联合多意图识别与语义槽填充的双向交互模型
2024-03-12孙镇鹏
李 实,孙镇鹏
东北林业大学信息与计算机工程学院,哈尔滨 150040
目前现实生活中的人机交互方式主要以人机对话为主,如苹果Siri、谷歌Home等。人机对话中的口语理解(spoken language understanding,SLU)是整个对话系统中的关键组成部分,其准确性将直接影响着对话系统的性能。
意图识别(intent detection)和语义槽填充(slot filling)是口语理解中的两个主要任务[1]。意图识别的目的是根据用户输入的话语推断出话语中对应的意图[1],根据用户的意图将话语划分为先前定义的意图类别,可以看作预测意图标签的分类任务。意图是用户的意愿,包含用户在对话中表达的行为信息,一般由“动词+名词”组成。
语义槽填充旨在为用户输入话语的每个单词识别并标注特定领域关键词的属性值,属于序列标记任务[2]。语义槽填充的属性标注方法采用BⅠO(beginning,inside,outside)标注策略,其中“B”表示属于同一种槽类型短语的开始单词,“Ⅰ”表示属于同一种槽类型短语的后续单词,“O”标记无关词汇。这两个任务的目的是将用户所输入的话语转化为计算机能够理解的形式并形成如表1所示的语义框架[3]。由于这两个任务有密切的联系,考虑意图和语义槽之间的关系能共同提升两个任务的性能,例如在表1 的语句中,如果识别出用户的意图是播放音乐,那么“最长的电影”的语义槽标签就会被预测为“B-音乐名”而不是电影名。因此现在主流的口语理解系统中采用联合模型来建模两个任务的相关性。
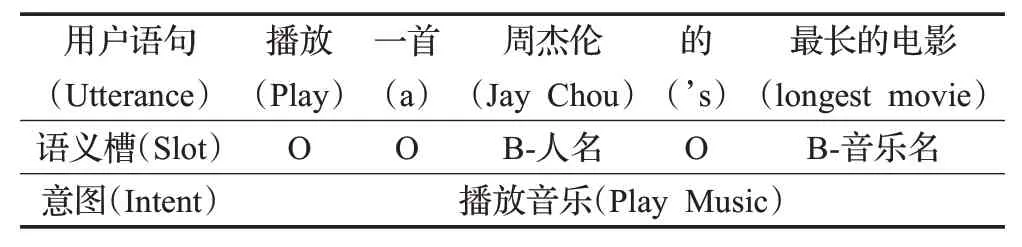
表1 口语理解语义框架Table 1 Spoken language comprehension semantic framework
在现实生活中,用户通常在一句话语中表达多个意图。Gangadharaiah 等人[4]在亚马逊数据集中发现用户的话语表达往往不只有一个意图,其中52%的示例含有多个意图,所以口语理解中多意图识别(Multi-Ⅰntent Detection)的研究越发重要。然而,现有的多意图识别联合建模的研究较少,大部分模型只能对单一意图进行识别,无法同时理解用户语句中的多个意图,或未能充分利用多个意图信息与语义槽之间的关联关系。
目前多意图识别存在的问题大致有:(1)数据来源匮乏[1]。在实际的意图识别的研究过程中,带标注的文本较少,获取也十分困难,给多意图识别的研究和发展带来了阻碍。(2)用户表达的不规范性。用户的对话文本一般具有表达口语化、指代关系多、内容省略等特点,这就加大了意图识别的难度。(3)意图的隐含性。隐式意图指用户没有明确自己的意图需求,需要通过分析用户的潜在意图来推理用户的真实意图[2],这也给多意图识别的研究带来了挑战。因此如何对针对口语短文本进行多个意图的识别并与语意槽填充任务进行联合训练是一个难点。
针对上述问题,本文提出了引入标签信息的意图-语义槽双向交互的图注意力网络模型(label attention bidirectional interaction model,Label Bi-Ⅰnteraction)来建立两个任务的双向关联,自适应的学习多个意图与语义槽之间的关系,使得模型可以整合话语中的多个意图信息引导相关的语义槽填充,利用语义槽信息促进意图更好地识别,弥补现有联合模型中两个任务关联信息未能充分利用的不足,增强两个任务的交互性。同时考虑到多标签分类任务(multi-label,ML)与多意图识别任务的相似性,借鉴多标签分类任务中引入标签信息的方法[5]将意图和语义槽标签的信息和语句上下文隐藏状态进行融合,建立标签与话语上下文之间的关系,从而提高了意图识别与语义槽填充的准确率,使模型更好地识别用户话语中的多个意图。
