用于对情感词候选列表Wsorted快速过滤以减少对源情感词误判。词表构造基于语言模型coreNLP(https://stanfordnlp.github.io/CoreNLP/)的词性识别结果,即将源语料中的指示代词、人称代词、系动词、部分介词筛选去重,并记为情感无关的常见词表C,而把数字、特殊符号放入无关符号词表S;k为预设的情感词个数。
算法1执行时前,先备份重要性分数最大的首选词word1,以应对候选情感词列表Wsorted被筛选为空的情形(第1行);然后,调用算法2从源句子中获取与情感无关的名词集合N,对算法2稍作调整即可获取情感相关的形容词、副词集合J(第2~4 行);然后将候选列表Wsorted中和无关情感词集合C、S和N重复的部分过滤(第5~9 行);若候选集合Wsorted变为空集,则将word1作为默认的情感词(第10~12行);否则将从过滤后的候选序列中选出前k个放入情感词集Wstyle,k的大小和候选词的总个数λ相关(第13~17行);接着再使用情感无关的词表C对情感相关的形容词集J过滤,这是因为coreNLP 在识别形容词时可能会将某些系动词误判为形容词(第18~22 行);最后,将与情感相关的形容词和部分表示情感否定的词(如not,no)不加重复地添加到情感词集Wstyle中,即得到过滤后的情感词集合Wstyle。
对于k的设定(第13~17行),由于实际情感词个数可能不止k个,且考虑过滤后的候选词越多,真实的情感词个数也应该越多。因此算法1 采用了两种策略来尽量接近情感词的准确个数:(1)根据候选的情感词数量λ与情感词个数k的统计规律,对不同的候选词数量分段指定情感词数k的大小;(2)在选取k个情感词的操作完成后,再将与情感相关的形容词集合J不重复地并入词序列Wstyle中,以弥补当k远小于真实情感词个数时可能导致的迁移失败。
算法1(源情感词识别算法)
输入:源句子的词序列W按注意力分数降序排列为Wsorted={w1,w2,…,wn},即源情感词候选列表;预定义与情感无关的常见词集合C,预定义与情感无关的符号词集合S;预设的情感词个数k
输出:源句子中的情感词集合Wstyle

算法2 描述了从源句子中识别情感无关名词的过程。在输入部分除了必要的词性识别模型coreNLP 和情感分类器Classifier(https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment)外,还预设了方便识别名词词性的标签集合POSnoun,其中包含有名词单数(NN)、复数(NNS)、专有名词单数(NNP)和专有名词复数(NNPS)。
