基于改进Faster R-CNN的隧道衬砌中离散实体目标自动检测研究
2024-03-07崔广炎王艳辉丁冠军秦湘怡任秋阳
崔广炎,王艳辉,3,4,徐 杰,丁冠军,秦湘怡,任秋阳
(1.北京交通大学 先进轨道交通自主运行全国重点实验室,北京 100044;2.北京交通大学 交通运输学院,北京 100044;3.北京交通大学 北京市城市交通信息智能感知与服务工程技术研究中心,北京 100044;4.北京交通大学 城市轨道交通运营安全管理技术及装备交通运输行业研发中心,北京 100044)
隧道开裂、渗漏水、老化、沉降、钢筋缺失等一系列突出问题严重危害公路、铁路隧道的运营安全,因此对隧道基础设施质量的定期检测和维护势在必行。对于一些无法直接从表面观察且十分隐蔽、复杂的缺陷问题,使用常规的检测手段通常难以达到效果[1]。针对这类隐蔽缺陷问题,常使用无损检测技术进行解决,其中探地雷达因其高效、便捷、分辨率强等优势在隧道、桥梁、路基、路面、大坝等基础设施质量安全检测领域得以广泛应用,且探地雷达对于基础设施内部的孤立体目标检测效果尤为显著。在探地雷达剖面图像中,孤立体目标的雷达图像特征呈现离散分布状态,其雷达图像特征的尺寸面积较小且一般呈开口向下的半双曲线形状,对于具有此类特征的实心体目标可将其定义为离散实体目标。最为典型的离散实体目标如隧道衬砌结构中的钢筋、拱架等,离散实体目标的缺失直接危害隧道衬砌的质量安全,因此隧道工程领域常将衬砌内部钢筋和拱架的数量和位置检测作为验收指标。
尽管地质雷达无损检测技术能够对隧道衬砌中的离散实体目标进行有效检测[2],然而常规的雷达图像人工解译方法因主观性强、费时费力等缺点限制了地质雷达在隧道衬砌无损检测领域的进一步发展。面对这一卡脖子问题,众多科研技术者尝试利用现有人工智能技术进行雷达图像的自动解译研究。就目前来看,其研究思路主要分为两个方面,一种是以原始雷达数据为基础,利用机器学习算法进行数据预处理、特征提取和模式识别进而实现目标的自动检测,该方法可以很好地利用地质雷达其特有成像原理并充分发挥数据的优势,然而其难以实现对目标体的精准定位且解译效率较低。王艳辉等[3-4]提出一套基于遗传算法的隧道衬砌雷达剖面数据中多目标体自动检测的算法,实现了对仿真数据及实测数据中钢筋、管线及小型空洞的自动检测。周熙人等[5]提出一种GPR-B扫描图像自动解译模型来检测埋藏管线,该算法可实现对管线半径和埋深的预测,但是该算法处理流程较为烦琐且受雷达图像分辨率影响较大。
除此之外,另一种研究思路是利用现在逐渐成熟的深度学习算法对雷达图像进行特征提取、分类预测与回归损失计算,进而实现对雷达图像中离散实体目标的自动检测和定位。此类算法处理效率高且可对雷达图像进行直接处理,然而需要依托强有力的硬件系统和大量的图像数据投喂,其检测结果的精度也受到数据规模、网络结构和模型参数的影响。近年来,以深度学习为基础的目标检测方法已经逐渐成为研究热点。Barkataki等[6]在数据预处理阶段通过不同的边缘检测算子对原始雷达图像进行边缘检测处理,进而通过CNN(convolutional neural network)算法实现对雷达数据中的目标体尺寸(直径/半径)预测。