基于浏览记录的个性化新闻推荐实证分析
2024-03-05高小虎孙克争
王 妍,高小虎,孙克争
(江苏商贸职业学院,江苏 南通 226011)
0 引言
随着信息技术的发展,短视频开始兴起,并时时刻刻在生产网络新闻。网络新闻具有传播速度快、互动性强、信息量大、时效性强等特点,阅读网络新闻已经成为人们增长知识、了解世界动态的重要方式。用户阅读网络新闻时一般选择自己熟悉或知名的网络平台,在浏览时往往具有随意性,除了自身感兴趣的主题外会浏览近期热点新闻话题。如何向用户推荐符合其喜好的新闻成为各大网络平台提高核心竞争力的关键,新闻网站需要精准快速地向用户推荐个性化新闻,优化用户体验感,减少用户搜索新闻的时间。刘佳茵基于知识图谱构建了个性化新闻推荐模型,可以给用户推荐符合其偏好的新闻。胡凯达提出了改进后的循环神经网络算法模型,并结合用户的兴趣特征进行新闻推荐。不同的推荐算法有着不同的适用范围和优缺点,目前的个性化新闻推荐系统可以分为两种,即基于内容的个性化新闻推荐和基于协同过滤的个性化新闻推荐。基于内容的个性化新闻推荐是指对新闻记录和用户数据进行建模,对用户曾经浏览过的新闻进行分析,找寻与该新闻相似的新闻并将其推荐给用户。基于协同过滤的个性化新闻推荐则更注重用户的历史行为,可以通过用户的历史行为来预测其未来的行为,进而向用户推荐个性化的新闻内容。基于物品的协同过滤推荐算法建立个性化新闻推荐模型,是对优化推荐模型的探索,有利于进一步优化个性化新闻推荐系统,提高新闻网络平台的竞争力。
1 基于物品的协同过滤推荐算法
协同过滤推荐算法的原理是用户会喜欢与自己兴趣爱好相似(同样的历史行为)用户喜欢的物品,如某个用户的朋友喜欢电影《流浪地球》,该算法就会推荐电影《流浪地球》给该用户。协同过滤推荐算法主要分为两种,即基于用户的协同过滤推荐算法和基于物品的协同过滤推荐算法。
基于物品的协同过滤推荐算法是各大新闻门户网站普遍使用的推荐算法,亚马逊、Netfix、YouTube的推荐算法都是对基于物品的协同过滤推荐算法的改进。基于物品的协同过滤推荐算法不再测量用户间的相似度,而是计算物品间的相似度,如用户在网上商城购买了一款手机,网页就会向用户推荐这款手机的手机壳。基于物品的协同过滤推荐算法能够计算出手机壳与手机之间具有很大的相似度,所以推荐手机壳。该算法是向用户推荐与其过去喜欢的物品相似的物品,通过分析用户的行为记录演算出物品与物品间的相似度数值,而不是简单地利用物品本身的特征来计算,即对物品a有兴趣的用户大概率对物品b也有兴趣才会认为物品a和物品b具有相似性。基于物品的协同过滤推荐算法的概念示意图详见图1,具体步骤为:①基于用户过往的行为特征,求出某一物品与另一物品之间的相似度数值。②凭借物品之间的相似度数值和用户过往的行为特征生成推荐列表。

图1 基于物品的协同过滤推荐算法的概念示意图Fig.1 Conceptual diagram of item-based collaborative filtering recommendation algorithm
如表1所示,用户X喜爱物品甲与物品丙,用户Y喜爱物品甲、物品乙和物品丙,用户Z喜爱物品甲,通过分析可确定物品甲与物品丙比较相似,喜爱物品甲的人也可能喜爱物品丙,由此推断出用户Z大概率也会喜爱物品丙,所以将物品丙推荐给用户Z。

表1 基于物品的协同过滤推荐Tab.1 Collaborative filtering recommendations based on items
基于物品的协同过滤推荐算法根据用户的历史行为向用户做推荐解释,可信度较高,用户只要对一个物品产生行为,即向其推荐与该物品相关的其他物品,使推荐更加个性化,能反映出某位用户的兴趣传承。该算法适用于物品数量少但用户数量多的情况,可以用来进行个性化新闻推荐。
2 数据来源说明
为验证基于物品的协同过滤推荐算法的推荐效果,通过网络爬虫技术从某新闻网站上抓取309 907条可用新闻浏览记录,每一条记录有5个特征,分别为用户编号(user_id)、新闻编号(news_id)、新闻标题(news_title)、新闻发布时间(news_times)与新闻详细内容(news_all)。用户编号是用户唯一标识,已做脱敏化处理,新闻编号是新闻唯一标识。详见表2。

