融合卷积收缩门控的生成式文本摘要方法
2024-02-29甘陈敏唐宏杨浩澜刘小洁刘杰
甘陈敏,唐宏,杨浩澜,刘小洁,刘杰
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学移动通信技术重庆市重点实验室,重庆 400065)
0 引言
自动文本摘要技术是自然语言处理领域中的重点研究方向,将信息琐碎的长文本压缩精炼后,产生一段关键信息集中且语言简洁的短文本,获取有价值的内容[1]。
依据产生方法的不同,自动文本摘要技术可分为抽取式(Extractive)方法和生成式(Abstractive)方法[2]。尽管机器模型难以完全理解自然语言的深层词意,生成式方法易产生重复冗余的内容,不能完全把握文本关键信息[3],但是生成式摘要更符合人类逻辑思维对文本的撰写习惯,比抽取式方法的应用更加广泛。
当前,在生成式文本摘要方法中基于深度学习的主流模型是结合注意力机制的Seq2Seq 模型[4],遵循编码-解码框架,编码器能够准确地编码输入文本,学习文本的隐含特征和重要信息,解码器根据上下文的注意力分数提取信息解码生成摘要。特别地,随着文献[5]提出将基于循环神经网络(RNN)作为编码器和解码器构建文本摘要生成模型,融合注意力机制取得优异成绩。后续大部分研究开始在此基础上加以创新,更新了一系列网络模型,使得文本摘要评价指标ROUGE[6]的分数有所增加。
针对Seq2Seq 模型受到词表限制,难以解决集外词(OOV)的困扰,文献[5]在指针网络[7]的基础上设置“开关”,提出Switching Generator-pointer 模型,独立计算生成概率和复制概率来缓解上述问题。文献[8]提出复制机制,从输入序列复制生词到输出序列中,弥补集外词的空缺。文献[9]结合复制机制和指针网络提出指针生成网络(PGN),巧妙地利用覆盖机制[10]缓解重复词语问题,在CNNDM 数据集上获取当时最优结果。随着对神经网络模型认识的不断深化,RNN 原理架构的弊病逐渐暴露。比如,RNN 及变体都是逐词按序处理,难于实现并行计算,导致在训练模型和生成摘要阶段效率低下。此外,RNN 在编码阶段得到的前后信息仅简单地拼接,对单词间的联系缺乏有效建模,不可避免地出现丢失文本关键内容,生成的摘要中包含重复和冗余词句,主次颠倒,偏离文本原意。
文献[11]提出一种全新的完全基于注意力机制构建的预训练语言模型Transformer,具备快速并行计算的能力和强大的特征提取能力,逐渐被应用于文本摘要任务。文献[12]引入BERT[13]模型,提出一个通用的编码框架,能同时用于抽取式摘要和生产式摘要。文献[14]将BERT 与生成式预训练Transformer(GPT)[15]联合预训练组成BART 模型,在摘要数据集上进行微调,其ROUGE 评价获得当下较高的分数。文献[16]提出语言生成任务(ERNIE-GEN)模型,通过连续预测语义完整的跨度生成流程,训练模型生成更接近人类写作模式的文本。此外,文献[17]提出的间隔句以Transformer 结构为基础,探索为抽象文本摘要量身定制的预训练目标。上述模型在Transformer 的基础上设计新的训练方式,却未能寻求更适用于文本摘要任务的模型结构。
