基于GRU和LSTM组合模型的车联网信道分配方法*
2024-02-28王永华何一汕伍文韬
王 磊,王永华,何一汕,伍文韬
(广东工业大学 自动化学院,广州 510006)
0 引 言
随着5G通信技术的发展,车联网(Internet of Vehicles,IoV)受到了越来越多的关注。车联网中存在着不同类型的连接,分为车对基础设施(Vehicle to Infrastructure,V2I)和车对车(Vehicle to Vehicle,V2V)链路。在5G蜂窝V2X网络中,需要同时满足高速率的海量数据传输以供娱乐,另一方面更需要可靠的信道资源以供必要的通信,因此,信道资源是实现车辆间的相互通信关键条件。为满足这种不同场景下的通信需求,文献[1]对5G网络中异构网络应用场景以及未来的研究趋势进行了讨论。然而信道资源的稀缺,显然已经不能满足当前车联网中的高通信需求。因此需要设计更加智能的信道分配方案,降低通信时信道冲突,最大化车联网的网络效用,提升信道资源利用率。
为应对这个挑战,文献[2]为基于设备到设备的车载网络开发了一种启发式空间频谱复用方案,减轻了对完整 信道状态信息(Channel State Information,CSI) 的要求;文献[3]指出的最大化V2I链路吞吐量的V2X资源分配方案能适应缓慢变化的大规模信道衰落,从而减少网络信令开销;文献[4]利用网络切片技术联合优化频谱资源块分配和车辆信号发射功率控制,最大化信息娱乐服务切片的平均和吞吐量。然而,这些算法大多假设车联网环境背景信息已知,但在实际情况下大多无法满足。深度强化学习由于在处理大状态和动作空间时能够提供目标值(称为Q值)的良好近似值而备受关注。文献[5]针对车联网可分配频谱资源数目未知的情况,提出了一种基于深度Q网络(Deep Q-Network,DQN)的联合缓存和计算资源方案。为进一步解决高移动性和多数目车辆环境中的频谱资源难以集中式管理问题,文献[6]提出了一种用于 V2V 和 V2I 通信的混合式频谱复用和功率分配方案,并设计基于卷积神经网络(Convolutional Neural Networks,CNN)的实时决策方法实现频谱复用和功率分配。
虽然使用深度强化学习算法能够实现车辆自主探索未知空间,智能地解决信道分配问题,但在实际车联网中由于传输需求不同,网络拓扑结构的变化十分迅速,从而使得传统的深度神经网络(Deep Neural Network,DNN)对这种在时间序列上变化快速的数据进行建模,运用到深度强化学习中时也很难让智能体学习到有效的信道分配策略。针对这个问题,目前的研究大多只是将长短期记忆(Long Short-Term Memory,LSTM)或者门控循环单元(Gated Recurrent Unit,GRU)去替代DNN在深度强化学习中的拟合Q函数的作用。