面向DCU 的LDS 访存向量化优化
2024-02-29杨思驰赵荣彩韩林王洪生
杨思驰,赵荣彩,,韩林,,王洪生
(1.郑州大学计算机与人工智能学院,河南 郑州 450000;2.国家超级计算郑州中心,河南 郑州 450000)
0 引言
通用计算单元CPU 加专用计算单元GPU 构建的异构系统架构(HSA)如今已广泛应用于实现高性能计算、机器学习和图形处理等领域来完成各种计算密集 型任务[1]。深度计算器(DCU)是运行 在ROCm 环境下的国产通用加速器,它具有用于逻辑判断、分支跳转和中断处理等功能的控制单元,在芯片上设计了数量众多的算术运算单元[2],这让DCU设备在面向多数据并行计算的问题和具有高算术密集度类型的应用上有着很强的算力[3]。本文的实现面向DCU 所组成的异构平台,该平台主要使用HIP编程实现异构程序[4]。
如今已经出现了很多面向向量化的分析方法,CPU 实现了一些依据数据的依赖关系来寻找可并行的语句,然后将并行语句用向量的方式来并行执行[5]。近年来,GPU 中的访存向量化技术也得到了广泛的研究和探索,其中现有的访存优化技术可以有效实现向量化计算,例如通过共享内存[6]、统一计算设备架构(CUDA)中的向量类型和内置向量函数[7]等技术来提高访存效率。王细凯[8]针对异构内存访存管理机制提出了基于bank 划分的机制。该机制利用了存储器中bank 的并行性和并行通道的特性,实现了高效的内存访问和管理。也有研究者致力于改进现有的访存技术,例如:杨世伟等[9]在对GPU 的优化研究中引入了新的向量类型、优化内存访问模式等方法;YANG 等[10]通过研究GPGPU 编译器的内存优化和并行管理分析内存带宽和延迟的影响,提出了一种数据布局和并行管理的策略,在减少内存访问次数和优化访问模式的同时提高了并行性能;王琦等[11]实现了基于单指令多数据流(SIMD)的自动向量识别及调优方法来改进访存向量化技术。这些技术可以实现高效的访存优化,进一步提高计算性能和能源效率。
随着异构计算平台的广泛应用,如何提升并行程序的运行性能依旧是需要解决的主要问题,而其中访存性能的提升往往会成为系统性能提升的关键[12]。对此,本文从面向DCU 的异构平台中数据的访存性能优化方面入手,研究在本地数据共享(LDS)中数据的访存向量化方法,实现对LDS 的访问向量化。在对程序中的连续内存地址进行向量化实现之后,数据重叠的访存特征与数据读取向量化之间因为有LDS 中特殊的冲突特性存在,可能发生数据读取延迟的问题。基于此,完成向量化算法的关键是在访存向量化实现的同时解决向量化过程中的访存延迟问题。本文通过研究该类访存特征下访存效率低下的问题,提出一种面向DCU 的LCD 访存向量化优化方法,实现向量化所带来的最佳效率提升。
1 共享内存访问向量化基础
1.1 向量化实现可行性