1 相关工作
传统口语理解任务的管道方法(pipeline method)独立建模意图识别和语意槽填充两个任务。意图识别可以看作预测意图标签的分类任务,挖掘用户在语句中表达的意图,许多句子分类方法被用于意图识别[2]。传统的机器学习模型有朴素贝叶斯模型(naive Bayesian model,NBM)[6]、支持向量机(support vector machines,SVM)[7]、Adaboost[8]等。神经网络兴起后,一些基于深度学习模型的研究也取得了不俗的效果,主要的有卷积神经网络(convolutional neural network,CNN)以及循环神经网络(recurrent neural network,RNN)及其变体。Xu 和Sarikaya[9]利用CNN[10]提取5-gram 特征并应用最大池化获得单词表示;Ravuri 和Stolcke[11]成功地将RNN 和长短期记忆网络(long short-term memory,LSTM)[12]应用于意图识别任务,这表明序列特征有利于意图识别任务;Xia等人[13]采用基于胶囊[14]的神经网络[15]对意图识别分类进行研究。
语义槽填充可以看作序列标记任务,旨在得到用户话语中的语义槽和其对应的值[2]。序列标注领域中常用的机器学习模型有隐马尔科夫(hidden markov model,HMM)[16]、最大熵马尔科夫(maximum entropy Markov model,MEMM)[17]、条件随机场(conditional random fields,CRF)[18]等。深度学习中常用的长短期记忆网络(LSTM)[19]和门控制循环单元(gate recurrent unit,GRU)[20]模型也取得了不错的效果。例如,Yao等人[21]采用RNN语言模型RNN-LMs 来预测语义槽标签,随后又提出了一种用于槽填充任务的LSTM 框架[22];Mesnil 等人[23]研究了几种RNN 架构,包括Elman RNN、Jordan RNN 及其用于SLU 的版本;Liu 和Lane[24]提出使用采样方法对插槽标签依赖关系进行建模,通过将采样的输出标签(真实或预测)反馈给序列状态;Kurata等人[25]利用来自编码器的句子级信息来提高语义槽填充任务的性能。目前学术界的主流做法是将神经网络自动提取特征与机器学习计算联合概率相结合,如Bi-LSTM+CRF 的模型等[26-29]。
由于意图识别和语意槽填充两个任务有密切的联系,单意图口语理解系统中采用联合模型来建模两个任务的相关性以提升口语理解任务的准确率。为此,Zhang 等人[30]基于多任务学习框架提出了一个联合模型;Liu 等人[31]提出了一个基于注意力的RNN 模型,应用了一个联合损失函数来隐式地连接两个任务;Hakkani-Tür 等人[29]引入了一个RNN-LSTM 模型。但上述研究没有建立意图和语义槽之间的显式关系,他们只是通过共享参数来模拟意图和语义槽之间的关系。随后Goo等人[32]提出了一种语义槽门控模型,该模型将意图信息显式地应用于语义槽填充任务并取得了优异的性能;Qin 等人[33]提出了一种新的堆栈传播框架来执行Token级的意图识别并指导语义槽填充。上述模型都取得了很好的性能,但以前的大多数工作只关注简单的单一意图场景,他们的模型是基于每一个话语只有一个意图的假设进行训练。