虽然LSTM和GRU都能够处理前后连续的历史序列,但LSTM本身由于其结构内部参数较多,如果时间跨度很大,在网络比较深的情况下会使得计算量变大,很耗时,且有过拟合的风险[7]。同样,虽然GRU的简单结构,让其在训练时拥有比LSTM更低的计算复杂度,但在拟合精度上却比不上LSTM。这种由于网络结构上的缺陷导致的算法性能上的不足,会使车联网中的信道分配问题难以寻找到最优解,导致算力上的浪费。
将GRU训练周期短与LSTM拟合精度和稳定性高的两个优点结合起来,能使算法更加高效和稳定[8-10]。本文以此为出发点,考虑将GRU-LSTM组合网络模型结合到分布式强化学习中,并围绕如何降低车联网中V2V链路的信道冲突并最大化网络效用的问题进行研究。
1 系统模型及问题陈述
1.1 系统模型
图1所示为由单个基站(Base Station,BS)以及M条V2I链路和N条V2V链路构成的十字路口车联网无线通信模型[11],M条V2I链路将车辆与BS进行连接,承载着娱乐以及交通管理数据(非安全数据)的传输,N条V2V链路主要承载安全数据的传输。为保证高质量V2I链路通信,假设每条V2I链路已被预先分配了不同的正交频谱子载波以消除网络中V2I链路之间的干扰,同时假设V2V链路对V2I链路的干扰也在理想状态内。V2I链路作为授权用户,拥有独立的信道,V2V链路可提供相邻车辆之间的直接通信。为了提高频谱利用率,V2V链路作为感知用户需要利用与环境交互获得的部分可知信息,动态地感知V2I链路的信道条件,复用V2I链路的上行链路频谱进行信息交换,即在不影响V2I链路的正常通信的情况下以下垫式接入到其信道中来完成各自的传输任务。
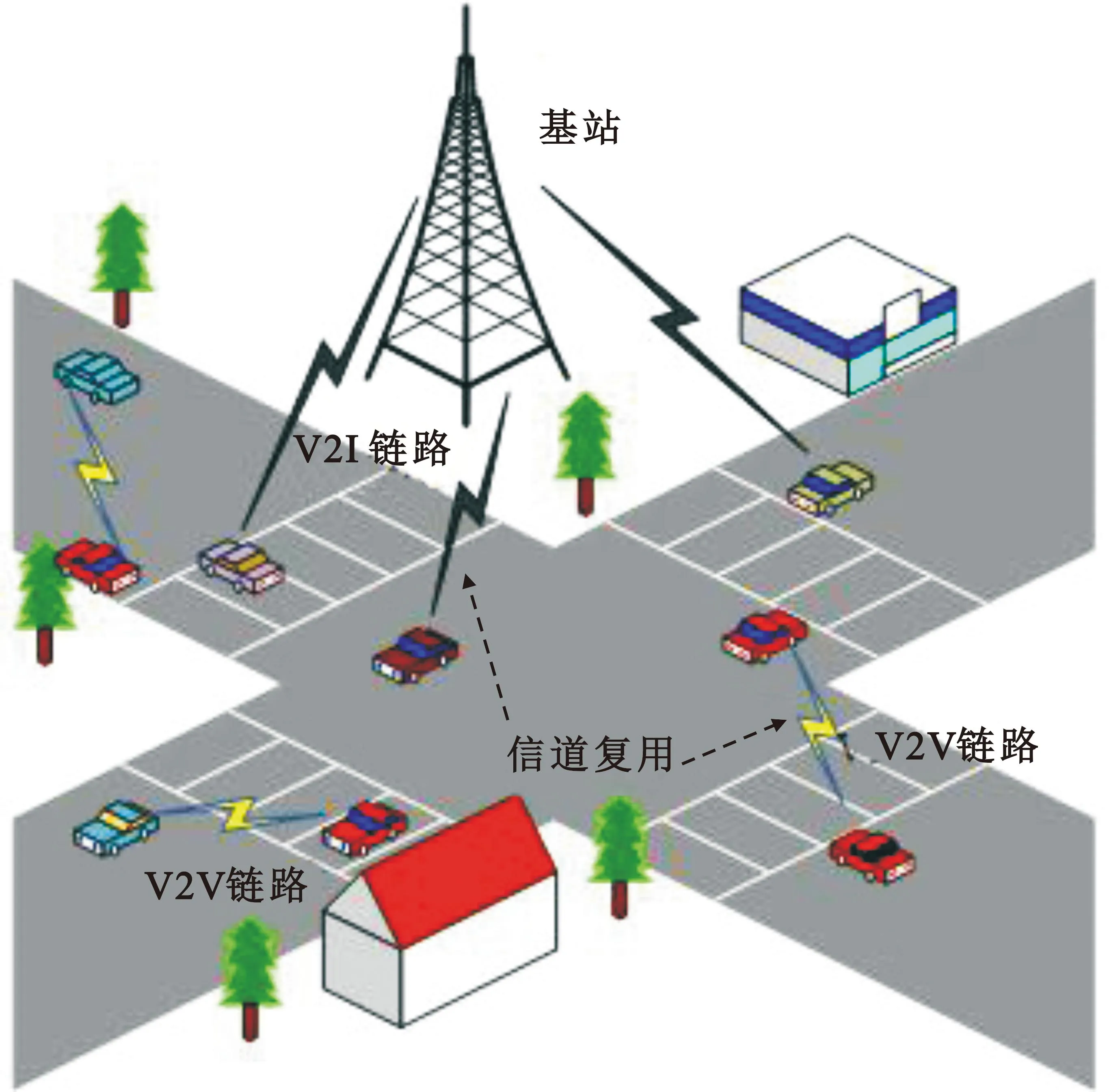
图1 车联网系统模型[13]
因此如何设计一种快速稳定的算法完成这种信道资源稀少的场景下的信道分配问题,且能最大程度上降低信道冲突,提高V2V链路复用V2I链路信道资源的利用率是研究的重中之重。假设V2I链路被分配的正交信道数集合为C*={1,2,3,…,C},而V2V链路的数量集合表示为N*={1,2,3,…,N},当复用上行链路资源时,在每个时隙V2V链路都可以任意选择V2I链路的信道,且可以动态的选择继续留在该信道还是切换信道发送信息。因此,为实现V2V链路在共享V2I链路过程中最大化网络效用,尽可能降低信道冲突,就必须考虑各V2V链路之间的信道碰撞率,以及信道空闲率。
1.2 信道碰撞率
定义k为时隙t下第c条V2I链路中选择复用此信道传输信息的V2V链路的数量,规定仅仅只能存在单条V2V链路选择复用第c条V2I的信道时信息才能够发送成功,当有两条及两条以上的V2V链路共同选择复用同一条V2I链路时,就定义为产生了信道的碰撞,信息必定传输失败,此时的碰撞次数就为1,如式(1)所示:
(1)
因此,将i次信息传输过程中C条V2I链路信道中产生的碰撞总次数与这i次传输中的总信道数的比值,定义为这i次传输中的信道碰撞概率μ,如式(2)所示:
(2)
1.3 信道空闲率
定义φ为信道空闲率来间接表示V2I链路信道的利用情况。当n条V2V链路都进行了信道的共享策略后,第c个信道中的剩余容量γc如式(3)所示。规定当第c条V2I信道被占用且V2V链路成功发送了信息,那么该信道的剩余容量γc就为0;如果该条信道上,发生了多条V2V链路的竞争,造成了通信失败,此信道就没有被利用,其剩余容量γc为1;当然,如果某条信道没有被V2V用户选择共享,其信道剩余容量γc自然也为1。
(3)
规定将i次信息传输过程中C条V2I链路信道的剩余容量γc之和与这i次传输过程中的总信道数的比值,表示该回合信道空闲率,如式(4)所示:
(4)
可见,信道空闲率与碰撞率呈正相关关系,信道空闲率的降低,也间接表明了碰撞率的降低和信道利用率的提升。因此,本文提出的算法将围绕这两个优化指标来进行设计和实现。
2 本文提出的算法
2.1 深度强化学习算法框架
本文的车联网信道分配场景中,由于真实环境信息是未知的、高维复杂的,因此,将信道资源分配问题建模为深度强化学习问题,提出一种基于GRU-LSTM组合网络模型的深度双重Q学习算法框架(Hybrid GRU-LSTM DDQN,HG-LDDQN),算法结构如图2所示。

图2 HG-LDDQN算法结构框图
HG-LDDQN算法与环境交互模型如图3所示。算法模型采用集中训练、分布式执行的方式,将每条V2V链路作为智能体与环境进行交互,接收环境观察结果O(t),以得到环境中在t时隙下的状态信息S(t);将t时隙下的状态S(t)送入GRU-LSTM组合神经网络模型中进行训练,得到Q函数的值Q(s,a)。然后,依据Q值智能体得到下一步所要进行的动作A(t),并且在同一种奖励评判机制下,每条V2V链路单独获得回报Rn(t),继而反复探索训练,更新GRU-LSTM组合网络。最后,通过迭代学习最大化每回合的平均奖励,来改善信道分配策略。
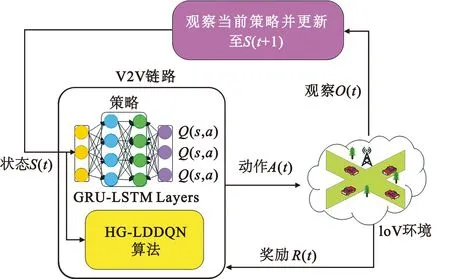
图3 HG-LDDQN算法与环境交互模型
下面对HG-LDDQN算法与环境交互模型中的几个深度强化学习要素分别进行阐述。
1) 状态空间
在算法模型中,t时隙下的状态空间S(t)是通过V2V链路对环境进行观察O(t)后得到的,其包含三部分,即V2V链路作为智能体的动作a(t)、当前每个信道的剩余容量δ(t)以及确认字符信号(Acknowledge character,ACK)的返回结果η(t)。
