基于元强化学习的自适应卸载方法*
2024-02-28郑会吉余思聪邱鑫源崔翛龙
郑会吉,余思聪,邱鑫源,崔翛龙
(武警工程大学 a.信息工程学院;b.反恐指挥信息工程联合实验室,西安 710086)
0 引 言
近年来,随着新的计算和通信技术快速发展,增强现实、无人驾驶以及移动医疗等创新型移动应用和服务日益涌现。这些移动应用对计算和存储资源具有大量需求,从而在云和终端用户之间产生较大的网络流量,给传输链路造成沉重负担,影响服务传输时延。新兴的移动边缘计算技术[1]为解决这一问题提供了一种解决方法,其核心思想是将云计算的强大能力扩展至靠近终端用户一侧,以缓解网络拥塞和降低服务时延。
计算卸载是移动边缘计算中的一项关键技术,它能将移动应用的密集型计算任务从终端用户卸载到合适的边缘服务器。一般来说,计算卸载和资源分配共同构成一个混合整数非线性规划问题,是一种NP-hard问题[2],现有的许多方法都是基于启发式或近似算法[3-5],但对于移动边缘网络,这些方法都十分依赖先验知识和精确的模型,当环境发生变化时,则需要对应地去更新先验知识和模型。因此,特定的启发式或近似算法很难完全适应动态的移动边缘环境。