本文以Transformer 为基础预训练语言模型,利用其优势设计性能更佳的文本摘要生成模型。在编码器阶段,选择BERT 作为编码器提取文本特征并生成编码字向量,在解码器阶段,搭配基础Transformer 解码架构,设计两种改进的解码器,包括共享BERT 作为解码器部分模块和采用GPT 作为解码器部分模块,以更有效地融合编码输出和解码输出,提升模型性能和文本摘要生成的质量。
1 基于Transformer 和卷积收缩门控的文本摘要模型
本文在Transformer 模型的基础上进行改进和完善,提出基于Transformer 和卷积收缩门控的文本摘要模型,模型结构如图1 所示,包括编码器、卷积收缩门控单元和解码器。编码器采用BERT 模型读取输入文本构建编码表示,由卷积收缩单元和门控单元组成的卷积收缩门控单元筛选与全局语义相关的有用信息作为编码输出。解码器除了选择基础的Transformer 解码模块构建TCSG 模型外,还设计了共享BERT 编码器作为解码器部分的ES-TCSG 模型与采用GPT 作为解码器部分的GPT-TCSG 模型。
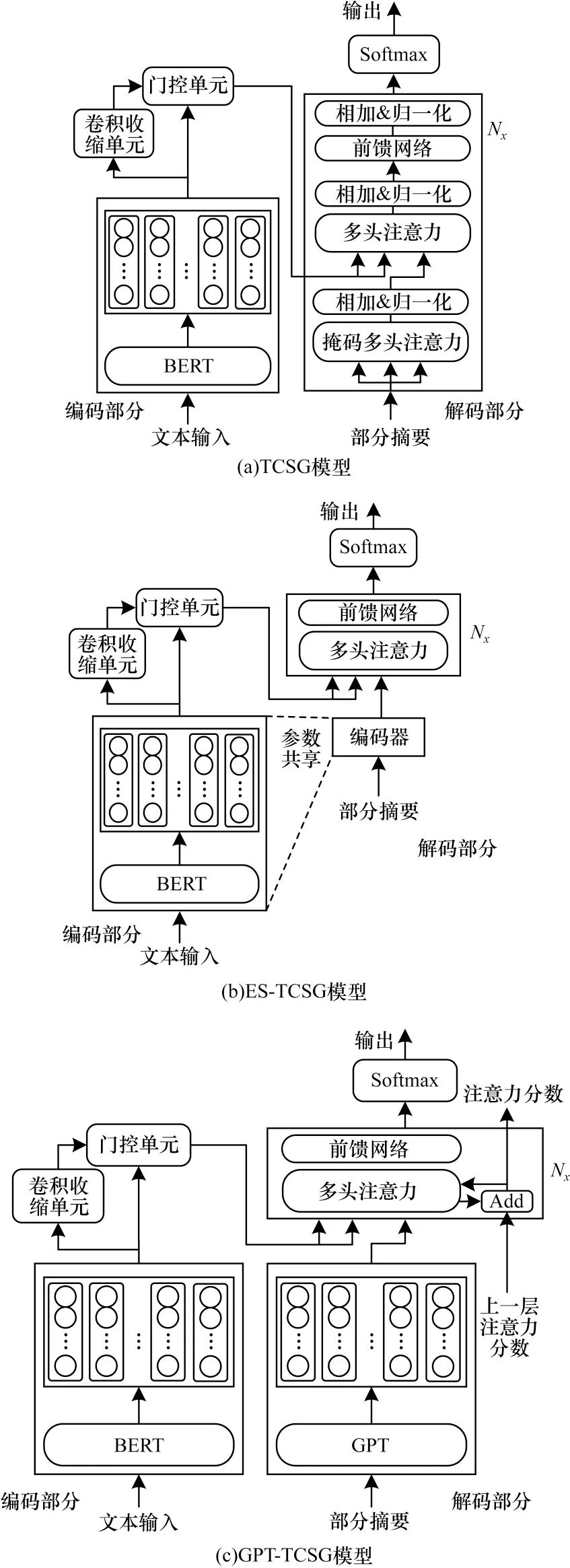
图1 文本摘要模型Fig.1 Text summarization model
1.1 问题形式化
给定源文档D,将其表示为输入序列X={x1,x2,…,xn},其中n表示输入序列的长度。自动文本摘要技术的目标就是将D作为模型输入,经过训练生成简短文本摘要序列Y={y1,y2,…,ym},其中m表示输出文本长度,且输出文本长度m要远小于输入文本长度n。模型通过输入序列X逐步最大化得到生成摘要序列Y的概率,尽可能提高生成的摘要Y和参考摘要Y′的相似度。
1.2 编码器
BERT 能够双向建模做到并发执行,可以获取更多的上下文信息,全面地反映句子语义,更适用于需要编译大量文本的任务。其结构基于多层Transformer 的编码模块,主要包含多头注意力层和前馈网络层。多头注意力层期于获取单词之间的联系分数和上下文表示向量,如式(1)所示:
其中:自注意力机制的输入是由同一单词转换成的查询(Q)、键(K)、值(V)3 个向量,且Q=K=V=x;分别为对应第i个头的可学习的参数矩阵;Wo∈Rhdv×d表示线性变换,dk和dv分别对 应K向量和V向量的维度,d表 示模型输入输出维度,h表示多头注意力层的头数,且dk=dv=d/h。
前馈网络层作用在多头注意力层之上,以此增强模型的非线性拟合能力,计算公式如下:
其中:W1∈Rd×df、W2∈Rdf×d表 示线性变换,df表示该前向反馈层的维度;b1和b2为偏量参数。
此外,本文解码模块也都基于Transformer 结构,其方法及公式与编码模块相同,故本文不再赘述。
1.3 卷积收缩门控单元
