基于多尺度YOLOv5的交通标志检测
2024-03-05朱宁可张树地王翰文李红松余鹏飞
朱宁可,张树地,王翰文,李红松,余鹏飞
(云南大学 信息学院,云南 昆明 650504)
0 引言
随着现代网络技术以及经济的发展,汽车的使用方便了大众的生活,自动驾驶以及智能辅助驾驶系统逐渐进入商业领域。交通标志的检测对于行车安全至关重要,但是交通标志常常会受到天气、光照、遮挡等因素的影响,这给无人驾驶的应用带来了很大的安全挑战,因此设计出一种既实时又准确的交通标志检测智能系统至关重要。
交通标志检测是智慧交通系统(Intelligent Traffic System, ITS)以及无人驾驶系统的基础。在过去的几十年中,目标检测所采用的方法较为传统,通过采用手工设计特征加浅层分类器来进行目标的获取以及分类。例如,朱双东等[1]通过将RGB彩色交通标志图片转化到HIS颜色空间以降低光照对图片的影响,但此过程仍具有一定的计算量。Gavrila等[2]通过方向梯度直方图(Histogram of Oriented Gridients, HOG)进行模板匹配的形状检测。汤凯等[3]提出一种颜色特征、形状特征和尺度特征的多特征协同方法,采用支持向量机(Support Vector Machine,SVM)对融合的特征进行分类来获取预测结果。甘露等[4]使用Gabor滤波来提取交通标志的纹理特征以及形状特征,将纹理特征以及形状特征融合输入到BP神经网络进行分类,有效地提升了精度。时至今日,交通标志检测的主流方法是通过深度学习进行交通标志的分类以及预测位置。由于基于候选框的深度学习目标检测算法精度较高,被研究人员广泛关注,其中,两阶段目标检测算法代表性的是由Girshick等[5]提出的一种基于候选区域的目标检测算法——R-CNN(Regions with CNN features),该网络通过深度卷积神经网络(Convolutional Neural Network,CNN)对目标区域进行分类取得不错的效果,但是该网络过多地重复选取候选框造成大量存储资源以及计算资源的浪费。Girshick[6]提出的Fast R-CNN以及Ren等[7]提出的Faster R-CNN在R-CNN的基础上进一步将候选窗口的生成和候选窗口的分类与回归统一到一个网络中联合学习,大大提升了网络的检测速度。另外,一阶段代表性的目标检测算法主要包括SSD[8]算法以及YOLO系列算法,其中SSD算法采用不同特征层来预测不同大小的物体,YOLO则是将图像分成N×N大小的子区域,并预测每个区域是否存在目标物体以及目标物体的类别、概率和位置。一阶段目标检测算法速度快,可以满足实时检测的要求,但是其精度不如两阶段目标检测算法。因此,本文选择YOLO系列进行改进,以提升交通标志检测的准确率。
