基于深度学习的网络安全命名实体识别方法
2024-03-05李大岭张浩军王家慧李世龙
李大岭,张浩军,王家慧,李世龙
(1.河南工业大学 信息科学与工程学院,河南 郑州450001;2.河南省粮食信息处理国际联合实验室,河南 郑州450001)
0 引言
随着大数据时代的到来,网络入侵、病毒感染等网络攻击事件越来越频繁,网络攻击严重影响了计算机使用的安全性。没有网络安全就没有国家安全,为了保证网络空间安全,国家通过各种技术实时监测网络,产生了大量的网络安全数据。同时网络空间还存在大量的安全信息、漏洞信息等。
为有效地从海量的网络安全信息中抽取实体,本文提出一种融合汉字多源信息的中文命名实体识别(Named Entity Recognition,NER)方法。在Embedding层使用BERT模型融合汉字偏旁部首信息和字符频率信息获取字向量,并使用改进的Para-Lattice模型对字向量和词向量进行融合,使得字向量能更准确表达字符的信息,进而提升模型的性能。
1 相关工作
命名实体识别任务的目的是识别出人类自然语言中专有名词的实体[1]。基于深度学习的NER任务可以转换为序列标注任务[2],将大量带有标签标注的数据样本输入到模型进行训练,最后由模型进行预测。统计机器学习算法在NER中得到广泛应用,隐马尔可夫模型(Hidden Markov Model,HMM)[3]、支持向量机(Support Vector Machine,SVM)[4]和条件随机场(Conditional Random Fields,CRF)[5]等机器学习算法被广泛叠加到深度学习模型中,其中CRF因为能更好地获取标签之间的状态转移信息,从而被广泛应用到NER任务中。
随着人工智能的发展,神经网络和深度学习逐渐应用到各个领域,基于深度学习的NER模型在领域内逐渐占据主导地位。Wu等[6]开发了一个深度神经网络,通过无监督学习从大型无标记语料库生成词嵌入,使用最小特征工程方法识别中国临床文档中的临床实体。Zhang等[7]首次提出基于字符和词典的Lattice-LSTM模型,模型会编码输入字符以及语词典匹配的所有潜在词语,得益于丰富的词汇,模型在数据集上取得了很好的表现。Li等[8]提出FLAT模型,将晶格结构转化为扁平结构,模型可以通过位置编码来捕获词信息,有良好的并行计算能力。Ma等[9]把词典信息编码到字符表示层,并设计了一个编码规则来尽可能地保留词典的匹配结果,模型效率提升,同时提升了性能。杨飘等[10]通过BERT预训练模型获取字向量,将字向量序列输入到BiGRU-CRF模型中,在MSRA数据集上实验结果表明模型的性能得到提升。
