基于OpenStack的高可用城轨云平台:设计、实现与可用性分析
2024-03-07李子恒
朱 力,李子恒,唐 涛,王 悉
(北京交通大学 轨道交通信号控制与安全国家重点实验室,北京 100044)
在我国城市轨道交通迅猛发展的态势下,城市轨道交通的运营及设备管理已成为行业部门关注的重点。传统城市轨道交通系统架构存在IT资源浪费、设备负载率高、不同系统数据共享困难等问题。如何在城轨规模扩大的同时,对城轨运营和应用设备进行统一管理维护,提高各系统的资源利用率及系统间数据交互的便捷性,并在保证系统设备可靠性的前提下,提高城轨交通的运输效率,是亟待解决的问题。
近年来,云计算技术,即一种IT基础设施的交付和使用模式,因其可以按照用户需求提供相应的基础设施资源,同时用户可“按需付费”使用对应资源而广泛地在各行各业得以应用。然而,由于城轨系统对于可靠性的要求较高[1],在城轨云计算产业建设过程中,云计算平台具有规模较大、结构复杂,云环境呈现高度动态的特点,单个节点的失效成为常态。应用云计算时,在云虚拟机环境中构建高可靠的应用服务同样是一个具有挑战性的关键研究问题。本文首先通过使用IaaS层面云平台技术——OpenStack构建高可靠城市轨道私有云平台。在此基础上利用故障树分析(fault tree analysis, FTA)工具及马尔科夫过程(Markov process)建模方法对承载轨道交通云应用的虚拟机进行可靠性分析及高可用研究,实现了单个虚拟机故障或节点故障时,云应用仍能对外提供服务的目标。最后,将城轨CBTC系统应用运行在高可用虚拟机上,并对虚拟机的可用性进行测试与评价,通过测试结果分析衡量虚拟机应用的可用性与可靠性。为轨道交通行业解绑传统架构软硬件束缚提供了技术与理论支撑[2]。
1 城轨云计算应用背景
当前我国大部分城市的城轨系统设备均采用“烟囱式”传统垂直架构体系,见图1。在这种架构下,不同系统具有各自独立的存储设备、管理工具及数据库,不同系统间无法共享资源,无法交互与访问,存在数据共享壁垒,容易造成信息孤岛与资源孤岛。

图1 传统轨道交通系统垂直架构体系
具体来说,传统架构现存问题可以总结为以下三点:
1)一条线路上车站级服务器占到服务器总数的90%以上,但大多数服务器CPU利用率低至5%,并且由于容错需求,服务器关键设备需要使用冗余备份的方式运行应用程序,这就造成了更多IT资源的浪费。
2)个别设备存在负载率较高的问题,均值超过70%,设备长期工作于高负载工况下,使用寿命大幅降低。
3)传统基于硬件架构的城轨系统不具备动态调整能力,随着线路规模不断扩大以及客流量的快速增长,使得城轨核心业务(列控系统、CCTV系统等)呈现爆发式增长,只能通过增加服务器数量来满足线路需求,大幅增加了企业开销。
传统城轨系统架构无法满足未来智慧城轨的发展目标,而云计算技术最显著的优势是部署灵活,规模易于扩展,资源池化并按需分配。利用云计算的优势,可实现城市轨道交通物理硬件资源的最大化利用,避免出现某些设备资源过度占用,其他设备资源余量较多的情况,大幅减少了生产环境中的开支。此外,云计算还帮助城轨交通系统实现集中部署、集中监控、集中运维的需求,降低系统设备的运营维护成本。
就轨道交通行业云计算的应用研究来说,2012年,广州地铁开始搭建私有云的环境,是行业内首个上线投产云计算数据中心的城轨企业,首次利用基础架构和云强大运算能力打造弹性软件应用,为行业如何引入云计算建设和应用方面提供了有意义的尝试。2018年,武汉和呼和浩特被协会批准成为云计算的重点试点城市,南京、重庆、无锡、温州等一批城市也积极推进云平台建设和云上应用深化。
从2019年开始,云计算在实际城轨线路中的建设发展如雨后春笋一般不断呈现。目前,已有北京、上海、广州、深圳、武汉等这样运营线网规模较庞大的城市在部署和推动城轨云的建设,也有呼和浩特、太原等新兴地铁建设城市着手城轨云的建设。2019年9月,呼和浩特搭建了全球首个多线多业务系统的城轨云项目,从顶层设计入手,构建生产中心云平台、灾备中心云平台、站段云平台,为多系统提供IaaS服务,满足呼和浩特轨道交通1、2号线的建设要求。
