联合知识和视觉信息推理的视觉问答研究
2024-03-12苏振强
苏振强,苟 刚
贵州大学计算机科学与技术学院公共大数据国家重点实验室,贵阳 550025
随着网络的飞速发展,数据的存在形式是多种多样的,其用途和来源也是十分广泛。不同存在形式或信息来源都可以称之为一种模态,往往单模态信息表达的内容有限,加之文本、语音、图像等单模态信息技术的逐步成熟,多模态信息挖掘走进了人们的视野。本文关注的是一项结合计算机视觉和自然语言处理的学习任务:视觉问答(visual question answering,VQA)[1]。视觉问答需要机器充分感知、识别、理解图像信息和问题语义,并推理出正确的答案,是一项极具挑战性的任务。换言之,该任务就是教会机器如何去“观察”和“阅读”。视觉问答在跨模态人机交互场景下极具应用前景,包括但不限于帮助视障人士感知世界,提高公安系统监控视频检索效率,优化智能系统中人机交互体验。
视觉问答主要是对图像和问题分别进行特征提取,一方面利用Word2Vec[2]、Glove[3]、Bert[4]等技术进行文本编码,另一方面采用VGG[5]、ResNet[6]、Faster R-CNN[7]等技术进行图像编码,进而实现特征的理解和融合等操作。2014年第一个视觉问答数据集的发布,拉开了VQA研究的序幕。Malinowski等人[8]提出了一种神经图像视觉问答方法,利用长短期记忆网络(long short-term memory,LSTM)[9]处理问题文本和生成答案。Ren 等人[10]不同于前者将视觉问答视为序列生成问题,而是看作分类问题,从预定义的词汇表中选出正确的答案。但是他们都采用了双向LSTM,从前后两个方向分析问题,一定程度上解决了远距离单词依赖丢失的问题。
如果依靠图像和文本的全局特征,往往容易传递无关或嘈杂信息。因此,有学者引入注意力机制来有效地避免此类情况的发生。譬如,Chen等人[11]将问题特征表示从语义空间转化为视觉空间来生成卷积核,从而在空间图像特征图中搜寻与问题语义信息最相关的视觉区域特征,获得语义对齐后的视觉注意图,但忽略从视觉特征出发的注意力引导。视觉任务需要同时理解图像和问题,Fukui 等人[12]提出了双线性池化(multimodal compact bilinear pooling,MCBP)方法,将视觉和文本特征进行跨模态融合,在一定程度上有效融合了模态特征,但是外积的融合方式无法表征复杂的交互信息。因而,Ben-Younes 等人[13]提出了MUTAN 模型,运用张量分解的方式对双线性模型的参数张量进行分解,以此进行复杂交互。Anderson等人[14]通过“自下而上”和“自上而下”相结合的视觉注意力机制,学习图像区域和文本问题之间的隐含对齐关系。Kim 等人[15]提出一种双线性注意力网络模型BAN,利用双线性注意力映射和双线性池化的方式提取图像和问题的联合表示。Yu 等人[16]提出了一种提出了一种深度模块化共同注意力网络(modular co-attention network,MCAN),注重单模态的内部注意力和跨模态之间的交互注意力,加强了模态的内部依赖和跨模态的对齐关系。以上方法在视觉问答领域都取得了不错的成绩,但是对于基于知识的开放性视觉问答,忽略了外部知识,仅仅依靠图像和问题信息难以推理出正确的答案。
