基于潜在特征增强网络的视频描述生成方法
2024-02-29李伟健胡慧君
李伟健,胡慧君
(武汉科技大学计算机科学与技术学院,湖北 武汉 430065)
0 引言
视频描述生成旨在根据视频内容自动生成描述性的自然语言句子,视频中蕴含着丰富的信息[1],以往的研究致力于理解静态的视觉信息,但是如何对视频中丰富的时空信息进行建模仍是一项具有挑战性的任务[2]。
视频中显著对象的检测是目前计算机视觉前沿领域必不可少的关键任务,该任务通常被称为目标检测任务。例如,文献[3]提出的OA-BTG 通过构建双向序列图来提取视频中的重要目标,然后整合整个视频中的全局特征生成字幕。文献[4]提出的STG-KD 采用图卷积网络(GCN)对检测到的对象进行关系推理,以增强对象级的关系表示。文献[5]提出的DETR 首次采用Transformer 方法进行视频描述生成中的对象检测,计算输出区域和真实区域的集合相似度,将对象检测视为1 个直接的集合预测问题。因此,处理不同视频帧中对象之间的关系是视频描述生成任务的关键。
现有方法往往是根据编码器-解码器的结构设计来生成视频描述。通过不同的特征提取器,如IncepResNetV2[6]、I3D[7]和Faster R-CNN[8],不同编码器可以从不同角度捕捉视频信息。显然,同时使用不同的特征进行连接可能会取得更优的性能,但是这种方法往往会忽略不同特征之间的上下文语义信息,而这些信息在具有时空信息的视频中起着重要作用。XU 等[9]和WANG 等[10]通过对视频帧进行局部特征融合来学习判别性的特征,从而提高视频描述生成质量。例如,文献[11]提出的SAAT 通过融合对象和时间特征来生成相应的动词。但是,只融合局部特征难以获得全局的时空语义视频信息。例如文献[12]提出的POS+CG 设计1 个交叉门控模块来融合外观和运动特征,并进行综合阐述,然而,仅通过预测的全局POS 来表示生成的每个单词,而忽略了微妙的细节信息,从而难以捕获准确的对象。
为了解决上述问题,本文设计新的潜在特征增强网络(LFAN)模型。该模型融合不同的特征来生成具有更高维度的潜在特征,并且通过构建连接视频特征的动态图来获取时空信息,并利用GNN 和长短时记忆(LSTM)网络推理对象间的时空关系,进一步丰富视频内容的特征表示,并结合LSTM 和门控循环单元(GRU)设计一种新的解码方法来处理上下文信息和全局信息,从而生成准确、流畅的视频描述。
1 相关工作
1.1 视频描述生成
视频描述生成作为计算机视觉和自然语言处理的交叉领域,早期大多数方法都是基于特定的模板[13-15],这些模板需要大量人工设计的语言规则,并且处理有限类别的对象、动作等,难以生成准确的语句描述。
随着深度神经网络的兴起,VENUGOPALAN等[16]提出一种编码器-解码器框架来克服这些限制。当前,基于编解码框架的视频描述生成方法成为主流。YAO 等[17]提出一种动态总结视觉特征的时间注意力机制。CHEN 等[18]提出从视频中去除冗余帧,从而解码重要的视觉信息以生成视频描述。文献[19]提出的M3 通过建立记忆网络来模拟长期的视觉文本依赖,以生成高质量的描述。文献[20]提出的MARN 设计一种记忆结构来寻找候选词汇和包含它所有视频特征的关系。TAN 等[21]提出一种新的时空视觉推理模块RMN,实现显式的、可解释的视频字幕处理。BAI 等[22]采用生成对抗网络(GAN)来保证生成描述的准确性。RYU 等[23]提出一种语义分组网络(SGN),通过语义组预测下1 个生成的单词。Open-Book[24]从语料库中检索语句,作为生成描述性语句的指南。CHEN 等[25]提出R-ConvED,从已注释的视频句子对中检索相关的视觉内容和句法结构,并利用这些上下文知识促进描述性语句的生成质量。
