深度伪造及其取证技术综述
2024-02-24丁峰匡仁盛周越孙珑朱小刚朱国普
丁峰,匡仁盛,周越,孙珑,朱小刚,朱国普*
1.南昌大学软件学院,南昌 330047;2.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150006;3.南昌大学公共政策与管理学院,南昌 330047;4.江西省物联网产业技术研究院,鹰潭 335003
0 引言
深度伪造(Deepfake),通常指使用深度学习(deep learning)进行多媒体伪造的技术。Deepfake是一种全新的媒体造假方式,它利用深度学习技术来合成假图像和视频,其出现震惊了世界。恶意使用和滥用该技术进行欺诈活动和虚假传播信息(Shin和Lee,2022)会给各利益相关者带来很大的风险(Murphy 和Flynn,2022)。Deepfake 一词来源于2017 年12月在Reddit 论坛上有ID(identifier)为Deepfakes 的用户,他把通过深度学习将盖尔·加朵的脸用做素材合成的不雅视频上传到了网上。随后,这些应用程序生成的视频和图像越来越多地被用于干预政治活动,从而影响公众舆论(Li 等,2022)。自此之后,Deepfake 成为深度伪造技术的代名词。深度伪造技术不断发展,人们难以分辨Deep⁃fake(Groh 等,2022),其成为商业和学术界研究的热点之一。如图1 和图2 所示,从2018 年到2022 年在谷歌学术上以Deepfake为关键词搜索出的论文数量明显增加,相关Deepfake 的论文从2018 年每年329 篇增长到2022 年的4 150 篇。并且从2023 年初至7 月就已经有2 770 篇Deepfake 相关论文。同时,中国知网收录的以深度伪造为关键词的论文也逐年升高,国内对于Deepfake 这个安全领域的研究也越来越多。
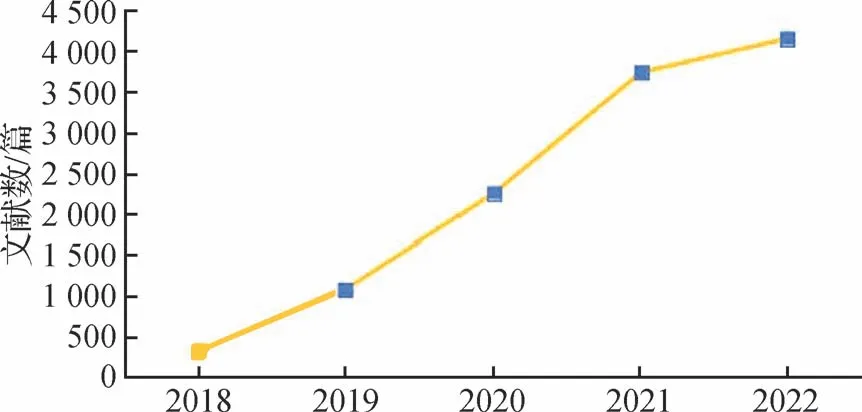
图1 在谷歌学术上以“Deepfake”为关键字检索的2018—2022年的文献数量Fig.1 The number of papers searched on Google Scholar using the keyword “Deepfake” during 2018—2022
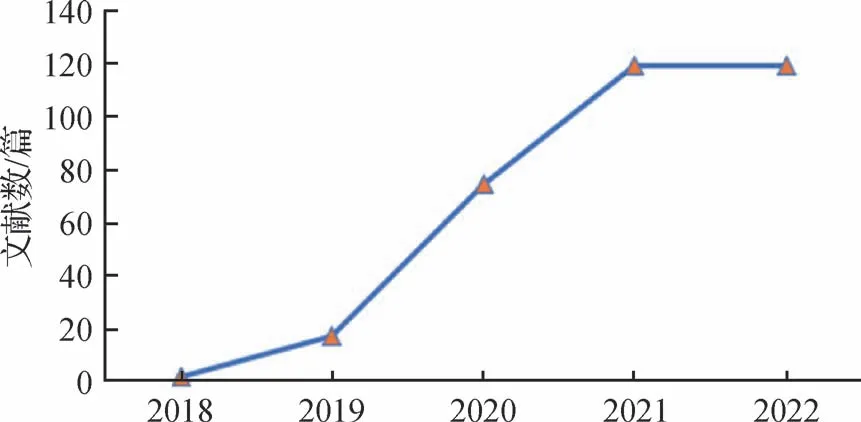
图2 在中国知网以“深度伪造”为关键字检索的2018—2022年的文献数量Fig.2 The number of papers searched on CNKI using the keyword “Deepfake” during 2018—2022
人类面部涉及的社会、政治、经济等方面的敏感性,使得深度伪造技术对社会和个人的安全产生了威 胁(Allcott 和Gentzkow,2017;Dash 和Sharma,2023)。目前,各国在法律上都对相应技术有所约束和监管。如美国在2020 年12 月由特朗普总统签署了《识别生成性对抗网络输出法》,欧盟则在2021 年4月21日提出的《欧洲人工智能方法条例》中明确提出人工智能服务需要履行透明度义务。而我国在2019 年12 月15 日公布的《网络信息内容生态治理规定》中明确指出网络信息内容服务使用者和生产者不得开展违法活动。标志性的工作之一就是在2019 年9 月由Facebook、the Partnership on AI、麻省理工、亚马逊和微软以及来自诸多院校的学者创建的Deepfake Detection Challenge,用100 万美元的总奖金来促进深度伪造检测技术的发展。本文主要对现阶段的深度伪造方法进行总结,以及在基于前人国内外研究综述总结(李旭嵘 等,2021;王任颖 等,2022;谭明奎 等,2021;周文柏 等,2021)的基础上进一步挖掘,详细介绍深度伪造数据集的特点以及伪造方法,另外区别了以前综述分类方法(曹申豪 等,2022;李晓龙 等,2021;李泽宇 等,2023;梁瑞刚 等,2020),分别从输入维度、浅层特征和深层特征对深度伪造检测技术进行分类。本文将讨论深度伪造及检测技术的现状和发展,以及未来可能面临的挑战并提出展望,为今后的深度伪造检测技术的发展提供方向性的指导。
1 深度伪造算法
人工智能的造假并不是完全无中生有,而是从若干样本中学习对应的模式,即为人工智能中的一个大分类:生成模型的产生。其中用到最多的是以自编码器(autoencoder)(Kingma 和Welling,2014)、生成对抗网络(generative adversarial network,GAN)(Goodfellow 等,2020)和扩散模型(diffusion model,DM)(Ho等,2020)为基础的深度伪造算法。
自编码器结构由两个卷积神经网络(convolu⁃tional neural networks,CNNs)组成,分别作为编码器和解码器,如图3所示。
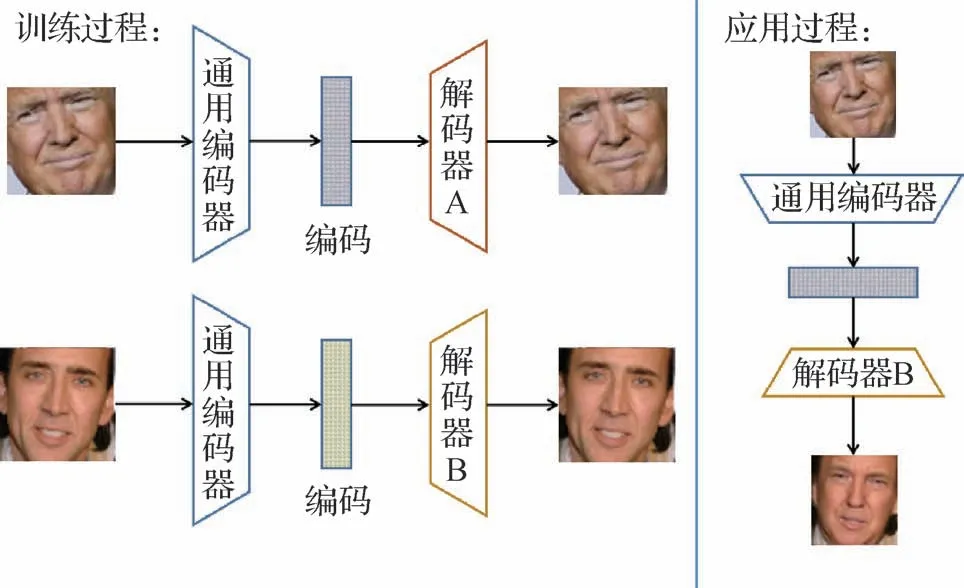
图3 自编码器人脸替换生成过程Fig.3 Face replacement process base on autoencoder