深度强化学习(Deep Reinforcement Learning,DRL)将强化学习和深度神经网络相结合,通过试错学习来解决游戏、机器人等复杂问题。深度强化学习在各种任务卸载问题中的应用也被越来越多研究者关注,将终端用户、无线信道以及边缘服务器看作环境,通过与环境的交互学习卸载策略。此过程通常被建模为一个马尔可夫决策过程(Markov Decision Process,MDP),主要元素包括(S,A,R,γ),分别表示环境的状态、智能体执行的动作、环境反馈的奖励以及折扣因子。文献[6-12]提出的算法由于样本效率比较低,需要进行充分的二次训练以更新策略,因此比较耗时[13]。
元学习是以一种系统的、数据驱动的方式从先前经验中去学习。收集描述先前学习模型的元数据,然后从元数据中学习,以提取和传递用于指导搜索用在新任务上的最佳模型的知识。本文中,元学习通过对不同任务场景先训练一个通用元策略,明显加快新策略的学习。同时,结合强化学习,元强化学习通过借鉴历史任务,与环境的少量交互中学习新策略。基于此,本文提出一种基于元强化学习的自适应卸载模型,将卸载过程建模为一个马尔可夫决策过程(Markov Decision Process,MDP)。该模型包含两个子模型,一个外部模型利用历史任务数据训练得到元策略;基于元策略,内部模型通过少量梯度更新快速学习新策略,适应新环境[14]。
