结合背景图的高分辨率视频人像实时抠图网络
2024-02-24彭泓张家宝贾迪安彤蔡鹏赵金源
彭泓,张家宝*,贾迪,2,安彤,蔡鹏,赵金源
1.辽宁工程技术大学电子与信息工程学院,葫芦岛 125105;2.辽宁工程技术大学电气与控制工程学院,葫芦岛 125105
0 引言
人像实时抠图的应用领域广泛,涉及到影视、短视频社交、网络会议等。对于给定视频帧I∈RH×W×C,可将其看做是由前景F∈RH×W×C与背景B∈RH×W×C按一定透明度α∈[0,1]线性叠加而成,即
式中,H、W和C分别为视频帧的高、宽和通道数量。抠图的主要目的是分离前景与背景,并计算每个像素对应的α,进而生成蒙版图。
视频抠图可分为传统和基于深度学习两类方法,传统抠图方法常将三分图作为辅助信息输入,主要根据图像中的前景与背景色来估算差异。其中,三分图是将图像分为前景F、背景B和前景—背景相接的未知区域。在应用三分图辅助抠图任务中,只需专注未知区域中前景的透明度,而无需关注前景和背景的具体像素值,减少了问题的解空间,可以辅助预测更为精细的蒙版图。根据样本间的相似度,可将传统方法分为基于采样和基于传播的抠图方法。基于采样的抠图方法(Hong 等,2018;Shah⁃rian 等,2013;Chuang 等,2001;He 等,2011;Wang 和Cohen,2007)根据样本间的连续性和相似性估计前景色与背景色所占比例,进而求解“未知区域”中的蒙版图。基于传播的抠图方法(Aksoy 等,2017;刘天艺 等,2022;He 等,2010;Lee 和Wu,2011;吴玉娥等,2010;Levin等,2008;Chen等,2013b)根据像素间的相似度将已知区域中的透明度值传播至“未知区域”,求解完整的蒙版图。尽管传统视频抠图方法取得了阶段性成果,但在复杂场景中仍存在处理速度慢、目标图像边缘模糊、细节处理不够理想(如发丝、镜片等)的问题。
随着深度学习的崛起,基于学习的抠图方法在具有挑战性的场景中取得了突破性的进展。Chen等人(2013a)将深度学习与KNN(K-nearest neigh⁃bor)相结合,在高维特征空间中应用KNN 计算蒙版图,优化了抠图效果,然而该方法在定义高维特征空间时存在难度,很难提高人物边缘的抠图效果。因此一些方法利用三分图中的辅助信息弥补人物边缘抠图信息的不足,为网络提供更多的边缘信息。Xu等人(2017)将三分图作为辅助信息,同时在编码器—解码器网络之后增加一个卷积网络,对预测的蒙版图进行精细化处理,从而解决抠图边缘模糊的问题。Sun 等人(2021a)提出基于语义三分图的可学习抠图模式,估计未知区域相应的像素分类置信度图,将传统三分图转化为语义三分图,辅助原始图像估计蒙版图,提高了抠图效果。Park 等人(2022)和Liu等人(2023)将三分图作为全局先验知识,并提出基于Transformer 的抠图模型,在Transformer 块中充分利用三分图信息进一步提高了蒙版图的精度。Liu 等人(2021)基于三分图提出一种三方信息挖掘和融合网络,采用三方信息集成模块完成多分支信息之间的交互,实现了全局信息和局部信息之间的协调性,并取得了高质量的效果。弥补了人物边缘模糊的问题。然而制作精准的三分图需要耗费大量的时间,并且三分图的质量也直接影响着抠图的效果。对此,Yu 等人(2021)提出一种以粗糙掩码作为指导信息的抠图框架,通过构建自引导模型逐步完善“未知区域”进行回归抠图,降低了人工制作精细三分图的要求。