Zhu 等人[17]提出了Mucko 模型,从视觉、语义、知识三个角度将图像表示成一个多层的多模态异质图,并利用异质图卷积网络来从不同层的图中自适应地收集互补线索。王屹超等人[18]结合图像描述和知识图谱作为外部知识用来解决开放性知识问答。以上方法用不同方式结合问答所需要的知识信息,用单模态的特征与知识库进行交互,然而在一些问答实例中需要联合图像和问题语义进行知识交互,才能推理出正确的答案。
外部知识的引入可以丰富模型的推理能力,视觉信息也不容忽视。如图1(a)所示,图像信息并没有关于“这些人是游客还是当地人?”的相关信息,可以从视觉信息捕捉到“行李包”这一个信息对象,结合相关联的外部知识:“旅行包是手提包,用于装旅行者的衣服和其他个人物品”和“行李是存放旅客物品的箱子”,可以推理出图中的人是游客这一答案。图1(b)中,外部知识仅仅能提供这个物体是用于表示时间的相关概念性信息,而对于问题需要的具体时间仍需要从视觉信息中进行获取。

图1 联合知识和视觉信息的视觉问答实例Fig.1 Knowledge-based visual question answering example
因此,本文提出了联合知识和视觉信息推理的双线性推理结构,将模型的推理过程分为视觉信息推理和外部知识信息推理,设计了图像特征和文本特征双引导的注意力机制,从而与外部知识进行充分交互。
本文的主要研究工作如下:
(1)提出双线性推理结构,关注视觉信息的提取和知识嵌入的方式,充分利用视觉信息和知识信息来进行问答推理。
(2)设计了双引导的注意力模块,使得每一个问题词和每一个图像区域都可以实现与外部知识实体的密集交互,有助于理解其中的细粒度关系,更好地推理出问答所需的知识信息。
1 相关工作
1.1 LXMERT
目前关于视觉语言的推理都要求模型能够正确的理解视觉概念和语言语义,以及两者之间的关系,并将它们对齐。LXMERT[19]框架通过三个编码器(对象关系编码器、语言编码器和跨模态编码器)来学习视觉语言之间的关系。为了使LXMERT能够将视觉概念和语言语义关联起来,利用掩码语言建模、掩码目标预测、跨模态匹配、图像问答等预训练任务,在大量“图像句子对”数据集上对模型进行了预训练。这些任务有助于模型学习模态内部和模态之间的关系。因此,该文拟利用LXMERT 在模态内和跨模态间表现出良好的建模能力的优势,对问题和图像进行编码,以进一步抽取视觉信息和输入对象的特征表示。
1.2 MCAN