DCU 的存储结构中包含复杂的硬件层次,其中主要包括全局内存、缓存、共享内存、寄存器。DCU中的存储器结构如图1 所示。LDS 是DCU 中的一个关键存储部件,在DCU 中,全局内存的所有加载和存储请求都要经过二级缓存,这是DCU 中,计算单元(CU)之间数据统一的基本点。相较于二级缓存和全局内存,LDS 和L1 一级缓存在物理上位于CU内,可以被同一block(由多个线程组成的线程块)中的所有线程访问,具有更低的访问延迟[13]。

图1 DCU 存储器示意图Fig.1 DCU memory structure
为了得到一个高效的HIP 程序,需要合理地利用DCU 中不同种类的存储空间。不同的存储空间对访问模式有着不同的要求,例如显存访问需要满足合并访问规则才能达到最大带宽,缓存则要求访问的数据有重用性才能得到高效的利用等[14]。在LDS 的访存过程中,如果在访问多个数据时访存指令的访存地址连续,就能够将多个数据的访存通过向量化“vector load/store”的方式实现读取[15]。实际上是将多条地址连续的访存指令进行合并,使用一条向量化指令去实现多个数据的同时存取[16]。
对于数据读取的load 指令而言,当实现向量化数据读取“vector load/store”指令后,还需要从该指令所获取到的数据中提取出单个load 指令的各个元素[17]。在CPU 中,这种向量化对程序性能通常表现不佳,因为在大多数架构上,提取出向量寄存器中的元素会造成很大的程序消耗。此时,对CPU 来说更好的做法是将每个元素单独读取到它自己的标量寄存器中。然而在DCU 的硬件设备中,向量化方法的实现是通过“vector load/store”的向量化指令将数据直接加载到VGPR 中。VGPR 是DCU 中的一种寄存器类型,用于存储多个线程同时运行时所需要的数据。与CPU 中的向量寄存器不同的是,VGPR 由多个标量寄存器组成来存储向量化读取后的多个数据,对于DCU 硬件设备来说,并不需要从VGPR 中提取向量元素。因此,该方法的实现是不会加重程序负担的。
本文中所提到的向量化,可以称之为合并,访存指令可以对DCU 内核产生巨大的性能影响,随着如今程序中对LDS 的使用越来越频繁,这种向量化的机会在HIP 异构编程中也屡见不鲜。图2(a)所示为程序从LDS 中读取float 类型数据的一系列过程:原汇编指令表示出需要从v15 寄存器所存储的数据地址指向的LDS 中读取3 个数据并存入寄存器v24、v25、v26,该汇编指令中的3 条数据读取的偏移量为4 Byte,可知3 条指令所读取的数据连续。因此,该方法即可完成图2(b)所示向量化后的结果:使用1 条指令访存1 次读取连续数据之后存入3 个连续的VGPR 中。显而易见的是,优化实现后,程序减少了连续数据存取中访问LDS 的次数,对异构程序的性能提升具有较大优势[18]。
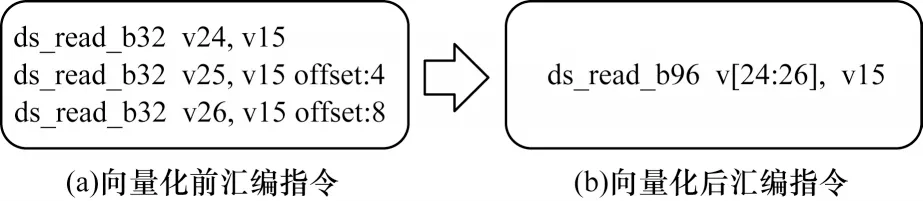
图2 向量化的具体实现Fig.2 Concrete implementation of vectorization
1.2 访存方式及bank 冲突