算法2中,首先将无情感的名词集合Nno-style初始化为空,利用coreNLP 调用词性标注函数pos_tag()获得标注结果(第1、2行);对于每个标注取出被标注词和对应的词性标签,如果当前是名词,根据模板“it is [名词].”和“we get [名词].”构建两个句子,再利用情感分类器Classifier 分别给出情感标签,当两个标签均为中性(0)时,即认为该名词对人与物都是情感无关的,则加入到情感无关的名词集合Nno-style中(第3~18行);最后算法返回集合Nno-style。
识别情感相关的形容词的过程与算法2结构相同,只需作两处改动:一是把词性标签设为形容词(JJ)、比较级(JJR)、最高级(JJS),以及副词(RB)和具有情感属性的感叹词(UH);二是将中性分数判断的语句(第7、8行)改为使用情感标签(积极、消极、中性)来判定,即当构造的句子所得分类标签不是中性,就将当前形容词添加到与情感相关的集合中去。
算法2(识别情感无关的名词算法)
输入:源句子的词序列W={w1,w2,…,wn},情感分类器Classifier,用于计算句子的情感标签,包括中性、积极、消极(0,1,-1);语言处理库coreNLP,以及预设用于识别名词词性的标注集合POSnoun={NN,NNS,NNP,NNPS}
输出:源句子中与情感无关的名词集合Nno-style

算法1识别源句子“The restaurant is a good place and have fun !”情感词并遮挡的结果如表1 所示。从表1 可看出,若简单取Wsorted的前两个词作为情感词,即“good”“restaurant”。此时去遮挡一方面会损失关于餐馆的内容信息,另一方面遗漏了其他情感词,如“fun”。改进后的算法1减少了这些错误。

表1 识别源样式词的一个实例Table 1 Example of identifying source style words
2.2 提示构造
研究中发现使用转折词“but”和源句子作为提示可有效实现对立特性的文本样式迁移。如句子“the food is expensive .”先遮挡其源情感词“expensive”,再用“but”连接原句子作为提示并与遮挡后的句子拼接,即“the food is
构造提示句的过程可分为两个阶段:(1)获得与源情感一致语句。通过借助GPT2(https://huggingface.co/gpt2/)模型,在已知源句子xs的前提下生成下一句与源情感一致的句子xnext。(2)构造提示句。即按模板组合提示信息来得到提示句子xp。以下具体展开。
在第一步中,为确保xnext情感与原句子一致,需在生成下一句前对源句子进行样式增强:先在句首加入一组情感标签同为s的词组as,作为对源句子情感的强化。接着在xs的末尾加入递进词wpro(如“furthermore”),显式地限定下一句情感和xs情感一致,如式(3)所示:
在第二步中,为充分利用不同提示信息,本文针对情感迁移任务设计了构造提示句xp的四种模板,如式(4)~(7)所示,其中winflect代指转折连词。