YOLOv5是目前比较主流的一种单级目标检测器,具有优秀的性能以及检测速度,同时还具有清晰的结构来进行分解和调整[9]。虽然YOLOv5是一个强大的目标检测模型,但是其本身被设置为一种通用模型,对于交通标志这种小目标物体检测效果并不会过于显著[10]。因此本文提出了一种多尺度的YOLOv5检测模型来融合更多尺度的信息,以更好地提升检测效果。主要贡献有:
① 将YOLOv5原本的3层特征融合改进为4层特征融合,以便于更好地保留底层信息(包括位置信息、纹理信息等);
② 为了使网络更好地关注小目标,对CBAM注意力机制进行改进,在空间注意力中引入U型结构以及残差结构以提升CBAM对小目标的敏感度;
③ 将Fusion模块嵌入到Path Aggregation Network(PANet)下采样过程中,促进底层信息的保留与融合;
④ 将Adaptively Spatial Feature Fusion(ASFF)模块嵌入到3个检测头前,以便于获取更加丰富的特征进行分类以及位置预测。
1 YOLOv5模型结构
1.1 网络结构分析
YOLOv5的结构是在YOLOv4的基础上进行改进,其中改进的部分主要是在主干部分使用了Focus网络结构,使图片在下采样的过程中,在信息不丢失的情况下,将图像的像素信息集中到通道上,再使用3×3的卷积对其进行特征提取,使得特征提取得更加充分。另外在主干部分以及特征加强网络中也加入了CSPlayer,以更好地提取特征。中间部分是特征加强网络,所采用的结构是PANet[11]。最后是检测头部分,用于检测不同大小的目标物体。
1.2 YOLOv5不足之处
首先,YOLOv5是一种通用的一阶段目标检测模型,如果直接应用于自动驾驶领域则存在对小目标检测能力不足的问题,尤其是在目标存在模糊、密集以及遮挡的情况下;其次,YOLOv5中的特征增强模块PANet侧重于深度特征图的融合,而忽略了底层的细节特征,削弱了对小目标的检测能力,对于小目标的交通标志来说会产生大量的特征冗余,造成计算资源的浪费;最后,小目标物体在经过多次卷积之后会存在部分细节信息和位置信息消失的问题[12]。因此本文对YOLOv5模型进行改进,融合多尺度信息来加强网络对交通标志目标的检测能力。
2 模型改进
根据以上存在的不足,本文分别对特征加强网络、注意力机制进行改进。首先,从主干网络中多引出一层改进特征层,将引出的特征继续与加强特征网络融合,使得网络更多地融合底层的位置信息;其次,底层的特征中也存在着较多的噪声并且对于目标物体的聚焦程度不足,因此在主干网络输出到特征加强网络的特征中添加改进的注意力机制CBAM_U,能够有效地融合底层的语义信息并过滤掉大部分噪声,使得网络对于目标物体更加敏感。然后在网络中添加细融合Fusion模块,促进自身特征之间的细融合;最后在特征加强网络后加入ASFF消除融合后特征之间的冲突。改进的YOLOv5结构如图1所示。

