文档级事件抽取反向推理模型
2024-03-12纪婉婷马宇航鲁闻一王俊陆宋宝燕
纪婉婷,马宇航,鲁闻一,王俊陆,宋宝燕
辽宁大学信息学院,沈阳 110036
事件抽取(event extraction,EE)是自然语言处理领域一项重要且极具挑战性的信息抽取任务,旨在利用自然语言处理技术从非结构化文本中抽取出用户感兴趣的事件并进行结构化展示。目前,事件抽取在金融、立法、医疗等领域的文本分析类工作中被广泛应用,极大地提升了人们在海量文本中检索关键信息的准确率和效率。
根据输入数据不同,事件抽取可分为句子级事件抽取和文档级事件抽取。早期方法[1-8]多为句子级事件抽取,即从单个句子中提取其中的事件信息。然而,一些事件(如金融事件)包含的事件要素较多,这些要素无法完全同时存在于单一句子中,需要从多个句子中抽取。因此,文档级事件抽取方法被提出,旨在从输入文档(包含多个句子的输入)中直接提取事件相关的要素信息。
目前,文档级事件抽取主要存在两大挑战亟待解决:(1)事件要素分散:事件要素散乱分布在文本的多个句子中,如何从全局角度建模,充分利用文本上下文语义特征,准确高效地从文档中抽取事件要素;(2)多事件共存:输入文本中可能存在多个事件,同一个实体可能在不同事件中扮演不同的事件角色,如何充分考虑构成多个事件的事件要素之间的交互性,以及如何充分利用多事件之间的依赖关系。如图1 所示,在输入文本中,稀疏分布于各个句子中的事件要素构成两个“股东增持”类型事件,并且“B 公司”作为事件要素同时存在于这两个事件中。现有的研究[9-11]将文档级事件抽取转化为对预定义事件表的填充任务,并根据预定义事件角色的顺序依次识别事件要素,但是这种序列式的要素抽取流程导致了严重的错误传播问题,并且无法充分利用多事件之间的依赖关系。
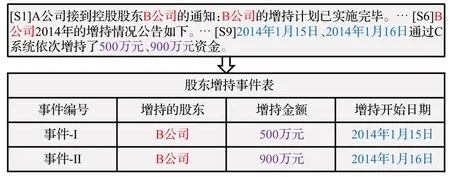
图1 多事件文本案例Fig.1 Example of multi-event text
为了应对上述挑战,同时避免序列式预测导致的错误传播[1]问题,提出了一种面向文档级事件抽取任务的反向推理模型(reverse inference model for documentlevel event extraction,RⅠDEE),将事件抽取转化为两个子任务:候选事件要素抽取和事件触发推理。在候选事件要素抽取阶段,利用命名实体识别技术从文本中识别出全部实体(候选事件要素)以及对应的实体标签(经标注后的事件角色)。在事件触发推理阶段,以事件类型为单位,通过广义笛卡尔积运算组合扮演不同事件角色的事件要素,进而反向推理组合事件的真实性。此外,设计了一种用于存储历史事件的事件依赖池,并通过对待推理事件和历史事件之间的依赖关系进行建模,帮助模型对多事件文本的抽取。在CCKS 2020 提供的文档级事件要素抽取数据集(https://www.biendata.xyz/competition/ccks_2020_4_2/data/)上的实验结果表明,相比于当前最先进的方法,RⅠDEE 取得了更优的抽取性能。
本文的主要贡献如下:
(1)面向文档级事件抽取任务提出了一种端到端的反向推理模型RⅠDEE,并设计了一种联合损失函数来匹配上下游损失,引导全局优化。
(2)基于无触发词的设计,将事件抽取转化为候选事件要素抽取和事件触发推理两个子任务,并行式抽取事件要素并检测事件类型。
(3)设计了一种用于存储历史事件信息的事件依赖池,通过事件之间的依赖关系帮助模型对多事件文本的抽取。
(4)在公开数据集上进行了实验。实验结果表明,在进行文档级事件抽取时,RⅠDEE的性能优于当前最先进的方法。
