基于CLIP和交叉注意力的多模态情感分析模型
2024-03-09赖宇斌廖宇翔陈宁江
陈 燕, 赖宇斌, 肖 澳, 廖宇翔, 陈宁江
(1.广西大学 计算机与电子信息学院,广西 南宁 530000;2.广西大学 广西多媒体通信与网络技术重点实验室,广西 南宁 530000)
随着科技的发展和短视频平台的流行,人们在社交媒体和各种网站平台上的情感表达方式也越来越多样化,不仅有文本,还有图片、音频、视频等多模态信息。相比于单一模态信息,多模态数据可以从不同视角表达语义信息,包含更多情感内容。图1为一个多模态表达的例子,一段视频片段配上字幕“你那点财务还需要助理?”,如果只看文字,可能会感觉说话者是在轻视和嘲讽对方,让观众认为此处表现出消极的情感极性。但是结合视频内容,就可以发现说话者是在开玩笑地和对方交流,想表达的是积极情感。因此,利用多模态信息的互补和增强,可以更全面和准确地理解人们的情感状态。

图1 多模态数据示例
在文本数据缺乏情感信息的情况下,可以利用图片、视频或其他模态信息来加强和补充。但文本和图像包含的情感信息属于不同层次和不同程度的信息,因此存在相关性的同时也会包含冗余信息和噪声信息。此外,目前许多特征融合方法依赖预设的规则或权重,不能自适应地调整模态之间的关系和重要性。因此,多模态情感分析任务面临着一些挑战。
情感分析任务最早由Pang等[1]提出,通过词袋框架和有监督的机器学习方法对电影文本评论进行情感分类。随着数据语料库和人工智能技术的发展,情感分析任务得到了越来越多人的重视,并得到了广泛的应用[2]。目前,情感分析研究不局限于单一模态的文本数据,还包括图片、动图、视频等多种模态数据相融合的情感分析。
在文本情感分析方面,李勇等[3]基于双向长短时记忆网络(Bi-LSTM)与位置注意力机制提取语义特征,使用CNN对食品评论进行分类,得到比较好的分类效果。Munikar等[4]通过BERT预训练模型对10 000余条电影评论数据进行细粒度情感分析,提高了多分类情感任务的效果。在视觉情感分析方面,Zhu等[5]提出了一种统一的CNN-RNN模型,通过不同层次的特征融合和依赖关系,有效地实现了视觉情感识别。You等[6]提出了一个基于注意力机制的视觉情感分析模型,能够自动发现和加权图像中与情感相关的局部区域。在多模态情感分析方面,针对多模态情感分析中存在的标注数据量少、模态间融合不充分,以及信息冗余等问题,Wang等[7]使用选择加法学习方法将不同模态的特征进行加权平均,得到一个多模态的特征表示,可以提高神经网络的泛化能力;吴思思等[8]使用后端融合的方法,提出了一种基于感知融合的多任务多模态情感分析模型,有效地整合了文本、语音和图像3种模态信息,并利用多任务学习来提高模型的泛化能力。但上述多模态情感分析模型在特征融合上有一定缺陷,需要使用自注意力机制加强模态之间信息交互和融合。
针对多模态情感分析数据集数据缺乏、模型特征融合不足等问题,本文提出了一种基于对比语言-图片训练(contrastive language-image pretraining,CLIP)[9]和交叉注意力(cross-attention,CA)的多模态情感分析(multimodal sentiment analysis,MSA)模型CLIP-CA-MSA。本文使用了根据自然语言指示从图像中预测最相关的文本片段的CLIP多模态预训练模型和利用提示学习,在少量数据下得到较好的文本情感分类效果的PIFT[10]模型,并进行特征提取,同时引入了交叉注意力机制来实现不同模态之间的信息传递。对于视觉情感分析,借助CLIP预训练模型的丰富先验信息,使用标签文本作为提示信息,并采用预训练的对比学习方法进行相似度计算,得到相似度分数最高的类别作为视觉情感分析结果。为了减少冗余和噪声信息的影响,使用了不确定性损失函数来自动分配视觉和文本的重要性占比,以增强模型的泛化能力和鲁棒性。
1 基于CLIP和交叉注意力的多模态情感分析模型
本文提出的CLIP-CA-MSA模型结构如图2所示。