编码器将输入目标的面部图像进行降维,编码成对应面部特征的向量,为了使编码器网络只学习到通用的特征描述,让编码器的参数进行共享(Ding等,2020),即通用同一个编码器。再将提取出来的面部特征向量送入每个原始面部专属的解码器来尽可能地还原面部,在提取特征和还原面部的过程中进行网络学习。在一次自编码器的面部替换过程中,用一个共享参数的编码器来提取广义的目标面部特征后,再用特定的解码器来将相应特征还原到源人脸上。Faceswap(Korshunova 等,2017)、Deep⁃FaceLab(Perov 等,2020)、Dfaker(Deepfaker)(Jiang等,2020)、DF-VAE(Deepfake-variational autoencoder)(Rössler 等,2019)、Deepfake tf(Deepfake on tensorflow)(基于tensorflow 的Deepfakes)等都采用了这种方法。
生成对抗网络的结构则使用了一个生成器和一个判别器,生成器类似于自编码器的解码器,将输入的噪声转换成图像,与真实存在的图像送入判别器进行辨别,如图4所示。
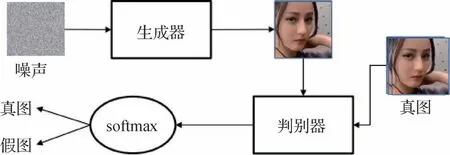
图4 基于GAN生成图像过程Fig.4 Image generation process base on GAN
判别器和生成器均使用反向传播来优化参数,当判别器尚能分辨生成器输出与现实存在图像时,对生成器的参数进行优化以提升生成图像质量;对判别器的参数进行优化以提升判别器分辨准确率,达到纳什均衡时模型优化至最佳。针对深度伪造领域(Ding 等,2023b),基于这两种技术也有更好的生成效果、更多生成选择的复杂算法,如,使用基于风格生成器来分离特征以操纵特定属性的StyleGAN(Karras 等,2019)、用2D 输入重建3D 模型人脸的MoFA(Tewari 等,2017)、脸部修饰 的DG(dualgenerator face reenactment)(Hsu 等,2022)、适合换脸的RAFSwap(region-aware face swapping)(Xu 等,2022a)、DCGAN(deep convolution generative adver⁃sarial networks)(Radford 等,2016)、WGAN(Wasser⁃stein generative adversarial networks)(Arjovsky 等,2017)、WGAN-GP(Wasserstein generative adversarial networks with gradient penalty)(Gulrajani 等,2017)、PGGAN(progressive growing GAN)(Karras 等,2018)、BIGGAN(Brock 等,2019)、self-attention GAN(Zhang等,2019)、spectral normalization GAN(Miyato 等,2018)等。表1为各种伪造工具的总结。

表1 常见的伪造工具总结Table 1 Summary of common Deepfake tools
另外一种为扩散模型,它有两个过程。一个是正向过程,也称为扩散过程,在此过程中设置不同的均匀超参数分别作为扩散过程中的权值,然后通过重参数化的方法逐步加入噪声,使最终的图像呈标准高斯白噪声;另一个过程是逆扩散过程,也称为反向过程,通过不断采样从噪声慢慢恢复成原来的图像。扩散模型的骨干网络一般采用输入和输出相同尺寸的U-Net 网络。在采样过程中如果在中间插入要更改的图像可以生成相同风格的图像,以达到换脸的效果。扩散模型生成的图像质量较好(Dhariwal和Nichol,2021),容易控制图像特征的生成(Rom⁃bach 等,2022)。这也是最近很热门的人工智能(artificial intelligence,AI)绘图和文本转图 像(Ramesh 等,2022)所采用的主要图像合成技术之一,已经广泛运用于多模态生成任务当中,如DALLE(dalle)(Ramesh 等,2021)、CogView(recogniz⁃able view)(Ding 等,2021)、DALLE2(dalle2)(Ramesh等,2022)、CogView2(recognizable view)(Ding等,2022b)和Imagen(image generation )(Saharia等,2022)。
2 深度伪造数据集和评价指标
2.1 数据集
作为模型知识的来源,一个好的数据集对模型性能是至关重要的。同样,在深度伪造检测任务中,数据集也经过了不断的发展来弥补过往的缺陷。数据集的真实视频和图像的采集前期主要来自网络,后期主要请演员根据不同要求拍摄;而伪造视频和音频主要方法则可划分为5 类:人脸替换、唇部同步、姿势变换、属性编辑和完整人脸生成。