1 系统模型
图1所示为本文的移动边缘场景,由边缘服务器和N个移动终端组成,表示为N={1,2,…,N}。每个移动终端在时间t时刻需要处理计算任务,不同任务权重值不同。计算任务遵循二值卸载策略,即移动终端要么在本地执行,要么将任务卸载到边缘服务器执行。假设边缘服务器的计算能力远大于移动终端,定义t时刻的计算策略为xt={xn(t)∈{0,1}|n∈N},xn(t)=0表示本地计算,反之表示卸载计算。
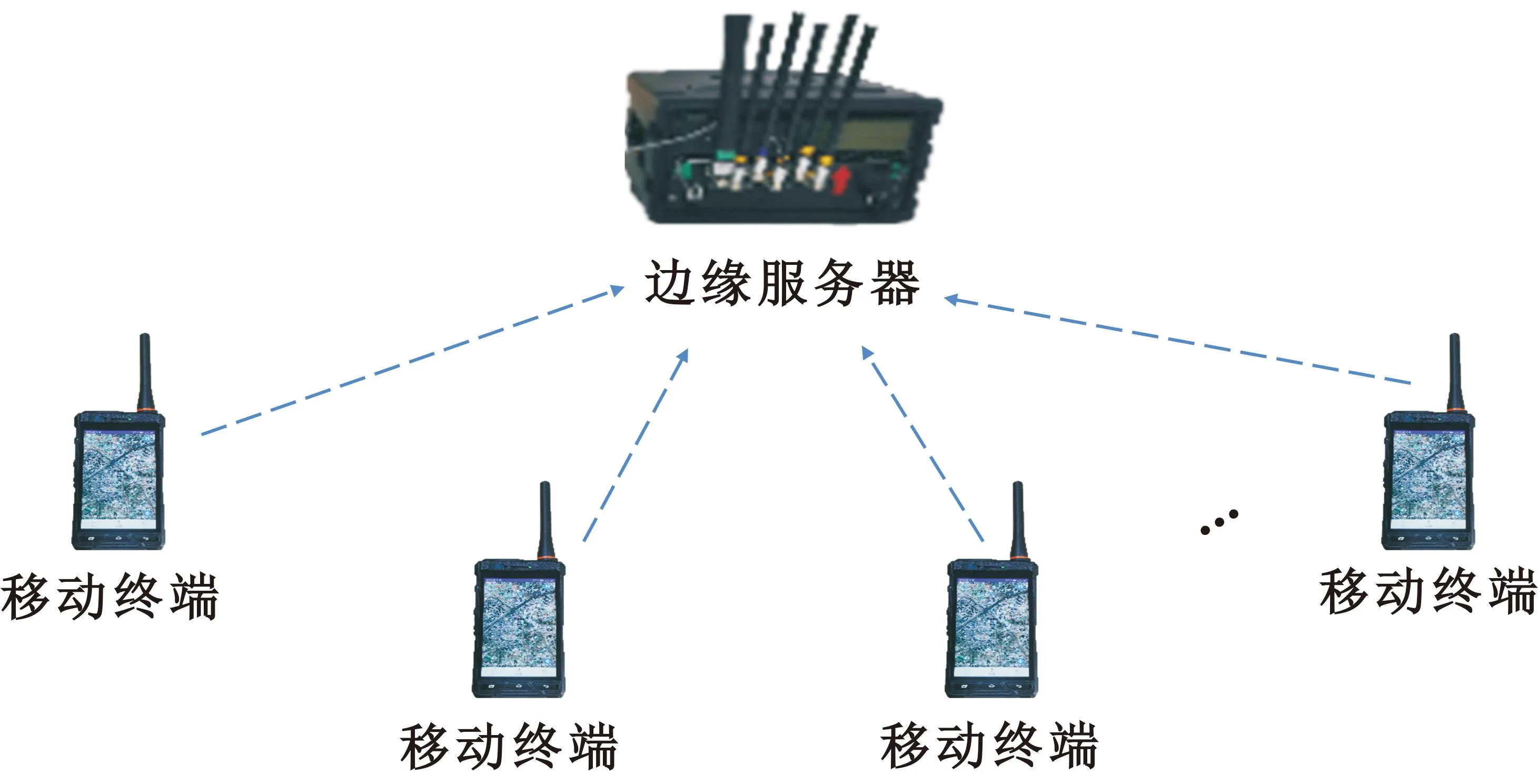
图1 移动边缘场景
1.1 时延模型
主要研究移动边缘网络中考虑时变无线信道因素的时延优化问题。计算任务表示为一个列表taskn=[in,on,ζn],分别表示数据大小、回传结果大小以及完成任务所需的CPU周期数。移动终端n和边缘服务器之间传输速率为
(1)
式中:Bn是传输信道带宽;Pn是传输功率;ω0是环境噪声功率;hn(t)∈ht是对应的信道增益。则移动终端n的总通信时延为
(2)
边缘服务器和移动终端的CPU周期数分别为fe和f0,根据前面的假设,满足f0≪fe。因此,边缘服务器的处理时延为
(3)
同理,移动终端本地执行的时延为
(4)
则移动终端n的时延为