图2 CLIP-CA-MSA模型结构
首先将视频按照一定的帧率分割成若干张图片,然后使用CLIP预训练的BERT模型和ViT模型来提取标签特征和每张图片的图像特征,并使用Transformer编码器将图像特征构建成一个视频特征向量。接着使用PIFT模型来提取文本数据的文本特征。随后,使用交叉注意力机制将图像特征向量和文本特征向量进行交互。最后,再利用标签特征计算视频和标签之间的相似度,得到一个视频分类特征向量。该向量和文本分类特征向量一起被输入到同方差不确定性损失中进行计算,并输出最终的情感分类结果。
CLIP-CA-MSA模型算法如下。
输入:视频数据集Dv和文本数据集Dt,数据集数量大小M,最大迭代次数N;
输出:模型f。
① fort=1,2, …,Ndo
② form=1,2, …,Mdo
③ ∥将视频数据输入到视频编码器
④ video_encorder←Dv(m);
⑤ Transformer_encorder←video_encorder;
⑥ ∥将文本数据输入到文本编码器
⑦ text_encorder←Dt(m);
⑧ ∥特征提取
⑨Hv←Transformer_encorder;
⑩Ht←text_encorder;
1.1 特征提取
本文使用的多模态情感分析数据集包含文本、视频2个模态。
(1)文本特征提取。文本模态由文本信息(视频对应的字幕信息)和标签信息(加入提示的标签文本)构成,如式(1)所示。
Text={T,P1,P2,P3}。
(1)
式中:Text表示文本模态;T表示文本信息;P1、P2、P3表示加入提示的分类标签(如中性、积极和消极)信息。
将文本信息T和标签信息P1、P2、P3按字粒度划分,如式(2)、(3)所示。
T={TCLS,T1,…,Tn};
(2)
(3)

为了避免模型规模过大和训练难度大的问题,采用了基于提示嵌入和焦点损失函数的PIFT模型来提取文本特征,具体提取过程如式(4)所示。为保证模型的情感分析精度,利用经过CLIP预训练的BERT模型来提取标签信息,提取过程如式(5)所示。
Ht=PIFT(TCLS,T1,T2,…,Tn);
(4)
HP=[HP1,HP2,HP3]=BERT(P1,P2,P3)。
(5)
式中:Ht表示文本特征向量;Hp表示所有类别的标签特征向量。
(2)视频特征提取与融合。为了获取视频表示,首先从视频片段中按帧提取出一组图像,即V=(V1,V2,…,Vm),其中m表示每组图片最大数量(本文实验中m=6)。然后通过视觉编码器对其进行编码,得到视频特征序列。
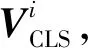
(6)

如图2中视频编码器模块所示,CLIP-CA-MSA利用ViT编码器对输入图像中每个块之间的相互关系进行建模以获取图像特征,如式(7)所示。
H={H1,H2,…,Hm}=ViT(L1,L2,…,Lm)。
(7)
式中:H1表示ViT从第1张图片提取出图像特征;H表示视频特征序列。
最终,需要融合图像特征序列得到代表整组图像特征的视频特征向量Hv。本文使用Transformer编码器来融合视频特征序列。首先,插入标记HCLS作为视频全局特征表示,并为图像加入时序信息;其次,使用自注意力机制获取视频中的时空关系,以有效地帮助识别视频情感极性。具体融合过程如式(8)所示。
Hv=Transformer(HCLS,H1,H2,…,Hm)。
(8)
式中:Hv为视频的特征向量,蕴含视频的重要信息。
1.2 交叉注意力机制
为了减少单一模态情感信息不足或噪声污染的问题,本文使用交叉注意力机制进行模态交互。交叉注意力机制是一种在多模态情感分析中用于融合不同模态信息的注意力机制,它可以在图像、文本等模态之间交叉计算注意力分数,以提取共享的情感特征,并增强每个模态的表示能力。本文采用的交叉注意力机制的基本原理如图3所示。

