适用于S-NUCA 异构处理器的任务调度与热管理系统
2024-02-29周义涛李阳韩超赵玉来汪玲李建华
周义涛,李阳,韩超,赵玉来,汪玲,李建华,3*
(1.合肥工业大学计算机与信息学院,安徽 合肥 230601;2.安徽交通职业技术学院,安徽 合肥 230601;3.合肥工业大学情感计算与先进智能机器安徽省重点实验室,安徽 合肥 230601)
0 引言
异构多核处理器集成了不同计算能力和微架构的核心,相比于普通同构多核处理器,具有高性能、低功耗、可定制化等优点[1]。例如联发科的天玑9000 处理器,在CPU 架构上使用了“1+3+4”的三丛集架构,其中便包含了ARM 公司的Cortex-X2、Cortex-A710 与Cortex-A510 这3 种公版架构。
异构多核处理器的最后一级缓存(LLC)架构可采用均匀缓存架构(UCA)或非均匀缓存架构(NUCA)[2]。与UCA 不同,在NUCA 下,基于瓦片(Tile)结构的LLC 用片上网络连接起来,这实现了不同核心之间的缓存访问,拥有更低的缓存访问延迟。因此,某个核心访问某一片Tile 上的缓存延时与目标Tile 的位置有关。
随着异构多核处理器处理核数量和规模的增加,线程映射问题与处理器热安全问题逐渐凸显。线程任务调度问题是指在多线程系统中如何分配和调度多个任务,使得系统的性能最优化。线程任务调度是一个NP-hard 问题[3]。现有的线程映射方法大多使用静态或动态启发式算法[4-6],在进行任务调度时,不仅需要考虑对象任务的规模(任务的时间复杂度、空间复杂度),也要考虑现有资源的分配情况(片上空闲处理核的数量、任务与处理核的映射关系)。热安全问题则是由于处理器性能在不断增长时[7]高负载、高频率和高电压给芯片带来的更高的功耗和散热压力。以上问题对一系列同样采用异构多核架构的移动设备的散热设计和电池容量提出了更高的要求。因此,需要对异构多核系统进行温度约束,保证热安全以提高系统稳定性。
机器学习算法可以通过学习大量历史数据来拟合数据之间的关系,人工神经网络(ANN)在计算机任务调度、资源分配等任务中逐渐发挥出巨大优势[8]。目前,ANN 在异构多核系统中的应用呈上升趋势,对比深度学习网络(DLN)以及Deep Q-Network(DQN)等算法,ANN 具有轻量化、模型结构简单、计算开销低等优势,更适合应用于实时操作系统以及线程调度等场景。目前,在异构多核系统上应用机器学习技术进行任务调度也有了相应研究,如文献[9]所提出的动态调度方法,使用机器学习来将应用程序调度到各自最佳的核心,以减少具有可配置缓存系统的能耗。该文献还提出一种动态调度方法,使用机器学习来预测最佳核心,并使用调优启发式算法来确定非最佳核心上的最佳配置。如果最佳核心忙碌,调度器会考虑其他空闲核心,或者根据哪个决策更节能来暂停应用程序。
本文提出一种面向S-NUCA 异构多核处理器且基于ANN 的任务调度和动态热管理解决方案,简称为TSCDM。通过ANN 进行性能预测,利用动态调整线程与核心的绑定关系来最大化系统性能,同时动态调整每个核心的功率预算,减少热余量并防止暗硅效应产生[10]。本文的主要工作如下:
1)设计一种基于ANN 的性能预测器,通过预测每个线程在任意大核或小核上的每周期指令(IPC)值,在以IPC 值最大化为目标的前提下决策出任意线程与大核或小核的绑定关系。
2)提出一种线程动态映射算法,均衡活跃核心的可分配功率预算与缓存访问延迟。根据S-NUCA架构的缓存访问特性,算法优先将线程映射至靠近片上中心位置的核心,同时根据线程的算力与访存需求动态地执行任务迁移策略。
3)提出一种满足热安全功率(TSP)的核心功率动态调整机制。根据基于瞬态温度的安全功率(T-TSP)算法[11],由线程与核心的映射关系和当前核心的初始温度计算出每个核心的瞬时热安全功率值,保证系统的热安全同时尽可能地提高系统性能,减少热余量。
