基于DCGAN算法的服装效果图生成方法
2024-03-08郭宇轩
郭宇轩,孙 林
(大连工业大学 服装学院, 辽宁 大连 116034)
服装效果图是服装设计中的重要环节,设计师通过服装效果图表现服装款式、色彩以及材料,为后续成衣生产提供形象依据和设计方案[1]。互联网电商与快时尚产业的发展加速了时尚产品的迭代[2],消费者对个性化设计的需求增加,设计环节需要提高效率以适应快节奏的服装生产周期。传统的服装效果图绘制主要依赖设计师的设计灵感、个人审美和绘画技术,设计师常使用画笔或Photoshop等计算机软件进行人工绘制,需要消耗大量精力,导致出现设计方案片面、设计风格固化以及创意灵感匮乏等问题。
机器学习与深度学习算法在图像生成领域的应用为设计的智能化提供新的思考维度,生成对抗网络(Generative Adversarial Networks, GAN)算法及其衍生网络给予设计提供新的途径,在汽车造型设计[3]、迷彩图案设计[4]以及服装款式搭配[5]等领域均有应用。在服装设计领域,Wu等[6]提出的ClothGAN模型可生成带有敦煌元素的时尚服装;Tirtawan[7]提出的条件生成对抗网络(Conditional Generative Adversarial Networks, CGAN)能够生成蜡染图案服装;Ping等[8]提出了一种用于编辑上衣的衣领、袖长等属性的Fashion-AttGAN算法;任雨佳等[9]使用深度卷积对抗网络(Deep Convolutional Generative Adversarial Networks, DCGAN)进行小黑裙的款式设计,提出了服装款式个性化设计的方法。通过优化算法能够提高GAN模型的性能,王文靖等[10]对GAN系列模型的改进提高了生成服装图片的质量;Makkapati等[11]引入的对称损失优化 GAN 模型减少了训练时间。目前图像生成领域更加注重高分辨率图像生成,在图像质量提高的同时也增加了模型训练时间和训练难度[12]。
相较于深度置信网络(Deep Belief Networks,DBN)、变分编码器(Variational Auto-Encoder, VAE),GAN模型生成图像质量更高,生成数据更加多样[13]。DCGAN在GAN的基础上进行改进,能够更好地捕捉图像特征,相比于生成高清图像的StyleGAN模型,DCGAN的硬件要求与训练时间成本低,图像生成效率高[14]。服装效果图生成的任务重点是提取服装特征并快速表现服装色彩、款式以及人体,DCGAN模型可以较好平衡模型训练时间与图像质量的关系,其隐含空间(Latent Space)效应能大大丰富生成设计的多样性,适合执行快时尚类服装效果图生成任务。