此外,还有一些学者将工作重点放在了无需三分图的输入上。Sengupta 等人(2020)采用拍摄照片前捕获无主题照片作为辅助信息,通过膨胀腐蚀操作生成人像粗分割图像,以此估计蒙版图和前景图,免去了制作三分图的环节并获得了较好的结果。通过形状模板图和X-Y坐标信息作为辅助信息,也可以在无三分图的前提下更好地估计蒙版图(许征波和杨煜俊,2020)。Chen 等人(2022)提出高分辨率细节分支和语义上下文分支进行交互,进一步解决了无辅助信息指导的需求。虽然上述方法在抠图细节上已经具备了较好的表现力,但在视频任务中仍不具备连续处理视频帧的能力,更无法达到实时性能。为了能够连续处理视频帧,Sun 等人(2021b)基于深度学习提出将初始帧三分图作为参考,通过三分图传播网络引导后续目标帧,并采用时空特征聚合模块获取时域信息,估计对应帧的蒙版图。此外,Seong 等人(2022)提出级联三分图模块和蒙版图计算模块,采用传播三分图信息和α值对视频帧进行回归计算蒙版图,降低了视频帧三分图的制作要求。然而该方法仍然依赖人工制作三分图。为了解决人工制作三分图依赖的问题,一些学者在网络中融入了三分图生成网络自动生成三分图辅助视频抠图,Zhang 等人(2021)将用户标注的视频关键帧输入到视频对象分割网络中,用于生成视频三分图,辅助计算蒙版图,消除了手动制作三分图的需求。然而对三分图生成模块的设计降低了网络处理的实时性。为解决三分图生成网络的冗余,Jin 等人(2022)采用在绿幕背景下拍摄视频,有效提高了网络的实时性。Song(2022)和Lin 等人(2022)采用无辅助信息输入的方式进行视频抠图,进一步加快了网络的实时性。然而,对于高分辨率视频,网络的实时性和抠图精度仍具有挑战性,为此,Lin 等人(2021)提出基于背景的方法,采用两层神经网络,基础网络计算低分辨率图像误差,优化网络在误差图上选择误差较大的图像区域进行优化处理,获得视频帧蒙版图,提高了人像视频抠图质量,但是由于优化网络未考虑全局信息,导致在部分细节区域的效果不佳。
为提高高分辨率视频实时抠图质量,本文在考虑视频帧间序列相关性的基础上,采用背景作为辅助信息,提出一种结合背景图的高分辨率视频人像实时抠图网络,主要贡献点如下:1)给出一种高分辨率视频实时抠图网络结构,能够有效处理人像边缘和细节处的像素信息,提高蒙版图构建的准确率。2)提出一种循环解码器网络,融合连续视频帧间信息,充分利用上下文时序信息提高相邻帧特征的捕获能力,同时引入类残差结构降低了模型的参数量,提高了模型的处理速度。3)对高分辨率信息指导模块进行设计,结合协方差均值滤波、逐点卷积等处理,给出一种精细化网络结构,能够有效提取高分辨率影像中人物轮廓细节区域的抠图质量。
1 方 法