1 相关工作
本文为基于S-NUCA 架构的异构多核处理器设计线程调度算法,并应用热管理框架为核心设定热安全功率,通过应用DVFS(Dynamic Voltage and Frequency Scaling)设定保证芯片符合热安全约束。
1.1 异构多核系统的调度问题
图1 所示为一个操作系统内线程调度问题示意图,在计算机操作系统内,调度器负责对准备就绪且待映射的线程与所需映射的目的CPUID 进行绑定。一个高性能的S-NUCA 异构多核系统集成了一定数量、不同处理性能的核心。由于不同的处理器核心具有不同的性能特点,因此如何合理地调度任务是一个关键问题。如果调度不当,就会导致性能下降,甚至会使得系统崩溃。
本文从线程调度的映射方法类型和决策特征两方面对相关工作进行总结,如表1 所示。

表1 现有映射方法总结 Table 1 Summary of existing mapping methods
离线静态调度是一种在编译时进行调度的方法,通过对程序进行静态分析来确定每个线程映射的最优映射核心,从而实现效率最大化。文献[12]提出一种基于种群算法的静态调度方法,能够在探索性和开发性搜索模式之间进行动态切换,实现任务调度和DVFS 决策。文献[13]使用遗传算法(GA)提出一种群体智能任务调度策略,以提高异构多核处理器的性能,通过预先处理指定任务来检测不同核心的计算能力,并引入自适应变异策略和注入策略来避免过早收敛和陷入局部最优解。
基于启发式算法的在线动态调度是一种在程序运行时进行线程调度的方法,可以根据实时状态来调整线程映射。文献[14]提出一种动态线程映射的启发式算法,该算法能够根据线程的运行时行为,将其分配给最合适的核心类型。仿真结果显示,该算法在256 核系统上的运行开销不超过1 ms。文献[15]提出一种改进的任务图调度算法,该算法采用贪心策略,通过复制任务的前驱节点来减少调度时间和处理器空闲时间,同时提高了分布式计算的性能,且不会增加调度时间。文献[16]设计一种并行感知调度算法,该算法计算各任务与终点之间的最长路径值,按照该值的降序来分配任务调度的次序。采用该算法可以显著降低任务调度的时延、减少通信量并提高处理器利用率。
离线和在线混合调度方式是一种融合离线和在线调度方式优点的线程调度方法,该方法通过利用离线分析数据来辅助动态启发式算法进行线程调度的决策。文献[17]提出一种名为HTM 的混合式调度方法,基于MPSoC 的嵌入式系统,通过捕捉应用的动态性来提高其性能。文献[18]提出一种改进的混合粒子群和模拟退火优化算法iHPSA,该算法结合了改进的粒子群优化、NoC 映射的模拟退火算法和K-means 聚类算法,根据通信带宽执行线程调度。
近年来,也有将机器学习引入任务调度的方法出现,通过收集大量线程运行的历史数据训练AI 模型,以辅助系统进行任务调度决策。这种方法的优点在于可以根据历史数据和当前情况自动地决策出最优调度方案,相比传统的调度算法,这种方法更加灵活和高效。文献[19]通过引入与应用程序相关的性能和功率V/F 敏感度以及与核心相关的温度敏感度来训练神经网络模型,可以准确估计待映射线程的性能和功率V/F 敏感度。
1.2 处理器热量管理问题
为处理器设置热安全功率是一种动态热管理(DTM)策略,DTM 是指在处理器运行时调整其工作频率和电压,以控制处理器的温度不超过人为设定的阈值,从而避免产生暗硅效应之类的热安全问题。热安全问题是指处理器运行时的温度过高,可能会使处理器出现停止工作、运行缓慢或故障等问题。因此,确保处理器处于安全的温度范围内是异构多核系统稳定运行的必要条件。热安全功率是指处理器在安全的温度范围内可以运行的最大功率[6],如果处理器的功率超过了热安全功率,就有可能因过热而产生暗硅效应。因此,需要通过实时调整处理器的工作频率和电压、优化线程与核心的绑定关系等方式,在不影响系统稳定性的前提下降低功率。监控处理器的温度是实现处理器动态热管理的关键,通常通过在处理器上安装温度传感器来实现。温度传感器可以定期测量处理器的温度,并将信息发送给DTM 相应的控制模块,根据处理器的温度和热安全功率来决定是否需要调整处理器的工作频率和电压。
