面向视频行为识别深度模型的数据预处理方法
2024-02-29安峰民张冰冰董微张建新
安峰民,张冰冰,董微,张建新*
(1.大连民族大学计算机科学与工程学院,辽宁 大连 116650;2.大连理工大学信息与通信工程学院,辽宁 大连 116024)
0 引言
视频行为识别是计算机视觉中的一类基本任务,在智能监控、信息检索、自动驾驶等领域均具有重要的应用价值。随着深度卷积神经网络(CNN)在图像分类任务上取得的巨大成功,深度模型也逐渐成为视频行为识别中的研究热点[1-2]。与图像分类任务不同,视频行为识别任务的对象是具有复杂时序性质的图像序列,需要在模型中引入时序表示模块并优化图像序列处理效率,由此产生了一系列具有特色的视频行为识别深度模型[3-5]。在探索视频行为识别深度模型网络结构的同时,研究者也认识到以关键帧采样[6-8]与数据增强[9-11]为代表的数据预处理也是提升模型性能的重要手段。
由于视频数据在时间维度上的冗余以及计算资源的限制,将整个视频序列图像直接作为深度网络模型的输入并不现实,因此对视频序列图像进行采样来选取部分关键图像帧作为模型输入是解决该问题的一种有效方式。常用做法是在原始视频中以固定间隔均匀或连续随机采样图像帧[6],但这并未区分不同图像帧对视频整体识别性能的贡献程度。为采样到更具区分能力的视频图像帧,一些研究者通过训练可学习采样模块来自动选择具有重要时空特征的视频帧[12-14],较均匀或随机采样方式更加有效,但该类方法对训练视频数据的依赖性较高,在泛化性上仍存在一定欠缺。为此,研究者提出一种动作指导帧采样的视频动作识别的整体自适应采样策略[3],通过视频中的动作有区别地对帧进行采样,在捕获多数运动信息的同时抑制不相关的背景干扰,证明更优的采样策略可使视频行为识别深度模型获得更高的精度。尽管动作指导帧采样策略具有非常精妙的设计思路,但是其在视频稀疏采样的过程中,却未能有效考虑采样关键视频帧的短期信息。此外,在多个计算机视觉任务上数据增强操作已被证明是增加深度模型训练样本数据量和多样性的重要手段[15-17],既可有效缓解深度模型过拟合问题,又能提高深度模型的鲁棒性和泛化性。同时,不同于图像识别任务,由于视频数据集会带来更大的计算消耗,视频行为识别的数据增强限制性更高,挑战性也更大。在视频行为识别深度模型中,现有工作多数使用的数据增强方法是基于翻转、旋转、裁剪、比例缩放、移位等典型空间变换操作,很少使用多种类型空间变换组合来获得大量扩增数据,使得视频数据样本扩增的丰富性有所欠缺,这在一定程度上影响了视频行为识别深度模型的精度性能。CUBUK 等[9]针对图像识别任务提出一种随机数据增强的图像数据增强方法,采用随机方式来优化选取不同的独立数据增强方法,通过设置增广强度的正则化参数来适应不同深度模型和数据集规模,实现了在大幅缩小增量样本空间的同时保障扩增样本的多样性,从原理上来说其对视频行为识别任务也具有一定的适用性。
针对视频行为识别深度模型在数据预处理中存在的采样视频帧区分性不足和数据增强方式单一的问题,设计一种面向视频行为识别深度模型的数据预处理方法。首先,在视频帧采样策略上以动作指导帧采样方法为基础,综合考虑视频帧间差异特征与视频片段短期时序特征,提出改进的动作指导的片段化视频采样策略,以显著行为动作获取视频关键帧并对其邻近视频帧进行采样,进一步提高所选取视频帧的时空特征区分能力。其次,为了减少扩增参数空间的同时保持视频帧的多样性,借鉴图像分类中的随机数据增强方法,以随机数据增强方式对采样后视频短片段进行数据增强处理,使视频识别深度模型学习到更复杂的空间变化信息。最后,将所提预处理方法在代表性视频行为识别模型和数据集上进行评估。
1 面向视频行为识别深度模型的数据预处理方法
介绍面向视频行为识别深度模型的数据预处理方法,包括在视频行为识别上引入动作指导的片段化视频采样策略和随机数据增强方法。首先,对所提方法进行整体概述;其次,详细介绍动作指导的片段化视频采样策略;最后,详细介绍随机视频数据增强方法。
1.1 方法概述
