基于改进粒子群算法优化的染色木材颜色检测算法研究
2024-02-27管雪梅杨渠三
管雪梅 吴 言 杨渠三
(东北林业大学机电学院,黑龙江 哈尔滨 150040)
在模拟珍贵材的木材单板染色过程中,颜色检测步骤至关重要[1-4]。该过程包括在配色阶段对目标材料色彩的精确测量,为构建染色配方模型提供基础,以及在质量检测阶段对染色木材色彩的准确测量,为质量分级提供有效的依据。然而,传统的木材染色工艺主要依赖分光光度计进行颜色测量,该方法只能进行单点离线测量,严重限制了木材染色的生产效率[5-7]。
随着人工智能技术的发展,神经网络技术已被越来越多地应用于颜色检测[8]。尽管反向传播(BP)神经网络在预测精度和泛化能力上存在显著的局限性[9],但与遗传算法结合可以提高其预测精度。然而,由于样本数量的限制,该方法的收敛速度并不理想[10]。卷积神经网络(CNN)有较高的测色精度,但因其对数据量的严重依赖,在时间和精力上的投入较大[11]。将随机森林(Random Forest,RF)与卷积神经网络进行模型组合,不仅可以提高模型测色精度,而且还能显著降低数据需求量[12]。通过主成分分析法(Principal Component Analysis,PCA)提取输入特征,可以进一步提高测色精度[13]。
在染色木材颜色检测领域,提高检测精度仍是研究人员追求的目标。极限学习机(Extreme Learning Machine,ELM)在各类预测问题中表现出了强大的泛化能力[14-17],鉴于此,本研究基于ELM,以光谱反射率为输入,色度参数L*、a*、b*为输出,建立预测模型,并运用粒子群优化(Particle Swarm Optimization,PSO)算法进行优化。在此基础上,针对PSO算法的不足加以改进[18-20],以提高模型的预测能力,实现高精度的颜色检测,从而推动木材染色技术的进一步发展。
1 材料与方法
1.1 试验材料