一般而言,处理器的工作频率和电压是相互影响的。在通常情况下,降低工作频率和电压会减少处理器的功率消耗,从而降低处理器的温度。然而,降低工作频率或电压会对处理器的性能产生影响。因此,在调整工作频率和电压时,需要考虑性能和处理器温度之间的平衡。此外,在实际应用中,处理器的热安全功率也会受到许多因素的影响,包括处理器的类型、封装、工作频率、电压、环境温度、风扇速度等。因此,为了更好地控制处理器的温度,需要对处理器的功率进行实时监测和调整。
随着处理器片上功率密度的增加,限制处理器的功耗以避免暗硅效应的方案增多。文献[20]提出一种用于异构平台的能量温度感知实时调度器,该调度器基于一个能量和温度模型,根据任务的截止时间和功耗,动态地选择合适的核心类型和频率,以最大化系统能效。该调度器还考虑了核心之间的温度依赖性,以避免过热问题。文献[21]研究使用U型并联微通道冷却系统对多核处理器进行热管理的方法,通过数值模拟和实验测试来分析流量、流速和热流密度对微通道内压降、温度分布和热阻的影响。文献[22]提出一种应用于异构多核平台的半分区调度算法HEAT,通过该算法有效地管理能量和温度。HEAT 算法分为4 个阶段,分别为截止时间划分、任务到核分配、温度感知调度、能量感知调度。HEAT算法能够在满足实时任务截止时间约束的同时最小化系统的能量消耗和温度峰值。文献[23]提出一种用于异构多核处理器的新型自适应DTM 框架,该框架为大核和小核制定基于温度的迁移策略,在保证温度不超标的同时能够防止系统性能下降。
本文通过分析S-NUCA 缓存特性,利用离线和在线混合调度的方式设计动态映射策略,并构建片上热模型,结合片上初始温度,为每个核心实时分配精确的热安全功率,在符合热安全约束的前提下尽可能地提升系统性能和能耗比。
2 热安全约束下的动态映射方法
本文研究对象为基于S-NUCA 并具备大小核设置的异构多核系统。图2 所示为本文所提TSCDM方案的主要架构,其由基于ANN 的性能预测器、映射器、T-TSP 热安全框架和阶段检测器构成。
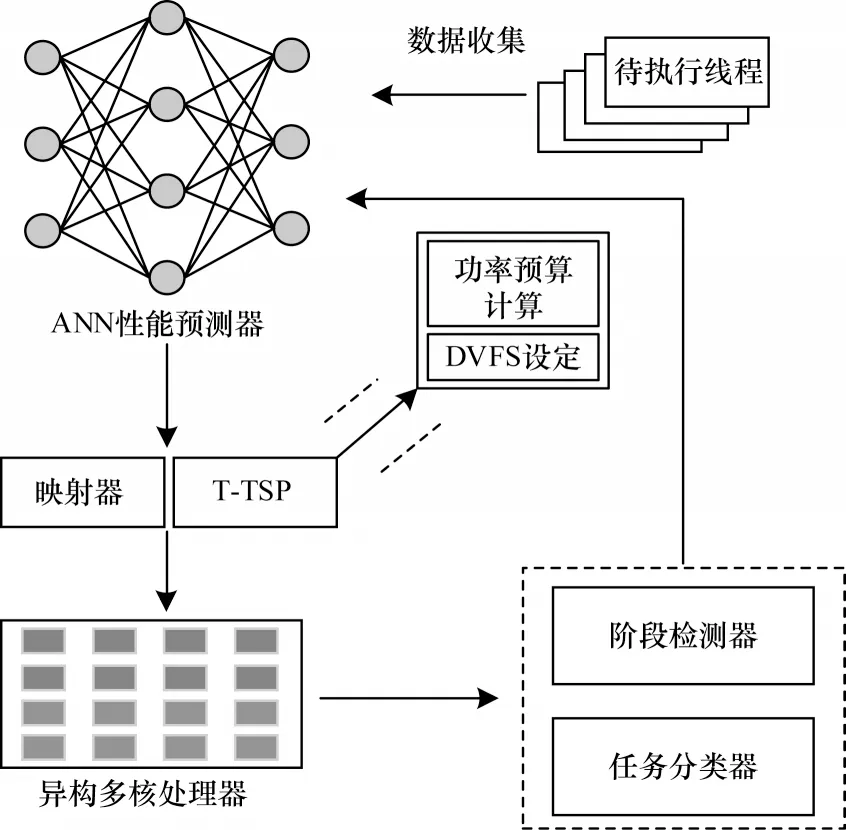
图2 TSCDM 整体框架Fig.2 Overall framework of TSCDM
2.1 阶段检测器
TSCDM 中设计一个阶段检测器以确定线程重映射的起始点。一个线程在其生命周期内可能经过很多个阶段,在不同的阶段所呈现的线程特征也不同,因此,某个核心在运行某个线程时,IPC 值也会随着阶段的改变而呈现明显的变化,如图3 所示。

图3 线程阶段变化示意图Fig.3 Schematic diagram of thread stage changes
由于IPC 值直观地反映了系统的性能表现,因此需要对线程所处的不同生命周期阶段进行检测,若某个线程的IPC 值出现大幅度改变,则可以认定该线程的生命周期阶段发生了变化。在这种情况下,本文系统会触发一次重映射,即第2.2.4 节中的线程-核心类型匹配以及第2.3.2 节中的线程与具体核心映射。
TSCDM计算任意核心在t时刻的IPC值和(t-Δt,t)时间内的平均IPC 值,若当前t时刻的IPC 值与平均IPC 值出现较大幅度的变化,即可认定该线程的阶段发生了改变。参考文献[24]对不同变化阈值下检测效果进行的研究和总结,本文所使用的幅度定义为50%,时间片Δt设定为2 ms。若满足|IPC(t) -IPCsum(t-Δt,t)| >IPCsum(t-Δt,t) ×0.5,则说明t时刻的线程阶段发生了改变,从而触发重映射。