相对比其他自然语言处理任务,文本摘要更注重把握文本重要内容,生成语义通顺内容简介的摘要。因此对于文本摘要任务,除了能有效地提取关键信息外,还需要减少生成重复冗余信息,尤其是生成式摘要模型。文献[18]引入自匹配机制,在编码阶段增加全局自匹配层获取全局信息和全局门控单元抽取文本核心内容,去除冗余。文献[19]提出由卷积门控单元组成的全局编码框架,改善源端信息表示,并基于新的编码表示进行关键信息筛选。而文献[20]在Transformer 模型上引入卷积门控单元,设计3 种连接方式的解码器,充分利用卷积门控的优势去筛选文本关键内容。实验结果表明,有效地融合BERT 和卷积门控单元能大幅提升模型性能。
受上述研究的启发,本文同样在卷积门控单元的基础上缓解摘要中重复冗余的问题。与上述研究不同,提出的卷积收缩门控(CSG)单元进一步加强了模型抑制冗余信息的能力,如图2 所示。
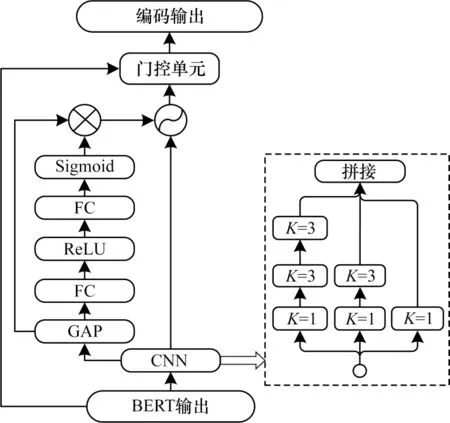
图2 卷积收缩门控单元Fig.2 Convolutional shrinkage gating unit
卷积门控单元主要由多个不同卷积核的卷积神经网络(CNN)模块、采用自注意力机制的注意力模块和门控网络模块组成。本文沿用CNN 模块使用多个(内核大小k=1,3,5)一维卷积提取n-gram 特征,遵循Inception 的设计原则,选择两个3 核代替5核,以避免内核大幅增加计算量(见图2 右侧虚框内)。具体计算公式如式(5)所示:
其中:ci为卷积输出;Wc表示权重 参数;δ是非线 性ReLU 激活函数;di-k/2,…,di+k/2表示卷积核窗口的滑动位置i为窗口的中间位置;b为偏量。卷积单元能实现参数共享,提取句子中的共同特征。注意力层在CNN 模块结果上能实现特征表示的自关注,深度挖掘全局语义相关的信息。然而,每个特征表示都融入全局信息会造成冗余。为有效地减少干扰,进一步抑制无用信息,本文采用带有软阈值的深度注意力模块代替自注意力机制。
软阈值化是一种常用的信号降噪方法,通过对阈值进行设置,将低于该值的特征截断为0,其他特征也朝着0 进行调整,即“收缩”[21]。本文将 其思想引入到文本处理中,根据文本编码表示设置一定的阈值,删除小于阈值绝对值范围内的特征表示,期于抑止不重要单词的干扰和构建高分辨特征。计算方法如下:
其中:x是输入特 征;y是输出特征;τ是正参数的 阈值。软阈值并非将负特征直接设为0,而是根据它们的实际贡献程度来选择保留部分有价值的负特征。由式(6)可以观察到,输出对输入的导数为1 或0,能有效避免梯度消失和爆炸问题。
人工操作设置合适的阈值是当前一大难题,此外,阈值参数的最佳值也因情况而异。为避免该情况,需要寻求在深层体系结构中模型能够自动确定阈值。压缩与激励网络(SENet)能将关注点放在特征通道之间的联系上。SE 模块通过压缩和激励操作帮助神经网络学习每个特征通道的重要程度,并依此去减少对当前任务无用的或不必要的特征,又称作“特征重标定”策 略[22]。如 图2 所示,首先将CNN 模块的输出c作为输入通过全局平均池化(GAP)进行特征映射并压缩,将通道中整个空间特征编码为一个全局特征,得到一维向量g;然后将向量g传播到两个全连接层(FC)中,衡量通道间的相关性,并得到和输入特征相同数量的权重,输出一个缩放参数;最后在末端应用能将缩放参数控制在(0,1)范围内的Sigmoid 函数。计算表达式为:
其中:W1和W2表示权重参数;δ是ReLU 激活函数;σ是Sigmoid 归一化函数;α为对应的归一化后的缩放权重参数。类似于注意力机制,将α视为对每个特征通道经过选择后的重要程度,乘以对应通道的特征向量,完成在通道维度上对原始特征的重标定,并将加权后的特征向量作为模块的输出,使模型具备更高的分辨能力去判断各个特征通道的贡献度。计算实现过程如下:
其中:τ表示阈值;Zc表示输入c的特征映射。在开始时,阈值需要预先设置为趋于0 的正参数,并在后续学习中自动修正。通过带阈值的深度注意力机制削弱无用特征,保留核心信息。
最后,门控单元基于上下文的全局信息控制从编码器到解码器的信息流筛选得到最终的编码输出h:
其中:hb表示BERT 的输出;hc表示卷积收缩门控单元的输出。hc通过Sigmoid 函数在每个维度上输出介于0~1 之间的向量,该值接近0 则删除大部分信息,接近1 则保留大部分信息。
1.4 解码器
在文本摘要任务中,解码器作为决定摘要生成质量的最后一个关键点是必不可少的。它将编码器输出和解码器上一时间步输出合并在一起作为输入,来计算当前时间步的输出。本文将致力于探求最佳的解码结构来更有效地融合编码输出和解码输出,在Transformer 结构基础上对比3 种不同连接方式的解码器变体,并进行实验和分析。
1)Base-Decoder:基于多 层Transformer 解码模块,根据文本编码信息初始化解码器后,对当下时间步t之前所有解码输出(即已经生成的摘要)序列Y={y0,y1,…,yt-1}进行编码,得到新的解码隐状态序列S={s0,s1,…,st-1}。之后根据S与编码输出h预测当下时间步t的解码输出yt。以此类推,最终生成摘要序列。
2)ES-Decoder:在解码过程中,解码器需要对解码输出重新编码,而编码器对文本输入序列进行编码,两个模块在功能上具有相似性。文献[23]在Transformer 结构上提出编码器共享,直接将编码器代替功能相似的解码器模块,优化模型性能。故本文参考其思路将BERT 编码器作为解码模块,去掉解码器中多余的多头注意力层,整合冗余模块。在训练过程中,编码任务均交给编码器,可以减少模型参数,降低复杂度。同时,由于同一空间映射能够深度挖掘输入序列与输出序列之间的联系,进而增强编码器的编码能力。
3)GPT-Decoder:不同于BERT,GPT 只采用Transformer 的解码架构。由于解码模块中的mask机制,GPT 通过观察文本中单词的上文来预测单词,使得GPT 更擅长处理文本生成任务。因此,本文采用GPT 架构作为解码模块,并添加额外的多头注意力层和前向反馈层合并处理编码输出和GPT 输出。解码模块各层都会维护自己的权重值,每层处理过程相同但计算结果不同。为加强解码模块对关键信息的敏感程度,在额外的多头注意力层之间外接残差网络,创建直接路径来传递注意力分数[24],将式(1)更改为:
其中:PPre表示上一层注意力分数。将上一层注意力分数直接传递给下一层,加强各层之间的联系,同时还能稳定模型训练,减少训练时间。经过多头注意力和前向反馈层的输出模块得到输出向量m,最终经过Softmax 层生成下一个单词,如式(11)所示:
其中:Wm表示权重参数;b为偏量。此外,本文各解码模块层数均为N=6。
2 实验结果与分析
为验证本文所提模型的可行性和有效性,本文在中文数据集LCSTS 和英文数据集CNNDM 上训练模型。为了验证每个改进策略对模型的影响效果,对改进模块独立进行实验研究,训练模型和分析结果,不断优化并获得最佳模型。本文选取多种生成式方法的基准模型进行对比,并细化分析本文模型的性能和实验结果。
2.1 数据集
使用两种不同类型的摘要数据集进行实验,研究并分析模型的表现。
中文数据集LCSTS 是一个短文本新闻摘要数据集[25],摘录于新浪微博,规模超过200 万。该数据集包括3 个部分,即24 万对用于模型训练的文本和摘要数据、10 000 条人工标记的简短摘要与相应的简短文本的相关性用于模型的验证以及用于模型测试的1 000 对数据。
英文数据集CNNDM 是从美国有限新闻网(CNN)和每日邮报收录上千万条新闻数据作为机器阅读理解的语料库。文献[5]在此基础上改进成文本摘要数据集。该数据集有匿名和非匿名两种版本,本文使用后者,包含28 万个训练数据对、1.1 万个验证数据对和1.3 万个测试数据对,固定词汇表有5 万个单词。
2.2 评价指标
针对自动文摘模型性能评价,普遍采用由文献[6]提出的ROUGE 自动摘要评价方法,其基本思想是统计生成摘要与参考摘要之间重叠的基本单元(n元语法、词序列和词对)的数目,以此客观地评价模型生成摘要的质量。本文从常见的3个粒度来计算重叠数目:ROUGE-1(1-gram),ROUGR-2(2-gram)和ROUGE-L(最长公共子序列),其分数越高,表明模型生成摘要的质量越高,模型性能越好。
2.3 参数设置
本文使用标准的编码器-解码器结构,均以Transformer 为基础,BERT 与解码器均设置为6 层结构,所有多头注意力机制拥有8 个头,隐藏层神经元个数为512,字向量维度为512,前向反馈层的中间层大小为2 048。使用dropout 方法避免过拟合,比率设为0.1。由于网络的复杂性,为保证模型的稳定性,在训练阶段,实验分别使用β1=0.9 和β2=0.999的Adam 优化器用于编码器和解码器,将初始学习率分别设置为lr1=0.0428 和lr2=0.1,并采用预热与衰减策略设置学习计划。为加快训练和测试速度,针对LCSTS 数据集,设置训练批次大小为128,初始文章最大长度为200,摘要最大长度为50;而CNNDM数据集的处理批次为64,初始文章最大长度为800,摘要最大长度为100。在测试时,使用束宽度为4 的束搜索方法选择候选摘要序列。
2.4 实验对比与分析