Dinh等[7]提出一种包含两阶段的钢筋自动定位和检测的算法,首选通过常规的图像处理方法将有可能包含钢筋目标的位置定位出来,其次基于定位出的位置找到原始数据中对应的雷达图像,进而通过CNN算法进行分类。王静等[8]提出一个基于深度学习的自动检测框架(region deformable convolutional neural network, R2_DCNN),该方法包含可变形卷积、特征融合、旋转区域检测模型等三个模块,可实现对隧道衬砌内部钢筋和病害目标的检测。张军等[9]利用CNN_ResNet50的网络结构进行特征提取,在此基础上通过YOLOv2算法实现对图片数据中目标的自动识别和定位。许贵阳等[10]针对高度铁路中CRTSⅡ型轨道板裂缝伤损病害,提出一种基于改进的Faster R-CNN方法实现对裂缝伤损的定位检测。
目前关于隧道衬砌中离散实体目标检测的深度学习算法依然受到雷达图像分辨率、色泽亮度、目标体尺寸等因素的影响,存在错检、漏检或目标定位不够准确的问题,文献[11]显示现场实测雷达数据不足严重影响了后期深度学习框架的训练精度。因此,本文基于多年来现场收集到的隧道衬砌雷达数据,并结合正演模拟技术得到的仿真数据,通过几何变化的方法实现对数据的增强处理以构建离散实体目标自定义雷达数据集。基于此,本文提出一套改进的Faster R-CNN算法对隧道衬砌中不同尺寸的离散实体目标进行自动检测,以提升对隧道衬砌中离散实体目标检测效率及辨识精度,并为类似基础设施中隐蔽缺陷目标的定位检测提供技术支撑。
1 改进的Faster R-CNN算法框架
隧道衬砌中的离散实体目标分布随机且呈离散状态,在雷达图像中呈现半双曲线特征且尺寸较小,由于Faster R-CNN算法在对离散小目标体检测领域兼具速度和精度的优势[12-13],因此本文为实现对隧道衬砌雷达数据中离散实体目标的精准辨识,采用Faster R-CNN网络框架并对其特征提取模块和特征金字塔结构进行改进。该算法主要包含三个核心模块:特征提取模块(Backbone)、区域目标候选模块(RPN)和Fast R-CNN预测模块。
针对现有Faster R-CNN算法,许多学者对其进行了改进提升,如姚万业等[14]在进行行人检测时,以Soft-NMS算法代替传统的NMS算法并通过Hot Anchors代替均匀采样锚点以避免额外计算。王巍等[15]分别通过聚类分析和ROI Align对原有Faster R-CNN算法进行改进,以实现对算式批改的自动化处理。然而,这些改进更多地属于技巧性的改进,对原有算法的骨干网络并未进行本质性提升,而本文算法分别对特征提取网络和FPN模块进行了修改,以适应对隧道衬砌雷达图像中离散实体目标的检测。
1.1 整体网络框架