图3 交叉注意力机制
首先,使用一个输入作为查询(Q),另一个输入作为键(K)和值(V),用注意力机制来计算2个输入每个元素之间的相关性;其次,将注意力权重与值(V)相乘并求和,得到模态间的交互特征;最后,将交互特征与原始输入连接起来,形成新的融合了多模态信息的特征表示。通过这种方式,可以有效地减少单个模态在情感分析中的局限,提高模型的泛化性能和鲁棒性。
多头注意力机制是交叉注意力机制进行模态交互的重点,其计算过程如式(9)、(10)所示。
(9)
(10)
式中:·为点乘操作;Softmax代表归一化函数;dk表示键向量的维度,此处的作用为对点积的结果进行缩放,避免结果过大或过小影响Softmax的梯度。

残差连接与正则化计算过程如式(11)、(12)所示。
S′t=LayerNorm(St+Qt);
(11)
S′v=LayerNorm(Sv+Qv)。
(12)
以式(11)为例,将Qt与St相加能够帮助特征向深层网络传递,再进行正则化以提高模型的稳定性和收敛速度,得到S′t。然后将其进行前向传播为特征增加非线性变化,增强其表达能力。最后经过一次求和与归一化得到文本-视频特征向量Ht2v。式(12)同理,最后得到视频-文本特征向量Hv2t。
1.3 图像相似度分类
为了在少量数据下提高模型效果,根据视频特征向量与每个情感分类标签之间的相似程度来判断其所属类别。具体相似度计算过程如式(13)所示。
(13)

1.4 同方差不确定性损失
多模态任务的重点之一在于如何平衡不同任务损失之间的权重,目前大多数方法采用对多个模态的损失函数进行加权,其损失函数如式(14)所示。
Lossall=μtLosst+μvLossv。
(14)
式中:μt与μv分别表示文本和视频模态损失函数的权重;Losst与Lossv表示文本和视频模态损失函数,Losst使用焦点损失函数,Lossv使用相似度计算损失函数;Lossall表示总体网络的损失函数,即多模态任务的优化目标。
然而,简单的线性加权求和方法需要人为设定每个模态的权重,这不符合实际数据的分布和特性,会导致某些模态被过分强调或忽略,也限制了模型的泛化能力。
因此,本文使用同方差不确定性损失来自动平衡不同模态之间的损失函数权重,同时避免信息的丢失或者冗余。假设x表示模型的输入,W为参数矩阵,其概率似然估计如式(15)所示。
P(y|fW(x))=Softmax(fW(x))。
(15)
式中:Softmax函数用来从产生的概率向量中抽取样本。假设文本与视频模态的输出向量为yt与yv,并都服从高斯分布,则模型的最大似然函数如式(16)所示。
P(yt,yv|fW(x))=P(yt|fW(x))·P(yv|fW(x))=
N(yt;fW(x),σt2)·N(yv;fW(x),σv2)。
(16)
为了最大化似然参数,需要最小化其负对数似然函数,过程如式(17)所示。
L(W,σt,σv)=-logP(yt,yv|fW(x))∝
logσt+logσv。
(17)

2 实验结果及分析
本文将详细介绍所采用的多模态数据集、实验评价指标和实验参数设置,将CLIP-CA-MSA模型与其他多模态模型进行对比实验并进行分析。
2.1 多模态数据集与评价指标
为验证CLIP-CA-MSA模型的情感分析性能,本文采用公开数据集CH-SIMS(chinese single and multimodal sentiment)[11]进行实验。数据集分布情况如图4所示。

图4 CH-SIMS数据分布图
CH-SIMS数据集是一个中文多模态情感分析数据集,视频来源于中文电影、电视剧和演出节目,根据说话者的话语将视频帧划分为多个片段,每个片段对应一个说话者的一句话,长度在1~10 s之间,对每个视频片段的文本和视觉模态分别进行消极、中性和积极的情感极性标注。
2.2 多模态模型对比实验
本文选取了几种常用的多模态情感分析模型作为基准模型,并与CLIP-CA-MSA模型进行实验对比和分析。这些基准模型包括以下几种。
TFN[12]:使用张量外积来显式地聚合单模态、双模态和三模态之间的交互关系。
LMF[13]:使用LSTM编码文本,CNN编码图像,用低秩张量外积来聚合模态间的交互关系。
MulT[14]:利用方向性成对交叉模态注意力,可以在不同时间步中关注多模态序列之间的交互,并隐式地适应数据的对齐方式。
Self-MM[15]:利用自监督任务来增强多模态情感分析的方法,可以同时学习不同模态的特征表示和情感分类。
MMAF[8]:利用多任务学习和感知融合层对多模态数据进行情感分析。
MMAF+T+A+V:将MMAF提取的多特征向量与单模态特征向量融合。
CLIP-CA-MSA模型与上述基准模型在CH-SIMS数据集的对比实验结果如表1所示。