它们对不同长度句子的迁移效果各有优劣,在一组提示中可包含多个模板构建的句子。对于指定的目标情感短语as可人工给出,如采用只表达情感而无内容的句子“terrible experience !”。直觉上将递进词wpro与目标情感短语asˉ拼接作为提示同样可行,但实际效果不如转折连词构建的提示模板。
2.3 目标语句构造
该步骤分为两个阶段:(1)筛选预测词。先将内容部分xms与提示句xp交由填空掩码模型检索预测词,对样式词筛选后用于构造新句子xsˉ,即(2)检测目标样式。需对新句子做样式检测以确认其样式为目标样式,即。此外,依据样式误判情况可适当调整提示策略。以下在2.3.1和2.3.2小节中对这两步作详细说明。
2.3.1 筛选样式词
提示方法无需微调预训练填空掩码模型,但训练语料自身的偏差(bias)可能导致对积极情感的预测高于对消极的预测,且模型往往更倾向于训练语料里的高频词(如“good”)而不完全依赖提示信息。为应对这些问题,需要对预测词进一步筛选,本文从两个方面改善迁移句子的质量:(1)限制高频词的使用以改善语义内容保留;(2)在目标情感分数的基础上同时考虑了与内容相关的次序权重。算法3描述了筛选目标情感词的具体过程。
算法3(筛选目标情感词算法)
输入:预定义高频词表WHF={good,great,…},预定义无效预测词集合Winvalid={-,_,‘,…};情感分类器Classifier,可计算句子在中性(0)、积极(1)、消极(-1)三个标签上的可能性分数;预训练掩码填空模型FillMask(https://huggingface.co/roberta-large),源句子情感词遮挡后的句子xms,与之对应的提示句子xp,目标情感标签tgtStyle
输出:目标情感最佳预测词集合Wtgt-style,其长度为k,对应待填空的个数
在算法3的输入部分,本文预定义了内容无关的高频情感词集合WHF和无效的预测词集合Winvalid,预训练的填空模型Fill-Mask 以及情感分类器Classifier。预定义词集构造是利用Fill-Mask对抽样遮挡句子提供预测词,将不是由小写英文字符构成的加入无效词集Winvalid,并把前两个预测词加入高频词WHF中。
算法3先初始化目标集合Wtgt-style为空,并以Wtpos=[0.35,0.35,0.55,0.75,0.95]作为与内容相关的候选次序权重列表,这是由于预测词初始越靠前涉及的内容信息越少(如good,great)而越靠后则含有的语义信息越多(如expensive,cheap),因此构造Wtpos时整体采用了等差序列,但假设前两个词语义信息相差不大故取值相同(第1、2 列)。然后利用Fill-Mask 模型获得预测词集合Wcandidate,它由k个长度为五的单词列表构成,其中k为遮挡的个数(第3~4行)。接着依次考察每个遮挡的5个预测词,Scores列表用于记录5个候选词在目标情感和语义内容上的最终分值,初始化为空(第7行)。