1 相关工作
1.1 句子级事件抽取
早期事件抽取方法主要关注于句子级事件抽取,即从单个句子中抽取事件信息。Li等人[1]使用人工设计的文本特征实现了对事件信息的结构化预测,而Chen 等人[2]和Liu 等人[3]则利用神经网络自动地从文本中提取特征。为了融入更多的语义信息,Chen等人[4]对句子的上下文信息进行建模,而Yang等人[5]直接采用了预训练语言模型,并通过整数动态规划解决了事件角色重叠的问题。此外,Li 等人[6]、Du 等人[7]以及Wang 等人[8]将机器阅读理解框架应用于事件抽取任务中,并基于问答的形式抽取触发词和事件要素。然而,即使上述部分方法在提取特征时超出了句子的范围,但抽取的水平仍处于句子级别。
1.2 文档级事件抽取
随着从文本中提取事件信息的需求增多,文档级事件抽取受到了越来越多的关注。针对文档级事件抽取存在的事件要素分散问题,Yang等人[12]提出一种关键事件检测策略从文本中检测关键句,并提出一种要素填充策略从关键句周围的句子中填充缺失的事件要素。在此基础上,Wang 等人[13]引入了事件要素的重要度来检测关键句,Zhong 等人[14]采用整型线性规划的方法进行全局推理,Wang 等人[15]将词汇之间的依赖关系融入到上下文编码中,并利用改进后的Transformer 编码器进一步帮助对事件类型的检测。此外,Du 等人[16]提出了一种多粒度阅读器,动态地聚合不同粒度(即句子级和段落级)的上下文信息。虽然上述方法都能够从文本上下文的全局信息中提取特征,并且实现了跨句子的事件要素抽取,但并未解决文档级事件抽取多事件共存的问题。
针对文档级事件抽取存在的多事件共存问题,Zheng等人[9]将文档级事件抽取转化为基于事件要素的有向无环图的路径扩展问题,以多路径扩展的方式实现了对多事件的抽取。Xu等人[10]提出了一种包含实体节点和句子节点的异构图交互神经网络,并且设计了跟踪器模块来捕获不同类型事件之间的依赖关系,从而帮助对不同类型多事件的抽取。Huang等人[11]将文本转化为一个融合实体和句子信息的无向无权图,并且通过图注意力网络在相关句子之间建立关联,缓解了要素角色重叠问题。上述方法虽有效应对了文档级事件抽取任务当前面临的两大挑战,但事件类型检测和事件角色分类子任务间的串行化执行流程以及基于前序要素信息的序列式事件要素抽取流程都导致了严重的错误传播问题。此外,上述方法仅有Xu 等人[10]通过设计跟踪器模块利用了不同类型事件之间的依赖关系,然而在真实语料中同文本下的多事件大多属于同一种事件类型。
本文将文档级事件抽取转化为候选事件要素抽取和事件触发推理两个子任务,并以组合事件为单位进行反向抽取,能够解决事件要素分散和多事件共存带来的挑战,并有效解决上述方法存在的错误传播问题。此外,通过对同文本下任意类型事件之间的依赖关系进行建模,能够有效帮助模型对多事件文本的抽取。
2 方法
本章首先介绍模型的整体构建架构,然后详细介绍模型的各个模块以及全局损失函数。
2.1 模型构建
如图2 所示,RⅠDEE 模型共包含两个模块:候选事件要素抽取(左侧)和事件触发推理(右侧)。
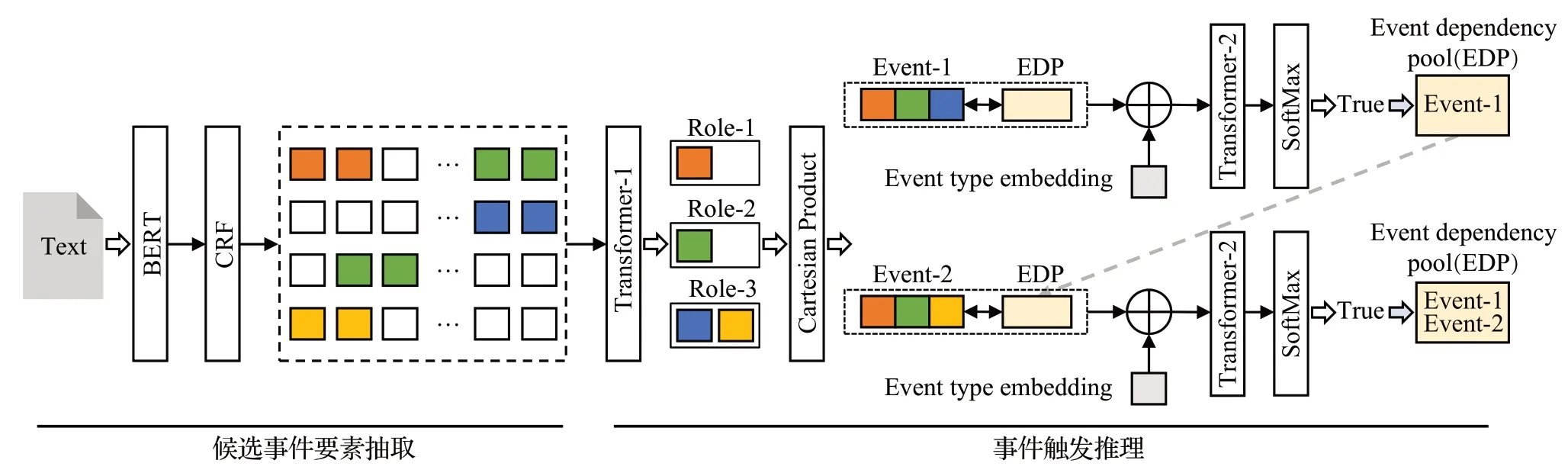
图2 RⅠDEE模型架构Fig.2 Model structure of RⅠDEE
候选事件要素抽取模块首先利用预训练BERT[17]获取句子中字符对应的词向量表示,然后通过条件随机场(conditional random fields,CRF)[18]抽取出扮演特定事件角色的候选事件要素。
