基于纹理特征的分布式视频压缩感知自适应重构方法*
2024-03-06张登银
陈 灿,周 超,张登银
(南京邮电大学物联网学院,江苏 南京 210003)
压缩感知(Compressive Sensing,CS)[1-2]理论提出利用测量矩阵对信号进行采样和压缩,并通过重构算法恢复原始信号。这种强大的信号采集和处理方式,使其适用于诸如视频监控[3]等资源受限的应用场景。在过去的十多年中,CS 已被成功应用于视频图像信号处理,其中最流行的一种应用就是分布式视频压缩感知框架(Distributed Compressive Video Sensing,DCVS)[4-5]。由于DCVS 整合了CS 和分布式视频编码(Distributed Video Coding,DVC)[6]的特点,十分适用于资源受限的应用场景,得到了学者的广泛关注。值得注意的是,由于存储空间的限制,在实际应用中往往采用基于块的CS 采样方式[7],而不是直接对帧进行CS 采样。
受启发于运动估计(Motion Estimation,ME)和运动补偿(Motion Compensation,MC),文献[5]提出多假设(Multi-Hypothesis,MH)预测算法,通过线性组合图像块来生成当前目标图像块的预测。文献[8]提出MH-BCS-SPL 算法,该算法结合了MH 预测和残差重构[9],能够获得不错的重构质量,因此衍生出一批相关算法[10-13]。文献[14]提出一种重加权的残差稀疏模型,该模型首先利用视频帧的空间相关性进行初始重构,再利用视频帧之间的时间相关性进一步提高重构质量。这些基于分析模型的重构算法尽管能够获得不错的重构质量,但是计算复杂度高,无法满足实时应用的要求。
近年来,深度学习技术在诸如目标检测、语义分割等机器视觉领域展现出巨大的潜力,已被成功应用于CS 领域[15],并被逐步引入分布式视频压缩感知重构中。文献[16]提出一种名为CSVideoNet 的重构网络,该网络结合卷积神经网络(Convolutional Neural Network,CNN) 和长短期记忆网络(Long Short-Term Memory,LSTM),能够有效进行视频帧重构。文献[17]提出一种基于LSTM 的多帧质量增强方法,该方法通过使用相邻高质量视频帧来提高低质量视频帧的质量。文献[18]提出一种基于CNN的联合采样重构网络,联合学习编码和解码,充分利用了帧间相关性和帧内相关性。
尽管基于深度学习的重构方法具备较高的重构效率和重构质量,能够满足实时应用的要求,但是现有基于深度学习的重构方法忽略了帧的纹理特征,限制了重构性能。由于同图像组中的视频帧具有较高的相似性,因此可以选择重构帧作为相邻重构帧纹理特征的参考。为了解决这个问题,本文提出一种基于纹理特征的分布式视频压缩感知自适应重构网络,命名为TF-DCVSNet。具体来说,TF-DCVSNet利用已重构相邻帧的纹理特征,激活当前重构帧的重构网络模块,进行自适应重构。大量实验验证了TF-DCVSNet 的有效性。
本文章节安排如下:在第1 节,介绍了相关背景知识;在第2 节,对所提方法进行具体阐述;在第3节,对所提方法进行性能验证和分析;在第4 节中,对本文进行总结与展望。
1 背景知识
1.1 压缩感知