表2 部分原始数据Tab.2 Part of original data
3 实证分析
以Anaconda为实验研究平台,该平台中包括众多流行的数据分析Python库。通过构建基于物品的协同过滤推荐模型,计算新闻A和新闻B之间的相似度,最后基于相似度矩阵向目标用户推荐与其喜欢的新闻相似度高的其他新闻,主要包括划分数据集、构建物品相似度矩阵并计算物品间的相似度、基于相似度矩阵进行推荐三个步骤。详见图2。
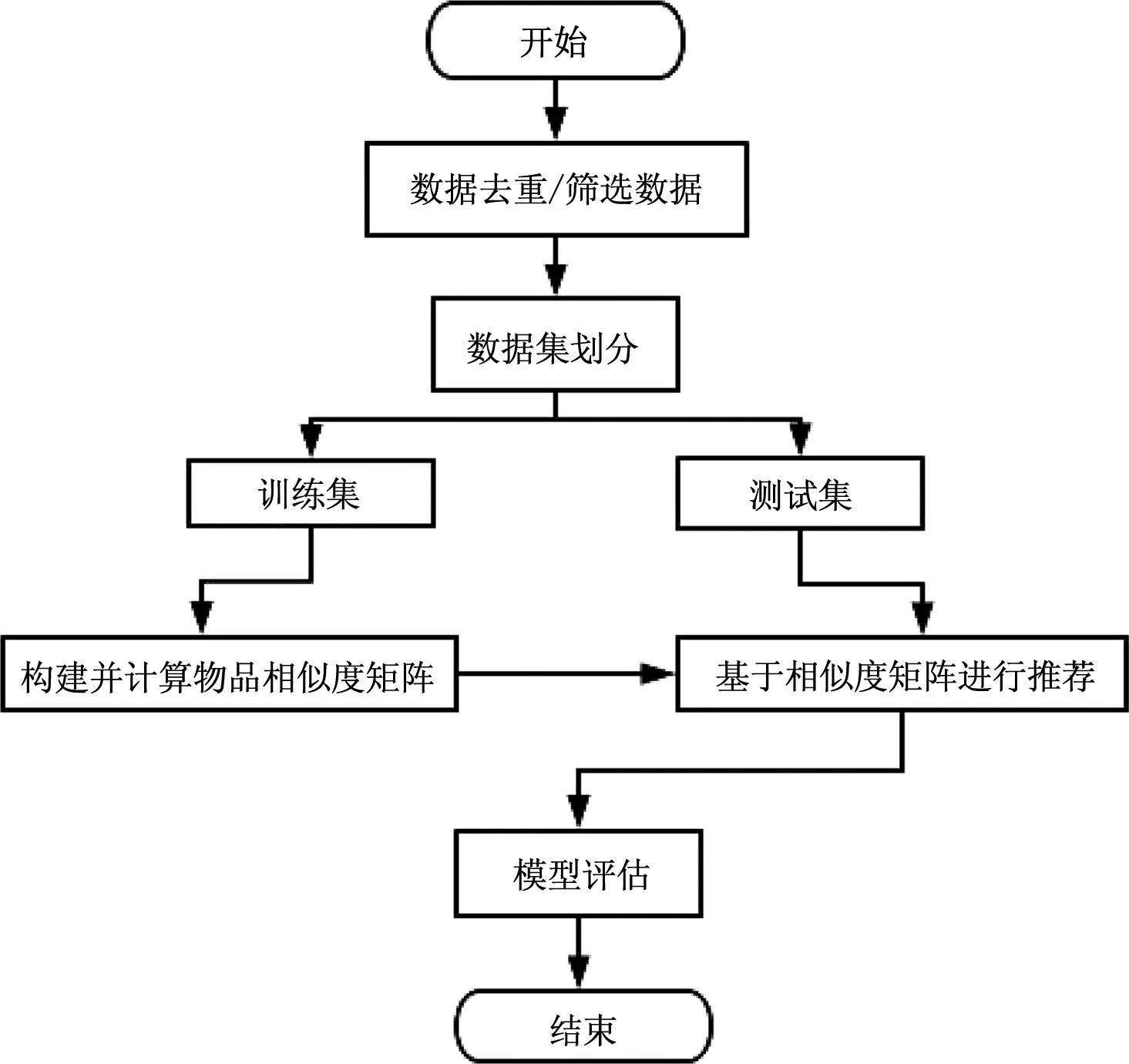
图2 总流程图Fig.2 General flow chart
使用pandas库中的read_csv函数读取数据集,对数据集中的新闻类型进行识别,新闻类型可分为全图或视频、图文一体和全文本三种,数据集中各类型新闻在整个数据集中的占比。详见表3。