2.2 基于ANN 的性能预测器
本文将线程调度问题定义为:将n个线程(表示为Thread=thread1,thread2,…,threadn)映 射到H×K(核心呈2D 网格排布,共H行、K列,其中1/2 为大核心,1/2 为小核心)的多核平台上执行,并使整个平台的计算性能最大化。其中,每个核心均有可调且独立的DVFS 策略。
在传统方法中[3],无法判断即将在处理核上处理的线程特征,因此,本文使用ANN 来预测某一个线程在大核和小核上的性能,在绑定阶段使所有核心的总预测IPC 值最大化,从而获得最优的线程与核心类型绑定方案。
2.2.1 ANN 参数选择
在TSCDM 中,ANN 会收集与性能相关的数据[25]以供训练。基于对处理平台的所有可选监测参数和具体参数的分析,本文选择与IPC 相关的参数,包括一级缓存命中率、二级缓存命中率、三级缓存命中率以及6 种与程序行为变化相关的参数,即浮点加法、减法、乘法、除法、跳转指令和读写内存指令[26-27]。这些参数与处理器性能直接相关,可以提供更准确的预测精度。
2.2.2 数据集构建与预处理
本文使 用HotSniper 模拟器[28],通过运 行HotSniper 中自带的SPLASH-2 基准测试程序并实时采集上文提及的参数,将它们保存为原始数据集。为了量化所有获取到的数据,同时平衡各种数据在单位和数量级上的关系,本文对获取到的数据集进行如下预处理:
1)将所有缓存命中率进行Z-Score 归一化处理[29]。
2)将CPU 指令相关参数转为该指令占所有指令的比值。
2.2.3 ANN 模型构建
针对ANN 网络模型参数,本文选择第2.2.1 节中的10 个与核心性能有关的参数,因此,神经网络的输入节点个数为10,每个隐藏层节点个数为25,隐藏层个数为2,输出节点个数为1(输出IPC 值),并使用ReLU 函数作为ANN 的激活函数,利用均方误差(MSE)损失函数对ANN 性能预测器进行训练。
2.2.4 线程与核心类型匹配
通过由ANN 得到的线程性能预测数据,可以得到线程与核心类型的最佳绑定方案。假设某一时刻待映射的线程数为N,通过ANN 即可得到所有线程在大核心和小核心上的性能表现集合,即:
由此可以得到2N个IPC 值,将这些数据进行排序,取IPC 值最大的N个结果,取每个元素的下标bigi或smallj,即可得到映射:线程X(序号为i或j的线程)→核心类型(big 或small)。
2.3 线程与核心映射方案以及任务迁移策略
在确定了线程与核心类型的绑定关系后,TSCDM 使用一种动态调度算法,综合考虑S-NUCA架构下活跃核心的平均曼哈顿距离(AMD)对缓存访问性能和功率预算的影响,得到线程对应的最佳映射位置。同时使用任务分类器自动感知计算密集型任务,使用任务迁移策略将其映射至AMD 值较大的核心。
2.3.1 核心AMD 的影响
在S-NUCA 架构中,线程所映射的核心空间位置会影响对应的核心缓存访问性能。图4 是一个S-NUCA 模型架构,每个核心都独享最后一级缓存(LLC)。某个线程访问所有内核上的LLC 的可能性相同,且与线程绑定的核心位置无关。LLC 的访问延迟与线程核心所处的位置和LLC bank 之间的跳数有关,可以使用曼哈顿距离进行衡量:d(a,b)=sum(ai-bi)。与所有核心相比,AMD 值较低的核心拥有更低的LLC 访问延迟[15]。可以发现,越靠近中心位置的核心拥有越低的AMD 值。

图4 S-NUCA 架构Fig.4 S-NUCA architecture
鉴于以上特性,使用S-NUCA 架构的片上系统的线程与核心绑定分布之间会影响系统缓存访问性能与分配的功率预算值。如图5 所示,在同一个系统测试程序时,使用相同的DVFS 策略和不同的映射方式(不同的AMD 值),2 种方案呈现出了不同的平均IPC 值和分配的功率预算值。