为了实现网络的轻量化,首先将高分辨率特征图按照采样率D进行下采样,可以在基准网络中减少(D2-1)/D2倍计算量,其次在基准网络的特征融合部分采用具有平均池化操作的轻量级金字塔池化模块,进一步减少网络的参数量。解码器部分,在保持高分辨率抠图精度的前提下,采用具有低参数量的线性插值的方式恢复高分辨率图像,从而提高网络的实时性能。
网络结构主要由基准网络和精细化网络两个部分组成,基准网络在低分辨率图像上进行处理,精细化网络根据基准网络的预测结果以原始高分辨率图像作为指导信息生成目标结果,如图1 所示。融合给定视频帧I与背景B,通过降采样获得低分辨率视频帧Il和背景Bl,并将其输入到基准网络中获得低分辨率蒙版图αl、隐藏特征图Hc以及前景残差图=F-I。精细化网络采用αl、和Hc及原始视频帧I指导低分辨率视频帧Il生成高质量蒙版图与前景图F。本文网络采用多帧图像作为输入,更有利于模型对时间信息的整合。

图1 总体网络架构Fig.1 Overall network architecture
1.1 基准网络
基准网络采用全卷积编码—解码网络,主要由编码器模块、金字塔池化模块(pyramid pooling mod⁃ule,PPM)(Zhao等,2017)及循环解码器模块组成。
1.1.1 编码器模块
为增大感受野保留更多视频帧信息,本文在编码器中采用空洞卷积来提取特征。图像细节特征提取依赖语义分割质量,采用DeepLabV3+架构的主干ResNet50(residual network 50 )神经网络作为编码器主体结构,将其第1 层卷积设为六通道输入,为保持编码器1/16 下采样输出,对编码器的最后一层下采样接入空洞卷积操作,提高编码器的语义分割能力,令gen(·)为编码器模块,以低分辨率图像Il作为输入获得特征图Fl,即
编码器不仅输出特征图Fl,还提取1/2、1/4、1/8和1/16 分辨率下的多尺度中间特征图,以此捕获精细结构,为后期循环解码器特征融合提供支持。
1.1.2 金字塔池化模块
多尺度特征提取有利于收集更多的细节和语义信息,进一步提升网络的鲁棒性。如图2 所示,金字塔池化模块由多个大小为1 × 1,2 × 2,3 × 3,6 × 6自适应平均池化操作组成,对其输出进行1 × 1卷积减少通道数,分别进行双线性上采样操作,并将输出特征图与模块输入图通过Concat()函数进行元素级联,通过1 × 1卷积输出多尺度特征融合图。

图2 金字塔池化模块Fig.2 Pyramid pooling module
1.1.3 循环解码器模块
结合长短期记忆网络进行解码器设计,采用循环架构提高视频流中的重要信息捕获能力,通过自适应学习的方式连续处理视频帧间信息。循环解码器由连续上采样层和残差门控循环单元模块(residual ConvGRU,R-ConvGRU)交替组成。上采样层将上一模块生成的特征图通过双线性上采样生成对应特征图Ft,分别与来自编码器提取的多尺度中间特征图F1/16、F1/8、F1/4和F1/2合并连接,通过无偏置卷积、批量归一化和ReLU 激活函数进行特征融合与通道合并,采用残差门控循环单元模块对特征图的信息流进行迭代更新,通过输出层分离目标预测图。为了更好地聚合信息流中的时间信息,采用如图3 所示的残差门控循环单元模块对视频流进行更新,利用卷积门控循环单元(ConvGRU)将分离后的特征图与视频前一帧特征图融合,并对信息流的时空序列信息进行更新。同时,在残差门控循环单元模块中引入类残差连接结构,将分离后的特征图与经ConvGRU 融合后的特征信息进行残差合并。上述设计不仅在一定程度上减少了参数量,而且还能使网络更加专注时空序列信息。