若单词w无效则用空串覆盖且分数置0(第10~13行)。接着再使用情感分类器Classifier获得单词w的情感标签和在该标签上的得分score。若情感标签与目标情感相反,再借助Fill-Mask模型计算w的情感对立词w-,当w-符合目标情感时就代替原来的预测词,否则用空串覆盖原词且分数置0。然后将分数score 加入Scores 列表(第15~27 行)。接着将分数Scores 和对应的内容权重Wtpos相乘,并把内容无关的高频词分数降低为非高频词中的最小得分,来凸显内容相关的非高频词(第30~36行)。再将得分最大的词加入目标集合Wtgt-style(第38行)。当每个遮挡都获得最佳预测词后,将集合Wtgt-style中重复的词只保留一个以提高语义内容的丰富性(第41行)。最后算法返回目标集合Wtgt-style。
在表2中展示了利用算法3对“The food is
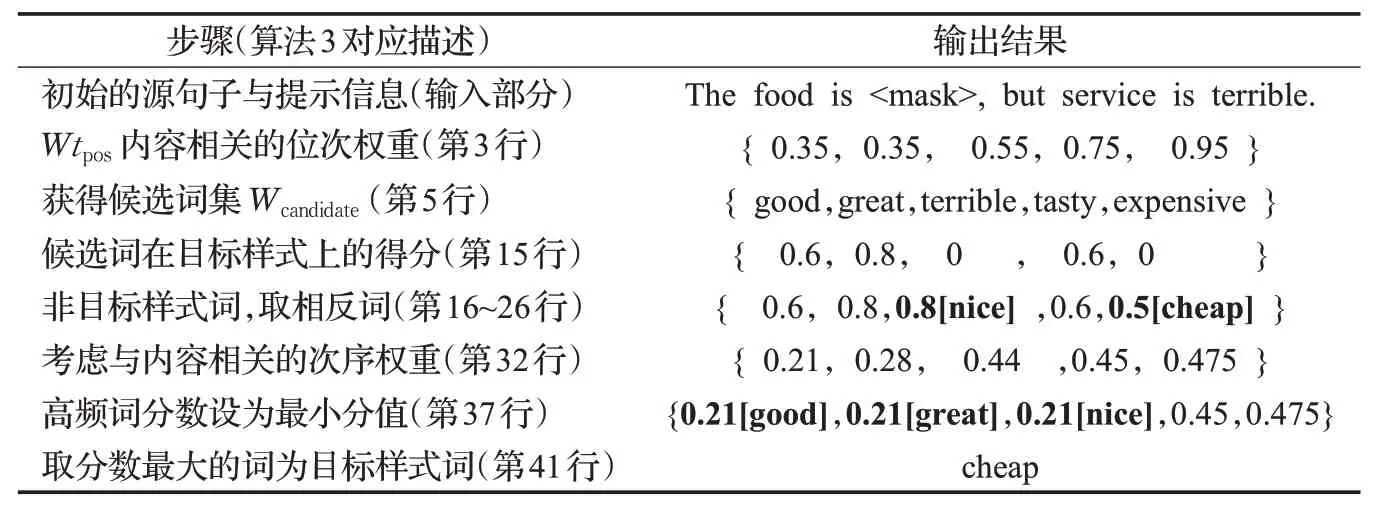
表2 筛选目标样式词的一个实例Table 2 Example of filtering target style words
2.3.2 检测目标样式
从算法3获得符合目标情感的最佳预测词集Wtgt-style后,分两种情况:(1)没有缺词(即不含空串)时,在对应遮挡位置填入预测词,即得到新句子,借助情感分类器检查句子的情感样式,若不是目标情感,则换下一条提示继续检索,否则迁移完成;(2)预测词部分缺少时,将部分有效的预测词填入,再利用遮挡减少后的新句子继续检索。这样相比因为个别缺少就完全舍弃的做法,提升了迁移成功率。若全部缺失则更换下一条提示。
情感分类器本身也可能误把有情感的陈述句判为中性。分析发现有两个原因:一是对消极情感的反讽句进行情感判定涉及外部知识,如评价“某餐厅适合睡觉”暗示了对服务的不满;二是表达积极情感的陈述句由于句子过长但情感词少,故被错误判定为中性。针对第二种情况,本文经统计分析发现,积极的陈述句被情感分类器判定为中性时,在中性标签上的得分远高于其他标签。为此,本文使用有标注的句子来确定阈值α。即从七万条已标注积极情感的句子中抽样500 条被误判为中性的句子,取其中性分数的均值作为初始的阈值α。然后,将标注为中性的100 条句子加入其中。之后,先借助情感分类器计算所有句子的中性分数gneu,采用公式(8)判定情感标签,接着与实际的情感标注比照,即可计算当前α下对积极情感标签的识别准确率。
接着增大初始阈值α直到识别精度达到98%,即接受阈值α从误判为中性句子中筛选真实的积极情感标签的能力。利用阈值α对迁移后句子的情感做判断,针对从消极迁移为积极情况,若迁移后句子的中性分数大于阈值α,即认为该句子表达了积极情感。
3 实验
3.1 数据集
为方便对比已有工作,本文使用Sudhakar等人[18]提供的数据集,包括两个情感迁移的基准数据集,Yelp 评论数据集和AMAZON 亚马逊产品评论集,数据集统计信息如表3所示。