图5 AMD 对系统性能与TSP 的影响Fig.5 The impact of AMD on system performance and TSP
对测试结果进行分析可以发现,不同的测试子项(SPLASH-2 内的测试子项)有不同的特点[30],可分为计算密集型任务与访存密集型任务。例如fft 对于AMD 的敏感程度大于fmm 子项,因此,对于fmm来说,它是一个访存密集型任务,而对于fft 来说,它是一个计算密集型任务。在S-NUCA 多核系统中,当待映射的线程数一定时,较低的AMD 值会提高处理核心的IPC 值(核心之间缓存访问性能提升),然而,较低的AMD 值会由于核心与核心之间的热感受性以及片上系统的热传递模型特性而导致核心可分配的功率预算值降低。
2.3.2 基于缓存特性的线程与核心动态映射策略
由于S-NUCA 架构下活跃核心的AMD 值会影响缓存访问性能与活跃核心的功率预算,因此在进行线程映射时必须考虑核心在平面上的几何位置。如算法1 所示,在进行线程与核心的绑定时,TSCDM使用一种基于缓存特性的线程与核心动态映射策略,尽可能保证所有线程优先绑定至AMD 值较小的核心,同时避免活跃核心出现相邻的情况。

2.3.3 基于任务分类的任务迁移策略
TSCDM 应用一种自动感知的任务迁移策略。在第2.3.2 节中,TSCDM 将待映射线程映射至AMD值较小的空闲核心上,但如第2.3.1 节中所述,某些线程呈现出不同的特征,即分为访存密集型与计算密集型任务。初始的动态映射策略保证了所有的线程都拥有相对较低的缓存访问延迟,对于计算密集型任务,TSCDM 单独识别并将其迁移至AMD 值较大的核心上,从而分配更高的热安全功率以提升性能,降低系统的热余量。
TSCDM 使用Roofline 算法为计算平台的计算性能进行建模[31]。通过获取计算平台的算力上限π和带宽上限β,从而得出计算平台在单位内存交换下可以进行的最多浮点计算次数以 及模型的理论性能,表示计算平台每秒能进行的浮点计算次数。当P=β·I(I<Imax)时,可以认为此时系统处于内存瓶颈。TSCDM 使用一个实时检测任务分类的任务分类器,通过识别程序的Imax和核心的性能P,与机器的单核峰值性能进行对比,若识别到某个线程属于计算密集型,则将其尽可能地迁移至靠近片上4 个角落的空闲核心。整个任务迁移策略流程如图6 所示。
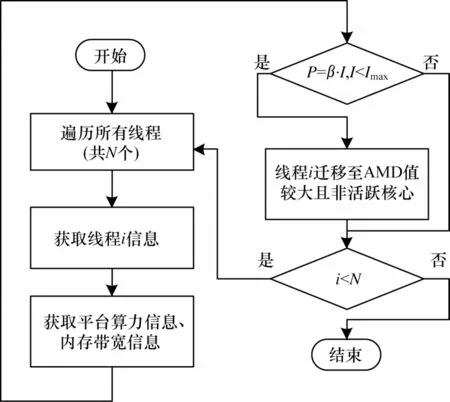
图6 基于任务分类的任务迁移策略流程Fig.6 Procedure of task migration policy based on task classification
2.4 热安全功率和DVFS 设定
TSCDM 的目标是为异构多核系统中的每一个核心寻找更加精确、动态细粒度的功率预算分配方法,以减少热余量。处理器核心的性能与其工作频率有关,所有的处理器核心都有其内置的工作频率和电压范围,高频率和高电压会给芯片的散热带来很大压力。传统的功率预算方法直接为整个处理芯片设定整体热设计功率(TDP),但是在异构多核处理器下,核心数量众多,不同的核心有着不同的处理能力,不同核心在不同时刻的工作状态差异过大,直接使用TDP 限制功率可能导致过多的热余量,使得芯片无法发挥全部性能。在一般的DTM 方案中,人为设定了一个温度阈值TDTM,即在片上系统中所有核心的最高温度不应超过TDTM,以避免暗硅效应的出现。当核心温度接近人为设定的警戒温度阈值时,系统通过降低核心电压与频率,以降低核心温度。因此,在热安全功率系统下,多核系统的性能会受到影响,且分配的功率预算越低,系统的性能降低也会越多。
TSCDM 使用文献[11]中的T-TSP 功率预算分配算法,可以基于每个核心的初始温度和处理核之间的热量传递模型在每个时刻为所有核心计算精确的功率预算。文献[32]提出处理器的RC 热网络模型架构,如式(3)所示:
其中:矩阵A表示核心的热电容;矩阵B为热传导参数;向量T为每个节点的温度值;向量T′表示每个节点上的温度对时间的一阶导数;向量P为各节点的功耗;Tamb为环境温度;列向量G为各节点与环境之间的热导。该公式描述了片上的RC 热网络模型,由该模型可以得出所有核心的稳态温度Tsteady。TSCDM 按照预设的温度阈值TDTM为每个核心寻找最佳的DVFS 设定。核心的功率与核心的有效开关电容、电压、频率有关,可以用式(4)进行表示[33],在得到所有核心的功率预算分配后,利用式(4)在V-F表中获取最佳的V-F 设置,以满足热安全功率的约束。
其中:Ceff表示有效开关电容;Vi、fi分别代表电压和频率。
3 实验和结果分析
本文利用HotSniper 模拟器搭建一个基于S-NUCA 架构的异构多核实验平台,运行SPLASH-2测试套件,将本文方案与Linux 自带的CFS 方案、模拟器自带的first_unused 方案、文献[34]提出的轮询调度(RRS)方案、文献[26]提出的基于机器学习的调度器(MLS)进行性能和功耗对比。RRS 是一种在每个调度周期轮流将线程分配给大核与小核的调度方式,而MLS 是一种基于机器学习预测模型的调度方案。
3.1 实验方法
本文使用HotSniper 模拟器搭建一个8×16 的异构多核平台,运行SPLASH-2 基准测试程序,以测试在不同策略下系统的性能,具体的平台参数如表2所示。
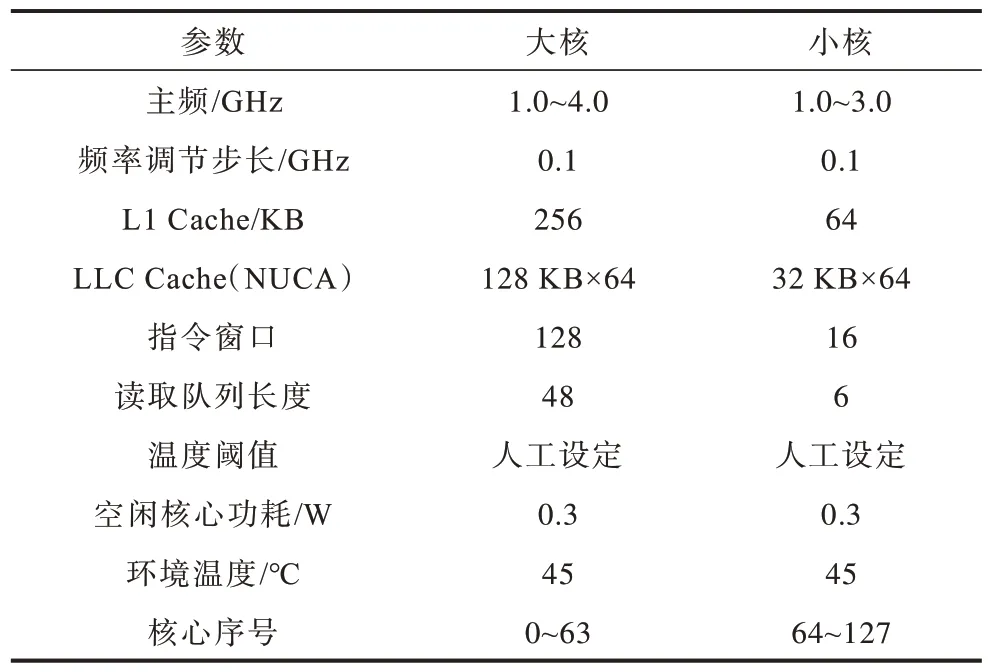
表2 实验平台参数 Table 2 Experimental platform parameters
SPLASH-2 中包含了各种不同性能侧重的测试子项,因此SPLASH-2 的不同子项也对算力和I/O 带宽有着不同的需求。根据文献[35],不同测试子项按照计算密集型与访存密集型的划分结果如表3所示。
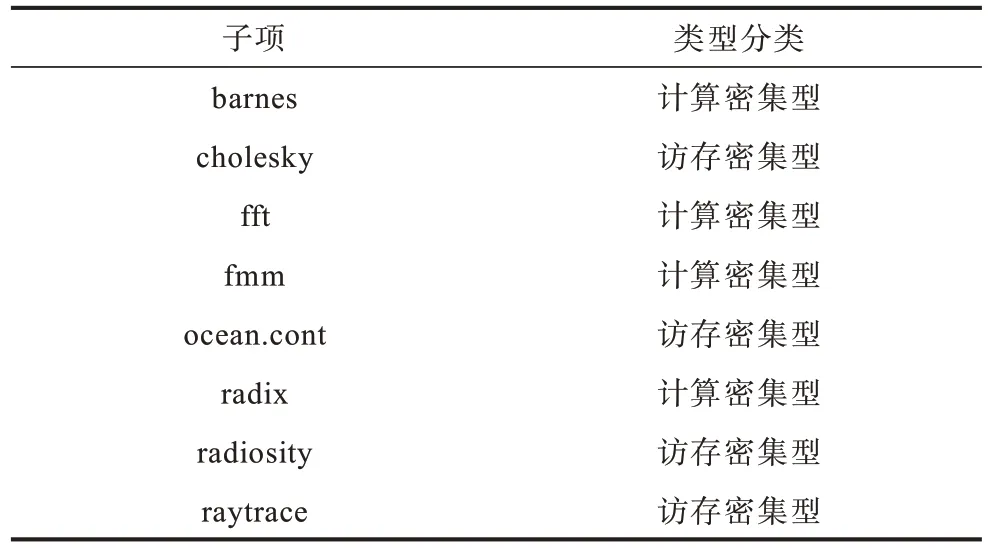
表3 不同测试子项的特征 Table 3 Characteristics of different test sub items
TSCDM 会区分计算密集型与访存密集型任务,因此,为了方便测试和评估性能以及尽可能提升本实验对于真实使用环境的模拟程度,将不同的子项进行组合测试,尽可能让不同的组合呈现不同的特征,具体的测试子项组合如表4 所示。

表4 实验程序组合 Table 4 Experimental program combination
3.2 结果分析
3.2.1 ANN 预测性能评估
由于本文所研究的对象为基于S-NUCA 架构的异构多核系统,而大核与小核的性能无法横向对比,ANN 需要预测某个线程分别在大核与小核上的性能,因此需要分开评估ANN 对于大核和小核的IPC预测准确度。
本次实验利用第2.2.2 节中获得的数据集,随机选取80%作为训练集,20%作为测试集,测试ANN对于大核和小核的IPC 性能预测值与真实值的均方误差,均方误差越低,说明ANN 对于数据的拟合程度越好,对于IPC 的预测值也越准确。实验结果如图7 所示,横坐标表示进行均方误差测试时输入ANN 的数据所属子项,纵坐标表示在某个测试子项下ANN 预测的IPC 值与真实值之间的均方误差。由图7 可以得到,ANN 性能预测器在radix 上的预测性能最好,在小核与大核上的误差分别为0.12 与0.17,在volrend 上的效果最差,误差分别为0.72 与0.79。这是由于在运行volrend 时,线程的阶段切换过于频繁,使得预测值无法对应下一阶段的线程运行状态,且在所有的应用中,ANN 性能预测器对于小核的IPC 预测值优于大核。同时,对于所有的测试子项,在小核与大核上的平均误差分别为0.28 和0.32,表明本文的ANN 性能预测器可以较精确地预测线程IPC 值。
