基于全景视觉的无人船水面障碍物检测方法
2024-02-29周金涛高迪驹刘志全
周金涛,高迪驹,刘志全
(上海海事大学航运技术与控制工程交通运输行业重点实验室,上海 201306)
0 引言
随着无人船应用技术的不断提高,应用场合不断扩大,越来越多的水上交通问题越发明显,其中,水面障碍物检测成为解决该问题和实现无人船避障与导航的关键。传统的水域目标检测方法分为接触式与非接触式。接触式检测方法主要与过往船只在短距离范围内通过传感器进行识别,但这种传感器使用并不方便,且受距离的限制。非接触式检测方法主要依靠特定传感器获取目标物体的磁场、声波等信息来进行识别。也有研究人员将轮廓检测等传统图像算法运用到目标检测任务中。但是,在光照变化、舰船遮挡、角度变化以及视线不足等情况下,这些传统目标检测方法的鲁棒性较弱,且无法实现实时检测的目的[1]。
在机器人、智能汽车、智能船舶以及地理信息获取等领域中,全景视觉取得了一些成果[2],并已成为相关领域研究的方向和重点,主要分为多目全景、鱼眼镜头全景和折反射式全景3 类。鱼眼镜头全景本质上是一种大广角镜头,且不能实现真正的全景视觉功能。折反射式全景系统因图像两端严重畸变,导致成像质量不佳。多目全景视觉相较于鱼眼镜头全景和折反射全景视觉系统,具有全视角、无畸变以及图像信息丰富完整等优点[3-4]。与传统视觉环境感知系统视场相比,多目全景视觉系统可以实现水平方向范围内的大视场监控,其宽广的视角为监控周围环境带来了便利。在多目全景图像拼接过程中,尺度不变特征转换(SIFT)[5]和加速稳健特征(SURF)[6]是2 种常见的基于特征的图像配准算法。SIFT 算法对旋转、尺度和光照具有较强的鲁棒性。SURF 算法是在SIFT 算法的基础上发展起来的,采用积分图像和盒型滤波器对高斯二阶偏导数进行简化,缩短特征提取时间,具有与SIFT 算法相似的鲁棒性。与SIFT 算法相比,SURF 算法大幅加快特征提取速度,但是在提取特征后,对2 幅图像进行匹配时,特征点仍然存在不匹配与误匹配的问题。随机抽样一致(RANSAC)[7]和M 估计样本一致(MSAC)[8]算法常用来剔除误匹配点。
基于深度学习的图像处理算法相对于传统图像算法,具有无须手工设置特征、精度高、速度快等优点。为此,利用全景视觉技术并结合深度学习目标检测方法,成为无人船水面障碍物检测的1 个重要技术。针对无人船在航行过程中障碍物检测的目标过小或目标被遮挡等问题,文献[9]提出一种基于深度卷积神经网络的海面小目标多帧检测方法,表现出可接受的泛化能力,比常规检测方法具有更优的探测性能。文献[10]基于K-最邻近(KNN)算法和异常检测的思想设计一种全新的分类器,有效避免现有方法在水面小目标检测时尺寸限制和特征压缩损失,显著提升性能。最新研究表明,YOLO 系列算法可以适用于各种不同的目标检测场景。文献[11]提出一种基于改进YOLOv5 的不同交通场景下的车辆检测方法。