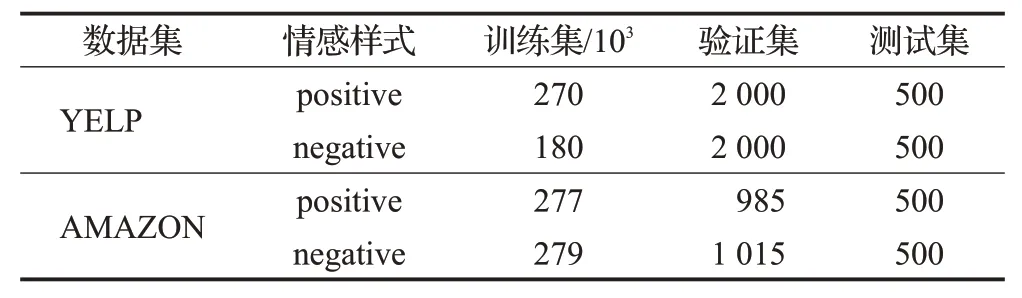
表3 数据集统计信息Table 3 Statistics for dataset
YELP数据集是带有情绪标签(负面或正面)的餐馆和商业评论。AMAZON 数据集是亚马逊上的产品评论,每条评论都标记为正面或负面情绪。
3.2 对比方法
本文将提示方法与三类情感迁移方法进行了对比实验:(1)与经典模型的比较;(2)与领先的编辑模型的比较;(3)与领先的生成模型的比较,以下对模型或方法具体说明。
经典模型包括从隐藏向量角度完成迁移的生成模型,如MultiDecoder[7]和CrossAligned[10]。还有首次在“删除-检索-生成”框架上执行文本迁移任务的编辑模型DeleteOnly 和DeleteRetrieve[19]。其次,领先的编辑模型选择GST[18]作对比,该模型引入transformer注意力来识别样式词。在YELP 和AMAZON 数据集上,本文与以上方法进行了比较。
最后选取领先的生成类模型作对比。DeepLatentSeq[9]利用新的概率生成公式,它结合了过去在无监督文本样式迁移方面的工作。DualRL[11]采用双强化学习方法。Dai 等人[12]提出Style-Trans 转换器,并在Transformer 中为样式匹配了注意力机制。unsuperMT[13]采用无监督机器翻译,即借助伪平行数据和反向迭代翻译方法来完成自动风格转换的任务,GTAE[14]将内在语言约束施加到自然语言的模型空间中,提出了一种基于图变换器的自动编码器。本文在YELP 数据集上与这些方法进行了比较。
3.3 评估标准
与已有工作一样,对生成样本在三个不同维度上进行比较:目标风格强度,样式无关的语义内容保持和流畅性。
为了估计目标风格强度,本文使用针对情感分类的预训练模型RoBERTa-base(https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment)作为风格分类器。该分类器在Yelp、Amazon的测试集上分别达到了98%、89%的准确率(accuracy,Acc)。
为了比较样式无关的语义内容保存,利用sacreBleu[21]计算迁移句子与源句子之间的BLEU 分数[19]。较高的BLEU 分数表明迁移的句子可以通过保留更多来自源句子的单词来实现更好的内容保存,此外还将计算迁移句子和相应参考之间的BLEU分数。两个BLEU分数指标分别称为self-BLEU(s-BLEU)和ref-BLEU(r-BLEU)。
流畅度是通过迁移句子的困惑度(Perplexity,PPL)来衡量的,本文使用KenLM[22]在两个数据集的训练集上训练了一个5-gram语言模型。利用这个语言模型来测量生成句子的困惑度。该模型在Yelp、Amazon的验证集句子上分别实现了平均18、16的困惑度。