改进的Faster R-CNN算法整体框架流程见图1,首先对自定义数据集进行数据预处理,包括标准化[16]及数据增强,其中输入图片的宽高尺寸会被限制在[800,1 333]像素范围内,以防止因图片尺寸太小或太大而影响检测效果。然后,使用改进后的特征提取模块(ResNet_FMBConv)对预处理后的图片进行特征提取[17-18],进而通过改进的特征金字塔结构(feature pyramid network, FPN)可得到7种不同尺寸的特征矩阵。在RPN模块中,使用3×3的滑动窗口实现对目标候选框的分类损失和边界框回归损失计算(RPNHead)。结合锚框生成器得到的achors运用Softmax进行目标框滤除,判断锚框属于背景还是前景。对正负样本进行选择处理,并通过ROI(region of interest)池化层将其缩放到7×7大小的特征图,然后使用展平层和2个全连接层(two MLPhead)将计算得到的特征矩阵映射到样本标记空间中,最后通过Fast R-CNN预测模块实现对预测结果的分类损失计算与边界框回归损失修正。
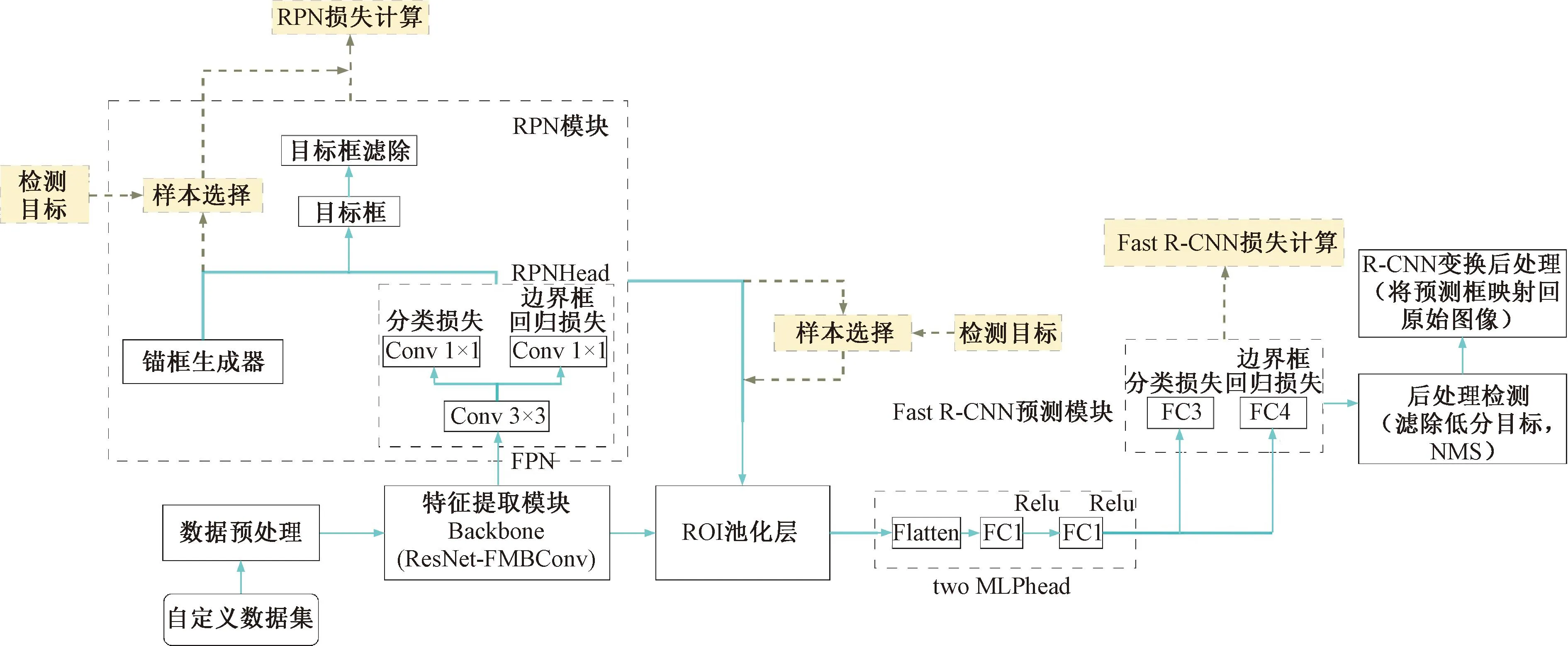
图1 改进的Faster R-CNN算法框架流程图
1.2 改进的特征提取模块
特征提取模块(backbone)作为Faster R-CNN网络的重要组成结构,其主要作用是对输入图像进行特征提取,常使用具有残差结构的Resnet-50网络[19]。然而,该网络结构对于隧道衬砌雷达图像此类目标尺寸较小且清晰度较低的图片数据特征提取效果不佳,且其计算参数较多,直接影响了Faster R-CNN网络的检测效率。鉴于此,本文借鉴EfficientNetV2[20]和MobileNetV3[21]网络的思想对Resnet-50网络进行改进,两款轻量级网络在保证检测精度的前提下可有效降低模型训练参数以提升检测效率。改进后的特征提取网络ResNet_FMBConv流程图见图2,共包含三个重要模块:Fused-MBConv、MBConv和SE(Squeeze-and-Excitation)模块[22]。该网络将Resnet-50网络的残差结构改进为卷积效果更佳的Fused-MBConv和MBConv模块,同时保持与Resnet-50网络同样的层结构以便于进行精度和效率验证。ResNet_FMBConv网络的模型参数见表1,以224×224×3的彩色RGB雷达图像为例,依次通过Convk7×7、Max poolk3×3、Fused-MBConv1,k3×3(3层)、Fused-MBConv4,k3×3(4层)、MBConv4,k3×3, SE0.25(6层)、MBConv6,k3×3, SE0.25(4层)和Conv1x1&Pooling&FC等操作符处理进而实现对图像的特征提取操作。其中,num_classes表示要分类的目标个数,k表示卷积核尺寸,SE表示注意力机制模块。

表1 ResNet_FMBConv网络模型参数表
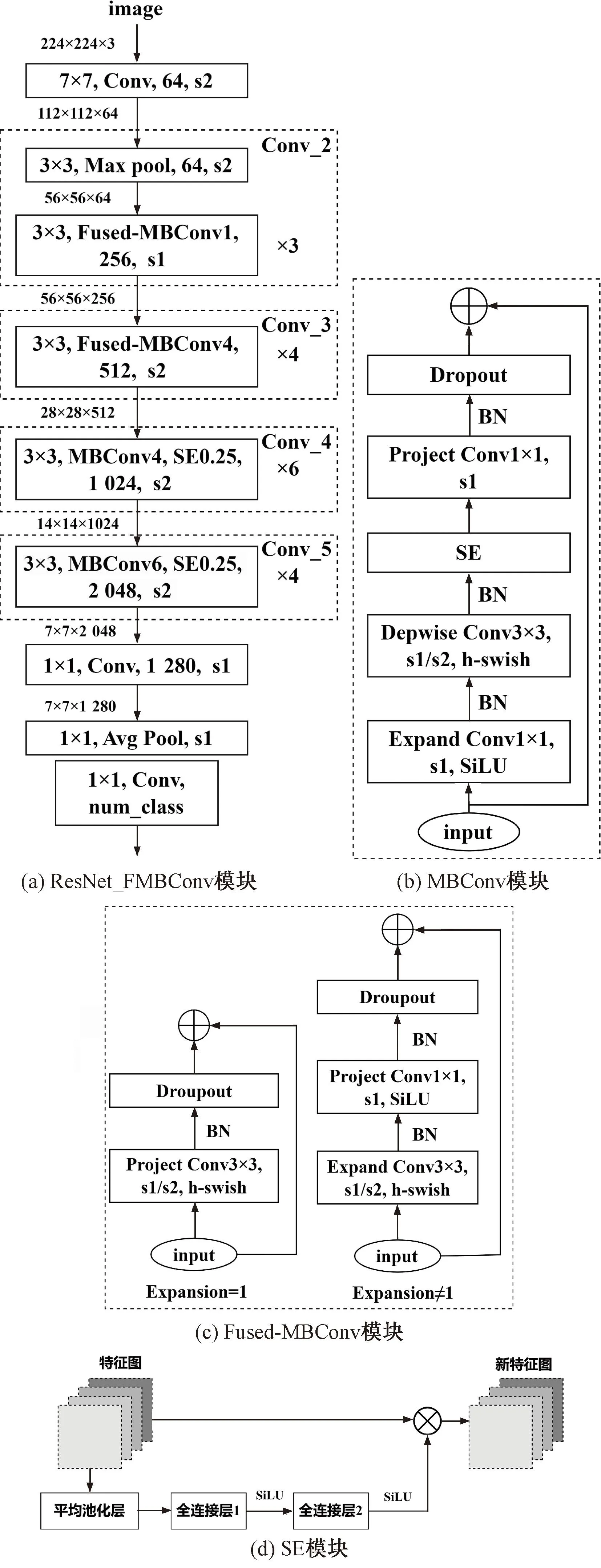
图2 改进的特征提取网络ResNet_FMBConv流程