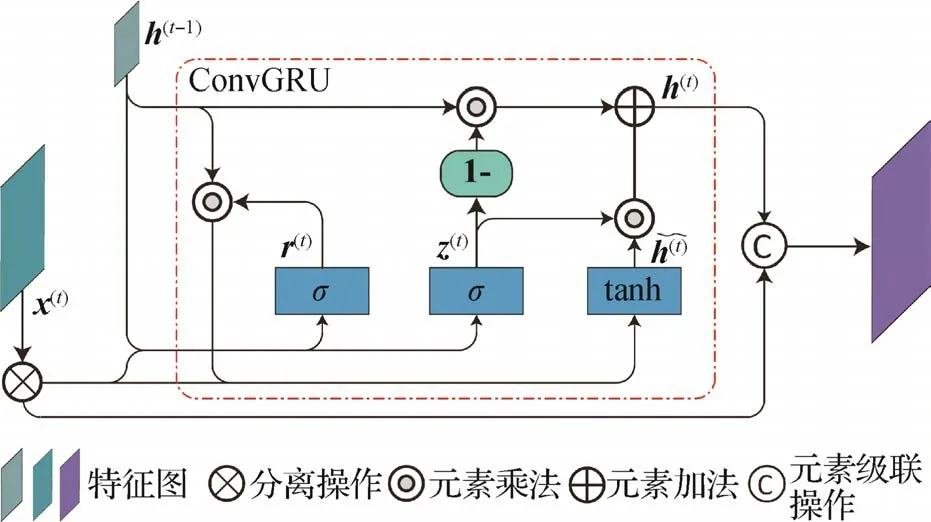
图3 残差门控循环单元(R-ConvGRU)Fig.3 Residual gated recurrent unit(R-ConvGRU)
在残差门控循环单元模块中,采用具有整合时空序列信息的卷积门控循环单元融合视频信息流,可表示为
式中,运算符·和∘分别为卷积操作与乘积,σ(·)和tanh(·)分别为sigmoid 激活函数和双曲正切激活函数,w和b分别为3 × 3卷积核与偏置项,h(t-1)为循环架构中上一个循环生成的隐藏状态图,将其作为当前隐藏状态图的输入,将初始隐藏状态图h(0)置为全零张量。输出层将上采样输出的特征图与输入图像通过Concat(·)进行级联,并通过两次3 × 3 卷积、批量归一化(Ioffe 和Szegedy,2015)以及ReLU 激活函数输出低分辨率预测特征(1 通道的蒙版预测图、3通道的前景残差图及32通道的隐藏特征图)。
1.2 精细化网络
基准网络中联合上采样操作将导致输出图像的边缘模糊,根据Wu等人(2018)提出的快速引导滤波,通过设计高分辨率信息指导模块构建精细化网络提高人像抠图质量。高分辨率图像Ih通过下采样处理获得低分辨率图像Il,并将Il与低分辨率预测特征(蒙版图αl、前景残差图和隐藏特征图Hc)作为精细化网络的输入,传递给高分辨率信息指导模块,如图4所示。
在高分辨率信息指导模块中,将Ih经卷积处理减小通道维度,并与批量归一化结果融合获得高分辨率特征图Ph,对Il执行相同的操作获得低分辨率特征图Pl,并通过方差均值滤波计算Pl像素间的关联信息,进一步提取多尺度特征。
为充分提取图像的低分辨率特征,根据基准网络输出的蒙版图αl及前景残差图提取中期低分辨率指导信息Ql,具体为
式中,C(·)为元素级联操作,采用Concat(·)函数进行拼接。通过协方差均值滤波模块将Pl与Ql融合,再将方差均值滤波模块输出的特征图和隐藏特征图共同输入到逐点卷积模块中,计算低分辨率预测值与输入图像间的重构误差,获得低分辨率线性指导参数Al,该参数受到如下方程的约束,具体为
式中,wk为3 × 3 卷积滤波窗口,⊗为元素乘法,Ii为卷积滤波窗口wk内第i个像素,Qi为特征图内第i个像素。通过式(8)局部线性变换计算低分辨率图像偏移量bl,将参数Al和bl通过双线性上采样获得高分辨率线性指导参数Ah及高分辨率图像偏移量bh。为保留原始高分辨率图像信息,在高分辨率特征图Ph的指导下,通过线性层处理生成高分辨率蒙版图Qh,具体为
1.2.1 协方差均值滤波模块
协方差均值滤波可以更充分地提取低分辨率特征信息,采用如图5 所示的协方差均值滤波模块融合Ql和Pl,计算式为
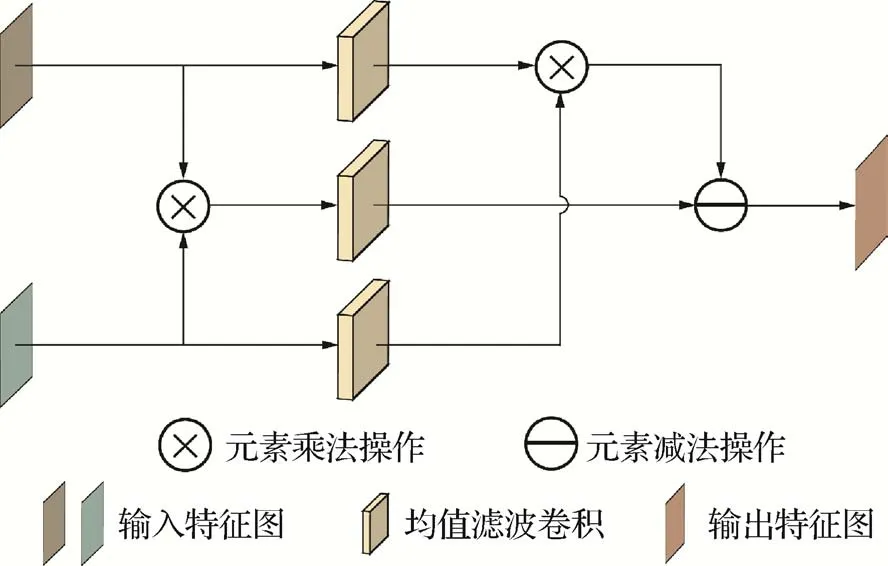