最新的研究挑战则是尝试构建大规模的端到端训练视频描述生成网络,如LIN 等[26]在视频描述生成领域中使用SwinBERT 进行端到端训练,以生成视频描述。但是这类网络模型通常使用Transformer进行编解码,训练参数量庞大,并且需要大量的计算资源。
1.2 潜在特征
不同的特征信息在生成视频描述中起着重要作用。文献[27]提出的GRU-EVE 使用对象标签增强视觉特征的语义信息。文献[12]提出的POS+CG 构建一种新颖的门控融合网络,对视频的外观和运动特征进行编码和融合。文献[4]提出的STG-KD[通过GCN 构建对象关系图,利用对象关系图推理视频对象之间的时空关系以获得潜在特征。文献[28]提出的ORG-TRL 使用GCN 实现关系推理从而获取视频中的潜在特征,丰富细节对象的表示。文献[11]提出的SAAT 设计1 个语法感知模型来增强动词的生成,使动作和目标之间的相关性更强。图1 所示为LFAN 生成描述的直观示例。本文使用基线模型Baseline 作为对比,其中仅使用传统的编码器-解码器框架,没有使用图神经网络和改进的解码方式。从图1 可以看出,基线模型缺乏时空语义信息,无法对视频上下文进行全面探索,从而产生较差的描述。SAAT 生成目标对象和相应的动词,但没有捕获完整的视频信息,从而生成不完整的描述语句。相反,本文模型 通过捕 捉突出 的对象“man”“chicken”和“plastic”,学习它们之间的对应关系从而生成准确的动词“put”,并完整描绘出视频内容。
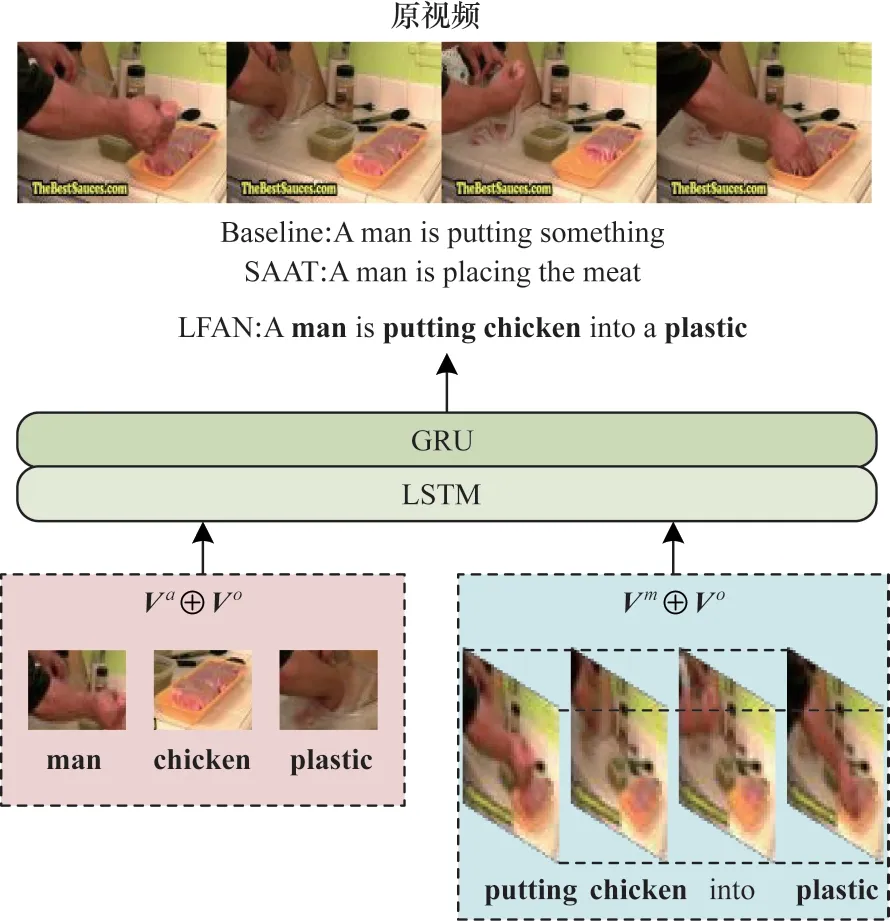
图1 LFAN 生成描述的直观示例Fig.1 An intuitive examples of LFAN generation descriptions
2 潜在特征增强网络
LFAN 模型框架如图2 所示。LFAN 模型由编码层、潜在特征层和解码层组成。首先,利用空间GNN增强目标特征以获得更精确的目标区域;然后,利用语义GNN 和LSTM 融合外观特征、运动特征和对象特征,得到具有语义信息的潜在特征;最后,利用可以处理全局信息的解码器生成视频描述。

图2 LFAN 模型框架Fig.2 Framework of LFAN model
2.1 编码层
在编码阶段,本文使用3 种预训练模型提取视频特征。对于给定的视频帧N,本文使用2D-CNNs和3D-CNNs 分别提取外观特征和运动特征,然后使用R-CNNs 提取区域目标特征区域目标特征包含空间上的额外维度。
2.2 潜在特征层
LFAN 模型使用GNN 融合不同的特征,得到潜在特征,利用GNN 和LSTM 实现潜在特征的增强,并得到更高维度的增强潜在特征,高维度的潜在特征蕴含着丰富的语义信息以生成更准确的视频描述。
对于先前生成的Va,Vm和Vo,本文首先利用动态显著区域图神经网络DyReg-GNN[29]对区域目标特征Vo进行增强,DyReg-GNN 可以通过学习发现与当前场景和目标相关的显著区域来改善视频的关系处理过程,增强后的蕴含时空信息,如式(1)所示:
其中:Ddyreg() 表示DyReg-GNN 中的图神经网络操作。
然后将增强后目标特征的中间2 维降为1 维,再将特征Vi=Va,Vm分别和增强后的区域目标特征由Softmax()函数计算关系矩阵权值:
其中:Wadj∈Rd表示可学习的参数;/代表矩阵点除。
为了让特征同时具有帧级的时间信息和对象级的空间信息,本文将特征Vi和得到的关系矩阵相乘,相乘后的结果和区域目标特征拼接得到潜在特征:
使用1 个双向LSTM 对潜在特征进行编码,将前一时刻的隐藏状态ht-1作为输入:
其中:表示增强的潜在特征;ht表示第t个时刻的隐藏状态;ct表示第t个时刻的细胞状态。由于ht具有丰富的历史信息,因此它对于增强潜在特征具有指导作用。