本文提出一种基于DCGAN模型生成服装效果图的设计方法,通过整理时尚秀场数据集,调整和训练DCGAN模型提取服装色彩和款式特征,快速生成符合流行趋势的服装效果图供设计师参考,以期为服装设计的智能化与自动化提供新的途径。
1 生成对抗网络
GAN是2014年由Goodfellow等[15]提出的一种深度生成模型,网络结构由生成器(Generator)和判别器(Discriminator)构成。生成器通过学习真实图片生成假图片,判别器的目的是判断输入数据是来自真实数据分布还是来自生成器数据的分布,通过生成器与判别器相互博弈,最终生成器能生成出判别器判断不出真假的图像。GAN的目标函数定义为:
[logD(x)]+Ez~pz(z)[log(1-D(G(z)))]
式中:G表示生成器;D表示判别器;E表示期望值;V表示最大化2项之和;p表示概率分布;z表示输入服从正态分布的随机向量;x表示真实图片分布中的随样本;D(x)表示判别器判别输入真实图像为真的概率;D(G(z))表示判别器判别生成图像为真的概率。
2016年Radford等[16]在GAN的基础上提出DCGAN,DCGAN成功将卷积神经网络(Convolutional Neural Network, CNN)模型嵌入到 GAN 模型中。CNN可以更有效提取图像特征,提升模型生成图像的表达能力。以大量特定形态的现实图像作为训练数据时,DCGAN可以从大批量无标记的产品图像中学习到良好的中间特征,生成与真实产品具有相似特征的图像,从而衍生出新的设计方案[17]。DCGAN的隐含空间效应能使1张生成图像平滑地过渡成为另1张生成图像。在模型生成图像的过程中,2张生成图片间的过渡状态有可能将不同的服装色彩与款式映射在同一张生成图片中,形成原创的服装设计,因此本文选择DCGAN模型进行服装效果图生成实验。
2 服装效果图生成实验
2.1 实验流程框架
根据任务目标与实验流程构建如图1所示的服装效果图生成任务系统框架,整个系统框架包括数据集构建、模型训练、图像评价和交互设计4个部分。

图1 服装效果图生成任务系统框架Fig.1 Effect drawing generation task system framework
首先,对近年来自巴黎、米兰、伦敦、纽约的时装周秀场图片进行预处理与筛选后作为训练数据集训练DCGAN模型。模型训练开始前需要对原始DCGAN模型进行调整,在保留原有CNN模型的同时调整网络结构,提高生成图像分辨率,模型开始训练后由生成器提取新的服装效果图设计方案。图像评价由设计师完成,通过对生成图片进行主观筛选,评估模型生成图片效率和设计师满意度,设计师对生成图像的满意度是生成质量的重要参考标准。最后,设计师可以根据实际情况对生成图片进行主观调整和优化,通过交互设计的方式获得最终服装效果图。