文献[16]提出的深度模块化协同注意网络,将问题中的关键词和图像中的关键区域进行深度的联合注意学习。这种深度的学习方式主要是利用了自注意力(self-attention,SA)[20]机制对问题和图像分别进行自注意,加强问题和图像各自的内部依赖关系;利用引导注意力(guide-attention,GA)的机制实现跨模态特征之间的协同。SA和GA内部结构如图2所示。
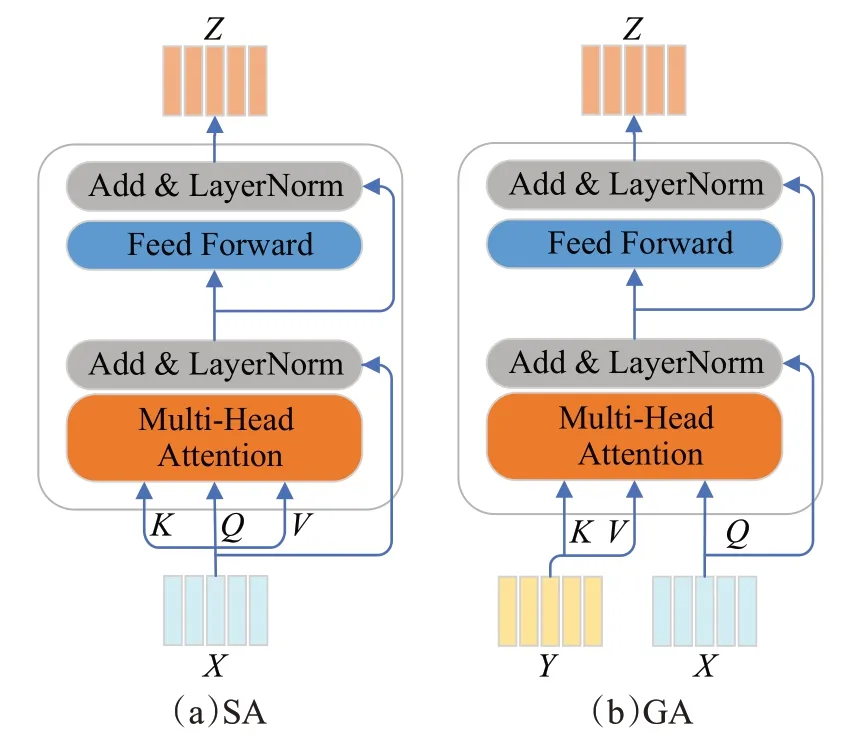
图2 SA和GA的内部结构Fig.2 Ⅰnternal structure of SA and GA
自注意力SA 是用于计算单模态之间的依赖关系。它摒弃了模态信息内部的顺序关系,通过相似度计算去衡量和表征模态信息。SA 传入的是三个相等向量Query、Key、Value,即Q=K=V。首先将Q和K进行点积,计算二者之间的相似度得到权重,并除以K的维度;然后通过softmax函数进行权重的归一化;最后将权重与V进行加权和得到最终的注意力表征,其表达式具体如下:
其中,dk为K的维度。
为了进一步提高模型的推理能力,采用多头注意力机制,其计算方式为:
其中,、、是第i个头的参数矩阵,n是多头的数量,Wm是多头注意力参数矩阵。
2 本文方法
本文的模型框架如图3所示,将模型的推理路径分为视觉信息推理和外部知识信息推理。

图3 联合知识和视觉信息推理的双线性模型框架Fig.3 Bilinear model framework for joint knowledge and visual information reasoning
2.1 视觉推理
视觉推理路径主要是分析问题和图像之间的隐含关系,从图像信息中发掘问题所需要的视觉信息。由于视觉-语言模型LXMERT在模态内和跨模态间表现出良好的建模能力。本文采用LXMERT对问题文本和图像进行编码,以进一步抽取视觉等信息。
2.1.1 特征表示和视觉信息
输入的图像Ⅰ本文采用Faster R-CNN,以“自下而上”的方式来提取输入图像的目标区域特征,最终每一张图像可以表示为一个视觉特征矩阵fv∈RK×d:
其中,K表示图像区域框的数量,d表示区域框的特征维度。
输入的问题文本Q运用WordPiece 进行分词并获得长度为D的单词序列fq:
将视觉特征fv和文本序列fq传入预训练模型LXMERT中,获得视觉编码LV∈RK×dv、问题文本编码LQ∈RD×dv和跨模态输出“[CLS]”,其中dv表示编码信息的维度。
考虑到LXMERT 预训练任务中对VQA 设置,本文从[CLS]表征中抽取跨模态的视觉信息,并喂入多层感知机(multi-layer perceptron,MLP)中以进一步推理出问答所需的视觉信息V∈R1×dr,其中dr是表示学习的维度大小。
2.1.2 图像的语义对齐