图5 协方差均值滤波模块Fig.5 Covariance mean filtering module
式中,b(·)为均值滤波卷积,卷积核大小均为4 × 4、权值大小相同。对输入的Ql和Pl进行元素乘积,通过均值滤波卷积剔除图像噪声点并保留细节,对Ql和Pl分别经均值滤波卷积去噪,再进行元素乘积,通过减法操作计算协方差均值特征信息Cov(F)。
1.2.2 方差均值滤波模块
方差均值滤波对特征图进行平滑处理,并充分提取低分辨率图像特征信息。将单一变量Pl作为输入,通过如图6 所示的方差均值滤波模块计算方差均值特征信息Var(F),具体为

图6 方差均值滤波模块Fig.6 Variance mean filter module
式中,b(·)为均值滤波卷积操作,卷积核大小均为4 × 4、权值大小均等,Var(F)将作为逐点卷积模块的输入。
1.2.3 逐点卷积模块
多阶段特征融合过程中,图像像素间各通道信息的相关性至关重要。逐点卷积操作可以通过跨通道的方式对特征进行整合,提高综合信息表达能力,采用如图7 所示的逐点卷积模块提取低分辨率线性指导参数Al。
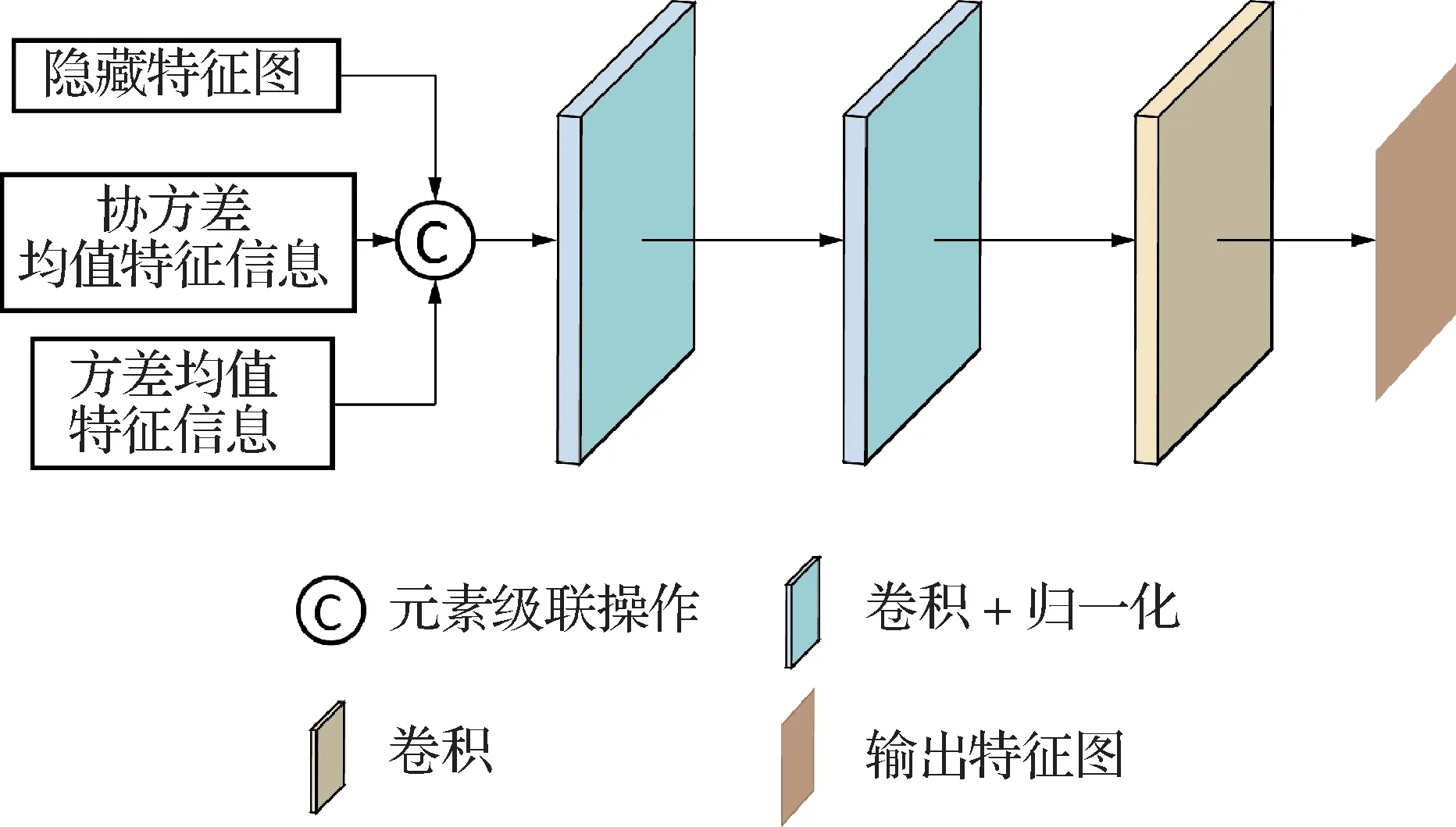
图7 逐点卷积模块Fig.7 Pointwise convolution block
采用隐藏特征图、协方差均值特征信息及方差均值特征信息相结合提取多阶段融合图M,根据得到的多阶段融合图提取每位像素特征,计算逐像素特征图F1。具体为
式中,C(·)为元素级联操作,采用Concat()函数进行级联,(·)表示卷积核大小为1 × 1、步长为1的二维卷积,B(·)为批量归一化(Ioffe 和Szegedy,2015)。最后经过逐点卷积处理输出参数Al,具体为
1.3 损失函数
对输入的视频帧计算蒙版图和前景图的损失,为了加快模型的收敛速度,同时降低离群点的敏感度,采用标准L1 损失函数计算蒙版图α和真值间的损失,具体为
同时,为了平衡视频帧局部信息与全局信息间的差异,引入拉普拉斯损失函数(Hou 和Liu,2019)和时间相干损失函数(Sun等,2021a),具体为
式中,Li(·)为第i层拉普拉斯金字塔,t为时间。采用标准L1 损失函数及时间相干损失函数共同计算前景图F与真值之间的损失,具体为
式中,B(·)表示布尔运算法则,则网络的总损失函数为
式中,M、N1、N2为拉普拉斯损失函数和时间相干损失函数的权重。
1.4 训练方法
采用Pytorch 架构与Adam 优化器进行训练。训练基准网络时,将编码器、金字塔池化模块及循环解码器的初始学习率设置为{0.000 1,0.000 1,0.000 5},批量大小为1。训练精细化网络时,将编码器、金字塔池化模块、循环解码器和高分辨率信息指导模块的初始学习率置为{0.000 05,0.000 05,0.000 1,0.000 2},批量大小为1,采用DeepLabV3 预训练的官方权重初始化特征提取器。采用单张NVIDIA GTX 1080Ti GPU 显卡在3 种数据集上依次训练:在Video240K SD 数据集上训练基准网络,输入帧序列为15,训练8 轮后,在Video240K HD 数据集上训练1 轮精细化网络。此外,为提高模型在处理高分辨率视频上的鲁棒性,在Human2K 数据集上继续训练精细化网络,令精细化网络的下采样率D为0.25,输入帧序列为2并进行50轮训练。由于AIM数据集精度较低,会导致模型训练精度下降,因此将AIM数据集仅用于测试。