俄罗斯樟子松(Pinus sylvestrisvar.mongolica Litv.)旋切单板,尺寸为40 mm×60 mm×0.5 mm;活性红(X-3B)染料、活性黄(X-RG)染料、活性蓝(X-3G)染料,上海佳英化工有限公司;染色助剂包括渗透剂(水性JFC溶液)、固色剂(无水碳酸钠)、促染剂(NaCl)等,常德比克曼生物科技有限公司;GP1601u标准色卡,美国Pantone公司。
1.2 试验设备
高光谱成像系统,芬兰SPECIM公司;数显恒温水浴锅(HH-4),上海力辰邦西仪器科技有限公司;电子天平(HC311),上海花潮实业有限公司;电热恒温干燥箱(202-Ⅰ型),天津泰斯特仪器公司。
1.3 染色处理
将活性红(X-3B)染料、活性黄(X-RG)染料和活性蓝(X-3G)染料按比例进行组合(如表1 所示),用蒸馏水配置500 mL的染液,并加入浓度为15 g/L的NaCl溶液。搅拌均匀后将染色单板浸入,在65 ℃的水浴锅中静置2 h,然后加入浓度为20 g/L的Na2CO3溶液固色30 min。随后,取出单板并用清水冲洗其表面,进行干燥处理。部分染色单板的照片如图1 所示。

图1 染色后部分木材单板照片Fig.1 Pictures of partial wood veneer after dyeing
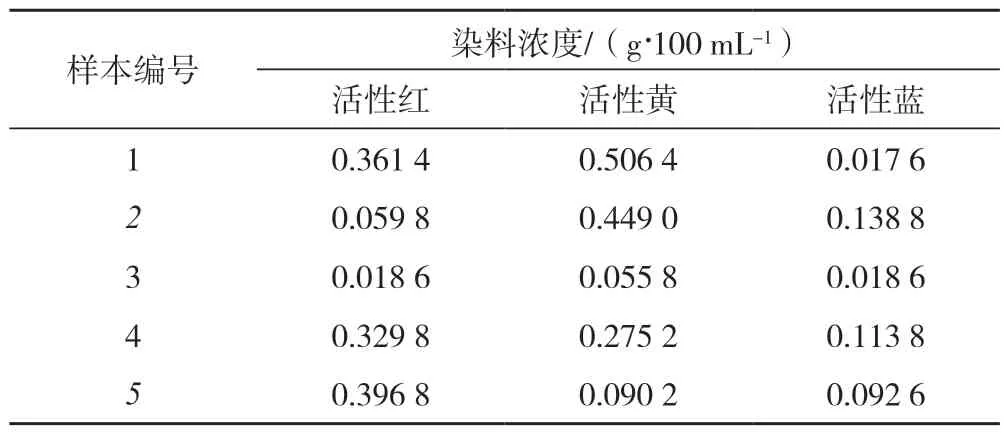
表1 部分木材单板染液染料配比Tab.1 Dye ratio of partial wood veneer dyeing solution
1.4 数据采集
为保证基于光谱分析的染色木材颜色检测方法的有效性,选取的颜色样本质量至关重要。本研究选取美国Pantone公司GP1601u标准色卡作为样本,并以此建立训练数据集。将染色后的木材单板作为测试样本,并以此建立测试数据集。图2 为标准色卡中部分色块的照片。

图2 部分色块照片Fig.2 Pictures of color blocks