如果V2V链路用户已经在t时隙选择了第c条信道(1≤c≤C)进行数据传输,那么将该条信道状态ac(t)设置成1,剩余的信道状态设置成0。a(t)如式(5)所示:
a(t)={a1(t),a2(t),…,ac(t)}
(5)
此外,在时隙t对于当前C个信道中的第c个信道按式(3)中定义的单条V2I信道的剩余容量γc的计算方法,计算此刻所有V2I链路信道的剩余容量δ(t),如式(6)所示:
δ(t)={γ1,γ2,…,γc}
(6)
假设在时隙t完成信道共享后,V2V链路间发送数据包的同时也会给对方发送一条ACK信号,如果数据传输成功就返回一个数值为1的ACK信号,传输失败,则返回的ACK信号为0。ACK信号返回结果η(t)如式(7)所示:
(7)
由此,构成了在时隙t下的状态空间S(t),如式(8)所示:
S(t)={a(t),δ(t),η(t)}
(8)
2)动作空间
根据可选信道c,n条V2V链路在t时隙的可选动作空间A(t)由式(9)定义为
A(t)∈{0,1,2,3,…,c}
(9)
即每条V2V链路都可以选择此时刻网络空间中的任一V2I链路的信道。当t时刻下第n条V2V链路的动作值an(t)=0时,代表该条V2V链路在t时刻下选择不接入V2I的信道。
3)奖励值设定
在t时隙下,第n条V2V链路成功发送信息后,根据V2V的接收方返回的ACK信号状态,对该次动作an(t)的选择给予一个奖励值Rn(t)。如果返回ACK信号为1,说明数据信息发送成功,即表明V2V链路合理地复用了V2I的信道,同时避免了信道的冲突,给予该次动作an(t)数值为1的正向奖励;反之,不给予奖励。因此,将t时隙下第n条V2V链路的动作an(t)的奖励值Rn(t)定义为
(10)
2.2 基于GRU-LSTM组合网络模型的深度双重Q学习算法
根据前述的强化学习的基本要素,对本文提出的算法结构进行分块阐述。
2.2.1 输入层
在本算法中,每条V2V链路都被看作是一个智能体,智能体观察并采集t时刻下的每个V2V链路的状态值St∈{S1,S2,S3,…,Sm}作为GRU-LSTM组合网络的输入。当V2V链路在状态St执行动作a(t),根据环境返回的η(t)获得一个奖励R(t)后,就转移至下一个状态St+1。
2.2.2 GRU-LSTM组合神经网络层
由于车联网的高移动性和网络拓扑的快速变化,经典的DNN无法学习到前后联系的历史序列,同时循环神经网络(Recurrent Neural Network,RNN)存在梯度消失和梯度爆炸以及可能过拟合的缺陷,因此,本算法使用GRU-LSTM组合神经网络模型。该组合神经网络模型的网络结构有3层。第一层采用 GRU,它将LSTM中的遗忘门和输入门合并为一个“更新门”,减小了矩阵乘法,更容易使算法收敛,可以减少训练时间[12]。但 GRU的拟合精度不如多参数的 LSTM,并且双层 LSTM 的精度要优于单层 LSTM[13]。因此,模型的第二层和第三层结构均采用LSTM。下面对该组合层进行分层介绍。