视频帧采样和数据增强是构成视频行为识别过程的重要部分,所提方法涉及视频帧采样和数据增强2 个部分,整体上属于一种通用的数据预处理策略,其融合长期时序信息、短期时序信息以及复杂空间信息来辅助深度模型实现更精确的预测,在整个视频行为识别中的位置如图1 所示。首先对输入视频使用所提方法进行处理,然后将处理后的帧送入卷积神经网络用于特征提取,最后使用Softmax 分类器进行分类。

图1 视频行为识别中的数据预处理过程Fig.1 Data preprocessing process in video action recognition
视频数据预处理过程如图2 所示,主要包括动作指导的片段化视频采样策略和随机数据增强策略。首先,针对视频帧采样设计出动作指导的片段化视频采样策略,该策略会选择T帧差异显著的帧,这T帧携带着长期时序信息。然后,通过T帧的索引采样一段包含K帧的短片段,使T个短片段进一步引入短期时序信息,通过综合考虑视频帧间差异特征与视频片段短期时序特征,以显著行为动作获取关键视频帧并对其邻近视频帧进行采样,可有效提高所选取视频帧的时空区分能力。最后,借鉴图像分类中的随机数据增强方法,以随机数据增强方式对采样后的视频短片段进行数据增强处理,使视频识别深度模型学习到更复杂的空间变化信息。为保持整个模型的计算效率,在预处理方法中仅复制第一个卷积层中的权重以感知短片段,而网络的其余部分仍然针对T帧进行独立处理。

图2 视频数据预处理过程Fig.2 Process of video data preprocessing
1.2 动作指导的视频采样策略
利用视频中动作来指导采样可以获得重要的可区分信息并有效抑制背景干扰,提高后续特征提取和分类模型的性能。早期研究者常采用光流[13]获得运动表示,但是对其直接计算需要较高的计算资源。为此,研究者提出利用CNN 估计光流并探索了其他光流代替方案[6]。ZHI 等[7]提出基于图像级别和功能级别的运动表示方法,该方法能够以较低的计算成本获得精准的运动表示,参考该方法来获得运动表示Vt,之后使用它执行动作指导采样,实现根据运动表示自适应地选择帧,并使采样帧覆盖重要的运动片段来获得短期信息。具体而言,定义一个关于变量X的累积分布函数:
其中:FX是从概率x1到xn的累积。基于该函数的定义,沿着时间维度构建运动累积曲线,并引入超参数μ调整原始运动分布Vt来控制运动引导采样的平滑度:
如图3 所示,μ值越低,运动幅度的概率分布越均匀。根据运动累积分布曲线,执行动作指导采样策略。该策略首先需要从输入视频中采样T帧,因此将图3 中的y轴均匀地分为T个片段,在每个片段中随机选择1 个值,并根据曲线在x轴上选择相应的帧索引。基于上述方法可得到T帧动作显著的帧,这T帧携带了长期时序信息,但是仅对每个片段采样1 帧会丢弃连续帧中过多有用的短期时序信息[14]。因此,接下来对这T帧进行片段化操作,使其携带短期时序信息。片段化具体操作为:每次对一个短片段(包含K帧)进行采样,而不是仅对单帧进行采样。经过上述方法采样可以得到K×T帧,为了保持稀疏采样的效率,将第一个卷积层中的通道维度相应地扩大K倍,同时将第一个卷积层中的权重也相应地扩大K倍,而网络的其余部分仍然保持不变。具体而言:常规采样方法得到T帧,并将T帧转化为张量并送入卷积神经网络进行识别,而动作指导的片段化视频采样策略得到K×T帧,并将K×T帧转化为张量,其形状为(bs,K×T,c,h,w),将其 重组为(bs,T,K×c,h,w)。由于c维度的 数据增加了K倍,将卷积神经网络的第一个卷积层的通道维度也相应扩大K倍以感知视频短片段中的短期时序信息。为了正确地加载权重,将第一个卷积层的权重同时扩大K倍并沿通道维度进行拼接后再载入模型。

图3 引入μ 的运动累积曲线图Fig.3 Motion accumulation curve with μ
1.3 随机视频数据增强
数据增强操作是增加深度模型训练样本数据量和多样性的重要手段,既可有效缓解深度模型过拟合问题,又能提高深度模型的鲁棒性和泛化性。较先进的随机数据增强方法[9]将多种增强操作相结合在图像识别中取得了巨大的成功。具体而言,图像中的随机数据增强方法需要收集C种增强变换作为参数空间,如表1 所示。
