MS-2HCNN:基于深度学习的高光谱图像信号分类方法*
2024-03-06吕龙龙秦丽娜
吕龙龙,卢 伟,秦丽娜
(运城职业技术大学信创学院,山西 运城 044000)
高光谱图像是通过高光谱成像仪采集可见光区域到短红外光区域的光谱而获取的图像,由于成像光谱仪在许多相互邻接和部分重叠的狭窄光谱波段上同时收集地面的辐射数据,每个波段都包含了规定范围内电磁光谱的反射光值,因而波段数常常多达数十到数百。与普通图像相比,高光谱图像的分辨率极高,且辐射、空间和光谱信息十分丰富且精细。目前,高光谱遥感对地观测技术的应用十分普遍,例如精准农业、食品安全和国土安全等领域[1]。而高光谱图像应用的主要问题就是如何对高光谱图像信号进行分类。
不同于对自然图像的分类,高光谱图像分类的对象是图像中的每一个影像单元即像元,其目的是对所有像元预测进而分配指定标签[2]。然而,高光谱图像具有数据量大、维数众多、标记样本困难、高度非线性、波段多、波段间相关性强以及存在混合像元等特点,给其在分类与识别应用中带来了诸多挑战[3]。
之前的高光谱图像分类常常采用逻辑回归[4]、最近邻方法[5]、人工神经网络[6]和支持向量机[7]。然而由于:其一,高光谱图像维度往往比可用的训练样本的数量大得多,而传统的方法大都是从多光谱数据的应用中移植而来的,无力负担高光谱图像这样的高维数据处理带来的高计算量;其二,传统的方法常常需要人工设计特征,对先验知识的要求较高;其三,传统的方法通常只利用了地物的光谱特征,无法进行相当完备的特征提取,导致对高光谱图像中丰富的空间信息考虑不够完全,在分类时容易出现Hughes 现象[8]。
近年来也有许多基于深度学习的高光谱图像分类方法。文献[9]提出一种用于高光谱图像分类的堆叠式自动编码器(Stacked AutoEncode,SAE),该方法结合了主成分分析(Principal Component Analysis,PCA)降维、分层特征提取和逻辑回归分类。文献[10]通过逐层学习受限玻尔兹曼机(Restricted Boltzmann Machine,RBM),从而构建深度置信网络(Deep Belief Network,DBN)来对高光谱图像的光谱特征进行提取和分类。然而,SAE 和DBN 的不足之处在于其中含有许多全连接层,因此参数量巨大训练耗时。
与上述深度学习方法相比,卷积神经网络(Convolutional Neural Network,CNN)不但在高光谱图像的特征提取方面表现更好,而且其中的局部连接和权重共享机制能够更有效地提取空间信息,并进一步减少了参数数量。文献[11]提出了一种五层空间&光谱CNN,利用每个光谱波段的均值和标准差来获取相关特征。