第一层神经网络由多个GRU单元组成。对于每个GRU单元,如图4所示,Zt为当前时刻的输入,Yt-1为上一个时刻的输出,Yt为当前时刻的输出。

图4 GRU单元结构图[10]
GRU有两个门,第一个门为更新门vt,决定了有多少历史信息可以继续传递给未来。更新门vt的计算方法如公式(11)所示[8]:
vt=σ(Wv·[Yt-1,Zt]+bv)
(11)
式中:Wv为更新门的权重矩阵;bv为偏差向量;σ表示激活函数 sigmoid。
第二个门为重置门rt,主要功能是确定有多少历史信息不能传递到下一个状态。重置门rt的计算方法如公式(12)所示[8]:
rt=σ(Wr·[Yt-1,Zt]+br)
(12)
式中:Wr为重置门的权重矩阵;br为偏差向量。
计算出更新门vt和重置门rt后,GRU将会计算候选隐藏状态ht。候选隐藏状态ht的计算方法如公式(13)所示[8]:
ht=tanh(Wh·[rt·Yt-1,Zt]+bh)
(13)
式中:Wh为对应的权重参数;bh为对应的偏差参数;tanh代表双曲正切函数。
最后t时刻 GRU 的输出Yt的计算方法如公式(14)所示[8]:
Yt=(1-vt)·Yt-1+vt·ht
(14)
在GRU网络层输出后第二层和第三层是LSTM网络层,对比于RNN和GRU,LSTM 模型的拟合精度总体更高,如图5所示。

图5 LSTM单元结构[10]
LSTM有3个门,如图5所示,Ct-1为前一时刻神经元的状态,Ut-1为前一时刻神经元的输出,Nt为当前时刻的输入,Ct为当前时刻神经元的状态,Ut为当前时刻神经元的输出。以下是每个LSTM单元的前向传播公式:
ft=σ(Wf·[Ut-1,Nt]+bf)
(15)
式中:Wf是遗忘门的权重矩阵;bf是偏差向量;ft表示最后一层神经元被遗忘的概率[8]。
it=σ(Wi·[Ut-1,Nt]+bi)
(16)
式中:Wi是输入门的权重矩阵;bi是偏差向量;it表示当前需要保留的负载信息的比例[8]。
pt=tanh(Wc·[Ut-1,Nt]+bc)
(17)
式中:Wc是输入门的权重矩阵;bc是偏差向量;pt是当前需要保留的负载信息的比例[8]。
Ct=ft·Ct-1+it·pt
(18)
ot=σ(Wo·[Ut-1,Nt]+bo)
(19)
式(19)中:Wo为输出门的权重矩阵;bo为偏差向量;ot为输出门[8]。
Ut=ot·tanh(Ct)
(20)
此处,LSTM层的输入就是GRU网络层的输出Yt。显然,此组合网络的数据更新过程比单纯的LSTM更简洁,也比单纯的GRU 网络拟合Q值过程更具有精确性和稳定性。
