基于多尺度特征融合的遥感影像场景分类方法①
2024-02-26秦望博
秦望博, 葛 斌
(安徽理工大学计算机科学与工程学院,安徽 淮南 232000)
0 引 言
遥感影像是通过人造卫星、无人机、或其他飞行器上收集地物信息的胶片或照片,遥感影像的解译工作在许多领域发挥着不可替代的作用,广泛应用于城市规划、灾害监测、地理空间坐标探测等领域,是当前热门的研究问题[1]。CNN具有强大的特征提取能力和表征能力,可用作图像的特征提取器。遥感影像含有较为丰富的浅层空间结构信息和深层语义信息,将结构信息和语义信息相融合可以提高网络模型的特征提取能力和表征能力从而提高总体分类精度。现有研究是通过不同层提取CNN特征去生成图像特征[2-3],也有学者利用预训练的CNN解决不同分类问题,再用遥感标签进一步训练[4]。但目前研究[5-7]很少充分考虑到遥感影像的多尺度信息空间信息和结构信息,没有融合图像高层特征和低级特征,地物目标尺度差异大[5],对于主体和背景区分不明显的遥感影像不能有效地提取整体特征。且随着CNN模型深度和特征提取模块的增加,网络的参数量呈指数增长,对算法的实际部署造成了困难。
针对上述问题,提出一个具有轻量级多尺度的遥感影像场景分类网络。主要工作如下:1)提出了多尺度特征融合模块获取遥感影像的多尺度特征。2)提出了轻量级遥感场景分类网络结构。经过公共数据集验证,拥有较好的性能。
1 模型构建
1.1 多尺度特征融合模块
为了网络模型的轻量化,减轻网络对硬件设备性能要求,使用MobileNetV2网络[7]作为主干网络来提取遥感影像的深层特征,利用多尺度融合模块对主干网络进行了改进,在不显著增加网络参数数量的情况下,使用多尺度融合模块提取并融合遥感影像的高层语义特征和低层纹理结构特征。
提出了多尺度特征融合模块(Multi-scale Feature Fusion Module, MFF)有效提取遥感影像中的多尺度特征,通过改变卷积的输入扩大感受野,提取图像的多级多尺度特征。设计的MFF模块将特征图等分为s组,当s较小时,遥感影像特征图的感受野变化不大,难以获取图像的多尺度特征,难以融合多级特征。当s较大时,没有增加输入特征映射通道,不能很好地提取特征。综合考虑,选择将特征图切分为4组。如图1的MFF模块所示。
多尺度特征融合模块将输入特征图按照通道维度等分为四组,等分成的特征图分别代表了遥感影像的多级特征,使用深度可分离卷积(Depthwise seperable convolution)有利于减少网络所需的参数量。使用3×3 DW卷积从第一组特征图中提取特征,第一组的输出与第二组输入相加一并作为第二组的输入,再使用3×3 DW卷积提取特征,经过类似残差结构,使得第二组的输出就包含多级特征。以此类推,直至处理完最后一组特征图,一共有四组输出,最后将所有的DW卷积输出进行级联,即在通道维度上进行拼接操作,输出特征图维度大小与输入特征图维度大小保持一致,且输出特征图融合遥感影像的多尺度多级特征。
1.2 遥感场景分类方法
提出的模型以轻量级网络MobileNetV2作为骨干网络,采用前面提出的MFF模块对MobileNetV2进行改进,提高网络的性能,网络整体架构如图2所示。

图1 多尺度特征融合模块

图2 网络整体架构