文献[12]提出一种基于YOLOv5 多尺度特征融合的水下目标检测轻量化算法。文献[13]提出一种基于YOLOv5 的卷积神经网络来检测轴承盖缺陷。文献[14]提出一种用于车辆目标检测的增强 型YOLOv4 网 络。文 献[15]提出一 种改进YOLOv5 的遥感小目标检测网络,解决遥感图像中小目标易被错检、漏检等问题。在水面障碍物检测方面,针对在小物体检测效果差,水面反射引起的估计精度低等问题,文献[16]提出一种基于图像分割的水面障碍物检测网络。文献[17]提出一种基于单目视觉的新型实时障碍物检测方法,以有效区分海面上的障碍物和复杂的背景。文献[18]提出一种基于扩张卷积神经网络的水面无人艇障碍物类型识别方法。文献[19]提出一种基于卷积神经网络的水面无人船障碍物检测方法,进一步提高对某些类型障碍物的检测和分类能力。但对于视角不足的问题,会造成检测时障碍物缺失从而影响无人船航向判断。
本文提出基于全景视觉的无人船水面障碍物检测方法。设计一种改进的SURF 算法,在SURF 算法的基础上引入k 维(k-d)树构建数据索引,并利用MSAC 算法剔除误匹配点,实现精匹配。同时,为解决拼接过程中出现的缝隙或重影等问题,提出一种基于圆弧函数的加权融合算法,并进一步对YOLOv5s 的主干网络和损失函数进行改进,提出改进的YOLOv5s 障碍物检测模型(DS-YOLOv5s),以实现目标检测的实时性和精度的提高。最终将得到的多目全景拼接图输入到训练好的模型中,验证本文方法的有效性。
1 图像配准与融合的改进
在图像配准阶段,通过对传统SURF 算法进行改进,引入k-d 树来构建数据索引,实现搜索空间级分类,并利用MSAC 算法剔除误匹配点,实现精匹配。在图像融合阶段,本文提出一种基于圆弧函数的加权融合算法,解决图像融合过程中重叠区域存在的拼接缝隙或重影问题,使得在图像重叠区域得到自然过渡效果和高图像质量,为后续全景图像中的目标障碍物检测奠定基础。
1.1 基于改进SURF 的图像配准算法
在检测水面障碍物之前,需要制作数据集,且数据量偏大。当数据集较大时,计算的复杂性将大幅增加,提取的特征点越多,计算所需的时间就越长,但是实时性难以得到保证。在这种情况下,考虑通过构建数据索引来加快计算速度。SURF 算法提取的特征点将呈现聚类形式,使用树结构构建数据索引,以实现搜索空间级分类并快速匹配。但是SURF算法提取的特征点没有折叠空间,因此可以使用基于搜索引擎的k-d 树。k-d 算法是建立平衡二叉树的过程,实际上是1 个递归过程。
为了使图像拼接可以得到更优的图像质量,在进行特征点快速匹配之后须进行精匹配。MSAC 算法与RANSAC 算法有相同的基本思想,2 种算法的区别在于成本计算方式不同。在成本计算上,RANSAC 对队列值的选择很敏感,太大的队列无效,太小的队列不稳定,而MSAC 可以减少补偿这些影响。因此,本文采用的多目视觉全景图种类较多,相比RANSAC,使用MSAC 算法进行特征点的精匹配更合适。
1.2 基于圆弧函数的加权融合算法
