基于深度学习的毛/粘混纺织物混纺比检测技术
2024-03-08林素存常帅才
林素存,魏 菊,常帅才
(大连工业大学 纺织与材料工程学院, 辽宁 大连 116034)
羊毛纤维是珍贵的天然蛋白质纤维,具有良好的弹性、吸湿性、皮肤亲和性,深受广大消费者喜爱。羊毛纤维产量有限,价格昂贵,毛/粘混纺产品可以在保留羊毛织物优良风格的基础上大幅降低原料成本,得到了市场的广泛认可。混纺比对织物的力学性能、服用性能、价格具有重要影响,需进行准确检测[1]。目前织物混纺比检测方法应用最多的是光学显微镜法和化学溶解法[2]。光学显微镜法[3]依靠肉眼观察纤维形态,主观性较大,专业性要求较高;化学溶解法根据纤维的溶解性差异进行质量分析,步骤繁琐,存在环境污染等问题。
随着计算机视觉技术的飞速发展,国内外学者已经探究了许多纺织品检测方法。在机器学习方面,Wen等[4]根据羊毛和羊绒的形态差异,选取鳞片直径、高度及其比例作为特征值,输入到贝叶斯分类模型中训练,模型识别准确率达94.2%。赵宇涛等[5]研发了一种棉/亚麻自动检测系统,提取棉和亚麻的直径、扭曲度、充满度等6个特征参数,引入反向传播(BP)神经网络模型训练,提高了模型识别精度。陶伟森等[6]提出一种径向基(REF)作为核函数的支持向量机(SVM)模型,将图片处理后获得的鳞片密度、鳞片面积等12个特征值输入模型训练,对羊毛和羊绒的识别准确率可达93.1%。在深度学习方面,肖登辉等[7]采集麻、棉纤维图像建立了Faster RCNN网络模型且模型的评价指标平均精度均值达到了0.91。刘瀚旗等[8]研究了Faster RCNN与YOLOv3 2种神经网络模型在棉/麻混纺纱混纺比检测上的应用,对二者学习率和数据增强部分进行改良,对比了二者的优缺点。
深度学习是一种由神经网络模型学习图像特征的机器学习方法,通过学习样本中的图像特征,获得感知图像中的数据信息的功能,从而完成目标检测、图像分割等任务[9]。将深度学习技术应用于混纺织物的混纺比检测能够有效避免使用化学试剂步骤繁琐、环境污染等问题,同时还提高了检测效率。深度学习技术在织物疵点检测[10-11]、异纤检测[12]领域已有广泛应用,但尚无在毛/粘混纺织物混纺比检测上的应用研究。本文采用光学显微镜采集纤维图像,通过YOLOv5建立检测模型并在主干网络中嵌入卷积注意力模块,增强分辨羊毛和粘胶纤维的能力,以实现毛/粘混纺织物混纺比的检测。
1 实验与方法
1.1 材料与仪器
材料:绵羊毛(平均直径23.19 μm,变异系数21.61%,河北省清河县宇冠绒毛制品有限公司);粘胶纤维(平均直径15.29 μm,变异系数14.07%,湖北省襄阳大成兄弟纺织有限公司);毛/粘(50/50)斜纹法兰呢(经纱线密度142 tex+138 tex,纬纱线密度91.5 tex×2,面密度256 g/m2,浙江省嵊州市华通毛纺织厂)。
仪器:Y172型哈氏切片器(江苏省常州第二纺织机械有限公司);OLYMPUS CX31型生物显微镜(日本东京奥林巴斯株式会社);Shineso图像分析系统(杭州迅数科技有限公司)。
1.2 图像采集
将羊毛和粘胶纤维梳理整齐,用哈氏切片器从纤维样本中切取长度在0.4~0.6 mm的纤维片段,将其分散在纯水中制备纤维切片。在不同光照强度下拍摄放大400倍的纤维纵向显微镜图像,统一保存为2 048像素×1 536像素的JPG格式图像。当显微镜视野中纤维过于密集或纤维有交叠现象时不予拍摄。共采集了468张纤维图像,采集的羊毛和粘胶纤维图像如图1所示。