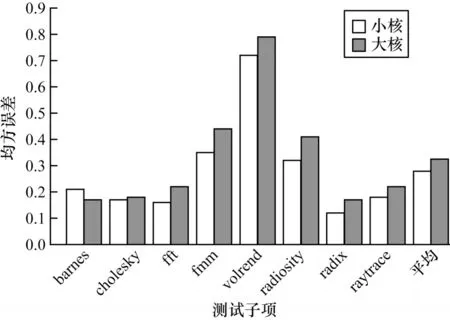
图7 ANN 性能预测器均方误差Fig.7 MSE of ANN performance predictor
3.2.2 热安全约束下动态映射算法的性能评估
为了评估TSCDM 的性能,实验对比CFS、first_unused、RRS 以及MLS 在运行不同测试子项组合下的性能表现,同时也对比了去除任务迁移算法对于模型性能的影响以及核心资源利用率。通过记录运行不同程序组合所耗费的时间计算出加速比。实验使用表2 中的参数配置,max_parallelism 参数均设置为8,并且使用相同的DVFS 策略。
图8 给出了TSCDM 分别对比first_unused、Linux 的CFS、RRS、MLS 运 行SPLASH-2 的加速 比情况,其中横坐标表示运行不同的SPLASH-2 程序组合(见表4),纵坐标代表TSCDM 相对上述4 种方案以及去除TSCDM 中的任务迁移策略的加速比。由图8 数据可知,在所有的程序组合下,TSCDM 的性能均优于其他调度方案。其中,TSCDM 在对比RRS 调度方案时获得了最高的加速比,为1.31,这是因为RRS 轮询算法并未考虑程序运行过程中的阶段性变化,也未考虑S-NUCA 架构的缓存特性。MLS 也是一种基于机器学习进行性能预测的调度方案,在调度阶段使用一种遗传算法(GA)进行映射方案搜索,因此也未考虑S-NUCA 架构特征,TSCDM 对比MLS 获得了平均1.14 的加速比。对比去除任务迁移策略后的方案,TSCDM 获得了平均1.05 的加速比,其中在程序组合2 中加速比最大,为1.08,但在程序组合7 下仅获得1.03 的加速比,这是因为程序组合7 中所运行的测试子项更偏向于访存密集型任务,因此在S-NUCA 架构下,对比去除任务迁移带来的计算密集型功率预算,TSCDM 的优势并不明显。通过实验可知,TSCDM的调度算法与任务迁移算法能有效提升S-NUCA 架构下的系统性能。

图8 TSCDM 加速比测试结果Fig.8 TSCDM acceleration ratio test results
图9 给出了TSCDM、CFS、first_unused、RRS和MLS 在核心资源利用率方面的对比结果。为了直观地展示不同调度算法在核心资源利用率方面的区别,本文实验平台核心数量为128,而max_parallelism 参数设置为8,因此在统计核心资源利用率时,本部分实验汇总使用的8 个核心在运行时的平均资源利用率,而不是整个片上的资源利用率。从图9 可以看出,TSCDM 在组合6 中得到了最高的核心资源利用率,为98.5%,且7 个程序组合的平均资源利用率为91.9%。通过实验结果可知,TSCDM 在所有的程序组合下核心资源利用率均优于对比方案。

图9 核心资源利用率对比Fig.9 Core resource utilization comparison
3.2.3 T-TSP 评估
为了验证与传统TSP 方案相比,本文采用的TTSP 是否可以提供更加精确的热安全功率,减少片上热余量,使得处理器可以使用更高的DVFS 设定以提升性能,实验使用表2 中的虚拟机平台配置,分别设定DTM(即温度阈值TDTM)为60 ℃、65 ℃、70 ℃,运行SPLASH-2 中的测试子项,max_parallelism 参数设置为8,以运行完所有测试子项所耗费的虚拟时间作为衡量,对比测试T-TSP 与传统TSP 的性能,结果如图10 所示,横坐标代表不同的测试子项,纵坐标则是在特定子项下本文T-TSP 对比TSP 方案的加速比。由图10 可知,T-TSP 在所有应用上的性能均优于TSP,且设定的温度阈值越低,T-TSP 的加速比越高,在cholesky 中,T-TSP 对比TSP 获得 的加速比 最大,为1.13。这是因为T-TSP 在低温度阈值下可以充分发挥芯片的热余量,相比TSP 可以使用更积极的DVFS 策略,而温度阈值过高时,这一优势会不明显。本实验说明在各种温度阈值下,T-TSP 均可以大幅减少系统的热余量以提高系统性能。