首先、由于数据集中的原始图像分辨率不统一,需要对遥感影像进行缩放操作将所有图像尺寸都转为256×256且保留了遥感影像的原始特征,再对其进行裁剪操作将图像尺寸变成224×224满足网络的需求。将预处理后的高分辨率遥感影像作为网络的输入,在瓶颈块中,遥感影像首先经过一个1×1卷积进行升维操作扩展输入通道,再使用DW卷积操作提取影像的特征,最后利用1×1卷积进行降维操作,目的是将特征映射到新的特征空间中,融合遥感影像的特征,形成了“中间粗、两头细”的瓶颈结构。步距不同时,使用不同的瓶颈结构。当DW卷积的步距为1时,经过DW卷积后会与瓶颈结构的输入相加即残差结构。当DW卷积的步距为2时,特征图经过DW卷积后尺寸大小会变成原来的一半,不能再进行相加操作,便没有捷径分支的残差连接结构。瓶颈结构和MFF模块可以当做一个整体,即图3中灰色矩阵圈起来的部分,基于多尺度特征融合的遥感场景分类方法中此部分重复堆叠了7次,遥感影像经过多次融合特征的特征图里包含了丰富的多尺度特征。表1是提出的网络结构。Input指输入到此模块的特征图大小。Operator的含义是进行何种操作的名称。Expansion factor的意思是扩展因子,指1×1卷积升维倍数,可以调节输入通道的倍数。Output channels指输出特征图的通道数。Repeated times指模块的重复次数。Stride指第一个BottleNeck的卷积步距,只针对第一层,第二层BottleNeck及往后的BottleNeck步距都为1。最后一层为全连接层输出分类结果,k为分类类别数,可根据不同的分类任务改变k值。

表1 总体网络架构
2 实验结果分析
2.1 实验数据与设置
为了验证提出模型的有效性,使用AID[8],UC Merced land-use[9](以下简称UCM)和NWPU-RESISC45[10](以下简称NWPU)三个遥感影像场景分类领域常用的公共数据集进行实验对比。AID数据集包含10000张分辨率大小为600×600的30类场景影像,每种场景含有220~420张图片。UCM数据集包含21种场景影像,每种场景包含100张尺寸为256×256的图片。NWPU数据集包含45种场景影像,每种场景都包含700张尺寸为256×256的图片。在Pycharm编译器下使用Python 3.9进行实验,PyTorch的版本为1.12,操作系统为Windows 10,硬件平台使用NVIDIA GeForce GTX-3060 GPU进行训练。
在实验过程中,每个训练集选取一定比例 的数据作为训练数据,其余数据作为测试数据,将训练样本的比例设为总样本数的20%和50%,其余作为测试集,训练200个epoch。此外,为了提升模型的鲁棒性,采用对图像旋转,裁剪等数据增强技术。
2.2 评价指标及实验设置
采用总体精度(Overall Accuracy, OA)和混淆矩阵(Confusion Matrix,CM)来评估模型的性能。
OA的定义为分类正确的样本数占测试集总样本数的比例,它反映了模型的总体数据集分类情况,计算公式为:
式中:S是测试集中分类正确的样本数,N是测试集中的总样本数。
为了缓解过拟合的问题,使用数据增强技术:将用于训练的图像大小统一调整为256×256,再对其进行随机水平翻转,随机垂直翻转和随机旋转。之后再通过随机改变亮度,对比度和饱和度对图像进行随机采样,最后将测试图像随机裁剪至分辨率大小为224×224,满足网络模型的需要。
2.3 实验结果与分析
2.3.1 UCM数据集上的性能对比
UCM数据集的场景类别较少,类间相似性也比较低,分类难度较小。以UCM数据集的20%和50%作为训练集,测试结果如表2,MobileNetV2网络提出了轻量级深度可分离卷积网络,本文方法是在MobileNetV2网络的基础上进行改进,增加了多尺度特征融合模块,并对整体网络进行了重新设计,在20%的训练比例情况下准确率提升了2.13%,在训练50%数据集时也有1.22%的性能提升。相对于MobileNetV3在训练20%数据集的情况下有2.42%的性能改进,训练50%数据集时,也有2.57%的性能改进。ShuffleNetV2是从内存访问成本和并行度的角度考虑设计的,降低FLOPs提升,网络运行速度。在20%的训练比例情况下,相较于ShuffleNetV2也有5.95%的性能提升,在50%的训练比例情况下也有1.84%的性能提升。GhostNet从冗余图生成大量特征图,在20%的训练比例情况下,相较于GhostNet也有2.61%的性能提升,在训练50%数据集情况下也有2.14%的性能提升。在UCM数据集上的实验说明提出的方法可以改善网络的特征提取能力,提高分类准确率。