文献[12]结合PCA 构建了含有一维(One-Dimensional1D)、二维(Two-Dimensional,2D)和三维(Three-Dimensional3D)输入特征的CNN 模型,以分别从高光谱图像数据中提取空间特征,光谱特征和空间&光谱特征。文献[13]融合语义光谱空间信息和3D-CNN 来进行高光谱图像分类。3D-CNN 的优势在于其结构与三维高光谱立方体图像数据契合,同时容易获得目标像元的信息[14]。深度密集关联卷积神经网络(Deep Densely Associated CNN)和深度残差网络(Residual Network)同样是用于光谱空间分类的两种CNN 类型[15]。此外,CNN 与其他方法,如形态学剖面[16]、判别嵌入[17]和稀疏光谱表示[18]结合使用也可以提高分类性能。文献[19]中提出了一种可以利用高光谱图像数据中互补空间& 光谱信息的三阶段CNN 架构,其中的互补信息来源于综合层级的低级特征信息和语义层级的高级特征信息的结合。文献[13]提出了一种融合语义光谱&空间信息进行高光谱图像分类的CNN 方法。
在高光谱图像分类中,可以采用多种正则化策略来克服极易出现的过拟合问题,如L2 正则化、Dropout 和批量归一化(Batch Normalization/Batch Norm,BN)[20]。这些优化技术通过解决时间消耗问题和模型收敛问题,可以很好地提高CNN 模型的最终性能。此外,设计一个合适的CNN 架构优化器是构建和训练网络模型的关键。随机梯度下降方法(Stochastic Gradient Descent,SGD)是深度学习中最常使用的优化技术,它使用单个样本对网络梯度进行迭代更新,这种频繁更新的机制避免了模型陷入局部最小值的影响,但同时如此频繁地更新模型显然会耗费更多计算成本,导致训练时模型的方差较高。基于此,许多自适应优化器被提出来解决其不足,包括AdaGrad、AdaDelta、RmsProp、Adam 等[21]。在这些优化器中,Adam 是计算机视觉领域最常使用的优化器,但由于权重衰减等问题,它有时无法收敛到最优解[22]。与它们相比,AdaBound 的收敛速度快且泛化能力较强[23]。为了利用网络的不同层对空间&光谱信息的支持,希望有一种模型能够将光谱信息和空间信息结合起来学习,以充分利用两者之间的关系,这便是本文方法的启发与灵感。本文提出一个MS-2HCNN(Multi Stage-Heightened &Hyperspectral Convolutional Neural Network)以学习合并光谱&空间特征,并加深模型以进行高光谱图像数据的分类。在卷积块中进行多次卷积运算,从主要的两层中提取的特征被合并以作为输入提供给相邻层,从而从特征中提取出最有用的信息。