图1 纤维纵向光学显微镜照片(×400)Fig.1 Longitudinal optical microscope photo of fibers (×400).(a)Viscose fibers; (b) Wool fibers
1.3 数据集处理
使用Labeling工具标注图片形成VOC2007格式的数据集,生成xml格式文件,每个文件包含图片的大小、保存路径、图片中所有纤维的位置坐标信息、类别。标注框包围整根纤维,处在边缘以及超短的纤维不进行标注。标注共计2 305 根纤维,其中羊毛826 根,粘胶1 479 根。按照8∶2的比例,将数据集划分为训练集和测试集。
1.4 混纺比检测模型构建
作为深度学习算法之一的单阶段目标检测算法YOLOv5有着很高的检测速度,被应用于多领域。YOLOv5算法可直接处理输入的整张图像,将图像划分成7×7的网格,每个网格负责预测该网格内的目标边框和类别概率,然后去除概率低的边框和冗余窗口,输出目标预测框[13]。综合考虑模型大小和检测精度,选用YOLOv5作为基础模型。图2所示YOLOv5分为4个部分:输入端(Input)、骨干网络(Backbone)、颈部网络(Neck)和预测端(Prediction)。
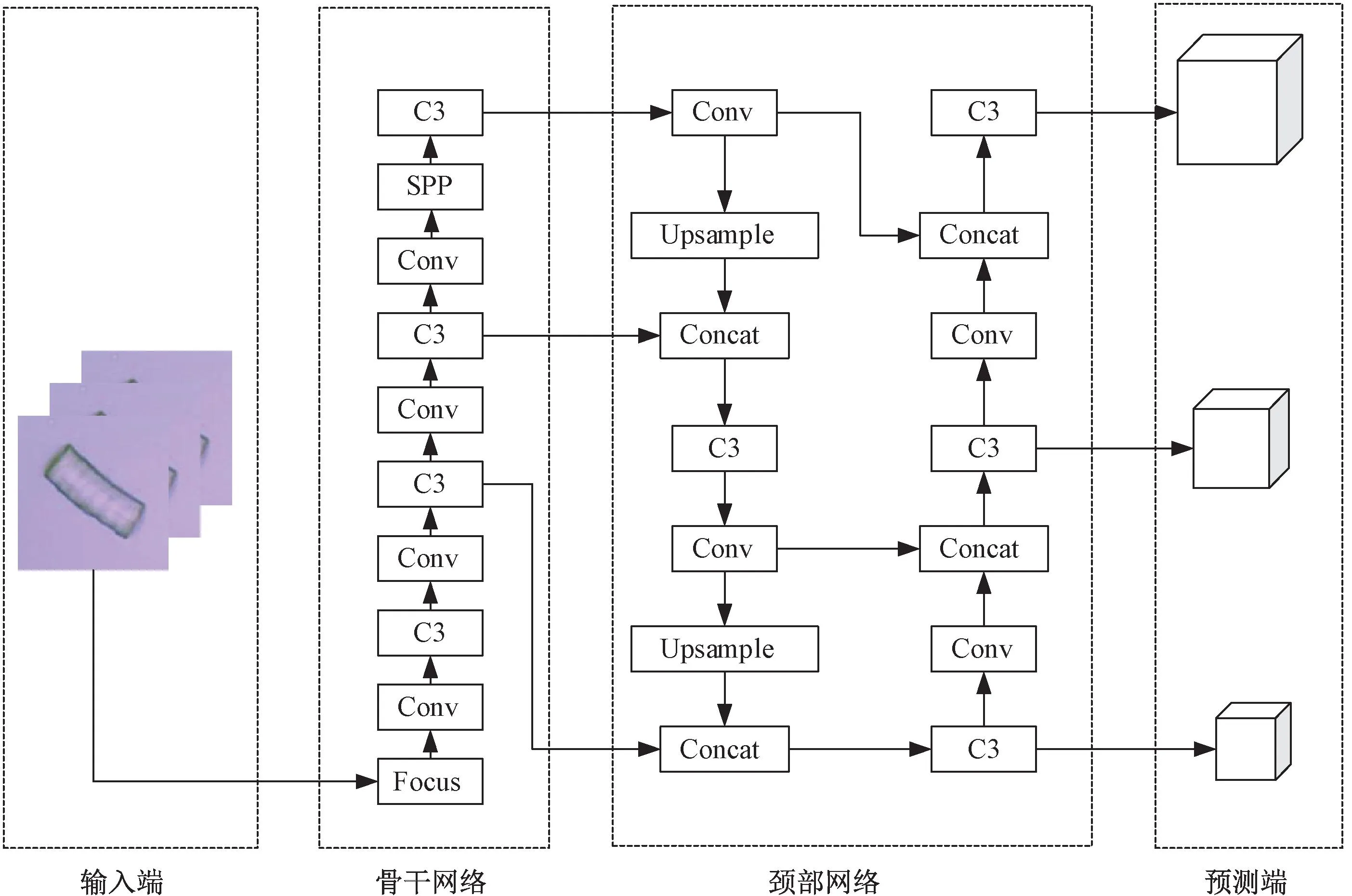
图2 YOLOv5网络结构Fig.2 YOLOv5 network structure
1.4.1 输入端
输入端包含Mosaic数据增强(Mosaic data augment)、自适应锚框计算和自适应图片缩放操作,主要对输入的羊毛和粘胶纤维数据集进行图像预处理,形成特征图,方便网络更好地提取信息。由于输入的纤维图像尺寸过大,首先根据缩放比例统一缩放并用黑边填充为640像素×640像素的标准尺寸;当黑边过多时,出现信息冗余,影响检测速度,自适应图片缩放操作通过添加最少的黑边以减少计算量。在网络训练中,以锚框为基础生成预测框,通过引入自适应锚框计算操作,根据建立的纤维数据集计算锚框。数据增强能够增加数据量,从输入的原始纤维图像里任意选取4张图像拼接,经无规律地随机剪裁、翻转、缩放等操作形成1张图像作为训练样本,丰富数据集。
1.4.2 骨干网络
由聚焦模块(Focus)[14]、标准卷积模块(Conv)、三卷积跨阶段局部瓶颈模块(C3)和空间金字塔池化模块(SPP)构成的主干网络通过层层卷积输入端处理后的纤维图像,目的是提取出不同层次的纤维图像特征。输入640×640×3的纤维图像首先经过Focus模块使其整合为320×320×32通道的特征图,实现图像信息的压缩以减少参数量,提升训练速度;接着输入Conv,对特征图执行卷积层、归一化层、SiLU激活函数(Sigmoid-weighted Linera Unit)操作,实现纤维特征信息的提取;并在C3模块作用下增加网络深度,把握纤维的全局信息。SPP使用3种不同大小的池化层对特征图进行提取,实现不同尺度的特征捕捉,增强特征图的表达,降低了模型训练门槛,提高预测框的产生速度。
1.4.3 颈部网络