表3 新闻类型分布Tab.3 News type distribution
为更好地了解不同新闻类型的浏览量分布情况,使用Matplotlib库中pyplot模块的pie函数绘制浏览量分布饼图,其中全文本类型的新闻浏览量最多,详见图3。
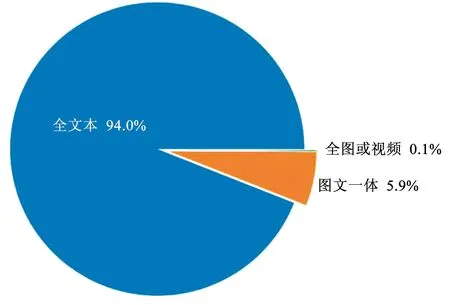
图3 不同新闻类型的浏览量分布Fig.3 Page view distribution of different news types
对数据集中的新闻类型和浏览量进行计数,结果显示,9267条新闻共产生了309 907条新闻浏览记录。浏览记录数据中存在的重复数据会消耗计算资源,使分析结果产生偏差,故先对其进行预处理:只看1~2条新闻的用户大都为随机点击网页查看新闻,可将此类用户定义为“游客”,若将这类用户数据纳入模型进行训练,将导致建模时出现相似度矩阵过于稀疏、计算开销庞大和预测结果精确率较低等情况,因此筛选出查看新闻条数≥3条的用户数据用于模型训练。在构建模型前随机抽取数据集中的数据,按7∶3的比例将数据划分为训练集和测试集,训练集的数据用于训练模型,测试集的数据用于模型评估。详见图4。

图4 预处理后数据集中的数据情况Fig.4 Data in the preprocessed data set
原始数据中只记录了用户浏览新闻的时间及内容,并未对新闻进行相应的评分或评论,因此采用杰卡德相似度计算物品与物品间的相似度,详见式1:
(1)
式中,|N(i)|表示喜欢物品i的用户数,|N(j)|表示喜欢物品j的用户数,|N(i)∩N(j)|表示同时喜欢物品i和物品j的用户数,|N(i)∪N(j)|表示喜欢物品i或物品j的用户数。从式中可以看出,物品i和物品j相似,因为它们同时被多个用户共同喜欢,喜欢它们的用户人数越多物品间的相似性就越高。
基于物品的协同过滤推荐算法,运用式(2)计算出用户u对物品j的喜欢程度:
Puj=∑i∈N(u)∩S(j,k)Wjirui
(2)
式中,N(u)表示所有用户喜爱的物品的总集合,S(j,k)表示与物品j最为类似的k个物品的所在集合,Wji表示物品j和物品i的相似度,rui表示用户u对物品i的喜欢程度。该公式的含义为与用户曾经最喜欢的物品相似度越高的物品在对该用户进行推荐的列表中排名越靠前。
生成推荐列表时,有时需要使用热点新闻补充个性化推荐的结果,这是因为部分新闻的点击量过少,与其最相似的k条新闻中存在相似度为0的新闻,此时仅保留相似度大于0的k1条可推荐新闻,再推荐k-k1条热点新闻。测试集中,由于部分新闻不在训练集的相似度矩阵中,无法根据相似度矩阵进行推荐,因此推荐k条热点新闻作为替代。
根据训练集中的物品相似度矩阵对测试集用户进行推荐,利用离线测试集构造模型评估指标,重点关注指标中的精确率,即真正在测试集中被用户浏览的新闻数与推荐给用户的新闻数的比率。选定测试方法和指标后,对编号(user_id)为174944的用户及其浏览的新闻进行测试,获取用户实际浏览的新闻。详见表4、表5。

表4 174944用户实际浏览的新闻Tab.4 Actual reviewed news of user 174944

表5 174944用户推荐的新闻Tab.5 Recommended news of user 174944
与新闻40相似的新闻有312、26、84、2129、6、353、487、54、1369,其中54是用户已经浏览过的新闻,精确率为8%。采用随机推荐算法,针对6027条新闻进行计算,精确率约为0.016%,说明即便在小样本空间中,基于物品的协同过滤推荐算法也可以有效提高推荐的精确率,且随着样本空间的增大,该算法会更有效,精确率也会继续提升。
4 结论
基于物品的协同过滤推荐算法通过用户的新闻网站浏览记录实现个性化新闻的智能推荐,即根据用户的浏览记录进行用户画像,向用户推荐与其曾经喜欢的物品相似度较高的物品,从而提高个性化新闻推荐的精准度。与随机推荐算法相比,基于物品的协同过滤推荐算法效果更好,推荐精确率更高,但该算法一定程度上忽视了新闻的时效性,在后续的研究中还需进行改进。