事件触发推理模块主要分为要素编码、事件组合和触发推理三个子模块。要素编码子模块首先通过最大池化(max-pooling)压缩得到实体提及以及句子对应的编码,其次利用Transformer编码器[19]得到融合了实体关系、句子位置和事件角色等语义信息的候选事件要素编码。事件组合子模块以事件类型为单位,通过广义笛卡尔积运算组合候选事件要素得到所有待推理的组合事件编码。触发推理子模块首先将所有组合事件编码融入相应的事件类型信息,然后将当前组合事件编码和事件依赖池中的历史事件编码拼接,并交由Transformer编码器捕获事件之间的依赖关系,最后通过相应类型的事件触发器推理是否触发事件。若触发成功,将组合事件拆分为多个事件要素,即可得完整事件信息。
2.2 候选事件要素抽取
候选事件要素抽取旨在从文本中抽取出可能会在事件中扮演特定事件角色的候选事件要素,供下游任务组合事件信息。本文将候选事件要素抽取定义为传统的以句子为单位的序列标注任务,而实体标签由事件角色通过BⅠO标注生成。此外,沿用了经典命名实体识别模型BⅠ-LSTM-CRF[20]的整体架构。不同的是,本文采用预训练语言模型BERT获取词向量表示,由于其内部的Transformer 编码器相比于LSTM 具有更强的上下文语义编码能力,因此后续并未继续使用LSTM。
给定一个文本,首先将其表示为长度为q的句子序列{S1,S2,…,Sq} 。然后,通过BERT得到文本中所有字符的词向量表示wi∈Rdm,dm表示词向量的维度。最后,以句子为单位将句子对应的字符编码序列交由CRF,抽取出所有与实体标签(经过标注后的事件角色)相匹配的实体提及(候选事件要素):
其中,ci∈Rdm表示由CRF 处理后的字符编码,n表示句子的最大长度。
2.3 事件触发推理
2.3.1 要素编码
由于一个实体提及通常包含长度不定的字符跨度,因此需要通过最大池化(Max-pooling)压缩实体提及对应的字符编码序列,使得每一个实体提及对应一个固定维度的编码。例如,给定一个跨度长为l的实体提及∈Rl×dm,对应第i句子中第j个字符到第k个字符的位置跨度。经过最大池化压缩后,得到实体提及对应的固定编码∈Rdm:
此外,基于此种方式,将每一个句子对应的字符编码序列{c1,c2,…,cn} 映射为一个固定维度的句子编码∈Rdm。
为使抽取出的实体提及编码充分融入所在句子之外的上下文语义信息,需要将句子编码和实体编码进行充分的交互。首先,针对所有事件角色分别设计了可训练的事件角色编码r∈Rdm,并通过简单的相加,将实体提及对应的事件角色编码融入到实体提及编码中,增强实体提及编码和事件主题之间的关联性。然后,联合文本对应的句子编码序列和实体编码序列得到联合编码,g表示从该文本抽取出的实体提及的个数,并且此处的实体提及编码以及句子编码都融入了对应句子的位置信息。接着,将联合编码交由Transformer-1编码器:
通过截取即可得到融合了上下文语义信息的实体编码序列{e1,e2,…,eg} ∈Rg×dm。最后,由于一个候选事件要素可能对应多个位置的实体提及,因此利用平均池化(Mean-pooling)对其实体提及编码序列{e1,e2,…,eo}进行压缩,得到候选事件要素对应的固定编码ai∈Rm:
其中,o表示第i个候选事件要素在文本中对应的实体提及数量。至此,便得到了文本中全部待组合事件的候选事件要素编码{a1,a2,…,at},t表示候选事件要素的数量。
2.3.2 事件组合
反向推理任务的关键在于通过已抽取的候选事件要素组合事件信息。本文将事件组合任务转化为数据库关系表的广义笛卡尔积连接过程。