此外,针对网络安全领域NER研究工作。Joshi等[11]基于CRF算法构建了一个用于识别文本中与网络安全相关的实体、概念和关系的模型。Lal等[12]提出了一种基于SVM算法的从非结构化文本中提取网络安全相关术语的信息识别方法。Mulwad等[13]设计了一种基于SVM算法的识别系统,提取用来描述漏洞和攻击的概念实体。秦娅等[14]结合特征模板提出一种CNN-BiLSTM-CRF的网络安全实体识别方法,在大规模网络安全数据集上表现良好。杨秀璋等[15]针对高级可持续威胁(Advanced Persistent Threat, APT)分析报告,提出一种BERT-BiLSTM-CRF的APT攻击实体识别模型,在数据集上取得了很好的表现。
针对中文网络安全领域的NER任务,提出改进的一种融合字向量和词向量的深度学习模型。考虑到中文预训练模型BERT仅提取汉字的信息,并没有涉及到汉字的偏旁部首,因此提取字向量时将汉字偏旁部首信息和字符频率信息与BERT字向量进行融合,进而提升模型性能。
2 模型与方法
本文模型如图1所示,整个模型分为3层,Embedding层将BERT字向量、融合字频信息的F-FI向量和偏旁部首信息向量进行拼接,Para-Lattice层充分获取词汇信息,CRF层通过学习标签间的状态转移信息构建状态转移矩阵进行预测。
2.1 词嵌入层
Embedding层任务是将输入到模型中的字序列映射成低维度的稠密向量输入到Para-Lattice层中。本文的Embedding层分为BERT模块、F-FI模块和PianPang模块三部分。其中BERT模块利用预训练的BERT模型将输入序列转换为实向量。图2为BERT模型的输入表示。
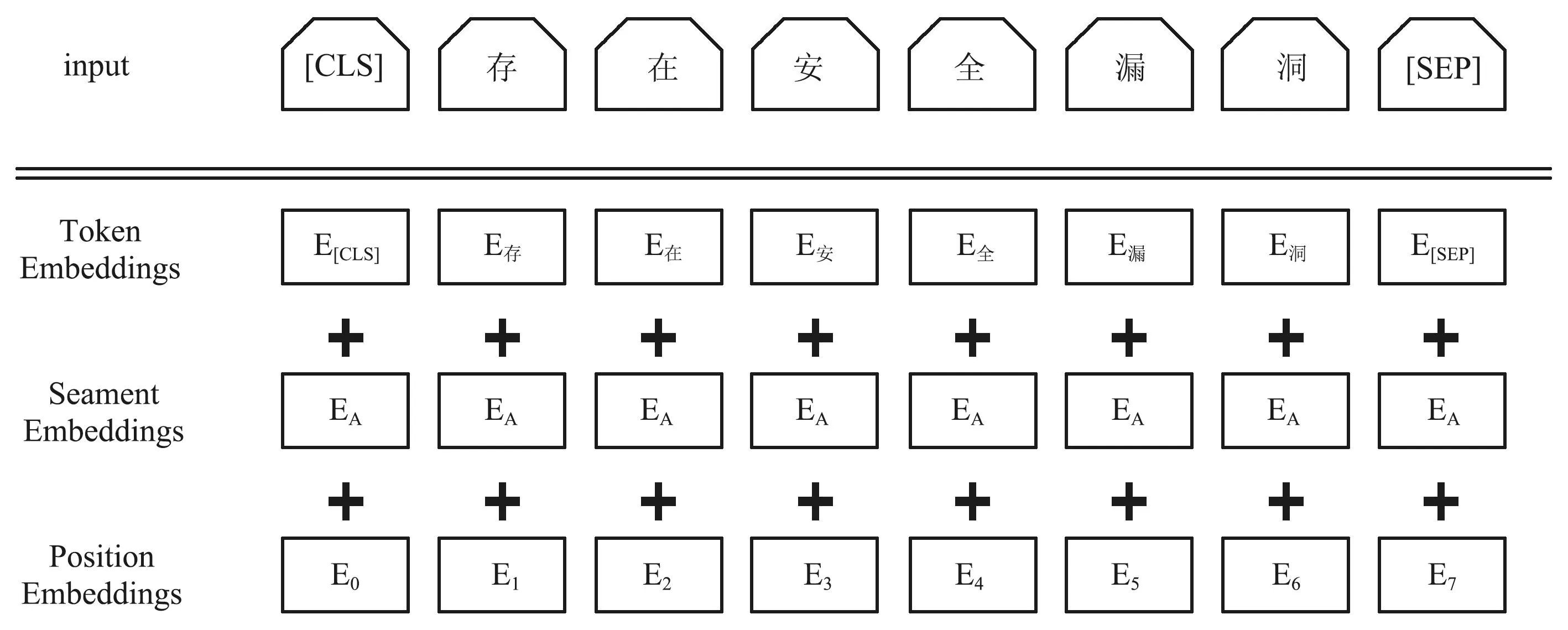
图2 BERT输入表示Fig.2 BERT input representation
本文以单个字符为输入单位,所以BERT模型的输出为字向量,为了使得试验最终结果相对较好且能降低字向量的维度,本文使用BERT模型最后一层隐含层获取字向量,对于给定的输入序列L={a1,a2,a3,…,an},利用BERT模型对序列中每个字符ai输出它的BERT字向量Bai,即:
Bai=BERT(h(-1)),
(1)
式中:h(-1)表示隐含层最后一层,最终Bai的维度为768维。
F-FI模块首先将训练集验证集和测试集作为统计数据集,计算每一个字符的F-FI值。其中F是字符字频,FI是字符频率指数。
(2)
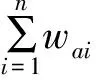
(3)
式中:N表示数据集中实例(Instance)总数,nai表示含有字符ai的Instance总数,加1是为了避免分母为0。
F-FIai=Fai*FIai,
(4)