此外,Sudhakar等人[18]发现基于学习模型的指标如困惑度和准确性,与人类评估并不完全相关,考察模型的性能不能依赖单个指标。因此,本文对ACC,s-BLEU,r-BLEU和log(PPL)的倒数提供了几何平均数用于衡量整体的表现,即综合指标(global metrics,GM)。
3.4 实验设置
在识别情感词的实验中,在计算注意力之前需先将系动词的缩写还原。利用Sudhakar 等人[18]公开的训练代码,用于计算获得最合适的layer和head,其结果分别是9、0。构造提示所需的下一句xnext时取其长度为15个单词。关于提示的四种模板的比例是1∶2∶4∶3。鉴别中性分数的阈值α=0.85 。在筛选情感词的个数时λ=5,k=3。在筛选目标预测词时,对于最后一个遮挡重复多次给出固定答案,仍未达到阈值的,实验中为避免死循环在三次重复后接受。
4 实验结果分析
实验数据对比分为四部分:(1)与经典模型的比较结果见表4、表6;(2)与领先的编辑模型的比较结果如表5、表6所示;(3)与领先的生成模型的比较结果如表7所示。(4)消融实验的结果如表8 所示。以下对结果进行具体分析。
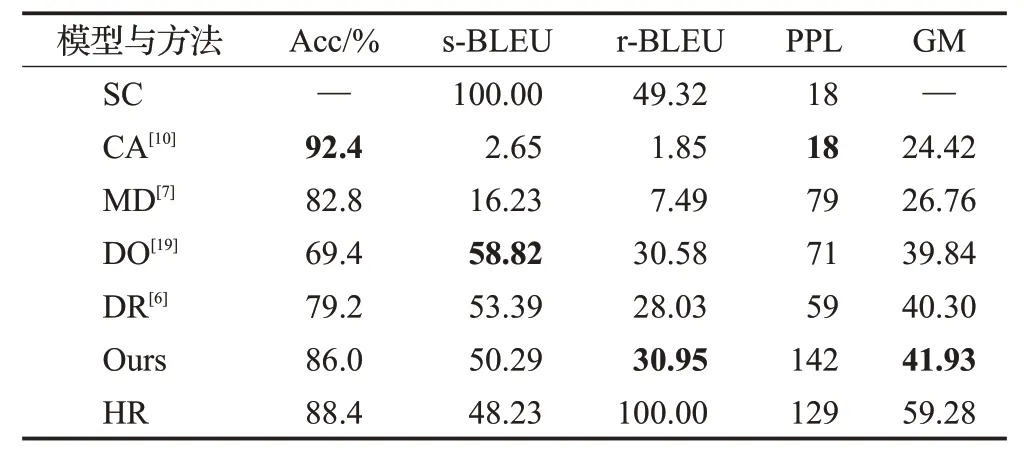
表4 在AMAZON上与经典模型的性能比较Table 4 Performance comparison with classical models on Amazon dataset
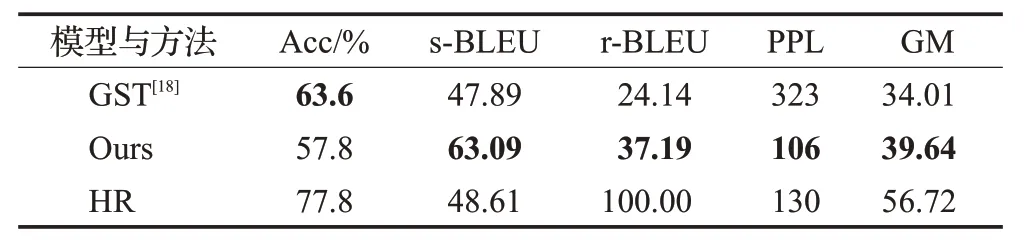
表5 在AMAZON上与领先的编辑模型的比较Table 5 Performance comparison with advanced editing models on Amazon dataset
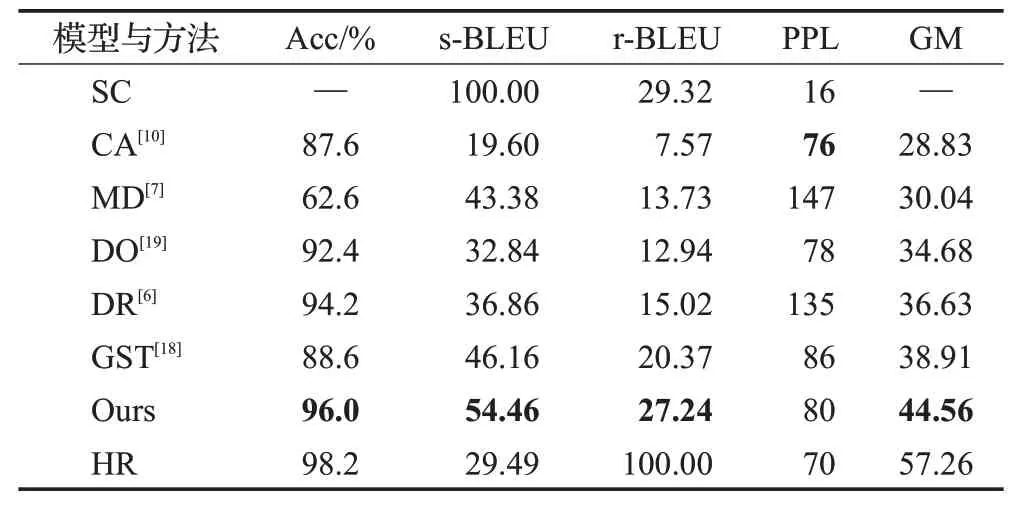
表6 在YELP上与经典模型的性能比较Table 6 Performance comparison with classical models on YELP dataset

表7 在YELP上与领先的生成模型的比较Table 7 Performance comparison with advanced generative models on YELP dataset
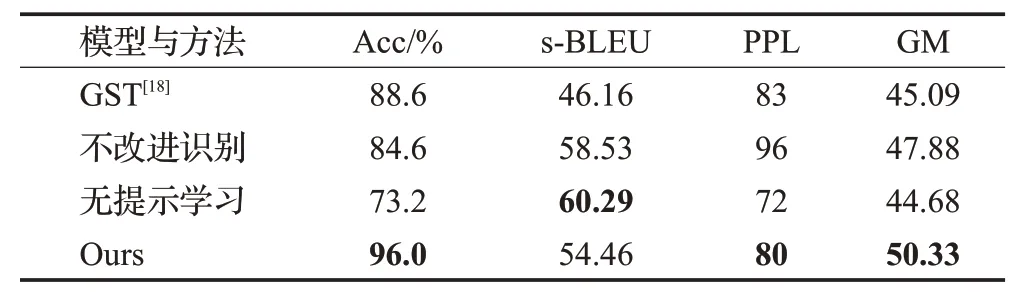
表8 在YELP数据集上的消融实验Table 8 Ablation experiments on YELP dataset