传统基于距离的加权融合算法是线性函数,随距离从0~1 线性变化。在整个过程中权重的变化率是均匀的,导致重叠区域不能完全自然收敛[20]。在多目视觉全景图拼接过程中,涉及到多张图像进行拼接融合,当重叠区域内容非常复杂时,中心将出现拼接缝隙或重影。为了解决这一问题,本文提出一种基于圆弧函数的加权融合算法,以获得非线性变化权重。基于圆弧函数加权融合的图像拼接算法示意图如图1 所示,w'1和w'2是改进后的权重,IL(i,j)和IR(i,j)是非重叠区域的像素值,I(i,j)是重叠区域的像素值,p是重叠区域的任意一点,d为点p的横坐标,d1是左图像中非重叠区域的右边界横坐标,d2是右图像中非重叠区域的左边界横坐标。重叠区域中的虚弧是重叠区域中左图像的权重,而实弧是重叠区域中右图像的权重,2 个权重由半径为r的弧组成,其中r=(d2-d1)/2,因此可以获得改进的权值w'1和w'2。
改进的权值计算式如式(1)和式(2)所示:
快速全景图像拼接处理主要由多目视觉图像快速获取、改进的SURF 特征点提取匹配和全景图像拼接融合3 个模块组成。根据第1.1 节改进的SURF图像配准算法和基于圆弧函数的加权融合算法,对获取到的多目全景视觉图像进行特征提取,确定相邻图像的重叠部分,根据重叠特征点的信息进行匹配和拼接融合。
2 YOLOv5s 网络模型改进
YOLOv5 网络的主干部分是跨阶段部分网络(CSPNet)[21]。为充分利用从不同层提取的特征信息,YOLOv5 还采用特征金字塔网络(FPN)结构[22]。在FPN 特征组合之后,在此基础上添加路径聚合网络(PAN)[23]结构。经卷积下采样后,将组合的底部特征图与左侧FPN 结构中的相同比例特征图拼接,最后获得3 个不同大小(19×19、38×38 和76×76)的输出特征图。大小为19×19 的特征图具有较大的下采样率,适用于规模较大的目标;大小为76×76 的特征图则具有较小的下采样率,适用于尺度较小的目标。
在主干网络模型中使用深度可分离卷积(DSCOV)替换掉常规卷积来减少网络参数量[24],在损失函数计算方面,使用简化最优传输分配策略(SimOTA)进行正负样本的匹配[25]。DS-YOLOv5s算法由网络训练和检测2 个过程组成,总体框架如图2 所示。网络结构主要分为骨干网络、颈部网络和头部网络,其中网络轻量化操作在骨干网络部分进行,网络结构中的虚线、实线、灰实线3 个框分别表示3 个尺度特征图。损失函数的改进部分在训练模块。另外1 个为检测部分。
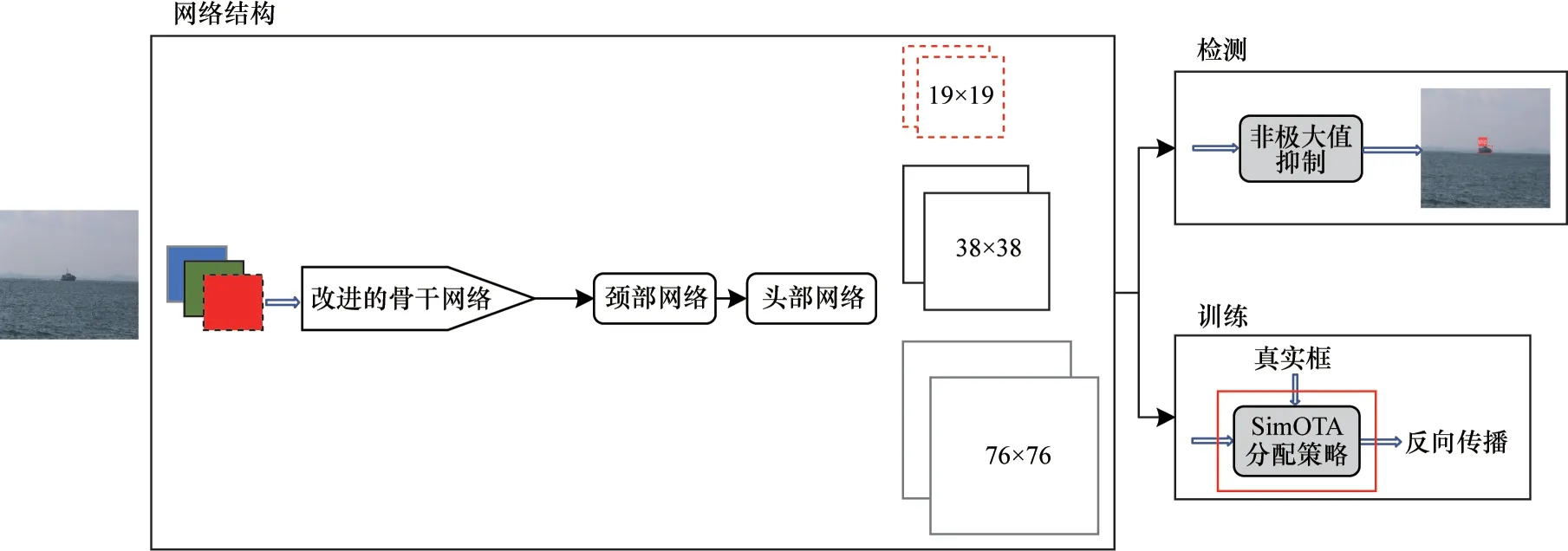
图2 DS-YOLOv5s 算法的总体框架Fig.2 Overall framework of the DS-YOLOv5s algorithm
2.1 YOLOv5s 网络轻量化