浅层的神经网络提取纤维的颜色、纹理、轮廓等图形特征;随着网络的加深,对图形特征不断融合从而产生了语义特征,高层语义特征包含丰富的组合信息,同时也会损失一些图形特征。劲部网络端通过特征金字塔(FPN)[15]和路径聚合网络(PAN)结合的方式可以更好地融合低层图形特征和高层语义特征,提高网络性能。FPN将高层特征的语义信息自上而下以上采样(Upsample)的方式传递下来,与主干网络传入的不同尺度特征图做特征融合(Concat);而PAN[16]是自下而上传递低层特征的定位信息,获取不同尺度的特征图并与语义信息做更好的融合,得到更加完整的纤维特征信息,增强检测能力。
1.4.4 预测端
颈部网络输出的3个特征图传入预测端卷积得到3个尺寸的检测特征层,负责输出检测信息,适用于大、中、小3种目标的检测,并根据损失函数和非极大值抑制算法(NMS)优化参数权重。损失函数又分为3个部分:位置损失、分类损失、置信度损失,用于评估预测的准确性。同时,YOLOv5模型采用非极大值抑制算法对生成的所有预测框与置信度最高的预测框进行交并比(IoU)遍历计算,筛选出预测结果最好的预测框作为预测输出结果,避免出现同一个纤维多次统计的情况。
2 过程与结果
2.1 实验配置
模型基于深度学习框架Pytorch 1.10,程序语言Python 3.7,硬件配套为NVIDIA GTX 1080Ti,操作系统为Windows 10。利用YOLOv5预训练模型进行迁移学习。设置模型训练参数:迭代批处理大小值为8、迭代周期为50。模型评价指标选用平均精度均值(mAP值)来衡量模型对于羊毛纤维和粘胶纤维的识别效果,mAP值越大,检测效果越好。
2.2 混纺比检测模型优化与训练
作为单阶段目标检测算法,YOLOv5的检测精度会随着检测目标大小而发生变化,目标越小识别效果越差。纤维属于小目标,训练结果不稳定且精度较低,因此在检测模型中加入了卷积注意力模块(CBAM)[17],使其忽略背景信息,聚焦于纤维特征。CBAM包括通道注意力和空间注意力2个子模块,可以从不同的通道和空间维度给特征图分配权重,从而加强目标的信息。传入的纤维特征图先在通道注意力子模块中经全局平均池化层和最大池化层来捕获全局信息和局部信息,得到最大和平均2个特征向量,再输入到MLP神经网络和Sigmoid函数(Sigmoid function)内获取通道权重,动态调整每个特征通道,生成加强表达的特征图;由通道注意力模块处理后的特征图在空间注意力子模块中同样进行全局平均池化和最大池化操作,由最大池化突出主要特征,平均池化感知整体,经过卷积层和Sigmoid激活函数,得到注意力机制模块的输出特征图[18]。注意力学习机制在深度学习领域有着广泛的应用,以增强重要特征的表达能力,提高对细小纤维的检测精度和识别效果。本文将CBAM模块添加到主干网络的第3个C3模块之后,方便增加网络的深度,使网络更好理解特征图的重要信息,进而提高识别精度。
为了进一步提高纤维的识别率,增加了不同颜色的羊毛和粘胶纤维图像以扩充数据量。同时,以纯水为分散介质制作纤维切片时容易产生气泡,对于模型学习影响较大,因此对处于气泡周围的纤维不进行标注。经过模型训练,mAP值为0.93,认为模型达到稳定收敛。模型训练的mAP值变化曲线如图3所示。

图3 模型训练过程中的mAP值变化曲线Fig.3 Comparison of mAP curves during model training. (a) Without CBAM added; (b) After adding CBAM
2.3 混纺比检测模型测试