(5)
移动边缘网络的加权时延和为
(6)
式中:wn(t)表示移动终端n的权重。
1.2 问题描述
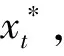
(7)
2 基于元强化学习的自适应卸载算法
MRL利用移动终端和边缘服务器的计算资源进行训练。训练包括两个模型:一个是针对具体任务的内部模型;另一个是针对元策略的外部模型。内部模型在移动终端训练(内部模型往往只需较少训练步骤和训练数据,因此假设移动终端能支持训练);外部模型在边缘服务器上训练。
MRL的详细训练过程如图2所示,包括4个步骤:第一步,移动终端从边缘服务器下载元策略;第二步,移动终端基于元策略和本地数据训练内部模型,以获得特定任务策略;第三步,移动终端将特定任务策略的参数上传到边缘服务器;第四步,边缘服务器根据接收到的参数训练外部模型,生成新的元策略,并开始新一轮训练。
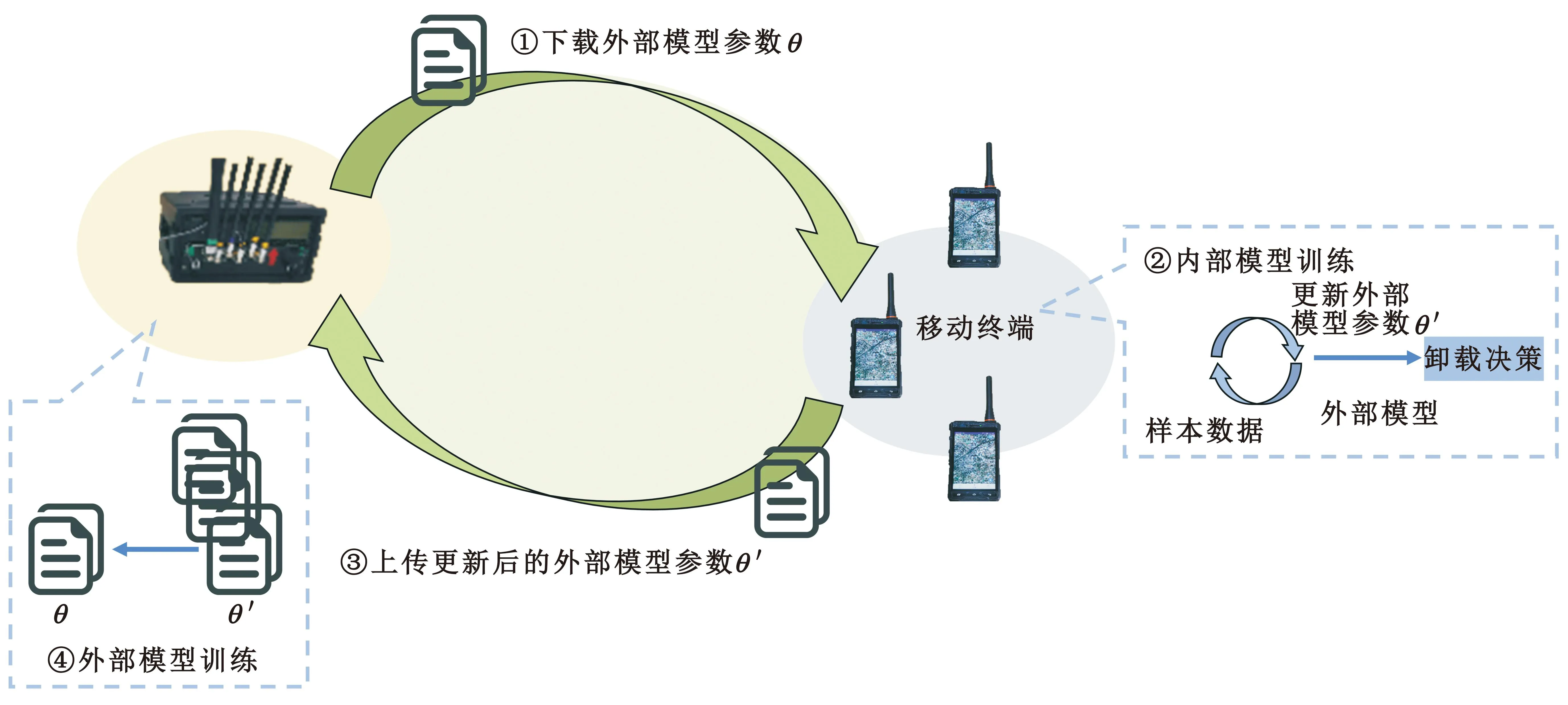
图2 MRL训练过程
2.1 MDP建模
将计算卸载过程建模为一个MDP过程,其基本要素包括:
1)状态空间:环境的状态是t时刻信道增益,则状态空间表示为state={ht};
2)动作空间:由于采用二值卸载模式,因此动作空间表示为action={0,1};