1)人脸替换操作包括将视频和图像(源)中一个对象的脸替换为另一个对象(目标)的脸,如图5 所示。与整个人脸合成不同,人脸替换中目标是生成逼真的假脸。对于整个换脸过程大部分都需要经历如下阶段:检测人脸、人脸的裁剪、五官特征提取、将目标人脸特征替换原始目标的人脸特征,最后将裁剪的人脸混合到原始图像和视频中。主要深度伪造工具有FaceSwap(faceswap)(Korshunova 等,2017)、DeepFaceLab(Deepfake face lab )(Perov 等,2020)、FSGAN(Nirkin 等,2019)、Face2Face(face to face )(Thies 等,2016)等。对于这些过程中的每一个阶段,都可以改变方法来提高假视频的质量。
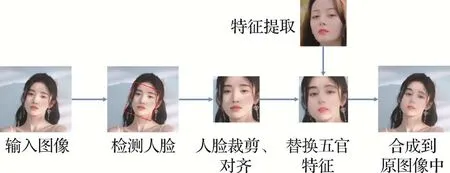
图5 人脸合成的一般步骤Fig.5 General procedures for face replacement
2)唇语同步分为从音频到视频同步、操纵原始人脸的唇部和目标音频同步以伪造他人说话,通常也伴随着语音上的伪造,常用ATFHP(Yi 等,2020)和Wav2Lip(wave to lip)(Chung 和Zisserman,2017);另外一种是从文本转化为音频再到视频的同步(Jia等,2018;Sun等,2022)。如Song等人(2022a)通过结合一个文本到语音的联合系统和同步语音的人脸生成模型来合成视频。大部分唇语同步首先将要控制的视频以及一段新的音频记录作为方法的输入;然后通常会使用一个递归神经网络,如长短期记忆(long short-term memory,LSTM)(Sabir 等,2019;Chen 等,2022a)或门控循环神经网络(gated recur⁃rent unit,GRU)(Cho 等,2014)来学习从原始音频特征到口型的映射;再然后,根据每一帧的嘴形特征生成视频中高质量的嘴形纹理,并将其与3D姿势对齐再进行合成,以创建与输入音频轨迹匹配的新视频,从而产生人眼不可分辨的结果。奥巴马和特朗普的演讲造假视频就是很好的例子。
3)姿势变换主要是操纵目标头部和肩部完成特定的动作,被大众使用最多的如恶搞唱歌、表情修改和动作同步(Chan 等,2019);通过流行的GAN 架构运用在图像层面,最流行的技术如Face2Face(Thies等,2016)、NeuralTexture(Thies 等,2019)和GC-AVT(granularly controlled audio-visual talking heads)(Liang 等,2022),这些方法将视频中一个对象的面部表情替换为另一个对象的面部表情。这种类型的操纵在增加趣味性的同时也可能会带来严重后果,例如扎克伯格说他从未说过的话的流行视频。
4)属性编辑也称为面部编辑或面部修饰,对人脸的特定属性进行指向性修改,如更改目标年龄、更改面部特征、皮肤的颜色和发型等,还可以增加眼镜和一些动物耳朵特效等。大部分这种操纵过程通常通过GAN 网络进行,例如StarGAN(Choi 等,2018)、StyleGAN(Karras 等,2019)。消费者可以使用这项技术在虚拟环境中试穿各种各样的产品,如化妆品、眼镜或发型以及各种道具如ZAO、抖音、美图秀秀等手机换脸美颜软件。网络上各种Deepfake图像以及视频大部分都是其中一种或多种的混合。
5)完整人脸生成会创建整个不存在的人脸图像。在早期的基于GAN 的生成模型中,通过生成器和判别器的对抗,可以将输入的噪声生成现实不存在的整张人脸。PGGAN(Karras 等,2018)提出了一种用于生成器和鉴别器的渐进训练方案,该方案可以产生高质量的图像。而StyleGAN 通过借鉴风格迁移重新设计生成器,在人脸图像合成方面取得了显著效果。
一般地,将深度伪造数据集分为两代,如图6 和图7所示。

图6 以DF-TIMIT数据集为例的第1代人脸伪造数据集采样Fig.6 Examples of images sampling from a first generation face forgery datasets(DF-TIMIT datasets)

图7 以DFDC数据集为例的第2代人脸伪造数据集采样Fig.7 Examples of images sampling from a second generation face forgery datasets(DFDC datasets)
在深度伪造检测技术发展初期,第1 代的数据集由于研究热度不高,往往数量不够大,内容质量也不够好。源视频通常来自视频网站或者现存人脸数据集,这会带来版权和隐私上的争议。而伪造视频的方法则来自Deepfake软件或者一两种基于自编码器或者GAN 的面部更换方法,常常包含可见的面部修改边界、颜色过渡不自然、原始人脸残存痕迹等明显缺陷,这在本文的训练中会给模型带来无用的经验,弱化模型的泛化能力。如早期的UADFV(Yang等,2019)、DF-TIMIT(Korshunov 和Marcel,2018)等都存在视频和图像少、真假视频和图像质量都不高、身份特点不超过50 个等缺陷,大部分视频都是来源于网上,往往人眼就能分辨出;使用的合成方法只有一到两种,现代面部伪造手段的多样性没能表现出来。数据集FF++(FaceForensics++)的出现解决了很多问题,FF++是第1 个包含1 000 个真实视频和4 000 个假视频的大型数据集,也是目前大部分Deepfake 检测和反取证主要通用数据集,图像和视频均取自于YouTube,通过两种基于计算机图形方法和两种基于机器学习的方法合成,运用了Face2Face、FaceSwap、DeepFakes及NeuralTextures换脸算法。1 000 个原始视频中的每一个都通过所选的4种方法进行处理,总共产生5 000个剪辑。