城轨系统应用云计算,从传统架构转向云环境的过程中,需要考虑众多因素,如云计算提供资源的形式、云计算的交付模式、云环境的可靠性、云应用的可用性等。轨道交通行业的云业务主要面向企业内部,因此私有云是城轨企业主要的云平台建设模式。同时城轨行业正处于云服务建设的起步阶段,IaaS层交付基础设施和自动化运维能力是企业目前的刚需。
另一方面,依据《城市轨道交通云计算应用指南》的建议,城轨私有云平台应由中心云、站段云节点构成,计算资源池应配置为高可用(high availability, HA)形式以承载线网生产业务运行。实现高可用配置需从两个方面着手,即云节点高可用、云上虚拟机高可用。云计算服务器出现宕机时,应触发集群节点的切换,主机上的服务自动进行故障切换。当某个计算节点中的虚拟机运行状态异常也应触发虚拟机高可用切换,在其他正常运行的业务节点上快速恢复业务,从而保证城轨业务平稳运行。
因此,对于部署运行在IaaS层的城轨应用业务,实现云节点集群的高可用及业务所在虚拟机的高可用是保证故障后城轨业务不中断的必要条件,同时实现虚拟机高可用,在任何可能导致虚拟机异常崩溃的情况下,保证虚拟机承载的城轨应用负载具有能够被继续访问的能力是城轨业务可靠上云的重要保证。
2 主流云平台技术及云容错方法
云计算管理平台为构建云的基础架构服务,能让用户更好地管理云计算资源。一个功能完整、性能较优的云管平台应该具有以下特征:平台动态可扩展、资源按需分配、组件高可用、服务高性能、负载均衡等。
2.1 主流云平台技术
云计算这一概念在20世纪70年代已有了雏形,随后计算机技术的迅猛发展以及互联网行业的兴起,都在向这个概念不断靠拢,从而推动了云计算基础设施的发展。直到2006年3月亚马逊公司推出弹性计算云服务EC2,按用户使用的资源量进行收费,这一里程碑式的服务开启了云计算商业化的元年。同样,云计算在国内也掀起风波,2009年1月,阿里建立首个电商云计算中心。2011年阿里云官网上线,并发布阿里云的第一个ECS云服务器。直到今天,国内已涌现出诸如华为云、Z-Stack等众多优秀云计算厂商。
除了商用云平台,诸如CloudStack[3]、OpenStack、Kubernetes等开源的云计算平台管理项目也不断发展并成熟,使云平台的管理更加方便快捷。城轨系统应用开源云技术,能够让企业具有平台二次开发能力,并能够解绑商用云计算厂家,具有较大优势。以下将介绍两种常用的开源云平台管理技术。
2.1.1 Kubernetes
Kubernetes(K8s)是Google开发的一个容器编排引擎,是PaaS云平台代表,它在Docker的基础上,为容器化应用提供部署运行、资源调度、服务发现等一系列功能,提高了容器集群管理的便捷性。
K8s是一个完备的分布式系统支撑平台,具有完备的集群管理能力。开发人员可以在物理机或者虚拟机的K8s集群上运行容器化应用,满足容器化应用的环境依赖和运维需求,例如多个容器子进程并行协同工作、健康检查应用运行状态、应用实例的扩容缩容、共享存储卷、负载均衡、K8s版本滚动更新、日志查询、认证授权等功能[4]。同时K8s提供完善的管理工具,涵盖了包括开发、部署测试、运维监控在内的各个环节。这些都是K8s强大的优势所在。
2.1.2 OpenStack
OpenStack项目最早由NASA、Rackspace等在2010年合作推出,其宗旨在于帮助组织或者个人运行一个虚拟化计算或存储服务的云,为用户提供可扩展的、灵活的云计算服务。OpenStack云计算技术支持部署IaaS层的私有云平台,并具有开源的特点,企业或个人可以按照自身需求搭建功能丰富的云计算平台[5]。OpenStack的特点是模块功能由一系列组件通过松耦合集成,可以根据自身需求自行拓展相应功能的组件,有较大的弹性空间,并且OpenStack组件基于Rest-full API实现,易于二次开发。同时OpenStack也支持高可用形式部署,满足企业需求。目前,OpenStack已在全球IaaS领域占据主导地位。