2.2 数据集收集与预处理
选择2018—2023年巴黎、米兰、伦敦、纽约时装周的女装秀场图片作为训练数据来源,为保证生成图片人体特征的统一性,只选取秀场走姿模特图片作为训练集,手动去除站姿、棚拍、艺术大片等图片,保证训练数据集具有较为统一的模特姿态。数据集并未通过人体边缘检测去除模特背景,意在保留服装和背景的整体协调性。训练开始前将所有数据集图片进行批量化预处理,获得42 287张分辨率为445×445的秀场图像,数据集部分样本如图2所示,由于预处理后图片比例纵向压缩,因此生成图像需要统一调整回正常比例。

图2 时尚秀场数据集部分样本Fig.2 Part sample of the fashion show dataset
2.3 DCGAN基本结构
DCGAN在GAN网络的基础上加入了CNN结构,生成器和判别器舍弃了CNN的池化层(pooling),判别器保留CNN的整体架构,由4个卷积层(Conv)和1个全连接层构成,全连接层使用Sigmoid函数作为激活函数,生成器则是将卷积层替换成了转置卷积(ConvTranspose),通过输入100维的随机正态分布向量合成3通道彩色图像,输出层使用 Tanh 激活函数。生成器和判别器网络结构中均加入批量标准化层(BatchNormalization),使得网络更容易训练。
2.4 DCGAN网络结构调整
经典DCGAN卷积神经网络输出的图像分辨率为64×64,由于较低的分辨率会导致生成图像细节模糊,因此需要调整网络结构提高生成图像的分辨率,同时保证真实图像的特征仍然能够被模型学习和提取。经典DCGAN卷积神经网络的卷积核(Kernel size)大小为 5×5,步长(Stride)大小为 2,本文方法主要修改生成器和判别器网络,通过增加1层卷积,并调整卷积核和步长以提高生成图像分辨率;卷积层考虑卷积核的大小能被步长整除,减少生成图像中存在的棋盘状伪影;生成器网络结构中使用卷积核4×4、步长为2,卷积核4×4、步长为1以及卷积核6×6、步长为3的3种转置卷积,生成分辨率为445×445的图像;为配合生成器,判别器网络结构需要做出相应调整,调整后的生成器与判别器网络结构如图3所示。

图3 调整后的生成器与判别器结构Fig.3 Modified Generator and Discriminator structure
3 模型训练与图像生成
3.1 实验环境配置
本文实验使用的编译语言为Python,Python解释器使用PyCharm,以 Pytorch作为深度学习框架。硬件环境:显卡型号 NVIDIA GeForce RTX 3080 Laptop GPU,CPU型号为 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz,显存大小16 G,内存大小16 G。