使用高光谱成像系统对标准色卡和染色后的木材单板进行光谱反射率采集。选取的波长范围为400 ~700 nm,在此范围内每间隔10 nm采集一次,共得到31 组光谱反射率。部分染色单板的反射率如图3 所示。
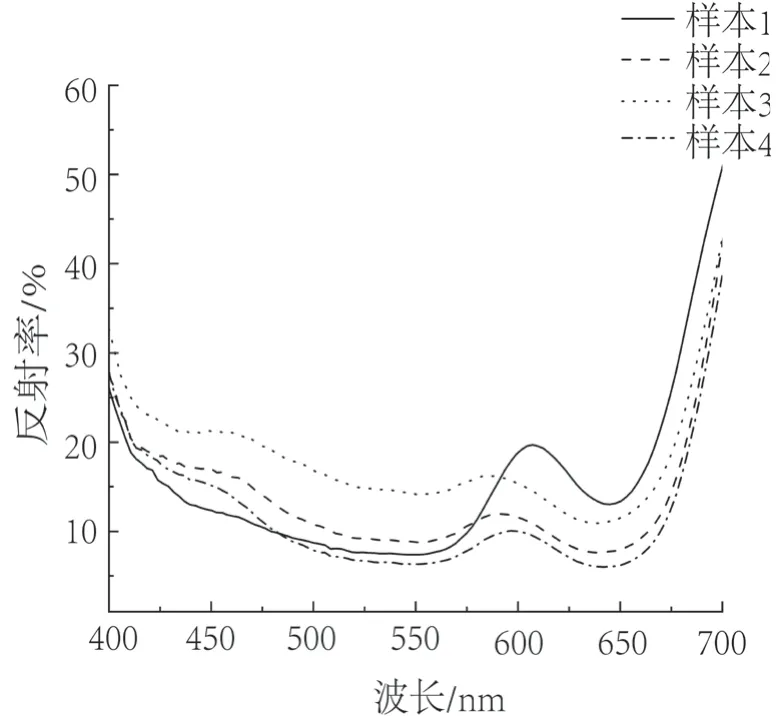
图3 部分染色单板反射率曲线图Fig.3 Pictures of the reflectance curve of stained veneer
使用色差仪对标准色卡和染色后的木材单板进行色度参数提取,在每张色卡和木材单板对角线的方向等距选取三点,测量后取其平均值作为样本的色度学参数。
2 研究方法
2.1 极限学习机
极限学习机(ELM)是一种单隐层前馈神经网络(Single-hidden Layer Feedforward Networks,SLFNS)的学习算法[21]。ELM的最大特点在于,其隐藏层权重和偏置都是随机生成的,不需要通过反向传播等迭代学习算法进行调整。对于一个样本数量为N的数据集(xi,ti),输入样本xi=[xi1,xi2,···,xin]T∈Rn,期望输出ti=[ti1,ti2,···,tim]T∈Rm,隐藏层节点个数为L,激活函数为g(x)的极限学习机网络结构如图4所示。

图4 极限学习机网络示意图Fig.4 Structural diagram of the ELM network

图5 粒子群算法原理Fig.5 Principle diagram of PSO algorithm
其数学模型可以表示为:
式中:xj为第j个输入样本;yj为第j个输入样本对应的输出数据;j=1,2,···,N;输入层与第i个隐藏层节点的连接权重ωi=[ω1i,ω2i,···,ωni]T;bi为第i个隐藏层节点的偏置;输出层与第i个隐藏层之间的连接权重βi=[βi1,βi2,···,βim]T,g(x)为激活函数。
ELM模型的训练目标为使输出的误差最小,即:存在βi,ωi,bi,满足:
式中:ωi·xj是ωi与xj的内积形式,tj为第j个样本的期望输出。
将式(2)表示为矩阵形式:
式中:H为隐藏层节点的输出;β为输出权重;T为期望输出。
ELM的训练过程其实就是寻找最优的β,使网络误差达到最小,其本质就是求式(3)的最小二乘解,即:
2.2 粒子群算法
粒子群优化算法(PSO)属于进化算法的一种,从随机解出发,通过迭代寻找最优解。在标准PSO算法中,粒子群中的所有粒子通过当前自己找到的个体最优解(Pbest)和群体共享的全局最优解(Gbest)来调整自己的速度和位置[22]。速度和位置更新公式如下:
式中:ω为惯性权重;vid(t+1)和xid(t+1)分别为粒子i在t+1代的速度和位置;c1和c2均为学习因子。本文取值为2,r1和r2是[0,1]均匀分布的随机数。
由式(5) (6)可知,ω决定了粒子位移大还是小。标准PSO中,ω采用以下公式进行计算:
式中:ωmax为最大惯性权重,一般取值为2;ωmin为最小惯性权重,一般取值为0.4;iter为当前迭代次数;itermax为最大迭代次数。
由式(7)可知,ω值随着迭代次数的增加线性递减,ω迭代前期较大,粒子进行全局搜索,迭代后期ω较小,粒子进行局部搜索,从而平衡算法全局寻优与局部寻优的能力。
2.3 改进粒子群算法
2.3.1 改进惯性权重
在标准PSO算法中,惯性权重ω采用线性递减的方式进行更新,这种更新方式导致在迭代后期全局最优解开始主导粒子的移动,容易陷入局部极小值[23-25]。因此,本研究采用一种基于Logistic混沌映射非线性变化方式。混沌映射属于一种非线性映射,其中Logistic映射在寻优应用最为广泛,具有良好的随机性,其定义如式(8)所示:
惯性权重ω的定义如式(9)所示:
式中:ωmax=0.9;ωmin=0.4;r(t)为迭代产生的随机数。
ω值随迭代次数的变化如图6所示。由图可知,ω值在迭代过程中是波动的,这种波动特性能够较好地平衡粒子的全局搜索与局部搜索能力,同时粒子的移动更加具有随机性,能有效避免陷入局部最优。