首先,根据事件角色将所有候选事件要素分配到不同的要素集合里,每一种事件角色对应一个事件要素集合。根据预定义的事件结构(如表1所示),可以判断出事件角色所属的事件类型,而每种事件角色对应的事件要素集合可理解为只包含一个属性(事件角色)的关系,从而一种事件类型对应了多个关系,关系的数量即相应事件类型包含的事件角色数量。

表1 CCKS 2020数据集的事件结构Table 1 Event structure of CCKS 2020 dataset
其次,通过广义笛卡尔积运算将相同事件类型下的关系进行连接,从而得到每种事件类型对应的唯一合成关系R͂,合成关系中的所有元组都是通过笛卡尔积组合而成的事件信息:
其中,R͂表示特定事件类型广义笛卡尔积运算后的合成关系,R͂i表示特定事件类型的第i个事件角色对应的关系,xi表示关系R͂i中唯一的属性,Nr表示特定事件类型下的事件角色数量。
最后,基于预定义的事件角色顺序(事件结构中各事件类型对应角色列表中的索引顺序),将组合事件对应的候选事件要素编码序列拼接,即可得到对应的组合事件编码Ei={a1,a2,…,aNr} ∈RNr×dm。此外,为使相同事件类型的组合事件编码具备相同的维度,对于未识别出要素的事件角色,采用填补零向量的方式进行补齐组合事件编码。
例如,针对图1案例文档中的“股东增持”类型下的多事件,只需将该类型下的所有关系做广义笛卡尔积连接操作,如图3 所示。经运算后得到合成关系R,其包含的四条元组都是由候选事件要素组合而来的事件信息,通过拼接要素编码可得到这四个事件对应的组合事件编码。在训练时,通过和数据集包含的真实事件比对,即可得到所有组合事件编码在后续进行触发推理任务时的真实分类标签。由图1事件表可知,组合事件Ⅰ和组合事件Ⅳ是文本的真实事件,因此将其标注为正例(T);相反,将组合事件Ⅱ和组合事件Ⅲ标注为反例(F)。

图3 广义笛卡尔积组合事件信息Fig.3 Event information combination based on generalized Cartesian product
2.3.3 触发推理
通过前文工作,得到了所有待推理的组合事件编码{E1,E2,…,Eu} ∈Ru×(Nr×dm),u表示组合事件的数量。接下来的任务即推理每个组合事件Ei∈RNr×dm的真实性。为了帮助模型推理,本文在该模块引入了三处关键设计:(1)为每一种事件类型分别提供了一个可训练的事件类型编码ti∈Rdw,使得组合事件编码充分融入对应的事件类型信息。(2)提出了一种用于存储历史事件信息的事件依赖池,通过捕获待推理事件和历史事件之间的依赖关系,可以更好地帮助模型提取文本中的多事件信息。在初始阶段,初始化事件依赖池为一个可训练的历史事件编码p∈Rdw。(3)为每一种事件类型分别设计了Softmax 事件触发器,使其专攻于推理特定类型的组合事件。
以第一个组合事件编码E1∈RNr×dm为例,首先将其与对应的事件类型编码t1∈Rdw相加,得到融入事件类型信息的组合事件编码。然后,将候选事件编码与事件依赖池中的历史事件编码拼接起来,并使用Transformer-2 编码器捕获当前事件和事件依赖池中的历史事件之间的依赖关系,并截取得到融入了历史事件信息的组合事件编码Ê1∈RNr×dm:
最后,经过简单的线性变换后,通过相应类型的事件触发器得到推理结果:
其中,Wt表示可训练的线性变换参数,相同事件类型下的组合事件共享该参数。若触发器推理为真实事件,即可通过平均池化(mean-pooling)将当前组合事件对应的要素编码序列压缩为一个历史事件编码h1∈Rdw,并将其加入事件依赖池中,然后开始预测下一个组合事件;若推理为非真实事件,则直接处理后续组合事件。例如,第k个组合事件前已有m个推理为正例的组合事件,事件依赖池中则存在m+1 个历史事件编码,Transformer-2编码器的处理过程应为:
其余步骤与针对第一个组合事件的处理过程一致。基于上述流程,待推理完所有组合事件后,所有推理成功的事件即从文本中抽取出的多事件信息。
2.4 全局损失函数
候选事件要素抽取模块在训练阶段,采用负对数似然函数以句子为单位计算CRF层的损失L1:
其中,q表示文本中有效句子的数量,Pi表示第i条路径的分数,N表示路径的个数,PRealPath表示真实路径的分数。在预测阶段,使用Viterbi解码算法得到最优标签路径。
事件触发推理模块在训练阶段,采用交叉熵损失函数计算所有组合事件进行触发推理的损失L2:
其中,yp表示第i个组合事件在特定事件类型下的预测标签,y表示第i个组合事件在特定事件类型下的真实标签。在预测阶段,使用Argmax 函数获取组合事件经事件触发器推理后的分类标签(0 和1 分别表示触发成功和触发失败)。
通过联合候选事件要素抽取模块和事件触发推理模块可计算模型的全局损失,可实现整体优化:
其中,λ表示损失率,用于调控两个模块在模型总损失中的比率。
3 实验
为测试RⅠDEE 模型的性能,本文在CCKS 2020 面向金融领域提供的文档级事件抽取数据集上与基线模型进行了对比实验。实验环境如下:操作系统版本为Windows 10,显卡为GeForce RTX 3080,显存大小为10 GB,python版本为3.8,pytorch版本为1.9。
3.1 实验数据集
CCKS 2020面向金融领域提供了文档级事件要素抽取数据集,共定义了9种事件类型(破产清算、重大资产损失、重大对外赔付、重大安全事故、股权冻结、股权质押、股东增持、股东减持、高层死亡)以及相应的事件角色列表,详细的事件结构信息如表1所示。由于原始数据集并未包含候选事件要素抽取模块所需的实体标签,不能满足模型设计的需求。因此,本文对原始数据集进行了手工处理,即根据数据集中的真实要素及其角色来标注实体、实体位置、实体标签等信息。经处理后,数据集中共包含3 485 条文本,其中609 条包含多事件信息,分布于“股权冻结”“股权质押”“股东增持”“股东减持”4种类型中,其余类型的文本仅包含单事件。详细的单、多事件数据集统计信息,如表2所示。
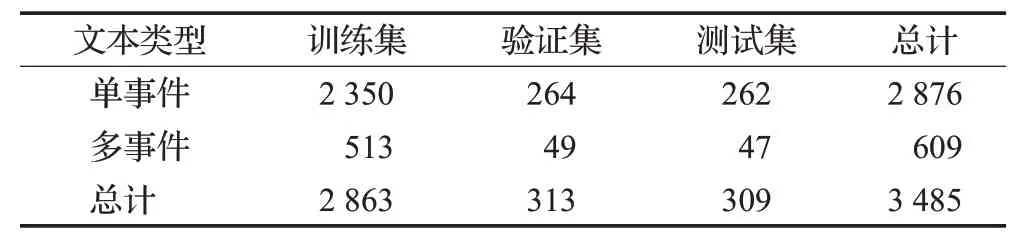
表2 CCKS 2020数据集统计Table 2 Statistics of CCKS 2020 dataset
3.2 超参数设置
在文本输入阶段,将最大句子个数和最大句子长度分别设为64和128。在词向量表示阶段,采用了预训练模型BERT,并将词向量维度设为768。在语义编码阶段,采用了8 层Transformer 编码器。此外,模型中的两处Transformer 编码器都采用相同的网络结构,但并不共享参数。在训练阶段,将损失率设为0.1,学习率设为10-4,训练周期设为100。其余超参数信息如表3所示。

表3 超参数设置Table 3 Hyper-parameter setting
3.3 基线模型
本文选取目前最先进的文档级事件抽取模型DCFEE[12](DCFEE-O、DCFEE-M)、Doc2EDAG[9]以及GⅠT[10]作为对比实验的基线模型。DCFEE首先通过关键事件检测策略从文本中检测关键句,然后从关键句周围的句子中填充缺失的事件要素,从而实现跨句子的事件要素抽取。DCFEE-O、DCFEE-M 是DCFEE 的两个版本,分别面向单事件和多事件抽取任务。Doc2EDAG 将文档级事件抽取转化为基于事件要素的有向无环图的路径扩展问题,以多路径扩展的方式实现了对多事件的抽取。在Doc2EDAG序列式预测事件要素的基础上,GⅠT提出了一种包含实体节点和句子节点的异构图交互神经网络检测事件类型,并且设计了跟踪器模块捕获不同类型事件之间的依赖关系。