随着研究的深入发现,用户通常在一句话语中表达多个意图。针对多意图识别任务,Xu 等人[34]采用对数线性模型并利用不同意图组合之间的共享意图信息进行多意图识别,但是针对大量的意图组合则会出现数据稀疏问题;Kim等人[35]提出一种基于单意图标记训练数据的多意图识别系统,他将句子看作三种类型,单意图语句、带连词的多意图语句和不带连词的多意图语句,然后采用两阶段法,但限定只能识别两种意图;Yang等人[36]将用户意图文本进行依存句法分析确定是否包含多种意图,利用词频-逆文档频率(term frequency-inverse document frequency,TF-ⅠDF)和训练好的词向量计算矩阵距离确定意图的数量,将句法特征和卷积神经网络(CNN)结合进行意图分类,最终判别用户的多种意图,该方法在多种类别的多意图识别任务中取得不错的效果,但是依赖于句法结构特征;Liu等人[37]采用胶囊网络(capsule network)构造基于单意图标记的多意图分类器对用户表达的多种意图进行识别。但上述工作主要研究如何识别多个意图,没有考虑多个意图和语义槽的关系进行联合建模。
多意图口语理解的联合建模与之前单意图的口语理解模型利用话语中单一意图来指导槽填充的方法[32-33]不同,多意图口语理解面临一个独特的挑战,即如何有效地结合多个意图信息来引导槽预测。Gangadharaiah等人[4]首先探索了具有语义槽门控机制的多任务框架;Wang等人[38]提出了一种双向模型考虑意图与语义槽的交叉影响;文献[39]提出了一种SF-ⅠD网络,为意图识别和语义槽填充建立直接连接,使两者相互促进。他们的模型通过简单地将意图上下文向量视为多个意图信息来合并意图信息,虽然这是合并多个意图信息的直接方法,但每个槽位都由相同的意图信息引导,没有为槽填充提供细粒度的意图信息集合。针对上述问题,Qin等人[40]提出了一种自适应交互网络,以实现多意图信息对槽填充进行Token级的细粒度引导,随后又进一步提出了一种用于联合多意图检测和语义槽填充的非自回归框架[41],其中局部槽位感知图交互层每个语义槽隐藏状态彼此连接,以明确地建模语义槽位依赖性,以缓解由于非自回归方式导致的不协调语义槽问题并引入全局意图-语义槽图交互层来执行句子级意图和语义槽交互。但上述模型在多意图识别任务中没有利用语义槽的信息,直接的双向连接仍未建立,实际上意图信息和语义槽信息之间具有高度相关性,可以相互促进。
2 方法
为了增强意图识别和语义槽填充两个任务的相互关联性,本文提出了引入标签信息的意图与语义槽双向交互模型,模型框架如图1 所示,该模型由一个共享的编码器(2.1节)、意图和语义槽的标签信息注意力层(2.2节)、意图-语义槽双向交互的图注意力层(2.3节),以及用于意图识别和语义槽填充的解码器(2.4节)组成。
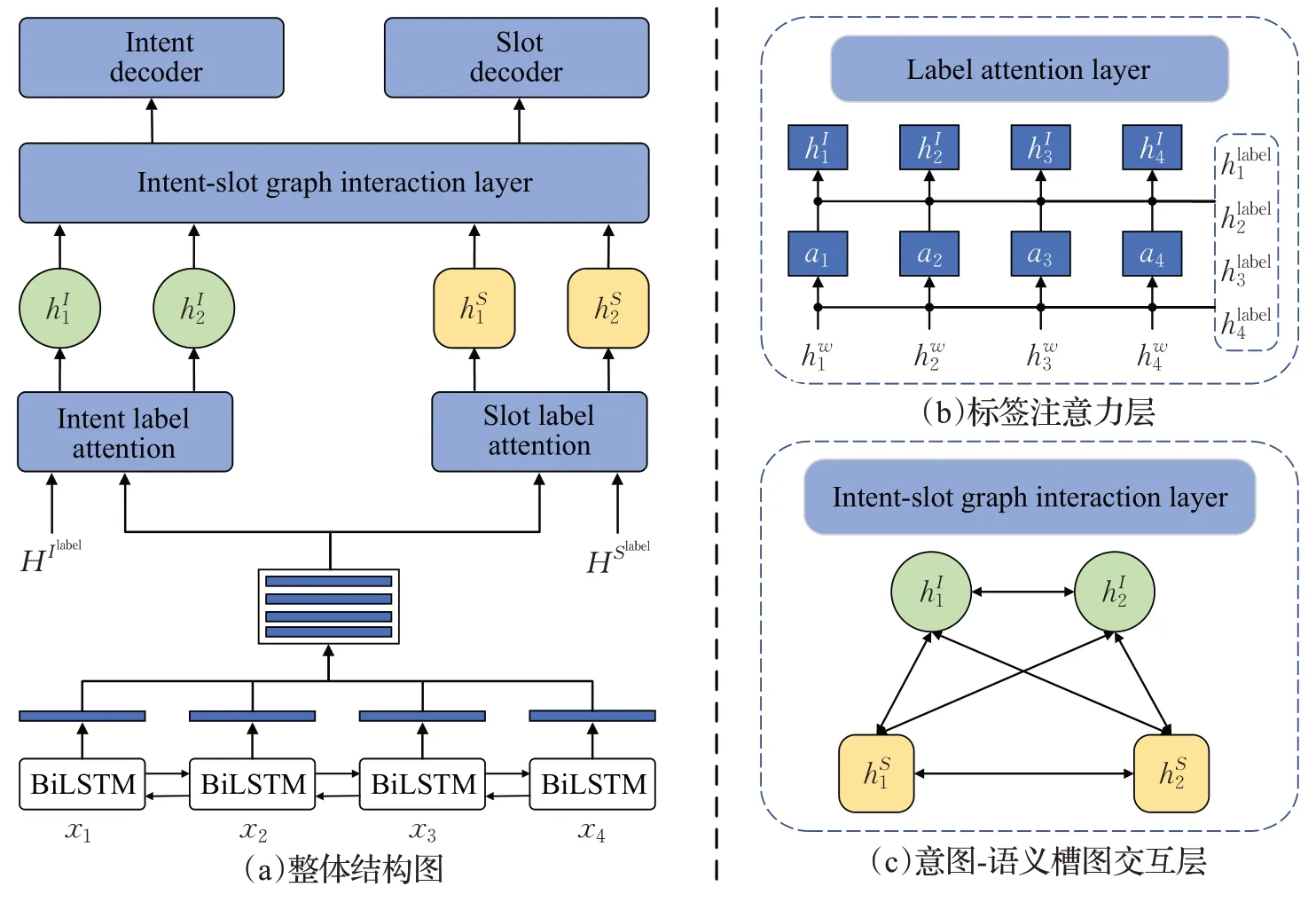
图1 模型总体框架Fig.1 General framework of model
2.1 共享编码层
模型采用BiLSTM 对输入序列X={x1,x2,…,xn}进行话语的时序和上下文信息建模,经过BiLSTM编码话语可以结合时序特征和上下文信息。第一层LSTM前向从x1到xn读取话语,第二层LSTM 后向从xn到x1读取话语,通过反复应用得到含有整个话语的时序特征和上下文信息的隐藏状态其中n是token的数量,φemb表示嵌入函数。同理将意图标签Ilabel和语义槽标签Slabel输入BiLSTM 编码器得到意图和语义槽标签的隐藏状态HIlabel和HSlabel。
2.2 意图和语义槽标签注意力层