图6 惯性权重随迭代次数变化图Fig.6 The variation of inertia weight with iteration times
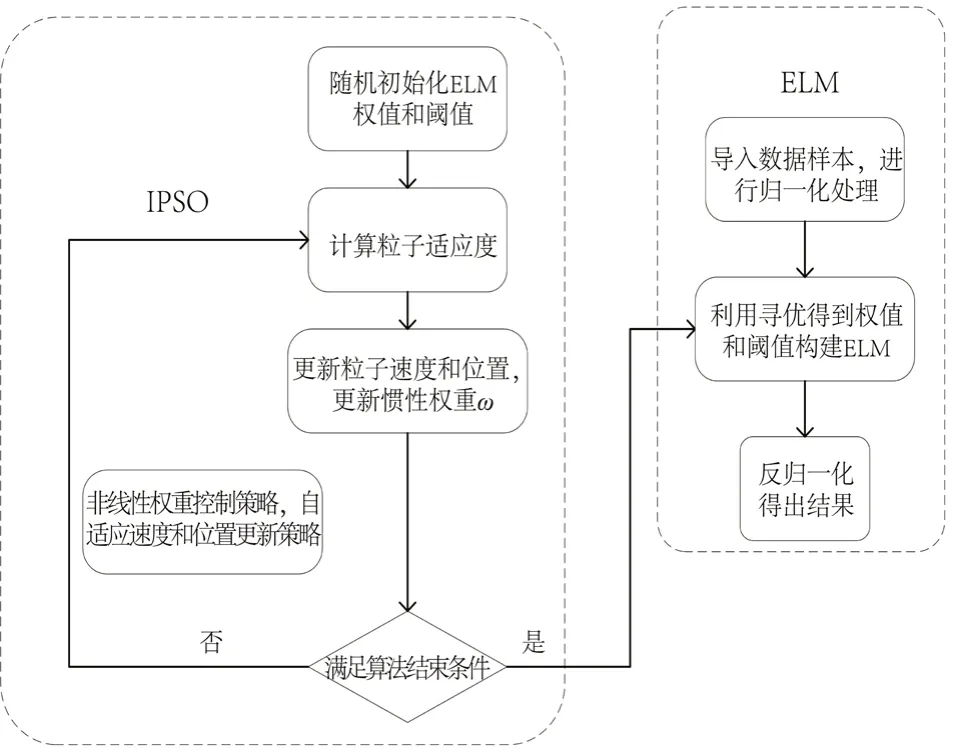
图7 IPSO-ELM原理图Fig.7 IPSO-ELM schematic diagram
2.3.2 改进粒子群位置和速度更新公式
在PSO算法中,粒子的运动方向由其个体最优和群体最优共同决定,这种基于个体最优和全局最优的学习策略使得粒子群算法具有收敛快、可靠性强等优点,但是在复杂问题上存在收敛过早、性能较差等问题[26-29]。研究发现,不同的学习策略会使得粒子群算法具有不同的探索和开发能力。在此基础上,本研究采用一种寻优效果更好的自适应位置和速度更新策略,使得粒子运动更多样化,增强了群体多样性,达到更好的寻优效果。
式(12)为判定依据,其中,fit()为粒子的适应度值;Pi为当前粒子的适应度值与种群中所有粒子平均适应度值的比值,当Pi较大时,当前粒子适应度值远高于粒子群平均适应度值,说明目前粒子弱于群体平均水平,应采用式(10)的更新策略进行粒子速度和位置的更新,增强其全局寻优的能力,从而提高算法搜索全局最优解的概率;当Pi较小时,当前粒子适应度值低于群体平均适应度,当前粒子性能高于总体平均水平,应采用式(11)的更新策略进行粒子速度和位置的更新,从而加强算法的局部搜索能力。通过反复试验Pi阈值设置为0.8。
2.4 基于IPSO-ELM木材染色色差检测模型的建立
2.4.1 确定模型输入和输出
光谱反射率作为一种能够刻画物体表面颜色本质特性的物理量,其反射率曲线的形态与对应物体的颜色存在高度一致性。在相同的照明条件下,同一颜色的反射率曲线具有唯一性。基于光谱反射率的这一特性,可以根据物体表面的光谱反射率来预测其颜色值。因此,本研究中,选择将各个波长下的反射率作为模型的输入特征,色度参数L*、a*、b*作为预测目标。