OpenStack整体逻辑架构见图2,其中不同组件负责向集群和用户提供对应的功能。图中七个组件是OpenStack的核心组件,分别提供计算、对象存储、块存储、认证、网络、镜像存储和用户界面功能。除此之外,OpenStack还提供诸如监控、计费等功能[6]。每个组件本质上都是多个服务的集合,用户可以按照自身需求与资源总量将上述服务选择部署在一台主机或多台主机上,灵活扩展集群规模。
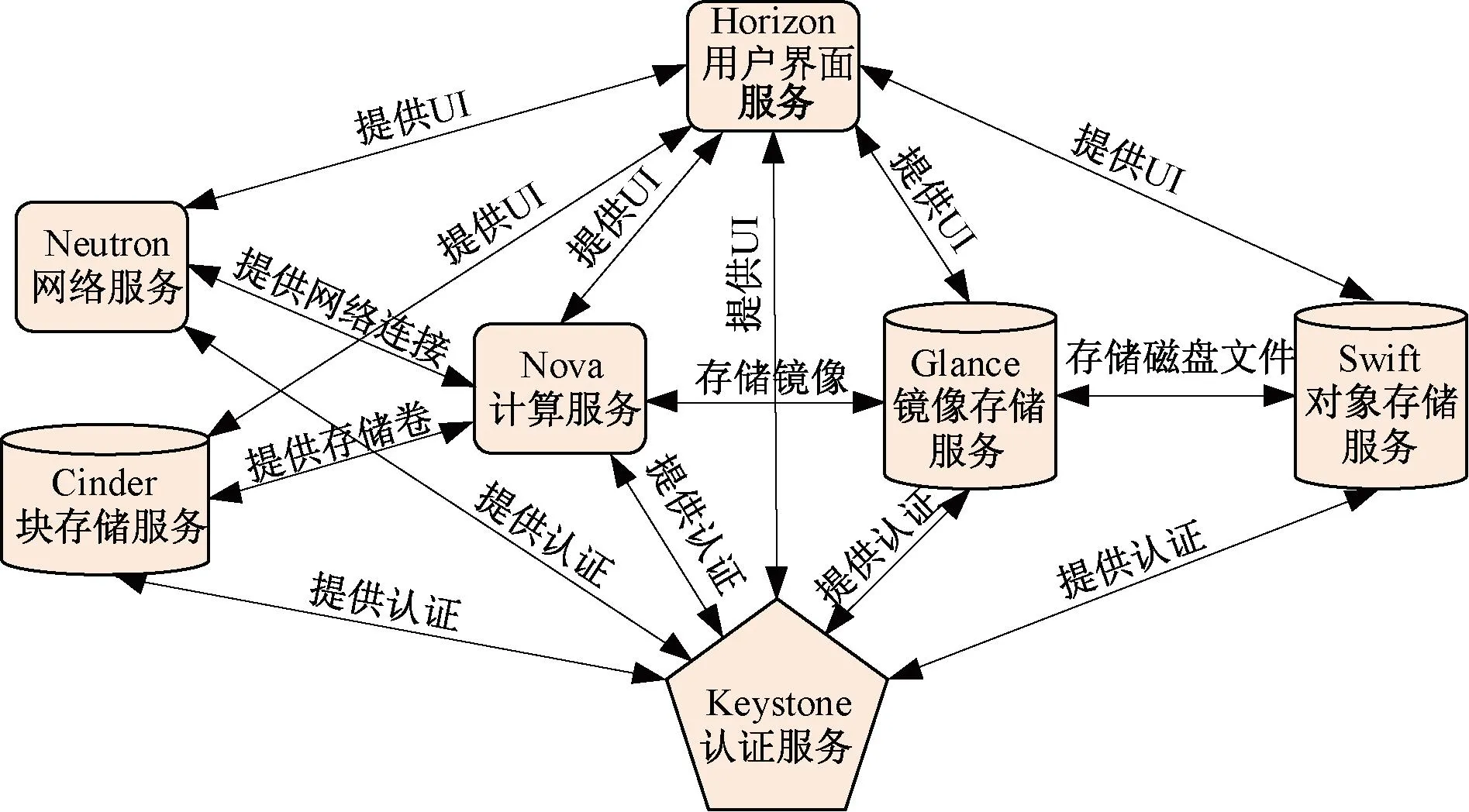
图2 OpenStack逻辑架构
2.2 云容错方法
容错是指在某个系统中出现错误或失效的情况下,能够继续提供服务的能力,是高可用技术的核心。为应对云平台潜在的失效风险,目前主要有两种标准的容错策略可用,分别是主动容错策略和被动容错策略。主动容错策略通过监控、风险感知等主动预防措施来避免失效,使用主动容错机制可以保证在应用服务失效前就识别到潜在风险。被动容错策略基于处理措施,即通过故障恢复手段,尽可能减少云系统中已经发生的失效所造成的严重后果。
2.2.1 主动容错策略
主动容错策略会根据系统的状态,判断当前可能会发生的失效情况,从而采取适当的手段预防失效的发生。主动容错技术包括预先迁移技术和软件恢复技术。预先迁移技术迁移需要持续监控云平台及虚拟机运行的状态,并不断分析虚拟机运行状态是否异常,在出现运行状态异常,但还未发生失效的情况下,集群将暂停虚拟机进程,记录其状态,将其从当前所在的物理节点转移到另一个节点并在该节点中恢复进程的操作,这其中包含一个检测与反馈的过程。
对于软件恢复技术,集群中虚拟机及与虚拟机运行相关的软件老化不可避免地会导致系统软件故障,因此可以主动应用软件再生技术避免潜在失效风险[7]。实际上,它是一种为系统安排定期重启的技术。每次重新启动后,系统将以干净可靠的状态运行。
2.2.2 被动容错策略
被动容错也叫作反应式容错,是指当系统故障形成错误后,采用合适的策略防止系统失效的发生。常用的被动容错技术包括检查点/重启机制和冗余机制。检查点技术允许云平台定期保存整个集群的运行状态为一个检查点,当集群中故障发生后,将最近的检查点恢复到整个集群中以实现容错。发生故障后,虚拟机将从检查点重新启动,而不是重建整个虚机。它是一种高效的容错技术,适用于托管在云中的高计算密集型虚拟机应用程序。
冗余机制是最流行的容错技术之一,可以根据当前场景的需求使用,将特定的服务或组件进行冗余配置。冗余技术一般分为主备模式以及主从模式。在主备模式下,正常情况下所有实例都在运行,由主机提供服务,数据同步至所有备机。当主机宕机后,备机启用,成为主机并接管服务。主从模式下同一时刻下多个实例提供服务,主从之间进行数据同步,保证主从之间信息一致,具备相同的系统状态。在虚机容错技术中,复制可以通过保持数据和服务的多个副本来实现。由于云环境中部署的应用服务通常包含大量组件,并且云中虚拟资源的获取较为容易,冗余机制通常是最多用来构建云节点及虚拟机的高可用策略。
3 高可用城轨私有云平台设计与实现
高可用城轨私有云分为两个部分:云平台高可用和虚拟机高可用。云平台高可用即保证为平台提供云服务的OpenStack组件具有高可用性,通常将集群组件运行在多个节点上,当某个节点的特定组件发生故障时,其他节点的该组件能够接替其继续工作,对外提供服务。云中虚拟机可以视为云组件所提供服务的具体实例,因此虚拟机的高可用建立在云平台高可用的基础上。同时,对于云上虚拟机来说,虚拟机内部故障和虚拟机所在物理节点的软硬件故障都有可能导致虚拟机失效,从而导致虚拟机中的应用无法正常工作[8],上述因素也是构建高可用虚拟机过程中需考虑的。本章介绍了实现完整的高可用城轨私有云所需的云平台和云上虚拟机高可用的整体设计架构及部署过程。
3.1 OpenStack平台高可用实现