表1 多模态模型对比实验结果
由表1可以看出,TFN和LMF的效果相对较差,说明张量外积聚合交互关系并不足以捕捉多模态数据之间复杂的关联性。MulT能够捕捉不同时间步中多模态序列之间的交互关系,但仍没有考虑到多模态数据之间的语义一致性和情感相关性。Self-MM让模型同时学习到多模态数据之间的内在联系,提高情感分类效果。MMAF通过引入多任务学习和感知融合层来增强多特征向量的表达能力,而MMAF+T+A+V能更好地理解每个单独模态以及整体模态对于情感分类任务的贡献程度,并且避免了信息冗余或丢失,两者的Acc和F1值均有明显的提升。
CLIP-CA-MSA模型利用CLIP方法来提取多模态特征和标签特征,引入PIFT模型来提取文本特征,交叉注意力机制能保留模态内特征和关注模态间特征,通过同方差不确定性损失自动调整模态重点,使得模型在准确率Acc上达到了78.07%,F1值达到了77.39%。
综上所述,CLIP-CA-MSA模型最优,其成功的原因在于它引入了强大的多模态特征提取方法、多模态融合方式以及自动均衡模态权重,使得模型能够更好地利用多模态数据之间的交互关系。
2.3 多模态融合对比实验
为验证CLIP-CA-MSA模型多模态融合的效果,先将视频和文本模态用视觉模型和文本模型分别进行单模态实验,再进行模态融合实验。
2.3.1 视觉模型对比实验
本文对CH-SIMS数据集中的视频模态部分进行情感分类任务,采用了常用的5个深度学习视觉模型进行测试和比较。进行实验对比的模型相关信息如下。
VGG-16[16]:使用小卷积核和多卷积子层方法的深度神经网络,提高计算效率和网络性能。
ResNet[17]:由多个残差块组成深度神经网络,使用快捷连接的方法,解决了深层网络训练中的退化现象。
ConvNeXt[18]:基于CNN卷积网络,参考Transformer网络的思想,对ResNet网络的卷积层、池化层和注意力机制进行了改进。
OpenFace2.0[19]:一个面部行为分析工具,使用基于卷积神经网络的局部模型,可以从图片中检测出68个人脸关键点,并根据这些关键点估计头部姿态、眼睛注视方向和面部动作单元。
ViT[20]:通过将图片分成固定大小的块,然后通过线性变化作为Transformer的输入序列,从而进行特征提取和分类。ViT-B-16使用16×16的块,ViT-B-32使用32×32的块。
视觉模型的实验结果如表2所示,P为精确率,R为回收率。
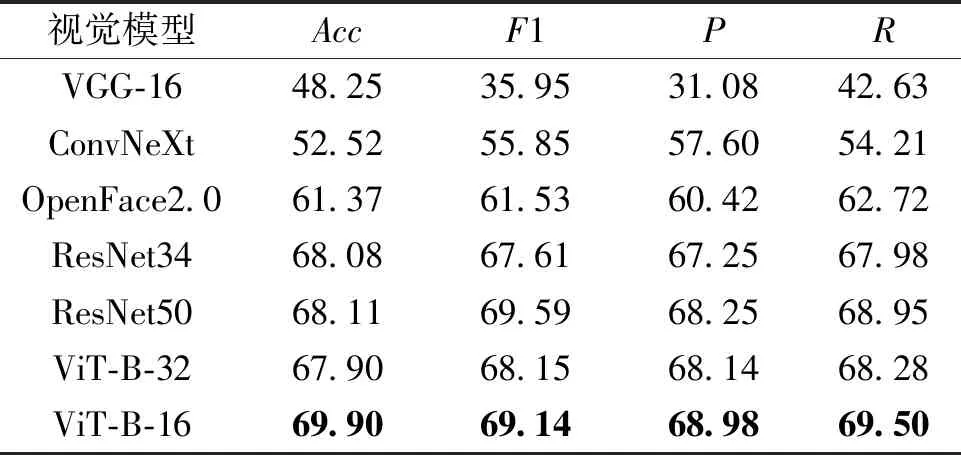
表2 视觉模型对比实验结果
由表2可知,VGG-16模型的层数较浅,无法很好地提取视频特征,所以表现最差。而ConvNeXt网络的卷积层、池化层和注意力机制的改进能使视频分类效果有一定提升。OpenFace2.0在面部行为分析上表现优异。ResNet34具有良好的深度和残差连接结构,能够很好地提取视频特征。ResNet50是ResNet系列中更深、更复杂的模型,具有更多的层和残差块,使网络能够更准确地进行视频分类,其效果略好于ResNet34,这也证明了深层网络能够提高模型的表现。
ViT模型中,相较于ViT-B-32,ViT-B-16的准确率和F1值分别提高了2.00百分点和0.99百分点,这是由于块的大小对模型性能的影响,更小的块可以捕捉到更细粒度的图像特征。相比于效果最差的VGG-16,准确率和F1分别提高了21.65百分点和33.19百分点。相较于ResNet50,其准确率提升了1.79百分点,但是F1降低了0.45百分点。
由于该数据集的规模不大、多样性不足,无法很好地判断2个模型的优劣。ViT-B-16准确率较高,说明其在处理图像中的全局特征和细粒度特征方面表现更好,可以更好地识别视频中的物体和场景,但需要更多的计算资源和数据量。而ResNet50有较高的F1值,这说明该模型在处理视频中的空间信息方面表现更好,能够更准确地对视频进行分类,同时具有较好的稳健性。
本文使用基于消融分析的可视化方法Ablation-CAM[21],为2个模型生成视觉解释并且定位图像中的相关区域,如图5所示。