式中:F-FI值为字符ai的F值乘以字符ai的FI值。F值可以很好地体现字符关键性,但数据集中常见字如:“的”的F值同样会大,所以用FI值弱化常见字的关键性。利用计算得出的F-FI值对100维的word2vec静态字向量进行加权,得到字频向量Tai。具体求解如算法1所示。

算法1:F-FI求解算法Input: L ∥文本序列Output: word_f_fi ∥字符F-FI值begin1 defaultdict(int) doc_fre2 for word_list L do3 for i word_list do4 doc_fre [i] ←doc_fre [i]+15 declare a dictionary word_f6 for i doc_fre do7 word_f[i] ←doc_fre[i] / sum(doc_fre.values)8 declare a dictionary word_fi9 doc_num ← len(list_words)10 defaultdict(int) word_doc11 foridoc_fre do12 forjIdo13 word_doc[i] ←word_doc[i] + 114 foridoc_fre do15 word_fi← math.log(doc_num / (word_doc(i) + 1)) 16 declare a dictionaryword_f_fi17 fori doc_fredo18 word_f_if[i] ← word_f[i]∗word_fi[i]19 return word_f_fiend
PianPang模块中使用新华字典作为本地字典,以百度汉语作为网络字典,以训练集验证集和测试集作为统计数据集,提取所有的字符汇集为一个字符集。针对字符集中每一个字符若本地字典中存在,则直接查询其偏旁部首并返回结果,否则到网络字典中查询并返回结果。将偏旁部首通过Embedding的方式得到一个130维PianPang静态向量表。对于给定的输入序列L={a1,a2,a3,…,an},利用PianPang模块对序列中每个字符ai输出它的PianPang向量Pai,即:
Pai=PianPang(ai)。
(5)
把字频向量Tai、BERT字向量Bai和PianPang向量Pai进行拼接得到字符ai的最终向量表示Eai。最终向量Eai的维度998维,即:
Eai=Bai⊕Tai⊕Pai。
(6)
2.2 编码层