OpenStack平台中虚拟机的功能由一系列组件提供,为实现IaaS平台的虚拟机高可用,首先需要实现平台集群高可用。原生OpenStack云平台的搭建过程中,整个平台主要由两个部分构成:控制节点和计算节点。控制节点通常被用来管理整个云平台,是OpenStack的控制中心。原生平台中一般设有一个控制节点,为保证高可用,则考虑控制节点的冗余,即部署两个以上的控制节点。计算节点负责为虚拟机提供内存、存储等资源,是虚拟机整个生命周期管理过程中必不可少的部分。
OpenStack高可用集群的整体框架见图3。
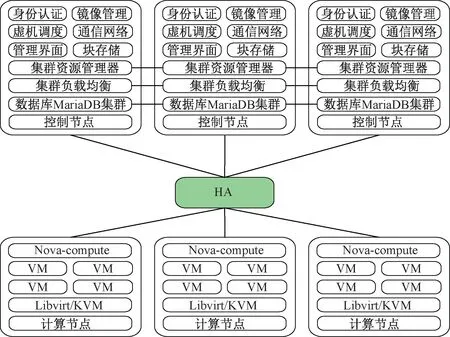
图3 高可用私有云平台架构
在集群中,控制节点随时监控集群全部资源的运行情况并进行资源启停、恢复和迁移等操作,因而集群中需要运行一个集群资源管理器,如Pacemaker。同时,高可用集群系统中的服务器通常被分为负载均衡服务器和真实服务器,负载均衡服务器用于分发用户请求给真实服务器,真实服务器接收到请求后会处理用户请求。高可用集群中每个服务均运行在多个节点上,以确保某个节点的服务失效时,用户的请求与命令仍能够到达某个正常运行的节点上[9]。为解决该问题,使用HAProxy作为高可用负载均衡代理服务器。以下分别对高可用平台搭建过程中关键工具Pacemaker及HAProxy进行介绍。
3.1.1 Pacemaker
传统的Linux高可用部署和目前OpenStack高可用集群部署中,最成熟的集群资源管理器方案是Pacemaker和Corosync的组合。在集群的高可用搭建中,全部控制节点上运行Pacemaker和Corosync进程,通过设置一个可漂移的虚拟IP(virtual IP, VIP)进行节点心跳通信和资源管理控制。任何运行在控制节点集群中的服务都可以设置为Active/Active模式或Active/Passive模式。
Pacemaker的架构由集群底层基础模块、集群无关组件和集群资源管理组件三部分组成。底层的基础架构模块向集群提供可靠的消息通信、集群成员关系等功能。集群无关组件主要包括资源本身及启动、关闭以及监控资源状态的脚本。集群资源管理组件包括集群资源管理器和资源代理控制系统,同时分布式锁管理器(distributed lock manager, DLM)利用Corosync所提供的集群消息和集群成员节点处理能力来实现系统集群,并对故障的服务或节点进行隔离操作。Pacemaker整体架构见图4(a)。

图4 Pacemaker与HAProxy逻辑架构
3.1.2 HAProxy
HAProxy开源软件能够为OpenStack云平台集群提供高可用与负载均衡支持,在TCP和HTTP的基础上实现应用代理,工作在七层以上,通过负载均衡算法,HAProxy能够接受大规模的访问请求并将其转发到后端服务器池中进行处理,分析数据包中的应用层协议并按照规则进行负载,对大规模的并发连接具有高可用性。HAProxy负载均衡架构见图4(b)。
3.2 OpenStack虚拟机高可用实现
OpenStack集群中,计算节点为虚拟机提供资源,对于虚机中的城轨业务来说,不仅需要考虑虚机自身的可靠性,还需考虑计算节点是否可靠。针对IaaS层云计算的高可用,目前的研究主要集中在如何实现控制节点的高可用上,对于计算节点,尤其是虚拟机的高可用研究较少。虚拟机高可用需考虑如何提高虚拟机在其运行过程中可用性。因此,实现虚拟机高可用需要在监控到虚拟机的运行状态和虚拟机所在主机的运行状态的前提下,考虑如何在虚拟机或主机故障后迁移并在新节点上恢复故障节点的虚拟机,最后再重新启动相关服务。本文通过在OpenStack集群的计算节点中将Pacemaker_remote和Masakari结合,构建云平台中的高可用虚拟机。
3.2.1 Pacemaker_remote
对于不同的OpenStack虚拟机HA方案而言,都离不开三个环节,即监控、隔离和恢复。在虚拟机HA中,监控需要实现两个任务,即虚拟机所在节点主机的故障监控和触发对于主机故障监控的相应操作(隔离和恢复等)。云集群中一般使用Pacemaker_remote实现节点监控功能。