图5 可视化分析
这2张热力图显示出了模型对于人脸表情的关注点。ResNet的热力图显示出了模型对于图像的整体区域都有关注,其中主要集中在人脸上,但分散的关注点可能会导致模型判断错误。而ViT的热力图则显示出了模型对于人脸表情的关注更加集中,这是因为ViT使用了自注意力机制,可以更好地捕捉到图像中的局部特征。
2.3.2 文本模型对比实验
采用文本分类模型ALBERT[22]、BERT[23]、ERNIE[24]、MacBERT[25]和RoBERTa[26]作为词嵌入工具,使用提示嵌入和焦点损失进行情感分类,得到的模型分别为Al-PIFT、B-PIFT、E-PIFT、M-PIFT和PIFT。文本模型实验结果如表3所示。

表3 文本模型对比实验结果
由表3可知,Al-PIFT在所有指标上都表现最差,说明其在降低参数量和内存消耗的同时,也限制了模型容量和表征能力。B-PIFT虽各项指标有了一定的提升,但表现不如其他模型。E-PIFT的各项指标均有所提高,说明ERNIE模型能增强对中文语言特征的理解能力。M-PIFT使用纠错型掩码语言模型等方法进一步提高模型性能。PIFT模型在所有指标上都取得了最好的结果,这说明RoBERTa通过增加数据量和训练时间等方法进一步提高模型性能,让模型学习到更丰富的先验信息。
2.3.3 模型融合实验
为验证模态融合的有效性,文本模型均采用效果最好的PIFT进行文本特征提取,对视觉模型使用效果较好的ResNet34、ResNet50、ViT-B-32及ViT-B-16进行视觉特征提取,再使用本文方法进行模态融合,实验结果如表4所示。