图1 改进YOLOv5结构Fig.1 Structure of improved YOLOv5
2.1 PANet改进
在自动驾驶的真实场景图片中,交通标志的像素仅占很小一部分;不同的交通标志有着尺度不一的特点,想要更加精确地识别交通标志,低层次的语义信息显得格外重要。YOLOv5与YOLOv4所使用的PANet结构相似,均是采用双多向融合的方式,即由下向上融合以及由上向下融合。在YOLOv4的PANet结构中,每次进行Concat拼接之后会经过5次卷积来调整通道数,加深网络,以此来增强特征的提取能力。而YOLOv5中使用的是C3模块,对特征进行反复的提取,但在C3模块中,先将特征的通道数进行降低后再进行卷积,所以产生的参数量更少。在YOLOv5的PANet中,由主干网络传入3个有效特征层,层级之间经过尺度变换进行融合,使得卷积网络的高级特征包含对象的全局语义信息,有助于区分不同的目标对象,具体结构如图2所示。
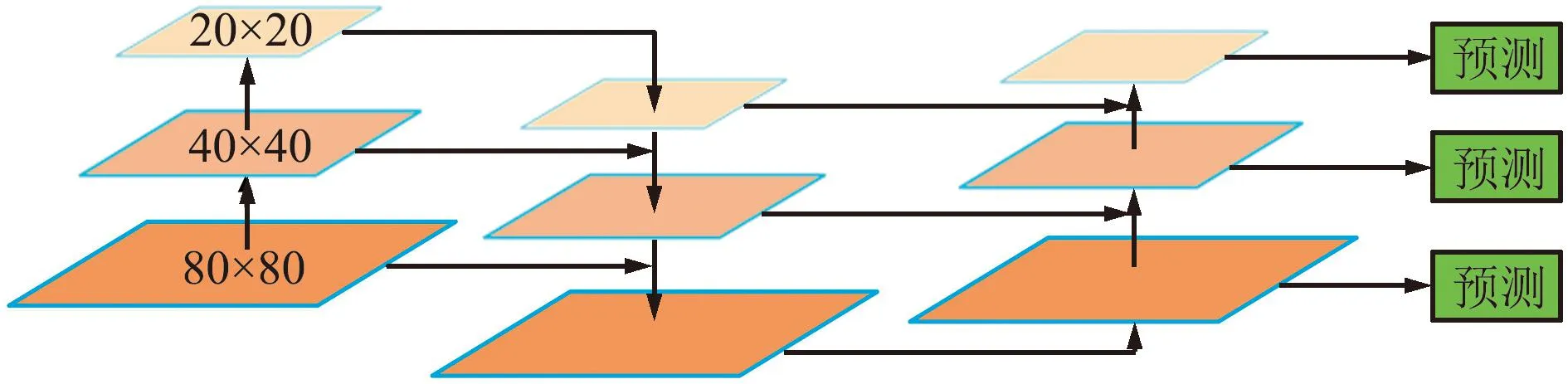
图2 原始PANet结构Fig.2 Structure of original PANet
然而随着卷积层的加深,卷积网络对于目标物体位置的变化不再敏感,导致高层次特征在物体的位置定位方面显得不足[13]。在低层次的特征中存在较多的位置空间信息,为了融合全局语义信息和空间位置信息,本文提出一种改进的PANet——PANet_M,在YOLOv5的PANet基础上额外增加一层融合,将高层次语义信息与低层次特征相结合,以获取更加丰富的信息和表达准确的特征图。
在YOLOv5中,颈部特征加强网络共设定3个检测尺度,分别是80×80、40×40和20×20,其中80×80的尺度用来检测小目标,40×40与20×20的尺度分别用来检测中目标以及大目标,具体结构见图2。本文从YOLOv5的主干网络中额外引出一层160×160的特征层与80×80的特征层进行融合,加强低层的语义信息,使每个特征层的语义信息更加丰富。具体改进结构如图3所示。
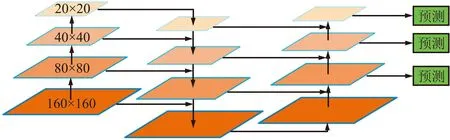
图3 PANet_M结构Fig.3 Structure of PANet_M
2.2 CBAM注意力机制改进