Pacemaker_remote允许将计算节点作为控制节点Packmaker集群的一部分,实现节点监控功能,同时使其独立于控制层面的Corosync集群。计算节点组成的Pacemaker远程节点负责运行OpenStack计算服务并接受控制层面的调度控制,其上运行的服务资源接受Pacemaker的统一管理和调度。
隔离是服务故障监控后的首要操作,其目的在于将故障节点完全孤立隔开,排除在云平台集群之外。云集群在其他节点重新启动虚拟机之前,必须确保故障节点完全失去提供服务的能力,以避免同一个虚拟机在不同计算节点同时运行,产生错误。在节点隔离方面,Pacemaker已内置该功能。
一旦集群监控到故障行为并且故障节点已被隔离,下一步措施是触发虚拟机疏散并在其他计算节点上恢复虚拟机。OpenStack中提供专门API以将虚拟机由故障主机迁移至正常主机。同时为成功完成虚拟机的迁移,虚拟机用户的系统镜像必须位于共享存储中。迁移与疏散操作完成后,虚拟机的系统镜像和应用程序并没有改变,仅是在其他节点上由相同的镜像重新启动虚拟机,而虚拟机其他全部属性仍保持不变。
3.2.2 Masakari
由于上述虚拟机监控、隔离和恢复操作需要手动配置与操作,本研究中使用OpenStack中的Maskari虚拟机高可用方案。基于Masakari组件和Pacemaker_remote软件的整体虚拟机高可用架构见图5。该组件通过自动恢复失效的虚拟机为OpenStack提供实例高可用性服务。基于共享存储下,Masakari中Masakari-monitors和Pacemaker协同工作,检测虚拟机或者整个计算节点的故障,并尝试将其恢复。
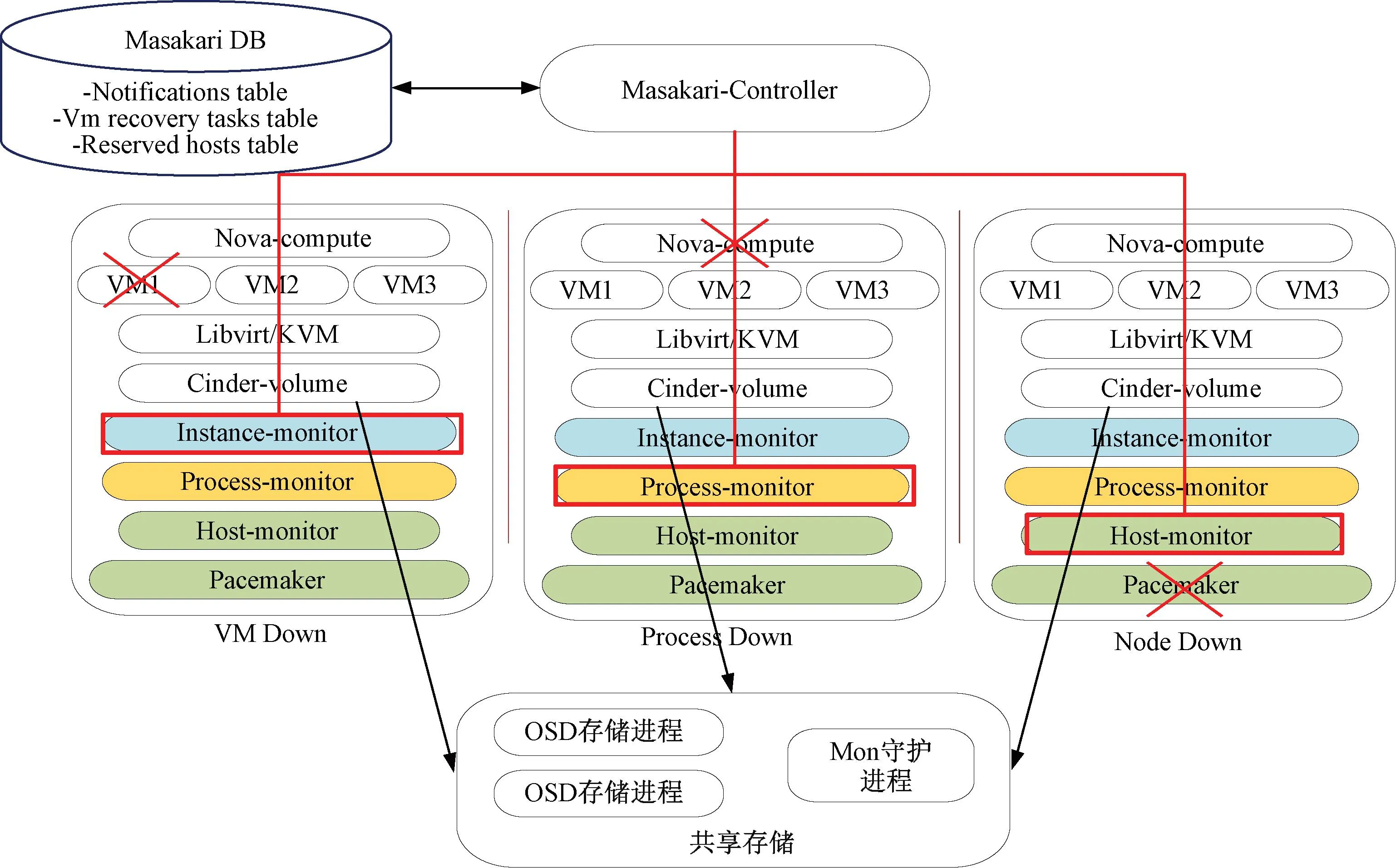
图5 虚拟机高可用架构
目前,Masakari可以从故障事件中恢复基于KVM的虚拟机,例如虚拟机进程关闭、配置进程关闭和Nova-compute服务所在主机故障以及其他一些节点故障情况。Masakari还提供监控服务API来管理和控制自动救援机制。当出现虚拟机自身异常或虚拟机进程异常的情况,Masakari将通过虚拟机的API关闭和重新启动虚拟机。当运行在计算节点上的KVM虚拟化进程异常,Masakari将设置Nova-compute服务为“down”状态,将节点隔离并启用虚拟机疏散机制。Masakari进行虚拟机的疏散操作同样需要共享存储提供集群间虚拟机镜像存储功能,以便完成虚拟机相关文件的复制。
4 云环境中虚拟机可靠性分析
OpenStack私有云平台中,虚拟机承载着云上城轨业务,业务本身的可用性与可靠性取决于虚拟机是否高可用与高可靠[10]。首先对影响平台虚拟机可靠性的因素进行分析,将失效因素用故障树模型描述;在建模得到失效率的基础上,通过马尔科夫状态转移分析法求得本文实现的高可用私有云平台的可用率。
4.1 可靠性分析基础
依据可靠性理论及云计算平台的特性,云计算的可靠性指标可从平台的可靠性及云上虚拟机的可靠性两个角度定义。转向云环境后,传统可靠性分析方法同样适用。可靠性研究中相关的技术指标与参数如下:
1)可靠度
可靠度是指系统从开始运行(t=0)到某时刻t这段时间里系统正常运行的概率。假设云系统符合随机失效过程,则可以用指数分布将其可靠度R(t)描述为
R(t)=P(T>t)=e-λt
(1)
式中:t为规定的时间范围;T为失效前时间;λ为系统失效率。
2)累积失效率和失效概率密度
累积失效概率是系统在规定条件下和时间t内,丧失规定功能的概率F(t),也称为不可靠度,通常表示为
F(t)=P(T≤t)=1-e-λt
(2)
失效概率密度是累计失效概率对t的导数,是系统单位时间内失效的概率,记为f(t),通常表示为
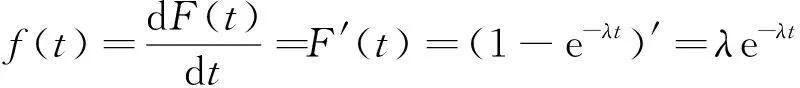
(3)
3)失效率
在可靠性分析中,失效率定义为工作到某一时刻t尚未失效的系统或产品[11],在该时刻后,单位时间内发生失效的概率,一般记为λ,它是时间t的函数,通常表示为

(4)
4)MTTF和MTBF