循环神经网络(Recurrent Neural Network,RNN)因为能够考虑到上下文内容而被广泛应用于自然语言处理(Natural Language Processing,NLP)方向,但是会存在梯度消失和梯度爆炸问题,不能完美地处理具备长期依赖的信息。长短期记忆网络(Long Short-Term Memory,LSTM)通过引入门机制控制神经单元之间信息的传递,缓解梯度消失和爆炸的问题。由于中文NER的特殊性,改进了一种可以进行batch并行化计算的Para-Lattice模型,模型通过word-cell对词汇信息进行编码,并将其融合到char-cell的字符编码中,使得模型可以充分地利用汉字和词汇的信息,原模型Lattice由于在进行词汇融合时不能提前预知需要融入的词汇数量,导致Lattice一次只能处理一条数据,进而导致模型的运算速度很慢,且更新的梯度受极端值影响较大,模型损失剧烈震荡。本文改进了一种可以进行并行化计算的Para-Lattice模型,在模型进行词汇信息融合之前,将词汇数量提前计算构建一个词汇数量的列表并一同输入到模型中,字词融合时将一同计算的所有输入序列的词汇最大值定为基准,对其余进行补零操作,进而可以实现并行化计算的Para-Lattice模型。
Para-lattice对词汇的算法为:
(7)

(8)
式中:w表示关于词粒度的变量,c表示关于字粒度的变量
Para-Lattice通过增加一个额外的门来控制字粒度和词粒度的选取,计算如下:
(9)
Para-Lattice对字符的算法如下:
(10)
(11)
式中:
(12)
(13)
通过式(14)得到
(14)
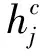

图3 Lattice-LSTM结构Fig.3 Lattice-LSTM structure
2.3 解码层
本文网络模型中编码层负责学习上下文信息,解码层CRF负责构建实体间状态转移矩阵。给定X,则Y的概率为P(Y|X),为计算P(Y|X),CRF作出以下2点假设:
① 假设该分布属于指数分布簇。即存在函数f(y|x)=f(y1,y2,…,yn|x),使得:
(15)
式中:z(x)为归一化因子,f(y|x)为打分函数。
② 假设输出之间的关联仅仅发生在相邻位置,并且这种关联是指数相加的。
(16)
式中:s(yi|xi)表示状态分数,t(yi,yi+1)表示转移分数。
对CRF采用对数极大似然方法计算损失函数,即:
ln(p(y1,y2,…,yn|x))=
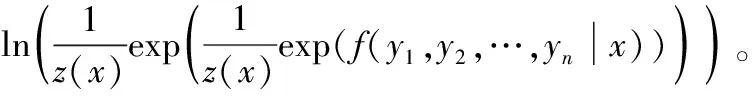
(17)
CRF损失函数的计算需要用到状态分数和转移分数,其中状态分数是根据训练得到的BERT+Para-Lattice模型的输出计算出来的,转移分数是从CRF层提供的转移矩阵得到的,其解码过程使用维特比算法得到最优的标签序列。
3 实验与分析
3.1 数据集和评估指标