为了实现异构程序高带宽运行,LDS 被划分为大小相等的内存模块,称为banks,允许同时访问[19]。因此,任何由n个地址组成的内存加载或存储请求都可以同时提供服务,从而产生比单个模块带宽高n倍的总带宽。但是,如果程序wavefront(由多个线程组成的线程束)内多个线程对LDS 请求数据位于同一个bank 中,则会引起bank 冲突,此时对LDS 必须序列化访问。硬件将具有bank 冲突的内存请求拆分为根据需要尽可能多的单独的无冲突请求[20],从而降低吞吐量。如果请求数为n,则初始内存请求称为导 致n路bank 冲 突[21]。由于DCU 在 运行程序时会有大量线程同时运行,对LDS 的访问要求同一个block 中的线程之间没有bank 冲突才能达到最大带宽,因此在完成HIP 程序的编写中,使用LDS 的程序访存应尽量避免bank 冲突[22],如图3 所示,当多个线程在读取4 Byte 的数据时,每个线程都没有对同一个bank 进行访问,这是最好的避免bank 冲突、高效利用LDS 的方法。

图3 无bank 冲突读取4 Byte 数据示意图Fig.3 Schematic diagram of reading 4 Byte data without bank conflict
其他情况如图4 所示,如果多个线程在读取8 Byte 的数据时,线程需要对2 个bank 中的数据进行访问,将前16 个线程放于一个wavefront 中,后16 个线程放入另一个wavefront 中,也不会在LDS 中引发bank 冲突。
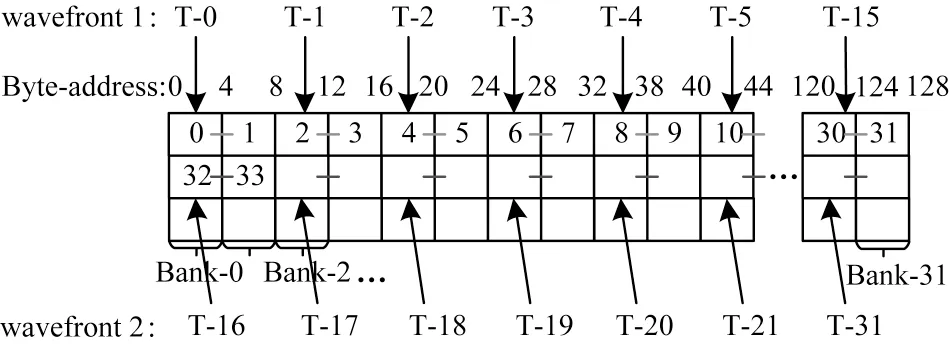
图4 无bank 冲突读取8 Byte 数据示意图Fig.4 Schematic diagram of reading 8 Byte data without bank conflict
在如图3 所示的多个线程同时对LDS 的访问过程中,同时读取数据时并没有发生需要重复读取同一bank 的情况。如果程序线程间需要同时访问相同的bank,如图5 所示,各个线程在对每个数组中的数据读取时,当线程0 去访问数组中的第1 个数据时,它需要访问LDS 中的bank-0,与此同时,线程1 访问了bank-1。在这种情况下,由于线程间同时访问存在一个bank 的差距,在后续读取第2 个数据时同样避免了访问同一个bank,这种方式也不会导致bank冲突,线程间不会发生多个线程请求的内存地址被映射到同一个bank 上的情况,这些请求也不会因此而变成串行执行。
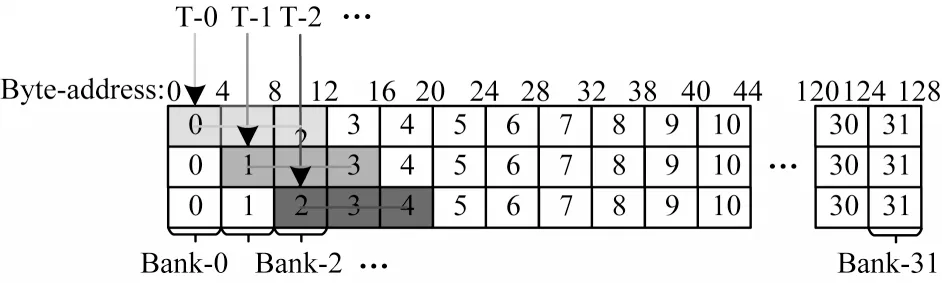
图5 12 Byte 数据重叠访问的情况Fig.5 The situation of 12 Byte data overlay access