激活函数在神经网络中通过非线性函数将神经元的输入映射到输出段,进而有效提升神经网络的非线性表达能力。因此,本研究对现有模块中的激活函数进行改进以提升模块的卷积性能,针对3×3卷积核采用h-swish激活函数,针对1×1卷积核采用SiLU激活函数(swish),针对SE模块中全连接层后的激活函数均采用SiLU激活函数。其中,SiLU激活函数是Sigmoid函数的加权线性组合,但是SiLU激活函数的计算求导较为复杂,对量化过程不友好,因此需对模块中的部分SiLU激活函数进行替换。由于h-sigmoid激活函数作为Sigmoid函数的替代[23],可以显著提高神经网络的准确性,因此可以将SiLU激活函数改写为h-swish激活函数。各激活函数计算式分别为
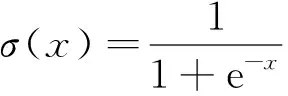
(1)
ReLU6(x)=min(max(x,0),6)
(2)
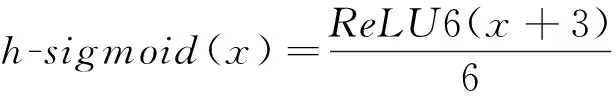
(3)
swishx=x·σ(x)
(4)
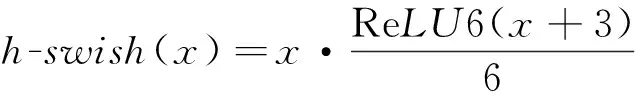
(5)
1.3 改进的特征金字塔结构
隧道衬砌雷达图像中的离散实体目标的尺寸会因雷达天线频率、检测位置以及图像分辨率的不同而改变,因此对于不同尺寸的检测目标可采用特征金字塔结构(FPN)[24]深度挖掘目标体的特征信息。高层的特征包含丰富的语义信息,但分辨率较低,难以准确保存物体的位置信息。与之相反,低层的特征语义信息较少,但分辨率高,因此可以准确地包含物体位置信息。而FPN可以将低层的特征和高层的特征进行融合,得到一个识别和定位都准确的目标检测系统。因此,借助FPN对不同尺寸目标在不同特征层进行精准预测,改进的具有FPN结构的ResNet_FMBConv_FPN网络模型见图3。由图3可知,该模型分别以Con2_x、Con3_x、Con4_x、Con5_x结构提取输出特征图C1、C2、C3和C4,并通过1×1的卷积核和上采样操作分别得到不同尺寸的特征图P2、P3、P4、P5。在P5基础上采用3×3卷积核得到特征图P6,再进一步通过h-swish激活函数和最大池化层操作得到特征图P7。在特征图P2~P7上使用3×3滑动窗口便可对不同尺寸目标进行目标框选,进而实现对不同尺寸检测目标的精准预测。

图3 改进的ResNet_FMBConv_FPN网络流程
2 自定义数据集构建
为检测改进的Faster R-CNN算法对隧道衬砌雷达数据中离散实体目标的检测效果,本研究利用隧道现场采集的真实雷达数据和GprMax正演模拟的仿真雷达数据共同构建离散单体目标自定义雷达数据集。通过数据增强处理,使数据集总量扩容至3 318 张,其中真实图片3 118 张,仿真图片200张,见图4。划分训练集∶测试集∶验证集的比例为6∶2∶2。实测雷达数据存储格式为.rd3格式,需要使用matgpr软件读取数据并转化为.mat数据格式,并使用imagesc()函数转化为.jpg图片。正演模拟脚本(.in文件)通过GprMax仿真软件[25]生成雷达图片。本文选择LabelImg软件将数据增强后的雷达图像标定为VOC模式(.xml文件),该软件是一个可视化的图像标定工具,基于Python编写,并用Qt实现图形界面。