第2 代的人脸伪造数据集则具有更好的伪造效果和图像清晰度,背景变得更多样,并启用了付费演员进行拍摄,使用多种修改算法以及全脸替换、随机生成人脸、修改人脸特征、唇形合成等多种修改任务来增加伪造手法多样性,并且添加多种扰动以增加模型鲁棒性,数据集规模和早期相比也不是一个量级(见表2)。如DFDC(Deepfake Detection Challenge)(Dolhansky 等,2020)包 含960 多个不同主题和10 450 多个视频。为了保证数据集的多样性,获取原始视频片段需要在不同的环境中,合成片段的方法也多到8 种,并且参与者的分布不受年龄、性别或种族限制,从而增加了样本的多样性。然而,DFDC数据集并非没有缺陷。数据格式不一致,例如分辨率和持续时间因剪辑而异。最近的DeeperForen⁃sics-1.0(DF-1.0)(Jiang等,2020)也是Deepfake检测热门数据集,邀请了100 名付费演员录制,其中1 000 个目标视频取自于FF++数据集。伪造方法单一,通过将每个源视频依次交换到10 个目标视频上,就可以合成1 000 个对应假视频。使用7 种扰动方法分别对真实和虚假视频进行调整增强,从而增加了泛化能力以及多样性。最终分别创建了50 000个真实片段和10 000个假片段。以前的数据集大部分是欧美人种为主,为了应对亚洲人种视频和图像在现有的Deepfake 检测数据库中数据量不足的问题,KoDF(Korean Deepfake detection dataset )(Kwon 等,2021)数据集的参与者主要是韩国人。包含403 名演员的175 776 个假剪辑视频和62 166 个真实剪辑视频,为了增加多样性,视频场景多样,摄像机角度、镜头长度、录制位置、背景、道具组成和灯光方面引入了细微的变化。最后,数据集采取各种方法措施,根据参与者的年龄、性别和身份,更好地管理数据分布使得数据均匀分布。Deepfake 合成的假视频由6 种不同的合成模型生成。至今KoDF 是公开可用的Deepfake检测数据集中最大的一个。前面提到的所有数据集仅专注于深度伪造视频而没有专门去合成音频,FakeAVCeleb(Khalid 等,2021)包含深度伪造视频和相应的唇同步合成音频,其中的真实视频的数据源来自VoxCeleb2(voice on celeb dataset)数据集,使用了一种基于迁移学习的实时语音克隆工具(real-time-voice-cloning,SV2TTS)生成克隆的音频。鉴于以前的音视频深度伪造数据集规模小,LAV-DF(localized audio visual Deepfake)(Cai 等,2022)是一个新的大规模公共视听数据集,大量的同步伪造音频和视频片段被用于替换与原始节点相对应的原始音频和视频片段。
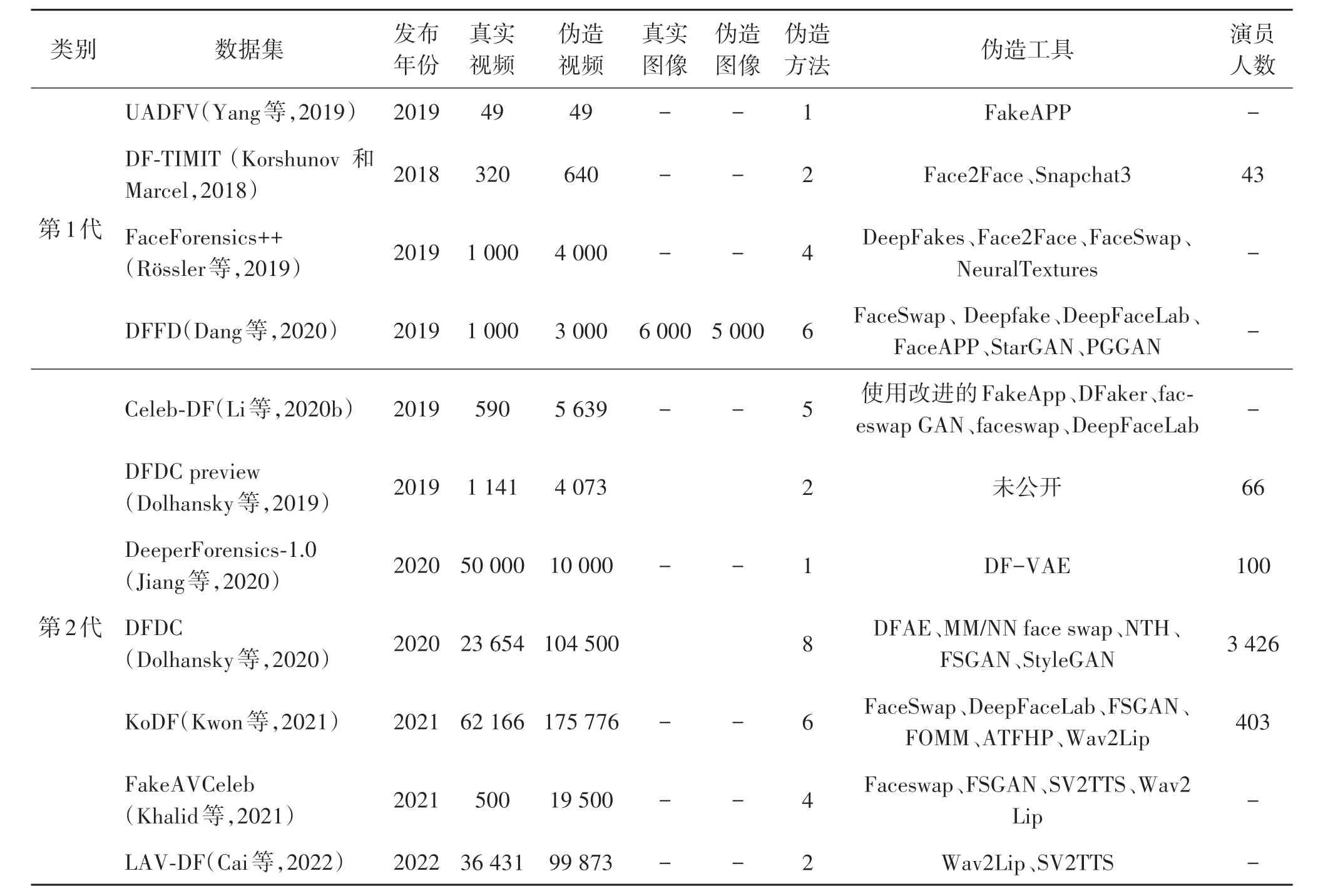
表2 第1代和第2代深度伪造数据集属性对比Table 2 Comparison of the content of first and second generation deep forgery datasets
当然,深度伪造检测数据集尚未发展完善,至今仍不断有其他工作补足先前数据集的不足,如:采用互联网上流行的伪造视频(Zi等,2020)、添加可能欺骗模型的对抗性攻击噪音样本、添加新的面部合成技术、添加特定人群的样本以改善特定人群的检测性能等。多种数据集的存在也提供了验证检测模型泛化能力的空间。
2.2 评价指标
在深度伪造检测评价中,准确率、AUC(area under the curve)(Bradley,1997)和ROC(receiver operating characteristic)曲线被广大研究者所采用。准确率可以表示为
式中,每个Deepfake 检测数据集都包含真实样本和虚假样本,经过检测器可能会将真实样本判定为假样本或为真样本,前者为真正例(TP),后者即为假反例(FN);同理虚假的样本被检测器预测为真实的就称为假正例(FP),预测为反例即为真反例(TN)。
AUC 是ROC 曲线下的面积,这是一个常用的性能考核评价指标(谢天 等,2023),用于评估不同阈值下的分类,显示模型在不同类别之间的区分程度。ROC 越光滑拟合的概率就越小,AUC 越高,越能覆盖整个区域,即越接近1,模型在正确预测每个类别方面就越好,更容易分离也更好分辨。表3 和表4分别展示了近几年深度伪造人脸算法在FaceForen⁃sics++(FF++)数据集上对应的4 种伪造方法的实验结果和在FaceForensics++数据集上训练、跨数据集检测的实验结果。可以看出,现在深度伪造检测器在FaceForensics++数据集上的AUC 分数已经非常高,提升分数已经很难(表3),但在跨数据集检测能力方面还有很长一段距离要走(表4)。