图5 所示的这种数据重叠访问的情况在LDS 的使用案例中也比较常见。对该案例中LDS 数据访问的不同访存特征来说,当数组中的数据发生重叠时,也可以避免bank 冲突发生,同样满足了程序对LDS的最大带宽的使用要求,使访存效率更高。本文1.1节中提出,可以通过向量化将LDS 中地址连续的访存指令进行合并来实现进一步优化,并在对数据访存地址进行研究分析时,发现使用向量化技术确实可以将一些连续访问地址的指令进行合并。最后值得注意的是,它所支持的合并方式在HIP 程序中并不能很好地兼顾LDS 所具有的bank 冲突特性所带来的问题,因此不完全具有通用性。
2 共享内存访问向量化及优化方法
对LDS 的访问向量化及其优化方法主要对数组在LDS 访存地址顺序性和线程间的数据访存特征2 个方面进行分析。在异构程序中,当数据的访存地址具有顺序性时,可以通过向量化的方法提升访存效率。与此同时,需要注意线程间的数据重叠的访存特征,避免发生LDS 冲突等待。图6 展示了一段使用LDS 的HIP 程序,利用此代码分析LLVM IR 中对2 种访存特征的检测和优化方法。在该实例中,将从LDS 中连续读取3 组数据,其中每组数据中包含3 个连续的float 类型数据,此过程中编译器会判断3 个float 类型的数据读取地址是否连续,可以完成向量化。

图6 HIP 程序实例Fig.6 Example of HIP program
2.1 向量化方法实现
本文所提出的向量化方法,旨在处理LDS 中的访存指令的合并。LDS 访存方式在对多个连续的float 数据进行访存时,需要使用多条访存指令分别实现数据存取[23]。该方法通过对程序中LDS 访存指令的访存地址进行连续性判断,将多条LDS 访存指令合并,进而提升访存效率。
LDS 访问向量化算法流程如图7 所示,以下以load 指令为例说明算法流程。首先,分别对LLVM IR基本块中地址空间指向LDS 内存空间的所有load 指令进行遍历,同时为了防止load 指令过多而导致的处理延迟过长,该方法将所有的load 指令分组为多个指令块,每个指令块中的指令数最多为64 条;然后,遍历指令块中的所有指令,循环执行并选出地址连续的多个指令保存在指定的集合中,等待完成最终向量化的实现;当指令集合中完成了访存地址连续的几条指令收集后,获取到连续数据的首地址,即可完成一次访存指令的合并从LDS 中读取多个数据存储在连续的VGPR 中,完成指令块中其中一部分的指令向量化,而后该方法将继续遍历后续指令,选择符合向量化标准的指令放入集合,最终实现一个指令块中所有可向量化指令的合并。
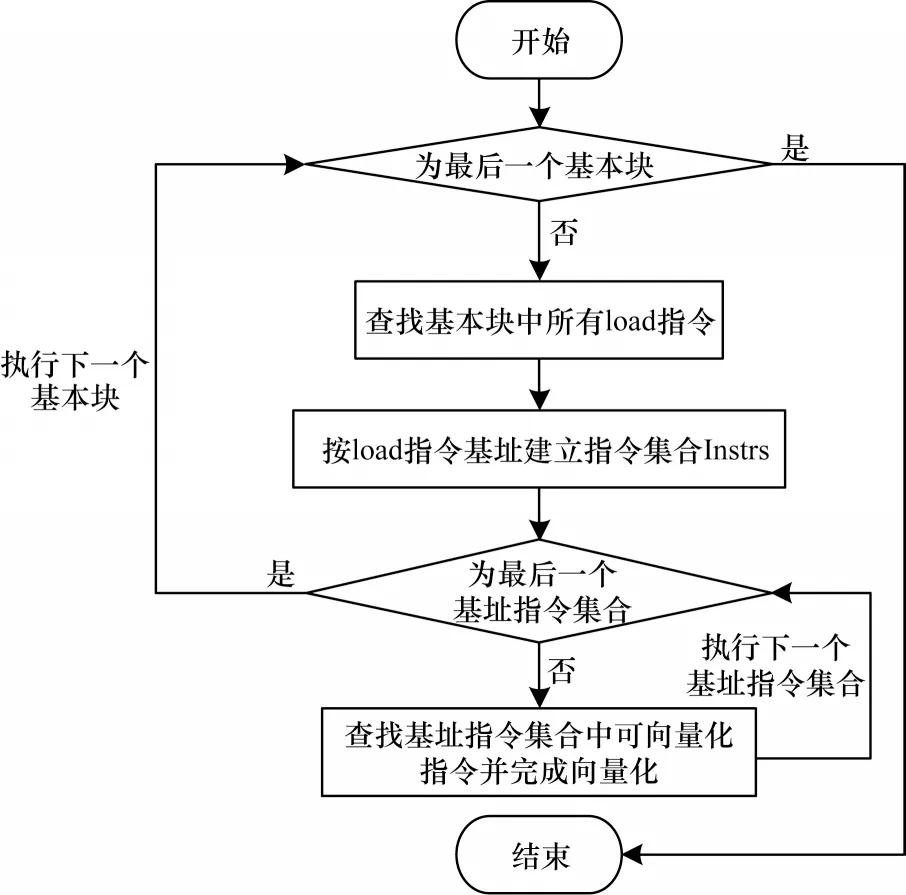
图7 LDS 访存指令向量化算法流程Fig.7 Procedure of LDS memory access instruction vectorization algorithm
算法在实现访存向量化之前,需要对每条LDS 访存指令的访存地址进行分析,判断其是否符合向量化条件并存储于指令集合Instrs 中。针对上文所给出的程序实例,图8展示了在LLVM IR 中,使用算法所遍历到的其中一组最终放入集合Instrs中的load指令,而后检查指令集合Instrs 中哪些指令的访存地址具有连续性,采取索引链表的形式来表示程序中存在的可向量化访存指令序列,并按照链表序列完成向量化。