不同于图像识别任务,由于视频数据集会带来更大的计算消耗,因此视频行为识别的数据增强限制性更高,挑战性也更大。为此,尝试将随机数据增强方法引入视频,进一步提高采样数据的短期时序信息与复杂空间信息,提出随机视频数据增强方法。
随机视频数据增强方法中的增强变换同样使用表1 中列举策略,每种变换被使用的概率均相等,为1/C。为减少参数空间并有效保持帧多样性,设定一个超参数N,即每次从C个可用增强变换中选择N个增强变换,可使随机扩增方法具有CN种潜在策略。此外,设定一个参数M,即每种增强变换的强度,并且使用相同的标准来定义M。在给定数据集上对这2 个参数进行网格搜索,可有效提高模型性能。考虑到直接对每个视频帧使用随机数据增强方法会对时间建模造成极大干扰,因此将一组视频帧作为一个单位,该组视频帧使用相同的数据增强方法,而不同组视频帧之间仍然使用随机数据增强策略。具体而言,随机视频数据增强需要T、N、M3 个超参数,其中,T是稀疏采样得到的一组视频帧,N是增强变换的数量,M是增强变换的强度。对于同一组视频的所有帧使用相同的增强变换策略,对于不同视频仍保持增强变换策略的随机性。该方法可在不对时间建模造成干扰的情况下,引入复杂的空间变换,使模型能够有效地学习空间不变特性,以此提高识别性能和鲁棒性。
2 实验结果与分析
本节将详细介绍视频数据预处理方法的实验验证情况。首先,介绍使用的数据集;其次,描述实验设置情况;再次,给出并分析消融实验结果;最后,与代表性视频行为识别模型进行比较。
2.1 数据集选取
在2 个常用视频基准数据集上评估所提方法,分别是Something Something V1[18](简称为S-S V1)和Something Something V2[18](简称为S-S V2)。S-S V1 有108 000 个 视频,S-S V2 有221 000 个视频,2 个数据集中均包含174 个类别。图4 为2 个数据集的部分图像帧示例,侧重于人类与对象的互动,例如拉动某物、推动某物等。S-S V1 和S-S V2 通过对不同的对象(Something)执行相同的操作,使模型被迫理解视频中的行为而不是识别对象,同时对这些行为进行分类需要重点考虑时间信息。因此,准确地捕获时间信息对于该数据集的有效理解是十分必要的。

图4 2 个数据集的部分图像帧示例Fig.4 Partial image frame examples from two datasets
2.2 测试模型和训练设置
使用TSM[19]和TEA[20]2 个典型视频行为识别模型作为基线来评估所提方法的有效性。TSM 模型是视频行为识别领域的经典模型之一,在保留2D 卷积神经网络计算效率的同时,通过时序建模模块捕获时间信息以提高模型性能,TSM 的出现使得以低成本实现高性能的视频理解模型成为可能。具体而言,TSM 模型使用一种通用且有效的时间移位模块,该模块通过沿着时间维度移动部分通道来促进相邻帧间的信息交换,同时可以插入2D 卷积神经网络实现零计算和零参数的时间建模,以此兼具2D 卷积的高效率与3D 卷积的高性能。TEA 作为一种代表性的基于深度学习的视频行为识别模型,在时序建模的基础上能够同时捕获短期和长期时间变化,进一步提高了时序建模模型的识别准确率。具体而言,TEA 模型使用一种新颖的时间激励和聚合模块,主要包括运动激励模块和多时间聚合模块,用于捕获短期和长期时间变化,其中,运动激励模块通过计算来自时空特征的特征级时间差异从而捕获短期时间变化,多时间聚合模块通过堆叠大量局部时间卷积从而捕获长期时间变化。