本文模型与以下基准模型在LCSTS 数据集和CNNDM 数据集上进行性能对比,并直接从文献实验数据中抽取结果。
1)words-lvt2k-temp-att[5]:基 于RNN 的Seq2Seq模型,利用时间注意力机制跟踪注意力权重,阻止关注相同部分。
2)RNN-context[25]:提 出LCSTS 中文 数据集,在Seq2Seq 模型的基础上进行实验研究。
3)PGN-Coverage[9]:在指针生成网络模型的基础上结合覆盖机制,计算覆盖向量来避免重复问题。
4)CGU[19]:在Seq2Seq 模型基础上提出全新的全局编码框架,利用卷积门控单元改善源端信息表示,捕捉关键信息。
5)Transformer[11]:基于注 意力机 制构建 的Seq2Seq 模型,具有快速计算的能力,能在更短的时间内获取更优的实验结果。
6)BERTabs[12]:将BERT 模型引入文本摘要任务中,利用其强大的表征能力获取文本编码信息,提升生成摘要的质量。
7)CBC-DA[20]:在编码部分融合BERT 和卷积门控单元,解码部分采用3 种不同的结构探讨更有效的融合方式去改善模型性能。本文选取文献中效果最佳的模型。
本文分阶段独立验证各改进方法的有效性,由此对以下模型做出说明:
TCSG:使用BERT 进行文本编码,利用卷积收缩门控单元筛选合适的编码信息输入基础Transformer 解码器中生成摘要。
ES-TCSG:在TCSG 的基础上共享BERT 作为解码器的部分之一,剔除模型功能重复的模块,减少模型的参数。
GPT-TCSG:在TCSG 的基础上充分利用GPT 的文本生成能力作为解码器部分之一,并添加额外的残差注意层加强解码器各层之间的联系,稳定模型。
不同模型在LCSTS 上的ROUGE 值如表1所示。
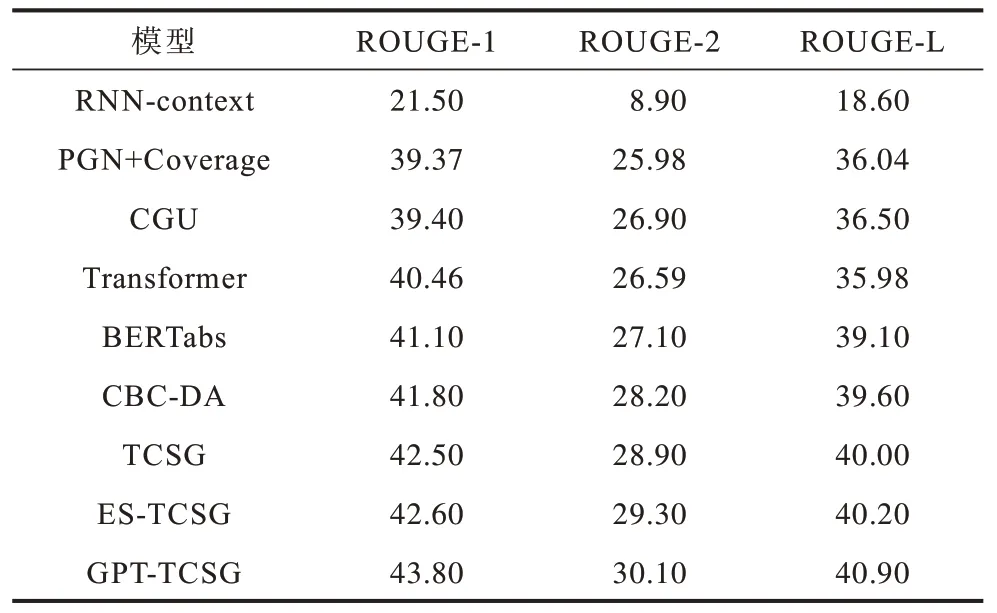
表1 各模型在LCSTS 上的ROUGE 值 Table 1 ROUGE values for each models on LCSTS
表1 中数据显示,本文模型在LCSTS 数据集上的实验结果均优于对比模型。由表1 中ROUGE 值分析可知:在前6 个基准模型中,CBC-DA 模型效果最好,而本文模型TCSG 与之相比,评价分数分别高出0.7、0.7 和0.4 个百分点,充分说明本文提出的卷积收缩门控单元能进一步抑制重复冗余信息,在文本摘要生成中发挥积极作用。同时,ES-TCSG 模型的3 个ROUGE 值相较于TCSG 模型分别提升了0.1、0.4 和0.2 个百分 点,GPT-TCSG 模型则提升1.3、1.2和0.9 个百分点,表明本文充分利用Transformer 架构的优势能获取更佳实验结果的解码器形式。尤其是GPT-TCSG 模型表现最突出,能提取完备的文本特征,生成质量更优的摘要。
不同模型在CNN/DM 上ROUGE 值如表2所示。

表2 各模型在CNNDM 上ROUGE 值 Table 2 ROUGE values for each models on CNNDM