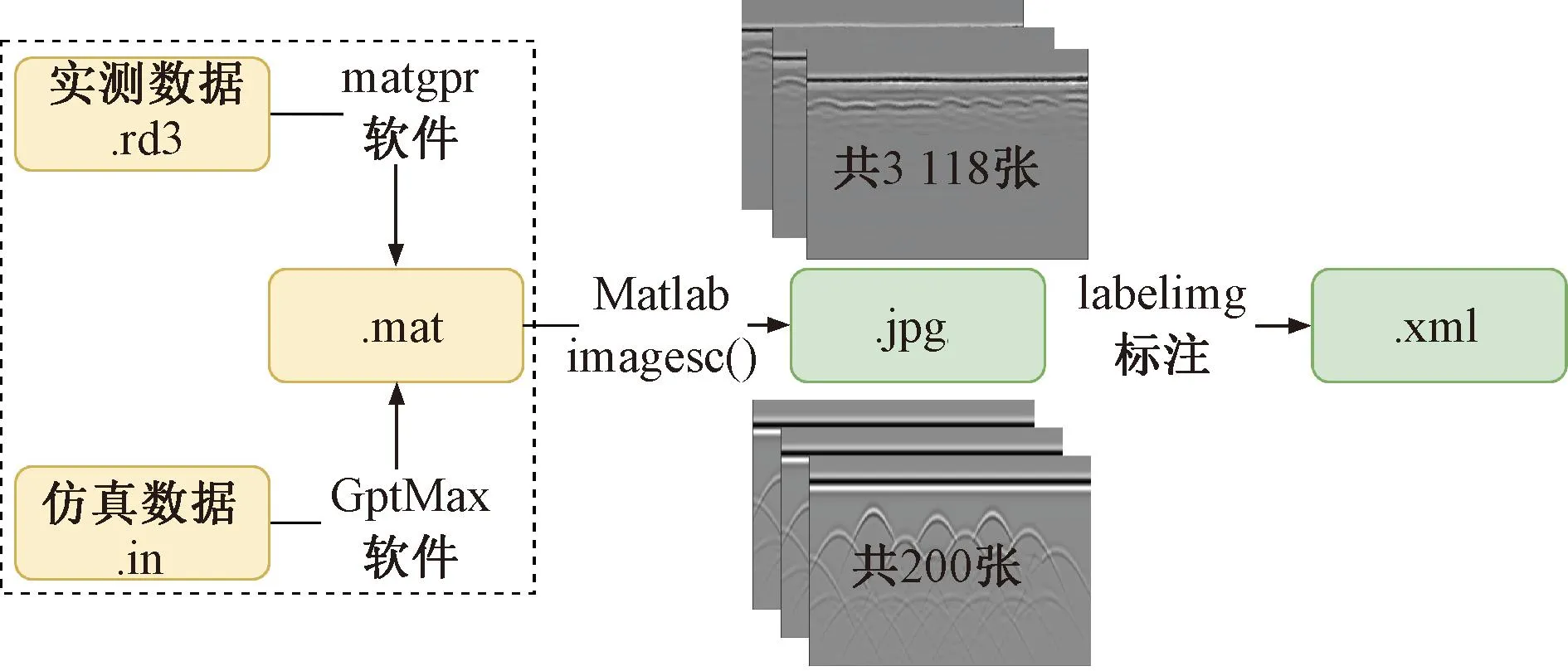
图4 自定义雷达数据集构建流程
2.1 数据来源
2.1.1 实测数据
本研究所使用的实测雷达数据均源于在隧道现场使用探地雷达设备检测得到的隧道二衬数据,经过试验分析可知当雷达天线为800、1 000、1 600 MHz时其对应雷达图像的分辨率较佳,因此本节构建的自定义雷达数据集主要包含此三种频率的雷达天线采集到的雷达图像。
受现场环境条件、雷达设备精度以及技术人员解译水平等因素的制约,部分雷达图像分辨率较差,无法显示检测目标的图像特征。因此,在进行实测数据标注处理时需对其进行筛选剔除处理,只保留探测目标的图像特征较为明显的数据样本。举例说明,该实测雷达数据(图5)采用瑞典RAMAC型探地雷达系统辅以800 MHz屏蔽天线进行检测,天线间距0.14 m,采样间距0.02 m,单道信号采样点512。

图5 隧道现场实测雷达数据
2.1.2 仿真数据
离散实体目标仿真试验模型见图6,模型尺寸为5.0 m×2.0 m×0.01 m内部设置多个离散实体目标,采用混凝土介质。编写相应的.in脚本文件,并使用GprMax仿真软件进行正演模拟,最后使用imagesc()函数得到雷达仿真图片,见图7。本研究共设计5组试验模拟隧道衬砌结构中的离散实体目标(单层钢筋和双层钢筋),试验参数见表2,其中x为钢筋水平方向坐标,y为钢筋深度方向坐标。

表2 仿真试验中钢筋布置信息
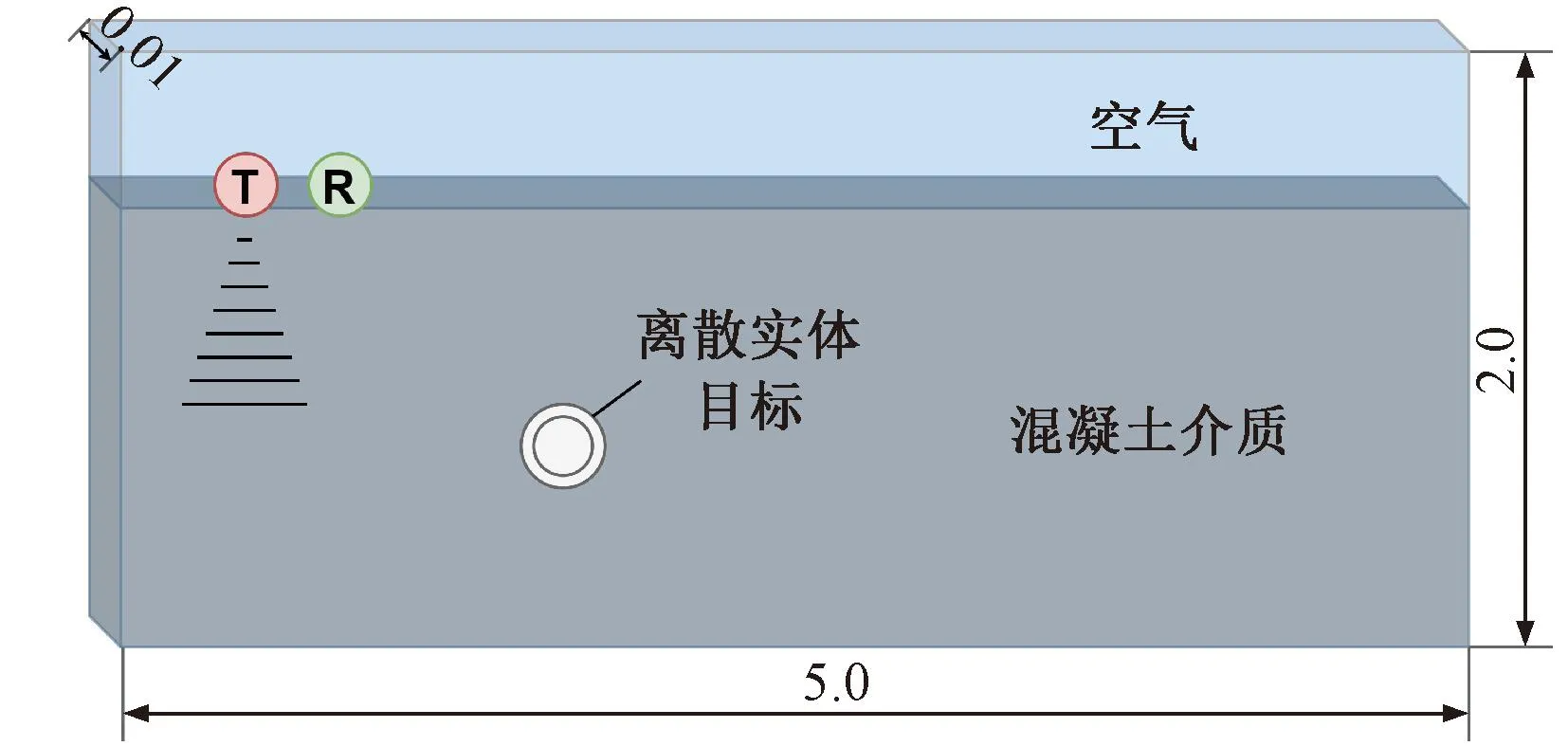
图6 离散实体目标仿真试验模型示意(单位:m)

图7 仿真试验雷达图像实例
2.2 数据增强处理
为扩充数据集,增加数据容量,采用翻转、旋转、裁剪和缩放等几何变换方法对雷达图像进行数据增强处理,见图8。对于那些对方向不敏感的任务,可以通过翻转、旋转操作实现对雷达图像的增强处理。旋转指的是围绕一个点,按照顺时针或者逆时针方向进行水平方向运动变化,而翻转则表示沿着对称轴,做一个对称轴图形。为了减少图像中无关成分的干扰,可以在训练的时候采用随机裁剪的方法去掉或减弱与主题无关的陪体,使画面主体更加鲜明集中,也可使画面的重心转移使之得到均衡。

图8 雷达图像数据增强示例
以上操作都不会导致图片失真,而缩放操作则会导致图片失真。多数情况下训练网络要求输入图片的尺寸大小是固定的,然而自定义数据集中的图像尺寸却大小不一,此时可选择裁剪或者缩放操作获得到网络要求输入的尺寸大小。缩放会产生失真,效果比裁剪差。在网络训练过程中,将图片缩放到800×1 330像素范围内,即对短边小于800像素或长边大于1 330像素的图片进行缩放。
3 试验与结果分析
3.1 评估指标
本文采用精准率Precision、召回率Recall和F1分数三个评价指标对模型的精度性能进行评价。精准率是指模型预测的所有目标中,预测正确的比例;召回率表示预测结果为正样本占全部真实样本的比例;F1分数被定义为精准率和召回率的调和平均数,取值范围为0~1,1代表模型的输出最好,0代表模型的输出结果最差。各指标的计算式分别为