在组合神经网络中,使用Huber损失函数来计算算法训练时的目标值Y以及估计值f(x)之间的差值。Huber损失是平方损失和绝对损失的综合,它克服了平方损失和绝对损失的缺点,不仅使损失函数具有连续的导数,而且利用均方误差(Mean Square Error,MSE)梯度随误差减小的特性,可取得更精确的最小值,也对异常点更加鲁棒,可以提高算法的稳定性[14]。Huber损失计算方法如式(21)所示[14]:
(21)
式中:δ为选择超参数,作为选择MSE与MAE时的评判值,由反复实验确定。
2.2.3 输出层
为解决算法训练中的过度估计问题,使用DDQN来解耦目标Q值动作的选择和目标Q值的计算[15]。具体而言,使用两个深度组合模型Q网络,Q1网络用于选择动作an(t),Q2网络用于估计与所选动作相关联的Q值。DDQN中的Q值的近似估算公式如式(22)所示[15]:
(22)
将提出的HG-LDDQN算法为所有V2V链路进行训练,训练步骤如下:
1 初始化:迭代轮数T,V2I链路条数 C,V2V链路条数N,步长α,衰减因子γ,探索率ε,经验回放池D,当前GRU-LSTM net1的参数ω,目标 GRU-LSTM net2的参数ω′=ω,所有状态和动作对应的价值Q
2 For iterationi=1,…,Ido
3 For episodem=1,…,Mdo
4 For time-slott=1,…,Tdo
5 For V2V linksn=1,…,Ndo
6 从环境中观察得到状态值Xn(t),输入到GRU-LSTM net1,产生对应所有可选的动作a∈{0,1,2,…C}的估计Q值Q(a)
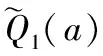
9 在经验回放池中存储
10 从经验回放池中随机抽取批量样本训练组合神经网络
11 计算当前的目标Q值:
12 计算目标Q值与估计Q值的
Huber loss与网络权重ω
13 End for
14 End for
15 End for
16 使用状态输入Xn(t)和输出Qs训练GRU-LSTM net1
17 每一个iteration使Q2←Q1
18 End for
3 实验与结果分析
仿真场景为位于十字路口道路的双向和单向车道区域,其宽为300 m,长为 400 m。场景中车辆起始位置和行驶方向在区域范围内随机初始化,在该范围内规定有2条V2I链路、3条V2V链路以及1个基站。在该场景模型中,使用HG-LDDQN算法实现3条V2V链路共享V2I链路的2个信道条件的尝试,分别在信道碰撞率、信道空闲率以及平均奖励和平均成功率4个评价指标上与其他信道分配算法对比,以验证HG-LDDQN算法的性能。