图10 T-TSP 与TSP 对比结果Fig.10 Comparison results between T-TSP and TSP
3.2.4 调度方案与T-TSP 能耗比评估
能耗比代表单位功率下处理平台的性能,对于某一固定的计算平台,CPU 的性能会随着主频的提高而提升,但两者不呈线性关系。然而,过高的主频会导致芯片温度过高从而触发动态热管理策略,不同的调度方案和功率预算策略为系统运行提供了不同的DVFS 设定,因此,系统的能耗比也会随着不同的调度方案和DVFS 策略而改变。
为了验证TSCDM 相比RRS 和MLS 所带来的能耗比提升,本文使用表2 中的平台配置,按照表5 中的数据锁定不同的处理器最高主频。由于RRS 与MLS 仅为映射方案,并未考虑DVFS 设定,因此本部分实验RRS 与MLS 均使用HotSniper 模拟器默认使用的DVFS 方案。

表5 能效测试实验配置 Table 5 Energy efficiency testing experimental configuration
为了对比不同频率配置下的能效,本次实验取序号6 的实验配置,使用TSCDM 所得到的平台功耗和性能作为对照(100%),其余实验组均依次按照百分数折算。按照第3.2.2 节中的性能评估方法,实验结果如图11 所示,其中横、纵坐标分别表示功耗和性能,图中同一根曲线上的不同点分别表示表5 不同配置下测试得到的性能和功耗,例如TSCDM 上的6 个点分别表示使用表5 的6 种不同最高主频而得到的功耗与性能,使用多项式拟合绘制出3 种调度方案的能效曲线。通过分析可知,图中的曲线整体越靠近左上角说明能耗比越高,反之,曲线越靠近右下角说明能耗比越低。由图11 可知,TSCDM 拥有比RRS 与MLS 更高的能耗比。在任意相同的功耗下,由于T-TSP 会尽量降低热余量而使用更加激进的DVFS 方案,因此在每个主频组别下TSCDM 均达到了最高的功率和性能。3 种方案在大核与小核均锁定1.0 GHz 时能效区别最小,这是因为此时3 种调度方案都可以锁定最高频率而不触发DTM,而TSCDM 由于在S-NUCA 上优化了缓存延迟,因此仍然获得了更高的性能。此外,由于本文的调度算法和T-TSP 降低了系统的热余量,因此在系统锁定最高频率时会呈现最高的功耗和性能。实验结果表明,本文TSCDM 方案可以有效提升整体能耗比。

图11 不同调度方案的能耗比对比Fig.11 Comparison of energy consumption ratios for different scheduling schemes
4 结束语
本文通过分析S-NUCA 架构下异构多核处理器的特点,提出一种基于ANN 和动态映射的调度算法TSCDM。使用ANN 来预测某一个线程在大核和小核上的IPC 值,通过使IPC 值最大化确定每个线程与大核或小核的绑定关系。利用动态映射算法优先将线程绑定至AMD 值较小的核心,再通过任务迁移策略自动判断计算密集型任务,将其迁移至靠近片上边缘的空闲核心,以提高功率预算结果。实验结果表明,相比CFS、first_unused、RRS 轮询调度与MLS调度方案,在运行不同的基准测试组合子项时,TSCDM 均能有效提升系统性能与能耗比,同时本文采用的T-TSP 方案相较传统TSP 方案可以有效降低热余量,提升系统性能。
下一步考虑将TSCDM 应用至实机中,以评估其在真实应用场景下的表现。此外,将对调度算法进行优化,以更好地应对多种计算密集型任务的运行情况,同时尝试将本文所提调度算法应用到其他架构下的异构多核处理器中,以评估其通用性。