对增强的潜在特征使用Transformer 中的位置编码,保存特征之间的相对位置用于指导生成更流畅的描述语句,然后通过图神经网络将其融合为潜在特征并参与训练。外观和运动潜在特征如式(7)和式(8)所示:
其中:LPi表示外观和运动潜在特征;PPE()表示Transformer 中的位置编码函数;K()表示kernel 函数,里面是图神经网络模块,包含卷积和批量规范化操作以及GELU[30]激活函数;×表示矩阵乘法;表示最终的增强外观和运动潜在特征;Sselfatt()表示自注意力函数,后面还有1 层LayerNorm 函数。本文考虑到虽然ReLU[31]函数能够解决梯度消失,但是依然存在一些不可避免的问题,如无法避免梯度爆炸,神经网络无法调整学习率的值。因此,本文采用自然语言处理(NLP)领域最近表现较优的GELU 作为激活函数,GELU 在BERT 和Transformer 中也得到了很好的应用。
至此,LFAN 模型完成帧级的外观特征和运动特征同对象级目标特征的融合,从而生成具有时空动态信息的高级潜在特征。
2.3 解码层
本文参考ORG-TRL[6]并设计一种同时使用LSTM 和GRU 的解码方法。LFAN 模型通过注意力LSTM 和GRU 解码潜在特征层生成,从而逐 渐生成最终的视频描述。
首先LFAN 模型对生成的潜在外观特征和潜在运动特征进行均值操作,然后用Cat 操作将它们拼接作为模型的全局视频特征:
其中:表示全局视频特征;Cat()表示Cat 拼接操作。
对于每个时间步长t,LSTM 根据历史隐藏状态、历史细胞状态与均值全局特征以及之前生成的单词wt-1进行连接,历史隐藏状态和细胞状态的表达式如式(10)所示:
对于局部对象特征,LFAN 模型使用DyReg-GNN中的方法,首先将不同帧中的对象对齐并合并在一起,然后使用空间注意模块选择应该关注哪些对象,并提取局部上下文特征。局部上下文特征的表达式如下:
其中:AATT()表示DyReg-GNN 中空间注意模块。
最后,GRU 总结全局和局部上下文特征以生成当前隐藏状态,这样本文生成描述时既有全局相关性也包含细粒度的上下文信息。在将单词概率Pt解码后是单层感知机和解码步骤t时刻的Softmax()运算。隐藏状态和单词概率的计算式如下:
其中:Pt表示词汇量的D维向量;Wz表示权值矩阵;bz表示可学习的参数。
3 实验结果与分析
为合理评估该网络模型的有效性和先进性,本文在2 个广泛使用的基准数据集MSVD 和MSR-VTT 上进行实验,并通过4 个广泛使用的指标BLUE@4、METEOR、ROUGE-L 和CIDEr 进行评估,将该方法与最先进的方法进行比较,并进行消融实验。
3.1 数据集
MSVD 由YouTube 收集的1 970 个网络视频组成,平均视频长度为10.2 s,每个视频大约有41 个英文句子,每个描述平均长度约有7 个单词。本文根据之前的工作[15]将数据集分为1 200 个训练视频、100 个验证视频和670 个测试视频。
MSR-VTT 数据集是开放领域视频字幕生成的大规模数据集,共包含10 000 个视频,平均视频长度为14.8 s,每个视频有20 个人为标注的英文描述,每个描述的平均长度约为9 个单词。本文采用标准分割将数据集分为6 513 个训练视频、497 个验证视频和2 990 个测试视频。
3.2 实验设置
本文在特征提取上使用预训练好的Inception ResNetV2(IRV2)、I3D 和Faster R-CNN 分别提取外观特征、动作特征和目标特征,每个视频采用26 帧的均匀采样,Faster R-CNN 从固定的26 帧中提取36 个proposal。对于语料库的预处理,本文将生成的所有描述转换为小写并去掉标点符号,最大词汇量设置为26 个单词,对超过26 个单词的描述进行零填充。本文将预训练GloVe.6B.300d 词表引入到解码器参与词向量训练,词向量维度为300。