2.4.2 建立模型
在ELM模型框架中,输入层与隐藏层之间的连接权重ωi和隐藏层节点阈值bi为随机生成,这存在一定的盲目性。在随机产生的过程中,有可能生成的随机数为0,导致某些隐藏层节点失去其功能[30],从而导致ELM模型预测精度降低。为解决这一问题,本研究使用粒子群算法对ELM的初始权重ωi和隐藏层节点阈值bi进行优化,以找到能够获得最佳预测效果的权重ωi和阈值bi,具体优化步骤如下:
1)读取事先准备好的光谱反射率数据和色度参数值,将光谱反射率作为输入,色度参数L*、a*、b*作为输出。
2)ELM参数寻优。将ELM初始权重ωi和阈值bi赋值给粒子位置,赋值后在样本集上进行训练,适应度函数选取预测值与真实值的平均绝对误差,将误差最小的粒子位置保留,然后根据式(12)选择更新策略进行粒子速度和位置的更新,重复计算适应度,并与之前适应度进行比较,超过最大迭代次数后,结束学习过程,得到位置最好的粒子。
3)将步骤2)中得到的最好粒子位置代入ELM的初始权重和阈值,在数据集上进行训练,保留训练后的模型,使用测试集进行预测,将数据反归一化后输出,采用的误差评价指标为平均绝对误差,平均绝对误差公式为:,yi(i=1,2,3)为测试样本真实色度参数,为测试样本预测色度参数。
本研究中粒子群算法种群规模设置为50,迭代次数为300。
3 结果与分析
为验证IPSO算法对ELM模型优化的有效性,将优化后的IPSO算法与PSO算法进行比较,其适应度值随着迭代次数的变化如图8所示。其中,IPSO-1为引入非线性惯性权重ω适应度值的变化曲线,IPSO-2为引入自适应速度与位置更新策略适应度值的变化曲线,而IPSO为引入惯性权重ω和自适应速度与位置更新策略适应度值的变化曲线。由图可见,IPSO在收敛速度和精度上,相比于PSO均有所提高,说明改进后的IPSO对ELM进行优化是合理的。
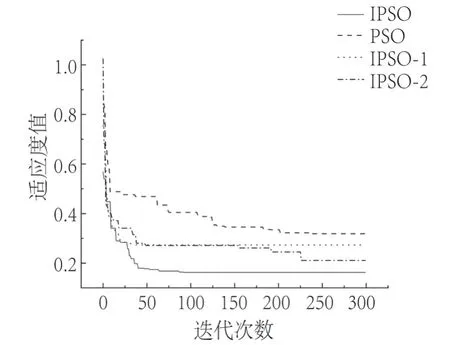