平均失效时间(meantimetofailure,MTTF)tMTTF指系统无故障运行的平均时间,为系统开始正常运行到发生故障之间的平均时间[12]。平均失效间隔时间(meantimebetweenfailure,MTBF)tMTBF是指系统两次故障发生时间之间的平均时间。平均修复时间(meantimetorepair,MTTR)tMTTR是指系统从发生故障到维修结束之间的平均时间[13]。MTTF与可靠度及失效率之间的关系为
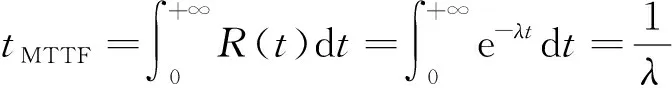
(5)
5)修复率和MTTR
修复率是指修理时间已达t时刻但尚未修复的产品在t时刻后单位时间内完成修复的概率,记为μ(t)。若维修概率服从指数分布,则修复率为常数μ(t)=μ。MTTR与修复率的关系可表示为

(6)
6)可用性(可用率)
可用性Availability是指在一个周期内,系统无故障运行的平均时间,由MTTF、MTBF和MTTR指标表示为

(7)
4.2 虚拟机可靠性分析
4.2.1 故障树建模分析
云环境中的失效,一般由单点故障导致。单点故障可以解释为一个系统中一旦失效,就可能引发整个系统产生故障风险的部件。为实现虚拟机的高可靠性,需要分析虚拟机潜在的单点故障。虚拟机的可靠性不同于云节点的可靠性,云节点失效通常由节点软件或硬件失效所导致。对于虚拟机而言,其硬件系统功能由计算节点所在物理服务器的软件模拟所得[14]。因此,虚拟机可靠性的分析可以从虚拟机运行时系统内部的故障、虚拟机所在计算节点的软硬件的故障考虑。同时,OpenStack计算节点所在服务与资源失效同样会对虚拟机的可靠性造成影响。
综上,将导致虚拟机失效的因素归纳为:虚拟机系统内部异常导致的故障、计算节点所提供资源不足导致的故障以及计算节点服务器软硬件失效导致的故障。在此基础上,通过故障树分析(faulttreeanalysis,FTA)法分析虚拟机的可靠性[15]。故障树分析法是一种将系统故障形成原因按树枝状逐级细化的图形演绎方法,主要包括:建立故障树、故障树的定性分析和故障树的定量分析。
定性分析的目的是寻找可能导致故障树顶事件发生的某个原因或某些原因的组合,以便能够发现该系统潜在的故障和安全隐患,进而指导人员进行系统维护与改进。故障树定量分析法的目的主要是通过基本事件故障的概率,计算顶事件发生的概率以及想要获取的可靠性指标。本文使用的定量分析法分析高可用云系统的可靠性。故障树分析中为计算顶事件的发生概率定义了割集与最小割集的概念,即故障树的一些底事件的集合,当这些事件同时发生时,顶事件必然会发生。若这个底事件的集合去掉任何一个底事件就不再成为割集,即为最小割集。每个最小割集是基本事件发生概率的乘积,不同最小割集之间是逻辑或的关系。因此有如下通过最小割集定义的顶事件概率。
设顶事件TOP=C1+C2+C3+…+Cn,C1到Cn为最小割集,则顶事件的发生概率Ptop为
[P(CiCjCk)+…+(-1)P(C1C2…Cn)]
(8)
式中:P(Ci)为每个最小割集发生的概率[16]。
由式(8)可知,当最小割集的数量比较庞大时,顶事件的计算较为复杂,因此近似计算顶事件发生概率为

(9)
本研究建立的虚拟机失效故障树模型见图6,三种中间失效因素分别表示为A、B和C。假设云环境中某个特定虚拟机发生这三种失效的概率为λA=λB=λC=λ*,图中基本事件的发生概率(即失效率)从左至右依次为λ1到λ13,假设每个基本事件相互独立,每个事件发生的概率相同,即为λ1=λ2=…=λ13=λ。此时中间事件E1、E3和E5的发生概率为E1=E3=E5=1-(1-λ)2,E2、E4和E6的发生概率为E2=E4=E6=λ2。则A、B和C的发生概率为A=B=C=λ3(2-λ)。由于该故障树最小割集较多,顶事件的概率计算会发生组合爆炸的问题。故在实际计算过程中,采用近似的方式进行计算,虚拟机失效概率PVM的近似计算式为

图6 高可用OpenStack云平台虚拟机故障树模型
式中:n为最小割集数量。