3)奖励函数:若动作为最优解的动作值,奖励为最小优化函数值的相反数,反之为最大优化函数值的相反数。
MRL采用AC(Actor-Critic)算法,其中包括actor和critic两个模块。actor模块会根据输入产生卸载动作,而critic则会对产生的动作进行评价打分,最后输出打分最高的卸载动作。
2.2 内部模型
训练集包含Ω个不同任务场景I={ψi|i=1,2,…,Ω},一个任务场景包含K个样本数据,表示为ψ={(hk,xk)|k∈K}。采用强化学习方法对元策略进行训练,算法具体如下:
输入:样本数据(hi,xi)
1 从边缘服务器下载元策略,初始化参数θi=θ
2 设定迭代数M
3 fori∈{1,2,…,M}do:
4 从I中采样样本数据Ib
5 forψi∈Ibdo:
6 从ψi中采样样本数据Di
7 输入无线信道增益hi
8 利用保序量化算法产生φ个卸载动作{xi}
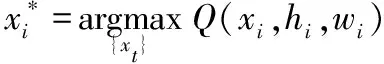


14 end
16 end

(8)
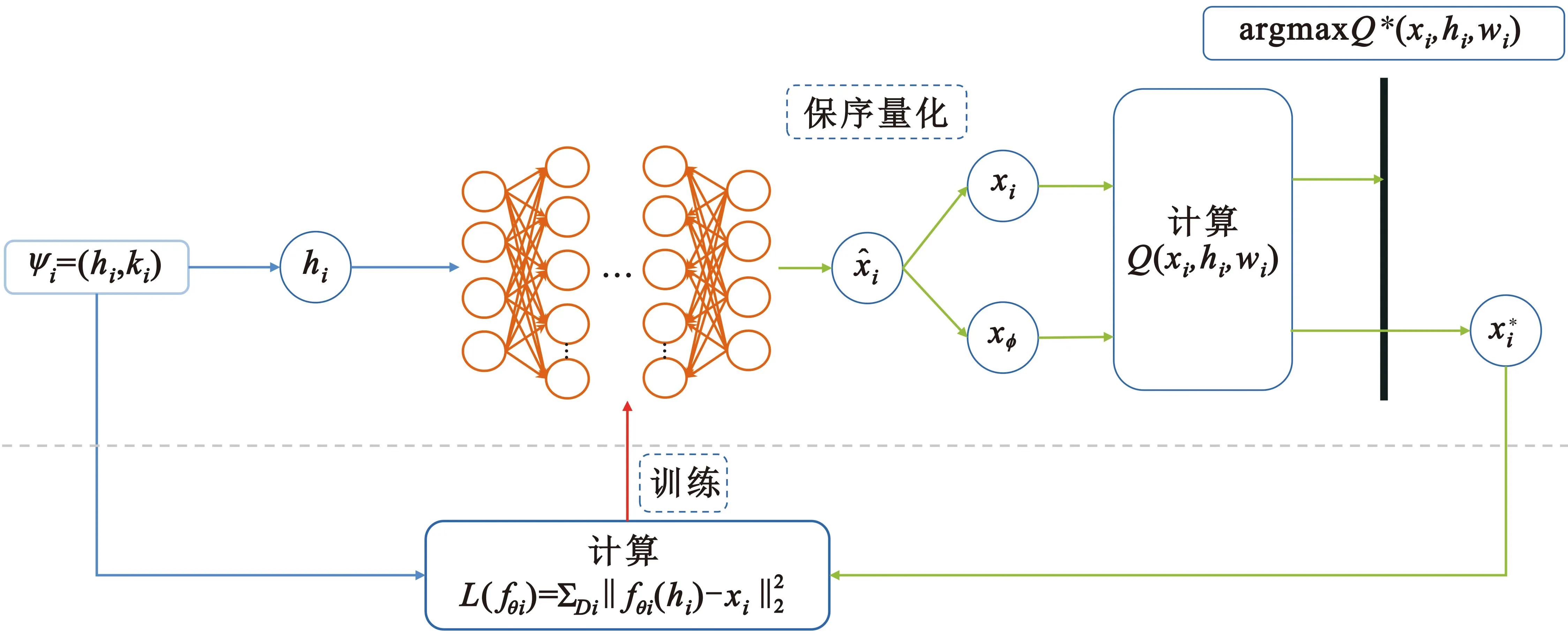
图3 内部模型
式中:fθi是内部模型的函数。最后,通过梯度下降的方法对模型的参数进行更新,即