注意力机制能有效地将计算资源分配给更重要的任务,同时解决信息超载问题。CBAM注意力是一种结合了空间(spatial)和通道(channel)的注意力机制模块[14]。CBAM中通道注意力机制聚焦于“什么”是有意义的输入图像,使用平均池化操作对输入特征图的空间维度进行压缩,来聚合特征图的空间信息并生成平均池化特征,与此同时使用最大池化聚焦于独特的物体特征并生成最大池化特征,所生成的2个特征被转发到一个共享的网络来产生通道注意力映射,最后共享网络应用于每个描述符后使用Element-Wise求和的方式来合并输出特征向量,通过Sigmoid函数进行标准化得到通道特征权值。空间注意力模块聚焦在“哪里”是最具信息量的部分,首先将通道注意力模块产生的特征图经过最大池化与平均池化得到2个H×W×1的特征图,其次这2个特征图基于通道做Concat拼接操作聚合成一个特征图的通道信息,然后将这些信息通过一个标准卷积产生2D空间注意力,最后通过Sigmoid进行标准化得到最终注意力特征图,CBAM结构如图4和图5所示。
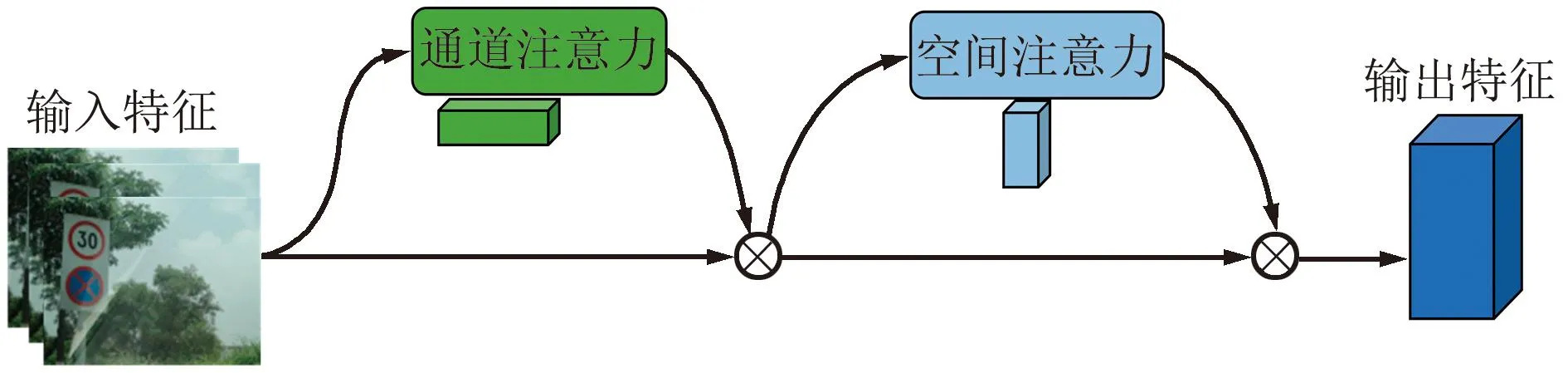
图4 CBAM模块Fig.4 CBAM module

图5 通道注意力模块与空间注意力模块Fig.5 Channel attention module and spatial attention module
本文中使用CBAM注意力机制并对其进行改进,使其更适应小目标交通标志的特性。通过对交通真实场景进行分析,可以发现复杂道路背景的干扰信息是交通标志定位和识别过程的一大障碍[15]。在目标检测的过程中,神经网络通常会滑动图片的所有区域进行特征提取,而不区分对象区域和非对象区域,因此没有特别的模块突出对象区域的重要性[16]。通过以上分析,本文改进了CBAM中的空间注意力模块——CBAM_U来解决上述问题,改进结构如图6和图7所示。
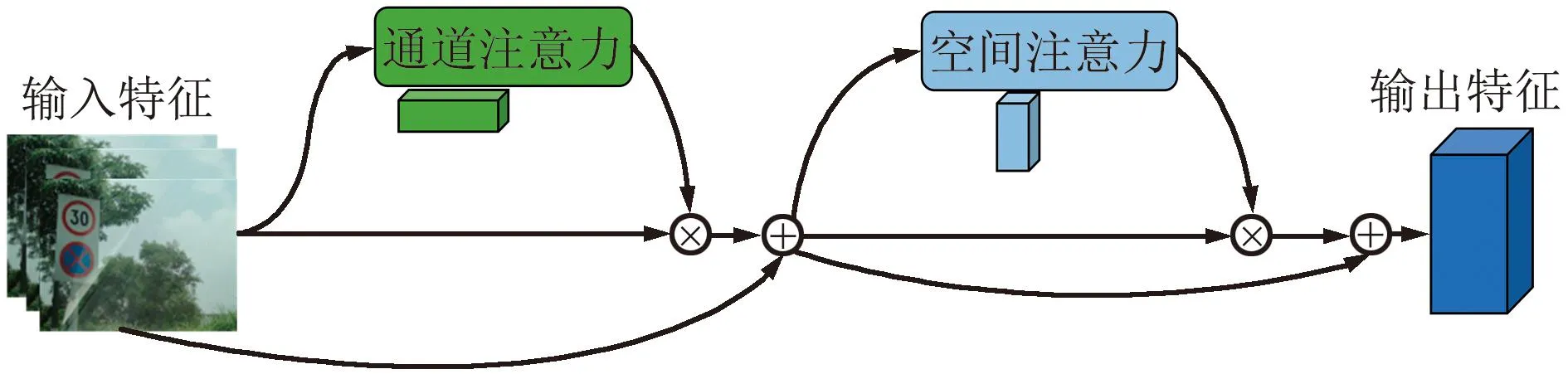
图6 CBAM_U模块Fig.6 CBAM_U module
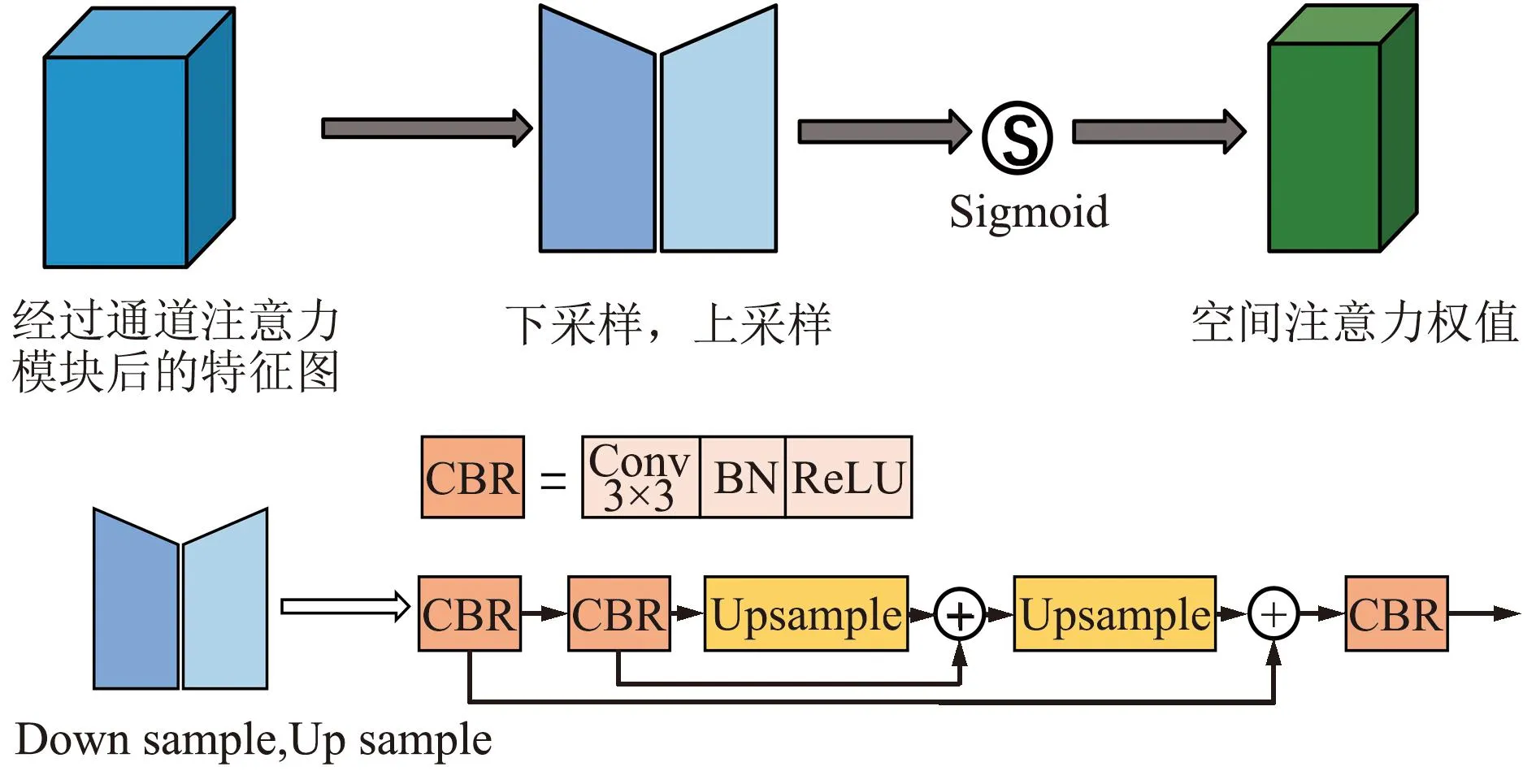
图7 改进空间注意力模块Fig.7 Improved spatial attention module
空间注意力机制主要模拟人眼的视觉神经,聚焦于特征图中重要的目标区域并过滤掉特征图中的干扰区域。受PANet以及U-Net[17]的启发,U型结构能够有效突出目标物体并且过滤掉部分干扰信息,因此本文在空间注意力模块中引入U型结构来探索每个特征图的空间信息,通过2次卷积快速获取高层次语义信息。高层次特征图中含有高级语义信息和少量空间位置信息,通过U型机制,低层次的语义信息能够通过跳跃连接与高层次语义信息进行融合,将底层的位置信息发送给高层。同时为了在不破坏原始特征图的情况下使用与残差网络[18]相似的结构,将高级特征与低级特征合并,并逐元素相加融合。使用Sigmoid函数增加网络的非线性,输出特征权值。另外,在通道注意力机制中加入残差连接确保每次聚焦特征层的有效性。