图8 可向量化指令集合中保存的指令Fig.8 Saved instructions on vectorizable instruction set
对于每一个指令块,如算法1 所示,使用并查集方法建立连续指令链表。算法首先对指令块中的指令进行顺序重排操作,按顺序为可向量化指令建立索引链表,后续对链表中的指令完成最终向量化。具体实现时,算法使用一个csct 索引链表来表示指令序号及所指向的下一条连续指令的序号,并将这2 条连续指令在指令块中的索引分别存入2 个数组:Heads 和Tails,它们分别是存储连续访问的指令序号的头序号和尾序号。这样就实现了使用索引链表的方式存储几条访存地址连续的指令。当遍历到连续地址的最后一条指令时,将该指令对应的csct 数组值定义为-1,表示该向量化指令集合已结束。

将该访存地址连续的指令按照索引链表中所给出的先后顺序放入可向量化指令集合中,并实现向量化指令。之后算法将继续查找下一组指令集合,直至索引链表中指令全部完成向量化。LLVM IR 中向量化后的指令如图9 所示。

图9 可向量化指令集合最终实现结果Fig.9 Final implementation result of vectorizable instruction set
2.2 数据访问重叠问题优化
针对LDS 的访问向量化能够在大部分程序中产生性能提升效果,但是其中有部分程序具有线程间数据访问重叠的访存特征,这类程序在实现向量化之后存在性能大幅下降的异常情况,并且其在使用LDS的程序中也并不罕见。为了实现向量化后程序性能的完全提升,在向量化实现前必须要明确的是程序所具有的访存特征。本文通过实现对LDS 的访存特征的判断,使其最终获得有效的性能提升。
一般来说,LDS 的访存特征都是基于程序中的多条内存访问指令间所涉及的内存位置关系来确定的,但是程序的运行不仅仅要考虑到程序中不同访存指令间的访存位置导致的冲突,对于DCU 内部的多线程并行过程,同一访存指令中也有可能因为数据重叠的访存特征存在冲突。尤其在完成该访存向量化之后,向量化实现了多条数据的合并访问,使得在访问向量化后的多个线程间,由于LDS 中具有bank 冲突的特性而产生数据读取的延迟,因此对向量化方法实现的关键在于如何规避同一访存指令在同时执行的线程间存在的数据重叠而导致的延迟情况。
2.2.1 访存特征检测方法
如图5 所示,如果实现了向量化访问,线程0 可以同时访问位于bank-0~bank-2 的3 个32 位的数据,而并行执行的线程1 也要去完成3 个数据的访问,位于bank-1~bank-3,此时就产生了多个线程间的数据读取重叠。为了避免发生bank 冲突,线程1 需要等待线程0 完成3 个数据读取后,才可以对数据所在的bank 进行访问读取,这种等待造成了程序性能的严重下降。