实验中构建图2中的GRU-LSTM组合神经网络,GRU层和两层LSTM均设置128个神经元。Huber损失函数的超参数δ经过大量实验设置为1.35。实验每次输入t-5个时刻的状态序列,使用Adam算法优化网络权重ω,经验池D的容量设置为1 000,探索率ε设置为0.02,探索率的衰减率设置为0.000 1,学习率设置为0.01,奖励折扣设置为0.9,干扰设置成0.1,模拟退火常数设置为1。
3.1 信道碰撞率对比
图6表示在55 000次的迭代中,3条V2V链路在动态共享2条V2I链路的信道时的碰撞率的变化情况,每5 000次作为一个回合,对数据结果进行一次记录。从图中可见,没有历史序列前后记忆功能的DQN算法在处理这种历史序列的学习任务时几乎没有学习能力,碰撞率很大,而对于单一循环网络算法而言,GRU+DDQN算法由于具有比LSTM+DDQN更为简单的结构,其学习迭代的更快。但这两种算法最后的收敛表现差不多,在第10个训练回合时收敛到0.27左右。相较而言,HG-LDDQN算法由于使用了GRU-LSTM混合网络模型,兼具GRU和LSTM网络单元的双重性能,能将GRU网络单元结构简单、训练快速的优势运用到V2V链路的训练中,当训练达到第4个回合时碰撞率就以最大的下降速度降低,使V2V链路之间的碰撞次数迅速减少,同时又因为LSTM网络单元中的多参数能带来更加精确的拟合精度,使得HG-LDDQN算法不仅提前5个训练回合完成收敛,又能够将碰撞率维持在比其他算法训练结果更低的0.006附近。
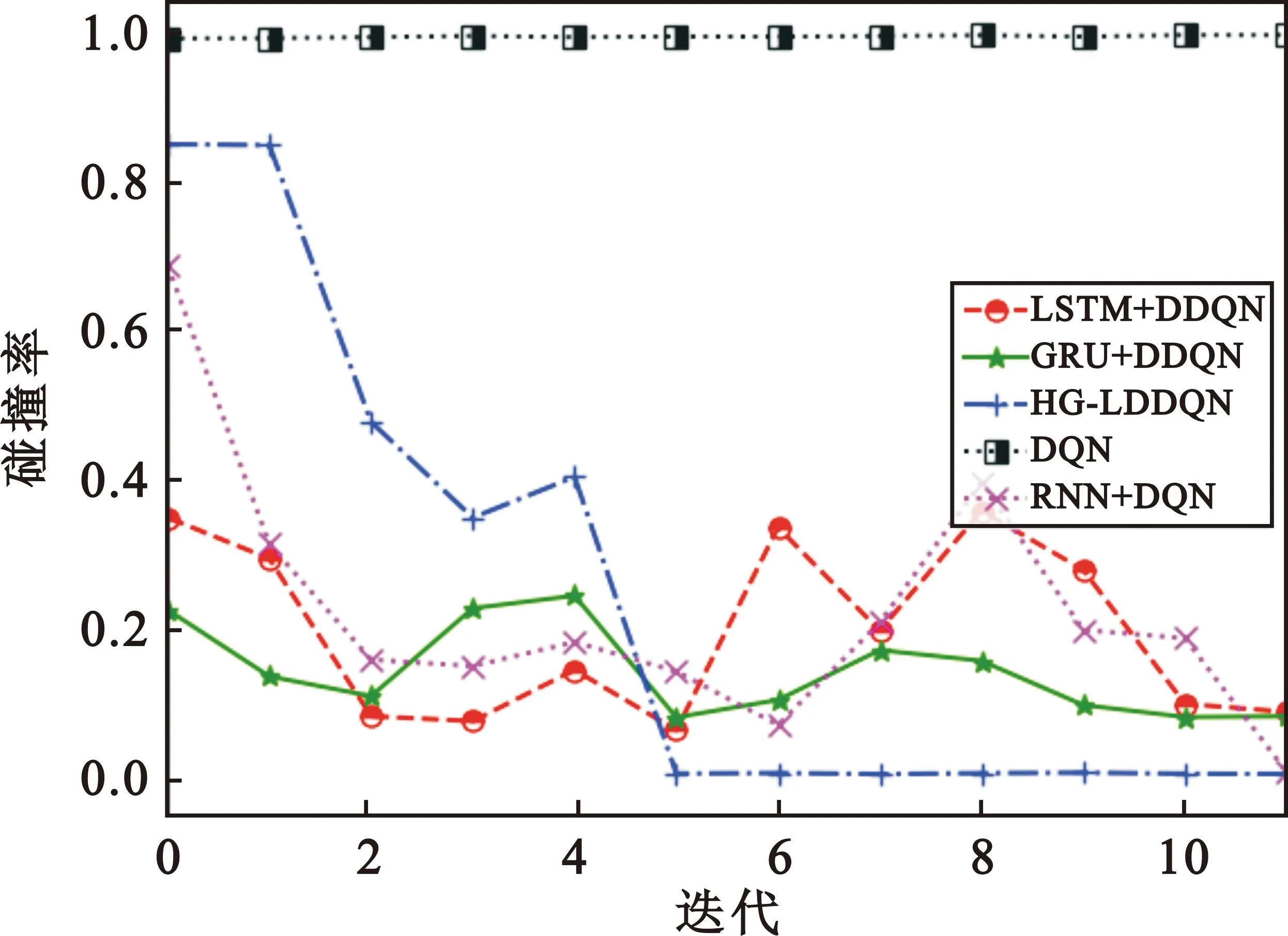
图6 3条V2V链路共享2条V2I链路信道时的碰撞率
3.2 平均奖励对比
图7为3条V2V链路共享2条V2I链路信道时的平均奖励的对比,可见HG-LDDQN算法凭借GRU-LSTM组合网络中GRU网络单元的简单结构,使V2V链路能够在第4个回合以后快速学习获得奖励,又可以凭借组合网络中LSTM网络单元的多参数拟合精确的特点,使V2V链路在第5个回合后几乎每次都能成功共享V2I链路的2条信道,完成信息成功发送,学习到了比其他算法更优的信道分配策略。本文算法比RNN+DQN算法提前约6个训练回合收敛,而GRU+DDQN和LSTM+ DDQN算法由于单一的网络结构无法在整体性能上表现出组合优势,导致在整体的算法性能上不如HG-LDDQN算法高效和稳定,最终的平均奖励值只能收敛到1.8附近,甚至不如传统的RNN+DQN算法。DQN算法还是因为使用DNN的原因,处于一种无法学习的状态,几乎不能获得奖励。
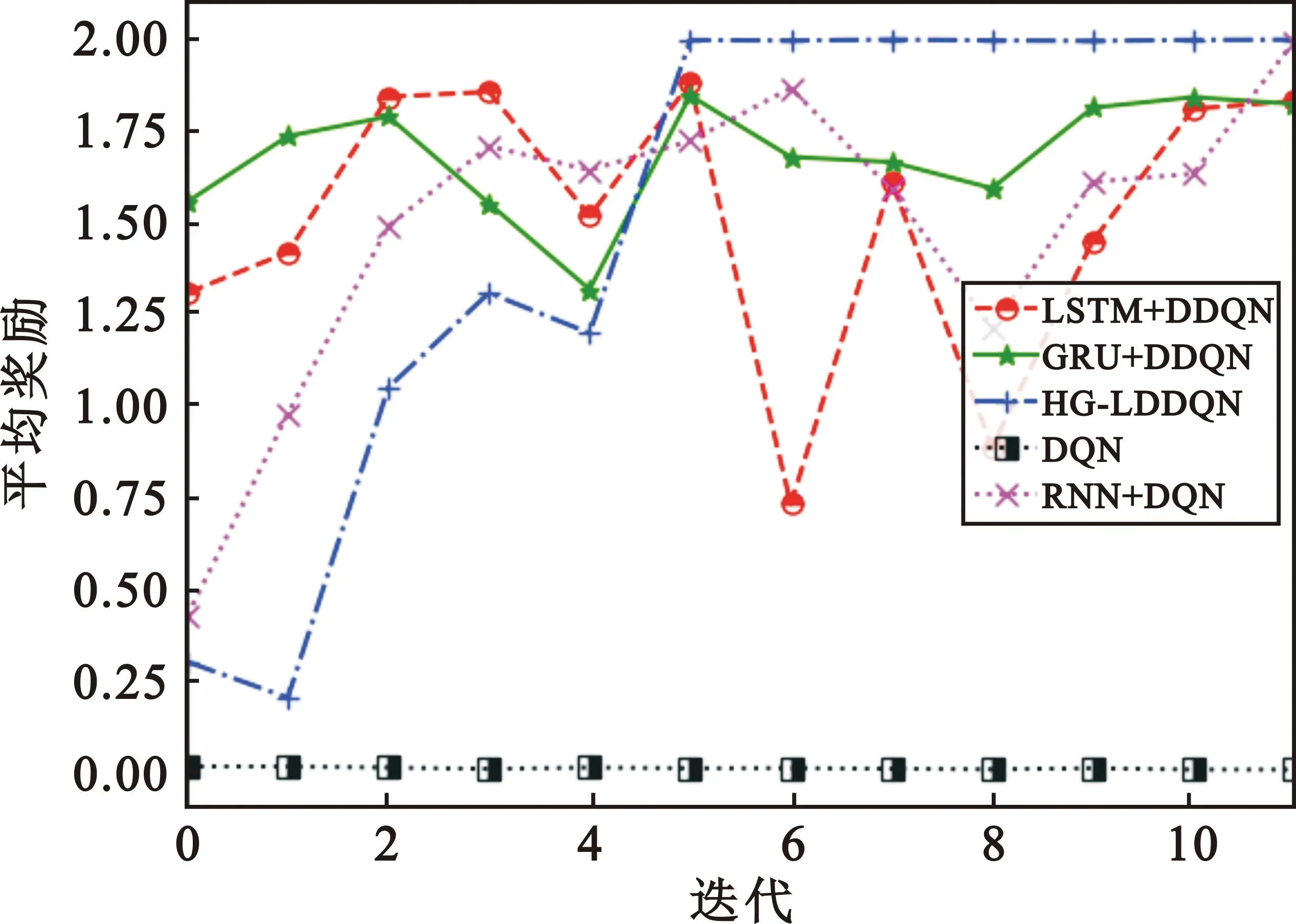
图7 3条V2V链路共享2条V2I链路信道时的平均奖励
3.3 信道空闲率对比