本文收集国家信息安全漏洞库的漏洞数据作为实验数据确保了实验数据的真实性。本次语料收集了近5年的漏洞数据这确保了实验数据的历时性,爬取的内容包含操作系统、应用程序、数据库、Web应用和网络设备等多个模块的漏洞信息确保了语料库文本数据的全面性,2014年12月—2019年9月共计5年的漏洞数据,其中2014年18份、2015年242份、2016年328份、2017年489份、2018年422份、2019年313份,确保了语料库的历时性。按照不同的模块进行统计,包含操作系统模块210份、应用程序模块1 067份、数据库模块23份、Web应用模块334份、网络设备模块178份的漏洞信息,确保了语料库文本数据的全面性。按照漏洞危害的程度分类统计,有高级1 041份、中级636份、低级134份。图4描述了网络安全文本原始数据的分布情况。
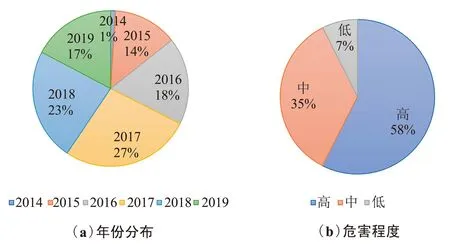
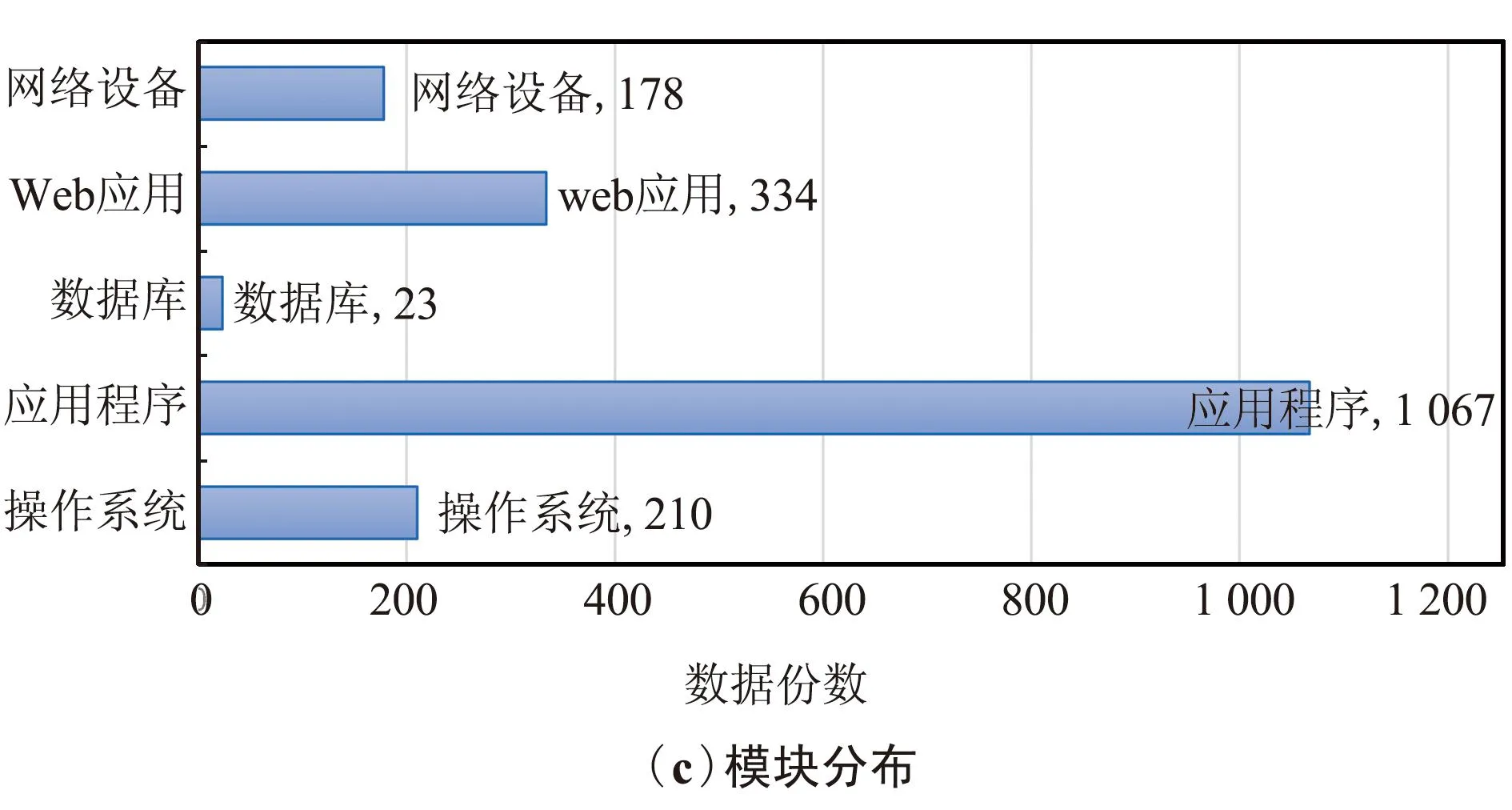
图4 网络安全数据分布情况统计Fig.4 Statistical chart of network security data distribution
参考了结构化威胁信息表达对网络攻击模式12种构件的定义,以及结合了丁兆云等[16]对网络安全情报数据的分析,将语料库中的实体定义为七大类,分别为漏洞编号实体(ID)、危害等级实体(CLA)、软件名实体(SW)、组织名实体(ORG)、漏洞类型实体(TY)、地名实体(LOC)和相关术语实体(RT)。各实体定义如下。
① 漏洞编号实体:标签为ID,用来记录漏洞在国家漏洞数据库中的编号,例如“CVE-2014-8016”。
② 危害等级实体:标签为CLA,用来描述该漏洞的危害等级,例如“高”“中”“低”等。
③ 软件名实体:标签为SW,用来描述漏洞所存在的软件名字,例如“Cisco Meraki MS MRMX”和“Huawei USG9560”。
④ 组织名实体:标签为ORG,用来描述存在漏洞的软件所属于的组织或公司名称,例如“华为”“思科”“谷歌”等。
⑤ 漏洞类型实体:标签为TY,用来描述漏洞危害的类型,如“拒绝服务漏洞”“SQL注入漏洞”“信息泄露漏洞”等。
⑥ 地名实体:标签为LOC,用来描述存在漏洞的软件的组织或公司所属于的地名,如“瑞士”“美国”“英国”等。
⑦ 相关术语实体:标签为RT,用来描述网络安全漏洞相关的术语,例如“拒绝服务”“HTTP会话”“蛮力攻击”等。
本文数据集采用BIO标注策略,B表示实体开始的位置,I表示实体的非开始位置,O表示非实体字符。本文数据集中共计包含15种实体标签,标签统计情况如表1所示。
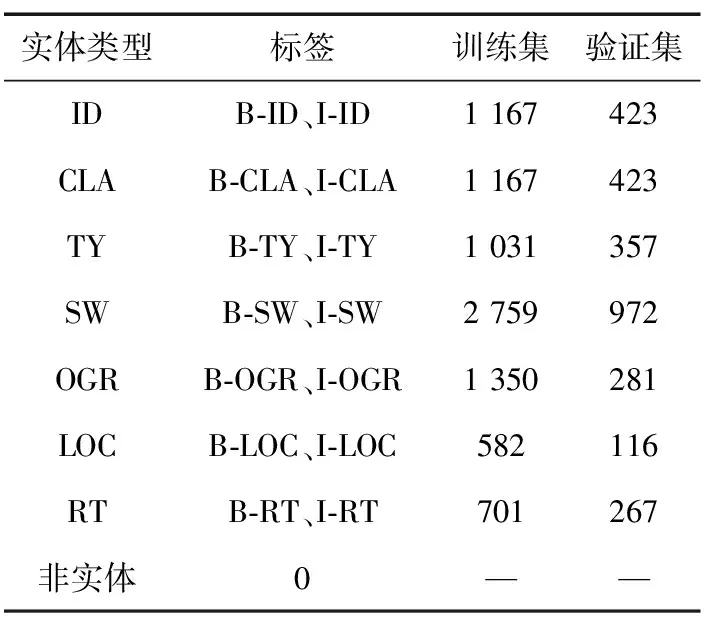
表1 网络安全实体数据统计