2.3 Fusion模块
在特征加强网络中,由于YOLOv5在特征融合中使用了多个上采样进行多层次的融合,即不同层级之间实现粗融合,使得一些关键性的细节信息丢失。为了解决此问题,在更细粒度的级别上合并多级特征,本文引入了一种Fusion模块来获取更精细的特征,具体结构如图8所示。本文提出的Fusion模块借鉴了RFB[19]的Inception结构的思想,输入的特征通过2个不同的分支并行,其中一个分支通过一个1×1卷积获取原始特征,相当于保险丝的作用;另一个分支增加额外的3×3卷积来增加不同的感受野,不同的2个卷积核产生具有不同感受野的2个特征,相当于产生2个不同的尺度特征。简单地将这2个特征通过逐元素相加的方式实现精细的局部多尺度融合,使得自身某些细小的特征得到加强,即实现下采样特征的细融合。
2.4 ASFF模块
在YOLOv5的特征金字塔中,多尺度融合是解决多尺度目标检测的有效方法,但是不同层级之间的特征存在一定的信息冲突,即不一致性,不同特征尺度之间的不一致性是基于特征金字塔的单阶段检测器的主要限制。为了抑制这种不一致性,Wang等[20]与Zhu等[21]将相邻级别的相应区域设置为忽略区域,但相邻级别的松弛往往会导致更差的预测为误报。本文引入ASFF模块[22]来抑制不同层级之间的特征的信息冲突,提高PANet的融合效果,进而提高目标检测的能力,具体结构如图9所示。
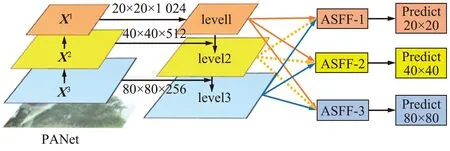
图9 ASFF模块Fig.9 ASFF module
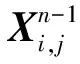
(1)
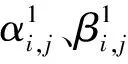
(2)
即通过不同层级之间自适应学习各尺度特征图融合的空间权重来解决不同层级之间存在的信息冲突。
3 实验与结果分析
3.1 数据处理
本文所使用的是长沙理工大学制作的2021版CCTSDB中国交通标志数据集[23],包含1.2万张图片以及对应的标注信息。本文的交通标志主要分为3类:警告类(warning)、禁止类(prohibitory)以及指示类(mandatory)。为了提高模型的泛化能力以及鲁棒性,使用了YOLOv5中的Mosaic[24]数据增强。
Mosaic数据增强简单来说就是将4张图片通过随机缩放、随机裁剪和随机排布的方式进行拼接,该数据增强的方法能够丰富检测物体的背景以及小目标,极大地丰富了数据集,使网络更具有鲁棒性。