采用训练好的毛/粘混纺织物深度学习混纺比检测模型对市售毛/粘(50/50)混纺织物进行检测,以测试其有效性。从待测织物上拆取一定量的经纬纱,切取0.4~0.6 mm长的纤维片段与纯水按1∶600的比例混合分散,滴取适量分散液到载玻片上,拍摄光学显微镜照片(×400)并输入到上述模型中进行纤维识别并计数,纤维识别效果如图4所示。
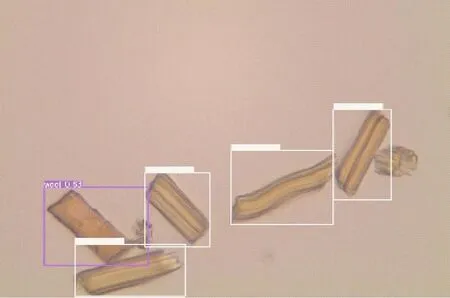
图4 模型对2种纤维的识别效果Fig.4 Identification effect of the model on two types of fibers
识别结束后,根据模型统计出的2种纤维根数,按照GB/T 16988—2013《特种动物纤维与绵羊毛混合物含量的测定》计算混纺比,计算公式如式(1)所示:
(1)
式中:Pi为某组分纤维质量百分比,%;Ni为某组分纤维的计数根数;Di为某组分纤维平均直径,μm;Si为某组分纤维平均直径标准差,μm;ρi为某组分纤维的密度,g/cm3。
采用显微镜直接观测法测量混纺织物中纤维直径,以液体石蜡作为分散介质制备纤维纵向切片,测试300根羊毛纤维和150根粘胶纤维的直径,测得样布中D粘胶为13.91 μm,S粘胶为2.51 μm;D羊毛为22.62 μm,S羊毛为8.60 μm。结合ρ粘胶为1.50 g/cm3,ρ羊毛为1.32 g/cm3计算织物混纺比[19]。
上述模型对同一毛/粘(50/50)混纺织物的3次独立测试结果如表1所示。3组混纺比检测结果与样品的名义混纺比差异值较小且都在2%以内,说明基于深度学习的毛/粘混纺织物混纺比检测具有较高的稳定性。

表1 基于深度学习技术的混纺比检测结果Tab.1 Blending ratio detection results based on deep learning technology
2.4 混纺比检测模型校验
依据GB/T 2910.4—2022《纺织品 定量化学分析 第4部分:某些蛋白质纤维与某些其他纤维的混合物(次氯酸盐法)》和GB/T 40905.1—2021《纺织品 山羊绒、绵羊毛、其他特种动物纤维及其混合物定量分析 第1部分:光学显微镜法》分别对毛/粘(50/50)混纺织物进行化学溶解法和光学显微镜法混纺比测定,不同检测方法测得混纺比差异值的计算公式如式(2)所示:
(2)

由表2可以看出,深度学习法与化学溶解法、光学显微镜法的混纺比差异值分别为0.1%和1.8%,且与名义混纺比相近,说明深度学习法的检测结果具有良好的可靠性。

表2 3种检测方法P羊毛/P粘胶检测结果对比Tab.2 Pi comparison results of the three testing methods
3 结束语
针对光学显微镜法和化学溶解法检测织物混纺比出现的效率低和污染问题,本文基于深度学习技术,研究了目标检测算法YOLOv5在毛/粘混纺织物混纺比检测上的应用。制备以纯水为分散介质的羊毛和粘胶纤维切片,构建纤维的光学显微镜图像数据集,将上述图像数据集引入到模型中训练与测试,并通过数据集扩充和在主干网络层嵌入卷积注意力模块进一步优化模型,使得模型对羊毛和粘胶纤维检测的平均精度均值达到0.93。用深度学习模型测得的市售的毛/粘混纺织物混纺比与名义混纺比差异在2%以内;在此基础上,用光学显微镜法和化学溶解法对深度学习模型进行校验,混纺比差异在2%以内,说明所开发的以YOLOv5为基础的毛/粘混纺织物混纺比检测模型具有一定的可靠性。在此基础上增加纤维数据集,可以进一步提高检测的准确性。