一般输入问题的语义关注对象只有图像中的一小块区域,而不是整张图像信息。如图1中的实例B,该问题只需要关注图像中的时钟对象,而其他对象信息实则为冗余信息。由于LXMERT是针对模态内部所有对象的隐含关系进行建模,所以经过编码的各个区域框的特征实际上也包含了其他区域框的视觉信息。因此,可以利用LXMERT的输出特征计算与问题语义对齐的视觉对象,从而减少噪声数据提升模型的推理能力。
引用文献[21]中的处理手段,首先将问题表征和图像中各区域框的视觉特征通过线性投射层映射到同一维度后进行矩阵相乘运算,构建出相似性矩阵A:
其中,W1和W2表示线性投射层中可学习的参数矩阵;其次利用逐行最大池化的方式从相似性矩阵中计算各对象区域框Oi与问题之间的相关性;然后利用Gumbel-Softmax结合硬注意力机制计算各个对象区域的语义相关性权重信息:
其中,i表示第i个区域框,gi表示Gumbel(0,1)的随机采样,τ表示Gumbel 的温度;最后将权重信息转化为one-hot分布从而得出问题语义对齐下图像区域块表征R∈R1×dv,其计算表达式如下:
2.2 知识推理
2.2.1 外部知识表示
本文编写SPARQL语句从Wikidata[22]知识库中抽取与现实场景相关联的知识实体,再过滤描述为空或非英语单词的知识实体后,共获取到187 308 个实体及其描述信息。因为预训练模型CLⅠP[23]突出的图文配对的能力,所以本研究中图像采用滑动窗口的对象抽取形式构建一批图像集,并利用CLⅠP 从过滤后的知识实体中检索与图像信息相关联的知识实体,用于该问答的外部知识信息。
外部知识的嵌入表示分为两个并行的视角,每个视角采取不同方式的知识嵌入手段。视角1利用Glove词嵌入技术将文本S转换为词向量,然后通过平均池化策略获取该文本的句子向量;视角2 利用预训练模型Sentence-BERT[24]得到其句向量特征表示Ss:
其中,Sg∈Rdg,Ss∈Rds,dg和ds分别表示Glove词嵌入和Sentence-BERT句嵌入的维度。
2.2.2 协同引导
多模态协同引导的注意力机制是挖掘问题、图像、外部知识三者特征表示之间交互信息的一种结构。受MCAN模型中GA单元的启发,本文设计了图像和文本特征双引导的协同注意力机制(dual-guided attention,DGA),其单元结构如图4所示,计算方式为:
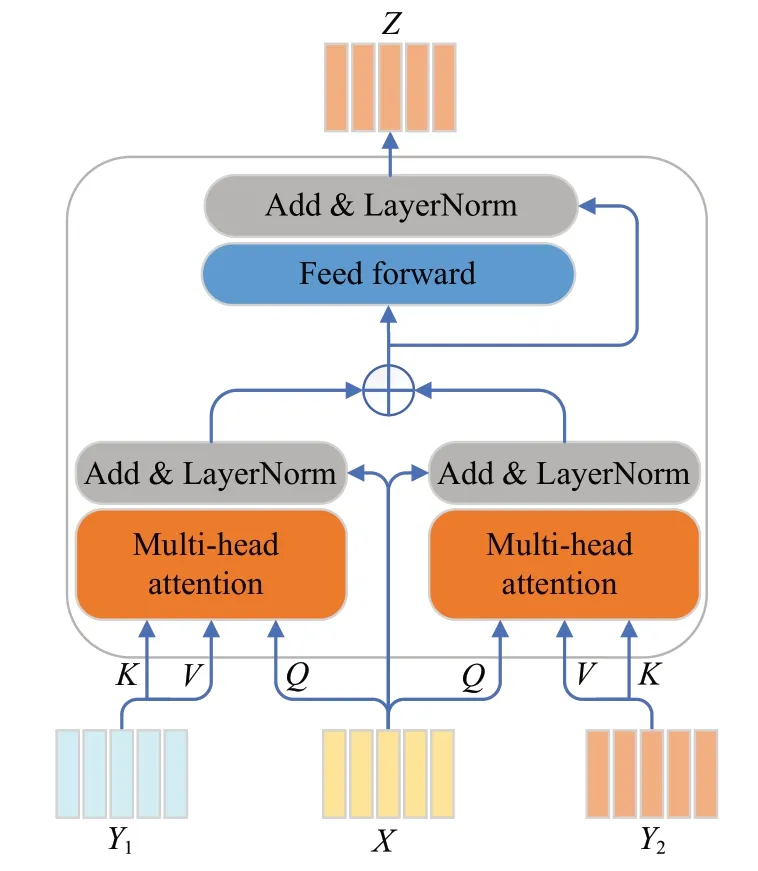
图4 DGA的内部结构Fig.4 Ⅰnternal structure of DGA
其中,X、Y1、Y2分别代表知识表征、图像特征和文本特征。
基于DGA和SA共同构成多模态协同注意力SDGA模块,模块结构如图5所示。
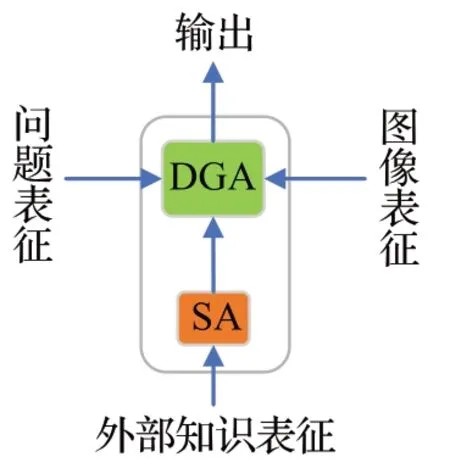
图5 SDGA的内部结构Fig.5 Ⅰnternal structure of SDGA