3.2 模型训练
通过多次参数调整和生成实验发现,随着训练次数不断增加,图像由最初的噪声逐渐出现人形轮廓和色块,在训练60轮(Epoch)后出现可以初步辨认的模特着装图像,但仍存在大量噪声。随着训练次数增加,扭曲模糊图案减少,背景与人物过渡较为和谐,训练进行至100个Epoch后服装轮廓与人体姿态较为清晰,200个Epoch后图像质量逐渐稳定。实验发现由于不同的训练参数设置,训练可能出现模型坍塌,生成全部为噪声的图像,虽然继续训练可能重新出现服装图像,但款式重复单一,效果较差。经过多次实验,综合考虑训练稳定与硬件限制,选择训练600个Epoch未出现坍塌的模型参数,学习率设置为0.000 3,训练过程中保存生成器生成的伪图像作为服装效果图的备选方案。
3.3 生成效果
数据集预处理时将图片比例调整为1∶1,因此模型生成服装效果图的人体比例也同样被压缩,需要将生成图像重新调整回原始图像比例,调整后生成的部分服装效果图如图4所示。大部分生成图像对于人体的姿态特征表现相对精确,画面呈现类似水彩技法的效果图表现方式,背景与模特有较强的区分,生成图像能够较好地表现富有垂感的面料与薄纱面料,部分生成图像能够形成面料肌理。生成服装效果图的服装廓形与色彩丰富且基本符合现代服装审美,能够减少设计师在服装款式与配色上的实验负担。虽然生成的服装模特脸部五官与手并不完美,但不影响效果图的整体表现力。

图4 DCGAN模型生成的部分服装效果图Fig.4 Part of effect drawing generated by DCGAN model
生成图像中存在隐含空间效应,效果图平滑转变为另一张效果图的中间状态仍然被生成和保存,如图5所示,过渡状态形成的具有混合特征的图像呈现出新的色彩搭配、服装廓形和背景图案。生成图像中存在的不规则、扭曲、色彩混沌等服装形态在正常情况下应视为不合格,但对于设计师而言,部分不规则图像能够提供创意灵感启发设计,仍然具有参考价值。

图5 生成图像隐含空间效应Fig.5 Latent space of the generated image
4 生成图像评价与交互设计
4.1 评价方法
模型训练过程中生成效果图的款式与色彩存在随机性和多样性,由于生成图像最终服务于设计师,因此需要服装设计师对生成图像进行评价。有效生成图像标准为服装模特形体较完整,服装款式与色彩符合当下流行趋势,并且能够启发设计师的设计灵感,辅助设计师完成设计表达。通过计算有效生成图像的占比,验证本文调整的DCGAN模型是否能够高效生成可供参考的有效服装效果图。