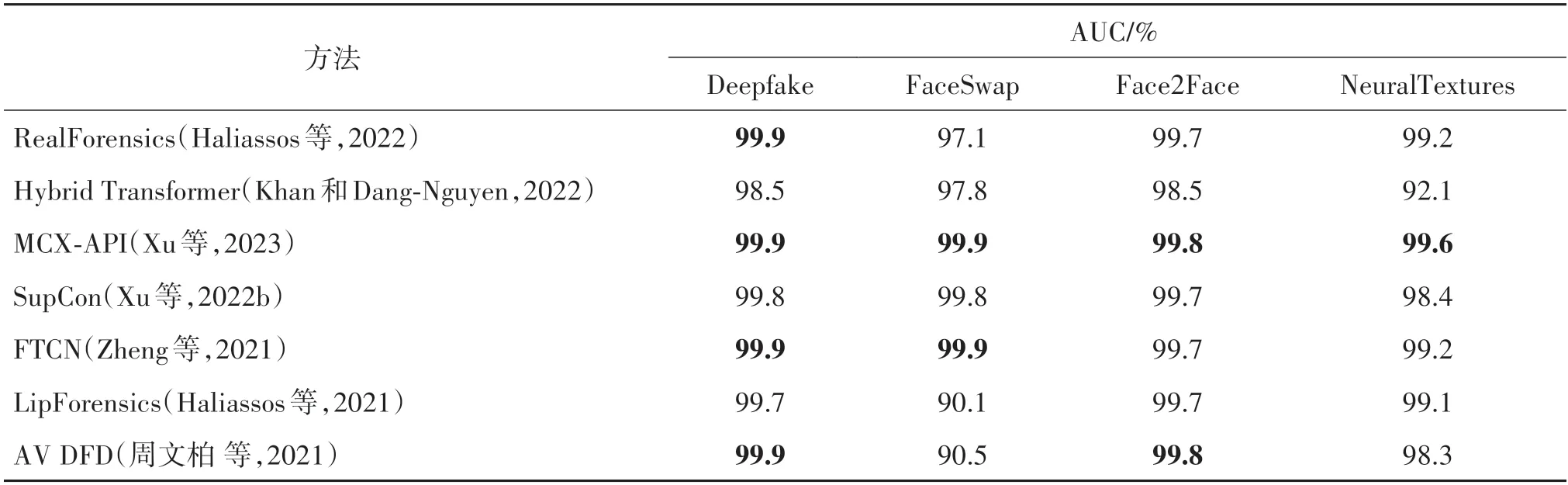
表3 各模型在FaceForensics++数据集上性能比较Table 3 Performance comparison of each models on FaceForensics++datasets

表4 各模型、分类器在FaceForensics++数据集上训练的跨数据集评估比较Table 4 Cross-dataset evaluation comparison of each models,classifiers are trained on FaceForensics++datasets
3 深度伪造检测技术
深度伪造检测技术以图像、音频或视频作为输入来判断是否为伪造产物。相对于传统的移动复制伪造检测(Wang 等,2010;Yang 等,2017),这里从几个角度对主流的深度伪造检测技术进行分类,如图8所示。

图8 深度伪造检测技术分类方法及类别Fig.8 Classifications of Deepfake detection techniques
3.1 输入维度
从输入维度上分类,可以分为3类:
1)图像或视频关键帧输入。将图像或者抽取视频关键帧进行输入(Li等,2021),从视觉表现上对输入进行判断(Lee 等,2022)。此种方法最常用,因为容易推广到其他计算机视觉分类模型中,且大多数深度伪造视频产物为逐帧图像操作(Zhu 等,2018;Wang 等,2022b)。Chen 等人(2016)使用最初为静态图像隐写分析而构建的特征提取器从运动残差中提取造假特征。祝恺蔓等人(2022)从视频流直接提取一定数量的关键帧,避免了帧间解码的过程;使用卷积神经网络将样本中单帧人脸图像映射到统一的特征空间来做最终的检测判决。同时也通过恢复空间特征并且增强纹理特征来提高低分辨率视频的检测性能(Li 等,2023)。基于图像或视频关键帧这种方法与使用其他输入维度的方法比较,网络结构、操作流程相对简单,不需要对视频进行大量的抽帧预处理,减少训练过程的过度采样和冗余信息,网络模型小的计算资源相对较少,通过多级特征融合在单一维度上操作可以更好地挖掘网络架构的性能,也是检测图像数据集最有效的方法之一。
2)视频连续帧输入。输入连续多个帧以使模型感知到真实视频和虚假视频中帧间关系的差异(Zhang 等,2022;Xu 等,2021),如Gu 等人(2022b)的方法用多个连续帧片段作为输入,并提出了一种新的采样单元snippet,还精心设计了片段内不一致性模块(intra-snippet interaction module,Intra-SIM)和片段间交互模块(inter-snippet interaction module,Inter⁃SIM)来捕捉片段内和片段间的信息差异。Hu 等人(2022)通过帧间推理来检测视频造假。视频连续帧输入方法注重前后帧不一致信息,对于插帧修改造假方法有很好的检测效果。通过检测视频连续帧能更好地反映视频造假的不一致信息,专注于视频的时空特征,更深入研究局部和长期视频帧序列编码的不一致来提高检测的准确率。但是这种方法需要提取连续的相似帧,存在较多的冗余信息,增加计算资源。
3)视频图像和音频同步输入。主要从输入的视频中提取视频帧和音频,然后融合这两种模态的相应提取特征来进行检测分析(Gu 等,2021;Elpeltagy等,2023)。如Zhou 和Lin(2021)的方法使用了视频帧和音频双数据流输入以捕获伪造视频在音视频之间不同步的缺陷。Cheng 等人(2022)提出声音和脸部一起同步检测。Cai 等人(2022)提出了一种边界感知时间伪造检测(boundary aware temporal forgery detection,BA-TFD)的多模式方法,通过串联视频编码器和音频编码器,再经过融合模块的输出生成片段来检测视频的不一致。视频图像和音频同步输入方法善于捕捉多模态的信息,在不同维度并行处理,在多个通道上检测特征的不一致性,通过综合分析来判别视频伪造(Ding等,2019),在检测方面往往会有出色的表现,但是网络结构比较庞大且复杂,占用大量计算机资源。
3.2 检测特征
深度伪造检测技术从检测技术上可以分类为浅层特征和深度特征。前者主要是基于传统的机器学习方法和统计学方法,后者主要是采用了深度神经网络进行深度学习来获取特征,例如RNN(recurrent neural network)和CNN。
3.2.1 浅层特征
深度伪造检测技术在浅层特征上可以分为两类:传统机器学习模型和统计学方法。