CS 理论指出,我们可以利用测量矩阵Φ∈Rm×n,以Sub-Nyquist 速率对信号x∈Rn×1进行采样:
式中:y∈Rm×1为测量向量,m/n为采样率。在基于块的CS 中,n=B2(B为分块大小)。由于m≪n,因此CS 重构为ill-posed 问题,传统方法通过求解明确的分析模型来进行信号的重构:
式中:λ为非负的权重常数,S(x)表示信号先验,例如稀疏先验[19]和低秩先验[20]。区别于基于分析模型的重构方法,基于深度学习的重构方法将重构建模为一个带参数的网络F(y;θ),基于包含M个数据的训练集,通过优化损失函数优化θ,实现信号的重构:
1.2 分布式视频压缩感知
研究者将DVC 和CS 进行结合,提出了DCVS。如图1 所示,该DCVS 框架首先把视频帧序列划分为多个图像组,图像组(Group Of Picture,GOP)内的首个视频帧被划分为关键帧xK,其余视频帧被划分为非关键帧xNK(也被称为Wyner-Ziv 帧)。在编码端,对关键帧和非关键帧分别以高采样率和低采样率,进行独立的CS 采样。在解码端,首先对关键帧的测量向量yK进行独立的CS 重构,获得重构后的关键帧x″K。然后利用x″K辅助非关键帧的测量值yNK进行联合重构,获得重构后的非关键帧x″NK。

图1 DCVS 框架
2 所提方法
现有基于深度学习的重构方法忽略了帧的纹理特征,限制了重构性能。为了进一步提高重构质量,提出一种基于纹理特征的分布式视频压缩感知自适应重构网络,命名为TF-DCVSNet。
2.1 网络框架
TF-DCVSNet 网络框架如图2 所示,包括初始重构模块和自适应重构模块。基于同图像组中的视频帧具有较高的相似性,因此在重构时可以选择相邻重构的结果作为当前帧的纹理特征的参考。所提方法首先在非关键帧的重构中,选择关键帧的中间重构结果作为非关键帧纹理特征的参考,进行非关键帧的自适应重构,获得;然后将作为关键帧纹理特征的参考,进行关键帧的自适应重构,获得。
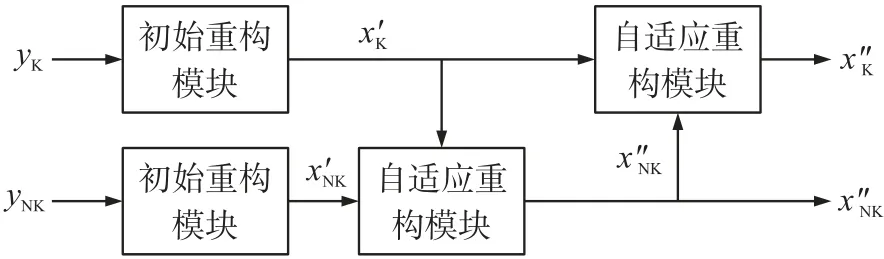
图2 TF-DCVSNet 框架
①初始重构模块
初始重构模块如图3(以非关键帧的初始重构为例)所示,由1 个卷积层(卷积核数量:B×B,卷积核大小:1×1,步长:1,填充:valid)和1 个变形层组成。首先利用卷积层对y进行卷积运算,然后利用变形层将卷积层输出张量变形为目标重构维度。
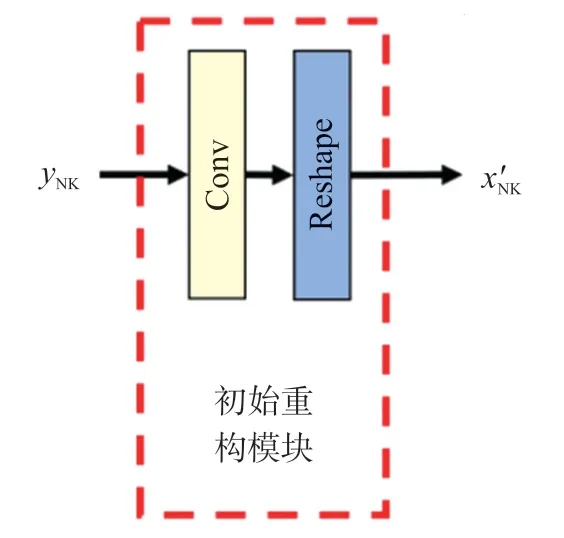
图3 初始重构模块架构
②自适应重构模块
自适应重构模块如图4(以非关键帧的自适应重构为例)所示,由1 个门模块和k个加权残差模块组成。首先输入门模块得到激活向量,激活向量自适应激活加权残差模块,对进行自适应重构。
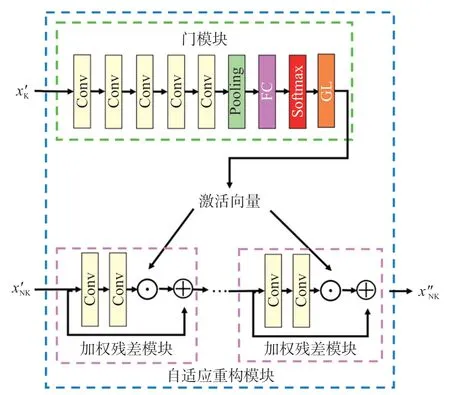
图4 自适应重构模块框架
门模块由5 个卷积层(卷积核数量:32,卷积核大小:3×3,步长:1,填充:same),1 个平均池化层(池化核大小:2×2)、1 个全连接层(神经元数量:k)、1 个Softmax 层和1 个过滤层构成。在过滤层(GL)根据设置的阈值1/4k,对输入张量t进行过滤,最终获得激活向量p():