在MS-2HCNN 中,设计了一个四阶段流程来合并和提取光谱&空间特征。最后,将所预测的特征输入到1×1 的全卷积层中,以获得较好的效果。基准数据集由于频带数量庞大,更容易出现过拟合问题。为了克服过拟合的问题,MS-2HCNN 采用了一种组合了SGD 和Adam 的优化器AdaBound。它使用动态的学习速率边界来实现从自适应学习速率到静态学习速率的渐进平稳过渡。AdaBound 优化器通过收敛步长提高了线性化过程的速度,同时也消除了过拟合的问题。此外,本文在MS-2HCNN 模型上比较了AdaGrad、AdaDelta、Adam 和AdaBound 等几种不同的自适应优化方法与SGD 的性能。
1 本文方法
1.1 基础构建介绍
CNN 是一类主要应用于计算机视觉的前馈人工神经网络[10]。如图1 所示,典型的CNN 是由许多堆叠的卷积层和池化层以及一个或多个全连接层(Fully Connected Layer)连接而成的[24]。CNN 通过加强连续层神经元之间的联系来表现局部连接,如当前层的输入神经元是前一层的输出神经元的子集。通过此前馈功能,输入的高光谱图像(Hyperspectral Input),经过CNN 从底层提取到的特征可以不断传递到上层。
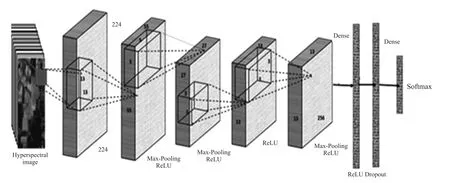
图1 用于高光谱图像分类的卷积神经网络典型结构
以下对CNN 进行介绍:
①卷积(Convolution):类似于数字信号处理中的1 维卷积操作,卷积神经网络中的卷积操作是通过利用滤波器来在输入图像/特征图的区间窗口中不断滚动而执行的复杂计算,而每个卷积操作生成的输出像素由区间窗口上输入像素的加权和组成。如式(1)所示:
②激活函数:激活函数是深度学习的重要组成部分,因为它可以将非线性特性引入到深度网络中,以进行输入到输出的复杂映射。ReLU(Rectified Linear Unit)是最常使用的激活函数之一,如式(2)所示,它将输入的负数值截断为零,同时保持正数值[25]。这样的形式使其相比于Sigmoid 和Tanh 可以很好地避免和纠正梯度消失问题。在本文的网络中使用ReLU 作为激活函数。
③池化层:池化层是模仿人的视觉系统对数据进行降维,用更高层次的特征表示图像。池化存在的意义有三:降低信息冗余;提升模型的尺度不变性、旋转不变性;防止过拟合。其中最常使用的池化为最大池化(Max Pooling)。
④BN 层:当数据中的特征具有不同的范围时,批量归一化操作可以使特征的数值处于相同的数量级,以加快梯度下降的速度,更快找到最优点,加快模型的训练。同时BN 使得网络可以省去或者减弱Dropout 比例与L2 正则化参数的惩罚因子:对Dropout 而言,经过BN 处理后,由于参数进行了归一化,因此神经元分布变得明显,经过一个激活函数以后,神经元会自动削弱或者去除一些神经元,就不用再对其进行Dropout;对L2 正则化而言,由于每次训练都进行了归一化,就会很少发生由于数据分布不同导致的参数变动过大问题。