表2 中展示了本文模型和对比模型在CNNDM数据集上ROUGE 分数。本文所提出的3 种模型的实验结果均有不同程度提升。类似于LCSTS 数据集上的分析,在相同条件下,对比TCSG 和BERTabs模型,TCSG 的评价分数分别提升了0.64、0.79 和0.62 个百分点,说明本文模型在长段落数据集上仍表现出色。此外,ES-TCSG 和GPT-TCSG 模型进一步提升了ROUGE 值,优化了模型性能。
2.5 消融分析
为进一步展示模型中各模块的性能和重要程度,本文选择在CNNDM 数据集上进行消融实验,结果如表3 所示。
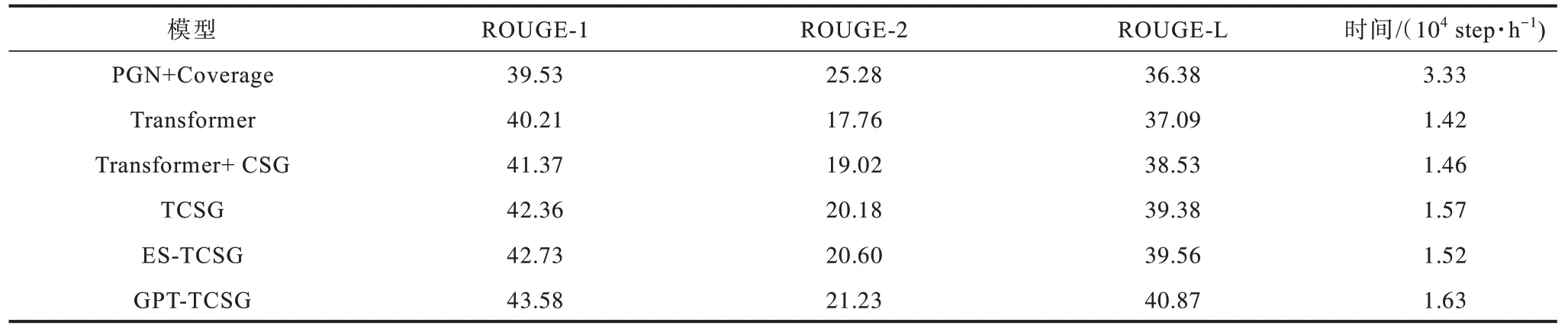
表3 消融实验对比分析结果 Table 3 Comparative analysis results of ablation experiments
由表3 实验结果分析可知:
1)实验细化分析各模型的贡献程度,在Transformer 模型的基础上加上CSG 单元得到表中第3 行数据,对比第2 行Transformer 模型实验结果,验证CSG 单元能有效指导编码器挖掘文本全局信息和深层联系,减少无用特征。同时,保持CSG 和解码器不变,对比第3 行和第4 行数据,表明BERT 作为编码器能大幅提升模型提取文本表征的能力,更全面地反映句子语义,获得更佳的实验结果。最后3 行数据说明不同解码结构对实验结果的影响,与TCSG 和ES-TCSG 模型对 比,GPT-TCSG 的性能 显著提高,GPT 作为解码模块能充分发挥其结构优势,生成更高准确率的摘要。
2)针对模型训练时效问题,本文复现基于RNN的PGN+Coverage 模型和基于自注意力机制的Transformer 模型,同本文模型一样通过20 万次迭代,统计每个模型的训练时长,以10 000 为单位计算耗时,结果如表3 中最后一列所示。对比PGN+Coverage 模型,本文模型均在更短的训练时长内获取更高的评价分数。对比Transformer 模型,本文模型架构复杂度增加,以时间为代价换取更佳的实验结果。特别地,由最后3 行可知,ES-TCSG 模型相比于另外2 种本文模型,时效有所改善,验证了将编码器共享作为解码器部分能提升模型训练速度。
综上所述,通过对比分析,模型中的各模块均是必需的,且充分发挥其作用,来提高模型性能和生成摘要的质量。
3 结束语
本文提出基于Transformer 和卷积收缩门控的文本摘要方法。首先采用BERT 作为编码器尽可能获取更多的上下文语义信息;然后利用卷积收缩门控单元进行文本关键信息筛选,强化全局信息,抑制冗余信息的干扰;最后设计3 种不同连接方式的解码器融合编码和解码信息,探索更适用于文本摘要生成任务的模型结构。在LCSTS、CNNDM 数据集上的实验结果表明,所提模型在ROUGE 评价指标上比基准模型效果更优,能获取更优质的文本摘要。下一步将考虑加强编码器和解码器之间的衔接和联系,以及模型预训练方式的设计和优化,采取更好的预训练目标减少模型的训练时间,提升模型性能。