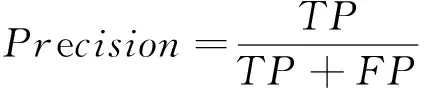
(6)
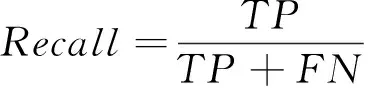
(7)

(8)
式中:TP为正样本被正确检测的数量;FP为正样本被错误检测的数量;FN为没有检测到目标的数量。
3.2 系统配置及训练步骤
本研究的硬件环境为RTX3080显卡,16GB内存,CPU为Intel(R)Xeon(R)Platinum8358P@ 2.60GHz,软件运行环境为PyTorch1.8.1,Python3.8(ubuntu18.04)以及Cuda11.1。整个训练过程主要分为两个阶段:①在预先训练好的ResNet_FMBConv结构的基础上训练RPN模块,然后使用训练好的RPN模块来获取初步的候选数据;②使用训练类别检测和位置校正模块来精确调整RPN模块生成的候选框位置,同时检测包含目标的候选框数据。为了防止数据的过拟合,增加了早期停止操作和随机丢弃方法(Drop-out)并采用冻结部分权重的方式提高整体训练效率,其余初始训练超参数见表3。
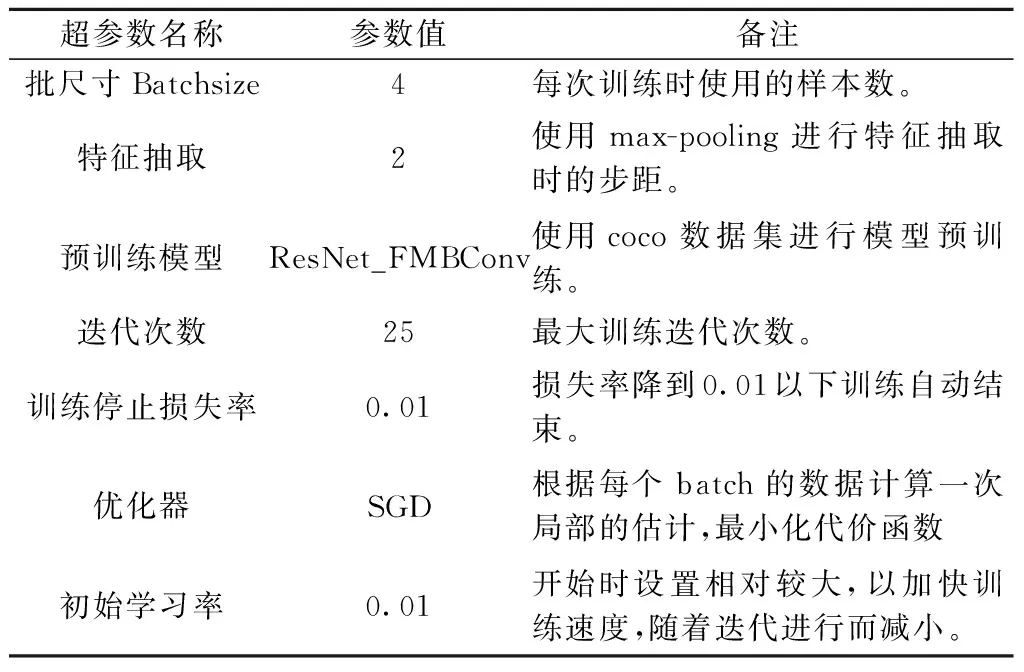
表3 初始训练超参数汇总表
3.3 数据增强前后检测结果对比
为了验证数据增强对于网络训练的效果,分别使用数据增强前后的数据集训练改进的Faster R-CNN网络。结果见表4。使用增强后的数据集训练网络,在IOU=0.50∶0.95情况下的检测精确率、召回率、F1分数三项评估指标均有2%~4%的提升。因此,可以说明本文给出的通过几何变化进行数据增强的方法可有效提升训练模型的辨识精度和检测性能。

表4 数据增强前后检测结果对比(IOU=0.50∶0.95)
改进的Faster R-CNN网络模型在数据增强后数据集上的训练损失与学习率随迭代次数的变化趋势见图9,图9中红色曲线表示模型训练的损失loss随迭代次数变化情况,可直接反映模型学习好坏的状态,蓝色曲线表示模型训练的学习率随迭代次数变化情况。本试验中学习率从0.01开始下降,一般随着学习率的调整,loss会越来越小。如果loss下降,说明模型还没完全学到数据的所有特征,模型会在这个学习率下继续学习;如果loss上升,说明模型已经充分学习到数据的特征,开始学习训练集里的无用特征,导致在测试集上准确度不够,产生过拟合。在Faster R-CNN网络训练过程中,随着迭代次数的增加,损失能迅速收敛,并在18个迭代次数epoch左右趋于稳定。模型在IOU=0.5时平均精确率mAP值随迭代次数的变化趋势图见图10,同样模型的mAP值在迭代至18个epoch左右趋于稳定,不再提升。因此,结果表明数据增强后的雷达图像数据可以用于模型的训练研究,且迭代次数设置为25次可得到最优的检测精度。
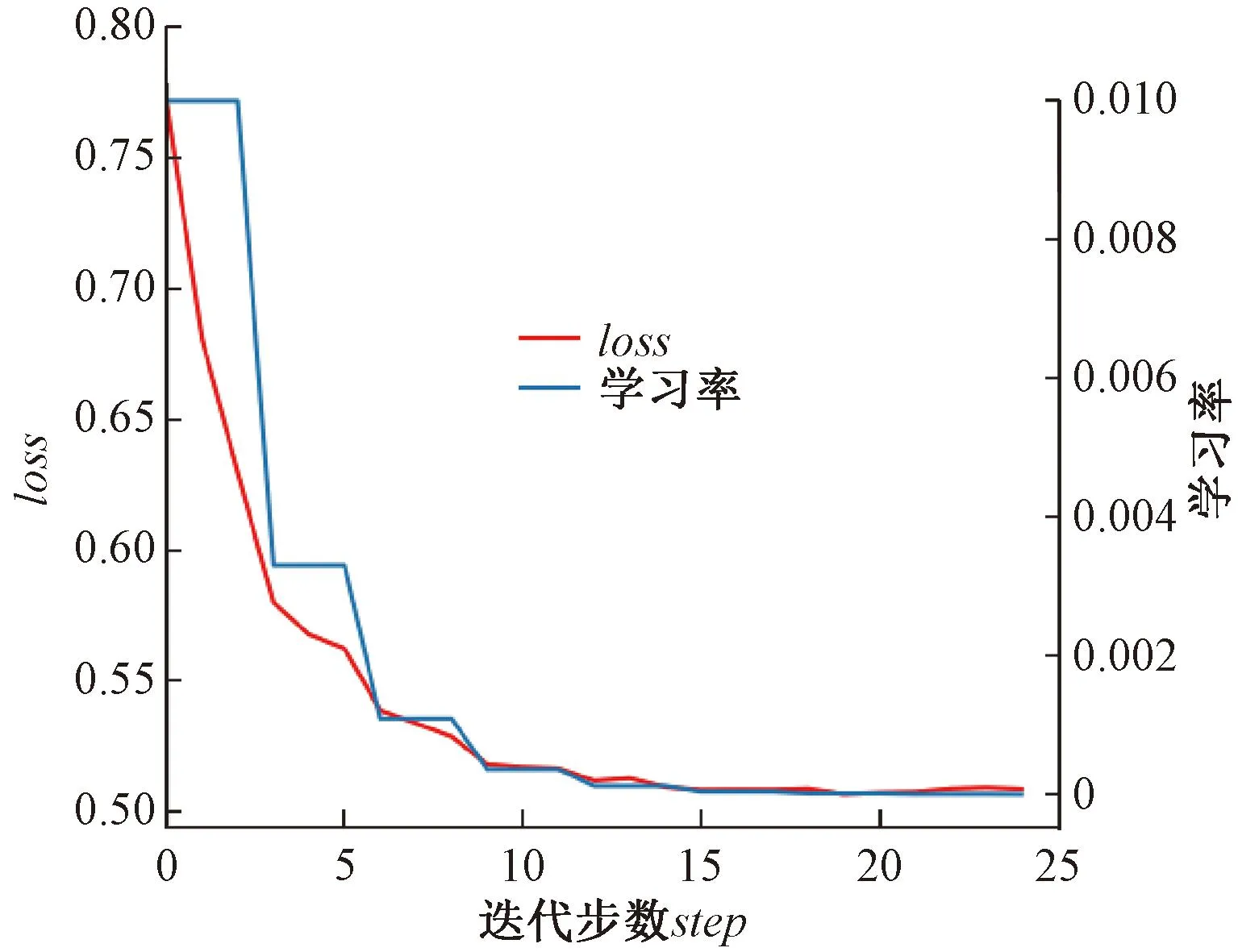
图9 模型训练损失及学习率变化趋势