针对障碍物检测的实时性要求,本文采用深度可分离卷积代替YOLOv5 骨干特征提取网络的普通卷积,以减少原模型的网络参数量,缩短模型的推理时间,提高整个模型的推理能力。其核心思想是将标准卷积分为逐通道卷积和逐点卷积2 个部分。深度可分离卷积过程如图3 所示,首先进行逐通道卷积,对每个输入通道进行卷积运算,得到与输入特征图通道数一致的输出特征图,然后进行逐点卷积,利用1×1 卷积运算对特征图进行降维,结合所有逐通道卷积输出。n和m分别为输入和输出通道数,k×k为卷积核大小。
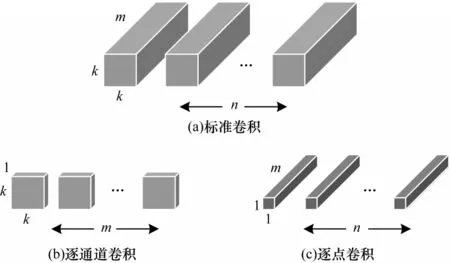
图3 深度可分离卷积过程Fig.3 Process of depthwise separable convolution
深度可分离卷积神经网络的计算式如式(4)所示:
其中:βi表示网络第i层的输入特征图;ξin表示第i层特征图的第n个通道;kn表示第n个通道的卷积核;D(·)表示逐通 道卷积 操作;S(·)表示 逐点卷 积操作;τ为D(·)操作的输出,表示第i层特征在经过逐通道卷积后的状态,并作为S(·)操作的输入;输出βi+1表示网络第i+1 层的输入特征图。
2.2 损失函数的改进
损失函数是衡量训练与实际结果之间相似度的重要指标。与YOLOv3、YOLOv4 不同,YOLOv5 在正样本和负样本的定义中采用跨邻域网络匹配策略,以获得更多的正样本锚点并加速损失函数的收敛。
YOLOv5 的损失主要由分类损失、置信度损失以及定位损失3 部分组成,计算式如式(5)所示:
其中:λ1、λ2、λ3为平衡系数;Lcls、Lobj、Lloc分别表示分类损失、置信度损失以及定位损失。
YOLOv5 根据锚帧和真实帧的交并比(IoU)来分配正负样本。然而,在不同大小、形状、遮挡条件下正负样本的划分也是不同的,并且还需要考虑上下文信息。较优的样本匹配算法可以有效解决密集目标检测问题,并在目标的极端比例或极端尺寸不平衡正样本时优化检测效果[26]。因此,SimOTA 将样本匹配视为最佳匹配。YOLOv5 原有的损失函数计算量偏大,在模型训练量较大时,容易导致真实值与预测值差别较大。因此,使用SimOTA 分配策略匹配正负样本,可在一定程度上减少损失计算量。成本计算式如式(6)所示:
其中:Cij为成本;λ为平衡系数;为分类损失;为回归损失。
通过式(6)可知,成本由分类损失和回归损失2 个部分组成,并且网络预测的类别和目标边界框越准确,成本越小。
2.3 数据集制作
基于YOLOv5 的无人船水面障碍物检测在很大程度上依赖于数据集质量。因此,在训练过程中使用高质量的数据集可以使深度学习器提取到更有效的特征。由于没有可用水面障碍物的相关大型公开数据集,因此一部分需要从网络上获取水面障碍物图像,同时也从一些公共水面障碍物数据集中获取图像。为保证深度学习器能够识别不同种类的水面障碍物,本文选取14 个类别图像,是海洋或内河中常见的障碍物,包含8 750 张图片,按常规比例7∶1∶2,将数据集划分成训练集、验证集和测试集。水面障碍物类别图如图4 所示。