表4 模态融合对比实验
通过实验评估,发现CLIP-ResNet50和CLIP-CA-MSA表现相近,但CLIP-CA-MSA在准确率和回收率2个指标上均优于CLIP-ResNet50。
3 消融实验
为验证本文各模块对多模态情感分析的性能提升效果,本文分别针对视频融合方法、特征融合方法、图像分类方法及损失函数,在CH-SIMS数据集上进行消融实验。
3.1 视频融合方法消融实验
视频融合的方法主要有MeanP、LSTM、Transformer[27]3种。其中,MeanP可以减少计算量和内存的消耗,但是也忽略了视频中的时序信息,无法捕捉视频的动态变化和关键帧。LSTM可以学习视频中的长期依赖关系,捕捉视频的时序信息和动态变化,但计算量和内存消耗较大,容易出现梯度消失或爆炸的问题。Transformer使用自注意力机制对多帧视频进行并行建模,实现全局交互和长范围依赖,捕捉视频中时空信息动态变化。视频融合方法消融实验结果如表5所示。

表5 视频融合方法消融实验结果
从表5可知,MeanP方法各项指标都较低,比文本单模态分类准确率低了0.44百分点,说明MeanP忽略了视频中情感的变换过程。LSTM可以有效地考虑到视频特征之间的时序关系,在各项指标上都有提升。Transformer方法能考虑到视频特征之间的空间关系与交互信息,准确率较LSTM方法提高了0.88百分点。
3.2 多模态特征融合方法消融实验
拼接(concat)和交叉注意力(cross-attention)为多模态特征融合的2种方法。简单拼接方法将各模态数据进行简单拼接后使用一个编码器来处理融合后的信息,可以节省计算资源,但会忽略单模态内的交互信息。交叉注意力为每个模态设计一个Transformer编码器,提取各模态特征,再交互模态特征,得到综合的多模态表示。可以实现不同模态之间的信息交互,从而获得更丰富的语义信息。其他模块保持不变,更改多模态特征融合方法,实验结果如表6所示。

表6 多模态特征融合方法消融实验结果
由表6可知,交叉注意力方法可以更好地处理各模态的特征,避免了冗余信息问题,因此相对于拼接方法的情感分类效果有了明显的提高。
综上所述,通过对多模态情感分析模型的消融实验进行效果对比,发现交叉注意力机制在CH-SIMS数据集上表现较好,验证了该方法的有效性。
3.3 视觉情感分类方法消融实验
本文实验使用CLIP模型中的相似度分类方法(similarity-CLS)将视觉特征与类别进行相似度计算,得分最高的类即为分类结果。与常用的线性分类(lineaer-CLS)进行对照实验,使用CH-SIMS数据集,结果如表7所示。

表7 图像情感分类方法消融实验结果
由表7可知,Linear-CLS方法的准确率为76.75%,比相似度分类方法低1.76百分点。线性分类方法需要单独训练线性分类器,在特征空间中寻找一个超平面,将不同类别的数据分离开来,这种方法的表现可能会受到特征空间分布的影响。并且由于CH-SIMS的数据量不大、视频中存在噪声干扰,也会导致线性分类方法准确率降低。而相似度计算方法与CLIP模型的预训练任务相同,预训练模型所学习到的丰富特征可以直接转移到下游任务,不需要额外的适应过程,减少了模型的训练时间和数据需求。
3.4 损失函数消融实验
为了证明本文使用损失函数的有效性,将其与加权求和损失函数进行对比实验。损失函数消融实验结果如表8所示。

表8 损失函数消融实验结果
由表8可知,使用加权求和后的各项指标较单模态而言已经有了较大的提升,这说明将损失加权求和能够在一定程度上平衡不同模态的重要性和难度。但同方差不确定性损失在多模态情感分析中具有更好的效果,其在准确率与F1值上较加权求和损失提升了1.32和1.29百分点,说明各模态固有不确定性的重要性以及自动调整各模态权重能够更加准确地学习到不同模态的信息,提高模型的性能。
4 结论
本文针对多模态情感分析存在的模态融合不充分、信息冗余以及数据量不足等问题,提出一种基于特征融合和不确定性损失的多模态情感分析模型CLIP-CA-MSA。首先,阐述了CLIP-CA-MSA的整体框架。然后介绍了实验所使用的数据集以及参数设置,通过实验验证了该模型的优越性,并探究了不同的视觉模型对该方法的影响,证明了多模态预训练模型对该方法的有效提升。然后,通过消融实验,验证各模块的有效性。但本文只使用了CH-SIMS数据集的文本部分和视频的视觉部分。后续研究将加入视频中的音频模态,以确保数据的完整性,进一步提升模型情感分析的准确率和泛化能力。