3.4 评估标准
本文采用精确率(precision,P)、召回率(recall,R)和综合评价指标F1分数(F1 score,F1)联合作为模型的评估标准,在相同的实验环境下与基线模型进行了详细的对比分析。精确率P用于计算在预测为正例的样本中,预测正确的样本所占的比例。其计算公式为:
其中,TP为正例中预测正确的个数,FP为负例中预测错误的个数,FN 为正例中预测错误的个数。召回率R 用于计算在真实正例样本中,预测正确的样本所占的比例。其计算公式为:
F1分数可看作是模型精确率和召回率的一种加权平均,同时兼顾了精确率和召回率。其计算公式为:
在评估过程中,以事件要素作为统计项单位,并联合事件类型以及事件角色得到事件级别的评估指标。具体的统计规则为:在事件类型预测正确的前提下,若事件要素及其事件角色均预测正确则将事件要素统计为正确项,否则统计为错误项。若事件类型预测错误,则将该类型下的事件要素均统计为错误项。此外,本文将训练周期中在验证集上F1得分最高的模型视为最佳模型,而模型的性能由最佳模型在测试集上进行评估。
3.5 总体实验结果
RⅠDEE 和基线模型在测试集各类型上的总体实验结果如表4所示。与最佳基线模型(各指标分数最高的基线模型)相比,RⅠDEE在精确率上虽未展现出优势,但将召回率提升了4.3 个百分点,从而将F1 分数提升了2.1个百分点。这归因于RⅠDEE充分考虑了同类型下事件要素之间进行交互的可能性,以事件为单位进行整体预测,极大地提升了真实正例要素被正确预测的可能性。此外,严谨的事件触发推理流程同时保证了预测的精确性。

表4 测试集上的总体实验结果Table 4 Overall experimental results evaluated on test set单位:%
表5 详细展示了RⅠDEE 和基线模型在所有事件类型的测试集上的F1 分数对比情况。总体来看,RⅠDEE显著优于其他基线模型,RⅠDEE 在“破产清算”“重大资产损失”“重大对外赔付”“重大安全事故”“股权冻结”“股权质押”“股东增持”“股东减持”“高层死亡”类型上的F1分数相比最佳基线模型分别提升了1.2个百分点、1.4个百分点、2.2个百分点、2.5个百分点、1.6个百分点、2.3 个百分点、3.1 个百分点、3.5 个百分点、1.5 个百分点。这表明RⅠDEE通过组合与推理并行地预测事件要素是可行的,且相比于基线模型更为有效。此外,相比于“破产清算”等仅包含单事件文本的事件类型,RⅠDEE在“股东减持”等包含多事件文本的事件类型上的F1分数提升的更为显著,这证明了RⅠDEE 在多事件抽取任务中的优越性。

表5 各事件类型测试集上的事件级别的F1分数Table 5 Overall event-level F1 scores evaluated on test sets of all event types单位:%
3.6 单事件&&多事件抽取
事件要素分散和多事件共存是文档级事件抽取任务面临的两大挑战,为验证RⅠDEE 在面向上述挑战时的有效性,本文将“股权冻结”“股权质押”“股东增持”“股东减持”4种类型的测试集依次划分为单事件测试集(文本中仅存在单个事件)和多事件测试集(文本中存在多个事件)并额外进行了实验。