加权残差模块由2 个卷积层组成。首先,利用1 个卷积层(卷积核数量:32,卷积核大小:3×3,步长:1,填充:same)对输入进行特征提取,获得特征图;其次,利用1 个卷积层(卷积核数量:1,卷积核大小:3×3,步长:1,填充:same)进行增强重构,获得增强重构结果;然后,将增强重构结果的数值与激活向量中对应的数值进行点乘运算;最后,与这个加权残差子网的输入进行相加,获得这个加权残差子网的最终输出。
2.2 训练策略
如图5 所示,针对所提网络框架,本文采用一种基于四阶段的训练策略。当前阶段将之前阶段训练的参数作为初始化参数进行训练。为使得公式更加简洁明了,下列公式皆为基于数据集的求和,省略了求和的上下标。
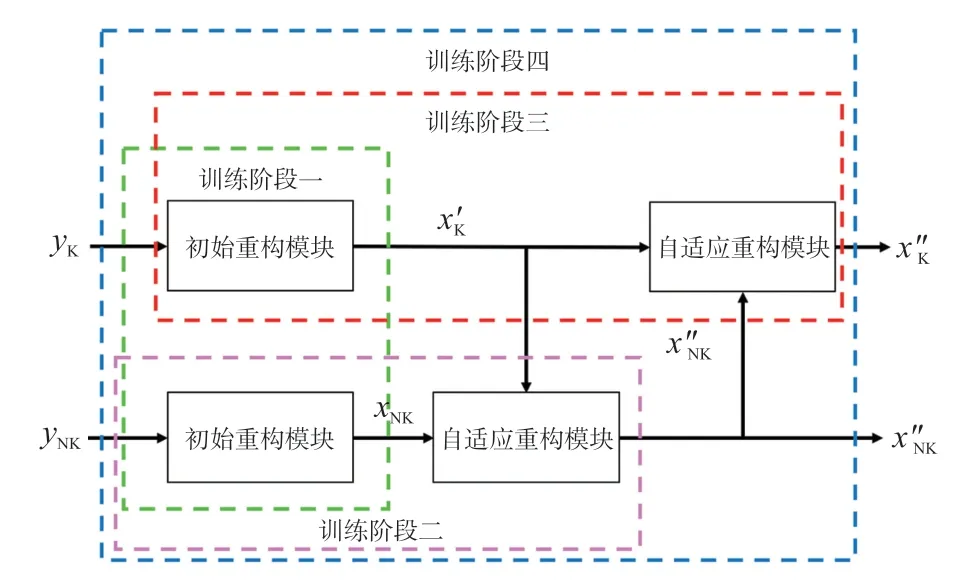
图5 基于四阶段的训练策策略
在训练阶段一中,通过优化式(5)和式(6),分别对关键帧和非关键帧的初始重构模块进行训练:
在训练阶段二中,通过优化式(7),对非关键帧的初始重构模块和自适应重构模型进行训练:
在训练阶段三中,通过优化式(8),对关键帧的初始重构模块和自适应重构模型进行训练:
在训练阶段四中,通过优化式(9),对整体网络进行训练:
3 实验
3.1 参数设置
由于没有专门针对分布式视频压缩感知的标准数据集,本文采用UCF-101 数据集[21]进行训练和测试。由于GPU 显存的限制,图像组大小设置为4,每个视频帧裁取中心区域(分辨率:160×160)组成数据集。将数据集随机划分为训练集(80%),验证集(10%)和测试集(10%)。其他参数设置如表1所示。采用所有视频帧的平均PSNR 和平均SSIM作为衡量重构质量的客观标准。

表1 实验参数设置
3.2 性能对比
为验证所提方法的有效性,将TF-DCVSNet 与以下三种主流的算法和网络进行对比实验:MHBCS-SPL[8],FIR[22]和ReconNet[23]。表2 展示了不同方法在测试集上的重构质量对比。以0.04 采样率的情况为例,相比于FIR,MH-BCS-SPL 和Recon-Net,TF-DCVSNet 在PSNR 上获得了4.26 dB,3.14 dB和8.6 dB 的提升,并在SSIM 上获得了0.136 1,0.094 3和0.301 4。图6 展示了不同方法的重构主观质量对比,不难观察到,在低采样率的情况下,ReconNet 由于独立地重构每个图像块,忽略了块之间的联系,并且未充分利用视频时空相关性,具有明显的块效应,重构性能不太理想;MH-BCS-SPL 利用了视频时空相关性,块效应有一定的改善;FIR 尽管借助深度学习技术,消除了块效应,但是并未充分利用视频时空相关性,重构质量仍有进一步的提升空间;TF-DCVSNet 展现出优越的性能,其原因在于TF-DCVSNet 充分利用了纹理特征信息,能够进行自适应的重构。

表2 重构质量对比
4 结论
本文针对现有基于深度学习的重构方法忽略了帧的纹理特征、重构性能受限的问题,提出一种名为TF-DCVSNet 的基于纹理特征的分布式视频压缩感知自适应重构网络,利用已重构相邻帧的纹理特征,激活当前重构帧的重构网络模块,进行自适应重构。大量实验验证了TF-DCVSNet 的有效性。今后的研究将围绕如何提高网络的重构效率进行开展。