多意图话语可能由一个或多个意图标签标记,并且话语中的每个单词对每个标签的贡献度不同。因此,为了得到与标签相关的单词文本表示,本文设计了标签注意力机制(label attention layer)将意图和语义槽的标签信息与话语输入的上下文信息进行融合,使模型除了学习到话语的上下文信息外,还能学习到上下文与标签之间的关系,具体方式如图1(b)所示。
共享编码层得到的Hw作为Query矩阵,Hvlab(elv∈{IorS},I代表意图,S代表语义槽)作为Key 和Value矩阵,经过注意力层交互后得到A={a1,a2,…,an} 后,与上下文隐藏层状态Hw进行拼接得到包含标签关系的意图表示和语义槽表示HS=一起送入意图-语义槽图交互层建立双向交互。
2.3 意图-语义槽图交互层
本文提出的意图-语义槽图交互层采用图注意网络(graph attention network,GAT)[42]建立意图和语义槽信息之间的双向交互,使模型自适应地将多个意图信息与语义槽双向关联,使用多个意图信息来引导语义槽位的填充,同时也利用语义槽值的信息来帮助多个意图的识别。因为图注意力网络可以融合模型中的图结构信息和节点特征,GAT的掩码自注意力(masked self-attention)层能促使节点关注相邻节点的特征并学习不同的注意力权重,可以自动获取当前节点与其邻接节点之间的重要性和相关性。
对于具有N个节点的给定图,单层GAT 获取初始节点特征作为输入,旨在生成更多抽象的表示作为其输出。GAT的注意力机制可以总结为:
其中,Ni是图中节点i(包括i)的一阶邻居节点,Wh∈RF′×F和a∈R2F′是可训练的权重矩阵,αij是归一化注意力权重,表示每个h͂j对h͂i的重要性,σ代表非线性激活函数。GAT通过mask attention将图结构注入机制,即GAT只计算节点j∈Ni的f(h͂i,h͂j)。为了使自注意力的学习过程更加稳定,将上述机制扩展为采用Vaswani 等人[43]的多头注意力:
其中,是由第k个函数fk计算的归一化注意力权重,||是连接操作,K是注意力机制的数量。因此,输出将由中间层的K×F′特征组成,最后的预测层将采用平均法得到最终的预测结果。
本文通过构建意图-语义槽的双向交互层以实现句子层面的意图和token 级语义槽的互动,所有预测的多个意图和语义槽都被连接起来,连接类型如图1(c)所示,图G的具体构建方式如下:
节点:对意图和语义槽位之间的进行token 级交互建模,在图中模型有n+m个节点,其中n是序列长度,m是意图标签的数量。语义槽token 特征的输入为,输入的意图特征为,其中是一个可训练的嵌入矩阵。语义槽和意图节点的第一层状态向量是
图G边的构建有三种类型的连接:
意图-意图连接。仿照Qin[40]的做法,将所有的意图节点相互连接起来,以模拟每个意图之间的关系,因为它们都表达了同一个语句的意图。
语义槽-语义槽连接。构建了语义槽位之间的连接,每个槽节点都连接到其前后的槽节点,以进一步建模语义槽的相关性,纳入双向的上下文信息。
意图-语义槽连接。由于意图和语义槽高度相关,构建了意图-语义槽位连接来模拟这两个任务之间的交互。其中,每个语义槽连接所有预测的多个意图,以自动捕捉相关的意图信息。
GAT信息聚合层的聚合过程可以表述为:
其中,GS和GI是顶点集,分别表示连接的语义槽和意图。促使每个token捕获相应的相关意图信息。采用图注意网络来模拟意图和语义槽在标记层面的交互。表示第l层图中的节点i,该图由t时间步长的解码器状态节点和意图节点组成。是第l层中的隐藏状态表示。为了更好地利用多个意图信息,语义槽位隐藏状态节点直接与所有意图节点相连,第l层中的节点表示的计算为:
其中,Ni代表节点i的一阶邻居,所有节点表征的更新过程可由公式(3)~(8)计算。通过L层自适应意图-语义槽的图交互,得到了t时间步长的最终的隐状态表示,它可以自适应地捕获token级的重要意图信息。用于意图识别和语义槽的预测。
2.4 意图识别和语义槽解码器
语义槽填充任务的计算公式为:
其中,为话语中第t个单词预测的语义槽标签。
意图识别任务的计算公式为:
其中,Wi、Wc是可训练的参数矩阵,σ代表sigmoid 激活函数,是话语的意图输出,n是单个意图标签的数量。因为本文是多意图识别任务,最终的多个意图I={I1,I2,…,Im} 由预测值大于阈值tI的意图构成,其中0 <tI<1.0。
本文采用联合训练来优化更新意图识别和语义槽填充两个任务的参数,联合训练的公式为:
其中,、分别为意图和语义槽的真实标签,NI是单个意图标签的数量,NS是语义槽标签的数量,n是话语中的单词数,最终的联合损失公式为:
其中,α是超参数,通过联合损失函数可以对两个任务联合优化,进一步减少误差。
3 实验
3.1 数据集
本文在Qin 等人[40]提供的多意图数据集MixSNⅠPS和MixATⅠS上进行了实验。MixSNⅠPS数据集由SNⅠPS数据集构建,其中数据来自Snips 个人语音助手,使用and 等连词连接具有不同意图的句子,最后得到用于训练的45 000个话语,验证的2 500个话语和测试的2 500个话语。类似地,从ATⅠS 数据集构建另一个多意图数据集MixATⅠS,ATⅠS数据集由预订航班用户的音频记录组成,得到用于训练的18 000个话语,验证的1 000个话语和测试的1 000 个话语。在这两个数据集中,包含1、2、3个意图的话语的比率为[0.3,0.5,0.2],数据集划分情况详见表2。

表2 用户话语划分情况Table 2 User utterances division
3.2 实验参数
实验采用Adam(adaptive moment estimation)来优化本文模型中的参数,实验设置的超参数如表3所示。

表3 模型超参数Table 3 Model hyperparameters
表中,batch size 为单次迭代训练批处理样本的个数,L2 regularization 为L2 正则化参数,learning rate 为模型学习率,dropout rate 为参数丢弃率,GAT layers number 为图交互层数,self-attentive hidden units 为自注意力隐藏层单元数,LSTM hidden units 为Bi-LSTM隐藏层单元数,α为联合损失函数中的超参数,tI为判别多个意图的阈值。MixSNⅠPS 的epoch 周期为100,MixATⅠS 的epoch 周期为200。对于所有实验,选择在验证集上效果最好的模型,然后在测试集上对其进行评估,实验均在Tesla V100上进行。
3.3 实验结果对比
本文与以往的意图识别和语义槽填充联合模型进行了比较。为了使单意图SLU 基线可以处理多意图话语,遵循Joint Multiple ⅠD-SF[4]中的方法将它们识别的单个多意图标签用#连接起来,以获得以进行公平比较,将更改后的模型命名为串联版本。(1)Attention BiRNN[31]:提出了一种基于对齐的RNN和注意力机制,它隐式地学习了意图和语义槽之间的关系。(2)Slot-Gated Atten[32]:提出了一个槽门联合模型来明确考虑槽填充和意图检测之间的相关性。