表4展示了在Amazon数据集上提示方法与经典模型对比结果。首行和末行数据分别代表迁移前的源句子(source corpus,SC)和人工迁移的参考结果(human reference,HR)。从表4 倒数第二行和倒数第三行的数据分析可知,对比经典的编辑模型DR,本文提出的提示方法在情感迁移的准确度上提升了6.8 个百分点,综合评分相对提升4%。如表4 第二行和第三行所示,对比经典的生成模型MD 和CA,提示方法的迁移准确率只略低于CA,而在BLEU分数上有压倒性的优势,这是因为通过提升情感词识别的准确率,实现了词级别的细粒度编辑,与情感无关的语义内容被尽可能保留了。
表5给出了在Amazon数据集上提示方法与领先的编辑模型GST 的对比结果。除了在情感迁移准确率上略低外,其他指标则远优于GST 模型,尤其s-BLEU 分数相对提升了32%,这说明本文针对GST只依赖注意力识别情感词的改进是有效的,尤其在对内容保持方面提升明显。对比GST 困惑度指标,提示方法相对降低了67%,这说明和GST 利用GPT 重新生成一组目标词不同,本文利用掩码语言模型检索的方法在流畅度上略有改善。
表6展示了在YELP数据集上提示方法与经典模型的比较。将倒数第二行数据对比表中第二行到第四行可知,提示方法整体优于经典模型,总体指标位列第一。此外,对比倒数第二行和第三行的数据可知,本文的方法在YELP 数据集上的全部指标上均优于编辑模型GST,总体指标提升了14.5%,说明本文提出的过滤策略与提示方法是有效的,提高了准确率的同时,并尽量保留了源句子与情感无关的内容。
在对比表5、表7的PPL指标的数据结果,可以发现困惑度分数在同一组数据中保持了相对一致性,但在不同数据集上波动明显,进一步说明使用整体评分是必要的。观察表7的前两列数据,可以发现随着迁移准确率的下降,s-BLEU分数逐渐升高,即当对源句子词汇保留增多时,生成方法也存在将源样式词错误保留的情况。
观察表7中不同模型两两比较时,在单个指标上表现好的模型,在另一个指标上却可能低于对方。如表7中本文的提示方法与近来最领先的生成模型DualRL比较,提示方法的迁移准确率相对提高了3 个百分点,s-BLEU 相对降低了17%。但通过观察表7 的s-BLEU 指标和GM 指标,可以发现s-BLEU 分数与综合评分并不一致。s-BLEU分数更多体现了迁移句子对源句子中相同词的保存程度,而并不能直接作为与情感无关的内容保留指标。如进一步观察表6的最后一行,在给出的参考中s-BLEU 分数不到三分之一,却实现了98.2%的迁移准确率,这说明只有保证了较高的迁移准确率时,s-BLEU 分数才能正确反映对情感无关内容的保留程度。即当s-BLEU 指标高而迁移准确率低时,说明模型错误保留了源情感词。此外,提示方法无需训练模型,在实际应用上也有一定潜力。