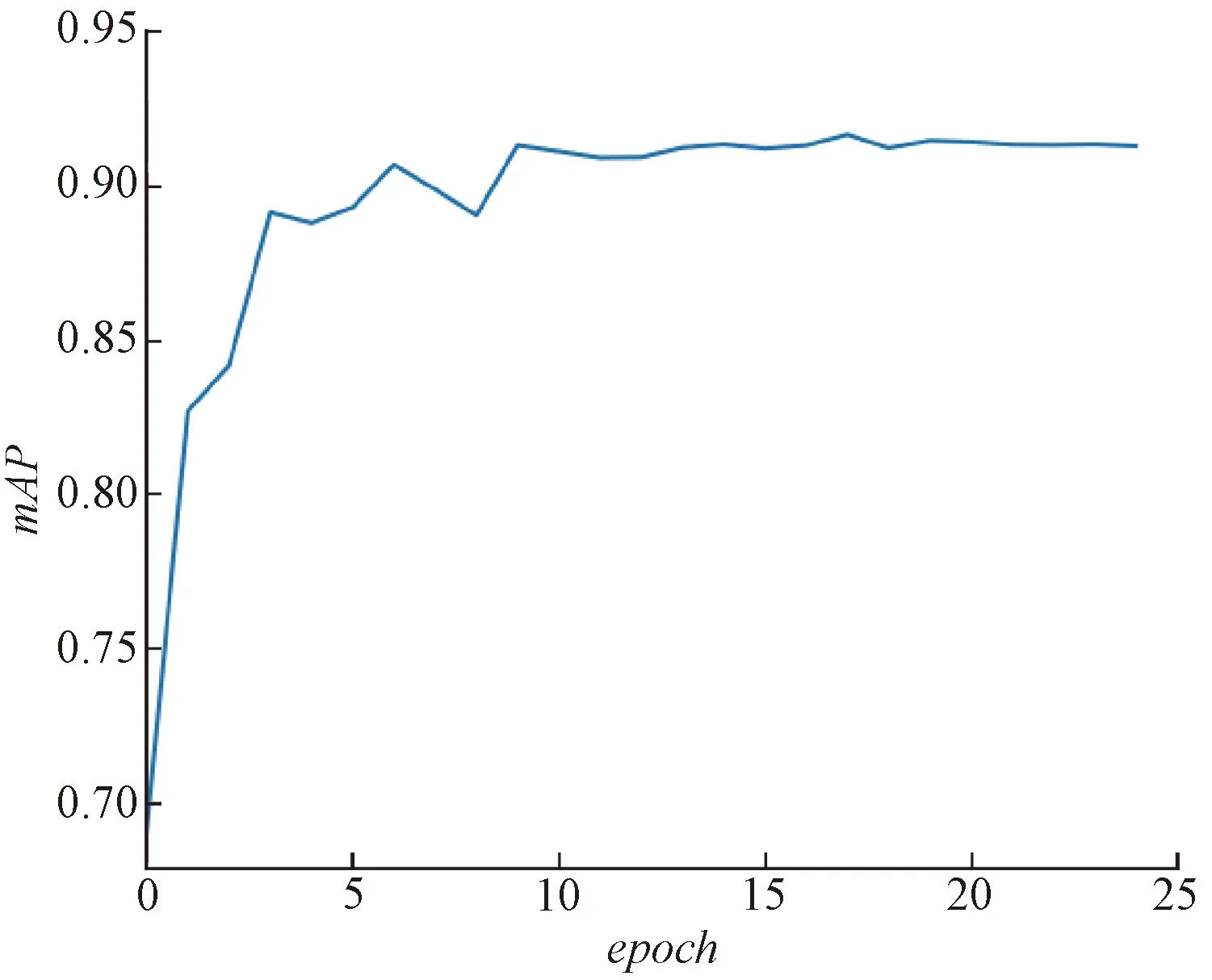
图10 模型mAP值变化趋势(IOU=0.5)
3.4 不同特征提取模块的检测结果对比
为了证明本文改进的特征提取模块ResNet_FMBConv的检测性能,试验以原有Faster R-CNN网络框架为基础,使用相同的数据集进行训练和测试,不同特征提取模块的检测结果见表5。ResNet_FMBConv_FPN模块的三项评估指标值均高于ResNet50_FPN、Efficientnet_b0_FPN、VGG16和Mobilenetv3_FPN网络,因此其检测性能更优。对比ResNet_FMBConv_FPN和ResNet_FMBConv模块,可见在增加FPN结构后,其检测精确率、召回率和F1分数指标的提升分别为13.7%、13.3%和13.7%。试验证明,本文改进的特征提取模块ResNet_FMBConv对离散实体目标的检测效果更佳。
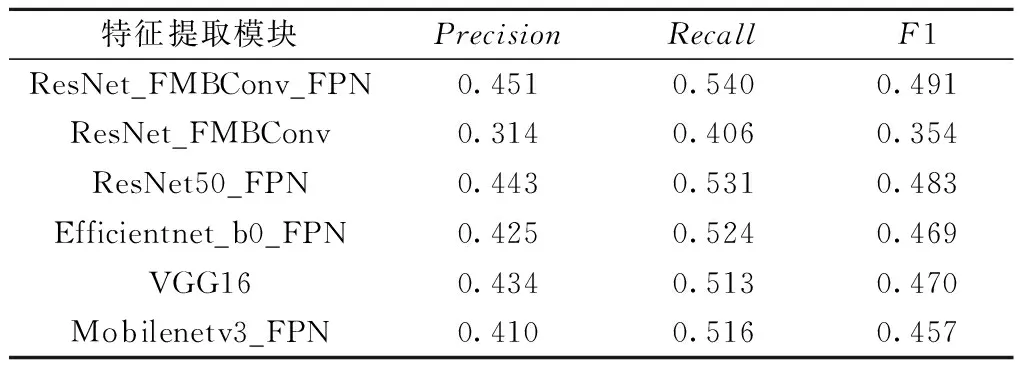
表5 不同特征提取模块的检测结果对比(IOU=0.50∶0.95)
3.5 与其他算法检测结果对比
为了验证改进的Faster R-CNN算法对离散实体目标检测的优越性,本小节另选择3种不同的深度学习算法SSD[26]、YOLOv3_spp[27]、Retinanet[28]算法进行比较。为了使算法尽可能地在相同的条件下进行比较,结合GPR图像的大小,将输入图像的大小缩放为734×547,而训练集、测试集、学习率参数和训练步骤等都是保持一致。四种算法均使用Pytorch深度学习框架,且增设FPS作为检测效率评估指标,检测结果见表6。在保证召回率基本持平的情况下,改进的Faster R-CNN算法的精确率和F1分数同比其他深度学习算法分别提升2%~9%和1%~6%,而YOLOv3_spp算法的精确率、召回率和F1分数指标值均最低。结果表明,就辨识效果而言本文改进的Faster R-CNN算法更适用于隧道衬砌中离散实体目标的自动检测研究。YOLOv3_spp作为一阶段算法要求对输入的图像进行缩放处理,因此在图像自动缩放的过程中容易造成图像失真,进而影响检测的精度。而SSD算法的参数较多,在进行训练过程中可能出现难以收敛的问题,导致实际检测效果不太理想。
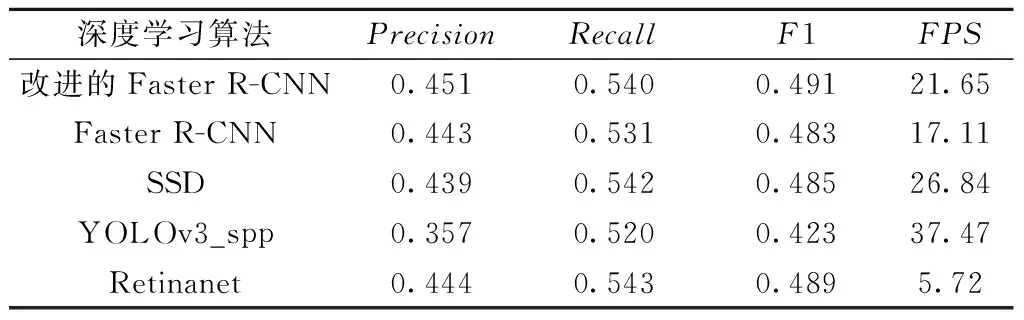
表6 不同深度学习算法的指标评估结果(IOU=0.50∶0.95)
同时本文还对比了不同算法的检测效率,YOLOv3_spp算法作为一阶段算法中的代表其处理速度最高为37.47 fps,改进的Faster R-CNN算法略低于YOLOv3_spp和SSD算法的检测速度为21.65 fps,而Retinanet算法的处理速度最低为5.72 fps。Faster R-CNN作为一种两阶段的算法,为更精准地辨识出检测目标,需要生成许多不同尺寸锚框并计算其分类损失和回归损失参数,因此会降低其检测效率。而SSD和YOLOv3_spp作为一阶段算法已经实现了端到端的处理,进而大大减少了参数计算的时间。在实际工程应用中,目标检测的准确性是进行隧道衬砌无损检测作业的首要考虑,因此在权衡检测速度和精度的情况下,本文将改进的Faster R-CNN作为隧道衬砌中离散实体目标自动检测优先选用的方法。