SDGA 的输入主要有问题文本特征LV、语义对齐的图像2特征R、外部知识的知识表征Ss。其中经LXMERT 处理后的问题文本特征,其重点关注问题文本中的名词、代词、冠词,这些词性的单词常在句子语义上起到重要作用,能够很好地引导推理过程。首先外部知识表征通过SA进行自注意力机制得出知识之间的关联关系;然后将其送入DGA中作为查询向量,与问题特征和图像特征分别进行协同注意力机制;最后将二者输出通过相加运算后,利用残差链接送入前馈神经网络与层正则化得到最终的输出表示Z∈Rn×dh,其中dh是注意力机制中的隐藏层大小。
2.3 特征减少和融合
模型通过视觉推理和知识推理得到两个输出:V和Z。为了获取Z的实际参与信息减轻问题特征和图像特征的过度引导,首先将Z送入一个双层的MLP 得到输出Z′;其次将Z′利用softmax计算其权重信息并进行加权和操作得到Z′;再次将Z′通过线性投射映射到与V同一个学习维度;然后二者利用相加运算的融合方式生成一个融合向量并传入MLP中得到最终的推理结果,最后将该推理结果送入与答案集合长度相同的分类器中,分类得出最终预测的结果。
3 实验
3.1 数据集
本研究是基于开放性的知识问答,在回答问题的时候需要借助外部知识信息。考虑到一些数据集的局限性,比如FVQA数据集[25]和KB-VQA数据集[26]均使用指定的知识库信息,导致了其泛化能力弱的问题。于是本文选用OK-VQA[27]作为实验的数据集。
OK-VQA是一个指包含外部知识解答的数据集,使用来自MS-COCO 数据集[28]的图像,共包含14 031 张图像和14 055 个英文问题。该数据集中问题的平均长度为6.8个单词,答案平均长度为2.0个单词。本文依照官方划分标准,将其样本划分为9 009 个样本的训练集和5 046个样本的验证集。
3.2 实验细节
本文实验的硬件环境是基于Ubuntu 18.04 操作系统,显存为22 GB,显卡为两张NVⅠDⅠA GeForce GTX 2080TⅠ,版本为CUDA11.1,软件环境基于Python 3.8,深度学习框架为Pytorch 1.8.1。
特征处理:输入的问题文本采用WordPiece 进行分词,设定最大长度D=20,得到文本字符映射到词典id的文本序列;输入的图像采用Faster R-CNN 以自下而上的方式提取图像区域框特征,设定区域框数量K=36,每个区域框的特征维度d=2 048;输入的外部知识实体的数量取值为20 并且使用Sentence-BERT 进行句子嵌入,句子表示维度ds=384,随后将句子表示向量维度映射到512。
多模态协同引导:SDGA 的层数设置为6。多头注意力机制中,设置head=8,隐藏层的大小dh=512,每个头的大小为64。
视觉推理:视觉推理信息V的表示学习维度为300。
输出层:本文选用的答案词典源自于训练集中出现的答案集合,为了提高训练效率和精度,实验中过滤答案集合中频率少于2 次的答案对象。实验的损失函数采用二分类交叉熵(binary cross entropy,BCE),优化器采用AdamW,实验中的超参数如表1所示。