表8第二、三行数据分别展示了去除识别源情感词策略(即算法1),以及不使用提示方法的消融实验结果。本文对情感词的识别基于对GST中Transformer注意力机制的改进,通过比较前两行数据可知,在不做源情感词过滤而只进行提示学习时,对比GST方法情感迁移的准确率下降了4 个百分点,而s-BLEU 分数上提高了26.8%,这说明提示学习在保存与情感无关的内容方面要优于依赖GPT2的生成方法。比较第二行和第四行的数据,当对源情感词不加过滤时,迁移的准确率下降了11.4个百分点,这说明过滤策略有效地提高了情感词识别准度,而BLEU 分数提高了7.5%,这可能是因为缺少过滤策略导致了更多的源情感词被错误保留。比较第三行和第四行的数据,在没有提示的条件下,迁移的准确率下降了22.8个百分点,说明提示方法可以有效指导掩码语言模型实现情感迁移,而BLEU 分数提高了10.7%,可能是因为没有提示信息下,候选词多和源句子部分重复,这也导致了未能正确迁移。
总体来看,本文的提示方法整体优于经典的方法。和现有领先的编辑方法,提示方法实现了更好的迁移准确率和情感无关的内容保留。即使与最领先的生成模型相比,提示方法也在整体性能上具有竞争力。
此外考虑到不同转折词对预测的影响,实验选取了18个带有转折含义的词,并在相同提示信息的条件下对同一组句子做情感迁移。主要考虑了候选词中正确预测样式所占的比例、首选命中的比例,以及与内容相关词在正确词中所占的比例。图2 中展示了排在前五的结果。实验表明,不同转折词对内容和样式转移方向的影响差异较大,如“by contrast”在内容相关词比重上相对于“but”提高了16个百分点以上。说明提示学习对个别词的改变波动比较明显。此外,实验中发现当句子中本身存在转折逻辑时提示的效果差,这可能是因为当前转折词和句子本身的逻辑发生冲突造成的。

图2 不同转折词对预测效果的影响Fig.2 Effect of inflection words on predictive performance
如图3所示,平均样式词个数随着句子变长而缓慢增长,普遍以两个样式词为主。注意到,经过对样式无关词的过滤,实际候选词个数一方面在句子长度增大时仍保持较小的涨幅,另一方面和平均样式词个数的增长速度保持一致。说明该策略有效减少了样式无关词对识别的干扰。从图中可推断topK策略的参数设定,当候选词个数超过5 时,平均样式词个数明显上升,故λ=5 作为阈值比较合理。即候选词少于5 个时默认k取前两个,否则应取k=3。
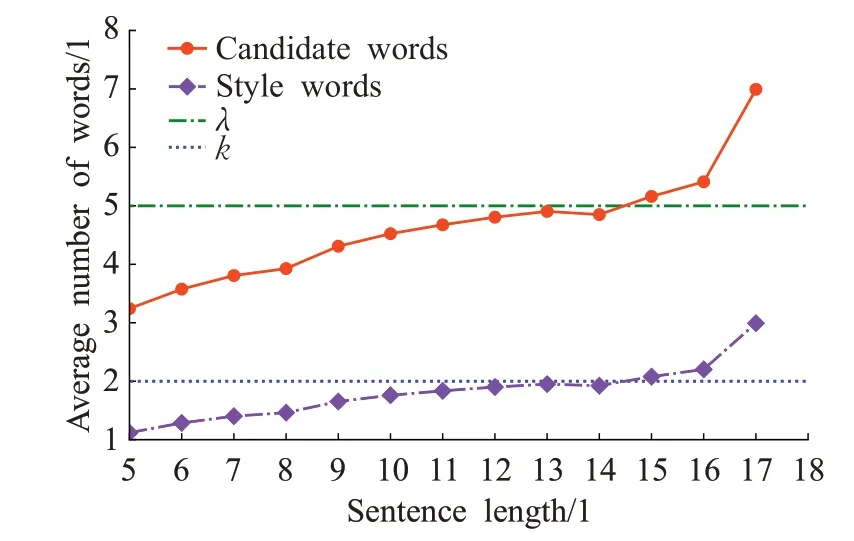
图3 句子长度对筛选目标词的影响Fig.3 Effect of sentence length on filtering target words
5 结语
本文提出了针对文本情感迁移的提示方法,对比已有的编辑方法,无需针对特定领域训练生成模型,而是直接采用预训练的填空模型。除改进对源样式词的识别精度外,为了充分挖掘大模型对于样式迁移的相关知识,本文引入了有效的提示方法,并设计了对目标候选词的筛选策略。
实验表明,提示方法在情感迁移方面优于现有编辑方法,并对最新的生成模型方法有相当的竞争力。此外,提示的数据由GPT2生成,可轻易获得大量与内容相关的提示。在未来的工作中,将研究提示方法在生成伪平行数据方向的应用。