对于模型训练,裁剪区域的高度(单位为像素)从{256,224,192,168}中随机选择,然后将其输入图像大小调整为224×224 像素,训练时使用的批尺寸为64,学习率为0.01,训练迭代周期为50。对于模型测试,采用1 次剪辑和中心裁剪的策略。所有实验均抽取8 帧(T=8),并设置初始通道数为3(C=3),在使用动作指导的视频采样策略后,通道数量增加到9(C=9),其他参数设置同随机数据增强方法[4],其中增强变换数量和强度均为2(N=2、M=2)。同时,为保证比较的公平性,视频数据预处理方法的权重衰减等其他参数与TSM、TEA 保持一致。此外,在S-S V1 和S-S V2 验证集上进行消融实验时,将输入图像大小调整为112×112 像素以提高消融实验的计算效率。所有实验均在Ubuntu 20.04 系统中进行,使用PyTorch 深度学习框架实现算法,所使用的计算机配置为NVIDIA Geforce RTX 3090。
2.3 消融实验
首先,使用TSM[19]和TEA[20]在S-S V1 数据集上的结果作为基线,并使用112×112 像素的输入图像,基本消融实验结果如表2 所示,其中,√表示使用该方法/策略,最优指标值用加粗字体标示,下同。TSM 在此数据集上的准确率(Top-1)达到41.2%,使用动作指导的视频采样策略(MGS)后,准确率提高到42.4%,比原TSM 模型提高了1.2 个百分点,表明动作指导的视频采样策略的有效性。在进一步引入片段化方法(SS)后,使视频帧携带短期时序信息,其准确率提高到44.6%,比仅使用动作指导的视频采样策略进一步提高了2.2 个百分点,比原TSM 模型提高了3.4 个百分点,表明短期时序信息的重要性及所提动作指导的片段化视频采样策略的有效性。最后,在采样方法的基础上,引入随机视频数据增强方法(RA),进一步引入复杂的空间变换使数据携带丰富的时空特征信息,准确率提高到46.8%,比使用动作指导的片段化视频采样策略提高了2.2 个百分点,比原TSM 模型提高了5.6 个百分点,表明时空特征信息比单一的时序信息更有效,也证明了所提方法的有效性。此外,在S-S V1 数据集上也使用TEA 模型进行了更多的实验,以展示所提方法能够迁移至其他视频行为识别模型。实验结果表明,所提方法使TEA 的分类精度明显提高,准确率提高到49.2%,比原TEA 模型提高了3.6 个百分点,进一步证明了其有效性和可迁移性。
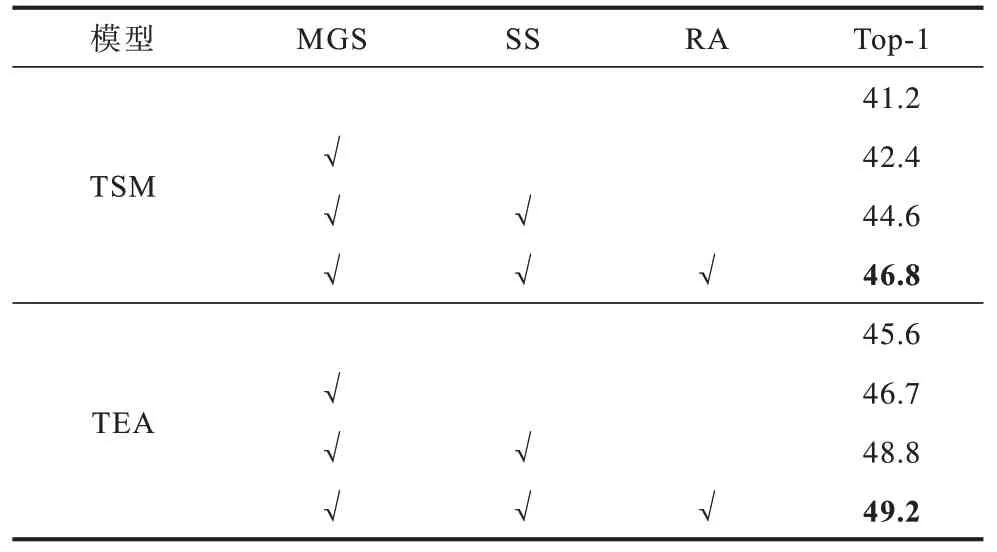
表2 在S-S V1 数据集上的消融实验结果Table 2 Results of ablation experiment on the S-S V1 dataset %
其次,在S-S V2 数据集上使用TSM 和TEA 模型进行消融实验,结果如表3 所示。TSM 模型在此数据集上的准确率为52.3%,使用动作指导的视频采样策略后准确率提高到56.8%,比原TSM 模型提高了4.5 个百分点。在进一步引入片段化方法后准确率提高到58.9%,比仅使用动作指导的视频采样策略提高了2.1 个百分点,比原TSM 模型提高了6.6 个百分点。在采样方法的基础上引入随机视频数据增强方法后准确率可提高到59.1%,比使用动作指导的片段化视频采样策略提高了0.2 个百分点,比原TSM 模型提高了6.8 个百分点。在TEA 模型上同样将基线从59.0%提高到61.5%。上述结果证明了所提方法可以有效提高模型的准确率。

表3 在S-S V2 数据集上的消融实验结果Table 3 Results of ablation experiment on the S-S V2 dataset %
结合表2 和表3 的实验结果可以看出,随机扩增方法在S-S V2 数据集上的准确率提升幅度比S-S V1数据集小。从数据集的介绍中可以看出,Something Something 数据集对不同的对象执行相同的操作,因此模型被迫理解视频中的行为,而不是识别对象。相比于S-S V1 数据集,S-S V2 数据集进一步地弱化了对象,使模型被迫理解时序信息从而理解视频中的行为。因此,S-S V2 数据集更加强调时序信息的重要性,弱化空间信息的重要性,这也是基于动作指导的片段化视频采样策略准确率提升显著而随机视频数据增强方法准确率提升较少的原因。虽然在S-S V2 数据集上准确率提升较少,但仍然使模型得到了更高的识别准确率,表明所提方法的有效性,在2 个数据集和2 个模型上的实验也表明所提方法的可迁移性。