1.5 数据集
VideoMatte240K 数据集(Lin 等,2021)给出一系列视频抠图数据。该数据集提供了484 个视频片段,其中384个视频为4 K分辨率,100个为高清分辨率视频,通过AE(adobe after effects)软件生成两组不同分辨率下的同一图像数据集(高清数据集Video240K HD 和标清数据集Video240K SD),包含240 709 幅蒙版图和前景帧。分别采用479 组视频帧用于训练,剩余5组视频帧用于验证。
Human2K 数据集(Liu 等,2021)提供了2 100 幅高精度人体图像,平均分辨率为2 560 × 1 440 像素。采用2 000 幅图像作为训练集,100 幅图像作为测试集。
AIM 数据集(Xu 等,2017)的训练集包含431 幅图像,测试集包含50 幅图像。从中选出269 幅人类图像作为训练集,11 幅人类图像作为测试集,图像平均分辨率为1 000 ×1 000像素。
背景数据集采用Lin 等人(2021)给出的共享背景图,并在百度上抓取8 859 幅背景图像,分辨率均在1 920 × 1 080 像素以上,将其分别按8 832、200、20 的比例构建训练集、验证集和测试集。为增强数据,引入多种噪声到数据集中,并对其作模糊处理,对所有视频帧采用随机裁剪、缩放和旋转等操作进行处理。对前景视频帧进行仿射变换、亮度、对比度和色调变化等操作,并在视频帧中加入帧率变换、随机翻转和跳帧取样等操作,以此增加数据的多样性。
2 实验评估
2.1 评估指标
与Xu等人(2017)评估方法相同,在蒙版图上采用绝对误差(sum of absolute difference,SAD)、均方误差(mean squared error,MSE)、梯度(gradient error,Grad)及连通性(connectivity error,Coon)进行客观评估。视频前景采用均方误差进行评估,此外将MSE、Grad 和Coon 分别缩放至103、10-3和10-3倍,以便更好地对实验结果进行对比评估。
2.2 评估结果
在3种测试数据集(Video240K SD、AIM 和Human2K)上进行实验,表1 给出了多种人像实时抠图结果。由表1 可见,本文方法优于多种结合三分图与背景的方法DIM(Xu 等,2017)、MGM(Yu 等,2021)、MF(Park 等,2022)、OTVM(Seong 等,2022)、AEM(Liu 等,2023)、BGM(Sengupta 等,2020)和BGMv2(Lin 等,2021),在AIM 数据集的测试上各种指标略低于AEM 方法,然而AEM 方法需要通过手动设置三分图作为辅助信息,本文方法只需设置一幅背景图像。

表1 不同方法在多个数据集上的性能对比Table 1 Comparison of different methods on multiple datasets