本文用标准的交叉熵损失函数计算模型生成的描述和Ground Truth 间的差异,采用Adam 优化器优化LFAN 模型,初始学习率设为1×10-4,动态调整学习率使其每5 轮削减50%。训练和测试批量大小分别设为256 和128,最大训练迭代轮次设为60 次。在MSVD 和MSR-VTT 数据集上,所有LSTM 模块隐藏状态大小分别设为1 024 和1 536,每个图卷积操作的特征大小为1 024。在测试阶段本文分别使用大小为4 和5 的波束搜索来生成描述。
3.3 实验结果定量分析
为验证LFAN 模型的有效性,本文选择使用CNN 作为编码器和LSTM 作为解码器,在MSVD 和MSR-VTT 2 个数据集上与最先进的方法进行比较。
在MSVD 和MSR-VTT 数据集上不同模型的实验结果如表1 所示,其中,B@4、M、R、C 分别表示BLUE@4、METEOR、ROUGE-L 和CIDEr,加粗表示最优数据。从表1 可以看出,LFAN 具有较强的竞争优势,在MSVD 数据集上,反映描述准确性的BLEU@4 分数为57,反映描述丰富性的CIDEr 分数达到了100.1,在MSR-VTT 数据集 上,BLEU@4 分数为43.8,CIDEr 分数为50.2,在多个指标上都优于主流视频描述生成方法,证明LFAN 模型的有效性。

表1 在MSVD 和MSR-VTT 数据集上不同模型的实验结果Table 1 Experimental results among different models on MSVD and MSR-VTT datasets
在MSR-VTT 数据集上,与不使用对象特征的RecNet、PickNet、MARN、SGN 和Open-Book 相比,LFAN 仅略逊于Open-Book,其原因为Open-Book 在生成关键词时从文本语料库中检索多个与视频内容相关的句子,生成的关键词与参考语句在生成关键词时,会从文本语料库中检索多个与视频内容相关的句子,因此生成的关键词与参考语句的相似度更高。这种方法在METEOR 和CIDEr 评价指标中会获得更高的得分。而在MSVD 数据集上,LFAN 在所有评价指标上都取得比其他方法更优的性能,表明对象特征在视频描述生成中发挥了重要作用,并且学到准确的对象特征。
此外,LFAN 与使用对象特征的OA-BTG、GRUEVE、RMN、STG-KD、SAAT 和ORG-TRL 进行比较。在MSR-VTT 数据集上,当ORG-TRL 引入TRL 外部语言模块来指导模型生成描述语句时,ORG-TRL 的CIDEr 得分增加为50.9,当ORG-TRL 去掉TRL 外部语言模块后,在CIDEr 上的表现不如本文模型,得分为50.1。本文提出的LFAN 在BLUE@4 和ROUGE-L中有更好的表现,表明LFAN 生成的视频描述准确度和召回率更高。
3.4 消融实验
本文主要对潜在特征模块和解码模块进行改进。为了说明本文的改进措施能使模型学到更有效的信息以生成视频描述,本文在潜在特征模块上设计3 个消融实验,分别是仅使用外观特征、运动特征和对象特征来生成视频描述的基线模型。
表2 和表3 所示为使用不同神经网络和不同解码方法的消融实验结果。LFAN-GNN 表示使用图神经网络融合不同特征,LFAN-DG 表示使用DyReg-GNN 加强目 标特征,LFAN-LSTM 和LFAN-GRU 分别是仅使用LSTM 和GRU 作为解码器。从表2 可以看出,无论是使用图神经网络融合不同特征还是加入DyReg-GNN 后,模型的各项指标都有所提升。相比LFAN-GNN,LFAN-DG 在2 个数据 集上的BLUE@4 分别提升了1.9 和0.6,说明本文的改进方法使模型提取到更准确的对象信息。本文在MSVD数据集上的CIDEr 分数比基线模型提高9.8,在MSR-VTT 数据集上比基线模型提高了3.1 的分数,进一步证明LFAN 的有效性。