由于上述消融实验在112×112 像素的输入图像上进行,因此在224×224 像素的输入图像上也进行消融实验来验证所提方法的有效性,结果如表4 所示。实验结果表明,所提方法在224×224 像素的输入图像上也仍然保持与112×112 像素的输入图像相似的实验结果。具体而言:在S-S V1 数据集上,使用预处理方法的TSM 模型(简称为VPP-TSM)的准确率比原TSM 模型提升4.2 个百分点,使用预处理方法的TEA 模型(简称为VPP-TEA)的准确率比原TEA 模型提升2.9 个百分点;在S-S V2 数据集上,使用预处理方法的TSM 模型的准确率比原TSM 模型提升3.9 个百分点,使用预处理方法的TEA 模型的准确率比原TEA 模型提升2.3 个百分点。实验结果表明,所提方法在224×224 像素的输入图像的多个数据集和多个模型上仍然有较明显的准确率提升。

表4 在S-S V1 和V2 数据集上的消融实验结果Table 4 Results of ablation experiment on the S-S V1 and V2 dataset %
2.4 与代表性模型的比较
在S-S V1 和S-S V2 数据集上比较了使用所提方法训练的2 个模型 和TSN[6]、GST[21]、TEINet[22]、GSM[23]、TDRL[24]、MSNet-R50[25]、MVFNet[26]、TSI[27]、TDN[28]、AK-Net[29]10 种代表性模型,比较结果如表5所示。由表5 可以看出,在没有使用视频预处理策略的模型中,TDN[12]在S-S V1 和S-S V2 数据集上取得了最高的识别准确率,分别为52.3%和64.0%。同时,TSM 和TEA 模型在2 个数据集上分别获得45.6%、57.9%和48.9%、60.9%的识别准确率,在所有模型中,在S-S V1 上分别排名第11 和第6,在S-S V2上分别排名第10 和第7。然而,使用所提方法训练出的VPP-TSM 和VPP-TEA 模型性能得到了明显的改善,在2 个数据集上分别取得了49.8%、61.8%和51.8%、63.2%的准确率,尤其是VPP-TEA 模型,在2 个数据集上的排名都上升到第2,仅次于TDN。这些实验结果再次证明了所提方法可以有效提高模型性能,使视频行为识别模型更具竞争力,能够与代表性模型相竞争。此外,表5 还给出了各模型的每秒10 亿次的浮点运算数(GFLOPs)结果。从整体上看具有更优识别性能的模型一般需要更大的计算量,但相对于TSM 和TEA 模型的3.3×1010和3.5×1010计算量,VPP-TSM 和VPP-TEA 在未增加计算量的情况下分别可获得最多3.9 和2.9 个百分点的识别准确率提升。然而,由于随机视频增强操作的引入,因此在时间成本上VPP-TSM 和VPP-TEA 较TSM 和TEA模型在训练阶段平均增加了约33%的时长,同时在测试阶段平均多用时约9%。

表5 在S-S V1 和V2 数据集上使用预处理方法训练的2 个模型与代表性模型的比较 Table 5 Comparison of two models trained with preprocessing methods and representative models on the S-S V1 and V2 datasets
3 结束语
本文提出一种面向视频行为识别的数据预处理方法,在采样策略中综合考虑帧间的差异特征与视频片段的短期时序特征,引入随机数据增强用于对采样后视频短片段的数据增强操作,使视频数据能够具有更好的可区分特性并覆盖更复杂的样本空间范围。在2 个公开数据集上对2 个典型视频识别模型的消融实验和对比实验结果证明了所提预处理方法的有效性。尽管模型识别准确率有所提升,但所提预处理方法在一定程度上是以增加时间复杂度为代价,因此在今后工作中,一方面将考虑在片段化过程中融合相邻帧以减少时间复杂度,另一方面将尝试在3D CNN 等架构中进一步评估所提预处理方法的性能。