表2 在UCM数据集上的总体精度结果比较
2.3.2 AID数据集上的性能对比
AID数据集与UCM数据集相比较,AID的场景类别增加到了30个,每个类别包括220~420张图片,且像素分辨率变化范围更大,类间相似性更大,也进一步增加了AID数据集的场景分类难度。将该数据集的训练比例分别设定为20%和50%对本文提出的模型进行验证,结果如表3所示。
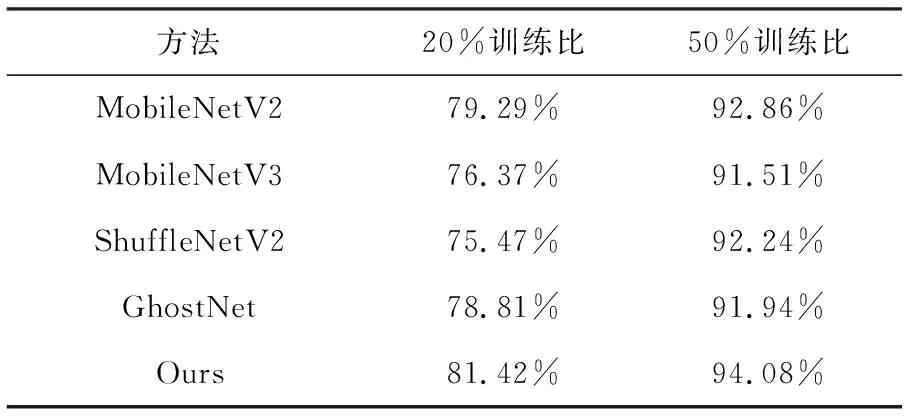
表3 在AID数据集上的总体精度结果比较
从表3中可以看出,当训练样本数量达到总样本数的20%和50%时,提出方法的总体精度都超过了其他场景分类方法。相比较MobileNetV2网络,在训练样本数量为总样本数的20%和50%时,提出的模型准确率分别提升了2.55%和1.26%。相对于MobileNetV3,在训练样本数量为总样本数的20%和50%时,性能分别提升了2.81%和2.42%。相比较ShuffleNetV2网络,在训练样本数量为总样本数的20%和50%时,网络分别有3.2%和3.04%的性能提升。相比较GhostNet网络,在训练样本数量为总样本数的20%和50%时,网络分别有4.31%和2.54%的性能提升。相比较VGG-VD-16网络,在训练样本数量为总样本数的20%和50%时,网络分别有0.47%和2.22%的性能提升。在AID数据集上的实验证明了提出方法的优越性。
2.3.3 NWPU数据集上的性能对比
NWPU数据集由西北工业大学发布,场景类别达到45类,具备多样性和规模较大的特点,分类难度更大,将数据集的20%和50%作为训练集,其余作为测试集,数据结果如表4。
表4 在AID数据集上的总体精度结果比较
从表4中可以看出,当训练样本数量达到总样本数的20%和50%时,提出方法的总体精度都超过了其他场景分类方法。相比较MobileNetV2网络,在训练样本数量为总样本数的20%和50%时,提出的模型准确率分别提升了2.7%和1.26%。相对于MobileNetV3,在训练样本数量为总样本数的20%和50%时,性能分别提升了3.82%和2.42%。相比较ShuffleNetV2网络,在训练样本数量为总样本数的20%和50%时,网络分别有2.9%和3.04%的性能提升。相比较GhostNet网络,在训练样本数量为总样本数的20%和50%时,网络分别有5.26%和2.54%的性能提升。相比较VGG-VD-16网络,在训练样本数量为总样本数的20%和50%时,网络分别有0.25%和2.22%的性能提升。在NWPU数据集上的实验证明了提出方法的优越性。
3 结 语
提出一种新颖的多尺度特征融合遥感影响场景分类网络。整体网络模型以轻量级网络模型MobileNetV2为骨干网络,具有更少的参数量,更低的硬件需求。首先通过卷积进行升维操作提取特征。多尺度特征融合模块的引入可提取并融合遥感影像的高层语义特征和底层的纹理特征,实现上下文特征的融合,有效解决了遥感影像中主体目标不清晰,易与背景混杂的问题,融合遥感影像的高层底层特征,获得不同层级之间的相关性。最后通过在UCM、AID和NWPU数据集上与其他先进的场景分类方法通过实验对比,提出的方法更有利于遥感影像的场景分类任务,且具有更强的区分性和鲁棒性。