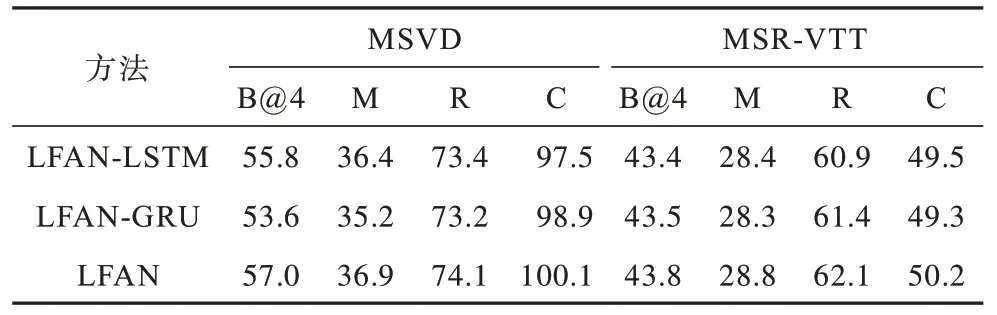
表3 使用不同解码方法的消融实验结果 Table 3 Results of ablation experiments using different decoding methods
从表3 可以看出,本文设计同时使用LSTM 和GRU 的LFAN 显然比单独使用其中1 个解码方法的性能更好,新的解码方法与LFAN-LSTM 相比评估效率也得到了改善,这充分证明了本文改进方法的有效性。
3.5 实验结果定性分析
图3 所示为LFAN 生成的一些描述实例与参考描述(GT)的对比。图3 中第1 行参考视频描述:GT1“a woman is applying something on her eyelids”;GT2“a girl is applying eye makeup”;GT3“a girl is applying makeup to her eyelid”;LFAN“a woman is applying makeup on her eye”。第2 行参考视频描述:GT1“the man is putting meat in the bag”;GT2“a man is adding chicken to a plastic cover”;GT3“a man puts chicken breasts into a bag”;LFAN“a man is putting chicken into a plastic”。第3 行参考视频描述:GT1“a man is dicing food”;GT2“a man is slicing garlic”;GT3“a person is slicing garlic”;LFAN“a man is chopping garlic”。第4行参考视频描述:GT1“a woman is cooking”;GT2“a woman showing how to cut garlic cloves”;GT3“a woman is chopping garlic”;LFAN“a person is preparing some food in the kitchen”。LFAN 可以精准识别出“woman”在“applying makeup”,而不是“draw something”。在第2 行的示例中,LFAN 成功地识别出主要对象信息“chicken”和“plastic”以及人物的动作“putting”,并且排除掉桌子上其他干扰对象信息,说明LFAN 不仅可以识别出主要对象,并且可以精准地描述对象动作。

图3 LFAN 生成描述与参考描述实例分析Fig.3 Example analysis of LFAN generation description and reference description
4 结束语
视频描述生成技术可以广泛应用于各种媒体软件,在视频推荐、辅助视觉、人机交互等领域也具有广泛应用前景[32]。本文提出一种基于潜在特征增强网络的视频描述生成模型LFAN。该模型着重于增强视频特征的时空和语义信息,从而显著提升生成的视频描述质量。大量的定量、定性实验和消融实验结果都证明了LFAN 的有效性,LFAN 模型能够精准地描述对象动作。由于在生成描述中一些视频的描述难以被模型正确地生成,这种情况尤其发生在一些罕见或复杂的场景或物体上,因此后续将基于多模态融合和KL 散度对LFAN 进行分析研究。