在DCU 中检测同一访存指令中的访存特征较为复杂,本文提出一种针对线程间存在的访存特征的判断方法。在第2 节所提出的HIP 程序实例中,语句1 读取了3 个连续的float 类型数据,对语句1 中的连续数据读取首地址的指令为%322=getelementptr [0 x float],[0 x float]addrspace(3)*@sh_float,i32 0,i32%add3.i184.epil357,该地址可以表示为First_address=@sh_float+%add3.i184.epil357。指令访存地址的分析结果为((4*%44)+(4*(1+%43)*(2+%8))+@sh_float),+,(16+(8*%8))。通过简化式子可以得出First_address=@sh_float+(%44+(%43+1+2)(2+%8))*4。其 中:@sh_float 是 该HIP 程序实例所申请LDS 空 间的首地址标识符;%43 和%44 代表寄存器中分别存储的threadidx.x 和threadidx.y(二维并行程序线程号)的值,共同完成首地址的计算;指令%add3.i184 地址分析所给出的地址计算树如图10 所示。
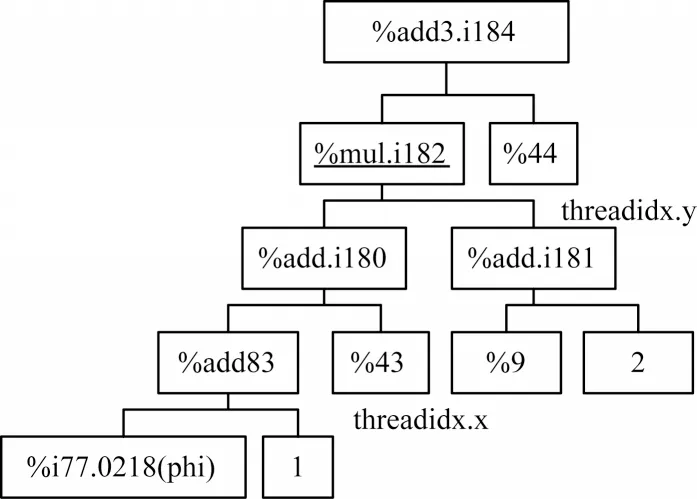
图10 %add3.i184 指令地址计算树Fig.10 %add3.i184 instruction address calculation tree
以二维的线程组织的并行程序为例,LDS 访存地址的基本计算公式为:Address_L0=First_shared+(ax+by)×4(x=0,1,…,y=0,1,…),其中:Address_L0为上文中向量化中指令的首条数据的地址;First_shared 表示程序在访问LDS 时所需地址;x、y分别表示程序的二维线程号。程序在同一条指令的线程间可能存在的冲突主要与可向量化数据读取的首地址在线程间的地址差距长度min{a,b}有关。如果在一个block 中,min{a,b}小于向量化方法所实现的向量化的数据长度,也就意味着在线程间存在数据重叠的访存特征,那么在向量化之后就会发生因为数据合并读取导致另一个线程的数据读取延迟,致使程序LDS 访存向量化优化效率低下。
2.2.2 向量化方法优化实现
为避免程序在向量化过程中线程间数据的访存特征出现重叠而导致LDS 访问延迟的问题,在向量化之前,要通过访存特征检测方法来终止指令向量化的实现。因此,在LDS 访存向量化方法实现之前,必须判断程序中是否具有线程间数据访问重叠的访存特征。得到程序的线程维度以及找到min{a,b}是进行访存向量化的重要判断条件。判断算法流程如图11 所示,首先需要获取向量化指令集的首条指令的访存地址计算GEP 指令,对该GEP 指令中的操作数进行遍历查找,重要的是需要查找操作数指令中所包含的乘法指令,以便于判断出哪些乘法指令中包含程序线程维度参数。然后使用数组WID 分别保存各维度所对应的乘数,选择最小值与向量化指令集长度进行比较,从而判断是否符合向量化条件。如果存在数据重叠的访存情况,程序应立即终止向量化。