图8 不同PSO的适应度值变化曲线Fig.8 Variation curve of fitness value of different PSOs
为进一步验证IPSO优化ELM的优越性,使用Python编程语言构建了IPSO优化的ELM、PSO优化的ELM和未进行优化的ELM模型。每个ELM模型的隐藏层节点数都设定为50。对于PSO和IPSO,设定种群规模为50,迭代次数为300。利用测试集分别对3种模型进行测试,评估它们的预测能力。表2展示了测试集中样本的实测L*、a*、b*值。表3、表4和表5分别展示了未优化的ELM、PSO-ELM和IPSO-ELM的预测结果。
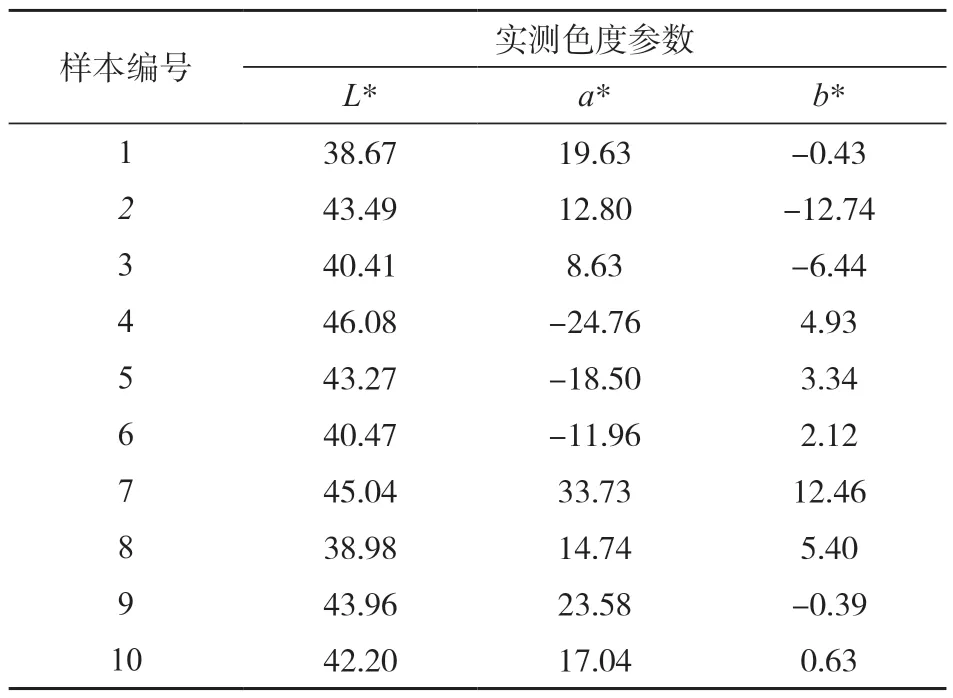
表2 选取的15 组测试集数据Tab.2 Selected 15 groups of test set data
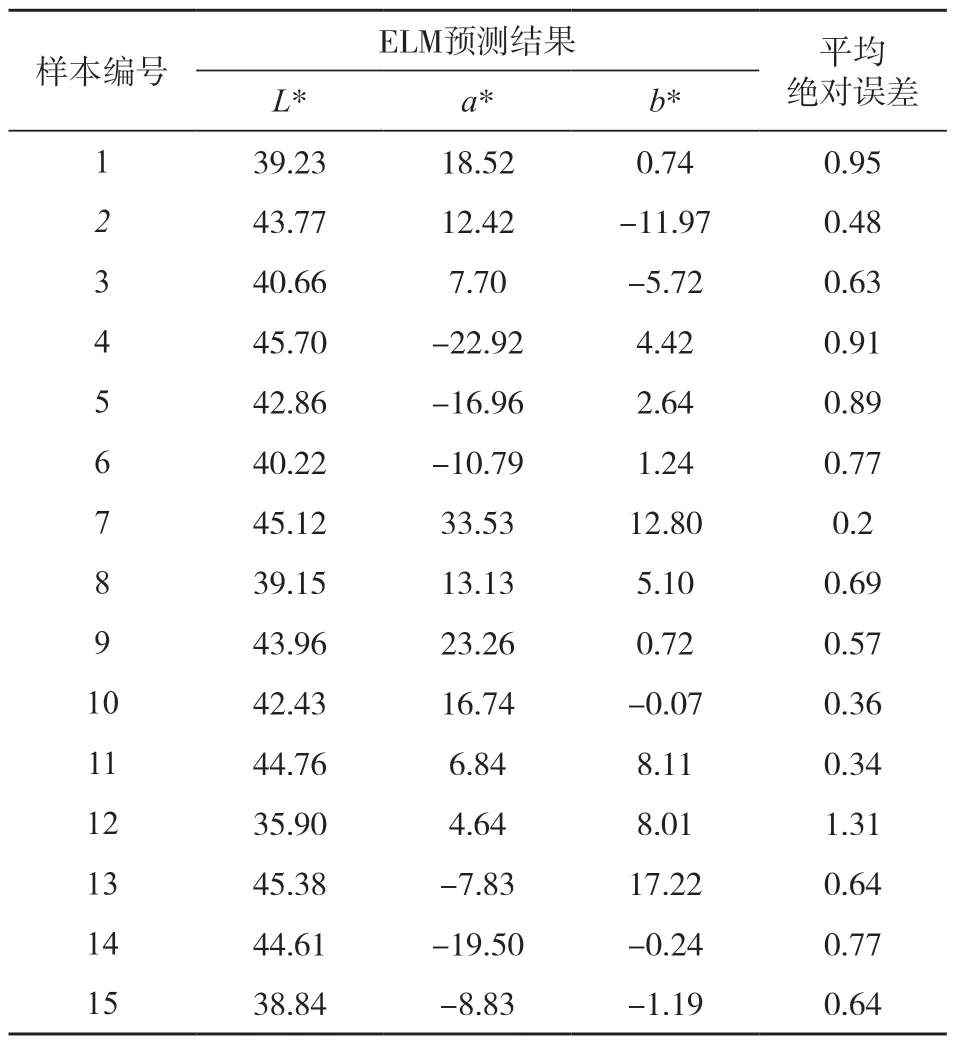
表3 ELM模型预测结果Tab.3 Prediction results of ELM model
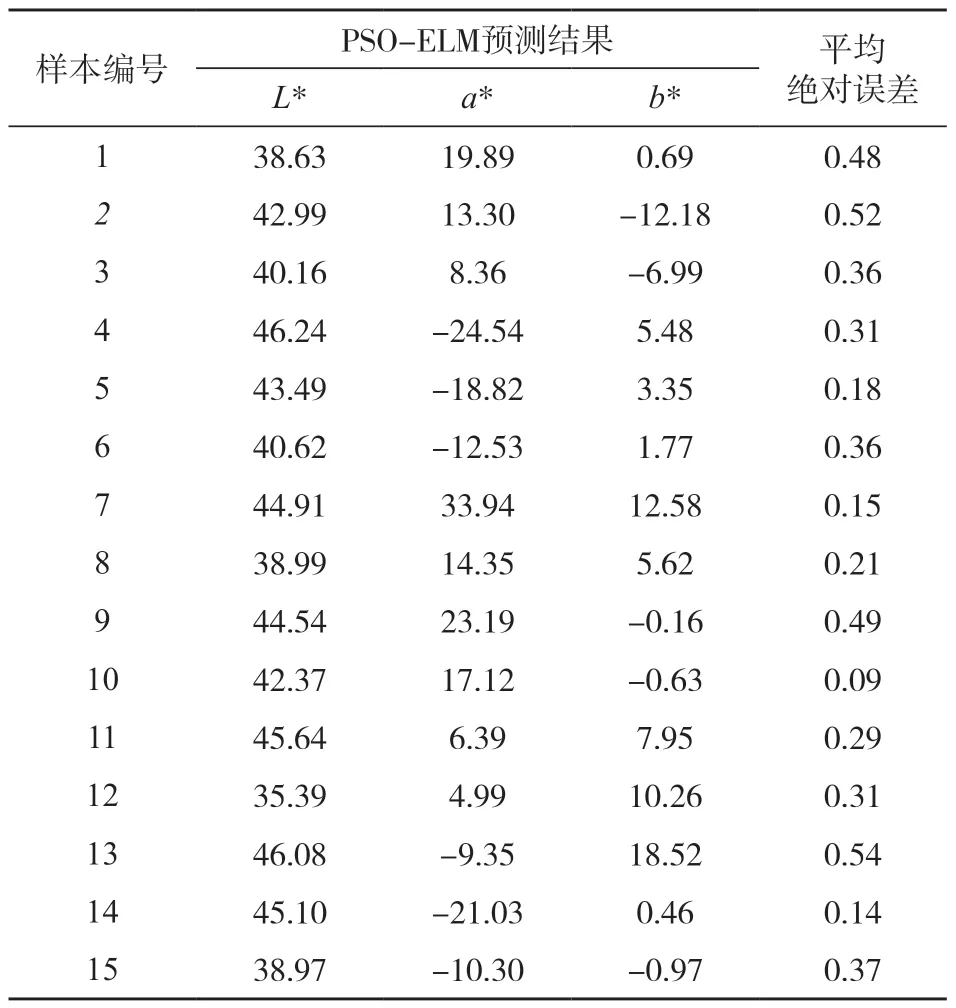
表4 PSO-ELM模型预测结果Tab.4 Prediction results of PSO-ELM model
根据IPSO-ELM、PSO-ELM和ELM的预测结果,绘制3种模型的平均绝对误差曲线图,如图9所示。此外,计算3种模型预测结果的平均误差,如表6所示。从图9和表6可以看出,相较于PSO-ELM和ELM,IPSO-ELM的预测精度更高,平均误差只有0.16,最大误差为0.69,最小误差为0.03,误差波动更小,稳定性更强,证明了IPSO对ELM优化的有效性。

图9 IPSO-ELM、PSO-ELM和ELM预测平均绝对误差对比Fig.9 Comparison of mean absolute error curves of IPSOELM, PSO-ELM and ELM formulations