图8 给出了本文方法与相关方法的可视化实验结果。第1 组结果中,其他方法预测的舞者手部(红色方框)蒙版图较为模糊或为半透明状,而本文方法可有效给出手部清晰的边缘细节。第2 组结果中,与其他的方法相比,本文方法在鲜花边缘处(红色方框)抠图结果更加精细准确。第3 组实验中,其他方法在人像的发丝部分(红色方框)未给出清晰的抠图结果,而本文方法更多地保留了人物的发丝细节信息。最后一组多人抠图实验中,其他方法在人物手臂交叉处(红色方框)未给出正确抠图结果,本文方法可以清晰地预测出人物各自的手臂。由此可见,本文方法可以更好地提取图像细节信息,从而提升人像抠图质量。

图8 可视化实验结果对比Fig.8 Comparison of visual experimental results((a)input images;(b)ground truth;(c)DIM(Xu et al.,2017);(d)MGM(Yu et al.,2021);(e)MF(Park et al.,2022);(f)OTVM(Seong et al.,2022);(g)AEM(Liu et al.,2023);(h)BGM(Sengupta et al.,2020);(i)BGMv2(Lin et al.,2021);(j)ours)
2.3 性能评估
采用Vladislav Sovrasov 测量模型的参数量(parameters)与乘加运算量(GMac)评估网络性能,结果如表2 及表3 所示。可以看出,与DIM、MGM、MF、OTVM、AEM、BGM 及BGMv2 方法相比,本文方法产生的模型参数量更小。处理多种分辨率(reso⁃lution)视频时,本文方法可以达到实时需求(见表3)。采用NVIDIA GTX 1080Ti GPU 进行实验,本文方法在低分辨率(512 × 288 像素)和中分辨率(1 024 × 576 像素)视频上的处理速度分别为49帧/s和42.4帧/s,在HD(1 920 × 1 080 像素)及4K(3 840 ×2 160 像素)视频上的处理速度分别为43 帧/s 及26 帧/s,与同类方法相比,本文方法获得了更佳的实时性。此外,若采用MobileNetV2 作为编码器主干,执行速率将进一步提升,且参数量更小。

表2 模型参数量和大小对比Table 2 Comparison of model parameter quantity and size

表3 不同方法间的性能比较Table 3 Performance comparison between different methods
此外,为探索拉普拉斯损失函数Lαlap和时间相干损失函数(Lαtc、LFtc)的权重M、N1、N2对网络结构的影响。本文进行了定量分析,依次改变权重大小观察其对指标SAD(绝对误差)的影响。如图9 所示,当M为0.2,N1、N2为5时获得的SAD最优。

图9 损失函数权重影响Fig.9 Loss function weight influence
2.4 消融实验