标注规则在遵循“不重叠标注、不嵌套标注、不包含标点符号”的基本标注原则的基础上,制定适合网络安全领域的标注规则。
① 最大范围标注
例1:Microsoft XML Core Services MSXML中存在远程代码执行漏洞,攻击者可借助特制的网站利用该漏洞运行恶意代码,进而控制用户系统。
例1中Microsoft为后面软件的公司名,遵循最大范围标注原则,将Microsoft和XML Core Services MSXML一起标注为软件名实体。
② 去特殊符号标注
例2:Cisco IOS XE是美国思科(Cisco)公司的一套为其网络设备开发的操作系统,Cisco IOS XE中的Web UI存在跨站请求伪造漏洞。
例2中Cisco为思科的英文名,遵循去特殊符号标注原则,将思科和Cisco分别标注为组织名实体。
图5为网络安全命名实体标注实例。

图5 网络安全命名实体标注实例Fig.5 An instance of a network security named entity annotation
表2将网络安全领域数据集与微博NER数据集Weibo-NER、微软亚洲研究院数据集MSRA、中国股市高管简历数据集Resume以及人民日报数据集PeopleDairy四种公开的常见的中文NER数据集进行了对比。通过对比可以发现,本文所构建的网络安全领域数据集相对于常见的中文语料库实体的类别比较丰富,其中MSRA数据集和PeopleDairy数据集包含的实体类型最少,均包含3类实体;本文数据集NSD-NER和Weibo数据集均包含7类实体,仅次于Resume数据集中的8类实体;MSRA数据集和PeopleDairy数据集数据体量比较大,分别为14 k和9.2 k,相对来说本文所构建的网络安全领域数据集NSD-NER数据体量比较小,数据大小为2.2 k,但其数据体量也大于Weibo数据集的0.8 k以及Resume数据集的1.4 k。5种数据集对比,本文数据集体量处于中游水平。
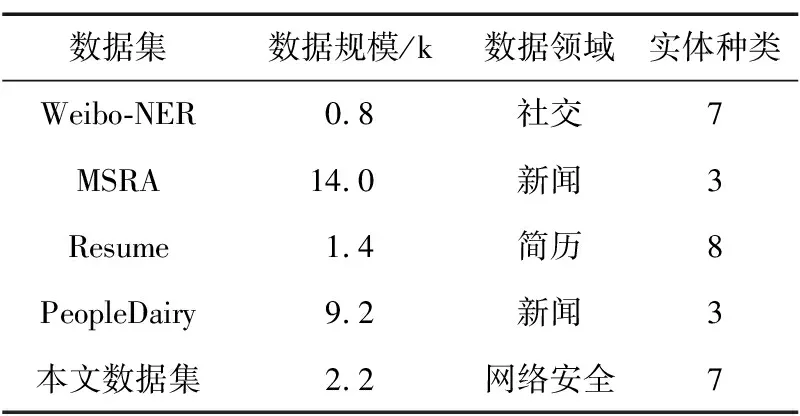
表2 不同语料库对比分析
本文采用精确率(P)、召回率(R)、F1值和ACC值作为实验的评估指标。其中P表示所有被预测为正的样本中实际为正的样本的概率,R表示实际为正的样本中被预测为正样本的概率,F1值是综合P值和R值的一个F1分数,ACC值表示模型的准确率。计算如下:
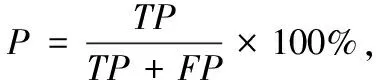
(18)
(19)
(20)
(21)
式中:TP表示正样本被判断为正样本的数量,FP表示负样本被判断为正样本的数量,TN表示负样本被判断为负样本的数量,FN表示正样本被判断为负样本的数量。