图8为3条V2V链路共享2条V2I链路的信道时的空闲率的对比。由于建模时允许某些V2V链路可以选择不发送信息,即不选择信道接入,因此该图与碰撞率的图有些许的差别。显而易见HG-LDDQN算法由于组合网络模型结构带来的双重优势,在收敛速度上比LSTM+DDQN或者GRU+DDQN算法快5个训练回合,比RNN+DQN快6个训练回合。在收敛后的空闲率上,随着迭代次数的增加,HG-LDDQN算法能使信道空闲率稳定在较低的水准,使V2I的2条信道基本都有V2V链路成功的共享,相较于单一网络结构的LSTM+DDQN或者GRU+DDQN算法下降了约27%。DQN算法同样由于网络结构的原因,不具备学习历史序列数据的能力。RNN+DQN算法下,信道的空闲率呈现出上下振荡的不稳定性,以及收敛速度慢的情况。
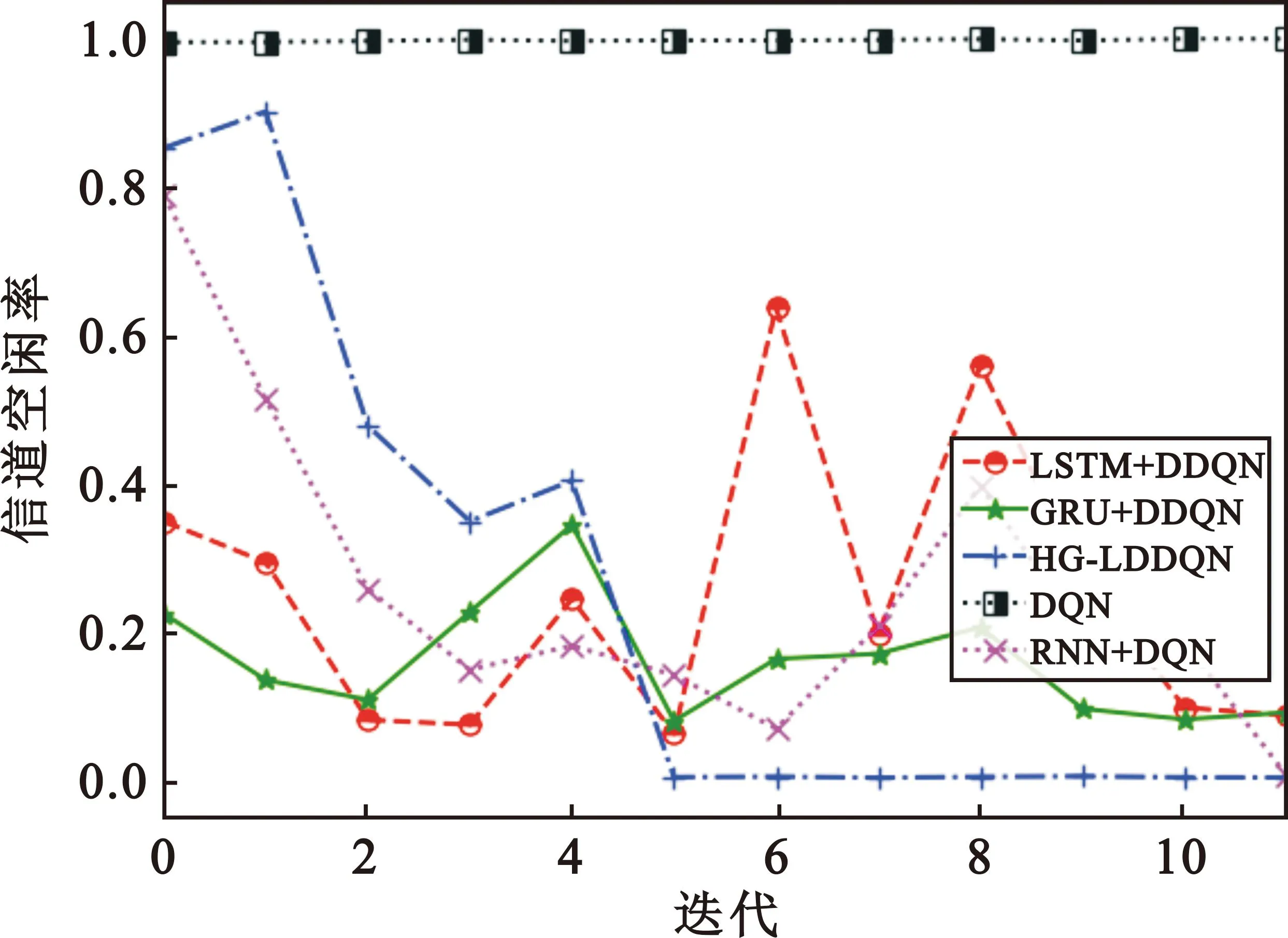
图8 3条V2V链路共享2条V2I链路信道时的信道空闲率
3.4 平均成功率的对比
图9表示3条V2V链路尝试共享2条V2I链路的信道的过程中的平均成功率情况。由于奖励函数的设计是每次对于V2V链路成功共享到V2I链路信道,并完成信息传输的动作选择就设置奖励值就加1,发生碰撞信道共享失败,奖励值就为0。因此,每一个回合内的累计的成功共享次数与该回合内的累计奖励值是一致的,可以看到平均化后的成功率折线图是和奖励图的趋势是一致的。从图中仍然可以发现,HG-LDDQN算法具有明显优势,能够快速完成收敛,使平均成功率达到了接近1的效果,比GRU+DDQN和LSTM+DDQN算法下的平均成功率提高了约10%,能够保证在之后的每个时隙中V2I的2个信道中都有V2V链路成功进行了共享且完成了信息传输。
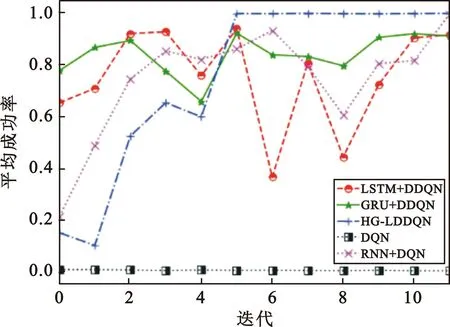
图9 3条V2V链路共享2条V2I链路信道时的平均成功率
4 结束语
本文研究了针对车联网中V2V链路复用V2I链路信道时的信道冲突以及网络效用低下的问题,提出了一种基于GRU和LSTM组合模型的动态信道分配算法。该算法以最大化每回合平均奖励为目标训练V2V链路,不需要在线协调,可实现多个V2V链路通过实时探知环境状态,选择V2I链路未使用的空闲频谱以完成V2V链路自身信息的传输任务,同时解决了大状态空间下V2V链路用户随着车联网节点拓扑结构变化带来的训练困难、训练周期长的问题。仿真实验结果表明,该算法能使V2V链路作为智能体在与环境不断交互过程中学习到合理的信道共享策略,有效地解决了快速变化的车联网环境中的信道分配问题,同时减少了V2V链路用户的信道碰撞率以及空闲率,间接最大化了V2V链路复用V2I链路信道资源的利用率。
后续将会在本文的基础上对V2I以及V2V链路的频谱资源分配进行信道及功率的联合优化研究。