3.6 实例验证
为了更直观地对比不同算法对离散实体目标的检测效果,从测试集中各选取一张实测图片和一张仿真图片作为实例,通过预测模型进行离散实体目标的自动检测,见表7,红色圆框标注的为错误识别的目标体。

表7 不同深度学习算法对离散实体目标的检测结果
其中,实测数据和仿真数据中分别有9和17个离散实体目标(经人工解译确定),通过统计得到各算法对实例数据中目标体的正检、误检和漏检数,如表8所示。改进的Faster R-CNN算法可检测出全部9个目标体不存在误检,另外三种算法均存在漏检。针对双层钢筋的仿真数据,四种算法均可对最上层的目标体进行准确检测,但是对下层目标体的检测效果则较差,主要是因为下层离散实体目标的双曲线信号受上层信号干扰而变弱,进而影响其检测效果。其中,改进的Faster R-CNN算法正确检测的个数为15个,存在2个漏检目标。将表8中的指标进行计算,可到各算法对实例数据中目标体的正检率、误检率和漏检率,见表9。对比可知,改进的Faster R-CNN算法对实例数据中离散实体目标自动检测效果要优于其他三种算法,可用于今后隧道衬砌雷达数据中离散实体目标的自动检测研究。
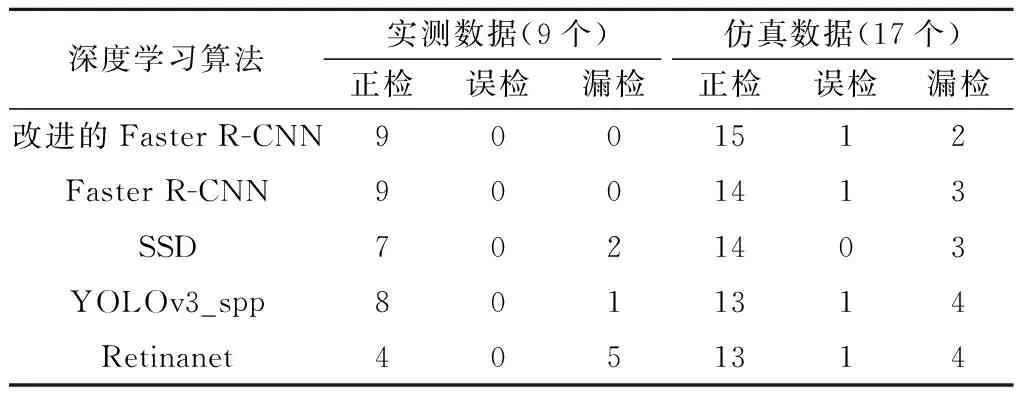
表8 不同深度学习算法对离散实体目标的检测结果
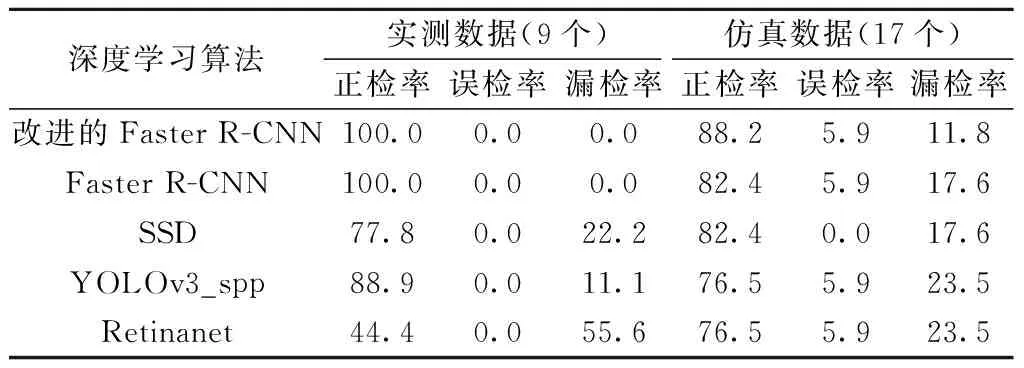
表9 不同深度学习算法对离散实体目标的检测结果对比 %
4 结论
本文提出的改进的Faster R-CNN算法有效提升了检测速度,能够对自定义雷达数据集中的离散实体目标进行准确辨识。当IOU=0.50∶0.95时,通过几何变化方法对雷达图像进行数据增强可有效提升改进算法的辨识性能,检测精确率、召回率和F1分数分别提升2.5%、2.4%和2.4%。同时,本文提出ResNet_FMBConv模块的检测精度和效率均优于Resnet-50、Efficientnet_b0和Mobilenetv3等目标分类网络。该算法与YOLOv3_spp、SSD等目标检测算法相比具有更高的检测精度,对于改进算法的检测精确率、召回率、F1分数和FPS分别为45.1%、54.0%、49.1%和21.65 fps。
尽管改进的Faster R-CNN算法在自定义雷达数据集上取得了良好的检测性能,但其检测结果仍然受限于雷达图像的分辨率、目标体图像特征完整性和重叠度。因此,在实际检测过程中提前清理干扰源、选择合适的天线频率和输入参数,以及在数据预处理过程选择合适的去噪步骤和参数均会提升最终获取的雷达图像分辨率和算法的检测性能。同时在未来的研究中,对于雷达图像中下层离散实体目标的准确辨识,可使用引导锚框对目标进行精准化检测。同时,可提前对锚框尺寸进行聚类分析,并在RPN模块中优化目标提取框的面积尺寸和长宽比例。