3.2 参数设置
本实验优化器采用Adam[17],该优化器集合了适应性梯度算法和均方根传播2种随机梯度下降扩展式的优点,可以高效地进行计算并且所需的内存比较少,模型使用Dropout[18]缓解过拟合的发生,在一定程度上达到正则化的效果。实验模型参数设置如表3所示。

表3 参数设置
3.3 实验结果分析
为了确定加入偏旁的有效性以及偏旁维度对模型最终结果的影响,使用融合汉字多源信息实体识别模型(Named Entity Recognition Model Based on Multi-Source Information of Chinese Characters,Msicc-NER)在Weibo数据集上做了各维度偏旁向量对比实验,实验结果如图6所示。

图6 偏旁维度对F1值影响Fig.6 Influence of radical dimension on F1 value
由图6可以看出,随着PiangPang向量维度的升高,F1增长值呈现上升趋势最后趋于平缓,综合考虑模型运行时间与F1值,实验最终选择最优的130维的PianPang向量与字向量进行融合。使用F-FI对100维的word2vec向量进行加权得到F-FI向量与字向量进行融合。
为了验证本文模型Msicc-NER的有效性和普适性,将模型与常见模型在Weibo和MSRA公开数据集上进行实验对比。Weibo和MSRA数据集数据统计结果表4所示。
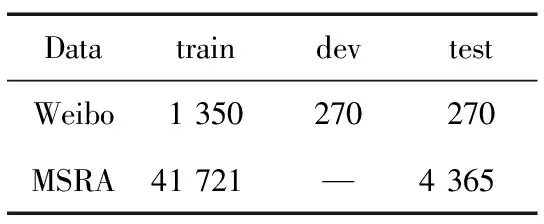
表4 公开数据集数据统计
图7和图8为各模型在公开数据集Weibo和MSRA数据集上的实验结果对比,通过对比结果可以看出,相对于Lattice+CRF、BiLSTM+CRF、BERT+BiLSTM+CRF等模型,本文模型Msicc-NER在公开数据集上有良好的表现,具有普适性,更进一步说明了融合偏旁信息和F-FI信息的有效性。
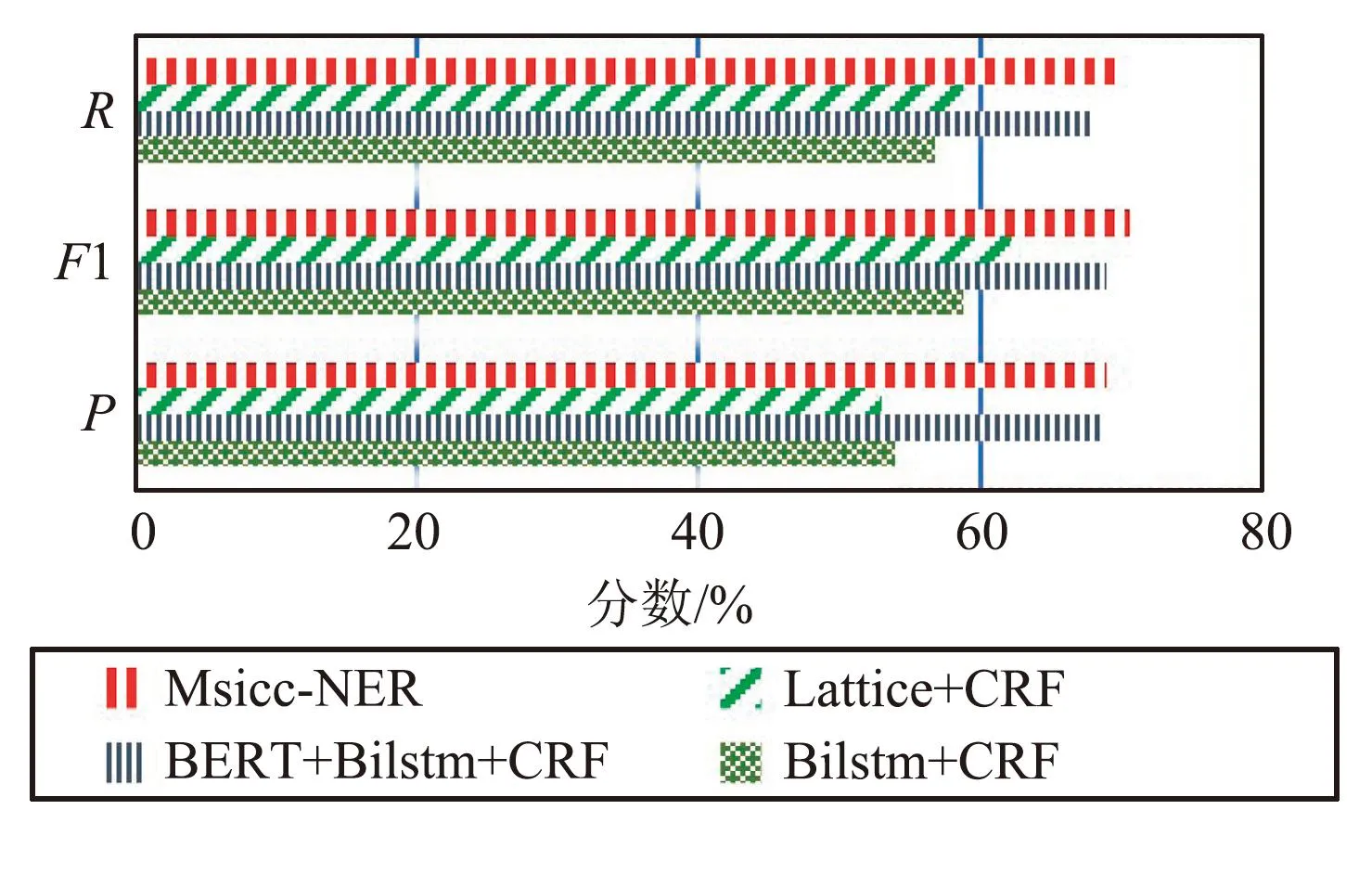
图7 不同模型在Weibo数据集识别结果Fig.7 Recognition results of different models in the Weibo dataset
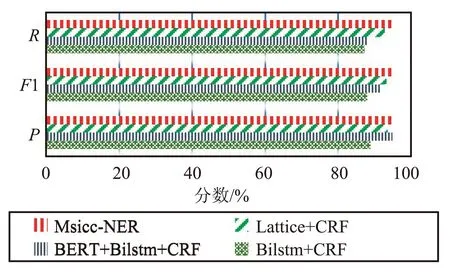
图8 不同模型在MSRA数据集识别结果Fig.8 Recognition results of different models in MSRA dataset
使用本文模型Msicc-NER与BERT+LSTM+CRF、BERT+BiLSTM+CRF、FLAT、PLTE[19]等模型在构建的网络安全领域数据集上进行实验对比,识别结果如表5所示。