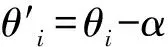
(9)
式中:α是一种超参数。
2.3 外部模型
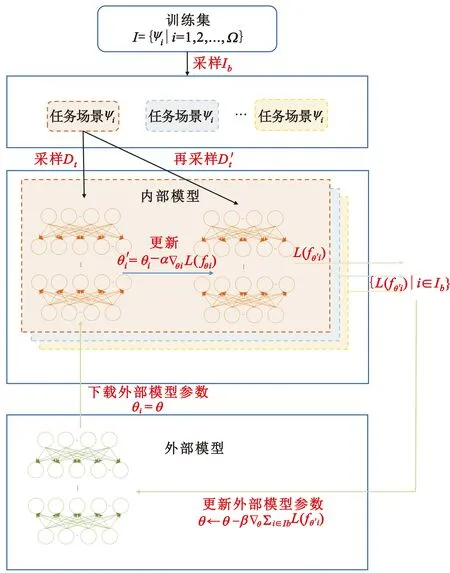
图4 外部模型
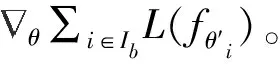
(10)
式中:β是步长。基于更新的外部模型,将采样下一批任务场景训练直至收敛。
3 仿真实验
3.1 参数设置
本文通过Python编程语言进行实验仿真,实验运行在Intel Core i7-9700H 3.6 GHz CPU,内存8 GB的服务器上,虚拟环境采用框架Tensorflow-gpu 2.3。假设所有移动终端随机分布在指定区域,服从概率为3×10-4的泊松分布,其计算所需的计算周期与输入大小有关,表示为γn=165 cycle[16]与边缘服务器之间的信道功率增益服从路径损耗模型H[dB]=103.8+20.9lgd[km],d表示移动终端与服务器之间的距离。部分实验参数如表1所示。

表1 实验参数
3.2 参数分析