在消融实验中,针对改进的特征提取网络(编码器)、轻量级金字塔池化模块、循环解码器中的残差门控循环单元模块,以及精细化网络中的高分辨率信息指导模块进行消融实验,以验证本文方法的有效性。
2.4.1 编码器的作用
表4 给出了分别采用改进的ResNet50(本文)、ResNet101 和MobileNetV2 网络作为编码器在Human2K 测试集上的测试结果,与后两者相比,改进的ResNet50 可以获取更精细的蒙版图,更适用于本文特征提取的任务。
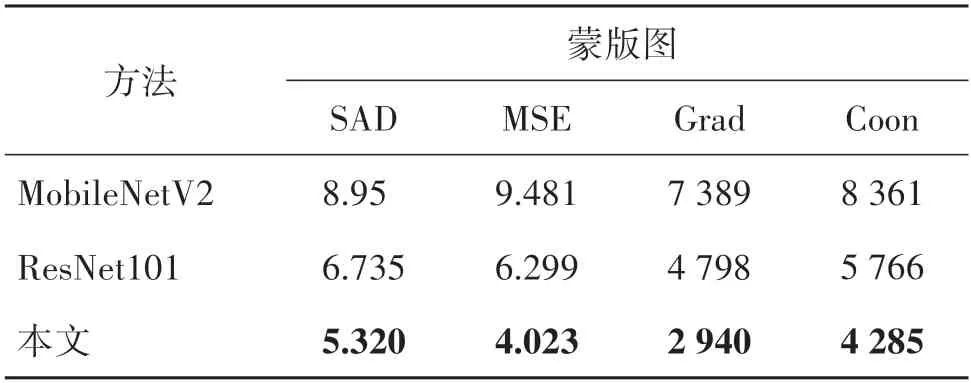
表4 编码器的有效性Table 4 Effectiveness of encoder
2.4.2 金字塔池化模块与循环解码器模块的作用
通过在基准网络中增加相应模块,验证基准网络中金字塔池化模块(PPM)与循环解码器模块(RConvGRU)对最终结果产生的影响,表5 为在Video240K SD 测试集上的测试结果。其中,对于基准网络模型(baseline),网络中未含有PPM模块与RConvGRU 模块;“+PPM”模型为在“baseline”模型中仅增加PPM 模块;“+R-ConvGRU”模型(本文)为在“+PPM”模型基础上增加R-ConvGRU 模块。采用相同的学习率和输入序列帧数训练每种模型,其中特征提取网络均采用改进的ResNet50结构。由表5可见,PPM模块可以提高蒙版图上的所有评估指标,而R-ConvGRU 模块在指标上的提高更加显著,分别在SAD、MSE、Grad、Coon 指标上降低了17.2%、27.3%、32.8%和23.7%。综上,实验结果验证了在PPM 和R-ConvGRU 模块的共同作用下,可以获得更为准确的蒙版图。

表5 PPM 与R-ConvGRU模块的有效性Table 5 Effectiveness module of PPM and R-ConvGRU
2.4.3 精细化网络的作用
为验证精细化网络对高分辨率视频抠图的作用,在Human2K 测试集上进行实验:一种采用不包含精细化网络的基准网络(base),另一种是包含精细化网络的总体网络(overall)。采用与2.4.2 节相同的方法进行实验,结果如表6 所示。由表6 可见,总体网络分别在SAD、MSE、Grad 及Coon 指标上降低了10.1%、19%、12.4%和13.2%,因此验证了在精细化网络的作用下,总体网络可以更好地预测蒙版图。

表6 精细化网络的有效性Table 6 Effectiveness of refined network
3 结论
本文给出一种实时高分辨率的视频抠图方法,采用基准网络中金字塔池化模块提取并融合视频帧的多尺度信息,通过残差门控循环单元模块聚合连续帧间时间信息。通过高分辨率信息指导模块捕获图像中的高分辨率信息,指导低分辨率图像计算高质量蒙版图与前景图。在高分辨率数据集Human2K 上进行实验,结果表明,本文的网络明显优于对比的同类方法,不仅可以获得更精细的人像抠图结果,而且在处理速度上具备较高的实时性,能够为后续高级应用提供更好的支持。此外,本文方法仍存在一定的局限性,将背景作为辅助信息限制了网络在动态背景中的应用,未来将进一步探索动态背景环境下的高分辨率实时视频抠图方法。