表1 实验中的超参数Table 1 Hyperparameters in experiments
评价指标:利用VQA 中提出的评价指标衡量实验模型的有效性:
3.3 实验结果
本文模型以文献[16]和文献[19]作为基线方法,并在OK-VQA 数据集上与其他主流模型进行对比,实验结果如表2所示。从实验结果中可知,本文与基线方法相比准确率分别提升1.97个百分点和4.82个百分点,与其他方法相比准确率也有不同大小的提升。实验结果表明,本文提出的联合知识和视觉信息推理的双线性模型是有效的。

表2 主实验模型与其他模型实验结果的比较Table 2 Comparison of experimental results between main experimental model and other models 单位:%
4 实验分析
4.1 多模态协同引导的消融实验对比
为了分析图像特征和问题特征对知识推理过程的影响,本文设计了将SGA[16]作为协同注意力单元的3种对比实验,分别从图像特征引导、问题特征引导、图像与问题特征双引导(将二者特征进行相加运算)策略分析单特征和多特征引导的差异性。三种策略的实验结果如表3 和图6 所示。实验结果表明,在单特征引导中基于SGA的图像特征引导策略比基于SGA的文本特征引导策略更具有推理能力,模型的效果更佳。整体来说,双特征引导明显优于单特征引导。产生差异的主要原因是:单特征引导在知识推理过程中提供信息引导的能力有限,无法具体理解整体问答语义即单从图像特征考虑无法理解知识表征应该关注哪一方面的信息,如对象属性、来源等等,若结合问题特征则能够很好地解弥补该不足。同样的,单从问题特征考虑,缺乏图像的目标对象,增加了模型的推理难度。

表3 不同策略的实验对比结果Table 3 Experimental comparison results of different strategies单位:%
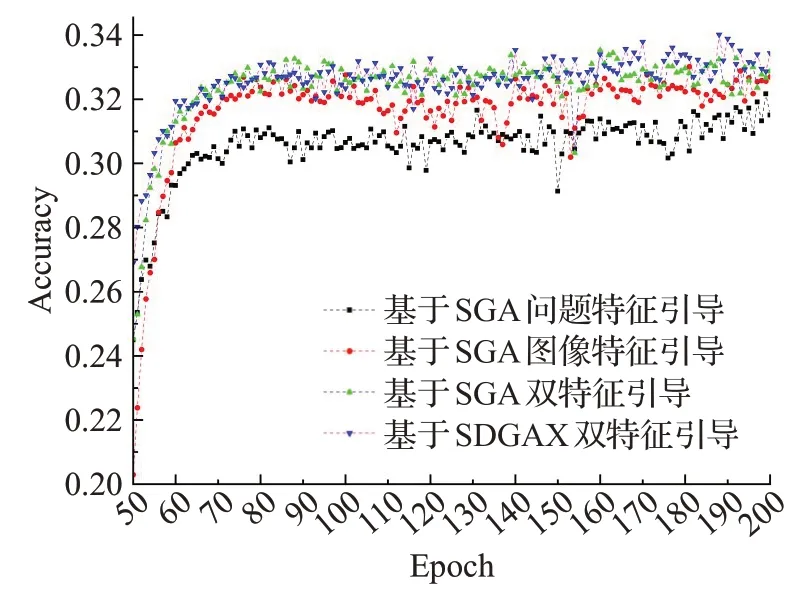
图6 不同策略对准确率的影响Fig.6 Effect of different strategies on accuracy
为了验证本文提出的SDGA模块的有效性,本文将基于SGA的双特征引导和基于SDGA的双特征引导方式进行对比实验。从图6 中准确率的走势中可以发现基于SDGA 双引导更加稳定,有明显的优势,实验的具体数据比较如表3。从表3 中可以知道,基于SDGA 双特征引导的实验达到了34.01%的准确率,高于基于SGA双特征引导0.48%,这说明SDGA单元结构是有意义的,在多模态协同方面更具合理性,能够细粒度地与外部知识进行交互融合和推理。
4.2 知识嵌入的消融实验对比