⑤损失函数:损失函数可以用来估量CNN 模型的预测值与真实图像的不一致程度,它是一个非负实值函数,而一般来说损失函数越小,模型的鲁棒性就越好,越接近收敛。典型softmax 损失函数的输出由预测的输出图像与真值图像的交叉熵计算得到:
式中:Ls为损失函数;每个类标签的概率用g表示,如式(4)所示,输出概率之和为1;n为数据集中的类别个数;v为当前输入的实际标签的独热向量预测。
式中:x是根据输出层权值变化的线性参数,将输出g(x)归一化为1。
⑥优化器:对损失函数进行最小化的关键在于使用一个好的优化器,如AdaGrad、AdaDelta、RmsProp、Adam 等。同时优化器在构建基于深度卷积神经网络的模型中扮演着重要角色,其中的超参数分布于各层。为了进行后向传播以更新模型参数,目标函数需要最小化,从而使得迭代过程中的每个实际输出和预测输出都进行后向传播。优化器的目的是不断最小化交叉熵使其无限接近于零,从而使得预测输出逐渐收敛于实际输出。
这里对典型的优化器也是MS-2HCNN 在训练时使用的优化器AdaBound 进行介绍。为了实现从自适应优化器过渡到SGD 优化器的目标,AdaBound优化器在所需的学习速率上使用动态边界。这就约束了自适应优化器和SGD 优化器之间的泛化差异。它的主要优势之一是在训练的初始阶段可以保持更快的学习速度。α作为算法的起始步长,α/Vt为学习速率。AdaBound 优化器的过程如算法1 如示:
算法1 AdaBound 优化器
其中动量值β1=0.9,β2=0.99。学习率α/(vt)1/2的每个元素都如式(5)被截断,使ηu和ηl成为带约束输出,以避免梯度爆炸。
此外,参数更新的规律为:
由式(6),学习率可以一直进行修正,且上限与下限之间的差距有减小的趋势,导致AdaBound 优化器在初始阶段的功能像Adam[26],并最终在边界范围内转换为SGD。
1.2 MS-2HCNN
本文提出的MS-2HCNN 在进行高光谱图像分类时的流程如图2 所示。
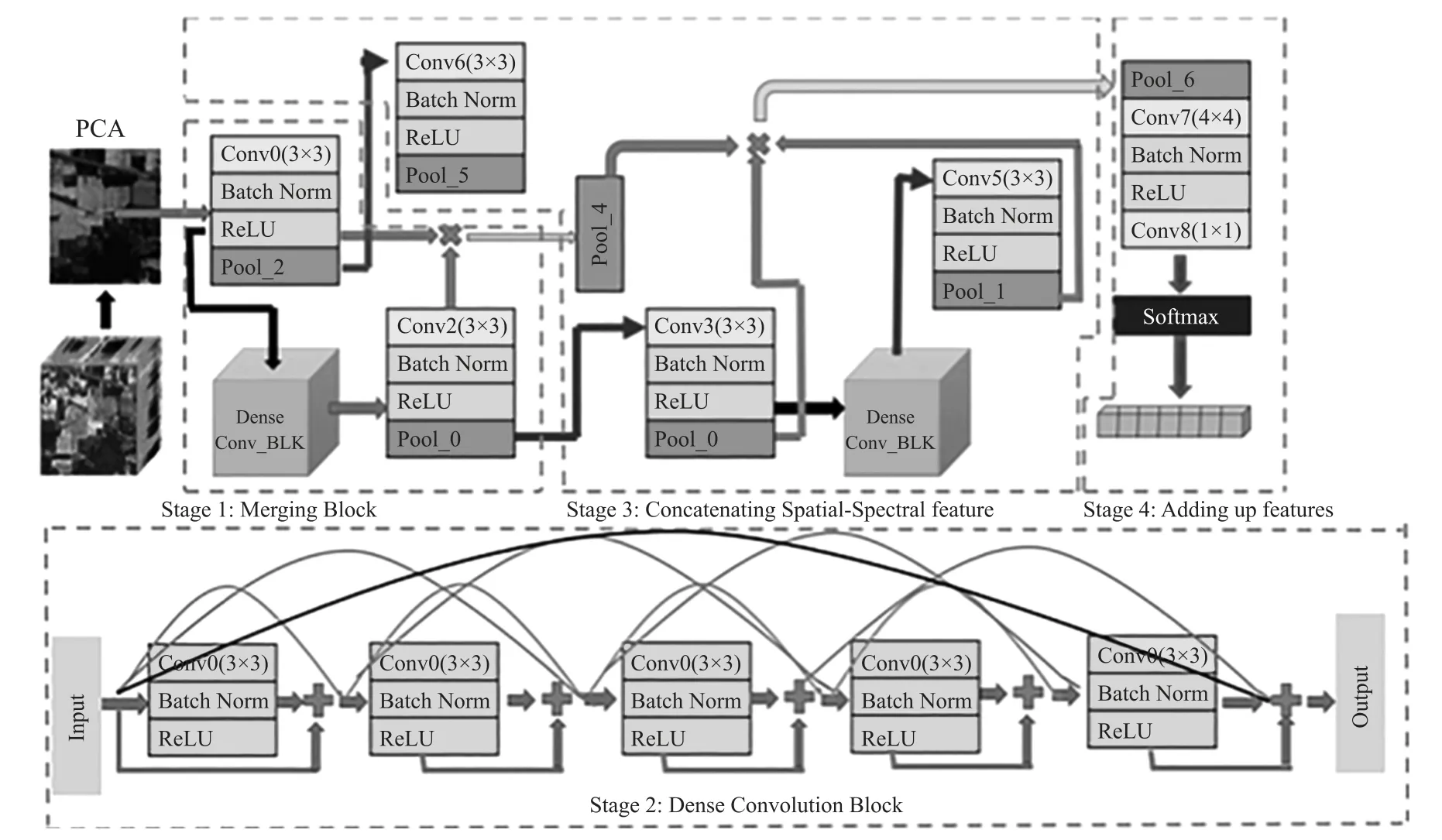
图2 本文的流程图
首先使用主成分分析提取出数据集中最主要的信息,然后将其分为测试集和训练集。在设计MS-2HCNN 模型时采用四阶段方法(如下所示),其中在卷积块(Conv_BLK)中通过大量的卷积运算融合空间& 光谱信息,以提取高光谱图像中丰富的特征,其中的conv(n×n)表示n×n大小的卷积核。此外,还采用了一种高效的优化器在两个不同的数据集上对模型进行训练。具体介绍如下:
Step1:将训练集中的n个标签样本数据记为(Xn∈Y1×d)nn=1,其中d为光谱数据的大小。将光谱数据和空间数据结合提取特征以提高分类精度。每个光谱像素与中心像素Xn的相邻像素视为块Hn∈YS×S(S为窗口的权重和高度)。
Step 2:四阶段设计:
①将浅层与深层融合(Merging Block),得以从特征图中提取更多的信息。②在密集卷积块(Dense Convolution Block)中,任意两个提取到的特征图都可以被连续级联在一起。③将提取的输入数据的相关空间特征和光谱特征进行拼接(Concatening Sptial-Spectral Feature)。④最后,利用1×1 卷积层对线性信道中的信息进行汇总(Adding up Feature)。
Step3:使用AdaBound 优化器,根据式(6)对模型的学习率进行相应的修改,以提高整体收敛性,并使用BN 方法对每层的输入值进行归一化处理。
Step4:通过式(9)中c类的softmax 函数计算每个类别所需提取的相应空间光谱信息。
Step5:测试集数据通过式(10)预测类来验证本文提出的MS-2HCNN 模型的性能。
1.2.1 空间特征和光谱特征的提取
首先空间特征信息和光谱特征信息是互相独立的,通过串联光谱级通道,将浅层的边界特征合并为深层的高层语义特征。此时的空间维度保持不变,提取到的特征图中包含大量信息。然后使用密集卷积块获取空间光谱特征。将之前层的特征组合作为输入,并附加权值给后续层,从而得到两个具有相同维数的特征图。这样一来,便可实现了特征在通道维度上的复用,进行特征增强,并减少了不常出现的特征信息,使用少量的卷积核就可以生成大量的特征,最终模型的尺寸也比较小,从而提高了卷积块提取特征的效率。因为一般情况下在反向传播时每一层都会接受其后所有层的梯度信号,所以随着网络深度的增加,靠近输入层的梯度不会变得越来越小,因此这种结构的设计还一定程度上减轻在训练过程中梯度消失的问题。最后,这种结构可以说是一种隐式的强监督模式,因为每一层都建立起了与前面层的连接,误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层获得直接监督。
1.2.2 空间&光谱特征合并和分类
为了给MS-2HCNN 模型提供必要的细节,必须识别多个空间光谱特征。此外,提取到的空间数据特征和光谱数据特征必须进行合并。因此,MS-2HCNN 的目标函数如式(7)所示:
式中:输入为Xn,输出为Yn,归并函数为∅,权重为w,偏置为b。另外,如图2 所示,在MS-2HCNN 的Step3 阶段,将多个池化输出进行池化并合并,实现空间&光谱特征提取。池化输出计算操作的合并如下所示:
式中:POOLsi{i=1,2,3,4,5}表示当前阶段的输入变量。⊗表示合并操作。这四个输入变量的合并获得了更多更丰富的特征信息,生成了一个集成特征图。由于空间结构映射的维数可能不同,因此采用1×1 卷积运算代替全连接层。1×1 卷积在集成新特征图的同时,有助于减少参数并进行通道间的有效通信。
最后阶段的输出特征由(Xn∈Y1×c)nn=1 组成,其中c表示类别数量。
在训练阶段,损失函数是Softmax 层中的一部分:
在测试阶段,预测的标签是MS-2HCNN 模型的输出。类标签生成如下:
式中:Xts为测试样本,Class 是预测标签,Yl是MS-2HCNN模型的输出。
2 实验结果与分析
2.1 实验设置
与四阶段设计方法相符,为了利用相邻像素之间的空间相关性,通过将光谱波段与主成分向量串联来产生输入的像素参数。此外,进行了降维从而避免过拟合,使用9×9 大小的PCA 算法处理了数据集。输入维数设置为9×9 和11×11 且光谱波段为10。
表1 所示为MS-2HCNN 网络模型的参数。本文方法基于Python 3.6 运行,使用Keras 2.2.4 作为后端库,Tensorflow 1.12.0 作为前端库。为了获得训练样本和测试样本的准确率和损失值的变化,将100 个epochs 固定并重复100 次。用于性能评价的指标如下:①总体准确率,即分类正确的样本占所有测试样本总数的比例;②平均准确率,即每个类的分类率;③Kappa 系数,将最终得到的特征图与真值特征图进行数值对比。

表1 MS-2HCNN 模型参数设置
2.2 数据集
本文基于两个不同的高光谱遥感数据集:Indian Pines 和Salinas 探究MS-2HCNN 模型的性能。在训练MS-2HCNN 模型时,从数据集的每一类中随机选择10%的标签数据,其余的数据作为测试样本。以下结合表2 对两个数据集的具体情况进行介绍:
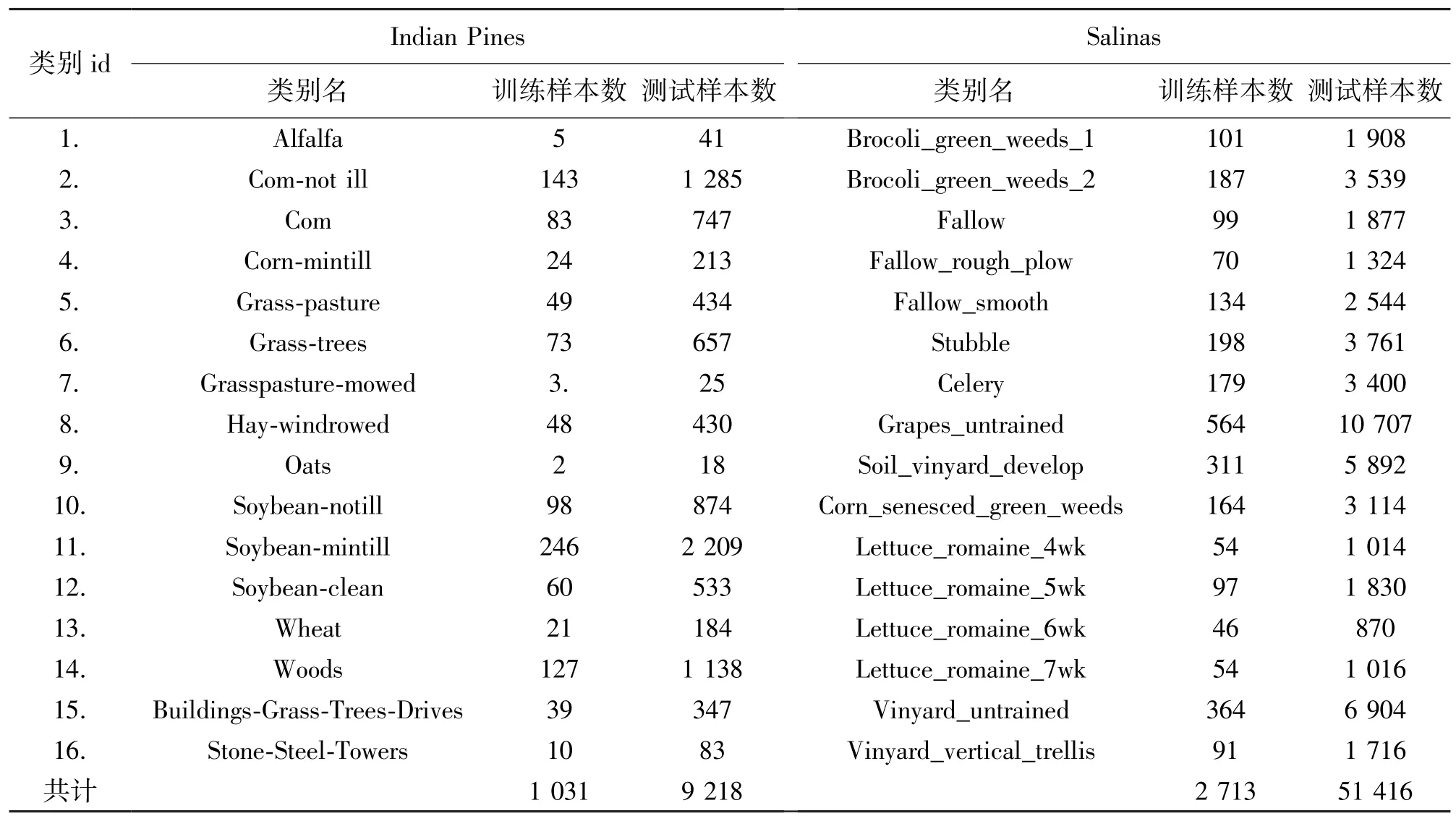
表2 数据集介绍
Indian Pines 是最早的用于高光谱图像分类的测试数据,由机载可视红外成像光谱仪(Airborne Visible Infrared Imaging Spectrometer,AVIRIS) 于1992 年对美国西北的印第安纳州农业区的印度松树进行成像,然后截取145×145 尺度进行标注,以此作为高光谱图像分类测试用途。此外,其空间分辨率约为20 m。而由于AVIRIS 成像波长范围为0.4 μm~2.45 μm,是在连续的220 个波段对地物连续成像的,但是由于第104~108,第150~163 和第220 个波段不能被水反射,因此,一般在使用时对这20 个波段进行剔除,只使用剩余的200 个波段进行研究。最后共计16 个类别。