(3)Bi-Model[38]:提出了Bi-Model 来考虑意图检测和槽填充之间的交叉影响。(4)SF-ⅠD Network[39]:提出了一个SF-ⅠD Network模型,为槽填充和意图识别建立直接连接,以帮助它们相互促进。(5)Stack-Propagation[33]:提出了Stack-Propagation 的联合模型来捕获意图语义知识并进行Token 级的意图识别以进一步缓解错误传播。(6)Joint Multiple ⅠD-SF[4]:采用了一种多任务框架,该框架具有用于多意图识别和槽填充的Slot-gated 机制。(7)AGⅠF[40]:提出了一种用于联合多意图识别和语义槽填充的自适应Graph-Ⅰnteractive框架,该框架提取了用于Token 级槽填充的意图信息。(8)GL-GⅠN[41]:提出了联合多意图识别和语义槽填充的非自回归方法,加快了模型的解码时间,并使用语义槽的局部交互图处理非自回归方法带来的不协调的语义槽问题。
本文使用F1分数评估语义槽填充的性能,使用准确度评估意图识别的性能,使用总体准确度评估话语级语义框架解析的性能,总体准确度代表句子中意图和语义槽都被正确预测的句子的比例。实验结果如表4 所示:与GL-GⅠN 相比,本文模型在MixATⅠS 和MixSNⅠPS数据集上,语义槽填充的F1 值分别提高了1.3、0.7 个百分点,意图识别准确率分别增长了2.4、0.7个百分点,语句级的总准确率分别实现了1.6、1.0 个百分点的提升。这表明提出的融合标签信息的意图-语义槽交互图可以更好地捕捉意图和语义槽之间的相关性,使两个任务可以相互促进,从而提高SLU性能。

表4 实验结果对比Table 4 Experimental results comparison
此外,本文还对比了模型的时间性能,根据表4 可以看到本文模型在性能提升的同时并没有花费更多的时间成本。时间复杂度列中,H表示隐藏层的特征维度,F表示原始的特征维度,F′表示输出的特征维度,m表示SF-ⅠD网络[39]迭代次数,n表示GAT层数,|V|代表图中的顶点数,|E|代表图中的边数。如表4所示,尽管本文模型在两个数据集上都取得了性能的提升,但两个数据集上的准确度和F1 值差异较大,MixSNⅠPS 数据集上的结果明显高于MixATⅠS 数据集,主要原因有以下两方面:(1)MixATⅠS数据集中的话语属于同一领域且意图类型的划分更细粒度化,意图之间的相似程度较高,这就导致模型在识别意图时更难判断意图的数量及预测意图标签。而MixSNⅠPS数据集语料跨多领域,意图的相似程度相对较低,模型更容易区分并识别多个意图,因此在MixSNⅠPS 上多意图识别任务的准确度更高。(2)MixSNⅠPS数据集的语义槽标签比MixATⅠS 数据集少且话语样本数量远大于MixATⅠS数据集,这样模型在语义槽填充任务中能更好地学习到语义槽值的相关信息,因此在MixSNⅠPS 上语义槽填充任务的F1值更高。总体准确度评价指标由多意图识别和语义槽填充两个任务的预测结果的计算得出,因此同样受上述两个原因的影响,在两个数据集上呈现出性能的差异。
3.4 实验结果讨论
意图识别与语义槽填充任务是紧密关联的,两个任务的信息进行双向交互可以相互促进。如图2所示,模型成功预测出话语意图为“BookTicket”和“GetWeather”时,可以引导语义槽识别Beijing 作为目的地城市或是查询天气的城市的槽值进行填充。同理,Harbin的槽值既可能是出发地也有可能是目的地,当模型正确识别Harbin的槽值为出发地可以消除歧义,一定程度上也能帮助意图的预测。下面通过消融实验分析三个部分的对模型的影响,消融实验结果详见表5。