图4 水面障碍物类别图Fig.4 lmages of obstacles categories on the water-surface
在各种扰动下的水面障碍物图像如图5 所示。水草或其他设施阻挡了部分检测目标、障碍物附近强烈的阳光反射、河流的复杂水面、图像中的目标太小以及目标附近有波纹等。上述情况是水面障碍物检测中的困难示例,添加此类图像可以提高模型的鲁棒性。

图5 在各种扰动下的水面障碍物图像Fig.5 Images of water-surface obstacles under various disturbances
3 实验与结果分析
3.1 图像配准与融合实验
多目视觉全景图是由无人船船体上的相机从多个角度采集到的图像拼接而成的。图像经过初步配准后会出现较为明显的拼接缝隙或重影,经过改进的图像融合算法处理后,可以在一定程度上解决该问题。本文对采用的基于改进SURF 图像配准算法和基于圆弧函数的加权融合算法进行实验分析。
3.1.1 基于改进SURF 算法的图像配准实验
待配准原图如图6 所示。图7 所示为不同配准算法得到的对比图。

图6 待配准原图Fig.6 Original images to be matched

图7 不同配准算法的配准图Fig.7 Registration images among different registration algorithms
本文采用匹配正确率(CMR)评价图像拼接的准确度[27]。CMR 作为一种相对客观评价算法匹配性能的衡量指标,其得到的数值越高,表明算法的匹配性能越优,相应的图像配准准确度也更优。匹配正确率(计算中用RCM)的计算式如下:
其中:NC表示正确匹配点数量;NR表示优化后所有匹配点数量。
不同算法配准对比实验结果如表1 所示,SURF在匹配正确率和时间上比SIFT 有更大的优势,匹配正确率提高了9.52 个百分点,耗时缩短了9.18 s。基于SURF+RANSAC 算法的匹配正确率比SURF 算法有较大优势,但在时间上没有优势,匹配正确率提高7.84 个百分点,耗时增加了6.94 s。基于改进SURF的算法与基于SURF+RANSAC 的算法相比,特征点的匹配正确率提高3.63 个百分点,匹配时间加快了5.83 s,与基于SURF 的算法相比,特征点的匹配正确率提高11.47 个百分点。因此,改进SURF 算法的整体性能更优。

表1 不同算法配准实验结果 Table 1 Experimental results of registration using different algorithms
3.1.2 基于圆弧函数的加权融合实验
为了更好地进行后续水面障碍物目标检测工作,本文需要得到更清晰的图像。在改进SURF 算法图像配准的基础上,本文选用分辨率较高的图像作为待拼接图,对采用的基于圆弧函数的加权融合算法进行验证。图8 所示为较高分辨率待拼接原图,图9 所示为融合前后的拼接图。

图8 较高分辨率待拼接原图Fig.8 Original images to be stitched in higher resolution

图9 融合前后的拼接图Fig.9 Stitching images before and after fusion
从图9 可以看出,经过基于圆弧函数的加权融合之后,在图像拼接过程中出现的拼接缝隙以及重影问题已经得到基本解决,使拼接图像的中心区域具有自然过渡效果并得到质量较高的图像,为后续进行目标检测奠定了基础。
3.2 检测模型训练结果与分析
本文实验使用的深度学习框架是PyTorch 1.7.0,操作系统是Ubuntu 18.04,CPU 是Intel®Xeon®Platinum 8255C CPU @2.5 GHz,GPU 是单卡NVIDIA GeForce RTX 3080(10 GB)。网络训练的初始学习率设置为0.01,学习率动量因子设置为0.937,权重衰减系数设置为0.000 5,超参数配置使用hyp.scratch.yaml 文件。Batch_size 设置为8,迭代次数为200。
本文将平均精度(mAP)作为模型性能的评价指标[28]。准确率(P)、召回率(R)和平均精度(mAP,计算中用mmAP)的计算式如式(8)~式(10)表示:
其中:TTP为真阳性;FFP为假阳性;FFN为假阴性;AAPi为某一类i的P-R曲线下的面积,通过将某些列的阈值调整为使用不同P和R值绘制的图像而获得。mAP 可以通过将每个对应类别下的AP 值相加和平均来获得,以反映模型的整体性能。
为验证该模型的有效性,本文选择YOLOv3[29]、YOLOv4[30]、YOLOv5s、YOLOv5m 和DS-YOLOv5s这5 种模型进行对比实验,结果如表2 所示,加粗表示最优数据。从表2 可以看出,DS-YOLOv5s 准确性和实时性都优于对比模型。在精度方面,DSYOLOv5s 比YOLOv5s 提 高1 个百分 点,mAP@0.5达到95.7%。在检测速度方面,DS-YOLOv5s 比YOLOv5s 提 高6 帧/s。YOLOv4 的 网络参数量更 大,导致其在各个指标性能均不理想。因此,当同时考虑检测实时性和准确性时,DS-YOLOv5s 具有更优的性能。