3.2 实验环境及评价指标
本文采用pytorch深度学习框架,Windows 10操作系统以及GeForce RTX 3090显卡进行实验。使用随机梯度下降法(SGD)来优化调整网络参数,初始学习率为0.01,权重衰减系数为0.000 5,还使用了动态调整学习率进行训练,其中动态调整学习率的方式为cos,另外还使用了混合精度以节省显存资源。
本文所采用的评价指标为平均准确率(mAP@0.5)、召回率(Recall)、查准率(Precision)以及F1-Score。将测试结果划分为四大类,分别为真正样本(True Positive,TP)、假正样本(False Positive,FP)、真负样本(True Negative,TN)和假负样本(False Negative,FN),具体方式如表1所示。

表1 混淆矩阵
Precision是指所有正样本中检测结果为正样本所占的比例,能够衡量模型的错检程度,即:
(3)
Recall是指所有正样本中正确识别的概率,能够很好地衡量模型的漏检程度,即:
(4)
mAP@0.5的值与AP有关,AP表示当混淆矩阵的IoU置信度取0.5时,针对目标检测中的某一类别具有x个正样本预测框,按照置信度进行降序排列,每一个预测框对应一个查准率(Pi),将所有的查准率求和取平均即可得到该类别AP的值,即:
(5)
mAP@0.5定义为检测目标中所有类的AP值取平均,mAP@0.5衡量一个模型对于每一类的查准率随召回率的变化,能更直观地表现出分类器的性能,mAP@0.5的计算为:
(6)
F1-Score是查准率与召回率的调和平均数,能够很好地评价检测算法的优劣。由于交通标志识别关系到安全方面的问题,需要较高的Precision与Recall,本文将二者的权重设置为相同,具体为:
(7)
3.3 实验分析
3.3.1 消融实验与分析
为了验证本文改进模块的效果进行消融实验,消融实验所得出的结果如表2所示。
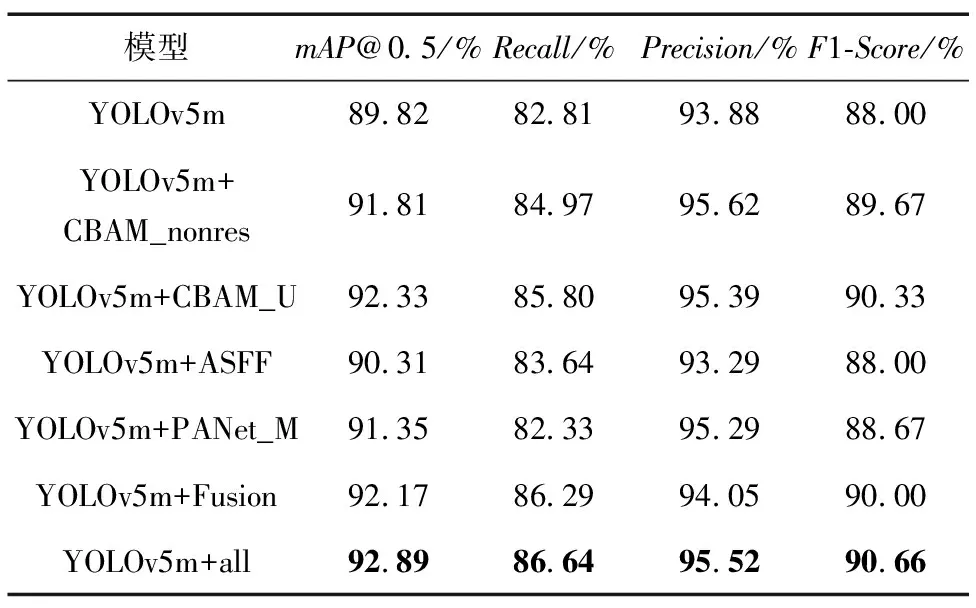
表2 消融实验
由表2消融实验可得,在CBAM通道注意力中加入残差连接相比于不加时,在mAP@0.5上提升了0.52%,确保了每次聚焦特征的有效性,通过将不同尺度的特征层分别进行粗融合与细融合,本文所提出的各个模块在原始模型中都有较大的提升。另外,本文提出的改进YOLOv5与原模型相比,mAP@0.5提升3.07%,Recall提升3.83%,做到交通标志检测的漏检程度更低;通过引入改进的注意力机制使得网络能更好地聚焦于目标物体,使得Precision提升了1.64%,准确率得到较大提升;另外F1-Score提升了2.66%,做到了Recall与Precision的平衡,检测算法更加优秀,具有良好的应用价值。