表6 展示了RⅠDEE 和基线模型在各类型单事件测试集(S)和多事件测试集(M)上的F1 分数以及平均F1分数。总体来看,所有模型在多事件测试集上的F1 分数都明显低于在单事件测试集上的F1 分数,这也证明了多事件抽取任务的挑战性。在单事件测试集的实验中,RⅠDEE在4种事件类型上的平均F1分数高于最佳基线模型1.2个百分点,这表明RⅠDEE通过组合事件要素反向整体推理可以很好地应对事件要素分散的挑战,能够更加精确地从文本中抽取出分散于各个句子中的要素信息;在多事件测试集的实验中,RⅠDEE 在4 种事件类型上的平均F1分数高于最佳基线模型2.1个百分点,这表明RⅠDEE 通过对事件之间的依赖关系进行建模,更能够捕获同文本多事件之间的语义相关性,从而在多事件抽取任务中表现得更为优异。

表6 单事件(S)集和多事件(M)集上的F1分数Table 6 F1 scores on single-event(S)and multi-event(M)sets单位:%
3.7 消融实验
为了测试模型各个关键模块设计的有效性,进行了如下消融实验:使用单一事件触发器代替多类型事件触发器、移除事件编码补齐模块、使用随机初始化词向量搭配Transformer 编码器代替BERT、移除要素信息(上下文信息、角色编码、位置编码)填充模块、移除事件依赖池模块、将Transformer编码层改为4层、将Transformer编码层改为12层。通过在原模型的基础上单独移除或更改上述模块,可依次得到7个版本的子模型。消融实验后,各子模型在所有事件类型下的平均F1 分数下降情况如表7所示。

表7 消融实验结果Table 7 Ablation experiment results 单位:%
总体来看,依次改动相应的设计模块后,F1分数分别下降了14.5%、6.2%、3.8%、3.2%、2.5%、2.2%、1.5%。其中,改动触发器模块后,模型性能下降的最为明显,这表明了不同类型事件之间存在明显的语义差异,也证明了多类型事件触发器对于整体模型设计的必要性。此外,通过在编码补齐、词向量表示、语义扩充、事件依赖关系以及网络结构等模块进行改动,模型的性能也有所下降,表明了所有模块在模型运转过程中都是至关重要的,也证明了RⅠDEE整体设计的有效性。
3.8 案例分析
图4 展示了Doc2EDAG 和RⅠDEE 对“股东增持”类型下一个多事件文本的预测案例。当候选事件要素“陈柏元”未被识别为事件角色“增持的股东”时,同事件中的后续事件要素“978 458”以及“二〇一九年六月五日”均未被成功识别,这证明了Doc2EDAG 基于前序要素信息序列式地识别候选事件要素会不可避免地导致级联错误预测。而本文所提模型通过组合事件,充分考虑了要素交互的可能性,以事件为单位进行整体预测,并利用事件之间的依赖关系帮助模型对多事件的抽取,从而成功预测出了所有事件信息。

图4 Doc2EDAG和RⅠDEE案例分析Fig.4 Case study of Doc2EDAG and RⅠDEE
4 结束语
本文提出了一种基于端到端的反向推理模型RⅠDEE,以解决文档级事件抽取任务所面临的事件要素分散和多事件共存的挑战。该模型基于无触发词的设计,将事件抽取转化为候选事件要素抽取和事件触发推理两个子任务,通过广义笛卡尔积运算组合事件要素,以整体事件为单位进行反向抽取,从而消除了传统方法带来的错误传播的问题。此外,设计了一种用于存储历史事件信息的事件依赖池,通过事件之间的依赖关系帮助模型对多事件文本的抽取。实验结果表明,本文所提方法的性能优于当前最先进的方法。展望未来,将致力于提升模型对相似事件的级联推理能力。