表2 不同目标检测模型的实验结果 Table 2 Experimental results among different target detection models
为更加直观地评价该模型的性能,本文对改进前后以及对比实验中其余模型的检测结果进行对比,结果如图10 所示。第1 列为被遮挡目标,第2 列为复杂水面环境,第3 列为多目标的图像。从图10可以看出,DS-YOLOv5s 模型表现较优的检测性能,检测到了更多目标,并识别出被遮挡目标,检测精度高,且不存在误检和漏检问题。在被遮挡目标检测对比中,YOLOv4 和YOLOv5m 模型存在漏检问题。这是因为2 个模型的网络参数量较大,随着网络深度的加深,感受野增大,而特征图的尺寸减小,位置信息变得越来越模糊,使得小目标的精确检测变得困难。综上所述,本文提出的模型在被遮挡目标、复杂水面环境以及多目标检测中检测效果最好。DS-YOLOv5s 模型检测速度为51 帧/s,具有实时的检测速度,且不存在误检、漏检等问题,满足水面环境复杂场景下障碍物检测实时性与准确性的要求。

图10 面向复杂场景的对比实验结果Fig.10 Comparison experimental results for complex scenarios
YOLOv5s 模型改进前后的P-R曲线如图11 所示(彩色效果见《计算机工程》官网HTML 版)。从图11 可以看出,对于每个类别,DS-YOLOv5s 模型整体性能是最优的,且绝大多数类别的检测准确率均高于YOLOv5s 模型。

图11 YOLOv5s 模型改进前后的P-R 曲线Fig.11 P-R curves before and after the improvement of the YOLOv5s model
为评估本文引入的模块和不同模块组合顺序对算法性能优化的程度,本文设计一系列消融实验。消融实验结果如表3 所示,其中,“√”表示在YOLOv5s网络模型的基础上加入该策略,“—”表示无任何策略加入。消融实验以组合形式考虑了DSCOV、SimOTA 分配策略这2 种因素的影响。从表3 可以看出,相比DSCOV,YOLOv5s+DSCOV 的mAP@0.5有所下降,这是因为DSCOV 使网络参数量减少,且加快检测速度,同时也会降低精度。相比YOLOv5s、YOLOv5s+DSCOV,YOLOv5s+SimOTA 的mAP@0.5分别提高1.2 和1.6 个百分点。相比DSCOV、YOLOv5s+DSCOV,YOLOv5s+DSCOV+SimOTA 的mAP@0.5 分别提高1.0 和1.4 个百分点。本文综合考虑实时性和准确度,改进后模型的14 个类别AP值更优,说明采用DSCOV 以及SimOTA 分配策略可以提升模型性能。因此,本文提出的网络在该数据集上具有最佳的综合性能。

表3 消融实验结果Table 3 Ablation experimental results %
3.3 全景图检测结果
本文将拼接完成的全景图输入到训练好的模型中进行检测,检测该模型是否可以快速准确识别到水面障碍物。图12 所示为从水平方向多个角度获得参与测试的多目视觉图像,对图像进行全景拼接,将得到的全景图用于测试。拼接后的多目视觉全景图如图13 所示,障碍物检测图如图14 所示。

图12 参与测试的多目视觉图像Fig.12 Multi-eye visual images of the participants in the test

图13 多目视觉全景拼接图Fig.13 Multi-eye vision panorama stitching image

图14 障碍物检测图Fig.14 Obstacle detection image
从图13 可以看出,拼接图已消除拼接缝隙或重影,进而得到更优的图像质量,用于后续的目标物检测。从图14 可以看出,对拼接好的全景图可以实现精准识别,检测速度为50 帧/s,满足实时性要求。
4 结束语
为解决无人船在海洋或内河等水域环境下水面障碍物检测视角狭窄问题,本文提出一种基于全景视觉的无人船水面障碍物目标检测方法。为提升图像配准速度和配准率,引入k-d 树来构建数据索引,实现搜索空间级分类,通过MSAC 算法对匹配点进行优化,剔除误匹配点。采用一种基于圆弧函数的加权融合算法解决图像融合中出现的拼接缝隙或重影问题,获得自然过渡效果和质量较高的图像。在目标检测部分,采用深度可分离卷积网络替换YOLOv5 主干网络中原有卷积网络,并对损失函数计算分配策略进行改进,提出水面障碍物目标检测模型DS-YOLOv5s。实验结果表明,基于改进的SURF 算法在特征点的匹配正确率和匹配速度均有明显的改善。在障碍物检测方面,基于改进的YOLOv5s 目标检测方法在实时性和准确度方面得到显著提高,可对多目视觉全景拼接图中的目标障碍物实现实时精准检测识别。因此,基于全景视觉的无人船水面障碍物检测方法为无人船自主避障、自主航行提供有效的解决方案。后续将采集更多样本进行检测研究,提高目标检测准确率。