3.3.2 交通标志检测模型对比
交通标志检测模型对比如表3所示。可以看出,本文改进的YOLOv5模型相比于SSD、FCOS、YOLOv4和Centernet检测模型,mAP@0.5分别提升了4.92%、6.17%、2.59%和1.55%,另外F1-Score分别提高了22.99%、9.33%、2.66%和0.53%。相比于较新的目标检测模型YOLOv5-6.0、文献[25-26],mAP@0.5分别高出0.7%、8.54%和0.42%,Recall与Precision也都有部分提升,由于模型参数量增加,所以在检测速度方面存在少许下降,但仍能满足实时性的要求。可见通过将多尺度的不同信息进行融合能够使网络捕捉到更多的细节信息,提升不同尺寸检测下的精度,改进的YOLOv5模型相比于这些模型更能满足在真实驾驶场景中高准确率的需求。
不同尺寸指标对比如表4所示。可以看出,在不同尺寸的检测中,本文的算法相比于原始网络在APs、APm以及APl中分别提升19.5%、7.2%以及2.7%,另外Recall分别提升18.1%、7.2%以及4.4%,做到了Precision以及Recall的同时提升,基本解决了小目标检测难、漏检率高的问题。
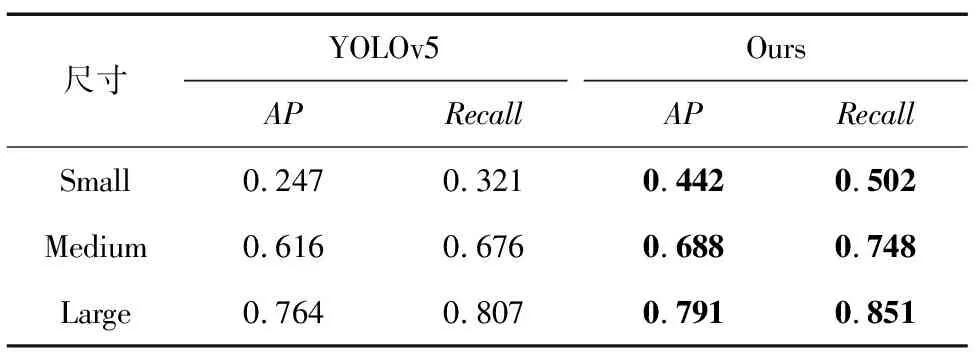
表4 不同尺寸指标对比
3.3.3 图片检测结果与分析
随机抽取网络搜集的不同目标尺寸的交通标志图片进行可视化比较,如图10所示,从左到右依次是YOLOv5检测结果以及改进YOLOv5检测结果,将目标物体分为小、中、大3种不同的尺寸进行检测。从图10可以看出,在小目标检测中,原始YOLOv5检测算法存在漏检的情况,而本文改进的算法对于小目标较为敏感。在中目标检测中,原始YOLOv5算法存在误检的情况,将背景物体检测为交通标志,这对无人驾驶领域是不安全的。在大目标检测中,本文的检测算法精度更高。综上,改进的YOLOv5算法在交通标志检测中具有更好的性能。

图10 CCTSDB检测结果可视化Fig.10 Visualization of CCTSDB detection results
通过模拟不同场景下的检测来检验网络的合理性。本文在网络搜集的交通标志图片中模拟了雾天、雨天以及夜间的场景分别进行检测。不同场景检测结果可视化如图11所示,通过图11雾天模拟场景可以看出,改进后的YOLOv5能够检测出大部分的交通标志,而原始网络仅能检测出一个,并且存在误检的情况。雨天场景中2种网络均能检测出所有交通标志,但是改进的YOLOv5算法的置信度更高,受噪声影响较小。在夜间检测的情况下本文算法没有出现误检的情况,而原始网络将指示类标志(mandatory)检测为禁止类(prohibitory),这对于真实的应用场景来说是很不恰当的。