1)传统机器学习模型用于分类预处理有很好的效果(Li等,2015)。Zhang等人(2016)提出了一种基于马尔可夫的图像拼接检测方法。Guarnera 等人(2020a)的方法使用期望最大化算法(expectation maximization,EM)提取图像中隐藏的卷积痕迹,再送入KNN(K-nearest neighbors)、SVM(support vector machine)(Wang 等,2017a)等分类器中进行判断,能有效区分不同体系结构和相应的生成过程产生的伪造视频。Yang 等人(2019)基于使用68 个面部位置标志估计的头部姿势与面部中心区域的头部姿势之间的差异来训练SVM 分类器,以区分真实图像或深度伪造视频。Akhtar 和Dasgupta(2019)提出一个框架,首先从给定的输入人脸视频中提取单个帧,并通过特定局部图像描述符提取特征,最后将提取的特征馈送到SVM 分类器,以确定最终的二进制决策是否为伪造视频。传统机器学习方法在图像分类任务中存在特征提取困难、依赖于人工特征工程、难以处理高维数据、无法捕捉局部和全局信息以及对数据分布假设过于简单等缺点,在Deepfake 检测中往往会作为一种辅助方法(Wang等,2017b),并与深度神经网络结合使用以便更好地检测伪造视频和图像。传统机器学习的检测方法在检测深度伪造任务上已经很少使用了。
2)统计学方法在深度伪造检测技术运用地比较少,大部分会与其他深层特征检测方法一起使用。Lu 等人(2008)提出了一种使用高阶图像统计和径向基函数(radial basis function,RBF)神经网络的图像检测方案。Nguyen 和Derakhshani(2020)通过统计生物特征眉毛匹配分数作为检测Deepfake 的方法。Guarnera 等人(2020b)提出了一种基于期望最大化算法从图像中提取Deepfake 指纹的方法,以检测图像生成过程中由GANs留下的卷积痕迹。统计学方法通常依赖于手动设计的特征提取器,这可能无法捕捉到图像中复杂、抽象的特征。统计学方法通常需要计算数据的统计量,对于大规模数据集来说,计算复杂度较高,容易导致计算资源和时间的限制。
3.2.2 深度特征
目前,深度伪造检测技术大部分还是基于深度特征,如表5所示。本文将深度特征分为3类:
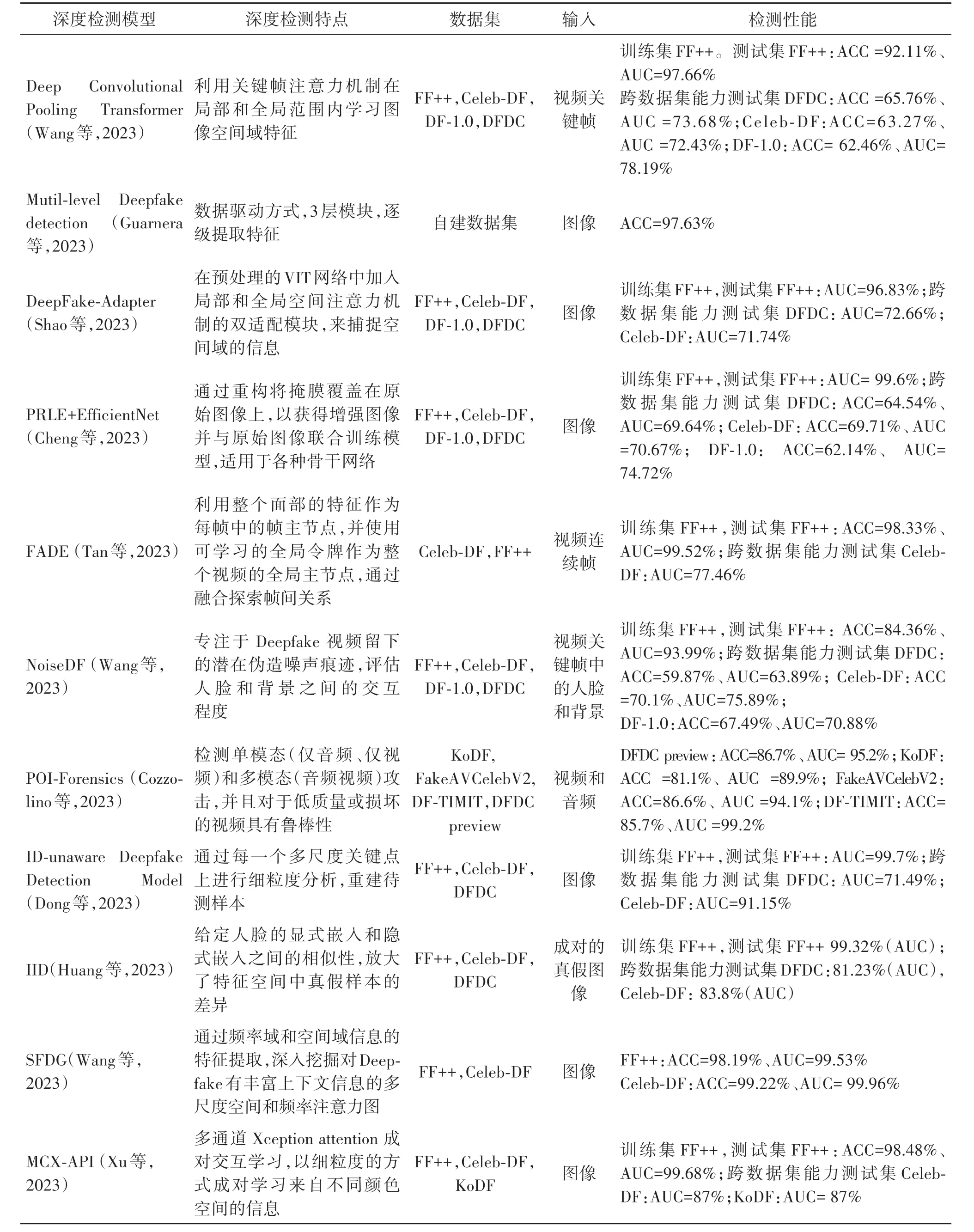
表5 2023年图像视频深度伪造常用检测方法总结Table 5 Summary of commonly used detection methods for image and video Deepfake in 2023
1)基于频率域的方法。Frank 等人(2020)使用GAN 生成图像和真实图像在离散余弦变换(罗向阳等,2007;Lu 等,2009)后加入一些扰动消除频率级别伪影,然后将原图和假扰动的图像一起给分类器判别,具有很强的泛化能力。Gu 等人(2022a)提出了一个渐进式增强学习框架,来利用RGB 和fnegrained 频率线索;它主要对RGB 图像进行fnegrained 分解,以便在频率空间中完全分离出真实和伪造的痕迹。Song 等人(2022b)提出了一种新的跨域人脸伪造检测深度学习框架,研究来自RGB 和频域的互补线索,从而挖掘潜在的一致性。Tian 等人(2023)设计了一个空间频率特征融合模块,对RGB频率信息进行综合融合,并且引入一个通道注意力模块来组装局部和全局上下文,以克服局部工件和全局特征上潜在的语义不一致。基于频率特征的方法的优点是可解释性比较强,抓住了生成过程上的不一致缺陷(杨少聪 等,2022),修复这些缺陷需要对生成模型进行修改。基于频率域的方法可以捕捉到频率域呈现的异常特性(Zhou 等,2023),对于相邻像素点变化幅度差异的敏感特性可以更好地帮助分析Deepfake 视频异常中的高频分量。相对地,基于频率特征的方法抗干扰能力较弱,对于带有扰动的输入判别能力会下降,如上采样、下采样和噪声等。
2)基于时空域的方法。视频可以视为帧序列和同步的音频信号具有时序性和空间信息,在伪造视频生成过程中往往只注重人脸位置和特征的匹配,这就会出现违反物理规律和人体生理学的破绽(Wang 等,2023)。这些破绽的解释性也比较强,有的能通过人眼直观发现。例如Amerini 等人(2019)使用帧间运动差异构成的光流场送入卷积神经网络进行训练,判断是否为深度伪造视频。Cozzolino 等人(2021)提出了ID Reveal 方法,通过度量学习和对抗性训练方法相结合的方式,学习视频中基于时间维度的面部特征,特别是一个人说话时的动作,不需要任何合成的训练数据,只需要在真实视频上测试训练,此外还利用了高级语义特征提高鲁棒性和泛化性。Xia 等人(2022)通过深度伪造视频生成时信号层面的失配所产生的异常来检测造假,如图像失配和音频视频同步的失配。Coccomini 等人(2022b)提出 了MINTIME(multiidentity size-invariant times⁃former)用来捕捉空间和时间异常,能够处理同一视频中多人的问题和捕捉面部大小的变化。Hu 等人(2023)提出了一种新的Deepfake 检测模型Deep⁃fakeMAE,该模型可以利用面部所有部位之间的一致性。基于时空域的方法优点在于解释性和直观性很强,能使非技术人员也明白其取证原理。缺点则是强烈依赖于几个特征,泛用性受到了限制,例如文中基于耳部特征的取证方法对于遮住耳朵的视频则无法取证。