模型训练过程中每个Epoch训练时间约为536 s,每个Epoch训练生成704张效果图,模型训练过程中能够较为迅速的生成大量效果图作为备选图像。从模型训练0~300 Epoch中每间隔25个Epoch随机抽取36张款式不重复的生成服装效果图作为评估样本。评估人员由7名受过服装设计系统训练的服装设计师组成,其中男性3人,女性4人。设计师根据评价标准选择出具有设计参考价值的有效图像,统计结果去除选择有效图像数量最多和最少的2位设计师的极端数据,保留5位设计师的评价结果。每个Epoch有效图像比例为5位设计师选择有效图像数量平均值与评估样本量的比,统计结果如表1所示。
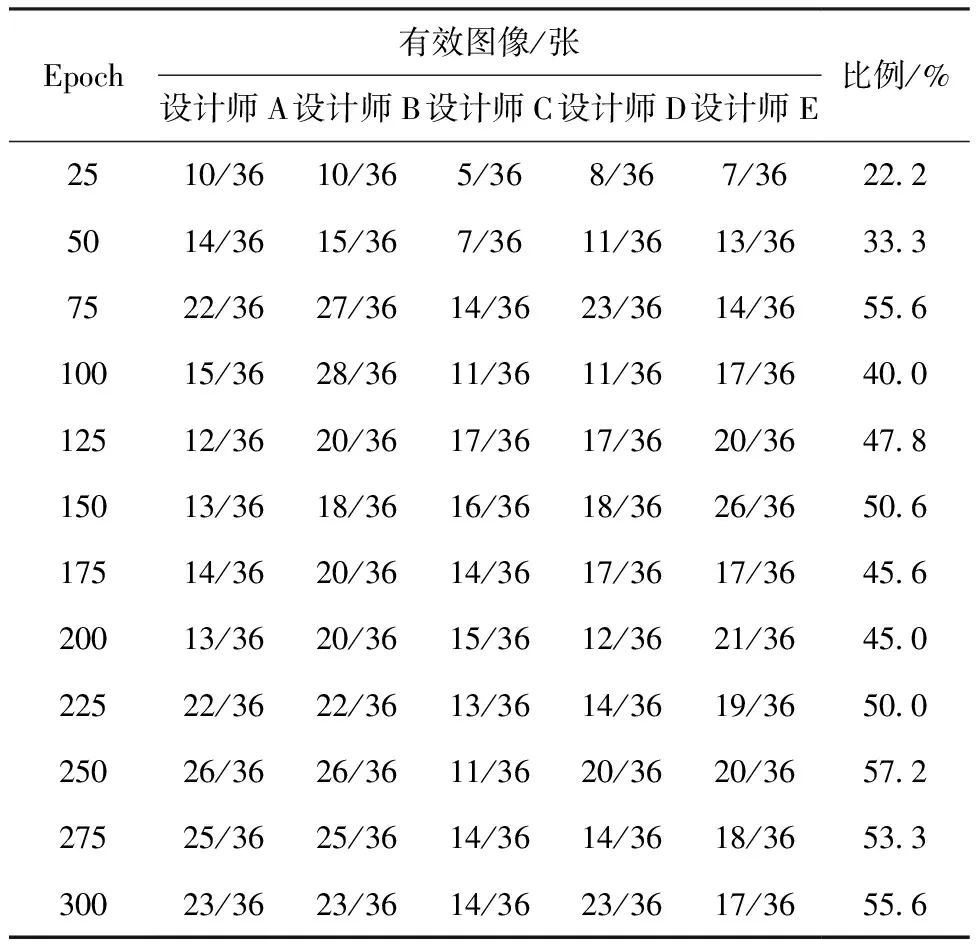
表1 有效生成图像调查表Tab.1 Effectively generate image surveys
由表1可知生成图像在0~75 Epoch中图像质量不断上升,75~200 Epoch由于模型训练波动导致生成图片质量不稳定,225个Epoch后有效图片占比基本稳定在50%以上,说明本文模型在训练稳定后生成的大量服装效果图中,超过半数的图像符合设计师的预期效果,为设计师提供多样化的服装款式和色彩设计参考,提高服装设计的效率。
4.2 人机交互设计
通过实验发现,DCGAN模型能够迅速学习秀场服装的色彩和款式生成服装效果图,节约服装设计师调研流行趋势和搜集灵感的时间,但由于生成图像分辨率和模型精度限制,服装结构细节需要设计师根据实际设计要求进行调整,在原始生成图像上进一步细化和明确,并根据生成图像提取服装款式与色彩,通过人机交互的方式形成设计方案,如图6所示。在生成图像保留流行趋势的同时加入设计师对于设计的理解,以设计师主导最终设计结果,可将DCGAN模型作为服装效果图辅助设计的新工具。
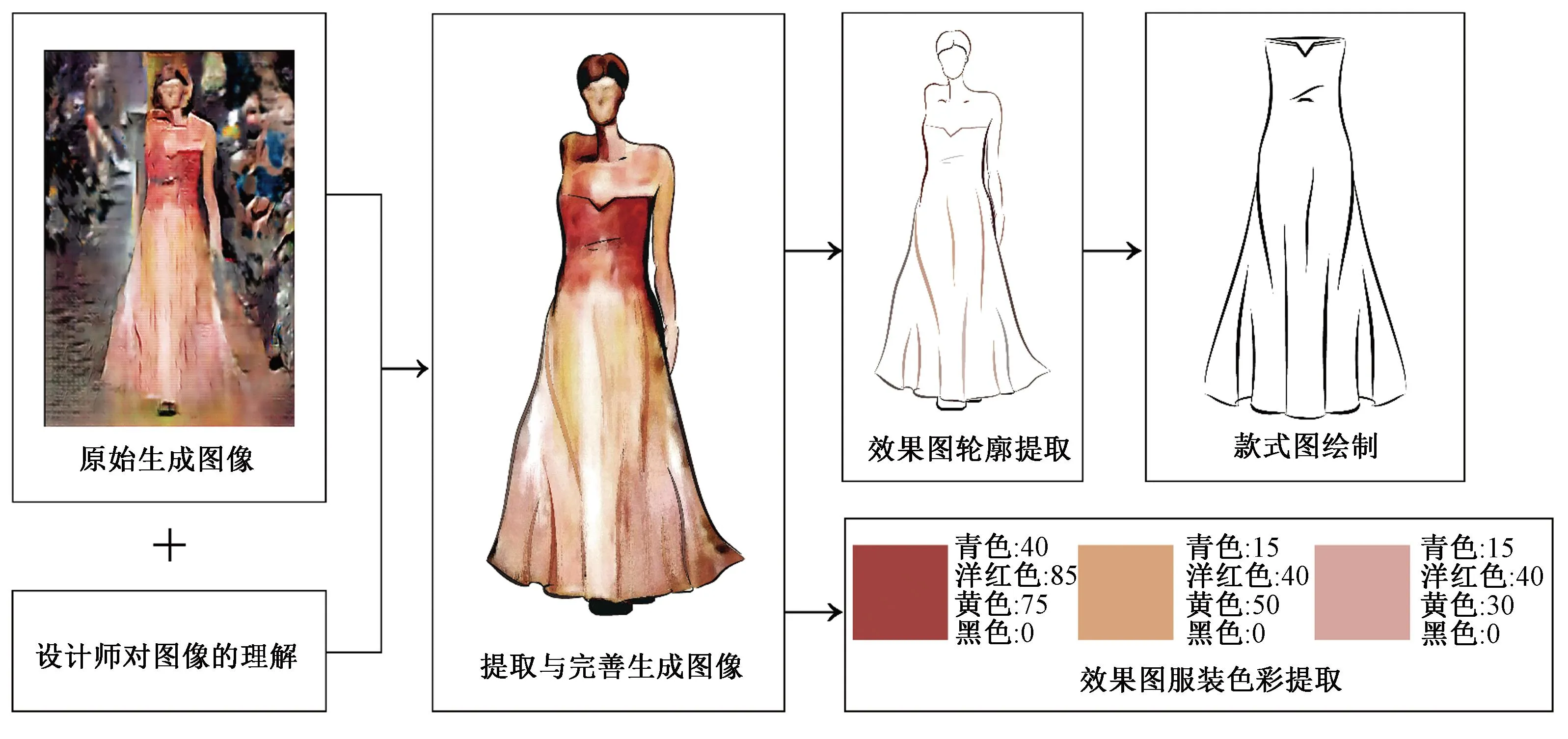
图6 人机交互设计流程Fig.6 Interactive design process
5 结束语
通过整理时尚秀场数据集,利用Pytorch深度学习框架,基于生成对抗网络GAN调整和训练深度卷积对抗网络DCGAN模型,并将其用于提取服装色彩和款式特征,最后进行服装效果图的生成实验和设计师评价。结果表明:通过调整的DCGAN模型进行训练后能够快速生成符合流行趋势的服装效果图,超过半数的生成图像符合设计师的预期效果,可为服装设计师提供灵感,提高设计效率。后续研究主要集中在训练数据集模特姿态与服装背景对生成图像的影响以及改进和优化生成对抗网络,提高生成设计方案的多样性与图像质量。未来服装企业可以根据设计目标和生产需求架构个性化的人工智能系统以提高设计效率,为消费者提供给更加多样化的时尚服装产品。