图11 不同场景检测结果可视化Fig.11 Visualization of detection results in different scenarios
另外,本文通过热力图Grad-CAM[27]来解释改进的网络对于不同尺寸目标物体所带来的提升,通过图12能直观地观察到在小目标检测中,原始网络对于小目标的注意是不够的,在图12(a)的检测中存在多个目标并且小目标居多,原始网络在检测中存在漏检的问题,较小的警告类标志未检测出来;在较远距离的小目标检测图12(b)中对于目标物体的敏感程度是不够的。本文所提出的网络能更精确地定位到小目标交通标志,并且不存在漏检的情况。

图12 小目标热力图Fig.12 Small object heatmap
对于中目标,通过图13(a)能够看出,本文的网络能够很好地注意到目标区域,而原始网络受到过多的背景信息干扰使得指示类标志敏感度降低。在图13(b)的检测中,原始网络将背景信息的一卷线缆误识别为目标物体,这对交通标志检测领域来说是很不恰当的。

图13 中目标热力图Fig.13 Medium object heatmap
对于大目标物体来说,尺寸较大,相对较好检测,但是在背景信息比较复杂的情况下原始网络的目标聚焦程度可能会受到很大的影响。图14(a)中的背景较为复杂,原始网络很容易受到干扰,而本文的网络通过注意力以及多尺度融合使网络对于目标物体的聚焦程度增加,性能表现更优。图14(b)中的检测则是背景信息与目标信息较为相似,原始网络将目标物体误认为背景信息,而改进的YOLOv5算法表现更佳,能够注意到所有的目标物体。
4 结论
本文为了解决交通标志检测中检测难、精确度低以及漏检率高等问题,提出了一种改进的YOLOv5算法。通过融合多层的主干特征解决对目标物体位置信息不足的问题,将输入的特征层通过改进的注意力机制滤除多余的噪声。在特征金字塔中加入Fusion结构促进特征之间的细融合,使用ASFF结构对输出的3个特征进行一致性融合,提升网络的检测能力。改进的YOLOv5模型在小、中、大3种目标尺寸的检测中mAP@0.5、Precision和Recall均有很大提升。所以本文提出的改进算法在自动驾驶辅助系统以及无人驾驶技术中有着较高的实用价值。本文所提出的模型存在一定的局限性,由于CCTSDB仅存在3种类别,模型可检测的种类可以做进一步拓展。针对自动驾驶的应用还可以将改进的算法进一步优化,以方便移植到算力有限的移动设备中。