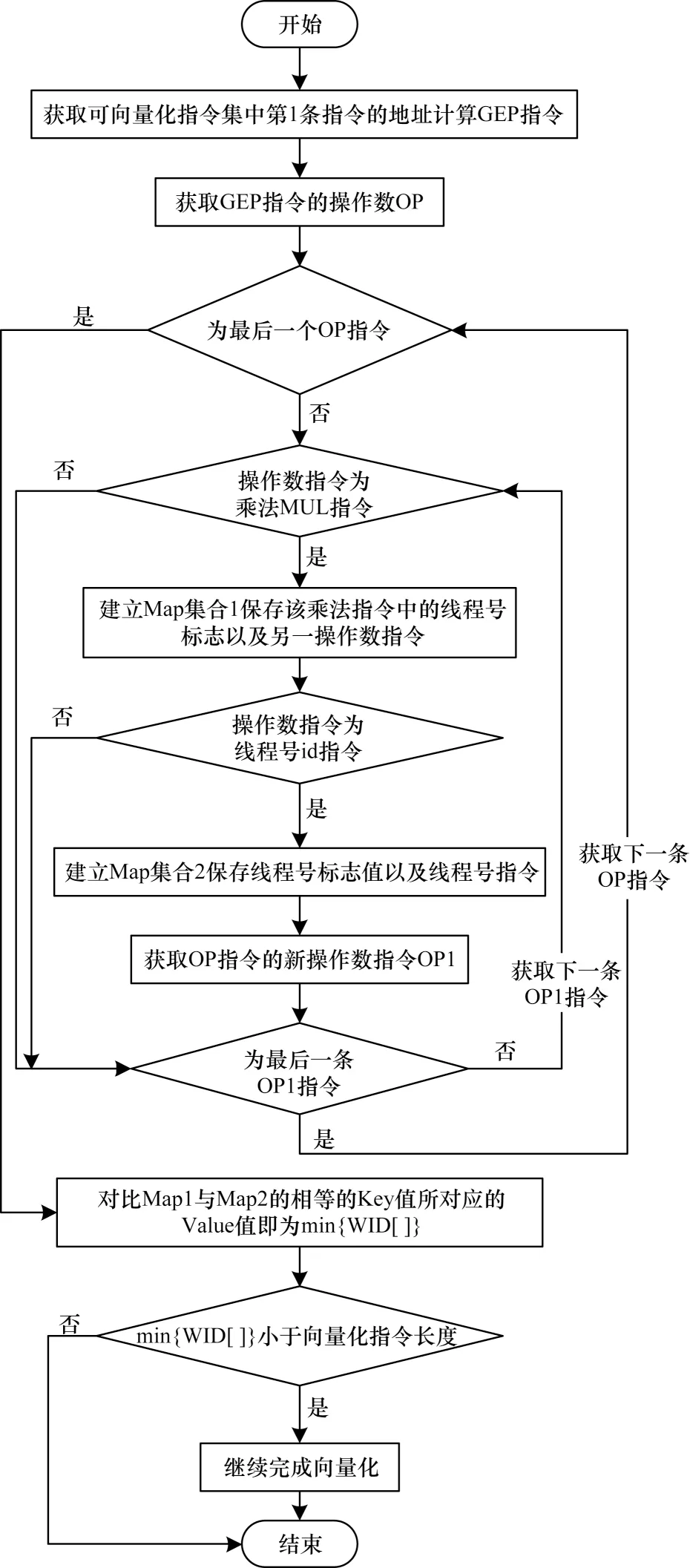
图11 可向量化条件判断算法流程Fig.11 Procedure of vectorizable condition judgment algorithm
3 性能分析
本文进行LDS 访存向量化的功能和性能测试,测试环境基于开源编译器LLVM(版本LLVM 13.0.0)搭建,其中,clang 版本为13.0.0,rocm 版本为4.5.2[24]。硬件采 用CPU+DCU 的异构平台,其 中,CPU 型号为Hygon C86 7185 32-core Processor,加速器为海光一号DCU。
3.1 向量化方法测试分析
选取GEMM 矩阵乘作为测试用例,在高性能计算领域,对矩阵乘的优化是一个非常重要的课题。GEMM 广泛应用于航空航天、流体力学等科学计算领域,这也是高性能计算(HPC)实现的主要应用场景。根据测试需要对划块实现的GEMM 用例作使用LDS 的调整[25],同时选取SHOC 测试集中符合条件的测试用例——快速傅里叶变换(FFT),它在信号分析和处理领域有着广泛的应用,是实现众多复杂功能的基础算法。
利用上述测试用例对本文提出的LDS 访存向量化方法进行测试,得到的功能验证结果如表1所示。

表1 功能验证结果 Table 1 Functional verification results
功能验证结果显示,优化前后性能(GFlops)得到了平均1.203 的加速比,该结果表明本文方法能够完成上文提到的LDS 连续访问向量化,且与未经过向量化处理得到的代码相比,经过本文方法处理的代码总体性能平均提升了22.6%,达到了预期的目标。GEMM 程序在向量化前后实现的IR 代码对比如图12 所示。

图12 向量化前后IR 指令对比Fig.12 Comparison of IR instructions before and after vectorization
3.2 数据访问重叠问题测试分析
对程序中具有数据重叠访存特征的向量化方法的优化,选取具备该访存特征的测试用例Stencil2D算法完成测试。
Stencil2D 算法是一种基于二维矩阵的迭代计算方法,常用于模拟物理现象或图像处理等应用场景。在Stencil2D 中,每个元素的值都由其周围的相邻元素计算得出,这种计算方式类似于模板,因此被称为Stencil。Stencil 通常需要对大型矩阵进行高效并行计算,以提高运算效率和速度,是一种常用的并行计算方法,可以应用于各种领域的计算任务,其并行实现也涉及到多种技术和工具,需要根据具体情况进行选择和优化。
在该测试用例的并行实现中,需要使用到共享内存来加速计算。Stencil2D 算法将矩阵数据分配给多个线程,并将相邻线程所处理的数据区域进行重叠,以便在计算时共享一些数据,减少内存访问和数据传输的开销,具有LDS 中的存取连续数据的特征且数据具有线程间重叠读取的特征[26]。