Salinas 是美国加利福尼亚州萨利纳斯山谷的图像,也由AVIRIS 拍摄完成的。其大小为512×217像素,谱带为0.36 μm~2.0 μ m,空间分辨率3.7 m。该图像由16 类224 个光谱波段组成。
2.3 实验结果与分析
为了进一步减少MS-2HCNN 模型的损失,并提高高光谱图像分类的性能,本文首先对相关的深度网络优化器进行实验探究,包括SGD,AdaGrad,AdaDelta,Adam 和AdaBound,旨在选取最优性能的优化器。
图3 给出了MS-2HCNN 结合不同优化器在两个数据集的输出分类特征图。首先可以看到相比于自适应优化器,SGD 优化器的表现最差。此外,AdaBound 优化器得到的分类图明显优于其他自适应优化器,最接近于真值图。

图3 不同方法的分类特征图,其中上方为Indian Pines 数据集,下方为Salinas 数据集
表3 展示了在Indian Pines 和Salinas 数据集上使用不同优化器的训练时间(Tt)和测试时间(Ts)。可以看到同一数据集上不同优化器之间的时间消耗差异很小,而AdaBound 优化器的综合消耗时间最少。

表3 不同优化器的时间复杂度
表4 和表5 分别给出了在Indian Pines 和Salinas 数据集的分类结果,可以看到与其他方法相比,MS-2HCNN 模型结合AdaBound 优化器的方法在每个类别上的和平均准确率上都实现了最优解。而它在Indian Pines 数据集上的总体准确率达到了99.36%,这也是所有对比优化器中表现最好的;而在Salinas 数据集上的总体准确率则达到了99.01%,稍弱于Adam 优化器的99.53%,原因可能是grapes_untrained 和vinyard_untrained 两类之间的类间距太小,只有0.35%的微弱差异。因此总体上来说,带有AdaBound 优化器的MS-2HCNN 模型比其他模型显示了更好的性能。
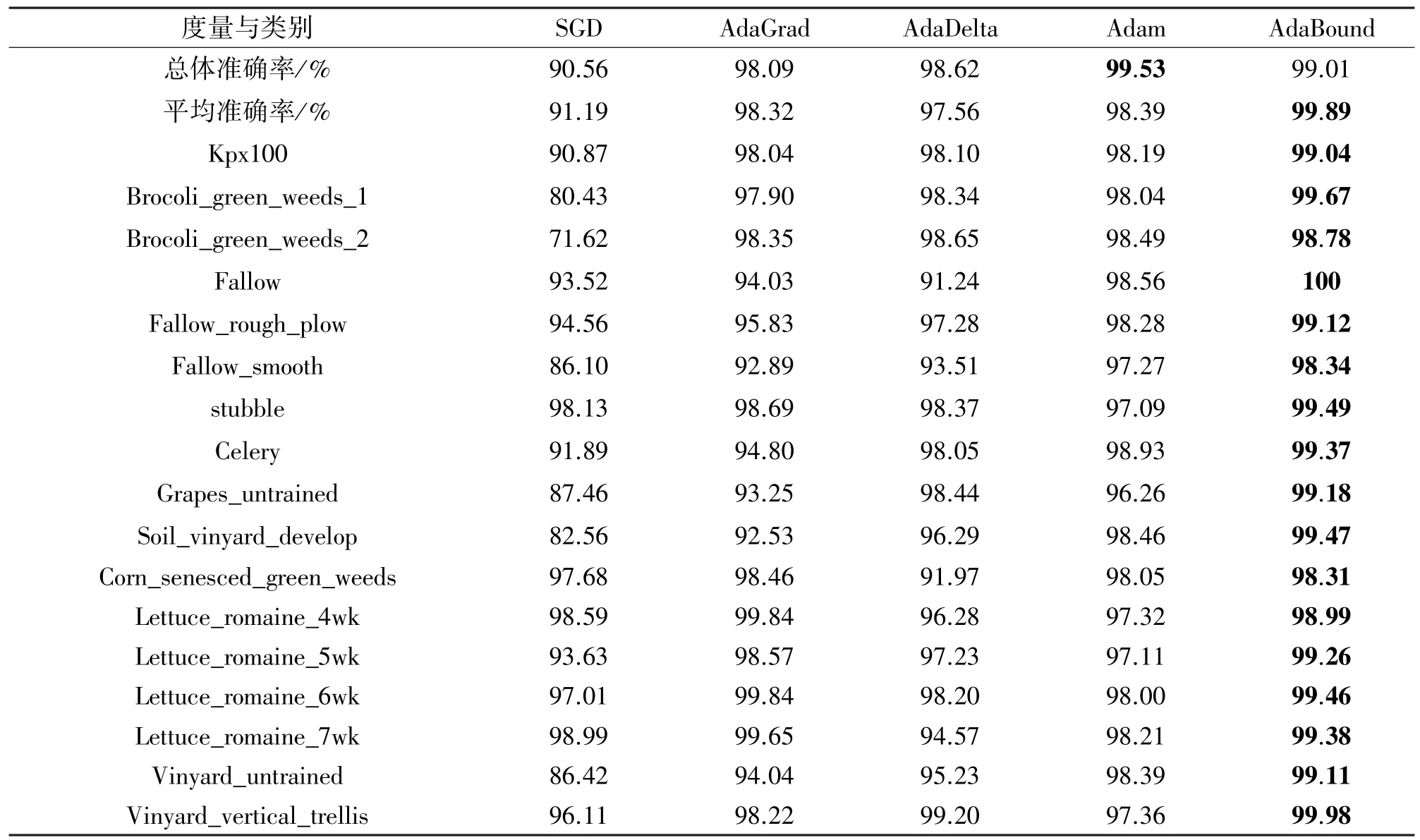
表5 Salinas 上不同优化器的实验结果
结合表3、表4 和表5 来看,AdaBound 优化器明显提高了传统卷积神经网络的稳定性和收敛速度。因此采用AdaBound 的MS-2HCNN 性能明显优于其他优化器,在整个测试过程中,测试精度的变化率确实很低,这是因为AdaBound 优化器在优化过程中使用了动态学习速率。AdaBound 优化器在训练初期类似于GD,随着训练周期的增加,优化器在速度和准确性方面都变得更加有效。自适应优化器Adam 和AdaBound 可以在最短的时间内对模型进行拟合,而SGD 需要很长时间。采用AdaBound 优化器的MS-2HCNN 比SGD、AdaGrad、AdaDelta 和Adam 优化器可以实现更快的收敛时间。从这点可以看出,利用AdaBound 优化器的确改进了MS-2HCNN 的分类性能。