A、B和C中某个事件发生都有概率导致虚拟机失效,三个中间事件因素也会由E1到E6的子中间事件或基本事件发生导致。在找到可能导致虚拟机不可用的潜在失效风险后,需要使用本文介绍的云平台容错方法的方法防范这些风险的出现。
4.2.2 马尔科夫过程建模分析
马尔科夫过程可以描述为:对于一个系统,其按照一定概率从一个状态转移到另一个状态,该状态转移概率依据转移前的状态得到,和系统最初态及之前的转移过程无关。云环境中,高可用云平台最开始处于完美无故障运行的状态,随着时间推移,系统中节点依次故障,可用节点越来越少,直至所有节点故障,最终云平台失效无法继续对外提供服务的整个周期符合马尔科夫过程。
在基于马尔科夫方法的云可靠性模型中,马尔科夫方法的自身特性可能会导致系统状态组合的维数灾难,因此该方法适用于低复杂度或状态数量较少的系统的可靠性分析。在OpenStack云平台中,系统通常采用三控制节点高可用部署形式,所构建的云平台节点马尔科夫可用度模型见图7,该模型满足以下条件假设:
1)高可用云计算平台由三个独立的控制节点组成,各节点具有相同的失效率λ,以及故障修复率μ。
2)当云集群中某个节点故障时,设置在集群中的心跳脚本无法继续接收到该节点发送的心跳信息,在进行了节点仲裁后,集群管理器认定该节点失效,将其从集群中隔离,待该故障节点完成修复后,可重新将其加入集群。
3)当且仅当全部节点均失效宕机时,云平台无法继续提供包括虚拟机在内的云服务,在三节点云平台集群中,若至多有两个节点故障,则云上虚拟机仍然能够正常运行。
因此,云平台节点马尔科夫可用度模型包含四种状态:
状态0:所用节点正常运行,系统无故障工作,系统处于该状态的概率记为S0;状态1:一个节点故障,其余两个节点正常运行,系统无故障工作,系统处于该状态的概率记为S1;状态2:两个节点故障,剩余一个节点正常运行,系统无故障工作,系统处于该状态的概率记为S2;状态3:所有节点均故障不可用,云服务故障,系统处于该状态的概率记为S3。根据模型可以得出:系统处于四个状态的概率之和为1,即S0+S1+S2+S3=1。
根据图7的转移概率可以得到状态转移矩阵P为
状态转移矩阵每一行代表一个状态,矩阵P表示一段时间内系统由一种状态转移到另一状态的概率,是一步转移概率,P*P表示两步转移概率,当到达极限状态时Pn+1=Pn,此时状态空间不再发生改变,即(S0S1S2S3)=(S0S1S2S3)P,由此可得极限状态转移方程为
云环境中,系统在0、1和2状态时虚拟机均是可用的,若已知λ和μ的取值,则可以得到高可用系统的可用率为
Acloud=S0+S1+S2
(13)
5 高可用虚拟机性能测试及可用性分析
根据高可用架构完成集群整体的部署与配置,将CBTC系统运行在高可用虚拟机中,以实现真实完整的高可用轨道交通私有云。在此基础上进行故障恢复能力测试,并通过虚拟机迁移和疏散过程中的指标与现象计算与评价私有云的可用性。
5.1 高可用虚拟机应用
高可用轨道交通私有云中,虚拟机仅用来完成轨道交通业务而并不对外开放。目前,城市轨道交通CBTC系统,主要由车载设备系统、地面设备系统与数据传输系统三部分组成。车载设备主要由列车自动驾驶系统(ATO)、列车自动防护系统(ATP)等组成;地面设备主要由列车自动监控系统(ATS)、计算机联锁(CI)、区域控制器(ZC)组成。两种设备之间的双向通信通过骨干数据通信系统(DCS)完成,多种系统相互配合使CBTC系统的功能得以发挥。目前多数在建的城轨云平台中,大多数首先选择将非安全相关的CBTC子系统(如ATS)移植上云。
5.2 虚拟机故障恢复测试及可用性指标分析
通常虚拟机的高可用性体现在两个方面:①虚拟机热迁移过程中,业务不中断,用户不会感觉到迁移的进行;②节点故障后虚拟机疏散所用时间较短,疏散工作完成后虚拟机的业务也能快速恢复运行。以下在虚拟机热迁移和疏散两个场景进行故障恢复能力测试,以反映其可用性性能指标。
首先根据实际生产环境中常用的虚拟机类型与规格,在测试场景中分别使用安装了Windows10和Ubuntu18.04操作系统的虚拟机。两种虚拟机的规格参数如表1所示,测试结果见图8。

表1 两种规格虚拟机配置参数