图2 意图与语义槽关联性示例Fig.2 Ⅰntent and semantic slot association

表5 消融实验Table 5 Ablation experiments单位:%
3.4.1 标签信息的影响
如表5 所示,本文首先去掉模型的标签注意力层,命名为without label attention layer,将Bi-LSTM 层得到的上下文语义信息直接输入到图注意力网络交互层。这表示模型只能从用户输入的语句得到语义信息,不能学习到意图和语义槽标签与上下文之间的关系。通过实验结果可以观察到语义槽填充和意图识别的性能均出现下降,这表明本文提出的学习意图和语义槽标签与话语上下文之间的关系对两项任务有正向的影响。
3.4.2 意图-语义槽双向交互的影响
为探究意图和语义槽信息之间的双向交互对实验结果的影响,实验分为两部分进行。首先删除意图到语义槽之间的信息流,将其命名为without intent to slot,只保留语义槽到意图之间的信息流以模拟意图和语义槽之间没有进行双向交互的情况。从表5 的实验结果来看,意图识别的准确率出现小幅下降而语义槽填充的F1值有明显下降。
类似的,再删除语义槽到意图的信息流,将其命名为without slot to intent,可以看到此时语义槽填充的F1 值小幅下降,意图识别的准确率明显下降。这表示本文模型建立的双向交互机制能够使这两项任务相互增强,且对于两项任务的性能同时有正向的影响。
3.4.3 不同意图数量的对比试验
本文分别设置了意图数量为1~3 时的对比实验以探究模型在不同意图数量下的效果。如表6所示,实验结果表明,随着意图数量的增多,模型效果逐渐降低。在只有1个意图时,模型不需要判断意图的数量且只需预测1个意图标签,多意图识别任务与传统的单意图识别任务相似,因此三项评价指标均为最高。意图数量为2时最接近包含所有意图的主实验结果,因为数据集中2 个意图的话语数量占比最多,并且难度较识别3 个意图低。意图数量为3时,可以观察到除语义槽填充的F1值外的两项指标出现了显著降低,这是因为意图数量增多加大了判断意图数量和预测意图标签的难度,同时数据集中3个意图的话语样本占比较低,模型在训练时学习到的信息较少,所以意图识别和总体准确度明显下降。而语义槽填充任务为话语中单词的序列标注任务,话语意图的数量对其影响较小,因此语义槽填充的F1值下降幅度较小。

表6 意图数量的对比实验Table 6 Comparative experiments on number of intents单位:%
4 结束语
本文的模型首先引入了意图和语义槽的标签信息,将两个任务的标签信息与上下文信息进行融合,同时构建了一种意图-语义槽双向交互的图注意力网络,使模型既可以利用多个意图信息来引导语义槽的填充,也可以利用语义槽值的信息来帮助意图的识别,从而提高意图识别与语义槽填充的准确率,能够更好地识别用户话语中的多个意图。实验结果表明,模型在两个多意图数据集上的达到了最好的效果。
虽然本文的研究在多意图识别与语义槽填充任务联合建模上取得了一定的进展,但是在多意图识别任务上还有许多值得探究的地方:(1)本文主要基于已有的单意图数据集整理的多意图测试集进行研究,因此对于多意图数据样本稀缺的问题,后续考虑采用零样本学习实现多意图识别任务。(2)在意图和语义槽识别任务中,由于用户话语可能会有语义歧义、代词省略等歧义现象,因此针对用户口语的不确定性如何利用结合事实性知识进行逻辑推理,或将领域知识和事实性知识图谱加入模型以消除歧义、指代等问题以提升整个对话系统的鲁棒性是下一步的探索方向。