为了分析知识嵌入方式对模型知识表征的影响,本文分别利用Glove 词嵌入和Sentence-BERT 知识嵌入的方式获取句向量,随后将二者的句向量映射到相同维度进行实验对比。采用Glove 词嵌入之后模型相比Sentence-Bert知识嵌入准确率下降了1.47%。造成该问题的主要原因是:Sentence-BERT 在大量的语句上进行训练,能很好地表征一个句子语义信息,而采用Glove词嵌入后,从单个词语的语义出发,未经历大规模的语句训练,编码信息较为单一,难以有很好的表征能力。
5 误差分析
本文对误差的案例进行分析,从图7(a)可以观察到,此时外部知识提供“世界时钟是显示世界各个城市的时间”等知识信息,然后结合图像和问题信息得出答案,而模型预测偏差的主要原因是答案词典的局限性,即本任务中将视觉问答作为分类问题,而问答词典的构建是基于训练集词典,所以训练集中的答案集合中不能覆盖所有验证集中答案字符。在某种程度上来说,模型预测的“tell time”是该情况下较为符合问题语义一种回答。

图7 误差案例分析Fig.7 Error cases analysis
从图7(b)和(c)中可以发现模型缺乏细致化的场景分析,其主要原因归咎于已构建的知识库内容的局限性和模型缺乏细粒度场景识别能力,才导致模型以外部知识信息为主导,缺乏对问题语义的细致理解。虽然知识库具备图像中绝大数对象的信息,但是多数对象在现实生活中存在不同的场景语义,现有的知识库无法提供更为丰富的信息,模型也无法对场景进行区分和理解,相反地,模型过度依赖检索到的知识信息。具体如图7(c),因为外部知识提供了“长凳用于学校的教室”的知识信息,所以导致了模型的误判。
视觉问答领域内通用的评判标准在该任务下缺乏语义性,过于公式化。如图7(d)中所示问答,以人类角度“Teddy bear”和“bear”在该场景下语义信息是一致的,二者均可作为本题的答案。
综上所述,模型具有以下几点局限性:
(1)模型缺乏自主生成答案的能力;模型过度依赖检索的相关知识,无法根据场景关联知识。
(2)知识库对某些对象场景覆盖面有限。
(3)评价标准缺乏该场景下的细致性理解。
6 结束语
本文提供了视觉问答与知识库结合的一种方式,提出一种双线性推理结构,将视觉推理和外部知识推理进行有机融合,有效提升了模型的整体推理能力,模型在OK-VQA 数据集上取得较好的效果。视觉推理主要是将问题和图像进行跨模态的交互分析,从视觉信息中推理出的知识信息(如图片对象文字、属性等信息);知识推理是在问题语义特征和图像对象特征的双引导下,实现与外部知识表征的交互融合,从而推理出符合问答语义的关键知识信息。
实验结果表明,该模型与前人的工作相比准确率有着不同程度的提升。在后续的消融实验当中也验证了模型结构在此任务上具有一定的有效性。在下一步的研究中,应进一步拓展知识库内容信息,丰富知识库表征能力,可考虑与知识图谱技术融合增强模型的多级推理能力和场景的细致化理解。另外,摒弃“分类式”的问题回答,采用词典组合等自主生成的答案方式更具有灵活性,也更加符合该领域的实际应用场景。