表5 不同模型在网络安全数据集上识别结果
由表5可以看出,本文模型在网络安全领域实体识别任务中取得了较好的效果,精确率、召回率和F1值为0.864 9、0.840 2和0.852 3,相较其余4种模型都有一定程度的提高。Msicc-NER相比LSTM模型的F1值提升8.98%,比BiLSTM模型F1值提升4.91%,比FLAT提升2.32%,比BERT+FLAT提升了1.68%,比BERT+PLTE提升了1.88%。其中,FLAT相较于LSTM与BiLSTM模型性能提升的主要原因在于模型中引入了词汇以及词汇位置信息,而BERT+FLAT相较于FLAT模型性能提升的主要原因是加入了BERT预训练模型的字向量信息。同时,本文模型的F1值是5种模型中最高的,主要原因在于本文模型同时将汉字偏旁信息和字频信息等先验知识融合进BERT字向量,又将字向量和词向量进行输入,实现了字、词融合进而提高了模型的性能。
为更形象地表示模型的性能,在网络安全数据集进一步进行模型实验对比,得出如表6所示的准确率。通过表6可以看出,与其他模型相比较,本文模型Miscc-NER取得最高的准确率96.54%,进一步体现了本文模型的有效性。
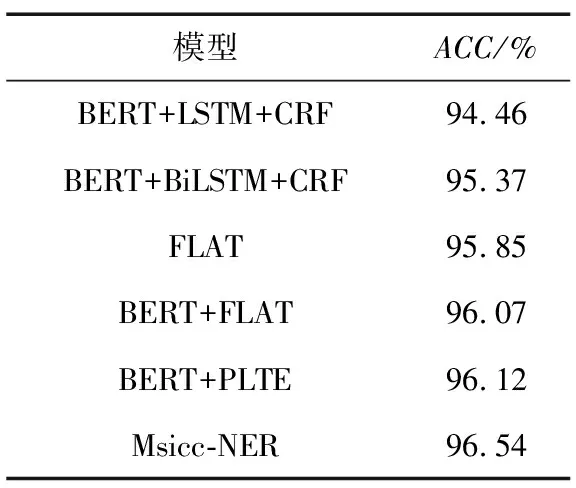
表6 不同模型在网络安全数据集上ACC值对比
图9为本文模型Msicc-NER在网络安全领域数据集上ACC值随着训练轮数的增加变化曲线,可以看出,ACC值首先快速增加,说明本文模型随着训练轮数的增加可以使神经网络有效地学习到知识;然后ACC曲线在ACC=0.965处逐渐趋于平缓,说明本文模型预测正确的概率在96.5%左右。
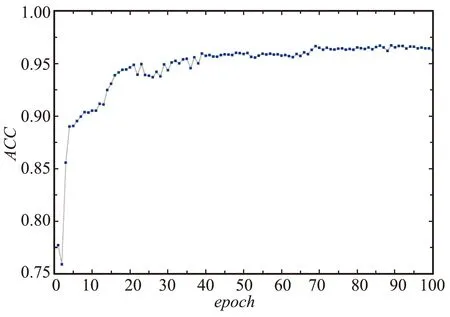
图9 Msicc-NER模型在ACC变化曲线Fig.9 ACC variation curve of Msicc-NER model
选取漏洞类型、软件名和相关术语3种类型的实体进行精确率、召回率和F1值比较,对比结果如表7所示。
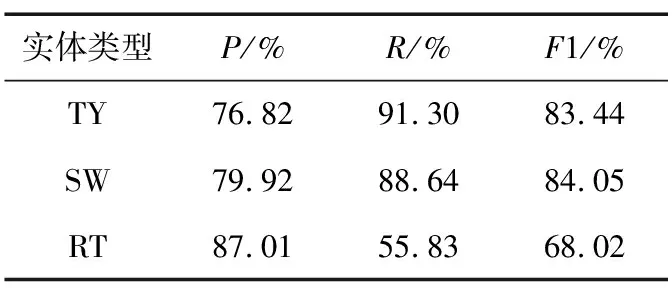
表7 Msicc-NER模型在数据集上识别效果对比
通过表7可以看出,相关术语实体识别性能的召回率和F1值相较于其他实体类型的识别性能比较低,主要原因是相关类型实体的定义比较宽泛,标注时的规则不是太明确,进而导致模型无法很好地学习,实体识别不完全。
4 结束语
本文提出一种融合汉字偏旁信息、字频信息以及词汇信息的中文网络安全命名实体方法,结合网络安全领域的特点设计了7种实体类别,通过实验证明了本文模型的有效性,为后续网络安全知识图谱的构建提供了帮助。在后续工作中将设计更加合适的模型算法,进行网络安全领域实体关系的抽取。