图5给出了MRL在不同参数下的收敛性能,包括学习率、内存大小和批量大小。图5(a)为学习率在Adam优化器中的影响,从中容易得出,过大的学习率(0.1)会导致算法难以收敛,过小的学习率(0.001)收敛速度较慢,所以,在仿真实验中,将学习率设置为0.01。在图5(b)中,较小的内存(512 B)导致在收敛上较大的波动,但较大的内存(2 048 B )需要更多的训练数据收敛至最优,因此将内存大小设置为1 024 B。如图5(c)所示,较小的批量(64)并没有充分利用保存在内存中的训练数据,但较大的批量(512)则会频繁采样旧的数据从而降低收敛性能,因此,将批量大小设置为128。

(a) 学习率
3.3 性能分析
在图6中,横坐标为微调步数,纵坐标为归一化计算速率(它是枚举的最优卸载策略和评估策略之间的比值)。为更好说明MRL的性能,将一般强化学习算法RL[13]作为对比,可以看到,在MRL中,内部模型的参数是从预训练的外部模型复制而来,它能在20步微调内适应新的任务场景,并使归一化计算速率达到0.99以上;相反,一般的强化学习算法则需要更多的步数来收敛,这说明了MRL能更快更高效地适应新任务场景。
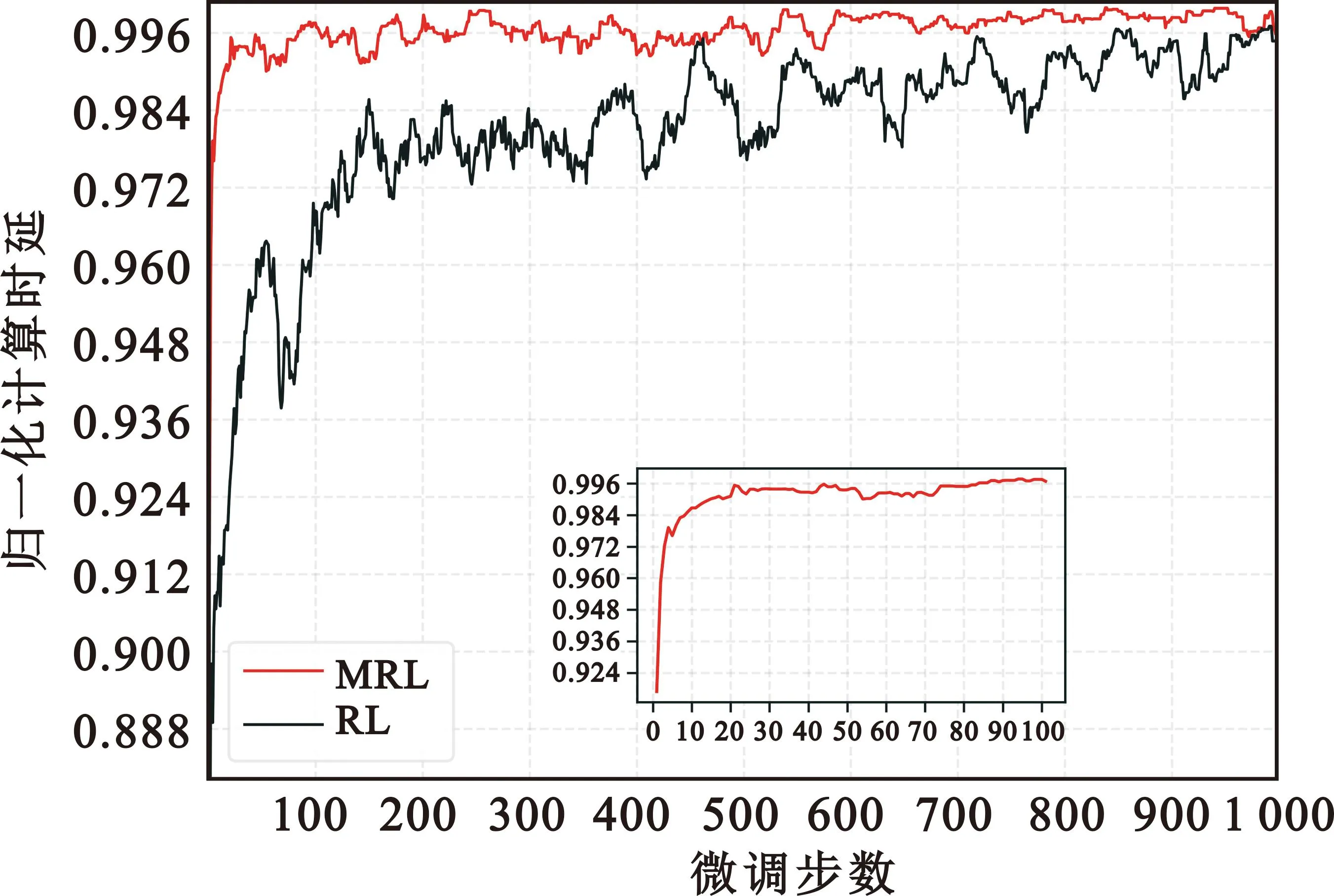
图6 MRL算法的性能