此外,还将MS-2HCNN 方法与其他高光谱图像分类方法进行了比较,包括传统用于高光谱图像分类的代表性机器学习方法支持向量机(Support Vector Machine,SVM),而深度学习方法选取了代表性的可以提取空间光谱高阶特征的2D-CNN、3DCNN 和Hybrid-SN 方法。
表6 展示了几种性能测量方法的结果,包括总体准确率,平均准确率和Kappa 系数。结合表4,可以看到相较于其他有监督模型,提出的MS-2HCNN模型在保持最小标准差的情况下优于现有监督模型。在Salinas 数据集上的结果表明3D-CNN 的结构设计逊色于2D-CNN 方法。而其他所有基于空间&光谱特征的模型在精度上皆优于SVM 方法。另一方面,2D-CNN 和3D-CNN 本身无法刻画出具有高度判别性的空间&光谱特征。而本文提出的MS-2HCNN 和Hybrid-SN 的性能优于其他模型。
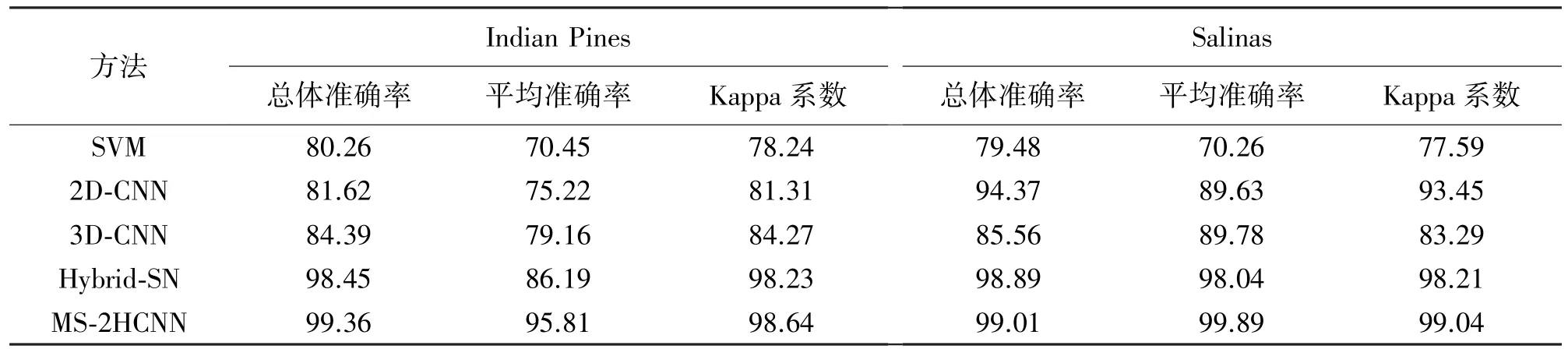
表6 Indian Pines 数据集和Salinas 数据集中不同方法的总体准确率,平均准确率和Kappa 系数比较
图4 和图5 分别展示了在Indian Pines 数据集和Salinas 数据集中不同训练时期各种分类器的结果对比,可以看到本文提出的MS-2HCNN 模型实现了更好的空间-光谱分类。
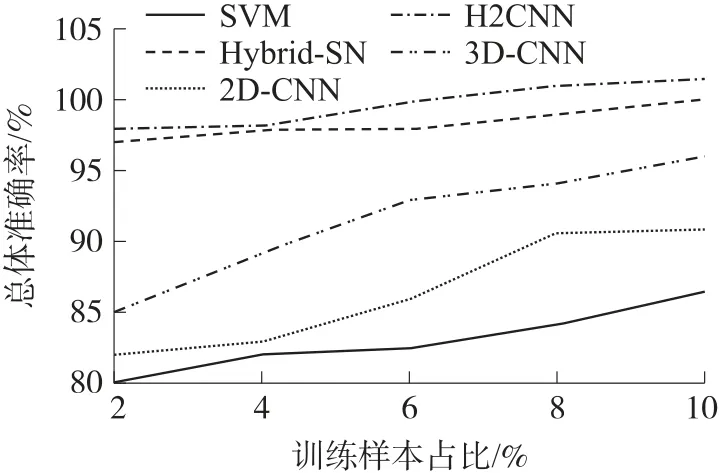
图4 Indian Pines 数据集中不同方法在不同时期的总体准确率
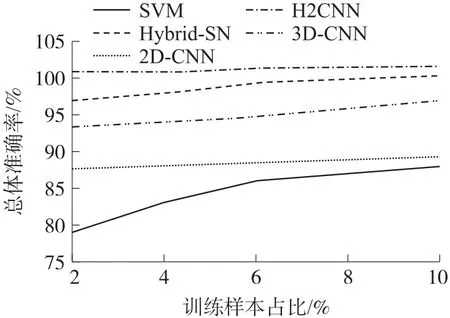
图5 Salinas 数据集中不同方法在不同时期的总体准确率
3 结束语
由于较高的样本特征比,因此在基于CNN 的高光谱图像信号分类方法中一直增加层的深度可能会导致过拟合问题。此外,由于高光谱图像的空间&光谱信息在不同层上不相关,因此可能会面临信息缺失的问题。针对这些问题,本文提出了MS-2HCNN 以进行应对。具体来说,首先通过卷积块合并连续两层的输出,并将合并的特征提取结果作为输入送到下一层,从而进行相关的特征提取;然后从低层到深层高层,通过将光谱特征连接到四阶段空间特征来获取光谱空间特征。此外,采用的AdaBound 优化器减少了MS-2HCNN 的模型参数并提高其拟合能力。在不同数据集上的总体准确率、平均准确率和Kappa 系数指标结果证明了提出方法的有效性。