图8 虚拟机热迁移及疏散测试结果
测试场景一:高可用组件检测到虚拟机自身或所在节点存在异常,可能导致失效风险。此时启动虚拟机热迁移,将虚拟机迁移到其他计算节点并将其重建。该项测试指标为从虚拟机迁移指令发出,到虚拟机状态再次变为Active的时间,对规格相同的虚拟机进行50次热迁移测试,测试结果见图8(a)、图8(c)。Windows10规格的虚拟机热迁移的平均时间为76.44 s,Ubuntu18.04虚拟机热迁移的平均时间为30.74 s。在迁移过程中虚拟机中的CBTC业务仍然正常运行,未出现宕机情况。
测试场景二:停止计算节点的云服务,模拟计算节点失效宕机。此时Masakari组件察觉到当前节点的失效故障,首先将该节点从集群中隔离出去,再发出虚拟机疏散命令,在其他正常节点重建虚拟机,此时虚拟机服务停止,待虚机重建完成后虚机中的服务再次正常运行。该项测试指标为从节点被隔离,到虚拟机重建后状态再次变为Active的时间。对同一台虚拟机进行50次热迁移测试,结果见图8(b)、图8(d),单台Windows10虚拟机的平均恢复时间为14.8 s,单台Ubuntu18.04虚拟机的平均恢复时间为7.69 s。
高可用云平台基于共享存储实现了虚拟机的热迁移功能,虚拟机热迁移过程中,虚机提供的业务不中断,云上应用仍然处于可用状态,相较于原生OpenStack平台中仅有的冷迁移功能(在计算节点之间迁移已关闭或已挂起的虚拟机,云上应用处于不可用状态),云环境的可用率大幅提高。
通过对Windows10虚拟机故障恢复数据的分析,根据4.2节中可靠性分析结果得到:μ=0.068,同时假设在云计算平台集群中,共有同一型号的1 000台服务器,在规定的条件下工作1 000 h,其中有10台出现故障,根据式(4)可得失效率定义为单位时间内服务器节点故障个数与试验到t时刻点还能工作的服务器节点数的比值,即λ=1×10-5,因此取λ=1×10-5/h,代入4.2.2节中极限状态转移方程,得到:S0=99.996%,S1=4.438×10-4,S2=6.567×10-8,S3=3.240×10-12。最终,云环境的可用率为Acloud=S0+S1+S2=99.999%。
假设云环境出现故障的可能性为1年1次,在宕机时间不超过5min的高可用要求下,该方案使得轨道交通云上应用具有较高可用性。此外,在测试场景中分别对λ和μ取不同的值,验证两个指标对于整个云集群环境可靠性与可用性的影响程度。
云系统可靠性的测试结果见图9(a),测试中云系统符合随机失效过程,由公式R(t)=P(T>t)=e-λt得到系统的可靠度,并在1 000h的测试过程中发现当λ>1×10-5/h时,随着时间推移所实现的OpenStack云集群将明显发生失效。云系统可用性的测试结果见图9(b),由图可知,在修复率μ相同的情况下,失效率λ的大小同样会对系统的可用性造成较大影响。

图9 集群可靠度与时间及可用性与修复率的关系
6 结论
1)本文将城市轨道交通系统与基于IaaS层面的OpenStack云计算平台相结合,实现了高可用OpenStack城轨私有云,包括私有云节点的高可用及平台中虚拟机的高可用。在此基础上,使用故障树分析法对云环境中虚拟机的可靠性进行建模分析,使用马尔科夫状态转移过程对云节点的失效转移情况进行分析,两种可靠性分析方法相结合,得到准确的可靠性与可用性分析结果。
2)本文提出两种虚拟机容错方法,最终在城轨云平台中实现虚拟机高可用,对虚拟机的可用性进行测试,通过迁移和疏散时长的测试结果得到系统的修复率,进而分析云平台的可靠性与可用性,说明实现云平台高可用及虚拟机高可用对应对失效风险的必要性,最终分析得出云环境虚拟机具有较高可用率。
3)本研究能够有效提升城轨云平台中虚拟机的可用性,但未对虚机内部运行的应用状态进行实时监测,未考虑虚拟机迁移对虚拟机中城轨系统应用运行质量的影响。同时,本研究也未使用诸如恢复时间目标(RTO)和恢复点目标(RPO)等高可用指标来衡量整体云环境的可用性的高低,在后续研究中需要完善。