图7给出了3个不同任务场景ψ1,ψ2和ψ3下的MRL。一旦任务场景变换,例如从场景ψ1变到ψ2,借助外部模型快速训练一个新的内部模型。如图7所示,MRL快速适应新的场景,并在100步微调都能达到归一化计算速率超过0.99。同时,如图8所示,对比不同算法下3个场景的平均时延可以看出,MRL相比一般的RL、贪婪算法以及深度神经网络[17](Deep Neural Network,DNN)具有最优的性能。
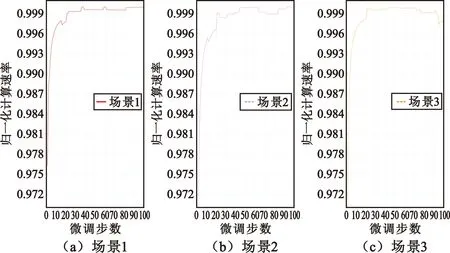
图7 动态场景下的MRL
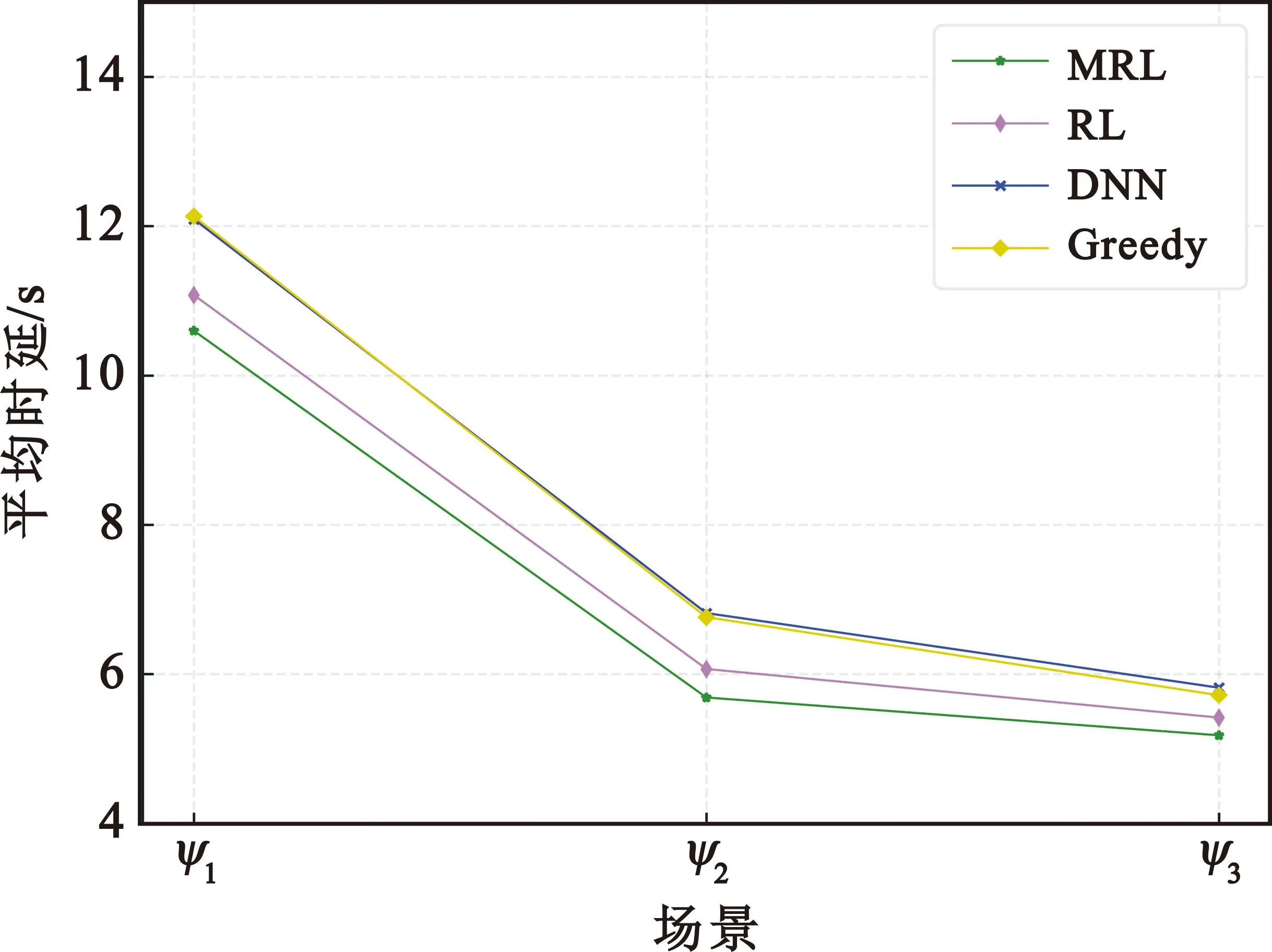
图8 平均时延对比
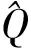
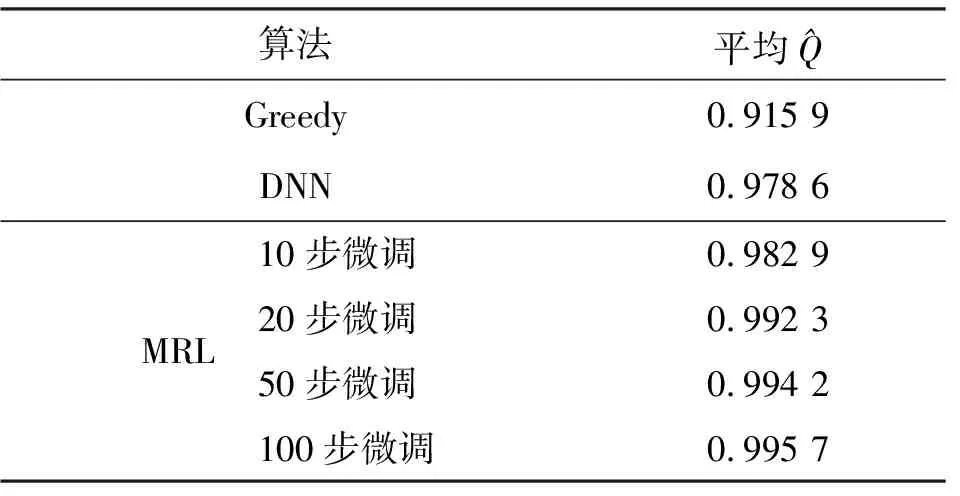
表2 不同算法性能对比
4 结 论
本文针对以往深度学习算法的不足,提出了一种基于元强化学习的自适应卸载方法,它能适应动态MEC任务场景。移动终端基于元策略和本地数据训练内部模型,以获得特定任务策略,用更少的训练数据可以快速训练一个内部模型以适应新的任务。仿真实验表明,MRL在少量的微调步数内能达到0.99以上的准确率。因此,该算法在未来移动边缘网络中的快速部署是可能的。