3)基于重建学习的方法。该方法用真实样本训练网络模型,并直接将重建误差较大的样本识别为深度伪造产物。Cao等人(2022)提出了一种基于重建分类学习的深度伪造检测框架,用重建差异突出图像上伪造痕迹的信号,并将其输入分类器进行伪造检测。Shiohara 和Yamasaki(2022)提出了一种自混合图像(self-blended images)重建合成方法来训练模型,用于检测混合源图像和伪造图像之间的边界不一致。Shi 等人(2022)先通过掩蔽图像建模(masked image modeling)在真实人脸数据集上训练模型,然后将模型应用于伪样本来重建样本,利用输入人脸和重建人脸之间的差异进行分类。彩色化和超分辨率(He 等,2021)也被用于真实样本的重建目标。重建学习的方法目前比较新颖,可以通过重建学习放大伪造产物的伪影,对于提升检测器的性能有很大帮助。但是重建学习方法需要重新采样生成中间样本,过程复杂,检测成功率也完全取决于重建样本的质量,如果不能很好地选择重建的特征,检测的效果可能会恶化。
4)数据驱动方法。这类检测方法不针对特定特征,而是用监督学习的方式将真实视频和伪造视频送入模型进行训练。这种方法类似于深度学习上的图像分类问题,将特征交由网络自身提取和学习,只是这里的分类为真实视频和伪造视频两种。早期数据驱动的检测方法对深度学习的标准模型进行重用,对于网络设计和视频输入也没有进行特殊的处理(Mo 等,2018;Wang 等,2019)。然而取得的效果并不差,如今大多数新的数据驱动方法都以Effi⁃cientNet(efficient net)(Tan 和Le,2019)和Xception(extreme inception)(Chollet,2017)为基准进行性能参照。后期工作则出现了对标准深度模型的块进行改良,例如Liu等人(2020)提出的GramNet(gram net⁃work )中设计了并行嵌入的Gram块并加入卷积神经网络,从而更好地捕捉全局图像纹理特征,以提高对深度伪造视频的泛化性和鲁棒性。与深度神经网络作用于其他计算机视觉任务一样,使用类似ResNet(residual network)(He 等,2016)的思想对神经网络块进行堆叠,在更大的数据集上能产生更好的效果。标志性的如在Deepfake 检测挑战中,第1 名的解决方案在模型结构上使用了多个EfficientNet 块,并且在训练上加入了大量数据增强以及对部分图像进行蒙版和遮盖以提升泛化能力。Guarnera 等人(2023)通过收集由9 种不同的生成对抗性网络架构和4 种额外的扩散模型生成的原始图像和伪图像的专用数据集进行分类训练来解决不同的深度伪造检测和识别任务。Hussain 和Ibraheem(2023)通过将卷积神经网络与Jaya 算法优化相结合,通过大量的数据集训练来精确检测深度伪造视频。数据驱动方法的优点在于不针对特定特征,网络能学习到人们观察不到的潜在伪造痕迹,因此泛化能力较强,也能较好地与新出现的深度学习方法进行结合;缺点则在于其解释性不够好,对数据驱动深度伪造检测方法的推广和改进带来了困难。
4 未来挑战和发展前景
尽管已有的深度伪造检测技术都表现出优越的性能,但还有许多潜在的未来挑战(Myvizhi 和Pamila,2022;蔺琛皓 等,2023)和发展角度值得完善和研究。
1)跨数据集的泛化能力。对未见过的数据追求同样优秀的准确率是所有计算机视觉任务所追求的目标。目前,评估检测模型的跨数据集的泛化能力主要通过训练集和测试集采用不同数据集来对比(Nadimpalli和Rattani,2022)。但随着伪造技术的进步,检测技术需要有更稳健更精准的分辨新的深度伪造产物的能力(Wang 等,2022c)。未来可以沿着Chen等人(2022b)使用类似GAN 的生成对抗结构进行自监督学习;或Jia等人(2022)基于几个自动编码器模型引入一个新的数据集等方向来提高模型的泛化能力和鲁棒性。
2)更强的取证能力。目前,大多数深度伪造检测工作还仅仅是将其作为一个二分类的问题。但作为数字取证的一个课题,本文希望检测结果能更加精准,同时也能追踪溯源(Liu 等,2019)。最近的研究将加密图像(Qian 和Zhang,2016)和图像隐写技术(Wang 等,2017a)也运用到检测中来提高检测性能,如Yu等人(2021)先训练了一个图像隐写(Zhang等,2014;Qin 等,2013)的编码器和解码器,以将人工的“指纹”和数字水印(Li 等,2011;Qin 等,2012;Wang等,2018)嵌入到用于训练的图像中,从而更简单高效地对深度伪造产物进行检测和溯源。此外,研究人员也探索从多角度提升深度伪造检测效果。Yang 等人(2022)提出了 DNADet(Deepfake network architecture attribution )模型来研究Deepfake 网络体系结构,在体系结构层次上对造假图像修改的机制。Hasan和Salah(2019)使用区块链(Tan等,2022)和智能合约的方法来对多媒体内容进行认证,帮助用户溯源以避免被伪造内容欺骗。Ding 等人(2023a)提出可以通过消除对抗性干扰来净化反取证图像。Liu 等人(2021a)采用3D 神经网络融合时间维度上的空间特征一起检测视频。此外追求轻量级深度伪造检测模型也是提高检测器性能的一个好方法(卓文琦 等,2023)。