表6 3 种测色模型的样本平均误差Tab.6 Sample average error of three color measurement models
同时,为了说明此模型在染色木材颜色检测中的适用性,将其与BP神经网络、RBF神经网络、麻雀算法(SSA)优化ELM(SSA-ELM)模型和鲸鱼算法(WOA)优化ELM(WOA-ELM)模型的预测结果进行对比。其中,BP和RBF神经网络隐藏层节点数均为50;SSA算法和WOA算法种群规模设置为50,迭代次数300;得到的预测误差曲线如图10所示,样本平均误差如表7所示。从图10和表7可以看出,ELM预测精度明显高于BP和RBF,IPSO-ELM在预测精度上也优于其他方法优化的ELM,更加接近真实值。
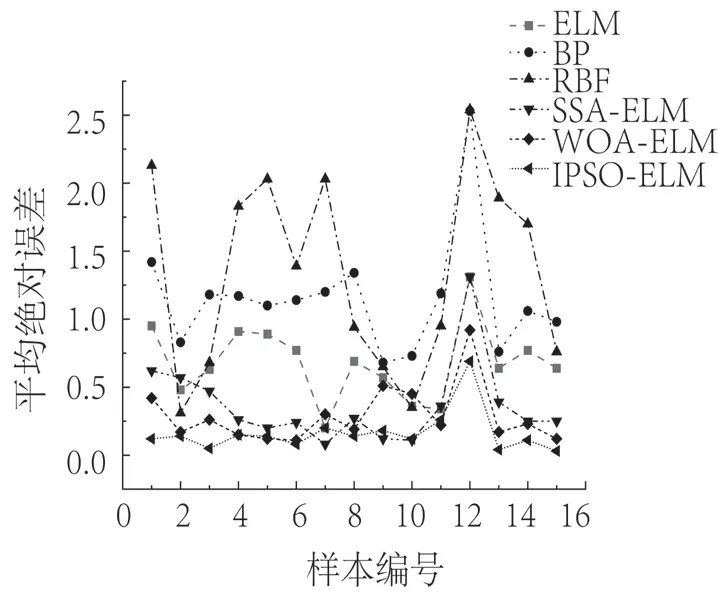
图10 各种模型的平均绝对误差曲线Fig.10 Mean absolute error curve of four model formulations

表7 各种模型的样本平均误差Tab.7 Sample average error of various color measurement models
4 结论
本文通过改进粒子群算法对极限学习机(ELM)进行优化,建立了木材染色颜色检测模型,将ELM初始权重ωi和阈值bi带入粒子群算法进行寻优。为避免陷入局部最优的情况,引入非线性变化的惯性权重和自适应粒子位置和速度更新策略,得到的色度参数平均绝对误差为0.16,与其他优化算法相比,更接近真实值,体现了IPSO-ELM颜色测量上的优越性。
与其他神经网络模型不同,ELM初始权重和阈值为随机生成,因此无需迭代学习。本研究减小了这种随机性对模型的影响,使其能够适应实际生产需要,对于促进木材染色加工生产效率具有重要意义。未来,可加入模型组合,或增加数据集,对其他优化算法进行深入研究。