在对该测试用例实现了向量化优化方法之后,再次对程序进行性能测试,以比较优化前后的性能差异。ALUStalledByLDS 是rocprof 中的一项性能指标,代表ALU 因等待LDS 数据而被阻塞的时间比例。当异构程序在执行Kernel 时,如果ALU 需要访问LDS 中的数据,而该数据还未被载入LDS,则ALU 会被阻塞,等待LDS 中的数据准备好。此时,ALUStalledByLDS 指标会统计ALU 被阻塞的时间占总时间的比例,反映LDS 访问延迟对异构程序性能的影响。对Stencil2D 算法进行性能测试,ALUStalledByLDS 指标如表2 所示。

表2 向量化优化前后ALUStalledByLDS 指标对比 Table 2 Comparison of ALUStalledByLDS metrics before and after vectorization optimization
当ALUStalledByLDS 指标较高时,说明异构程序在执行Kernel 时,ALU 被LDS 访问延迟所阻塞的时间较长。测试用例ALUStalledByLDS 指标向量化后明显升高的情况表明,向量化方法的实现使存在数据访存重叠的特征的程序在数据连续读取的过程中产生延迟,从而向量化优化方法实现之后的程序访存效率降低。通过对Stencil2D 算法的分析和测试表明,使用本文提出的优化方法能够检测到数据重叠的访存特征,并根据访存特征选取向量化实现方案,避免具有数据重叠访存特征的程序实现LDS访存向量化,使向量化方法尽可能发挥优势。对于数据访问重叠问题的优化测试结果如表3 所示,可见经过优化后的程序性能提升了33%。

表3 向量化优化前后Stencil2D 测试用例性能对比 Table 3 Comparison of Stencil2D test case performance before and after vectorization optimization
表3 结果显示,对于共享内存LDS 向量化的判断方法能够实现程序性能的较大提升。此外,该优化能够充分将DCU 的计算能力更好地发挥出来,减少了DCU 计算部件等待LDS 访问的时间。总体来说,通过使用合适的向量化优化方法可以很好地提高程序性能,对于共享内存LDS 中数据的向量化访问能够达到充分发挥DCU 的计算能力的目的。
4 结束语
本文主要研究面向DCU 的共享内存访存优化方法,实现针对LDS 的连续访问向量化,解决在向量化过程中由于LDS 冲突特性导致的具有数据访问重叠的向量化数据访问延迟问题。实验结果表明,本文提出的向量化优化方法能够有效提高程序对LDS的访问效率,形成一种面向国产通用加速器的高效访存技术。在共享内存LDS 中的连续访存向量化实现中,LLVM 后端实现指令选择存在2 种不同形式,为进一步优化DCU 的访存性能,后续工作将通过指令选择确定最优指令形式来实现减少访存次数的优化方案,进一步提高程序的执行效率。