3)反取证工作。随着深度伪造检测的能力不断增强,相应地,对检测技术进行反取证也是重要的课题之一(Ding 等,2022a),对深度伪造检测的反取证同样也是提升深度伪造检测能力的一部分。近年来已有对现有深度伪造检测算法进行对抗性攻击的研究,例 如Neves等人(2020)的GANprintR(GANfingerprint removal approach)就针对能有效被捕捉的GAN 生成伪造图像的“指纹”进行消除,能在保持人脸质量的同时对捕捉指纹的检测算法进行欺骗。Ding 等人(2022a)提出了用一个GAN 模型作为反取证工具,设计了一个辅助的监控模块,在反取证效果中取得巨大进步。Gandhi 和Jain(2020)则使用快速梯度符号法和Carlini and Wagner 攻击检测器,检测器的准确率从原始样本上的95%在受干扰样本上下降到27%。Qian 和Zhang(2014)去除了梳状直方图的指纹和块伪影提高反取证能力。Peng 等人(2022)提出了一种基于双向转换生成对抗网络(bidirectional conversion generative adversarial net⁃work,BDC-GAN)的计算机生成和自然面部图像之间的双向转换用于反取证。
4)其他形式的深度伪造。目前深度伪造检测工作主要着眼于人脸在视频和图像上的篡改工作,但深度伪造在其他领域的产物也是潜在的问题。在音频领域,目前最重要的伪造音频检测(Cozzolino 等,2022;Zhang 等,2021;Tak 等,2022)比赛ASVspoof(automatic speaker verification spoofing )中已经加入了用深度伪造技术生成的Speech Deepfake 检测任务。在国防安全上,深度伪造技术能对卫星图像进行伪造(Zhao等,2021a),这严重威胁到了国家安全。更多潜在的领域中一旦出现深度伪造的产物(Dong等,2022b)都要有相应的检测算法进行取证和约束。最近,ChatGPT(chat generative pre-trained transformer)火爆网络,它在文字处理、智能对话、文字润色和回答问题各方面几乎能达到一般学者水平,但是回答问题的答案有些是凭空产生的,没有根据,缺少引用。在给人们带来便利的同时也在误导人们的言论(Shen 等,2023)。Gravel 等人(2023)尝试去评估ChatGPT 在回答各种医学问题时提供的答案和相应的参考资料的质量。
5)计算机视觉和人工智能发展。深度伪造和检测技术离不开计算机视觉和人工智能技术的发展,结合领域内的前沿技术能促进深度伪造检测技术的更新以应对各方面的挑战。如前几年称霸自然语言处理领域的BERT(bidirectional encoder representa⁃tions from Transformers)(Devlin 等,2019)架构和LSTM(long short-term memory networks),随着去年的Vision Transformer(Dosovitskiy 等,2021)和Swin Transformer(Liu 等,2021b)等工作引入到计算机视觉领域并大显身手,同样地,有学者将其引入到深度伪造检测方法中(Coccomini 等,2022a;李颖 等,2023),如Khormali 和Yuan(2022)提出的DFDT(Deepfake detection Transformer )使用Vision Trans⁃former 搭建了一个端到端的深度伪造检测框架。也有学者综合各种检测方法,联合检测。如Wang等人(2022a)使用Transformer 模型来捕获不同尺度上的细微操纵伪影,以进行深度假检测。
6)更好的可解释性。在研究中,本文对深度神经网络模型带来的优异性能深信不疑,但是推广到社会中的使用,必须在可解释性上做出突破。尤其是数字取证和反取证领域作为对攻击的取证和揭示,需要有好的解释性作为基础。如Dong 等人(2022a)从图像匹配的角度解释深度学习分类问题,并验证提出的3个假设。Le等人(2023)从可解释性的角度对不同预处理步骤和攻击者的有意操纵因素进行了定量和可视化展示。
5 结语
本文介绍了深度伪造的发展历史及其带来的问题,深度伪造检测技术在当今的网络空间安全中也越发重要。本文详细介绍了深度伪造技术数据集的发展现状和评价指标,总结了各种深度伪造工具,在已有的评价指标上单个数据集的检测效果已经远远满足不了现阶段的深度伪造检测器,而跨数据集的检测性能指标将会是评价检测器能力的重要参数,同时设计更有挑战的、综合的深度伪造检测评价性能指标来判断检测器的能力也是今后的热门方向之一。在检测方法中,最近新颖的重建学习方法善于放大伪影特征,今后将会是一个重要方式来帮助提升检测器性能。本文对深度伪造技术的未来挑战和发展前景进行了展望。深度伪造技术和深度伪造检测技术对人类社会不可估量的影响决定了其研究的巨大价值。随着技术的不断进步和不断普及,深度伪造技术将以迅猛的速度发展,这要求检测技术能够匹配这些伪造技术,甚至超越其水平。对于深度伪造技术和深度伪造检测的研究道路还很漫长,既要改进如今尚存的不足,也要面对未来技术进步带来的挑战。
